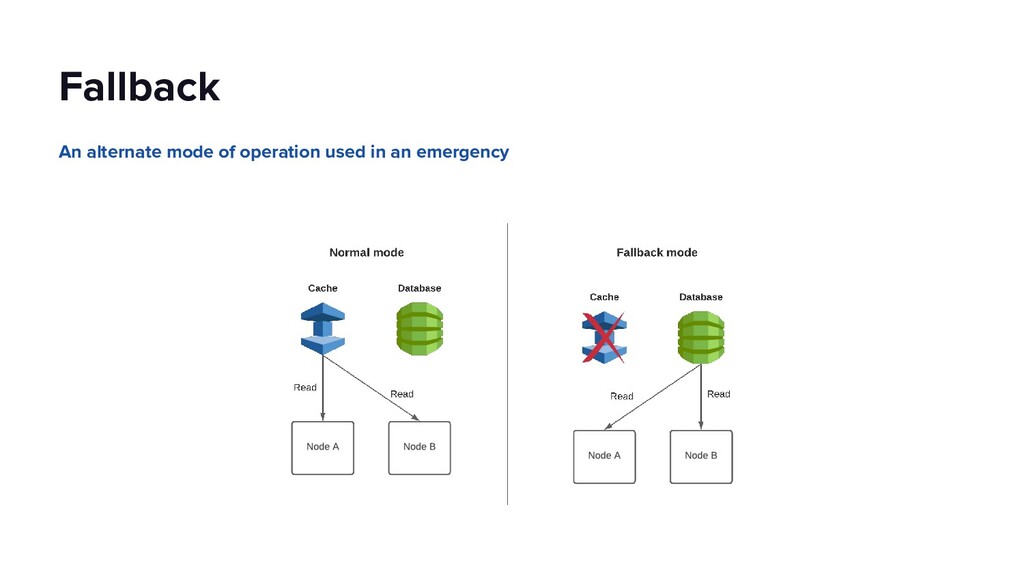
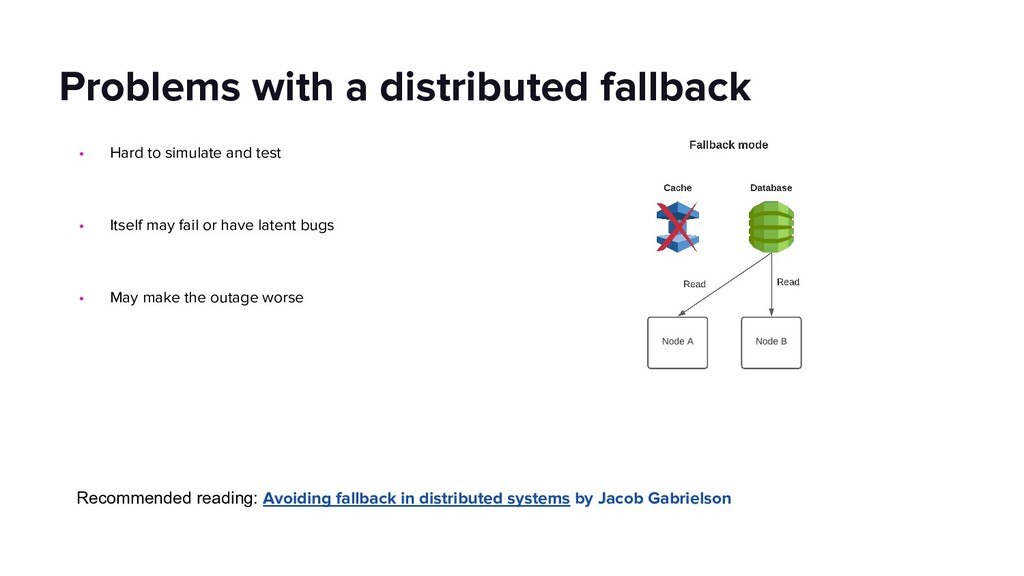
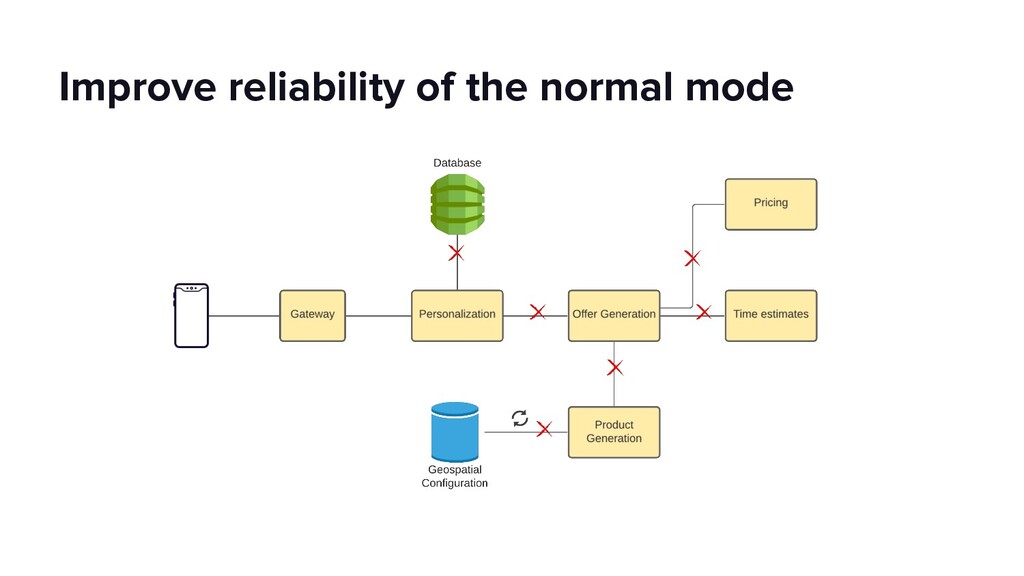
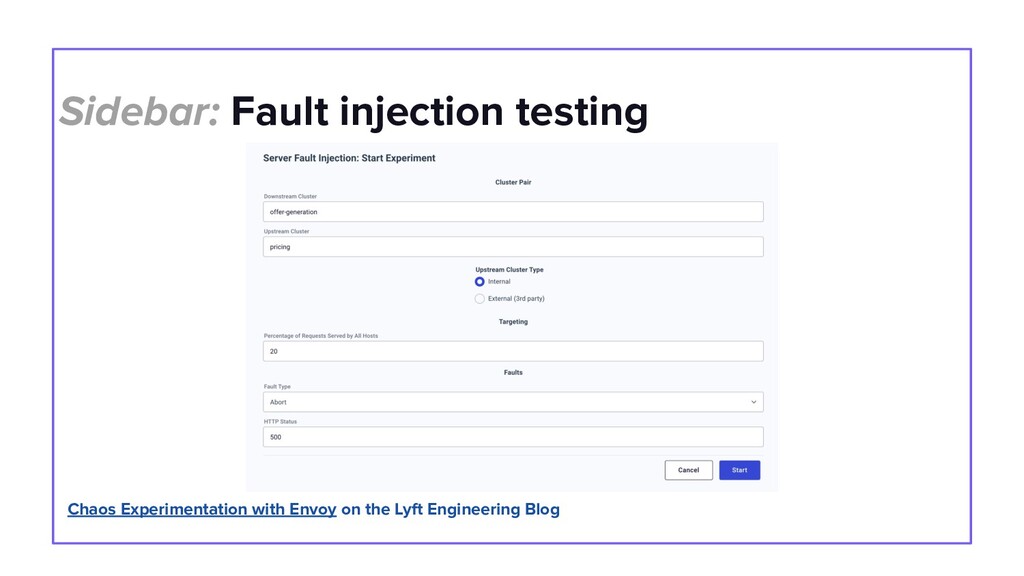
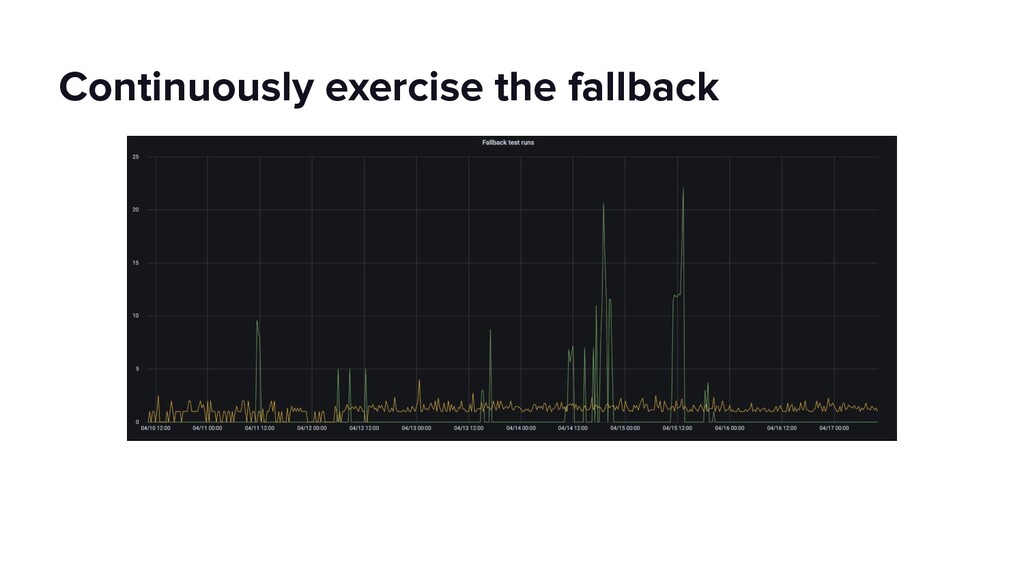
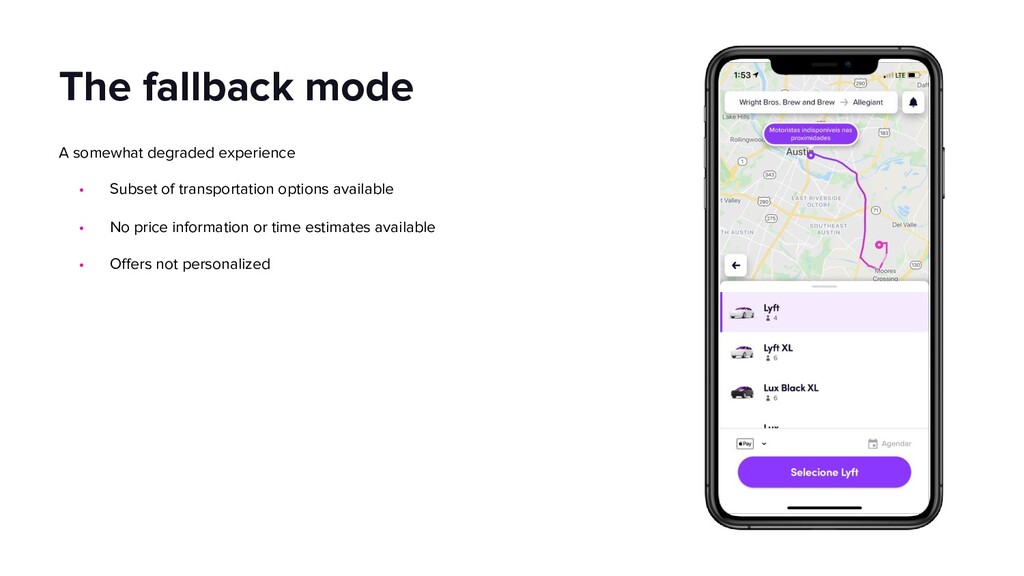
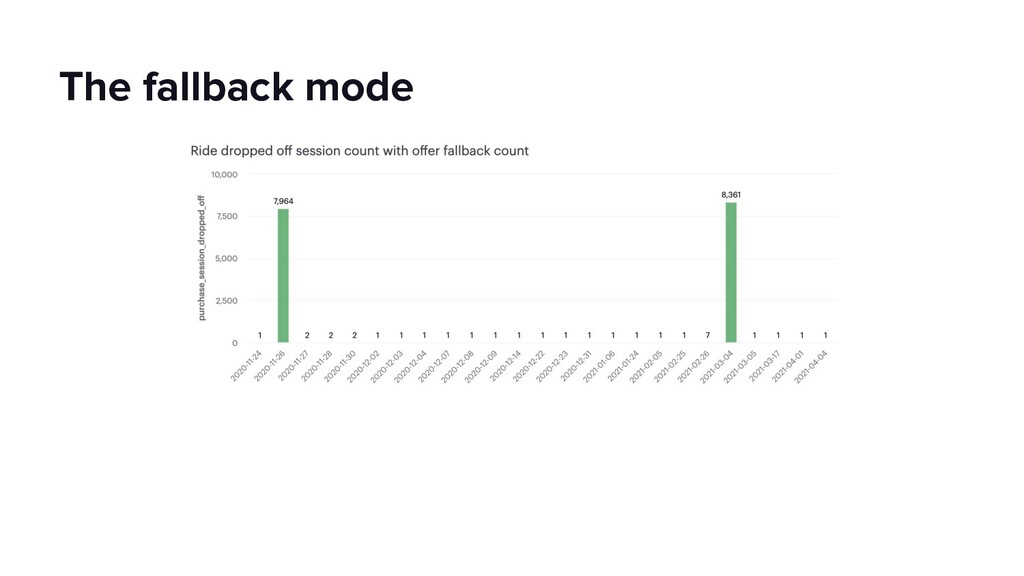
This talk will dive into the details of a best-effort fallback mechanism deployed at Lyft which helped us serve 8000 rides during a recent cloud provider outage, and continues to protect us from transient failures. We’ll talk about why we decided to pursue a fallback strategy despite its pitfalls, what the fallback experience looks like and how we overcame some of the challenges by building the automated mechanism in an API Gateway service. Our simple fallback design, and the techniques for simulating and testing it, will hopefully inspire the audience to start thinking about a best-effort fallback strategy for protecting their users.
{kind=link}
{kind=link}
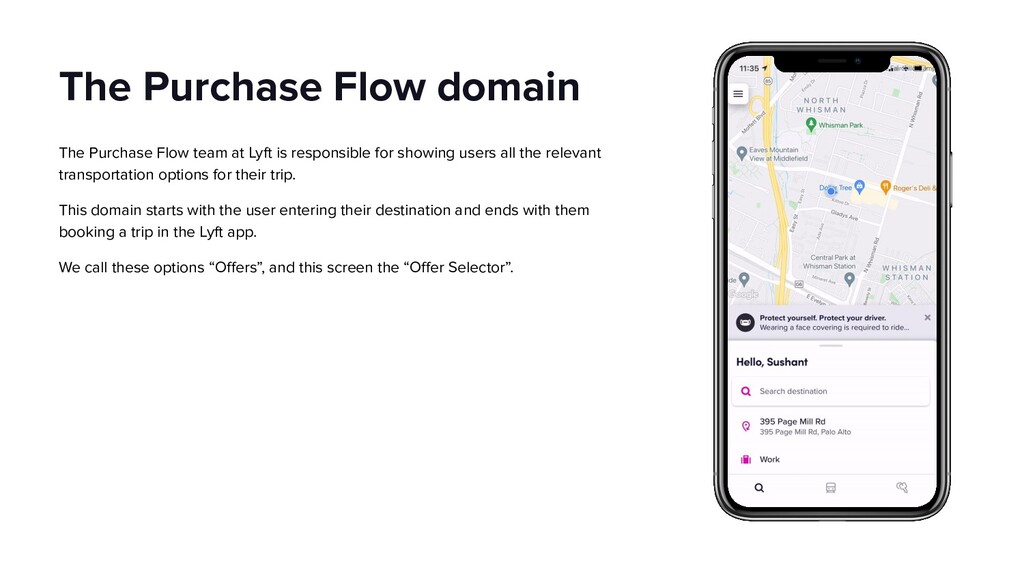{kind=link}
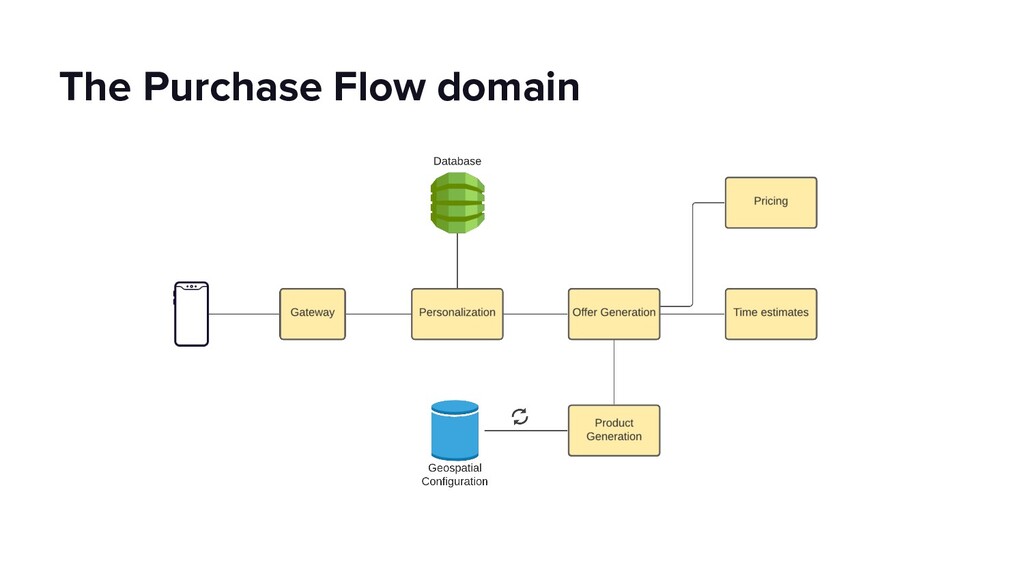{kind=link}
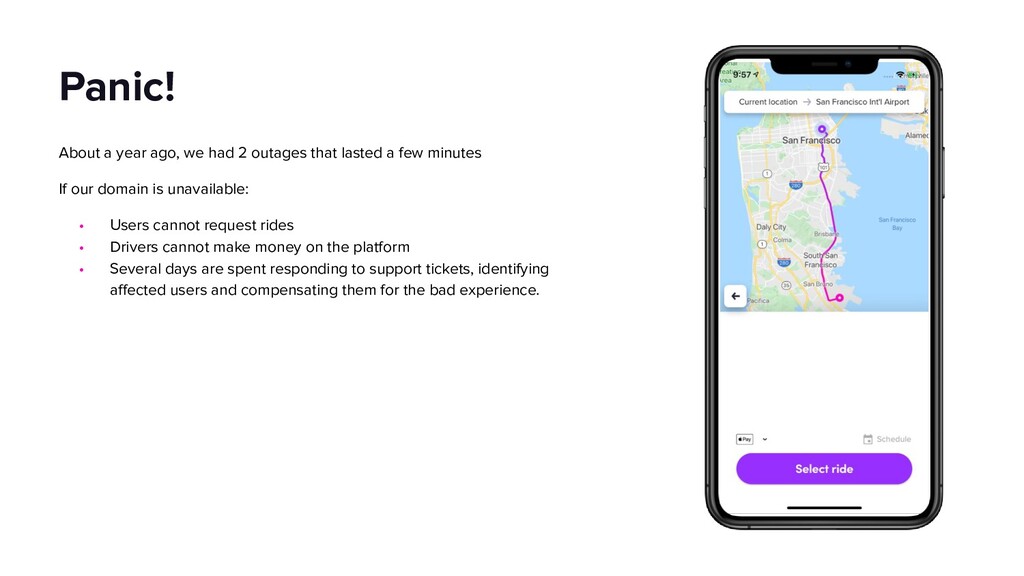{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}