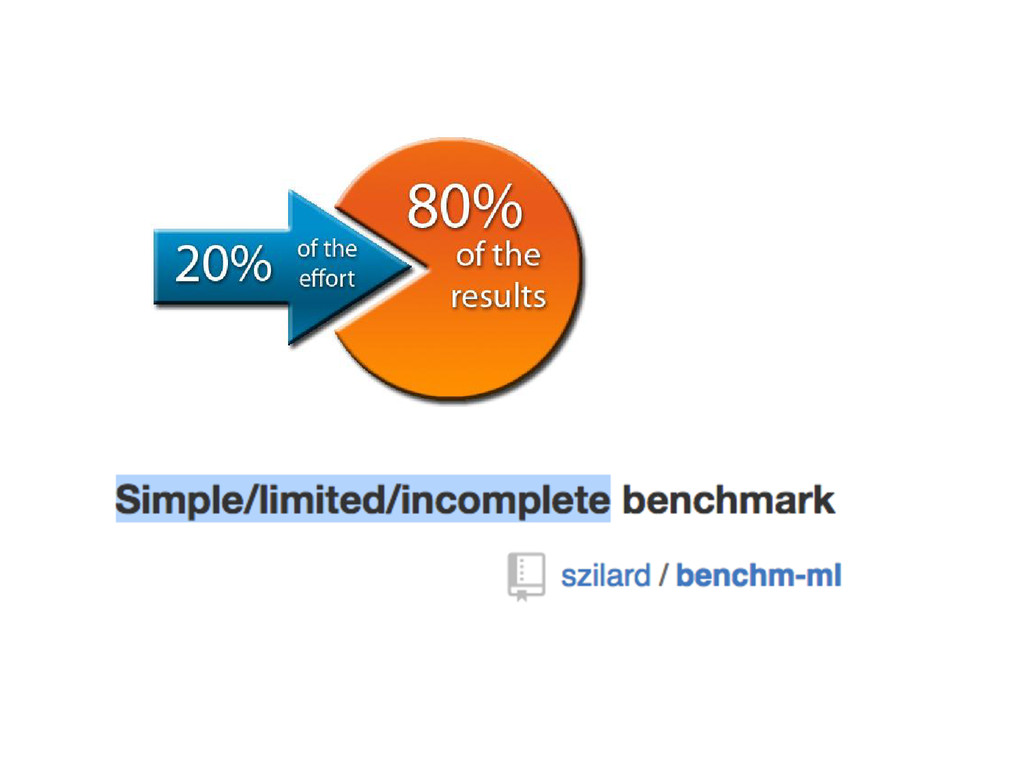
not “efficient” (from time budget perspective) to write my own algorithm [...] I can find open source code for what I want to do, and my time is much better spent doing research and feature engineering -- Owen Zhang http://blog.kaggle.com/2015/06/22/profiling-top-kagglers-owen-zhang-currently-1-in-the-world/
layer of complexity and [network] communication overhead. The ideal case is scaling linearly with the number of nodes; that’s rarely the case. Emerging evidence shows that very often, one big machine, or even a laptop, outperforms a cluster. http://fastml.com/the-emperors-new-clothes-distributed-machine-learning/
is diminishing as individual computing nodes (augmented with GPUs) become increasingly powerful. So I was ready for Jure Leskovec’s workshop talk [at NIPS 2014]. Here is a killer screenshot. -- Paul Mineiro
petabytes of [...] data to extract interesting features, but this paper explores the interesting possibility of switching over to a multi-core, shared-memory system for efficient execution on more refined datasets [...] e.g., machine learning http://openproceedings.org/2014/conf/edbt/KumarGDL14.pdf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![I usually use other people’s code [...] it is usually](https://files.speakerdeck.com/presentations/3df6476121524b17b7b417d75325c96e/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
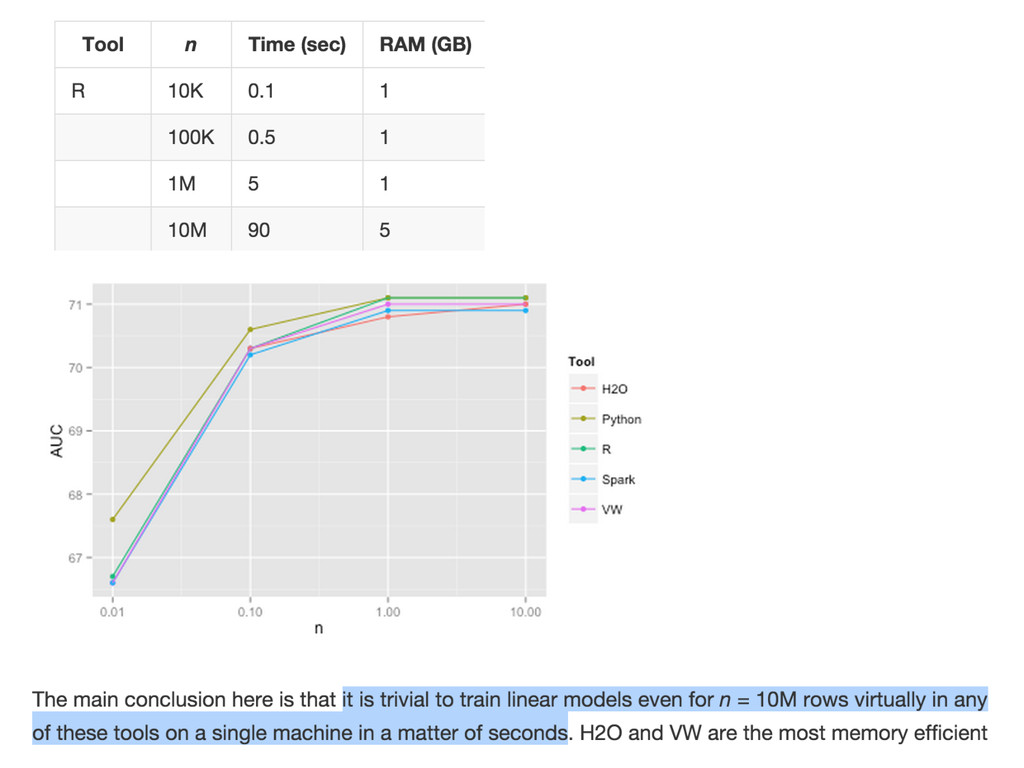{kind=link}
{kind=link}
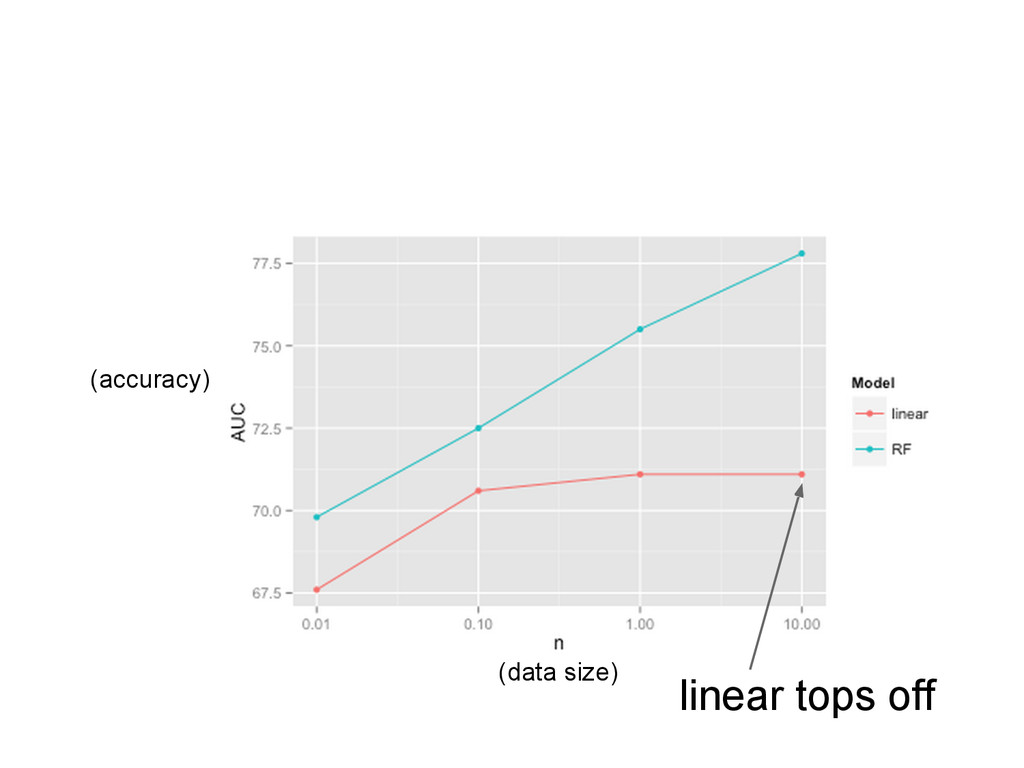{kind=link}
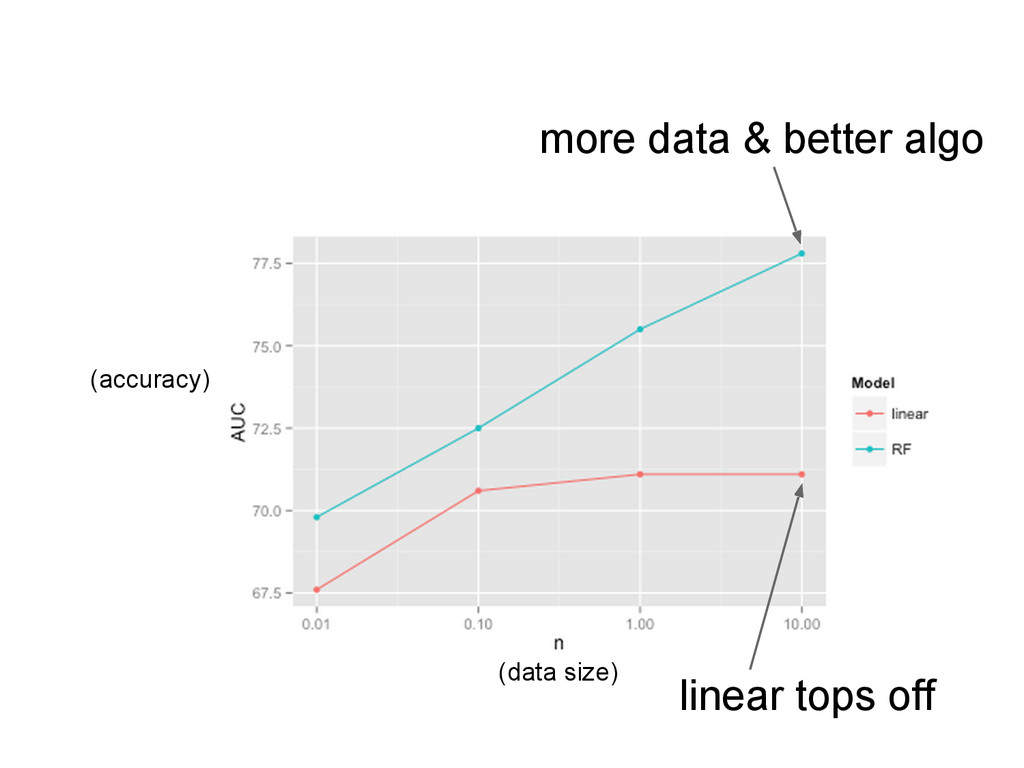{kind=link}
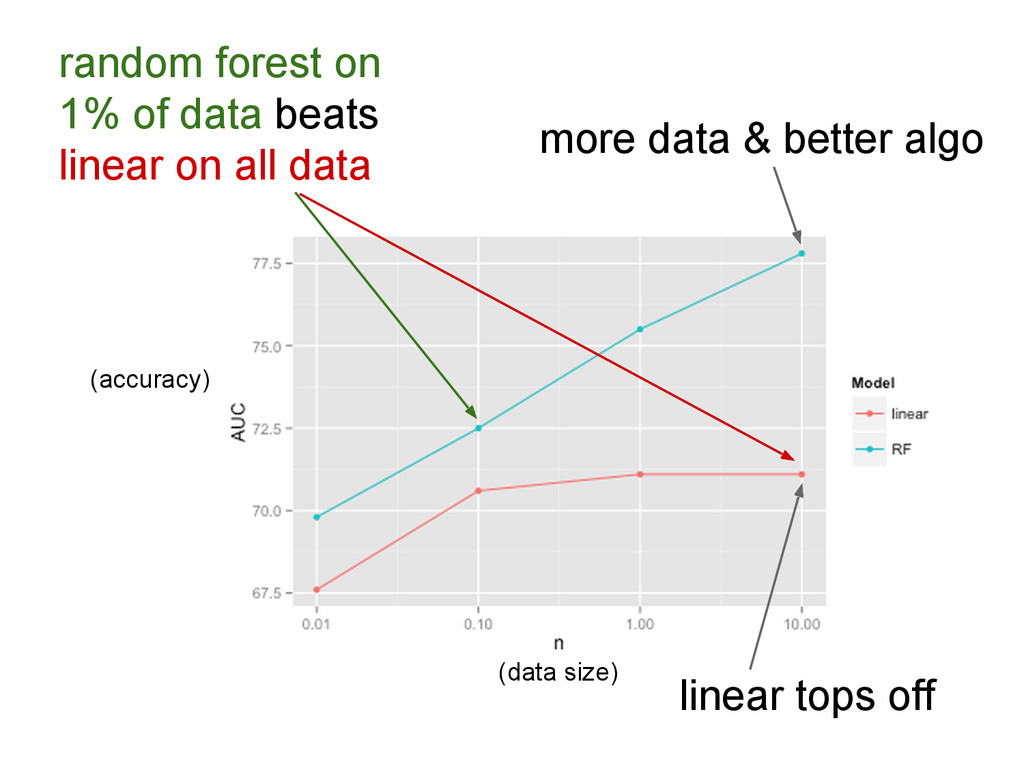{kind=link}
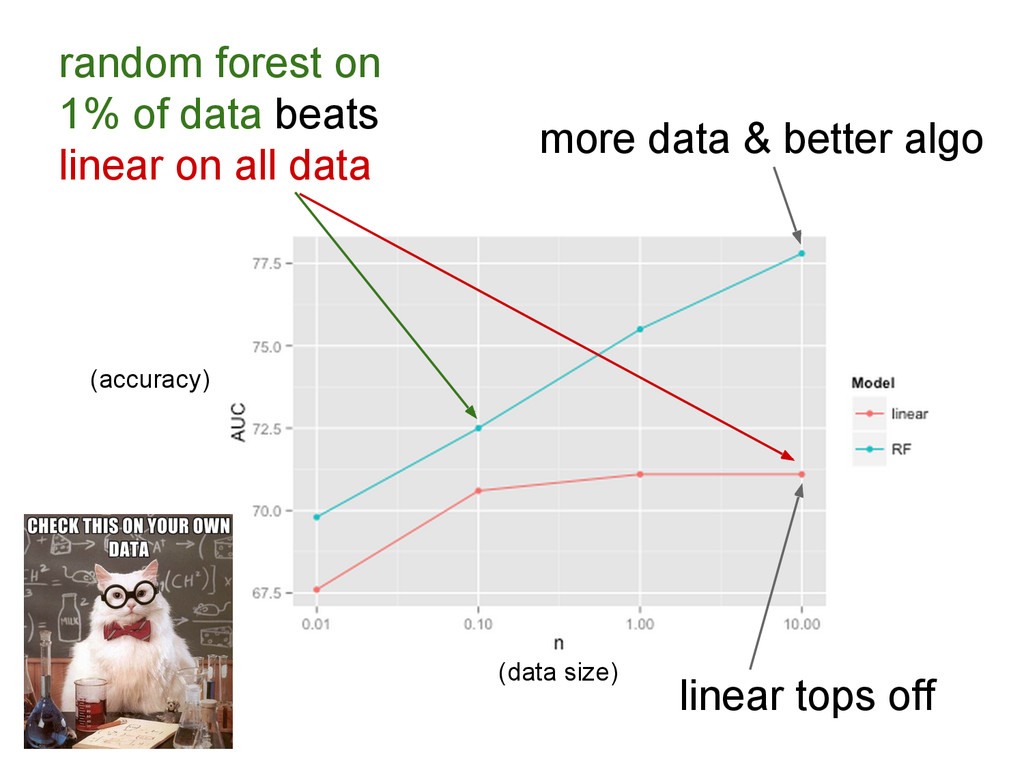{kind=link}
{kind=link}
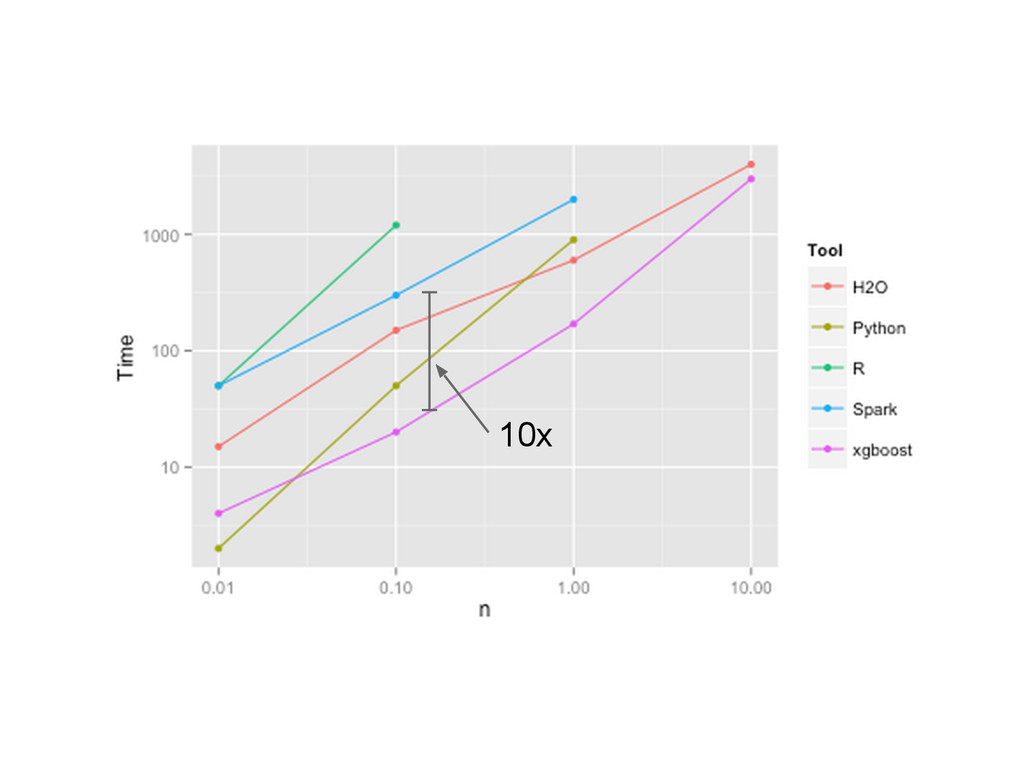{kind=link}
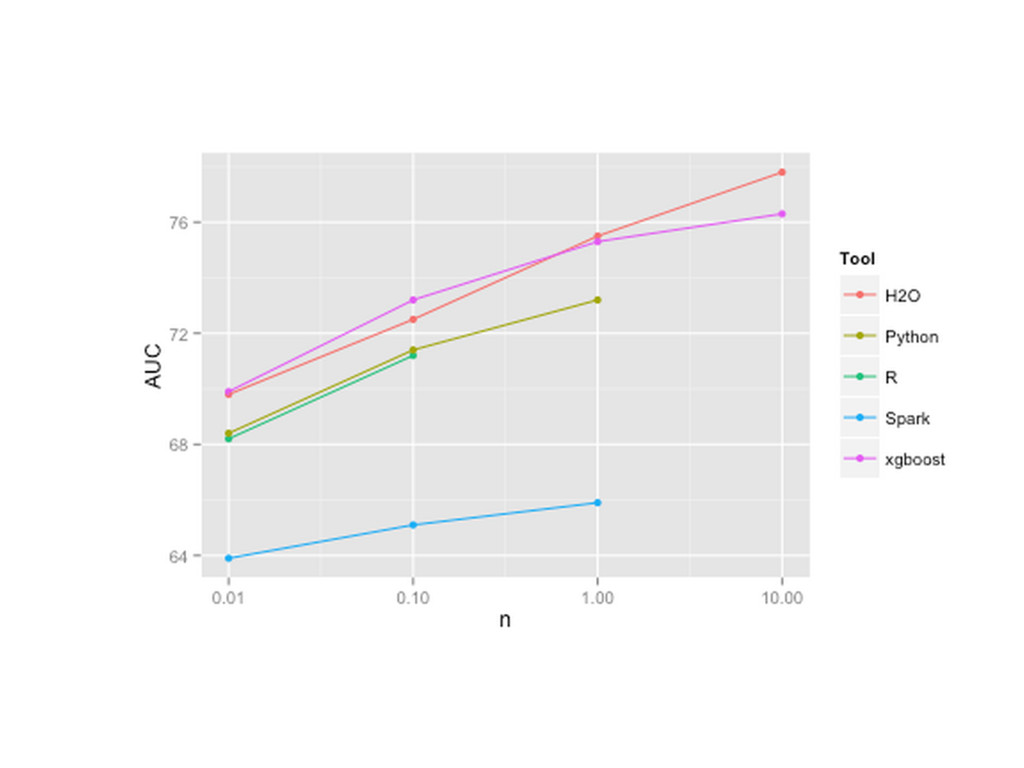{kind=link}
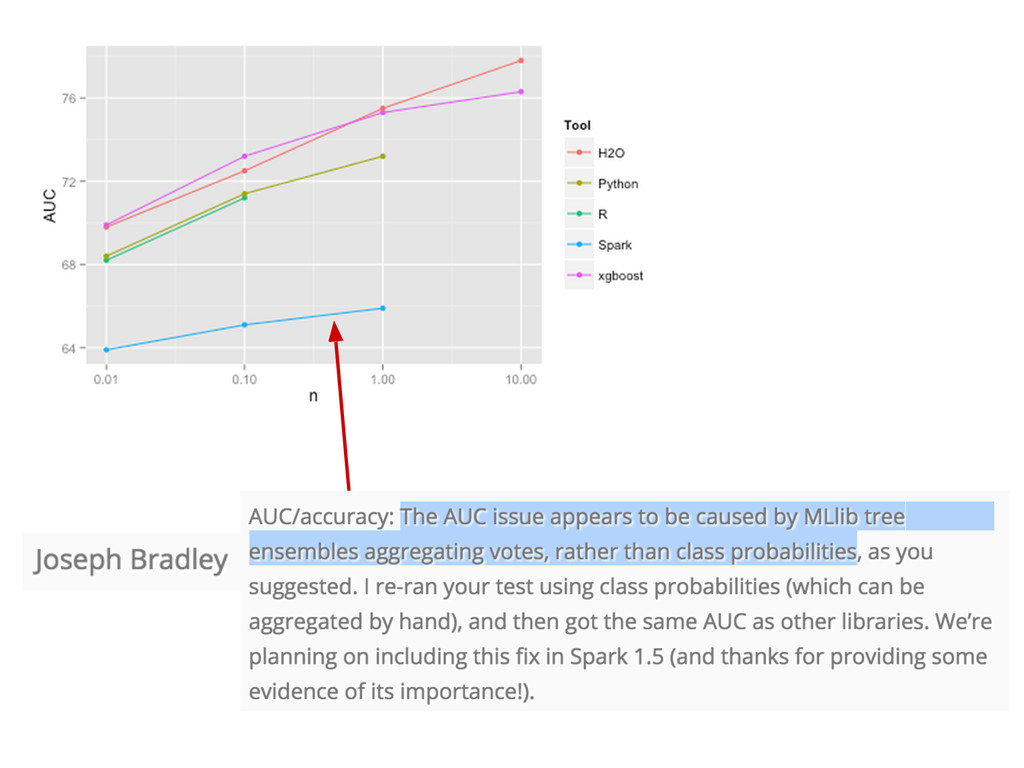{kind=link}
{kind=link}
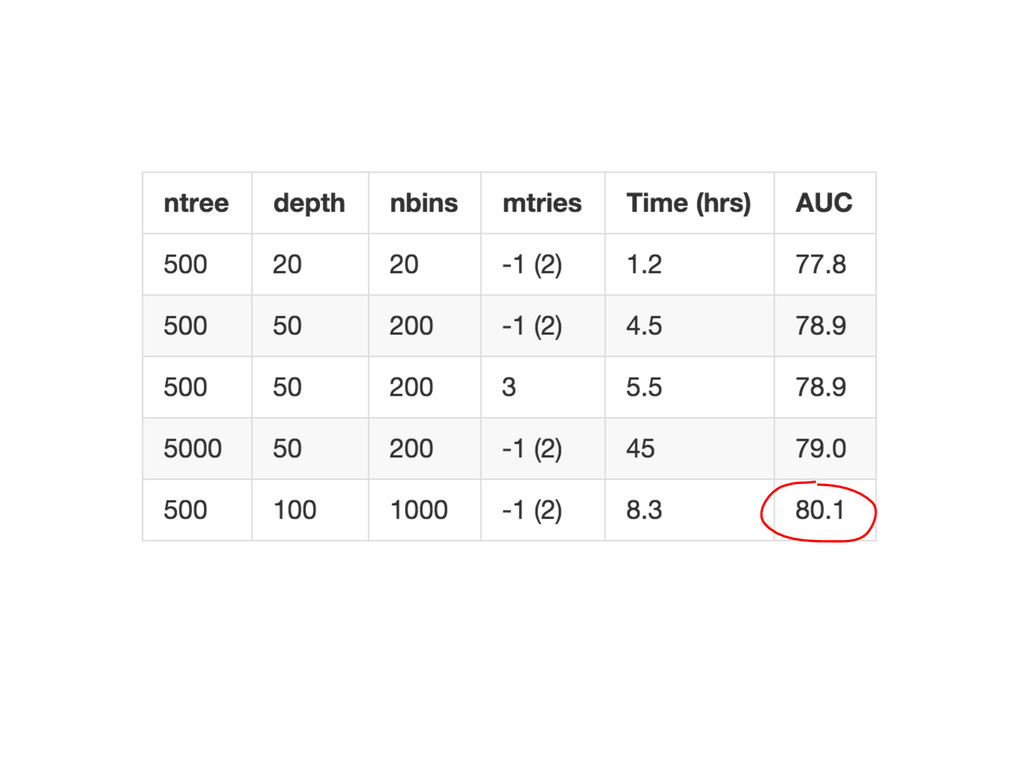{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![we will continue to run large [...] jobs to scan](https://files.speakerdeck.com/presentations/3df6476121524b17b7b417d75325c96e/slide_55.jpg){kind=link}
{kind=link}
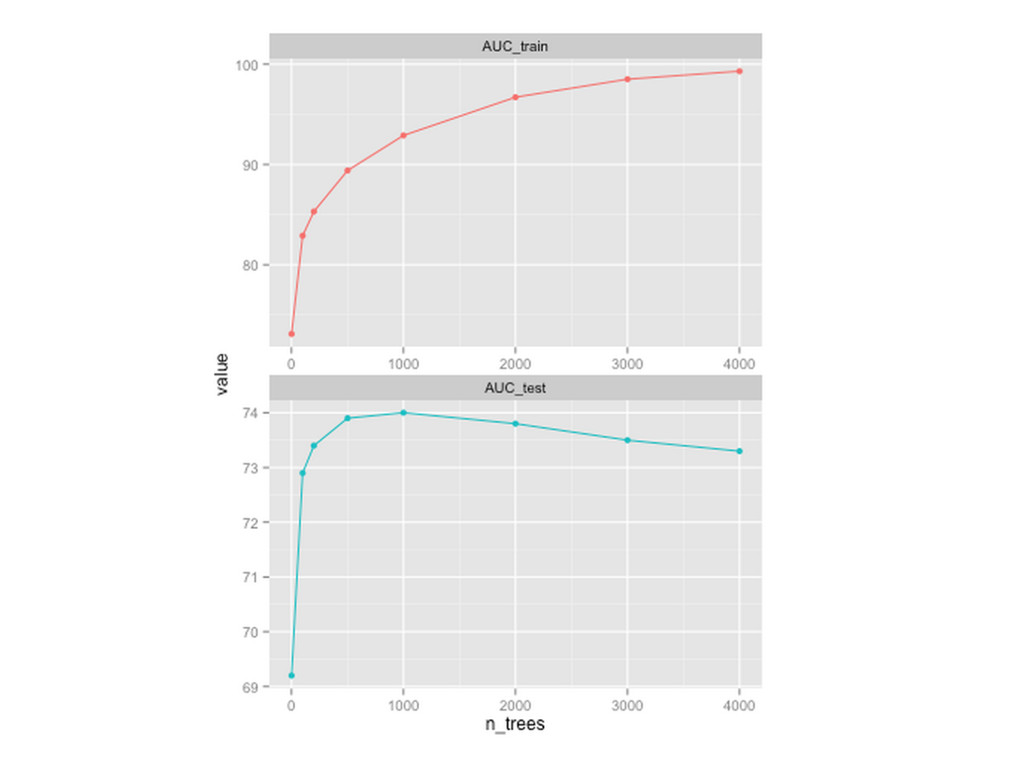{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}