Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Amazon_Bedrock_Knowledge_Basesを用いたAuth0調査の自動化.pdf
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
t.t
February 17, 2026
93
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Amazon_Bedrock_Knowledge_Basesを用いたAuth0調査の自動化.pdf
t.t
February 17, 2026
More Decks by t.t
See All by t.t
Bedrock AgentCore RuntimeでAuth0 Changelog調査AIをアップグレードした話
t5u8a5a
1
97
Serverless × AI で運用タスクを自動化した話
t5u8a5a
0
47
マイクロサービス×データ統合で実現する利用状況の全貌
t5u8a5a
0
43
Featured
See All Featured
Everyday Curiosity
cassininazir
0
230
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
540
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
380
XXLCSS - How to scale CSS and keep your sanity
sugarenia
250
1.3M
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
220
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
420
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Mind Mapping
helmedeiros
PRO
1
240
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
Chasing Engaging Ingredients in Design
codingconduct
0
220
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
1
180
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
240
Transcript
Amazon Bedrock Knowledge Bases を用いた Auth0 調査の自動化 エムオーテックス株式会社 辻 翼
自己紹介 名前 • 辻 翼(つじ つばさ) 業務内容 • AWS を用いたクラウドアプリケーションの開発
プライベート • バスケで汗を流してストレス発散中 • 家では子どもと犬に振り回される日々... 2 @tsu2_dev (最近始めました) 所属 • エムオーテックス株式会社 AWS 歴 • 4年ぐらい 好きな AWS サービス • Amazon Bedrock(まだまだ勉強中)
背景 • 弊社製品の認証基盤では Auth0 を使用している • Auth0 は外部サービスのため、日々 Changelog の監視を行っている
• すでに Auth0 Changelog の RSS を監視して自動通知する仕組みはあるが、 「アップデート内容の要約」や「弊社製品への影響有無」は手動実施 3 この手動作業を AI で自動化したい!!
要件とサービス選定 4 • Auth0 が更新されたら、自動で調査を始めてほしい • kiro cli のような対話型ツールは手動での質問が必要なので要件を満たせず •
RAG(検索拡張生成)を一から実装したくない • 文書のベクトル化、ベクトルストアの作成/保存、ベクトル検索の実装、 質問のベクトル化、検索結果+質問で回答取得、…(やること多すぎ) • コストを抑えたい • ベクトルストアは S3 Vectors を使用したい
要件とサービス選定 5 Amazon Bedrock Knowledge Bases なら要件を満たせそうだよ! これらの要件を満たせる サービスないかな? なにそれ!?
詳しく教えて!! それはね・・・ kiro kiro t.t t.t
Amazon Bedrock Knowledge Bases とは 独自データを活用したRAG(検索拡張生成)を簡単に実現できるサービス 従来のAIは一般的な知識しか持たないが、Knowledge Bases により 社内文書や専門知識を参照してより正確な回答を生成できる
6 カスタマイズ性は制限されるが、RAGの実装工数を大幅削減できる! フェーズ 独自RAG Knowledge Bases データ準備・取り込み ベクトルDB構築・設定が必要 S3への文書アップロードのみ 埋め込みモデル選定・実装 ベクトル化・インデックス自動 検索・参照 検索アルゴリズム実装が必要 関連文書の自動検索 検索ロジックを自由にカスタマイズ 検索方法の調整は制限 回答生成 RAG統合ロジックの実装が必要 検索結果+AIモデルで自動生成 回答フォーマットを自由に制御 根拠文書も自動で提示
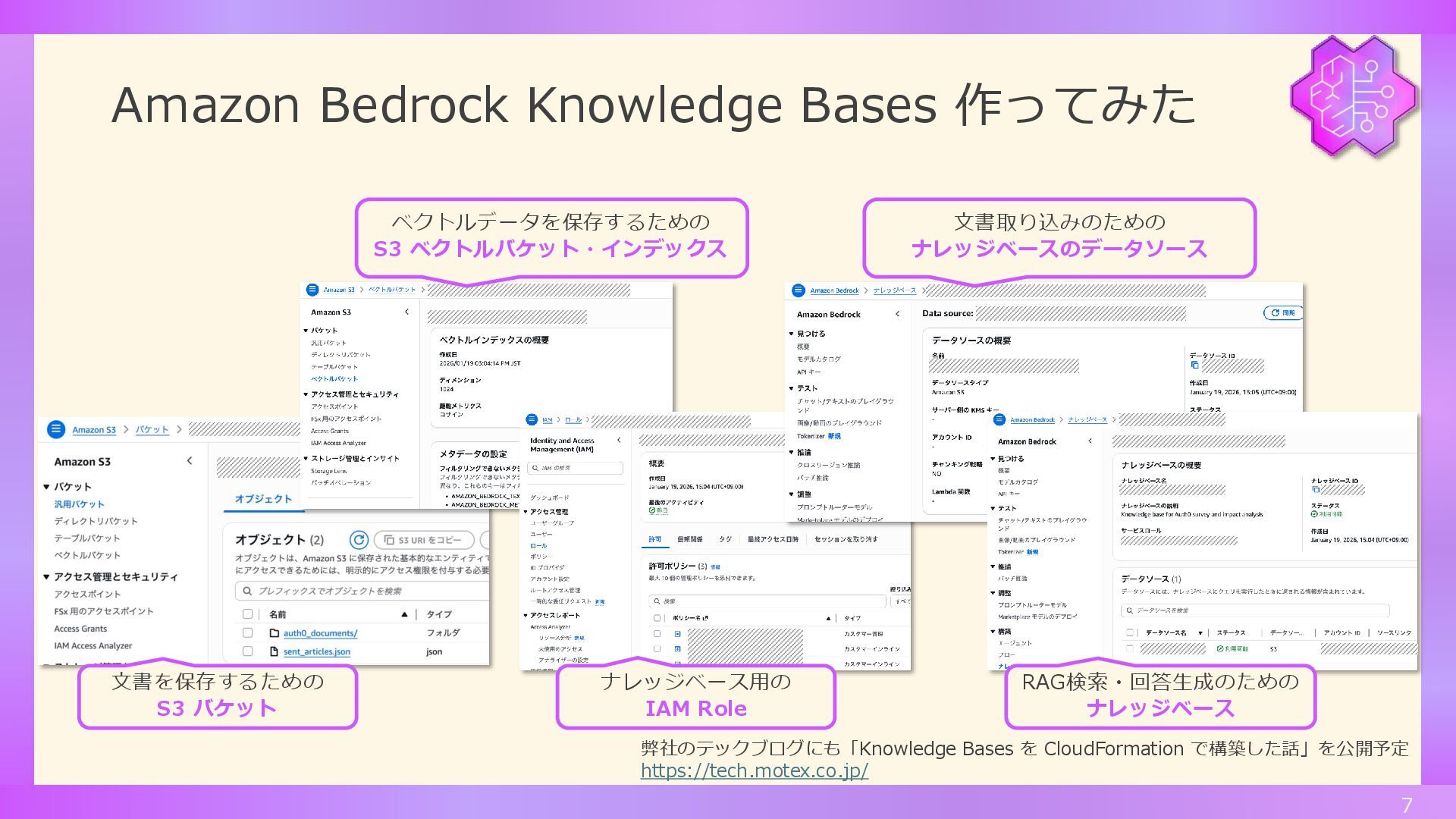
Amazon Bedrock Knowledge Bases 作ってみた 7 弊社のテックブログにも「Knowledge Bases を CloudFormation
で構築した話」を公開予定 https://tech.motex.co.jp/ 文書を保存するための S3 バケット ベクトルデータを保存するための S3 ベクトルバケット・インデックス 文書取り込みのための ナレッジベースのデータソース RAG検索・回答生成のための ナレッジベース ナレッジベース用の IAM Role
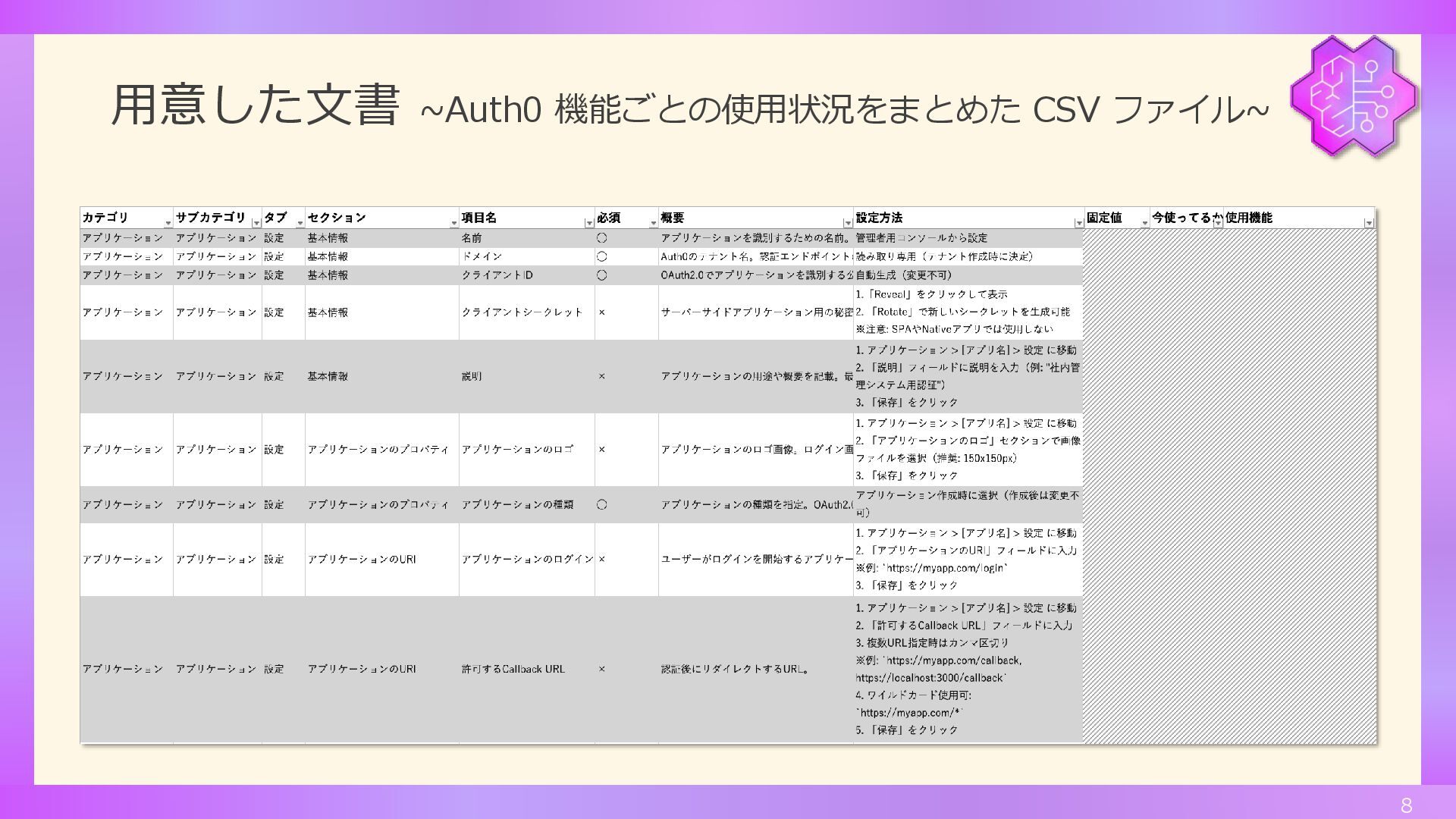
用意した文書 ~Auth0 機能ごとの使用状況をまとめた CSV ファイル~ 8
Amazon Bedrock Knowledge Bases にアクセス 9 Python コード(boto3)だと retrieve_and_generate で
RAG 検索・回答取得が可能 BEDROCK_AGENT_CLIENT = boto3.client(service_name='bedrock-agent-runtime’, region_name=REGION_NAME) def summarize_with_knowledge_base(changelog_content: str) -> str: """Bedrock Knowledge BaseでAuth0 Changelogを要約""" response = BEDROCK_AGENT_CLIENT.retrieve_and_generate( input={ 'text': changelog_content }, retrieveAndGenerateConfiguration={ 'type': 'KNOWLEDGE_BASE', 'knowledgeBaseConfiguration': { 'knowledgeBaseId': KNOWLEDGE_BASE_ID, 'modelArn': f'arn:aws:bedrock:{REGION_NAME}::foundation-model/{MODEL_ID}', 'retrievalConfiguration': { 'vectorSearchConfiguration': { 'numberOfResults': 10 }}, 'generationConfiguration': { 'inferenceConfig': { 'textInferenceConfig': { 'maxTokens': 4096, 'temperature': 0.0}}, 'promptTemplate': { 'textPromptTemplate': Auth0AnalysisPromptTemplate.PROMPT_TEMPLATE} } } } ) return response['output']['text'] 直接モデルを呼び出すわけではないため、 `bedrock-runtime`ではなく `bedrock-agent-runtime`になる 質問に関連する文書の 上位何件を対象にするか 質問や処理対象のテキストを渡す 独自の回答を生成するため、 デフォルトプロンプトをカスタムテンプレートで上書き 使用するKnowledge BaseのID 回答生成に使用するLLM(Claude等)のARN
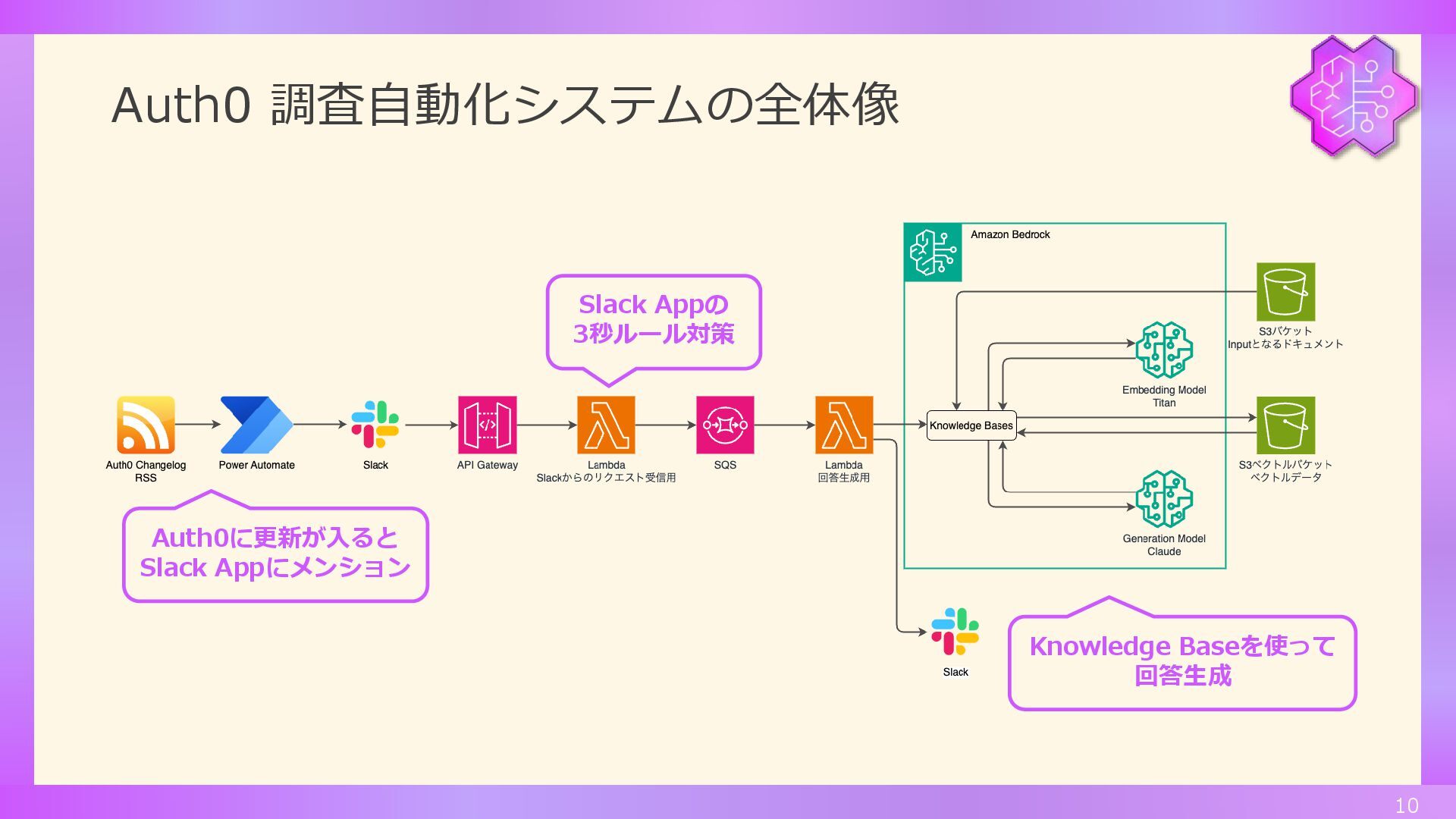
Auth0 調査自動化システムの全体像 10 Auth0に更新が入ると Slack Appにメンション Slack Appの 3秒ルール対策 Knowledge
Baseを使って 回答生成
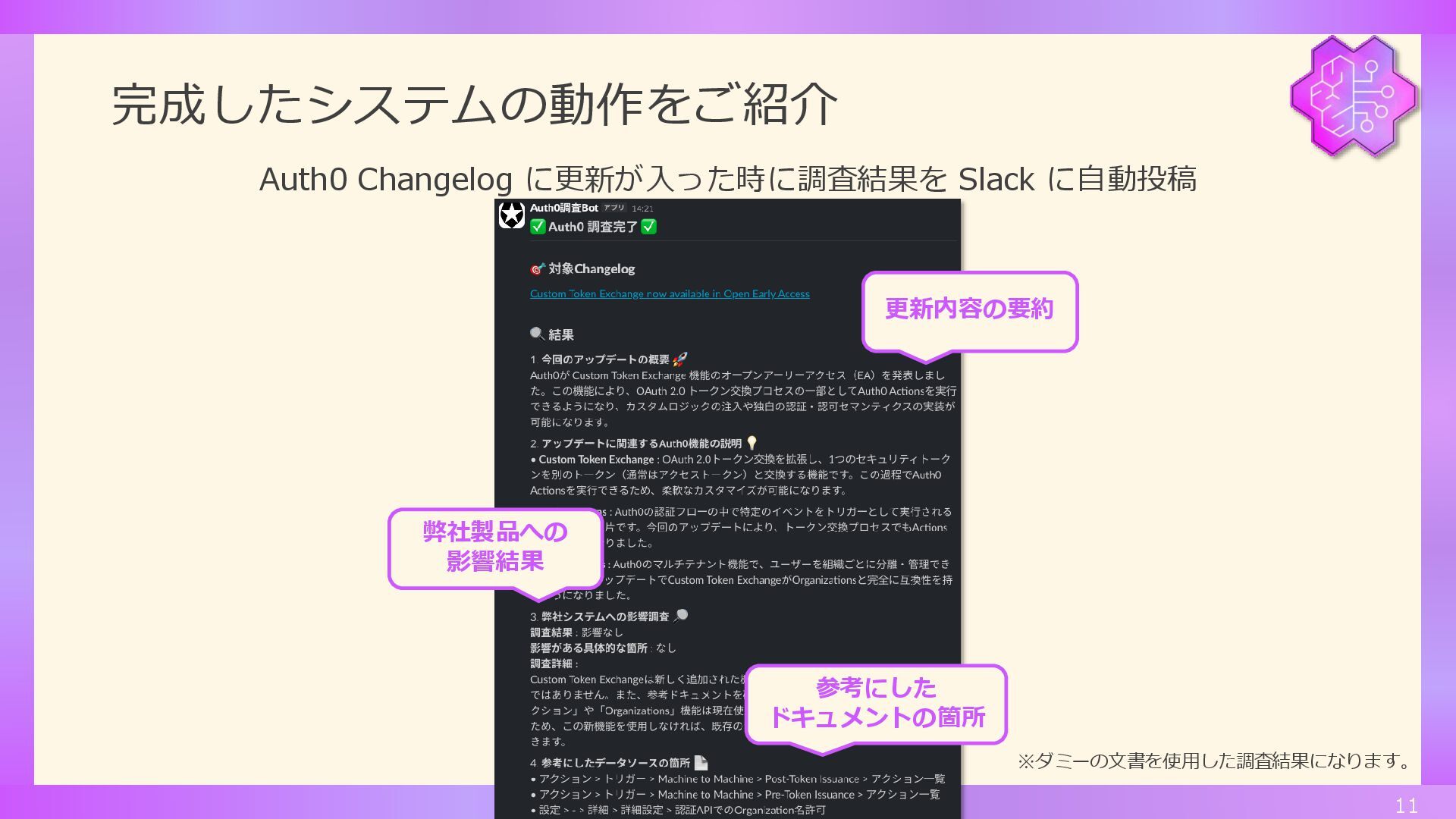
完成したシステムの動作をご紹介 11 Auth0 Changelog に更新が入った時に調査結果を Slack に自動投稿 ※ダミーの文書を使用した調査結果になります。 弊社製品への 影響結果
更新内容の要約 参考にした ドキュメントの箇所
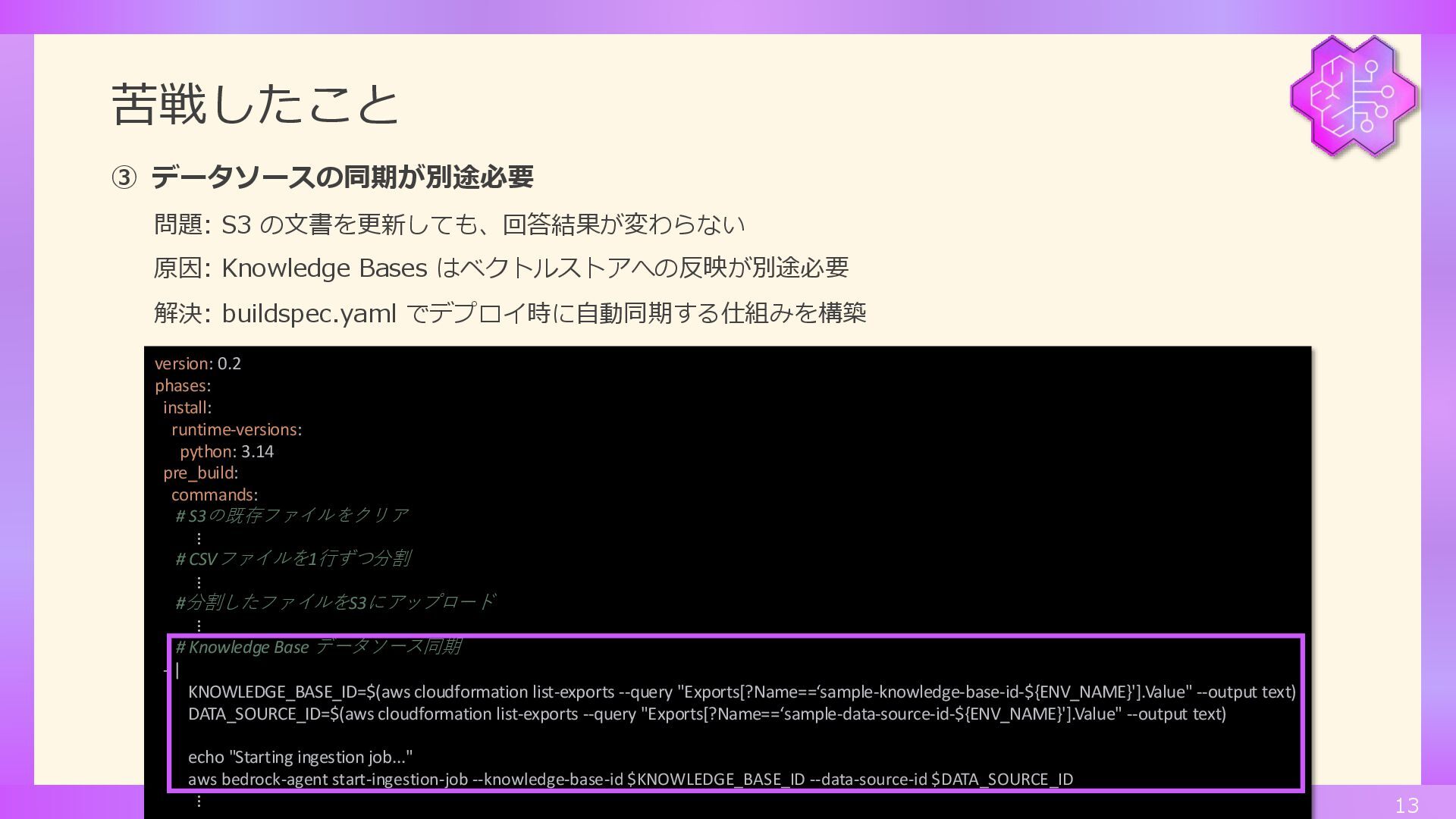
苦戦したこと ① チャンキングの重要性 問題: 回答精度が低い 原因: CSVの複数行が1つのチャンクに含まれてた 解決: 1行ずつファイル分割 +
ChunkingStrategy: NONE • FIXED_SIZE: 固定サイズでチャンク分割(デフォルト300トークン) • HIERARCHICAL: 階層的チャンク(親・子チャンク) • SEMANTIC: 意味的まとまりでチャンク分割 • NONE: 1ファイル = 1チャンク(今回採用) ② プロンプトの競合問題 問題: `Sorry, I am unable to assist you with this request.`という回答が返ってくる 原因: Knowledge Bases のデフォルトプロンプトと独自プロンプトが競合していた(っぽい) 解決: プロンプトテンプレートで上書き($search_results$, $query$ のみ使用) • $search_results$: 検索された関連文書 • $query$: ユーザーの質問内容 • $output_format_instruction$: 出力形式の指示 • $current_time$: 現在時刻 12
苦戦したこと 13 version: 0.2 phases: install: runtime-versions: python: 3.14 pre_build:
commands: # S3の既存ファイルをクリア ⋮ # CSVファイルを1行ずつ分割 ⋮ #分割したファイルをS3にアップロード ⋮ # Knowledge Base データソース同期 - | KNOWLEDGE_BASE_ID=$(aws cloudformation list-exports --query "Exports[?Name==‘sample-knowledge-base-id-${ENV_NAME}'].Value" --output text) DATA_SOURCE_ID=$(aws cloudformation list-exports --query "Exports[?Name==‘sample-data-source-id-${ENV_NAME}'].Value" --output text) echo "Starting ingestion job..." aws bedrock-agent start-ingestion-job --knowledge-base-id $KNOWLEDGE_BASE_ID --data-source-id $DATA_SOURCE_ID ⋮ ③ データソースの同期が別途必要 問題: S3 の文書を更新しても、回答結果が変わらない 原因: Knowledge Bases はベクトルストアへの反映が別途必要 解決: buildspec.yaml でデプロイ時に自動同期する仕組みを構築
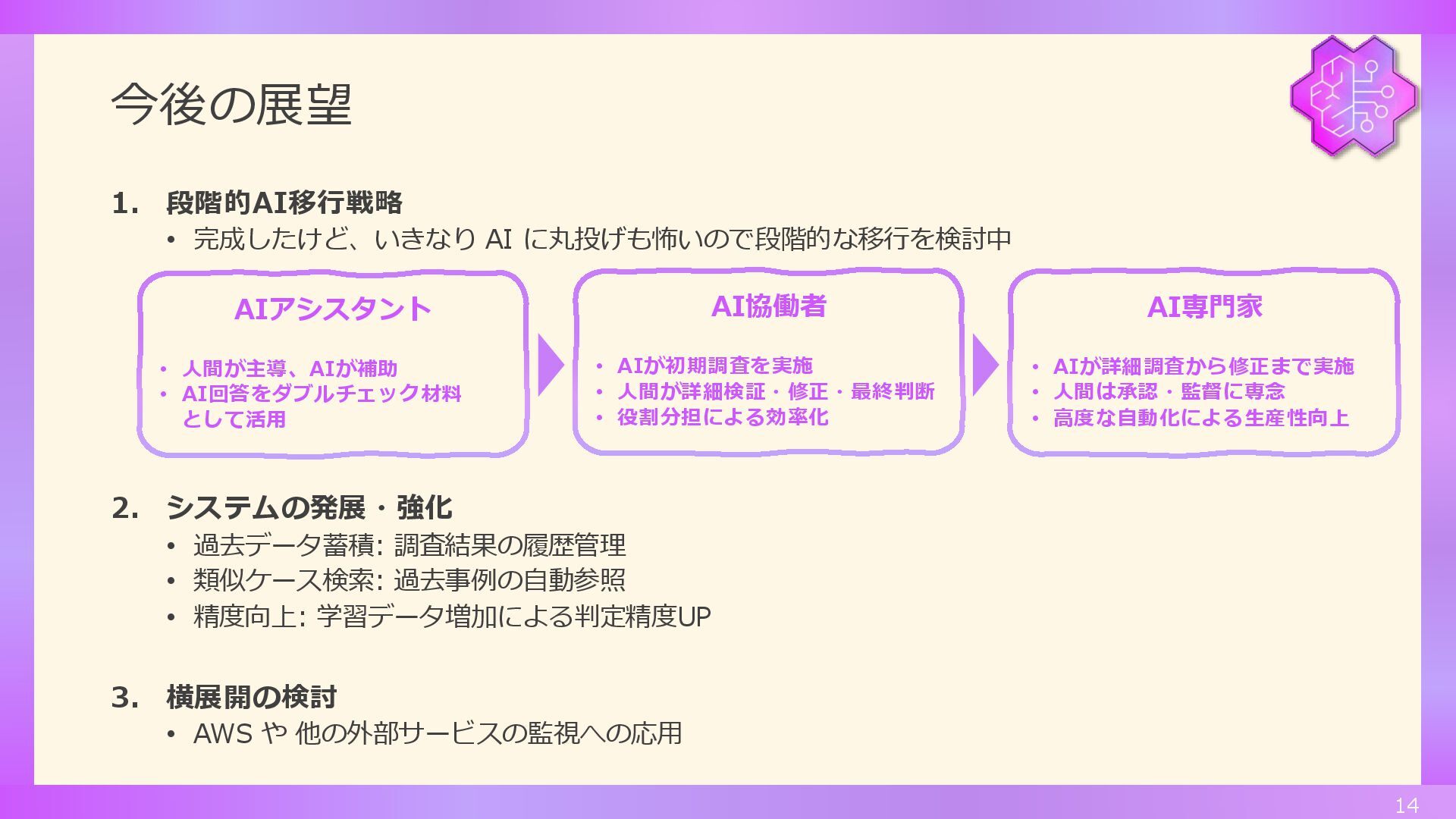
今後の展望 1. 段階的AI移行戦略 • 完成したけど、いきなり AI に丸投げも怖いので段階的な移行を検討中 2. システムの発展・強化 •
過去データ蓄積: 調査結果の履歴管理 • 類似ケース検索: 過去事例の自動参照 • 精度向上: 学習データ増加による判定精度UP 3. 横展開の検討 • AWS や 他の外部サービスの監視への応用 14 AIアシスタント • 人間が主導、AIが補助 • AI回答をダブルチェック材料 として活用 AI協働者 • AIが初期調査を実施 • 人間が詳細検証・修正・最終判断 • 役割分担による効率化 AI専門家 • AIが詳細調査から修正まで実施 • 人間は承認・監督に専念 • 高度な自動化による生産性向上
さいごに Knowledge Basesは、チャンキング戦略やプロンプト調整といった細かい部分で 試行錯誤は必要でしたが、思っていた以上に導入のハードルは低く、 すぐに動くものを作ることができました。 今後はKnowledge Baseのチューニングやパフォーマンス最適化を通じて、 仕組みのより深い部分まで探求していきたいと考えています。 本日はご清聴いただき、ありがとうございました! 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}