Victor Chernozhukov’s 2016 U Chicago presentation. https://www.youtube.com/watch?v=eHOjmyoPCFU Konan Hara (Arizona) Double/debiased machine learning March 8, 2021 2 / 26
model: Y = Dθ0 + g0 (X) + U, E[U|X, D] = 0 D = m0 (X) + V, E[V |X] = 0 , where we are interested in θ0 , and (g0 (·), m0 (·)) are regarded as nuisance parameters with very high dimension. Konan Hara (Arizona) Double/debiased machine learning March 8, 2021 3 / 26
lasso to the following model? Y = Dθ0 + X β0 + U, E[U|X, D] = 0, β0 ∈ Rp, where p is very large. Konan Hara (Arizona) Double/debiased machine learning March 8, 2021 5 / 26
ML prediction approach to the following model? Y = Dθ0 + g0 (X) + U, E[U|X, D] = 0. 1. Start from a guess of θ0 ⇒ ˆ θ0 2. Apply ML to predict Y − Dˆ θ0 using X ⇒ ˆ g1(·) 3. Regress Y − ˆ g1(X) on D ⇒ ˆ θ1 4. Iterate until convergence ⇒ ˆ θ0 Konan Hara (Arizona) Double/debiased machine learning March 8, 2021 6 / 26
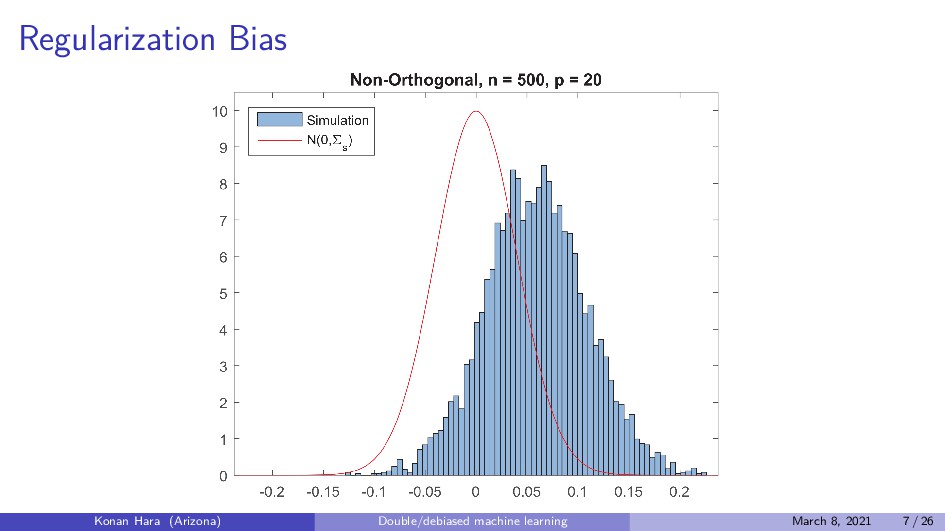
U, E[U|X, D] = 0, β0 ∈ Rp, where p is small enough. θ0 can be consistently estimated by regressing residual of regression Y on X on residual of regression D on X. Konan Hara (Arizona) Double/debiased machine learning March 8, 2021 8 / 26
estimation to the following? Y = Dθ0 + X β0 + U, E[U|X, D] = 0, β0 ∈ Rp, where p is very large. 1. Apply lasso to predict D by X, and collect the residual ⇒ ˆ V 2. Apply lasso to predict Y by X, and collect the residual ⇒ ˆ W 3. Regress ˆ W on ˆ V ⇒ DML estimator ˆ θ0 Konan Hara (Arizona) Double/debiased machine learning March 8, 2021 9 / 26
= Dθ0 + g0 (X) + U, E[U|X, D] = 0. 1. Apply ML to predict D by X, and collect the residual ⇒ ˆ V 2. Apply ML to predict Y by X, and collect the residual ⇒ ˆ W 3. Regress ˆ W on ˆ V ⇒ DML estimator ˆ θ0 Konan Hara (Arizona) Double/debiased machine learning March 8, 2021 10 / 26
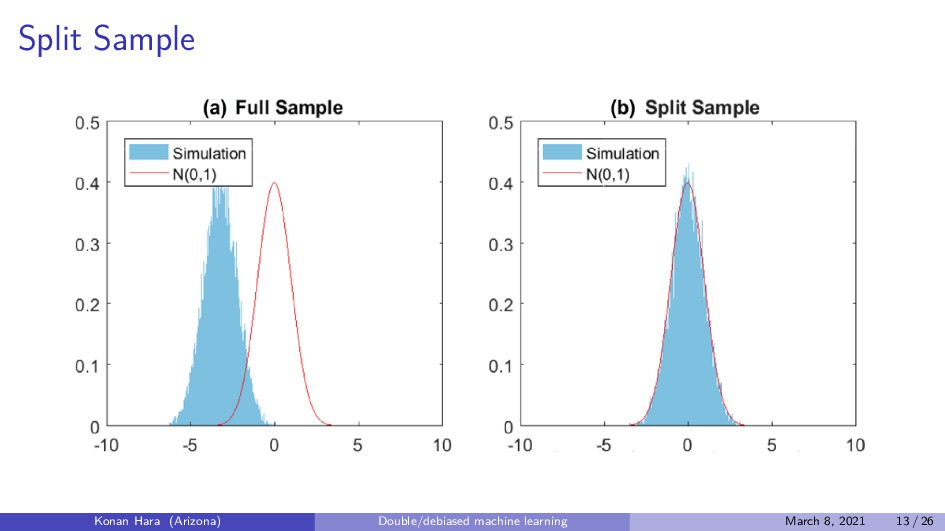
implementing 1. Estimation for residuals ˆ V and ˆ W 2. Regression ˆ W on ˆ V to get consistency. Konan Hara (Arizona) Double/debiased machine learning March 8, 2021 12 / 26
Dθ0 + X β0 + U, E[U|X, D] = 0 D = X γ0 + V, E[V |X] = 0 , where the demension of X, p, is very large. Apply lasso to predict D/Y by X, and collect the residual ⇒ ˆ V / ˆ W Let ˆ γ0 /ˆ µ be the lasso parameter for the predictions: ˆ V = D − X ˆ γ0 ; ˆ W = Y − X ˆ µ. Define ˆ β0 = ˆ µ − ˆ γ0 θ0 . DML estimator: ˆ θ0 = 1 n n i=1 ˆ V 2 i −1 1 n n i=1 ˆ Vi ˆ Wi . Konan Hara (Arizona) Double/debiased machine learning March 8, 2021 14 / 26
− Xi ˆ γ0 = Di − Xi γ + Xi (γ − ˆ γ0 ) = Vi + Xi (γ − ˆ γ0 ) and ˆ Wi = Yi − Xi ˆ µ = ˆ Vi θ0 − ˆ Vi θ0 + Yi − Xi ˆ µ = ˆ Vi θ0 − (Di − Xi ˆ γ0 )θ0 + Yi − Xi (ˆ γ0 θ0 + ˆ β0 ) = ˆ Vi θ0 + (Yi − Di θ0 − Xi β0 ) + Xi (β0 − ˆ β0 ) = ˆ Vi θ0 + Ui + Xi (β0 − ˆ β0 ). Konan Hara (Arizona) Double/debiased machine learning March 8, 2021 15 / 26
√ n(ˆ θ0 − θ0 ) ≈ 1 n n i=1 ˆ V 2 i −1 1 √ n n i=1 (Vi + Xi (γ − ˆ γ0 ))(Ui + Xi (β0 − ˆ β0 )). Since 1 n n i=1 ˆ V 2 i p → E[V 2] < ∞, it is enough to focus on the numerator. Konan Hara (Arizona) Double/debiased machine learning March 8, 2021 16 / 26
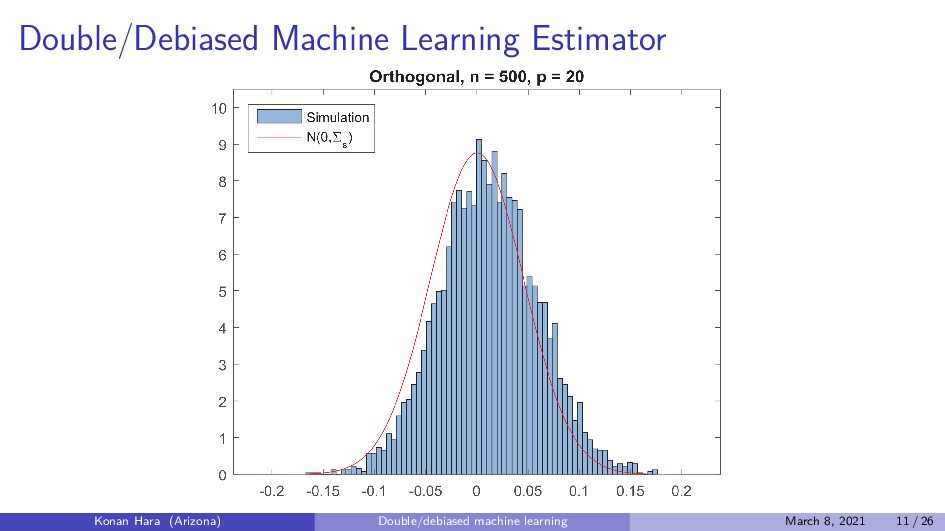
Dθ0 + g0 (X) + U, E[U|X, D] = 0 D = m0 (X) + V, E[V |X] = 0 . Apply ML to predict D/Y by X, and collect the residual ⇒ ˆ V / ˆ W DML estimator: ˆ θ0 = 1 n n i=1 ˆ V 2 i −1 1 n n i=1 ˆ Vi ˆ Wi . Konan Hara (Arizona) Double/debiased machine learning March 8, 2021 18 / 26
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}