Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
DNNベース音声分離の実施報告
Search
takeshun
December 23, 2022
Programming
1.3k
0
Share
DNNベース音声分離の実施報告
2022年9月にDLHacksで発表した資料です。
音声分離ツールキットの紹介と話者分離の実験を行いました。
takeshun
December 23, 2022
More Decks by takeshun
See All by takeshun
ESPnet2のTTS実施報告
takeshun256
0
1.7k
Other Decks in Programming
See All in Programming
Sans tests, vos agents ne sont pas fiables
nabondance
0
140
開発体験を左右するライブラリの API 設計 - GraphQL スキーマ構築ライブラリから考える #tskaigi
izumin5210
1
190
ソースコード→AST→オペコード、の旅を覗いてみる
o0h
PRO
1
140
SkillsをS3 Filesに置く時のあれこれ
watany
3
1.6k
Back to the roots of date
jinroq
0
880
リセットCSSを1行消したらアクセシビリティが向上した話
pvcresin
4
520
2026年のソフトウェア開発を考える(2026/05版) / Software Engineering Scrum Fest Niigata 2026 Edition
twada
PRO
23
13k
サーバーレスで作る、動画データ管理基盤
oyasumipants
0
220
Skillは並べた。動かなかった。契約で繋いだ。— 65個のSkillから、自走する開発サイクルへ
junholee
0
640
Import assertionsが消えた日~ECMAScriptの仕様はどう決まり、なぜ覆るのか~
bicstone
2
190
20260514 - build with ai 2026 - build LINE Bot with Gemini CLI
line_developers_tw
PRO
0
450
KMP × Kotlin 2.3 - How Android Got Slower While iOS Builds Improved by 47%
rio432
0
200
Featured
See All Featured
Color Theory Basics | Prateek | Gurzu
gurzu
0
310
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
22k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
65
54k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.2k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
360
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.7k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
300
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
4 Signs Your Business is Dying
shpigford
187
22k
Transcript
DNNベース音声分離の実施報告 ~音声分離の手法、評価方法やツールキットの調査~ 東京理科大学3年 竹下隼司 1
目次 1. 音声分離とは 2. DNNベースの音声分離アルゴリズム 3. 評価指標 4. データセット 5.
音声分離ツールキット 6. 話者分離の実験 7. 結果と考察 8. 今後の課題 9. 参考文献・クレジット 2
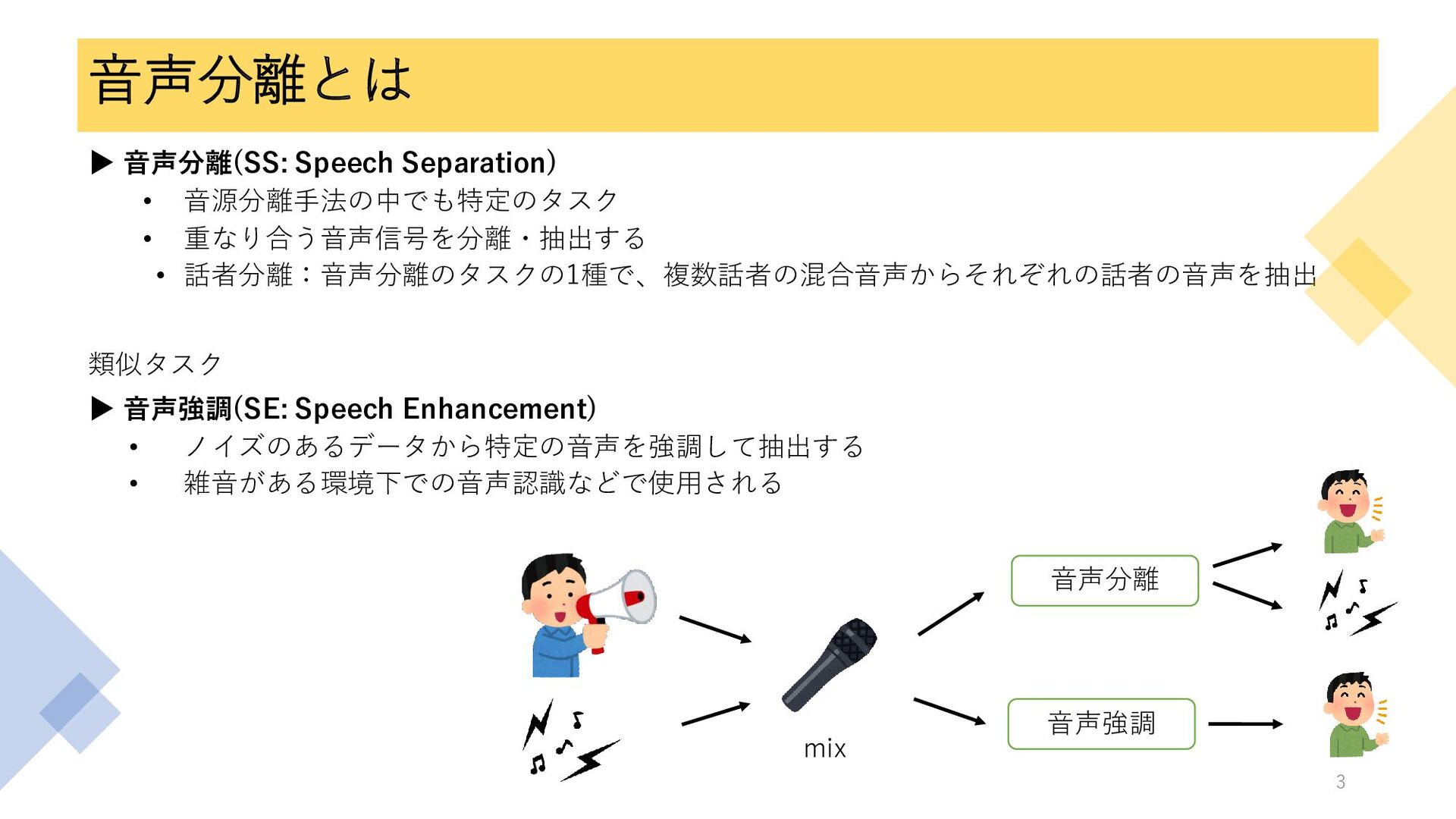
音声分離とは ▶ 音声分離(SS: Speech Separation) • 音源分離手法の中でも特定のタスク • 重なり合う音声信号を分離・抽出する •
話者分離:音声分離のタスクの1種で、複数話者の混合音声からそれぞれの話者の音声を抽出 類似タスク ▶ 音声強調(SE: Speech Enhancement) • ノイズのあるデータから特定の音声を強調して抽出する • 雑音がある環境下での音声認識などで使用される 3 音声分離 音声強調 mix
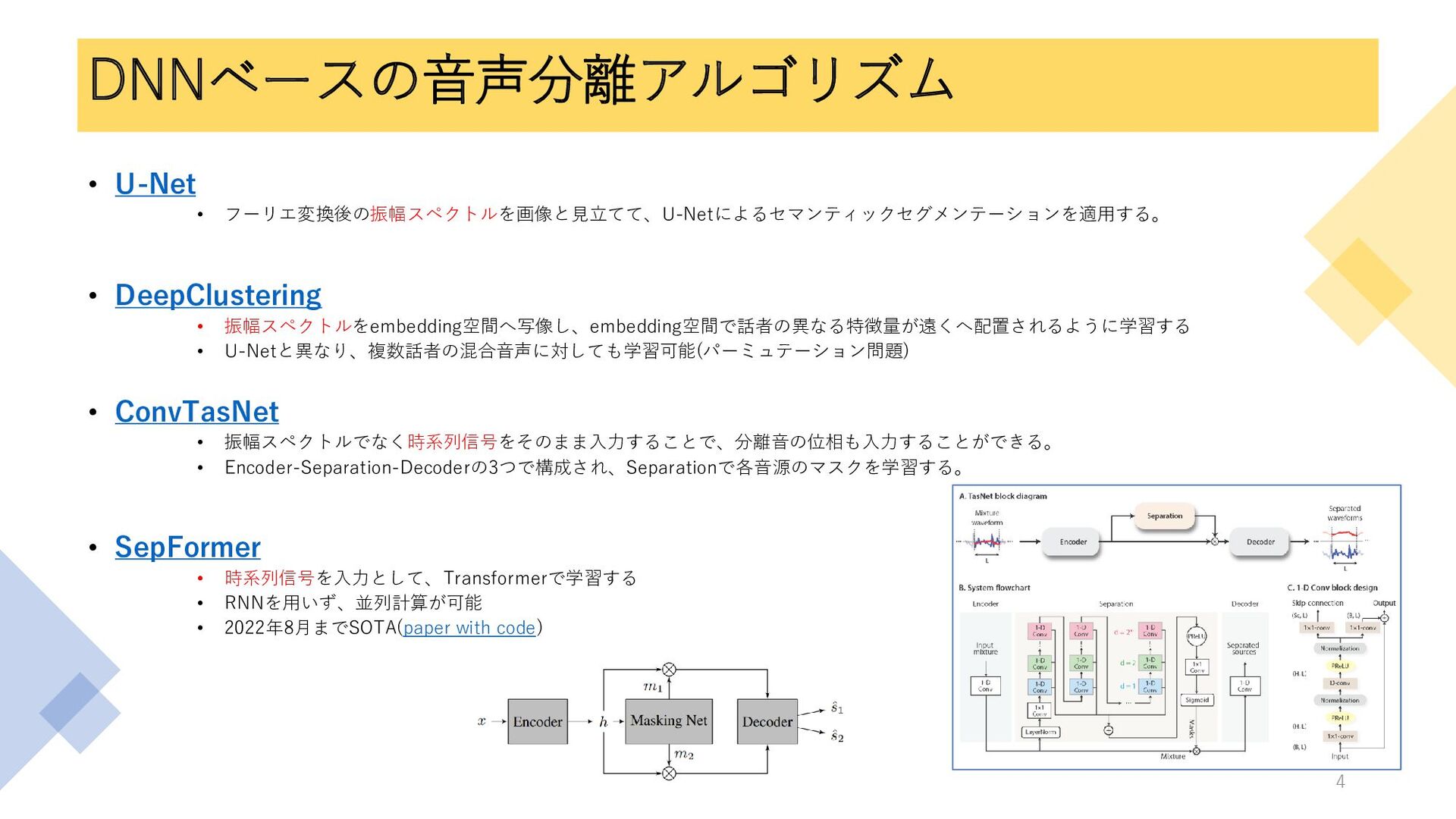
DNNベースの音声分離アルゴリズム • U-Net • フーリエ変換後の振幅スペクトルを画像と見立てて、U-Netによるセマンティックセグメンテーションを適用する。 • DeepClustering • 振幅スペクトルをembedding空間へ写像し、embedding空間で話者の異なる特徴量が遠くへ配置されるように学習する •
U-Netと異なり、複数話者の混合音声に対しても学習可能(パーミュテーション問題) • ConvTasNet • 振幅スペクトルでなく時系列信号をそのまま入力することで、分離音の位相も入力することができる。 • Encoder-Separation-Decoderの3つで構成され、Separationで各音源のマスクを学習する。 • SepFormer • 時系列信号を入力として、Transformerで学習する • RNNを用いず、並列計算が可能 • 2022年8月までSOTA(paper with code) 4
音声分離の評価指標 ▶ 目的の音声をどれだけうまく分離できたかを測る指標(音源分離や音声強調も同様) • 混合音声がいくつかの特徴のある音声に分離されたとする。 • Img=真の音源/目的音源、spat=ノイズ、interf=目的音源以外の干渉音声、artif=人工的な音 ▶ SI-SDR •
音声分離のベンチ―マークで使用される指標(SI-SDRi)の前進 • スケール不変のSDR(音声対全歪み比) • 音声のスケール(dB)によって値が変化しない • その他の評価指標 • SNR(音声対推論音声との差の歪み比) • SIR(音声対目的音声以外の干渉音声による歪み比) • SAR(音声対非線形(人工的な音声)歪み比) • ISR(音声対雑音比) ▶ その他:PESQ(音質の客観知覚評価)、音声認識(ASR)による評価 5 参照:https://arxiv.org/abs/1811.02508
URL 音声分離用のデータセット ▶ 音声分離(SS)や音声強調(SE)で使用されるデータセット • WSJ0-Mix • WSJ0というウォールストリートジャーナルの記事の朗読音声 • もともと音声認識(ASR)用だったものを、音声分離用のデータセットとして作り直したもの
• WSJ0コーパスが有料 • 音声分離のベンチマークで使用される • 英語、Wav形式、16kHz、40h程度 • WSJ0 Hipster Ambient Mixtures (WHAM!) • WSJ0-Mixデータセットにノイズを付加したもの • 英語、Wav形式 • LibriMix • オープンソースデータセット • MIT license • LibriSpeechのクリーンデータセットとWHAMのノイズを混合させたもの • 混合物の種類 : mix_clean (発話のみ) mix_both (混合発話 + ノイズ) mix_single (1 発話 + ノイズ) • 英語、Wav形式 6 時間
、ReproducibilityModularity 音声分離ツールキット ▶ 色々なオープンソースツールキット • Asteroid • Pytorchベースの音源分離ツールキット • MIT
License • 広範なデータセットとアーキテクチャをサポートしている • モジュール性(Modularity)、拡張性(Extensibility)、再現性(Reproducibility) • ESPnet • End-to-End(E2E)音声処理のためのオープンソースツールキット • Apache License 2.0 • タスク定義(TaskDesign)、Chainer-Free、Kaldi-Free、大規模データセットで学習可能(Scalable)、臨機応変(On-the-Fly) • SS、SE以外にも様々な音声処理タスクのレシピがある。(ASR(音声認識), 音声合成(TTS), 音声翻訳(ST), 機械翻訳(MT), 音声変換(VC)など) • SpeechBrain • Pytorchベースの音声処理ツールキット • Apache License 2.0 • 柔軟なマルチタスクで単一のツールキットにを持つことで、音声技術開発の効率化を図る • 容易(Easy to use)、カスタマイズ性(Easy to customize)、柔軟性(Flexible)、モジュール(Modular)、充実したドキュメント(Well-documented) 7 参照: 1. https://github.com/asteroid-team/asteroid/blob/master/docs/source/_static/images/asteroid_logo_dark.png 2. https://github.com/espnet/espnet/blob/master/doc/image/espnet_logo1.png 3. https://github.com/speechbrain/speechbrain/blob/develop/docs/images/speechbrain-logo.svg
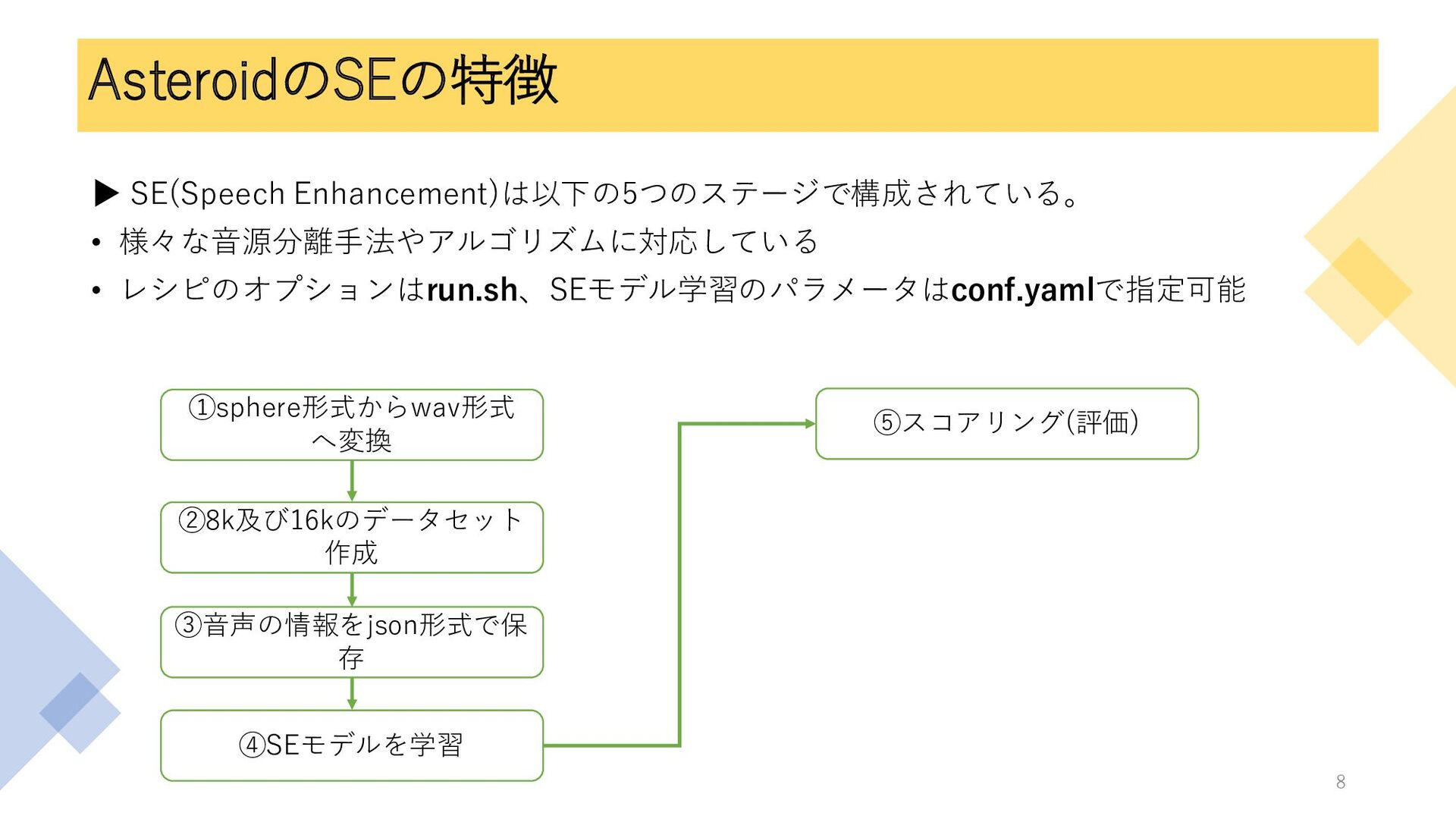
AsteroidのSEの特徴 ▶ SE(Speech Enhancement)は以下の5つのステージで構成されている。 • 様々な音源分離手法やアルゴリズムに対応している • レシピのオプションはrun.sh、SEモデル学習のパラメータはconf.yamlで指定可能 ①sphere形式からwav形式 へ変換
②8k及び16kのデータセット 作成 ③音声の情報をjson形式で保 存 ④SEモデルを学習 ⑤スコアリング(評価) 8
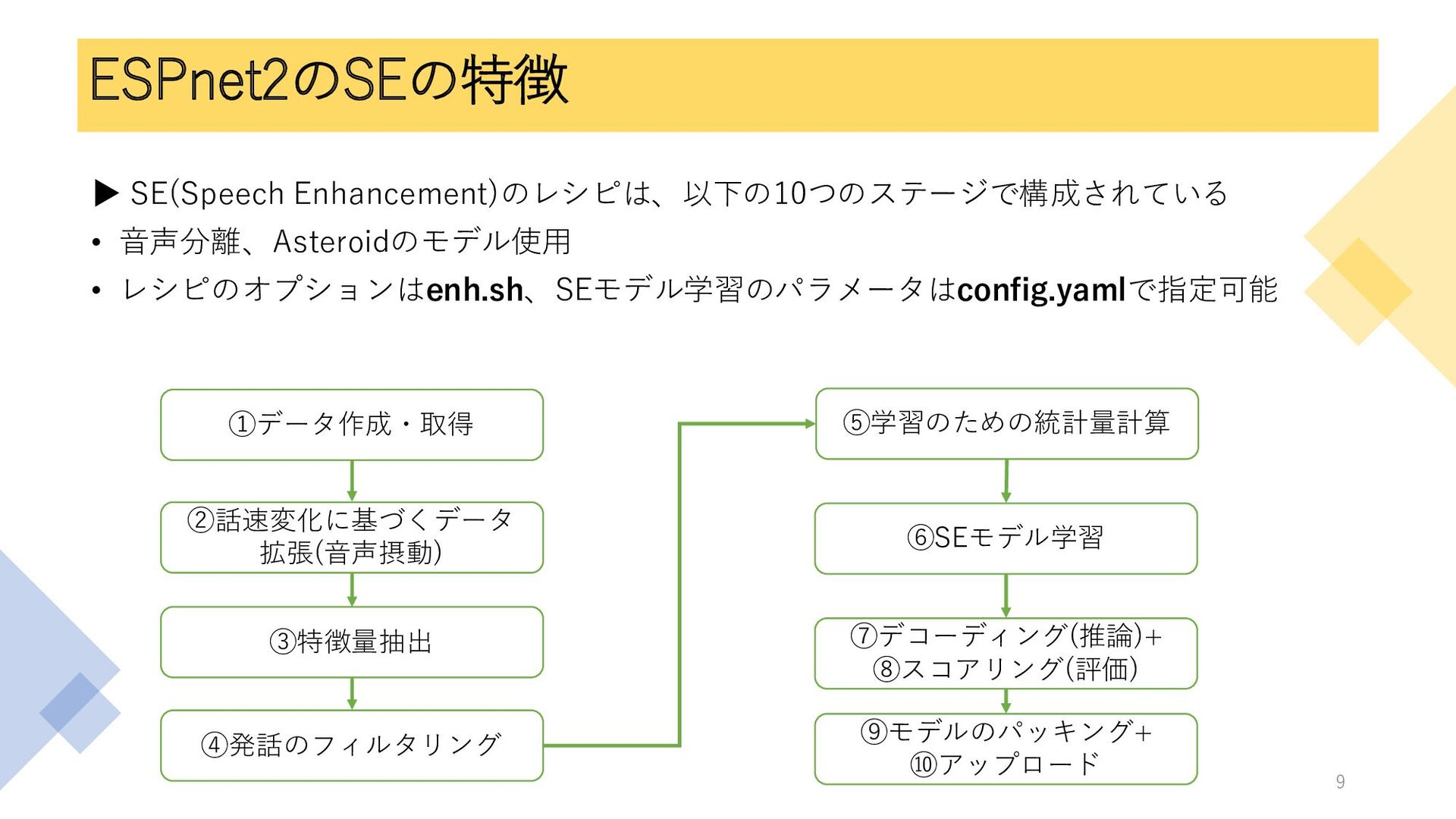
ESPnet2のSEの特徴 ▶ SE(Speech Enhancement)のレシピは、以下の10つのステージで構成されている • 音声分離、Asteroidのモデル使用 • レシピのオプションはenh.sh、SEモデル学習のパラメータはconfig.yamlで指定可能 ①データ作成・取得 ②話速変化に基づくデータ
拡張(音声摂動) ③特徴量抽出 ④発話のフィルタリング ⑤学習のための統計量計算 ⑥SEモデル学習 ⑦デコーディング(推論)+ ⑧スコアリング(評価) ⑨モデルのパッキング+ ⑩アップロード 9
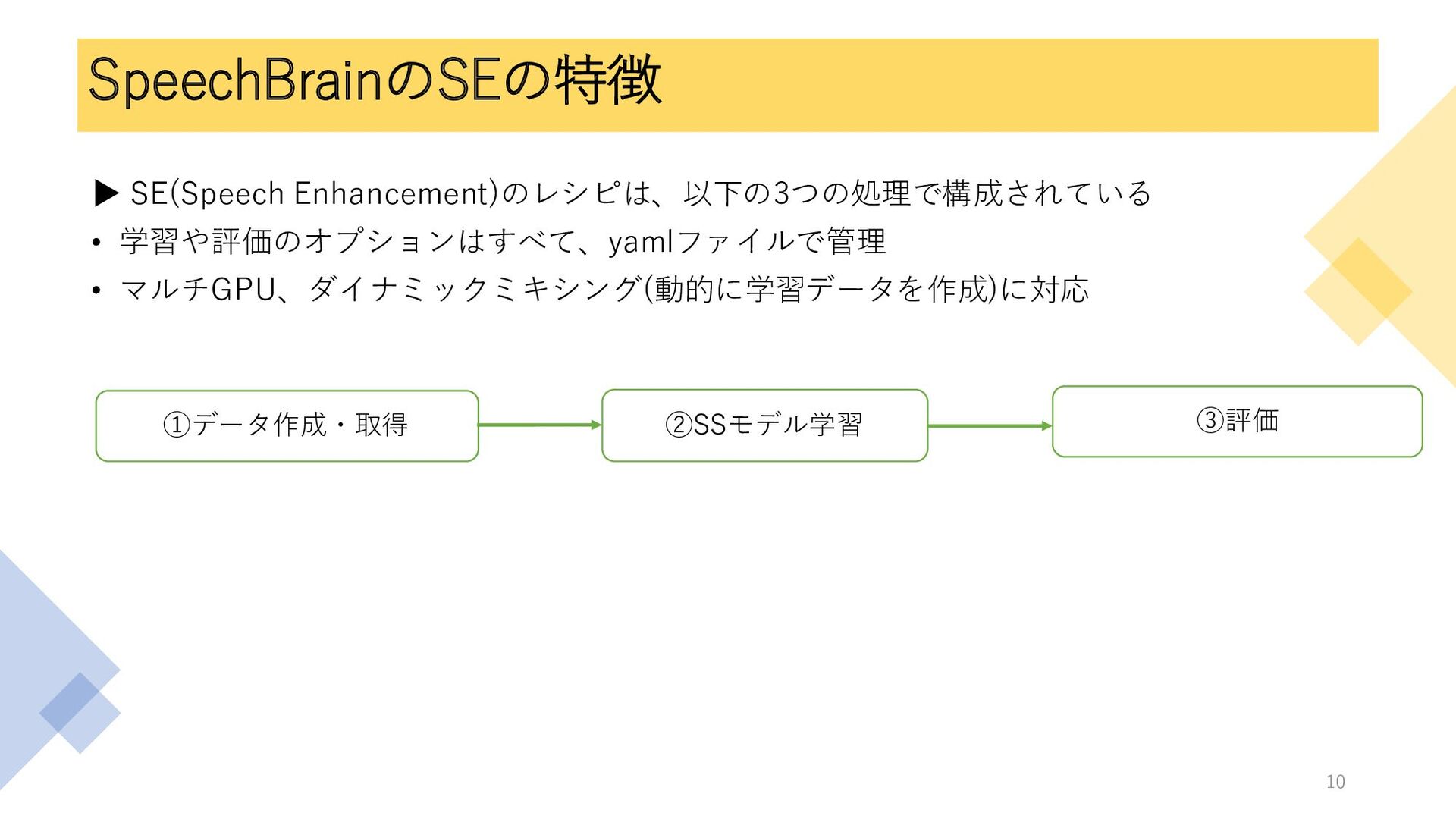
SpeechBrainのSEの特徴 ▶ SE(Speech Enhancement)のレシピは、以下の3つの処理で構成されている • 学習や評価のオプションはすべて、yamlファイルで管理 • マルチGPU、ダイナミックミキシング(動的に学習データを作成)に対応 ①データ作成・取得 ②SSモデル学習
③評価 10
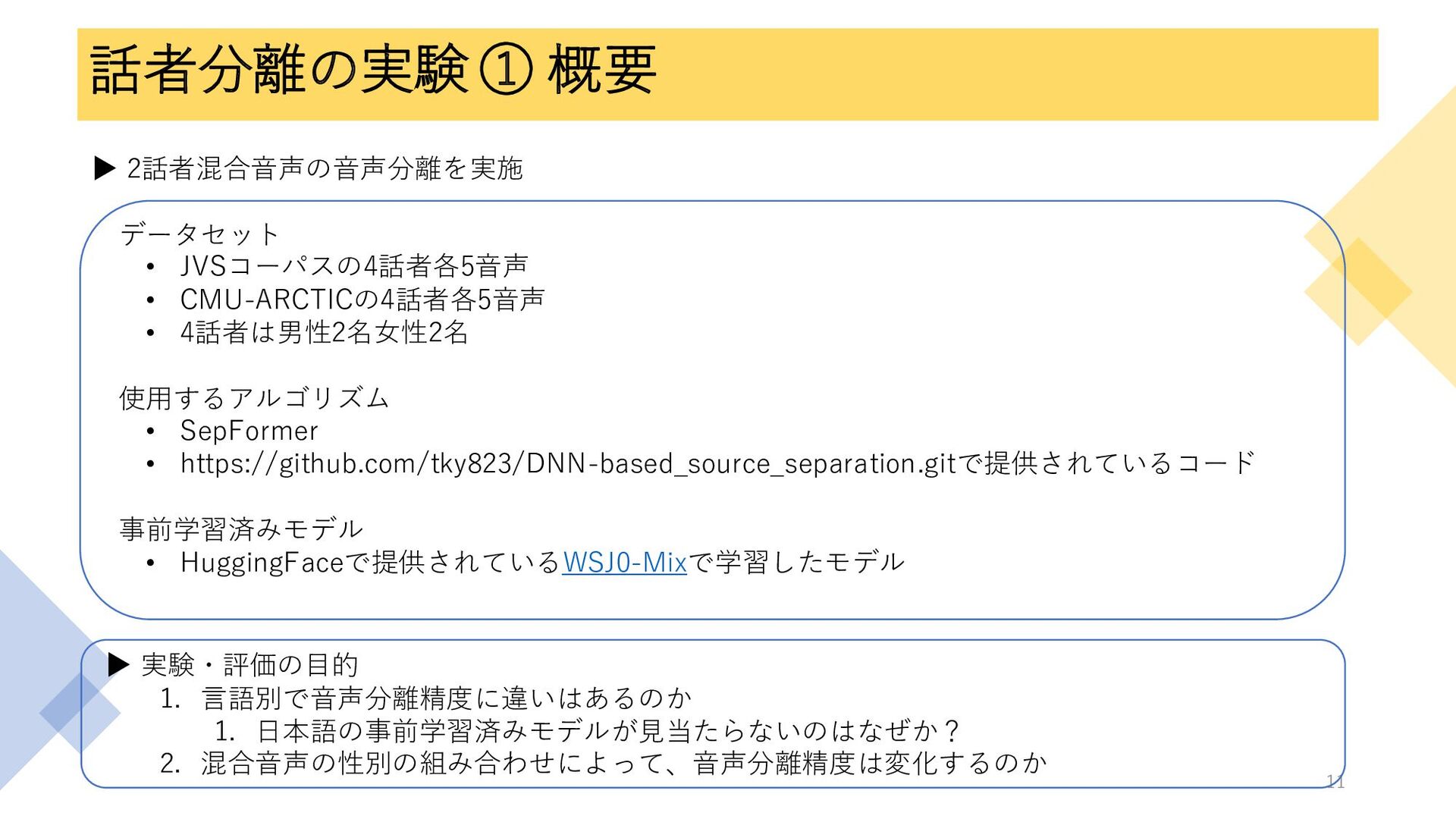
話者分離の実験 ① 概要 ▶ 2話者混合音声の音声分離を実施 データセット • JVSコーパスの4話者各5音声 • CMU-ARCTICの4話者各5音声
• 4話者は男性2名女性2名 使用するアルゴリズム • SepFormer • https://github.com/tky823/DNN-based_source_separation.gitで提供されているコード 事前学習済みモデル • HuggingFaceで提供されているWSJ0-Mixで学習したモデル 11 ▶ 実験・評価の目的 1. 言語別で音声分離精度に違いはあるのか 1. 日本語の事前学習済みモデルが見当たらないのはなぜか? 2. 混合音声の性別の組み合わせによって、音声分離精度は変化するのか
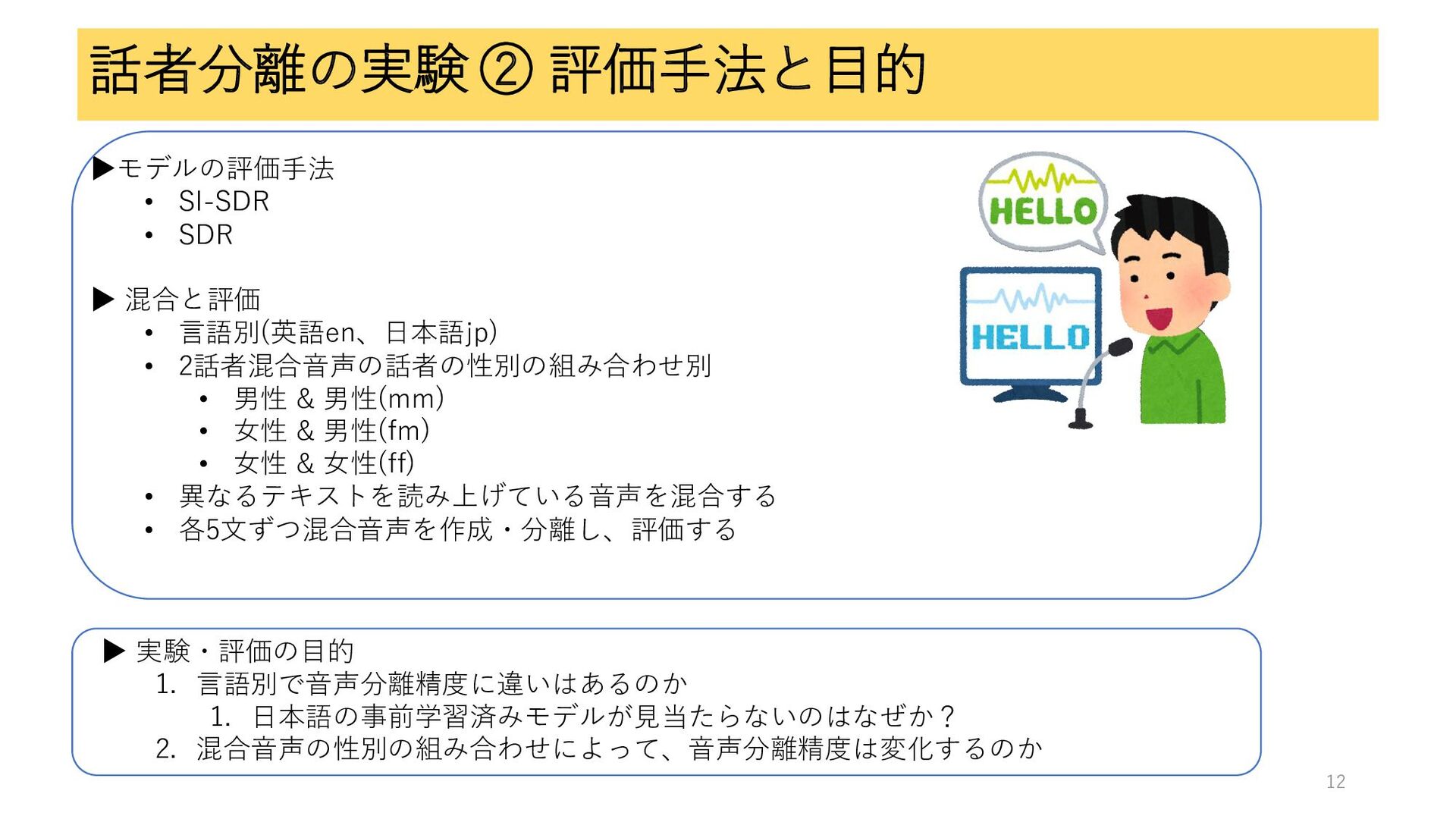
話者分離の実験 ② 評価手法と目的 ▶モデルの評価手法 • SI-SDR • SDR ▶ 混合と評価
• 言語別(英語en、日本語jp) • 2話者混合音声の話者の性別の組み合わせ別 • 男性 & 男性(mm) • 女性 & 男性(fm) • 女性 & 女性(ff) • 異なるテキストを読み上げている音声を混合する • 各5文ずつ混合音声を作成・分離し、評価する 12 ▶ 実験・評価の目的 1. 言語別で音声分離精度に違いはあるのか 1. 日本語の事前学習済みモデルが見当たらないのはなぜか? 2. 混合音声の性別の組み合わせによって、音声分離精度は変化するのか
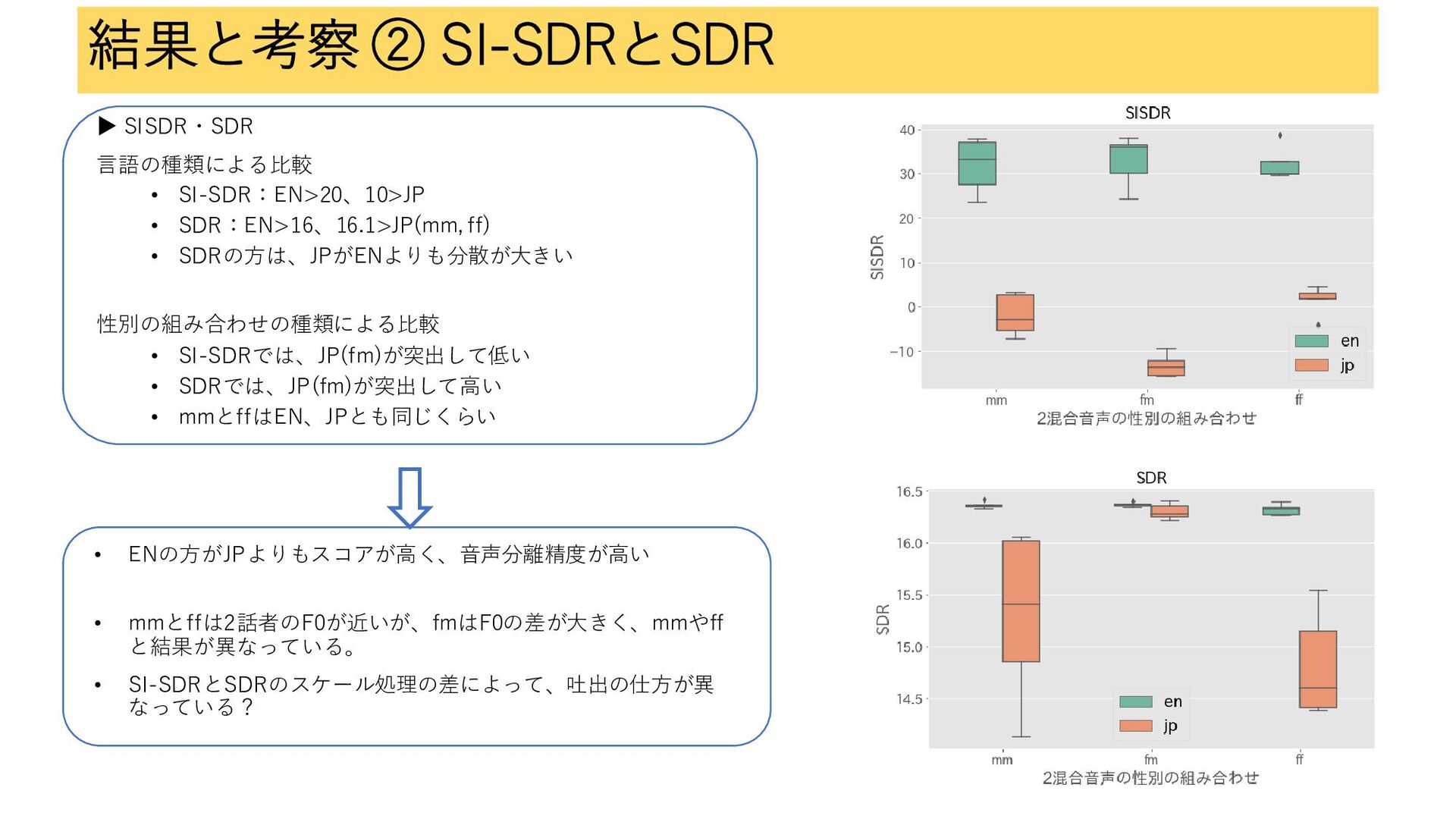
結果と考察 ② SI-SDRとSDR ▶ SISDR・SDR 言語の種類による比較 • SI-SDR:EN>20、10>JP • SDR:EN>16、16.1>JP(mm,
ff) • SDRの方は、JPがENよりも分散が大きい 性別の組み合わせの種類による比較 • SI-SDRでは、JP(fm)が突出して低い • SDRでは、JP(fm)が突出して高い • mmとffはEN、JPとも同じくらい 13 • ENの方がJPよりもスコアが高く、音声分離精度が高い • mmとffは2話者のF0が近いが、fmはF0の差が大きく、mmやff と結果が異なっている。 • SI-SDRとSDRのスケール処理の差によって、吐出の仕方が異 なっている?
考察と今後の課題 ▶ 考察 • 音声分離精度がEN>JP • 学習データの言語によって、精度に違い生まれているので、日本語の音声分離をするときは、日本語のデータセットで学習したモデル を使用したほうが良い可能性がある。 • 日本語の音声事前学習済みモデルがない
• 日本語には、LibriMixやWSJ0-Mixといった大規模な多話者のデータセットが少ない(JVSコーパスくらい) • ベンチマークとして使用されているWSJ0-Mixやフリーに使用できるLibriMixの方が使用される • 男性&男性や女性&女性の分離精度と男性&女性の分離精度が異なる • 性別によるF0周波数の違いが、分離のしやすさに影響している。 • 男性&女性の混合音声の分離時の突出の仕方がSISDRとSDRとでは異なる • 評価指標ごとに計算式が異なり、SI-SDRはスケール不変のSDRであるため、男性&女性でスケール(dB)の違いがスコアに影響した可能 性がある。 14 ▶ 今後の課題と展望 1. 評価指標の仕組み(計算式や利用目的)を調査 2. ノイズ音声を付加したデータセットの使用 3. 日本語データセットを用いた音声分離モデルの学習
参考文献・クレジット ▶ paper with code speech-separation https://paperswithcode.com/task/speech-separation ▶ paper with
code speech-enhancement https://paperswithcode.com/task/speech-enhancement ▶ 【サーベイ】深層学習を用いた音源分離手法のまとめ https://ys0510.hatenablog.com/entry/single_separation_survey ▶ Speech Enhancement Frontend Recipe https://github.com/espnet/espnet/tree/master/egs2/TEMPLATE/enh1 ▶ Speech Brain ドキュメント https://www.arxiv-vanity.com/papers/2106.04624/ ▶ First stereo audio source separation evaluation campaign: data, algorithms and results https://hal.inria.fr/inria-00544199/document ▶ SDR – HALF-BAKED OR WELL DONE? https://arxiv.org/abs/1811.02508 ▶ Compute and memory efficient universal sound source separation https://paperswithcode.com/paper/compute-and-memory-efficient-universal-sound 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}