Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ESPnet2のTTS実施報告
Search
takeshun
June 21, 2022
Programming
1.7k
0
Share
ESPnet2のTTS実施報告
DLHacksにて、6月20日に発表した資料です。
takeshun
June 21, 2022
More Decks by takeshun
See All by takeshun
DNNベース音声分離の実施報告
takeshun256
0
1.3k
Other Decks in Programming
See All in Programming
AI時代になぜ書くのか
mutsumix
0
430
20260514 - build with ai 2026 - build LINE Bot with Gemini CLI
line_developers_tw
PRO
0
450
横断組織出身のQAEがインプロセスQAEでつまずいたこと・活かせたこと
ty89
0
150
cloudnative conference 2026 flyle
azihsoyn
1
190
開発体験を左右するライブラリの API 設計 - GraphQL スキーマ構築ライブラリから考える #tskaigi
izumin5210
1
190
実践ハーネスエンジニアリング:ステアリングループを実例から読み解く / Practical Harness Engineering: Understanding Steering Loops Through Real-World Examples
nrslib
5
5.6k
ソースコード→AST→オペコード、の旅を覗いてみる
o0h
PRO
1
140
(Re)make Regexp in Ruby: Democratizing internals for the JIT
makenowjust
3
1.1k
ふにゃっとしない名前の付け方 〜哲学で茹で上げる、コシのあるソフトウェア設計〜
shimomura
0
120
「OSSがあるなら自作するな」は AI時代も正しいか ── Build vs Adopt の新しい判断基準
kumorn5s
7
2.8k
[BalkanRuby 2026] Drop your app/services!
palkan
3
550
書き換えて学ぶTemporal #fukts
pirosikick
2
380
Featured
See All Featured
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
690
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.1k
Discover your Explorer Soul
emna__ayadi
2
1.1k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3k
Abbi's Birthday
coloredviolet
2
7.6k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
350
Building Adaptive Systems
keathley
44
3k
Exploring anti-patterns in Rails
aemeredith
3
360
Agile that works and the tools we love
rasmusluckow
331
21k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
170
Site-Speed That Sticks
csswizardry
13
1.2k
Claude Code のすすめ
schroneko
67
220k
Transcript
ESPnet2のTTS実施報告 ~ESPnet2を用いたTTSモデル学習と評価~ 東京理科大学3年 竹下隼司 1
目次 1. ESPnet2とは 2. ESPnet2のTTSの特徴 3. 実験 4. 結果と考察 5.
今後の課題 6. 参考文献・クレジット 2
ESPnet2とは ▶ End-to-End(E2E)音声処理のためのオープンソースツールキット ▶ ESPnet2 • ESPnetの弱点を克服する為に開発され、利便性と拡張性を向上させたツール • Task-Design:ユーザーが任意の新しいタスクを定義可能 •
Chainer-Free, Kaldi-Free:ChainerやKaldiに依存せず、利用が容易に • Scalable:大規模データセットで学習可能 • On-the-Fly:テキスト前処理や特徴量抽出がモデルやレシピに統合され、音声データを直接 入力するだけで、学習可能 • E2E型モデル(Pythonライブラリ部)とレシピ(シェルスクリプト部)で構成される • 音声処理タスクは、主にASR(音声認識), 音声合成(TTS), 音声翻訳(ST), 機械翻訳(MT), 音声変換 (VC)など • ライセンス:Apache 2.0 • 論文引用数:781件 (2022/6/20現在) 参照:https://github.com/espnet/espnet/blob/master/doc/image/espnet_logo1.png 3
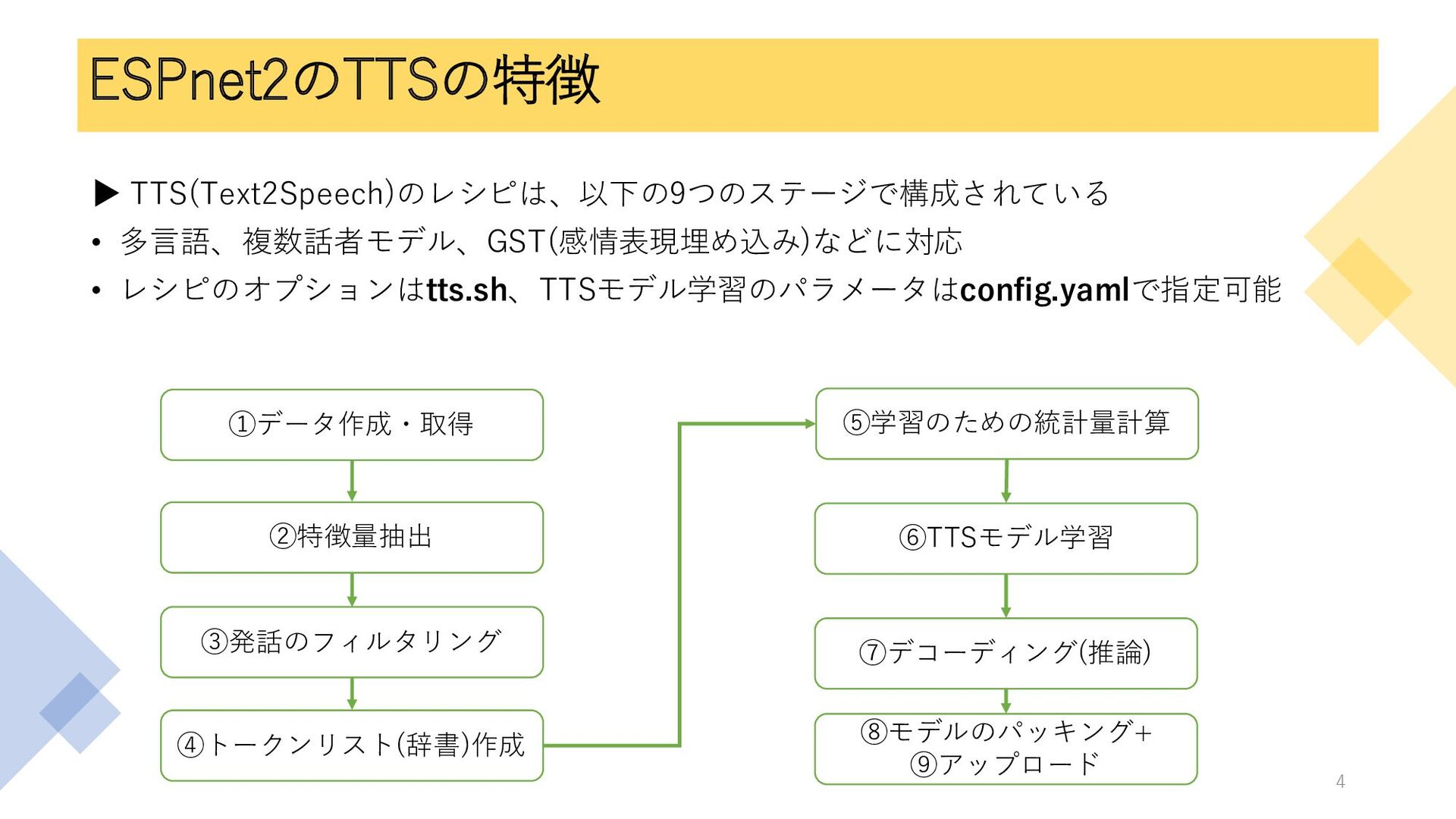
ESPnet2のTTSの特徴 ▶ TTS(Text2Speech)のレシピは、以下の9つのステージで構成されている • 多言語、複数話者モデル、GST(感情表現埋め込み)などに対応 • レシピのオプションはtts.sh、TTSモデル学習のパラメータはconfig.yamlで指定可能 ①データ作成・取得 ②特徴量抽出 ③発話のフィルタリング
④トークンリスト(辞書)作成 ⑤学習のための統計量計算 ⑥TTSモデル学習 ⑦デコーディング(推論) ⑧モデルのパッキング+ ⑨アップロード 4
ESPnet2のTTSの特徴 ①アーキテクチャの紹介 ▶ 非End-to-EndのTTSモデル(Text2Mel) • Tacotron2 • 注意機構を含むEncoder-Decoderモデル • LSTMによる自己回帰
• FastSpeech2 • Transformerを用いた非自己回帰モデル • 音声の分散情報として、Pitch・Energy・Durationを導入する • 並列処理による高速な推論 • ESPnet2では、Tacotron2によるDuration情報を取得する • Conformer FastSpeech2 • TransformerとCNNを組み合わせたConformerをFastSpeech2に導入する • コンテキストのグローバル情報とローカル情報の両方をより学習する • ESPnet2では、Tacotron2によるDuration情報を取得する ▶ Neural Vocoder(Mel2Speech) • ParallelWaveGAN • Parallel(並列)+WaveNet(自己回帰型)+GAN • WaveNetと同等以上の品質+並列処理による高速処理 自己回帰型 Attention 非自己回帰 Transformer Pitch, Energy, Duration Pitch, Energy, Duration 非自己回帰 Conformer メルスペク トログラム 5
ESPnet2のTTSの特徴 ②アーキテクチャの紹介 ▶ End-to-End(E2E)モデル(Text2Speech) • VITS • E2E-TTS • 敵対的学習の中で正規化フローと変分推論を利用して、生成モデルの表現力を向上
• 確率的継続長予測器によって、多様なリズムの音声を生成 • JETS • アライメントモジュールを組み込んだFastSpeech2とHiFi-GANのE2E-TTS • ファインチューニングと外部のアライメントツールを必要としない 6
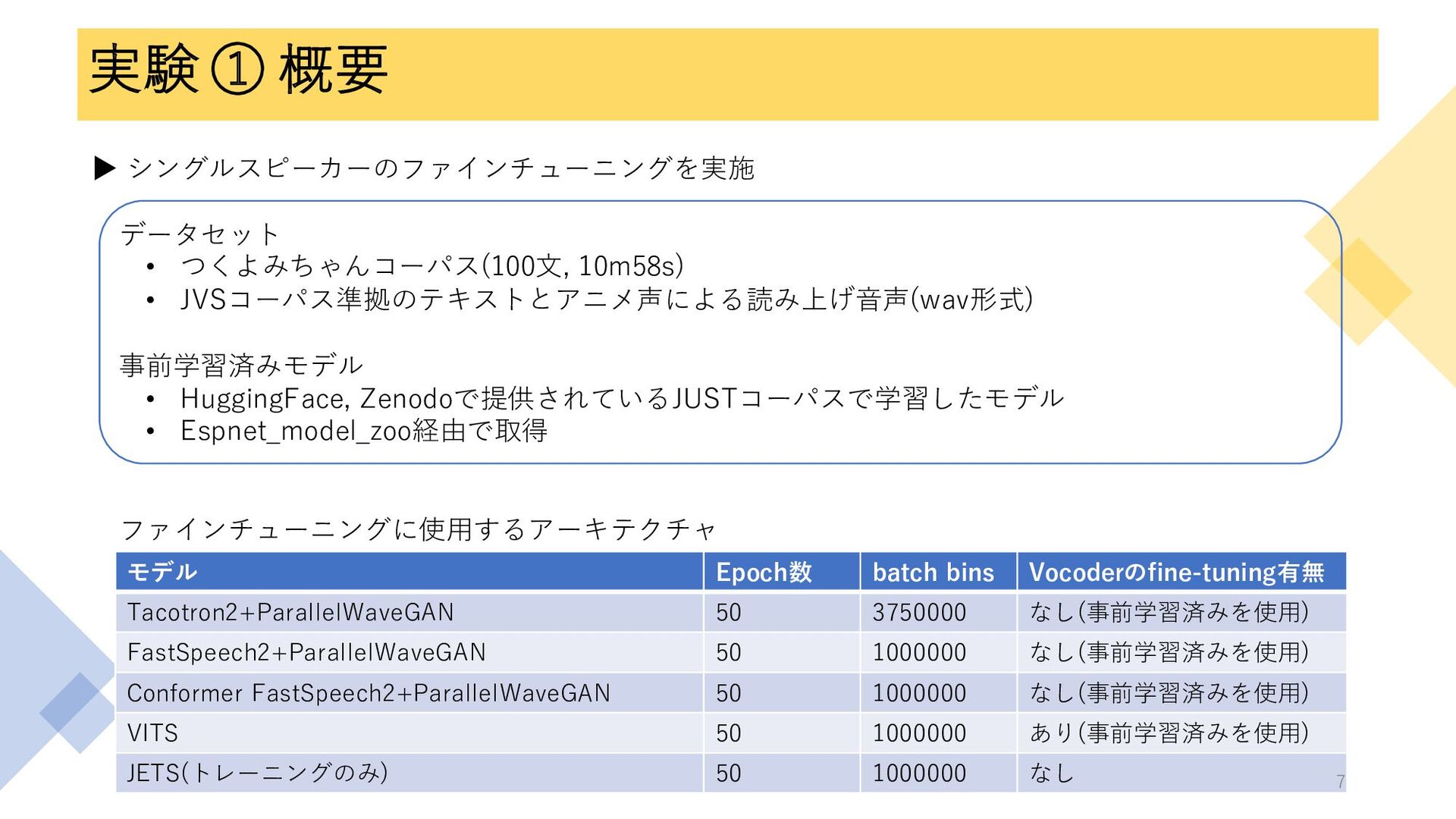
実験 ① 概要 ▶ シングルスピーカーのファインチューニングを実施 データセット • つくよみちゃんコーパス(100文, 10m58s) •
JVSコーパス準拠のテキストとアニメ声による読み上げ音声(wav形式) 事前学習済みモデル • HuggingFace, Zenodoで提供されているJUSTコーパスで学習したモデル • Espnet_model_zoo経由で取得 ファインチューニングに使用するアーキテクチャ モデル Epoch数 batch bins Vocoderのfine-tuning有無 Tacotron2+ParallelWaveGAN 50 3750000 なし(事前学習済みを使用) FastSpeech2+ParallelWaveGAN 50 1000000 なし(事前学習済みを使用) Conformer FastSpeech2+ParallelWaveGAN 50 1000000 なし(事前学習済みを使用) VITS 50 1000000 あり(事前学習済みを使用) JETS(トレーニングのみ) 50 1000000 なし 7
実験 ② 評価手法と推論方法 ▶モデルの評価手法 • MCD(Mel Cepstrum Distortion):MCEPのユークリッド距離から計算 • Log
F0 RMSE:対数をとったF0配列のRMSE • RTF:単位時間の音声を推論するのにかかる時間 RTF = (推論時間)/(音声時間) ▶ 推論 • 学習に使用した文章5文(Train)と学習に使用していない文章5文(Test) • 各文20回ずつ推論し、評価する 8
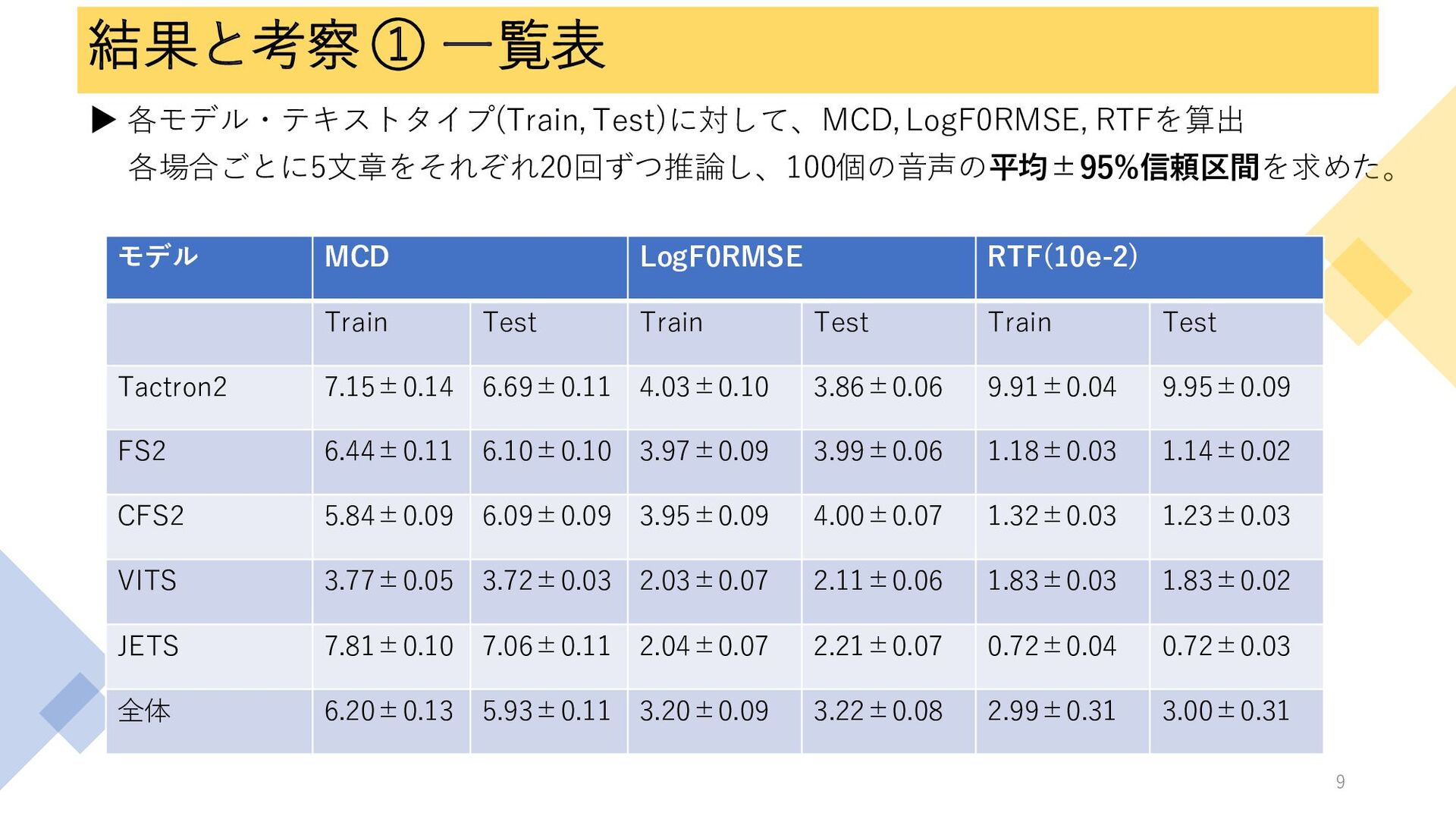
結果と考察 ① 一覧表 ▶ 各モデル・テキストタイプ(Train, Test)に対して、MCD,LogF0RMSE, RTFを算出 各場合ごとに5文章をそれぞれ20回ずつ推論し、100個の音声の平均±95%信頼区間を求めた。 モデル MCD
LogF0RMSE RTF(10e-2) Train Test Train Test Train Test Tactron2 7.15±0.14 6.69±0.11 4.03±0.10 3.86±0.06 9.91±0.04 9.95±0.09 FS2 6.44±0.11 6.10±0.10 3.97±0.09 3.99±0.06 1.18±0.03 1.14±0.02 CFS2 5.84±0.09 6.09±0.09 3.95±0.09 4.00±0.07 1.32±0.03 1.23±0.03 VITS 3.77±0.05 3.72±0.03 2.03±0.07 2.11±0.06 1.83±0.03 1.83±0.02 JETS 7.81±0.10 7.06±0.11 2.04±0.07 2.21±0.07 0.72±0.04 0.72±0.03 全体 6.20±0.13 5.93±0.11 3.20±0.09 3.22±0.08 2.99±0.31 3.00±0.31 9
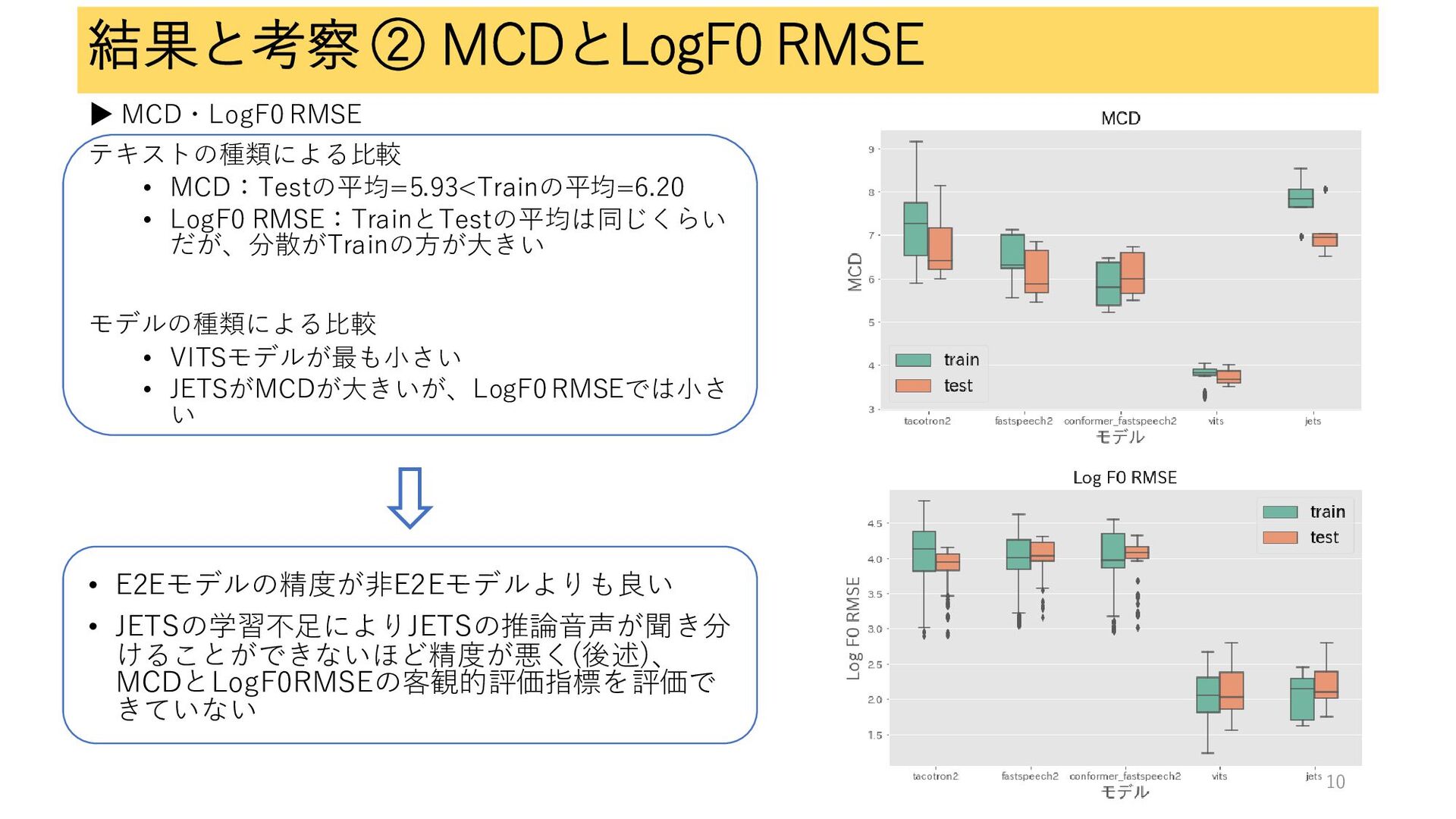
結果と考察 ② MCDとLogF0 RMSE ▶ MCD・LogF0 RMSE テキストの種類による比較 • MCD:Testの平均=5.93<Trainの平均=6.20
• LogF0 RMSE:TrainとTestの平均は同じくらい だが、分散がTrainの方が大きい モデルの種類による比較 • VITSモデルが最も小さい • JETSがMCDが大きいが、LogF0 RMSEでは小さ い • E2Eモデルの精度が非E2Eモデルよりも良い • JETSの学習不足によりJETSの推論音声が聞き分 けることができないほど精度が悪く(後述)、 MCDとLogF0RMSEの客観的評価指標を評価で きていない 10
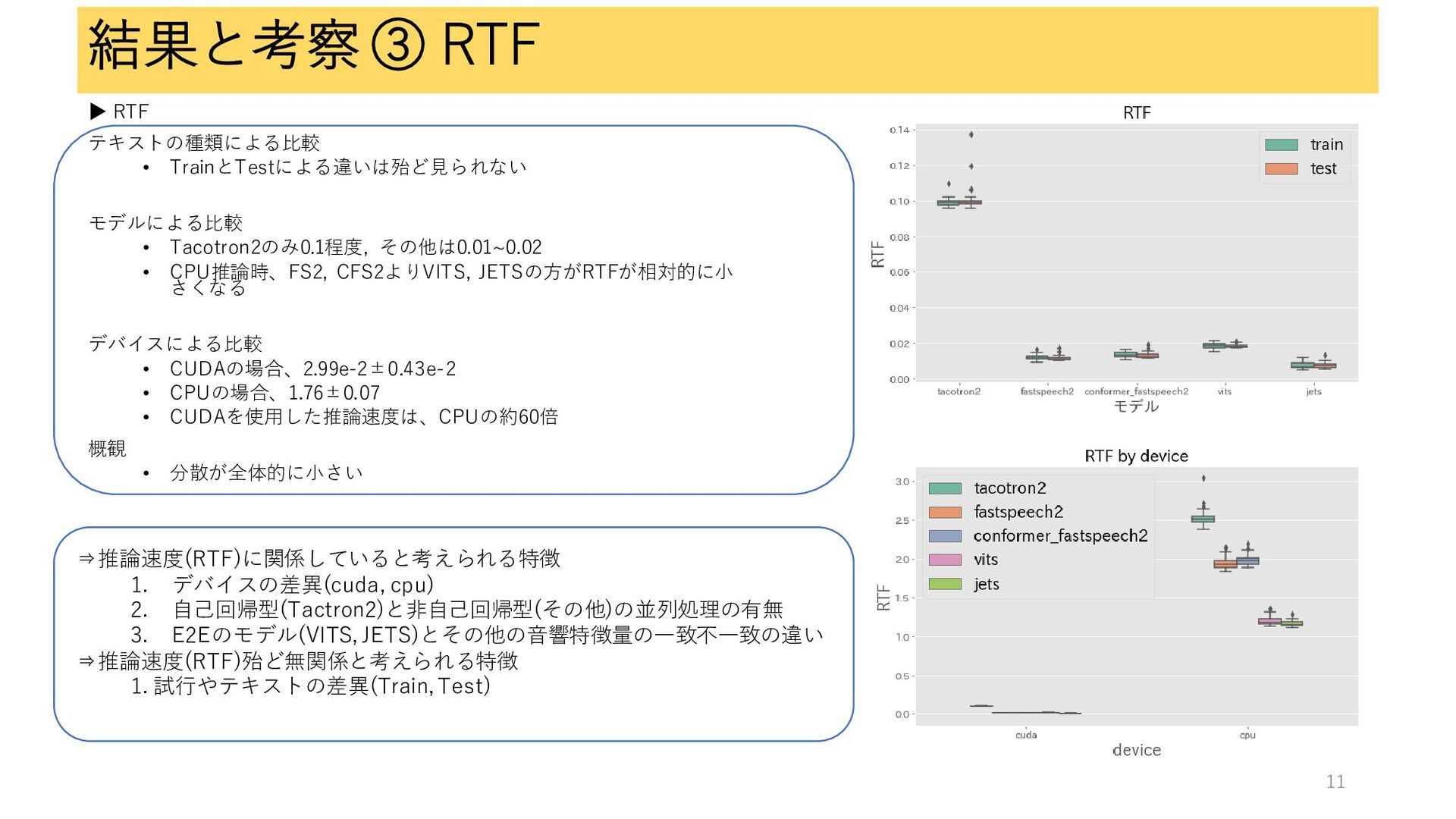
結果と考察 ③ RTF ▶ RTF テキストの種類による比較 • TrainとTestによる違いは殆ど見られない モデルによる比較 •
Tacotron2のみ0.1程度, その他は0.01~0.02 • CPU推論時、FS2, CFS2よりVITS, JETSの方がRTFが相対的に小 さくなる デバイスによる比較 • CUDAの場合、2.99e-2±0.43e-2 • CPUの場合、1.76±0.07 • CUDAを使用した推論速度は、CPUの約60倍 概観 • 分散が全体的に小さい ⇒推論速度(RTF)に関係していると考えられる特徴 1. デバイスの差異(cuda, cpu) 2. 自己回帰型(Tactron2)と非自己回帰型(その他)の並列処理の有無 3. E2Eのモデル(VITS, JETS)とその他の音響特徴量の一致不一致の違い ⇒推論速度(RTF)殆ど無関係と考えられる特徴 1. 試行やテキストの差異(Train, Test) 11
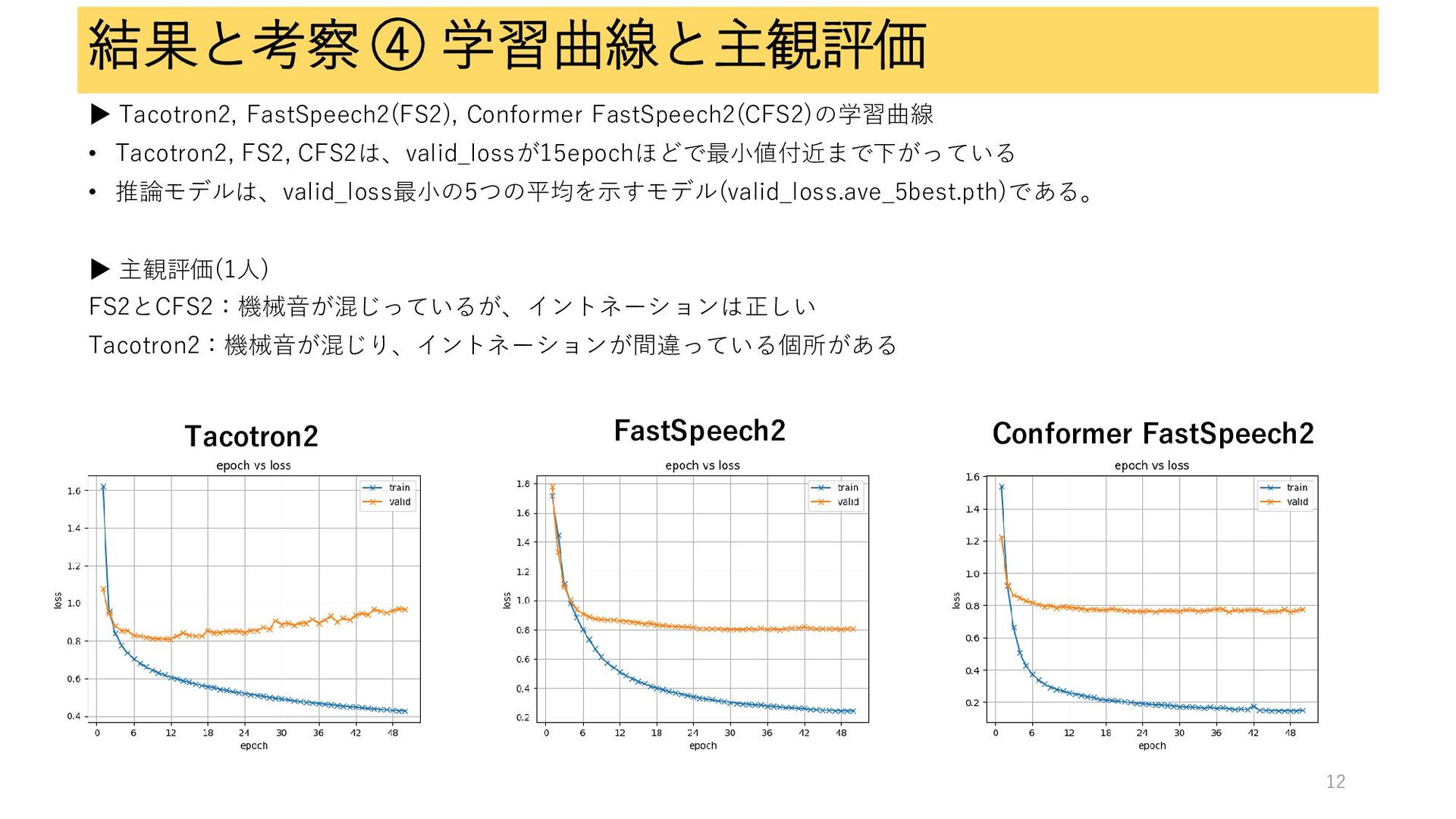
結果と考察 ④ 学習曲線と主観評価 ▶ Tacotron2, FastSpeech2(FS2), Conformer FastSpeech2(CFS2)の学習曲線 • Tacotron2,
FS2, CFS2は、valid_lossが15epochほどで最小値付近まで下がっている • 推論モデルは、valid_loss最小の5つの平均を示すモデル(valid_loss.ave_5best.pth)である。 ▶ 主観評価(1人) FS2とCFS2:機械音が混じっているが、イントネーションは正しい Tacotron2:機械音が混じり、イントネーションが間違っている個所がある Tacotron2 FastSpeech2 Conformer FastSpeech2 12
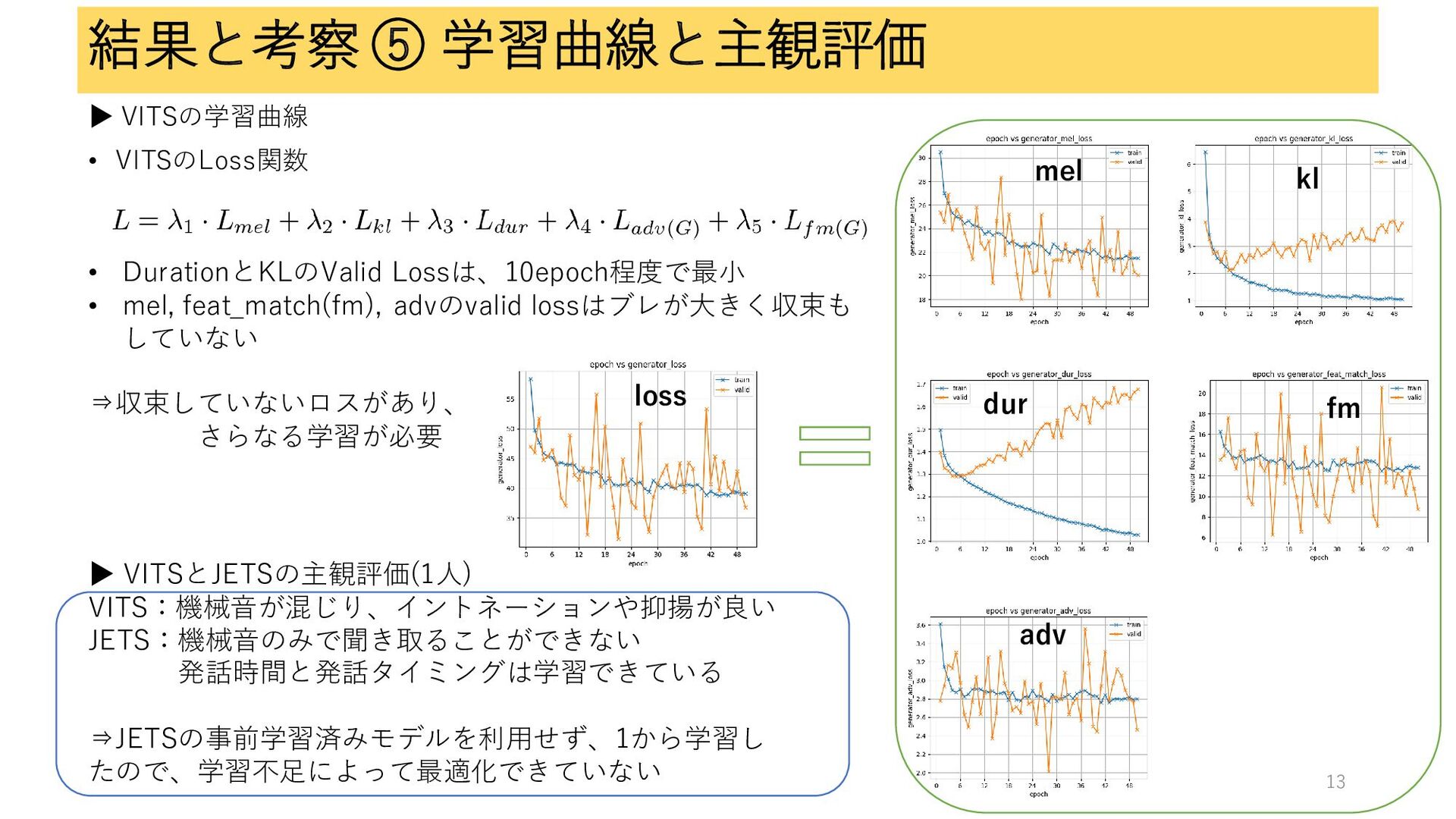
結果と考察 ⑤ 学習曲線と主観評価 ▶ VITSの学習曲線 • VITSのLoss関数 • DurationとKLのValid Lossは、10epoch程度で最小
• mel, feat_match(fm), advのvalid lossはブレが大きく収束も していない ⇒収束していないロスがあり、 さらなる学習が必要 mel loss fm dur kl adv ▶ VITSとJETSの主観評価(1人) VITS:機械音が混じり、イントネーションや抑揚が良い JETS:機械音のみで聞き取ることができない 発話時間と発話タイミングは学習できている ⇒JETSの事前学習済みモデルを利用せず、1から学習し たので、学習不足によって最適化できていない 13
今後の課題 主観評価指標(ex. MOS)の導入 • より正しい音声の品質評価 • 多人数による複数音声の5段階評価を行うので、導入コストが高い 1から学習モデルを学習させる • 事前学習済みモデルからのファインチューニングにより、短時間で任意のコーパスのTTSモデルを作成可能になる
• 事前学習済みモデルとして十分なモデルの学習には、4GPUで1week以上かかる 2段階TTS(非E2E)のJoint-Training(共同学習)の実装 • 2段階TTSは、Text2MelのモデルとNeural Vocoderを同じコーパスで一度にファインチューニングすること(Joint- Training)で、音響の不一致によるロバスト性の低下を克服することが可能 • 参照:Why the outputs contains metallic noise when combining neural vocoder? マルチスピーカーの実装 • テキストが共通するコーパスの用意 14
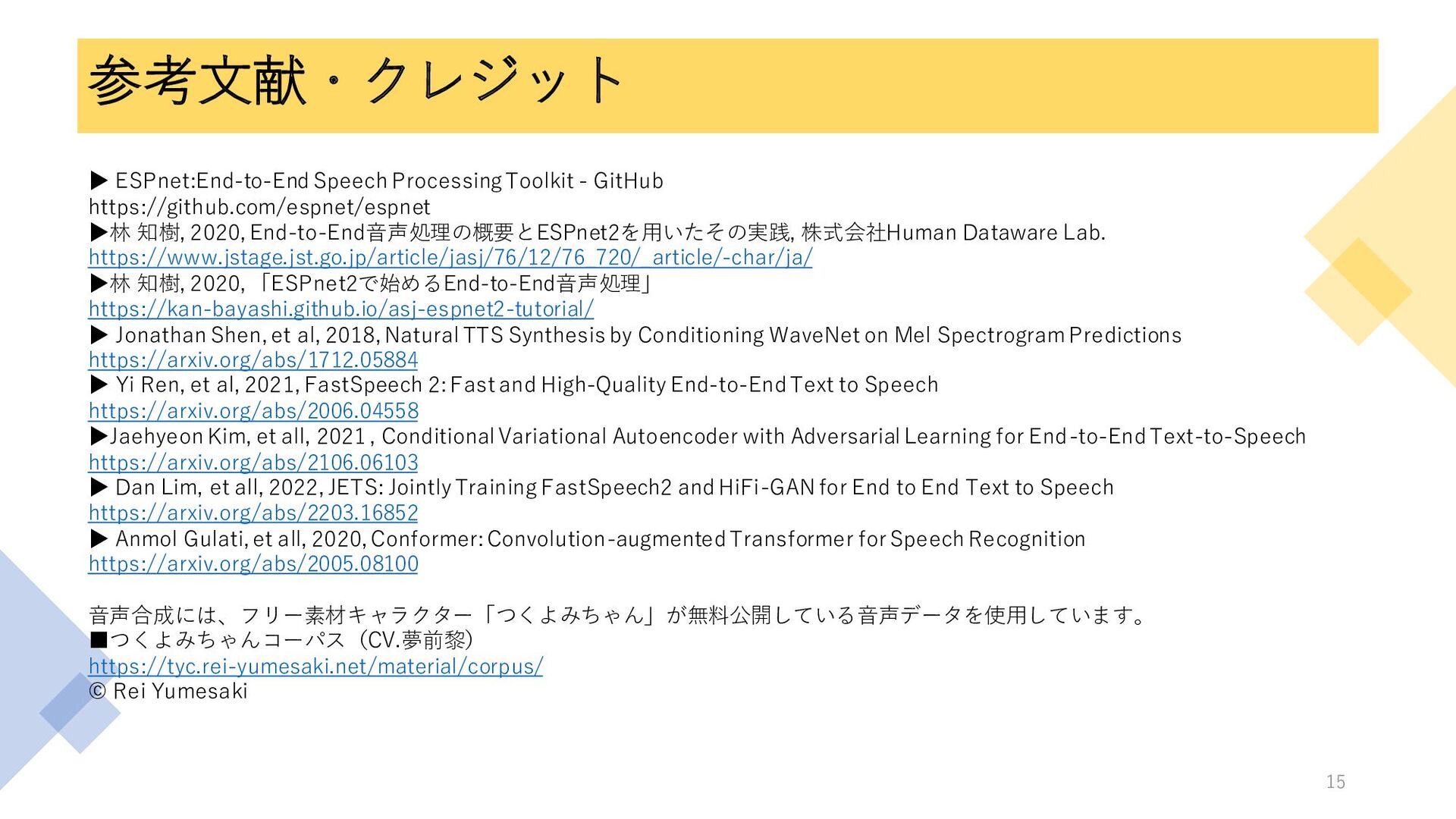
参考文献・クレジット ▶ ESPnet:End-to-End Speech Processing Toolkit - GitHub https://github.com/espnet/espnet ▶林
知樹, 2020, End-to-End音声処理の概要とESPnet2を用いたその実践, 株式会社Human Dataware Lab. https://www.jstage.jst.go.jp/article/jasj/76/12/76_720/_article/-char/ja/ ▶林 知樹, 2020, 「ESPnet2で始めるEnd-to-End音声処理」 https://kan-bayashi.github.io/asj-espnet2-tutorial/ ▶ Jonathan Shen, et al, 2018, Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions https://arxiv.org/abs/1712.05884 ▶ Yi Ren, et al, 2021, FastSpeech 2: Fast and High-Quality End-to-End Text to Speech https://arxiv.org/abs/2006.04558 ▶Jaehyeon Kim, et all, 2021 , Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech https://arxiv.org/abs/2106.06103 ▶ Dan Lim, et all, 2022, JETS: Jointly Training FastSpeech2 and HiFi-GAN for End to End Text to Speech https://arxiv.org/abs/2203.16852 ▶ Anmol Gulati, et all, 2020, Conformer: Convolution-augmented Transformer for Speech Recognition https://arxiv.org/abs/2005.08100 音声合成には、フリー素材キャラクター「つくよみちゃん」が無料公開している音声データを使用しています。 ▪つくよみちゃんコーパス(CV.夢前黎) https://tyc.rei-yumesaki.net/material/corpus/ © Rei Yumesaki 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}