Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ペパボが求める「守って攻める」インフラとは?
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Takuya TAKAHASHI
February 25, 2021
Programming
750
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ペパボが求める「守って攻める」インフラとは?
2021年2月25日開催の Pepabo Tech Conferenct #14 で発表した内容です。
Takuya TAKAHASHI
February 25, 2021
More Decks by Takuya TAKAHASHI
See All by Takuya TAKAHASHI
自作エージェントホスティングプラットフォームで実現する Ambient Agent Workflow
takutakahashi
0
50
顧客の画像データをテラバイト単位で配信する 画像サーバを WebP にした際に起こった課題と その対応策 ~継続的な取り組みを添えて~
takutakahashi
4
2k
実例から学ぶ Kubernetes Custom Controller の状態管理
takutakahashi
0
2.1k
しきい値監視からの卒業! Prometheus による機械学習を用いた異常検知アラートの実装
takutakahashi
0
2.7k
15年以上動くECシステムをクラウドネイティブにするためにやっていること
takutakahashi
1
2.4k
カラーミーショップの 可用性向上のための インフラ刷新
takutakahashi
1
560
Rook/Ceph on ZFS
takutakahashi
1
2.1k
Site Reliability を向上するためにやったことすべて
takutakahashi
11
2.3k
Deep-dive KubeVirt
takutakahashi
2
2.1k
Other Decks in Programming
See All in Programming
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
150
これって Effect でできたのでは? / TSKaigi Mashup Kansai #2
susisu
0
130
AI時代のPHPer生存戦略 ~「言語、もうなんでもよくない?」に本気で向き合う~
vivion
0
210
AWS CDK を「作」ってみた 〜フルスクラッチで見えた CDK の裏側〜 / aws-cdk-from-scratch
gotok365
3
2.7k
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
560
生成AIで帳票OCRが「簡単に」作れる時代になった?
kon_shou
0
110
Augmenting AI with the Power of Jakarta EE
ivargrimstad
0
340
数百円から始めるRuby電子工作
tarosay
0
120
「寝てても仕事が進む」Claude Codeで組む第二の脳
tomoyafujita2016
0
220
Lean は証明の正しさを確認するためだけのツールって思ってませんか?
inoueasei
1
130
yield再入門 #phpcon
o0h
PRO
0
840
【やさしく解説 設計編・中級 #4】ルールの寿命と、システムの年輪
panda728
PRO
2
180
Featured
See All Featured
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Everyday Curiosity
cassininazir
0
270
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Test your architecture with Archunit
thirion
1
2.3k
GraphQLとの向き合い方2022年版
quramy
50
15k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.5k
Utilizing Notion as your number one productivity tool
mfonobong
4
490
Practical Orchestrator
shlominoach
191
11k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
Navigating Team Friction
lara
192
16k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1.1k
Transcript
1 ペパボが求める 「守って攻める」 インフラとは? 高橋 拓也 @ 技術部技術基盤チーム 2021/02/25 Pepabo
Tech Conference #14
2 2 アジェンダ • 自己紹介 • 守りのインフラ ◦ 守りのインフラはどうなっていくのか? •
攻めのインフラ ◦ 攻めのインフラはどうなっていくのか?
3 自己紹介 3
4 4 高橋 拓也 (takutaka) 自己紹介 • インフラエンジニア • 所属:
技術部 技術基盤チーム • 自宅サーバを飼っています • https://github.com/takutakahashi • https://www.takutakahashi.dev • https://twitter.com/takutaka1220 写真
5 5 高橋 拓也 (takutaka) 自己紹介 • 所属: 技術部 技術基盤チーム
◦ 事業部のお手伝いをしたり、 ◦ 全社的なインフラ基盤を開発したりするチーム • 自宅サーバを飼っています • https://github.com/takutakahashi • https://www.takutakahashi.dev • https://twitter.com/takutaka1220 写真 WS 兼 k8s node k8s node k8s master k8s master Backup HDD 今は使ってない HDD
6 守って攻めるインフラ 6 何じゃそりゃ?
7 7 高い可用性と高コストパフォーマンスを維持しながら 運営サービスがチャレンジングな挑戦を 継続的かつ爆速で実行し続けられるインフラの仕組み
8 8 高い可用性と高コストパフォーマンスを維持しながら 運営サービスがチャレンジングな挑戦を 継続的かつ爆速で実行し続けられるインフラの仕組み 「守る」インフラ 「攻める」インフラ
9 守るインフラ 9 サービスを守るぞ!
10 10 解決したい課題
11 11 運営サービスの 可用性をさらに上げたい
12 12 ペパボのサービスインフラ いんたーねっと DC, ネットワーク機器などの物理層 クラウドプロパイダ (ex: OpenStack) HV,
SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード
13 13 ペパボのサービスインフラ いんたーねっと DC, ネットワーク機器などの物理層 クラウドプロパイダ (ex: OpenStack) HV,
SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード 事業部エンジニアで運用 プラットフォームチームで運用
14 14 ペパボのサービスインフラ いんたーねっと DC, ネットワーク機器などの物理層 クラウドプロパイダ (ex: OpenStack) HV,
SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード テストコードの実装 開発環境による動作検証 監視 検証環境構築 継続的アップデート 脆弱性対応 リソース監視とアラート スケール調整 ステージ分離
15 15 プラットフォームの障害発生 いんたーねっと DC, ネットワーク機器などの物理層 クラウドプロパイダ (ex: OpenStack) HV,
SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード
16 16 プラットフォームの障害発生 いんたーねっと DC, ネットワーク機器などの物理層 クラウドプロパイダ (ex: OpenStack) HV,
SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード
17 17 プラットフォームの障害発生 いんたーねっと DC, ネットワーク機器などの物理層 クラウドプロパイダ (ex: OpenStack) HV,
SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード トラブルシューティング 復旧作業 トラブルシューティング 復旧作業
18 18 プラットフォームの障害発生 いんたーねっと DC, ネットワーク機器などの物理層 クラウドプロパイダ (ex: OpenStack) HV,
SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード 祈る 祈る
19 19 可用性を上げたい プラットフォーム起因による大規模障害時にも 「プラットフォームの復旧を祈るしかない」という状態を無くし、 最悪の状況下でもサービス提供を継続できる状態を作りたい
20 守るインフラ 20 サービスを守るぞ!
21 21 守るインフラ? ユーザーからのアクセスに対し 期待される水準で正常に返答できる環境を提供することに 商業的に合理的な最大限の努力をするインフラ
22 - availability - 正常なレスポンスをちゃんと返す - reliability - 想定される遅延以内でレスポンスを返す -
security - データを安全に保管、管理できる 正常に応答する 守るインフラ 22
23 - サービス品質向上幅と消費コストは正比例しない - 一定水準以上はコストパフォーマンスが悪化する - 全てのコストは総量が決まっている - コストを削減すれば、他の部分に利用できるコストが増える -
品質向上は一定ラインで頭打ちする - 極端な例: 日本にDCがある以上日本が沈没したら終わる 商業的に合理的な最大限の努力 守るインフラ 23 コスト: - お金 - コンピュート - 人的リソース
24 やるべきことは2つ - コスト対品質向上効率を最大化する - ボトルネックを排除し、品質の上限を上げ続ける 商業的に合理的な最大限の努力 守るインフラ 24 コスト対品質効率最
大化 品質上限突破
25 25 守るインフラを 実現するために
26 26 守るインフラを実現するために いんたーねっと DC, ネットワーク機器などの物理層 クラウドプロパイダ (ex: OpenStack) HV,
SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード
27 27 守るインフラを実現するために いんたーねっと DC, ネットワーク機器などの物理層 クラウドプロパイダ (ex: OpenStack) HV,
SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード クラウドプロパイダ (ex: OpenStack) HV, SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード プラットフォームを分割 する
28 28 リージョンの作成 守るインフラを実現するために - メリットはいくつかあり、実現可能性も高い - 障害単位の分割がある程度可能 - プラットフォームの構成はコードで管理されている
- ユーザーが使い慣れている - プロビジョニングの資産が使い回せる
29 29 リージョンの作成 守るインフラを実現するために - 果たして最適か? - 保守コストは確実に上がる - IP
の取り回しやクラスタライフサイクルの考慮など - 利用コストも確実に上がる - プロビジョニング手順はどうやっても変わる - 恩恵は可用性向上のみ - 付加機能を与えたり、BCP としての役割は果たせない - 障害リスクが劇的に減るわけではない - 同じシステムを利用するし - 運用者が増えてスケールするわけでもないし
30 30 リージョンの作成 守るインフラを実現するために - 果たして最適か? - 保守コストは確実に上がる - IP
の取り回しやクラスタライフサイクルの考慮など - 利用コストも確実に上がる - プロビジョニング手順はどうやっても変わる - 恩恵は可用性向上のみ - 付加機能を与えたり、BCP としての役割は果たせない - 障害リスクが劇的に減るわけではない - 同じシステムを利用するし - 運用者が増えてスケールするわけでもないし もっとイケてるやり方が あるんじゃないか?
31 31 守るインフラを実現するために いんたーねっと DC, ネットワーク機器などの 物理層 クラウドプロパイダ (ex: OpenStack)
HV, SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード パブリッククラウド コンピュートリソース (ex: VM) アプリケーションコード パブリッククラウドを 併用する
32 32 ハイブリッドクラウド 守るインフラを実現するために - 障害点が完全に分割される - 地理的にも異なるサイトに存在する - 利用したい機能が多くある
- Managed Services - 利用者や運用担当が多い分障害に強い - 巨人の肩に乗れる
33 33 ハイブリッドクラウド 守るインフラを実現するために - AWS とプライベートクラウドを専用線で繋いだ - 任意のテナントと VPC
が L3 で接続可能になった!
34 34 守るインフラを実現するために プライベートクラウドは AWS の豊富な機能と可用性をてにいれた!
35 35 立ちはだかる大きな課題
36 36 AWS をすぐに活用できない 立ちはだかる大きな課題 - 既存の仕組みをなかなか HA にできない -
AWS にもうひとつサイトを作るのはとても大変 - 人的リソースが全然割けない - イニシャルの学習コストが高め 新規プロジェクトでは AWS フル活用したものも多いよ
37 37 金銭的コストが大きい 立ちはだかる大きな課題 - EC2 は(プライベートクラウドと比較して)ちょっと高い - 念の為多めにリソース確保といったことをしづらい -
プライベートクラウドがコスト面で圧倒的有利 - うまいこと使い分けたい - うまいこと?
38 38 エンジニアリングで解決する
39 39 守るインフラを実現するために いんたーねっと DC, ネットワーク機器などの 物理層 クラウドプロパイダ (ex: OpenStack)
HV, SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード パブリッククラウド コンピュートリソース (ex: VM) アプリケーションコード パブリッククラウドを 併用する
40 40 守るインフラを実現するために いんたーねっと DC, ネットワーク機器などの 物理層 クラウドプロパイダ (ex: OpenStack)
HV, SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード パブリッククラウド パブリッククラウドを 一部分だけ利用する マネージドサービス
41 41 パブリッククラウドを一部分だけ活用する 守るインフラを実現するために - 構成をがらっと変えなくても適用できる範囲はある - 大幅に可用性を向上できなかったとしても、プライベートクラウドのリス クを少しでも分散できたら利用する価値はある プライベートクラウドを拡張する
モジュールとして AWS を利用できる実装を行った
42 42 事例: LB on AWS DX
43 43 背景 LB on AWS DX (Direct Connect) -
プライベートクラウドでロードバランサを提供している - OpenStack Octavia - haproxy + keepalived の HA 構成を LBaaS として提供するもの - L4 ロードバランサとしての利用がほとんど
44 44 背景 LB on AWS DX (Direct Connect) -
概ね問題ないが、稀に負荷に耐えられず死ぬ - ノイジーネイバーでパケロスしたり - ネットワークサービス (Neutron) との連携をミスったり - LB のダウン中はサービスが停止する - 復旧まで時間がかかるケースが多い - かなり難易度の高い障害が多い - 新規 LB 構築で復旧を試みることが多く、時間がかかる
45 45 背景 LB on AWS DX (Direct Connect) -
LB 自体も可用性向上の為継続的にアップデートされる - LB のバージョンアップが大変だったりする - LB Image の更新 - 機能開放 - 脆弱性対応
46 46 背景 LB on AWS DX (Direct Connect) -
LB 自体も可用性向上の為継続的にアップデートされる - LB のバージョンアップが大変だったりする - LB Image の更新 - 機能開放 - 脆弱性対応 Octavia とは別の仕組みを利用して リスク分散を図りたい → Elastic Load Balancer (ELB)
47 47 Elastic Load Balancer (ELB) LB on AWS DX
(Direct Connect) - 詳しくは割愛 - レイヤごとに異なる特徴を持った LB を提供している - Network Load Balancer (NLB) - L4 Load Balancer - EIP 固定、暖機運転不要、設定項目少ない - Application Load Balancer (ALB) - L7 Load Balancer - EIP 不定、暖機運転が必要、柔軟に設定が可能
48 48 Elastic Load Balancer (ELB) LB on AWS DX
(Direct Connect) - 詳しくは割愛 - レイヤごとに異なる特徴を持った LB を提供している - Network Load Balancer (NLB) - L4 Load Balancer - EIP 固定、暖機運転不要、設定項目少ない - Application Load Balancer (ALB) - L7 Load Balancer - EIP 不定、暖機運転が必要、柔軟に設定が可能 L4LB の代替として NLB を利用した
49 49 カラーミーショップでの 導入事例
50 50 5秒でわかるカラーミーショップ カラーミーショップでの導入事例 - EC を運営するための各種機能を提供するサービス - ショップサイトは殆どがプライベートクラウドで運用されている
51 プライベートクラウド 51 カラーミーショップでの導入事例 L4LB Octavia SSL終端プロキシ ショップページ 決済システム ショップページ
ショップページ ショップページ 決済システム 決済システム 決済システム ユーザー
52 プライベートクラウド 52 カラーミーショップでの導入事例 L4LB Octavia SSL終端プロキシ ショップページ 決済システム ショップページ
ショップページ ショップページ 決済システム 決済システム 決済システム ユーザー LBが利用不能になると サービス全体が停止
53 プライベートクラウド 53 カラーミーショップでの導入事例 L4LB Octavia SSL終端プロキシ ショップページ 決済システム ショップページ
ショップページ ショップページ 決済システム 決済システム 決済システム ユーザー AWS L4LB NLB
54 プライベートクラウド 54 カラーミーショップでの導入事例 L4LB Octavia SSL終端プロキシ ショップページ 決済システム ショップページ
ショップページ ショップページ 決済システム 決済システム 決済システム ユーザー AWS L4LB NLB LBが利用不能でも NLB でサービス継続
55 プライベートクラウド 55 カラーミーショップでの導入事例 L4LB Octavia SSL終端プロキシ ショップページ 決済システム ショップページ
ショップページ ショップページ 決済システム 決済システム 決済システム ユーザー AWS L4LB NLB NLBやDXが利用不能でも Octavia でサービス継続
56 プライベートクラウド 56 カラーミーショップでの導入事例 L4LB Octavia SSL終端プロキシ ショップページ 決済システム ショップページ
ショップページ ショップページ 決済システム 決済システム 決済システム ユーザー AWS L4LB NLB Route53 によるヘルスチェックと 重み付け DNS ラウンドロビン Route53 によるヘルスチェックと 重み付け DNS ラウンドロビンで 定常時は10%だけ NLB に誘導する
57 57 本番環境への導入を実施した カラーミショップでの導入事例 - 二通りの経路にて導入を実施した - ショップ閲覧機能への入り口 - ショップオーナー用管理画面への入り口
58 58 NLB の構築と運用
59 59 構築と運用コストを限りなくゼロにしたい NLB の構築と運用 - 構築、運用コストの増大が容易に想像できた - 構築時に terraform
書くのが大変 - たくさん NLB 作るのも大変 - メンバの追加、削除を忘れる
60 60 構築と運用コストを限りなくゼロにしたい NLB の構築と運用 - 構築、運用コストの増大が容易に想像できた - 構築時に terraform
書くのが大変 - たくさん NLB 作るのも大変 - メンバの追加、削除を忘れる Kubernetes Custom Controlelr を利用して 構築運用自動化 API を実装した
61 61 Kubernetes Custom Controller NLB の構築と運用 - Kubernetes に任意の動作を拡張できる機能
- 新しいリソースを追加できる - リソースの変更をトリガしオペレーションを追加できる
62 62 Kubernetes Custom Controller NLB の構築と運用
63 63 Kubernetes Custom Controller NLB の構築と運用 Octavia LB の
UUID vpc, subnet などの情報 プラットフォームを 操作する秘匿情報
64 64 NLB 構築フロー
65 プライベートクラウド 65 LB 新規構築フロー L4LB Octavia SSL終端プロキシ 運用者 AWS
NLB 構築システム Octavia API
66 プライベートクラウド 66 LB 新規構築フロー L4LB Octavia SSL終端プロキシ 運用者 AWS
NLB 構築システム Octavia API Octavia LB の uuid を パラメータに NLB の構築をトリガ
67 プライベートクラウド 67 LB 新規構築フロー L4LB Octavia SSL終端プロキシ 運用者 AWS
NLB 構築システム Octavia API Octavia API に 与えられた uuid の LB の構 成情報を問い合わせる
68 プライベートクラウド 68 LB 新規構築フロー L4LB Octavia SSL終端プロキシ 運用者 AWS
NLB 構築システム Octavia API LB の listener, member, healthcheck などの情報を 教える
69 プライベートクラウド 69 LB 新規構築フロー L4LB Octavia SSL終端プロキシ 運用者 AWS
NLB 構築システム Octavia API NLB の定義情報を作成し 構築する L4LB NLB
70 70 NLB ターゲット変更フロー
71 プライベートクラウド 71 LB 運用フロー L4LB Octavia SSL終端プロキシ 運用者 AWS
NLB 構築システム Octavia API L4LB NLB Octavia に メンバが追加された
72 プライベートクラウド 72 LB 運用フロー L4LB Octavia SSL終端プロキシ 運用者 AWS
NLB 構築システム Octavia API L4LB NLB 一定間隔で API に 構成情報を問い合わせる
73 プライベートクラウド 73 LB 運用フロー L4LB Octavia SSL終端プロキシ 運用者 AWS
NLB 構築システム Octavia API L4LB NLB 返却された 構成情報に差分が生じる
74 プライベートクラウド 74 LB 運用フロー L4LB Octavia SSL終端プロキシ 運用者 AWS
NLB 構築システム Octavia API L4LB NLB 差分を元に NLB にターゲットを追加す る
75 プライベートクラウド 75 LB 運用フロー L4LB Octavia SSL終端プロキシ 運用者 AWS
NLB 構築システム Octavia API L4LB NLB サービス運用者は AWS を一切触らずに 運用が完結する!
76 76 自動化システムの導入により NLB の構築と運用 - NLB 構築の際に必要な作業が大幅に少なくなった - 元となる
Octavia LB と AWS クレデンシャルだけ - NLB 運用がゼロになった - メンバの増減はシステムが勝手に全部やってくれる - 切り替えは DNS による自動フェイルオーバー
77 77 自動化システムの導入により NLB の構築と運用 - NLB 構築の際に必要な作業が大幅に少なくなった - 元となる
Octavia LB と AWS クレデンシャルだけ - NLB 運用がゼロになった - メンバの増減はシステムが勝手に全部やってくれる - 切り替えは DNS による自動フェイルオーバー 限りなく少ない手順で AWS を活用した可用性向上が可能となった
78 「守るインフラ」は どうなっていくのか? 78
79 79 Nyah はハイブリッドクラウドプラットフォームになります 「守るインフラ」はどうなっていくのか? - 今まではプライベートクラウドとしての Nyah だった -
パブリッククラウドを透過的に利用できるプラットフォームになります 1つのプラットフォームを操作するように マルチクラウドを操作できる
80 80 Nyah はハイブリッドクラウドプラットフォームになります 「守るインフラ」インフラはどうなっていくのか? - Nyah のユーザーに例えば以下の体験を提供します - LB
を作成したら自然と NLB がついてくる - DNSラウンドロビンによる冗長構成がついてくる - NKE クラスタを作ると EKS がついてくる - プラットフォーム障害をユーザー対応無しで回避する - コスト効率を最適化したオートスケールができる
81 81 「守るインフラ」まとめ
82 82 「守るインフラ」まとめ - 手詰まりの状態を作らないようにプラットフォームを進化させる - AWS とのハイブリッドクラウドにより実現を目指す - 長年運用されているシステムでも恩恵を受けられるようにする
- LB を第一弾として適用を実践、事例を紹介した - 今後はさらにオンプレとパブリッククラウドの境界をなくしていく
83 「攻めるインフラ」 83
84 84 解決したい課題
85 85 可用性を維持したまま 開発サイクルを爆速にしたい つまりどういうことかというと
86 86 「多分動くと思うから リリースしようぜ」 画像略
87 87 多分動くと思うからリリースしようぜ 開発サイクルを爆速にしたい - ステージングでうまくいっても本番でうまくいく保証にはならない - データ量に比例して処理が重くなるとか - 地理的影響が大きかったとか
- 埋もれてた本番の設定差分が影響したとか - 「とりあえず本番に出してみよう」をできる限り可能にする - 可用性を犠牲にしない
88 88 多分動くと思うからリリースしようぜ 開発サイクルを爆速にしたい - どうすればいい? - ローリングリリース - 本番環境の家畜化
89 89 ローリングリリース 開発サイクルを爆速にしたい - 本番に少しずつリリースする - リリース時のユーザーへの影響を最小限にする 10% 30%
50% 100%
90 90 本番環境の家畜化 開発サイクルを爆速にしたい - 本番として動作できる環境一式を容易に構築できるようにする - 動作検証を本番環境で行い、ウォームアップ後リリースする - 障害発生時は他の本番環境にロールバックできるようにする
- 複数の本番環境を同時にサービスインできる構成を取る 100% 100% 100% 本番環境 api frontend LBなど ウォームアップ リリース済み 本番 スケールアウトや アクセス開放など 赤色は サービスイン済み 100% 100% 100% 本番環境 api frontend LBなど
91 - 本番環境が1つの場合 - 原因特定、revert, deploy を短時間で実施する必要がある - 原因が特定できるまで長引くとその分ダウンタイムが長引く 91
アプリケーション更新による障害発生時の対応 開発サイクルを爆速にしたい ダメな 本番環境 原因を特定し revert & deploy よい 本番環境 赤色は サービスイン済み
92 92 アプリケーション更新による障害発生時の対応 開発サイクルを爆速にしたい 100% 100% 100% ダメな 本番環境 リリース済み
本番 残された本番環境を ウォームアップし 切り替え 100% 100% 100% ダメな 本番環境 - 本番環境が複数ある場合 - とりあえず動作実績のあるバージョンに切り替え - ダウンタイムは O(1) となる 赤色は サービスイン済み
93 93 本番環境の家畜化の利点 開発サイクルを爆速にしたい - ロールバックが速い - 手法次第では数秒でロールバック可能 - サービス成長に寄与できる
- 縮小本番環境に一部リクエスト流してABテストしたり - 需要の増加に対し本番環境の追加で対応したり - ローリングリリースも家畜化で実現できる - 家畜10セットを1つずつリリースすれば10%段階リリース
94 94 本番環境の家畜化の欠点 開発サイクルを爆速にしたい - どう考えても管理が複雑になる
95 95 どう考えても管理が複雑になる 開発サイクルを爆速にしたい - ひとつの本番環境を運用するのでも結構大変 - 本番環境を本当に環境差分なく大量に運用できる…?
96 96 どう考えても管理が複雑になる 開発サイクルを爆速にしたい - ひとつの本番環境を運用するのでも結構大変 - 本番環境を本当に環境差分なく大量に運用できる…? 人手を必要とせずに大量の本番環境を うまく管理する仕組みが絶対に必要
97 97 オーケストレーションプラットフォームが必要 大量の環境をうまく管理する - 定義に則ってリソースをオーケストレーションするシステムが必要 - マルチクラウドできると最高 - 「守るインフラ」を実現する
- オーケストレーションシステムは管理の手間が少ないとよい
98 98 オーケストレーションプラットフォームが必要 大量の環境をうまく管理する - 定義に則ってリソースをオーケストレーションするシステムが必要 - マルチクラウドできると最高 - 「守るインフラ」を実現する
- オーケストレーションシステムは管理の手間が少ないとよい Managed Service が充実していて 社内外実績も豊富な Kubernetes が最適
99 99 Kubernetes を活用した 本番環境の家畜化
100 100 再掲 いんたーねっと DC, ネットワーク機器などの 物理層 クラウドプロパイダ (ex: OpenStack)
HV, SDN, SDS コンピュートリソース (ex: VM) アプリケーションコード パブリッククラウド コンピュートリソース (ex: VM) アプリケーションコード
101 101 再掲 いんたーねっと DC, ネットワーク機器などの 物理層 クラウドプロパイダ (ex: OpenStack)
HV, SDN, SDS コンピュートリソース (ex: VM) パブリッククラウド コンピュートリソース (ex: VM) Kubernetes Services prod prod prod prod Kubernetes の層が挟まる
102 102 再掲 いんたーねっと DC, ネットワーク機器などの 物理層 クラウドプロパイダ (ex: OpenStack)
HV, SDN, SDS コンピュートリソース (ex: VM) パブリッククラウド コンピュートリソース (ex: VM) Kubernetes Services prod prod prod prod VM は管理対象ではなくなり クラウド間の差分もなくなる (ように実装する)
103 103 再掲 いんたーねっと DC, ネットワーク機器などの 物理層 クラウドプロパイダ (ex: OpenStack)
HV, SDN, SDS コンピュートリソース (ex: VM) パブリッククラウド コンピュートリソース (ex: VM) Kubernetes Services prod prod prod prod この部分を 具体的に解説します
104 104 家畜化の具体的な活用方法 k8s Cluster A (On-Prem) k8s Cluster B
(EKS) Prod A-1 Prod A-2 Prod B-1 Prod B-2 Prod C-1 Prod C-2 k8s Cluster C (On-Prem) クラウドを跨いだ複数クラスタで 透過的に同一環境が動作する
105 105 家畜化の具体的な活用方法 k8s Cluster A k8s Cluster B Prod
A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) 2ドメイン冗長 冗長なし k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) ユーザー属性を考慮した Prod 間冗長を行う
106 106 クラスタ障害発生時
107 107 家畜化の具体的な活用方法 障害発生時 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) 2ドメイン冗長 冗長なし k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) とあるクラスタが動作不能になる
108 108 家畜化の具体的な活用方法 障害発生時 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) 2ドメイン冗長 冗長なし k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) このユーザーが サービス利用不可能になる
109 109 家畜化の具体的な活用方法 障害発生時 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) 2ドメイン冗長 冗長なし k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) これらのユーザーのアクセスは 守られる
110 110 家畜化の具体的な活用方法 障害発生時 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) 2ドメイン冗長 冗長なし k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) 何らかの方法で 利用する Prod を変更して復旧
111 111 アプリケーション更新
112 112 家畜化の具体的な活用方法 アプリケーション更新 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) 2ドメイン冗長 冗長なし k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) 指定した法則に乗っ取り 更新する Prod を選択する
113 113 家畜化の具体的な活用方法 アプリケーション更新 k8s Cluster A k8s Cluster B
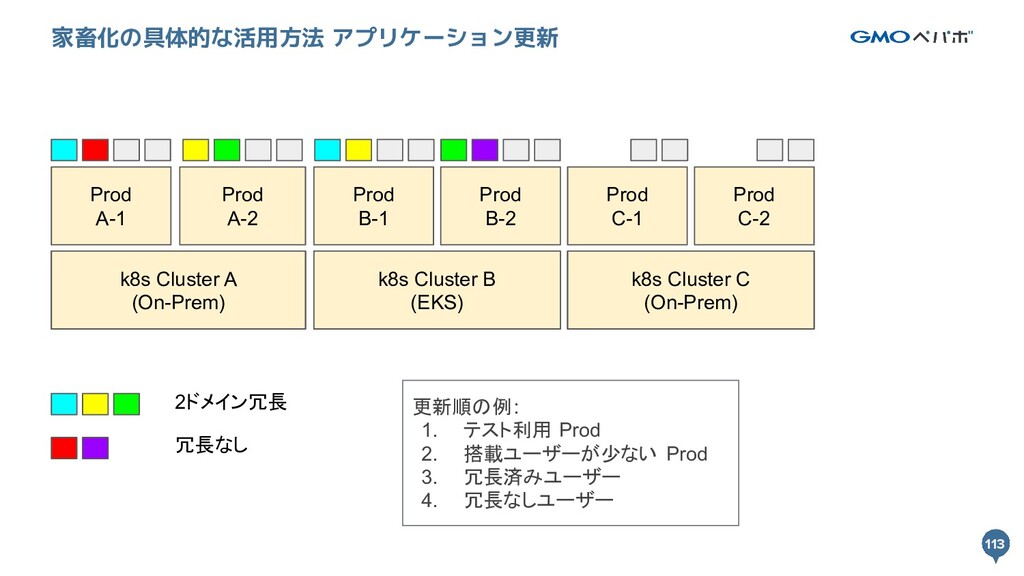
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) 2ドメイン冗長 冗長なし k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) 更新順の例: 1. テスト利用 Prod 2. 搭載ユーザーが少ない Prod 3. 冗長済みユーザー 4. 冗長なしユーザー
114 114 家畜化の具体的な活用方法 アプリケーション更新 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) 2ドメイン冗長 冗長なし k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) 更新順決定: 1. C-2 2. C-1 3. A-2, B-1 4. A-1, B-2
115 115 家畜化の具体的な活用方法 アプリケーション更新 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) 2ドメイン冗長 冗長なし k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) 更新順決定: 1. C-2 2. C-1 3. A-2, B-1 4. A-1, B-2 テスト用 Prod で更新実施後 動作確認を行う
116 116 家畜化の具体的な活用方法 アプリケーション更新 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) 2ドメイン冗長 冗長なし k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) 更新順決定: 1. C-2 2. C-1 3. A-2, B-1 4. A-1, B-2 ユーザー影響の少ない Prod を 更新する
117 117 家畜化の具体的な活用方法 アプリケーション更新 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) 2ドメイン冗長 冗長なし k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) 更新順決定: 1. C-2 2. C-1 3. A-2, B-1 4. A-1, B-2 アラートがでなければ次へ
118 118 家畜化の具体的な活用方法 アプリケーション更新 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) 2ドメイン冗長 冗長なし k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) 更新順決定: 1. C-2 2. C-1 3. A-2, B-1 4. A-1, B-2 更新完了
119 119 クラスタアップグレード
120 120 家畜化の具体的な活用方法 クラスタアップグレード時 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) Cluster A をアップグレードする
121 121 家畜化の具体的な活用方法 クラスタアップグレード時 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) 空きのある Prod へ リクエストを割り振る
122 122 家畜化の具体的な活用方法 クラスタアップグレード時 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) クラスタをアップグレードする
123 123 家畜化の具体的な活用方法 クラスタアップグレード時 k8s Cluster A k8s Cluster B
Prod A-1 Prod A-2 Prod B-1 Prod B-2 k8s Cluster A (On-Prem) k8s Cluster B (EKS) k8s Cluster B Prod C-1 Prod C-2 k8s Cluster C (On-Prem) 別のクラスタから リクエストを再配置する
124 124 どうやって実現する?
125 125 どうやって実現する? 本番環境の家畜化 - Prod のライフサイクル管理 - 構築、更新、リソース監視、退役 -
クラスタのライフサイクル管理 - 構築、更新、リソース監視、退役 - ユーザーのリクエストハンドリング - Prod スケジューリング - 向き先変更
126 126 どうやって実現する? 本番環境の家畜化 - Prod のライフサイクル管理 - 構築、更新、リソース監視、退役 -
クラスタのライフサイクル管理 - 構築、更新、リソース監視、退役 - ユーザーのリクエストハンドリング - Prod スケジューリング - 向き先変更 ライフサイクルの管理には Custom Controller が最適 Custom Controller を利用して 実装開始
127 127 現在の進捗
128 128 本番環境の家畜化 k8s Cluster A (On-Prem) Prod A-1 Prod
A-2 k8s Cluster B (EKS) Prod B-1 Prod B-2 Prod C-1 Prod C-2 k8s Cluster C (On-Prem) Prod の管理だけ実装できた
129 129 実装の進捗 本番環境の家畜化 - Prod を Custom Controller で管理することができるようになった
- kubectl create -f prod.yaml で作成できる - アプリケーション更新は自動化できた - git tag やブランチ更新を監視しイメージを切り替える - 未実装のものが色々ある - ロールバック - リソース監視 - ウォームアップ
130 130 実装の進捗 本番環境の家畜化 - Kubernetes クラスタの管理は考え中 - 可能ならリソースで管理したい -
ClusterAPI を使うか、独自実装するか - NKE の出来が良いので独自実装しても簡単そう
131 131 クラスタ自体の家畜化構想もある 本番環境の家畜化 - Workload Cluster と Control Plane
Cluster に分ける - Control Plane Cluster が Workload Cluster を設定管理する - Workload Cluster はイミュータブルに管理する - クラスタアップグレードしないで捨てる
132 132 実装の進捗 本番環境の家畜化 - ユーザーハンドリングは考え中 - あまりピンとくるアイディアがない - DNS
ラウンドロビンをするか、L7 Proxy を設置するか - スケジューリングをどうするか - クラスタ間のグローバルデータストアが必要? - 監視とフェイルオーバーをどうするか
133 「攻めるインフラ」まとめ 133
134 134 「攻めるインフラ」まとめ - 本番環境の家畜化で攻めていきます - ユーザー影響を最小化した開発サイクルを実現します - 人間のオペレーションをできる限り排除する実装をしています -
現在実装途中です - 「攻めるインフラ」が「守るインフラ」の実現にも繋がっています
135 「守って攻める」インフラ まとめ 135
136 136 「守って攻める」インフラまとめ - より可用性を高められるために試行錯誤を繰り返しています - 現在はハイブリッドクラウド活用による解決を模索しています - 同時に、事業の成長を加速できるインフラを目指しています -
こちらは Kubernetes + Custom Controller で解決します
137 137 「守って攻める」インフラまとめ - より可用性を高められるために試行錯誤を繰り返しています - 現在はハイブリッドクラウド活用による解決を模索しています - 同時に、事業の成長を加速できるインフラを目指しています -
こちらは Kubernetes + Custom Controller で解決します 一緒にインフラを守って攻める仲間を募集中です!
138 138 おしまい • 守りのインフラ ◦ AWS とプライベートクラウドの活用 ◦ NLB
on DX の導入事例 ◦ 守りのインフラの今後 • 攻めのインフラ ◦ 本番環境の家畜化 ◦ Kubernetes と Custom Controller の活用 ◦ 攻めのインフラの今後
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}