Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
わかりやすいパターン認識第5章
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Hassaku-kun
January 29, 2018
Science
1.7k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
わかりやすいパターン認識第5章
手塚若林研で行われたわかりやすいパターン認識読み会第5回の資料
Hassaku-kun
January 29, 2018
Other Decks in Science
See All in Science
Distributional Regression
tackyas
0
540
AIPシンポジウム 2025年度 成果報告会 「因果推論チーム」
sshimizu2006
3
530
データベース05: SQL(2/3) 結合質問
trycycle
PRO
0
1.2k
Testing the Longevity Bottleneck Hypothesis
chinson03
0
330
機械学習 - pandas入門
trycycle
PRO
0
620
Utiliser Bitcoin sans Internet
rlifchitz
0
190
(CVPR2026) Back to Basics: Let Denoising Generative Models Denoise
shumpei777
0
150
AI bij literatuuronderzoek in de wetenschap
voginip
0
190
力学系から見た現代的な機械学習
hanbao
4
4.3k
因果推論と機械学習
sshimizu2006
1
1.2k
Rashomon at the Sound: Reconstructing all possible paleoearthquake histories in the Puget Lowland through topological search
cossatot
0
1k
データベース08: 実体関連モデルとは?
trycycle
PRO
0
1.2k
Featured
See All Featured
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
400
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
200
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
950
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
330
The Curse of the Amulet
leimatthew05
1
13k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
320
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.3k
The Cult of Friendly URLs
andyhume
79
6.9k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
200
Paper Plane
katiecoart
PRO
1
51k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
2.9k
Transcript
わかりやすいパターン認識 第5章 特徴の評価とベイズ誤り確率 谷口正樹 1
5.1 特徴の評価 • 認識系は前処理部,特徴抽出部,識別部からなる(第1章よ り) • 認識系が期待通りの性能を発揮しなかった時,性能を低下させ た原因がどの処理部にあるのか明確にしたい 2
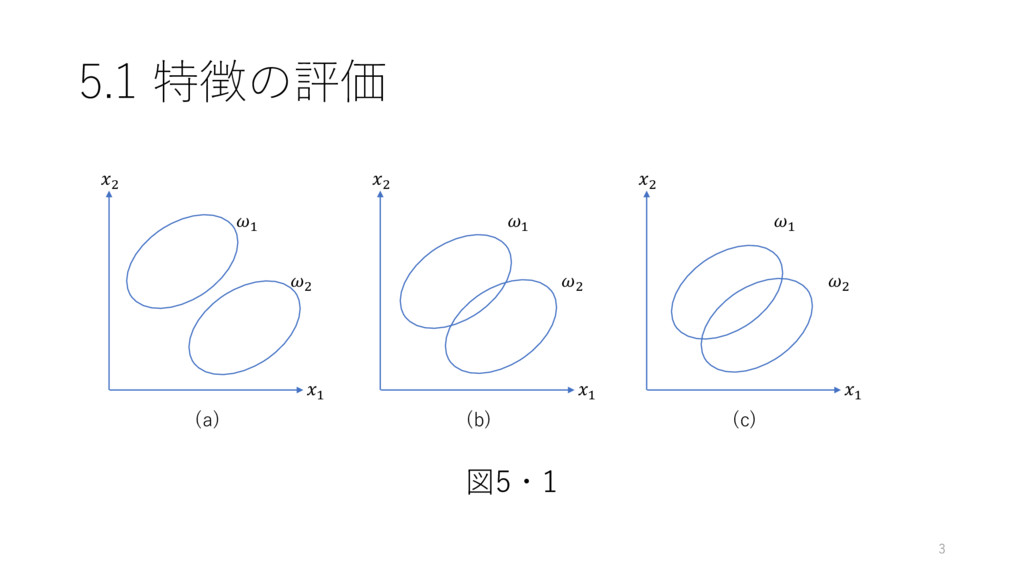
5.1 特徴の評価 図5・1 2 1 1 2 (a) 2 1
1 2 (b) 2 1 1 2 (c) 3
5.1 特徴の評価 • (a)のとき,特徴抽出部には問題はない • (b)または(c)のような場合,誤認識が発生する 予め特徴の評価が必要 4
5.2 クラス内分散・クラス間分散比 • 5.1より,同一クラスのパターンはなるべく接近し,異なるクラ スのパターンはなるべく離れるような分布にしたい. →分散で表そう! クラス内分散( 2 ) →
なるべく小さい方が良い クラス間分散( 2) → なるべく大きい方が良い J = 2 2 クラス内分散・クラス間分散比を考える 5
5.2 クラス内分散・クラス間分散比 実際の数式 クラス内分散 2 = 1 � =1 �
= − − (5.1) クラス間分散 2 = 1 � =1 − − (5.2) 6
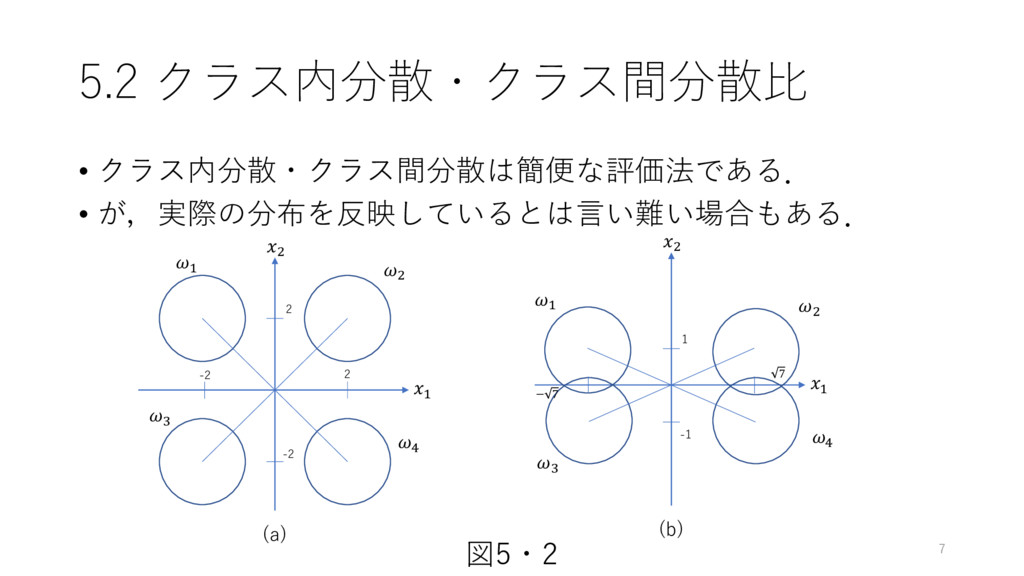
5.2 クラス内分散・クラス間分散比 • クラス内分散・クラス間分散は簡便な評価法である. • が,実際の分布を反映しているとは言い難い場合もある. 2 -2 -2 2
1 2 (a) 1 3 4 2 7 -1 1 1 2 (b) 1 3 4 2 − 7 図5・2 7
5.2 クラス内分散・クラス間分散比 • (a),(b)ではクラス内分散・クラス間分散比が一緒だが,(b)で は重なりが発生してしまっている. • これは,クラス内分散・クラス間分散比が,クラス間の距離だ けを見ていて重なりを考慮していないため 重なりの度合いを考慮した指標がほしい 8
5.3 ベイズ誤り確率とは • 男女を判定する場合を考える. • 一番正確に判定する方法 → 染色体による判定 • 現実的ではないので身長,体重,音声,服装などから判定した
い. → 分布が重なってしまい,一意に分類できない ベイズ誤り確率:「必然的に起こる誤りの確率」 →「分布の重なりの度合い」 9
5.3 ベイズ誤り確率とは 前の2つのクラスの問題を定式化する • 2つのクラス 1 男 ,2 女 •
上2つの生起確率 P 1 ,P 2 • 個の特徴 ベクトル = 1 , 2 , ⋯ − • が観測された時, 1 ,2 に属する確率 P | 1 ,P | 2 • の確率密度関数 10
5.3 ベイズ誤り確率とは 4.1節より 1 + 2 = 1 (5.4) |
1 + | 2 = 1 (5.5) = 1 | 1 + 2 | 2 (5.6) 式(4・4)のベイズの定理より | 1 = | 1 1 (5.7) | 2 = | 2 2 (5.8) が成立 11
5.3 ベイズ誤り確率とは 特徴空間上で分布の重なりがある以上,必ず誤認識を伴う. • あるに対する誤り確率 � | 2 ∈ 1
と判定した時 | 1 ∈ 2 と判定した時 (5.9) • 起こりうる全てのに対する誤り確率 = ∫ (5.10) 12
5.3 ベイズ誤り確率とは 誤り確率 を最小化するには,式(5.10)の において | 1 , | 2
のうち小さいほうが選ばれるようにする. つまり � | 1 > | 2 ⇒ ∈ 1 | 1 < | 2 ⇒ ∈ 2 (5.11) これは事後確率 | = 1,2 を最大にする を出力する 判定方法である. これをベイズ決定則と呼ぶ 13
5.3 ベイズ誤り確率とは の最小値を とすると = min | 1 , |
2 (5.13) である. を条件付きベイズ誤り確率とよぶ. 同様に の最小値を とすると = � d = �min | 1 , | 2 d となる. をベイズ誤り確率とよぶ. (5.15) (5.16) 14
5.3 ベイズ誤り確率とは (ベイズ誤り確率)は,誤り確率をこれ以上は小さくできないと いう限界を示している. その特徴抽出系での判定は よりも正確なものにはならない 15
5.3 ベイズ誤り確率とは を観測せずに男女の判定をする際には事前確率 1 , 2 し か情報がないので2つの比較のみで判定することになる. � 1
> 2 ⇒ ∈ 1 1 < 2 ⇒ ∈ 2 (5.17) 例) 男女比が4:6なら, 1 = 0.4, 2 = 0.6なので,女性と判定 するのが最良.(ただし,4割外れる) 母数が多い方にすれば大体当たるよねという判定 16
5.3 ベイズ誤り確率とは 一方,特定のを観測した場合には判定のための情報量は増える ため,より精度の高い判定が可能になる. その時の判定方法が式(5.11)のベイズ決定則である. � | 1 > |
2 ⇒ ∈ 1 | 1 < | 2 ⇒ ∈ 2 (5.11 再掲) 17
5.3 ベイズ誤り確率とは 今までは2クラスでやっていた ↓ 多クラスの場合に拡張できると嬉しい 18
5.3 ベイズ誤り確率とは 多クラスの場合のベイズ決定則 | > | ∀ ≠ ⇒ ∈
(5.18) あるいは(同じことであるが)表記方法を変えて max i=1,…, | = | ⇒ ∈ (5.19) となる.これは式(4.5)で述べた物と同じである. 19
5.3 ベイズ誤り確率とは また,多クラスの場合のベイズ誤り確率は式(5.16)の代わりに = �min ̇ 1 − | d
(5.20) となる. 20
5.3 ベイズ誤り確率とは 式(5.19)は | が識別関数として使えることを示している. 識別関数を とすると, = | =
1, … , (5.25) である.このようにベイズ決定則を実現するような識別関数を ベイズ識別関数と呼ぶ. 21
5.4 ベイズ誤り確率と最近傍決定則 前節より,ベイズ誤り確率が特徴評価において便利だということ はわかった. しかし,ベイズ誤り確率を求めるために必要な確率密度関数 が既知である場合というのは現実ではまず無い. そのため,ベイズ誤り確率を近似的に求める方法が必要である. 22 〔1〕 最近傍決定則の誤り確率
5.4 ベイズ誤り確率と最近傍決定則 よく知られているものとしてNN法がある.(1.3節参照) これは最近傍決定則による近似. ベイズ誤り確率を ,NN法の誤り確率を とすると,関係式は 以下になる. ≦ ≦
2 − −1 ≦ 2 (5.26) 23 〔1〕 最近傍決定則の誤り確率
5.4 ベイズ誤り確率と最近傍決定則 ≦ ≦ 2 − −1 ≦ 2 (5.26)
詳細に見ていくと, • NN法の誤り確率はベイズ誤り確率より大きい(これは自明) • NN法の誤り確率はベイズ誤り確率の2倍を超えない →割と良い近似になって嬉しい. というわけで式(5.26)を導いていきます.(ココでは = 2のとき) 24 〔1〕 最近傍決定則の誤り確率
5.4 ベイズ誤り確率と最近傍決定則 まず,予め所属クラスのわかっている個のプロトタイプ 1 , 2 , … , を用意する.
入力パターンに対する最近傍を′で表すと, ′はプロトタイプ の中から選ばれるので ′ ∈ 1 , 2 , … , となる. 25 〔1〕 最近傍決定則の誤り確率
5.4 ベイズ誤り確率と最近傍決定則 NN法で誤りが生じるのは,入力パターンと最近傍′が別のクラ スに属する場合なので,誤り確率 は = | 1 | 2
′ + | 1 ′ | 2 (5.28) である.起こりうる全てのに対する誤り確率 は = ∫ d (5.29) となる. 26 〔1〕 最近傍決定則の誤り確率
5.4 ベイズ誤り確率と最近傍決定則 ここで,次の仮定を置く. lim →∞ ′ = (5.30) つまり,プロトタイプ数を極限まで増やせば′はに限りなく 近づくということ.したがって,
lim →∞ | ′ = | i = 1,2 (5.31) が成り立つ 27 〔1〕 最近傍決定則の誤り確率
5.4 ベイズ誤り確率と最近傍決定則 式(5.28)と式(5,31)より, lim →∞ = 2 | 1 |
2 (5.32) = 2 | 1 1 − | 2 (5.33) 式(5.13)を用いて, = 2 1 − (5.34) が得られる 28 〔1〕 最近傍決定則の誤り確率
5.4 ベイズ誤り確率と最近傍決定則 式(5.13)の変形 = min | 1 , | 2
(5.35) = min | 1 , 1 − | 1 (5.36) ≦ 1 2 (5.37) 29 〔1〕 最近傍決定則の誤り確率
5.4 ベイズ誤り確率と最近傍決定則 今までの式(5.15),(5.29),(5.34)より を考える = ∫ d (5.15) = ∫
d (5.29) lim →∞ = 2 1 − (5.34) 30 〔1〕 最近傍決定則の誤り確率
5.4 ベイズ誤り確率と最近傍決定則 前述の3式より,NN法の誤り確率 は = lim →∞ (5.38) = �
lim →∞ d (5.39) = � 2 1 − d (5.40) = 2 1 − − 2・Var (5.41) ≦ 2 1 − (5.42) となる.ただしVar は の分散 31 〔1〕 最近傍決定則の誤り確率
5.4 ベイズ誤り確率と最近傍決定則 ここで, ≧ B (5.45) は自明(なはず)なので省略. (テキストに証明があります.式(5.40)からの変形で求まりま す.) 32
〔1〕 最近傍決定則の誤り確率
5.4 ベイズ誤り確率と最近傍決定則 式(5.37),(5.42),(5.45)をまとめると, ≦ ≦ 2 1 − ≦ 2
(5.46) となり, = 2のときに式(5.26)が導けました. ≦ ≦ 2 − −1 ≦ 2 (5.26再掲) ※ > 2のときの一般化の証明は原論文[CH67]参照 33 〔1〕 最近傍決定則の誤り確率
5.4 ベイズ誤り確率と最近傍決定則 今の話を具体的な例題でやっていきます 34 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 2つのクラス1 , 2 が1次元特徴空間上の区間[0,1]上に分布し, 両クラスの事前確率が 1 = 2
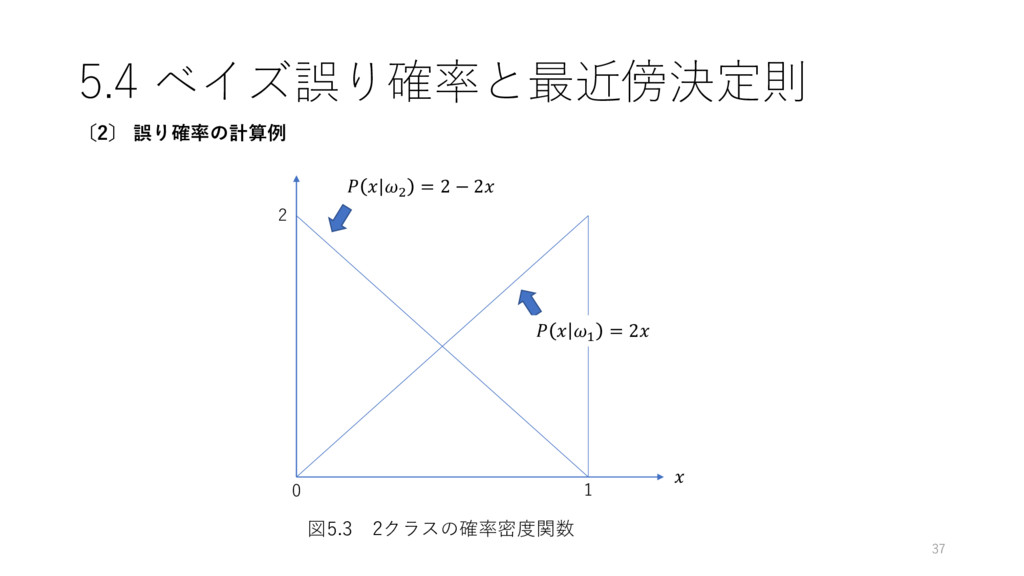
= 1 2 (5.48) と等しい時を考える. また,両クラスの確率密度関数 | 1 , | 2 を以下とする | 1 = 2 (5.49) | 2 = 2 − 2 (5.50) ここでは1次元の特徴値を表す. 35 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 式(5.6)より, = 1 | 1 + 2 |
2 (5.51) = 1 2 ⋅ 2 + 1 2 2 − 2 (5.52) = 1 (5.53) となるため,パターンは一様分布であることがわかる. 36 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 37 〔2〕 誤り確率の計算例 0 1 2 | 1
= 2 | 2 = 2 − 2 図5.3 2クラスの確率密度関数
5.4 ベイズ誤り確率と最近傍決定則 また,ベイズの定理式(4.4)より | 1 = (5.54) | 2 =
1 − (5.55) が得られる. 今後,両クラスで合計個のプロトタイプ1 , 2 , … , を用いて未知パターンを識別することを考える. ※以後, 1 , 2 などは特徴値と同時に入力パターンそのものを表す. 38 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 入力パターンをNN法で識別したときの誤り確率 , ′ は, 式(5.28)より = | 1
| 2 ′ + | 1 ′ | 2 (5.28再掲) , ′ = 1 − ′ + ′ 1 − (5.57) これを′で平均したものを と置くと, = ∫ 0 1 e , ′ , ′ d′ (5.58) = + 1 − 2 (5.61) 39 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 ここで, , ′ は未知パターンに対してその最近傍が′ となる確率. は ≝ ∫
0 1 ′ , ′ d′ (5.62) である. 40 〔2〕 誤り確率の計算例
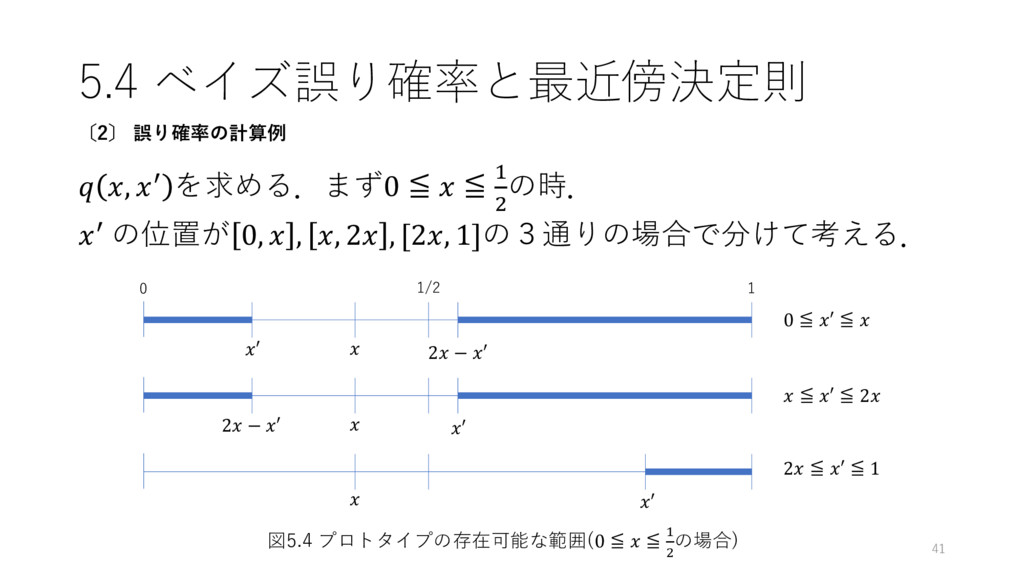
5.4 ベイズ誤り確率と最近傍決定則 , ′ を求める.まず0 ≦ ≦ 1 2 の時.
′ の位置が 0, , , 2 , [2, 1]の3通りの場合で分けて考える. 41 〔2〕 誤り確率の計算例 0 1 1/2 ′ ′ ′ 2 − ′ 2 − ′ 0 ≦ ′ ≦ ≦ ′ ≦ 2 2 ≦ ′ ≦ 1 図5.4 プロトタイプの存在可能な範囲(0 ≦ ≦ 1 2 の場合)
5.4 ベイズ誤り確率と最近傍決定則 追記:ダルい場合分けになってきたので整理しましょう • 0 ≦ ≦ 1 2 のとき
1. 0 ≦ 𝑥 ≦ 2. ≦ 𝑥 ≦ 2 3. 2 ≦ 𝑥 ≦ 1 • 1 2 ≦ ≦ 1のとき 1. 0 ≦ ′ ≦ 2 − 1 2. 2 − 1 ≦ ′ ≦ 3. ≦ ′ ≦ 1 42 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 個のプロトタイプの内1つが図5.4の′の位置に,残り − 1 個 が図の太線の区間に存在している必要がある.そのような確率を 求めると , ′
= 1 − 2 + 2′ −1 0 ≦ ′ ≦ 1 + 2 − 2′ −1 ≦ ′ ≦ 2 1 − ′ −1 2 ≦ ≦ 1 (5.63) よって明らかに∫ 0 1 ⋅ ′ d′ = 1 (5.64)が成り立つ. 43 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 式(5.63)と式(5.62)より, = + 1 +1 1 − 2
− 1 + 1 0 ≦ ≦ 1 2 (5.66) となる. 44 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 次に 1 2 ≦ ≦ 1の時. ′ の位置が
0,2 − 1 , 2 − 1, , [, 1]の3通りの場合で分けて同 様に考える. , ′ = ′ −1 0 ≦ ′ ≦ 2 − 1 1 − 2 + 2′ −1 2 − 1 ≦ ′ ≦ 1 + 2 − ′ −1 ≦ ≦ 1 (5.67) 45 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 個のプロトタイプの内1つが図5.4の′の位置に,残り − 1 個 が図の太線の区間に存在している必要がある.そのような確率を 求めると , ′
= 1 − 2 + 2′ −1 0 ≦ ′ ≦ 1 + 2 − 2′ −1 ≦ ′ ≦ 2 1 − ′ −1 2 ≦ ≦ 1 (5.63) 46 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 0 ≦ ≦ 1 2 の時と同様に, = +
1 +1 2 − 1 − 1 − 1 2 ≦ ≦ 1 (5.68) となる. 47 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 式(5.66),(5.68)を式(5.61)に代入して整理すると, = + 1 − 2 (5.61再掲) 0
≦ ≦ 1 2 のとき = 1 2 − − 1 + 1 1 − 2 n+2 + 1 − 2 n+1 − 1 − 2 2 + 1 (5.69) 1 2 ≦ ≦ 2のとき = 1 2 − − 1 + 1 2 − 1 n+2 + 2 − 1 n+1 − 2 − 1 2 + 1 (5.70) 48 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 したがってNN法の誤り確率 は2 − 1 = と置換することで = ∫
0 1 d (5.71) = 1 2 � 0 1 − −1 +1 +2 + +1 − 2 + 1 d (5.73) = 1 3 + 3+5 2 +1 +2 +3 (5.74) である. 49 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 求めたNN法の誤り確率 を確認していく. もし仮にプロトタイプが一つなら 2クラスの内片方のクラスは誤って識別されるはず → = 1 2
になる. 実際に式(5.74)に = 1を代入すると = 1 2 なので良さそう. 50 〔2〕 誤り確率の計算例
5.4 ベイズ誤り確率と最近傍決定則 プロトタイプが無限のときの = lim →∞ = 1 3 (5.75)
となる.ベイズ誤り確率 は式(5.16)より = ∫ 0 1 min , 1 − d = 1 4 (5.77) 式(5.46)に代入して, ≦ ≦ 2 1 − ≦ 2 (5.46再掲) 1 4 < 1 3 < 3 8 < 1 2 (5.78) となり,関係式が成立 51 〔2〕 誤り確率の計算例
5.5 ベイズ誤り確率の推定法 ベイズ誤り確率を定義式から直接求めるのは難しい →学習パターンから推定する手法を見ていこう 52
5.5 ベイズ誤り確率の推定法 偏り 与えられたパターン集合から何らかの統計量 を推定した場 合,確率変数となる.これを とする この時の の偏り(Bias)は のすべての可能なに渡る平均
値と真横値との差で定義される. Bias = − 0 (5.79) 偏りがゼロの時,不遍や不遍推定量と呼ばれる 53 〔1〕 誤識別率の偏りと分散
5.5 ベイズ誤り確率の推定法 分散 の分散(variance)は推定値間でのばらつきとして Var = E − 2 (5.80)
で定義される. 54 〔1〕 誤識別率の偏りと分散
5.5 ベイズ誤り確率の推定法 • 偏りが小さいほど推定量が真値に近い • 分散が小さいほど推定量の信頼性が高い 55 〔1〕 誤識別率の偏りと分散 推定量の良さの尺度として使える
5.5 ベイズ誤り確率の推定法 ここで,誤識別率を , とする. , :学習パターンの分布の集合 :テストパターンの分布の集合 ※誤識別率は一般に学習パターンとテストパターンの関数になるが,これ は識別機の設計に学習パターンが,評価にテストパターン使われることか
ら明らかである. 56 〔2〕 ベイズ誤り確率の上限および下限
5.5 ベイズ誤り確率の推定法 ベイズ誤り確率について考える. ベイズ誤り確率は真の分布で学習し,真の分布でテストした場合 の誤り確率であるといえるので, 真の集合をとした時, , 一方,有限個の学習パターンで推定された分布を � とすると次の
不等式が成り立つ , ≦ � , (5.81) � , � ≦ , � (5.82) 57 〔2〕 ベイズ誤り確率の上限および下限
5.5 ベイズ誤り確率の推定法 誤識別率はテストパターンに関して不遍なので,学習パターンと 独立なテストパターンに関する期待値=真の分布でテストした誤 認識率 学習パターンと独立なテストパターンの分布を � ′とすると � ′
{ � , � ′ } = � , (5.84) 式(5.81)より, , ≦ � ′ { � , � ′ } (5.85) 58 〔2〕 ベイズ誤り確率の上限および下限
5.5 ベイズ誤り確率の推定法 また,式(5.82)より, � � , � ≦ � ,
� (5.86) テストパターンに関する期待値は不偏より, � , � = , (5.87) よって � � , � ≦ , (5.88) 59 〔2〕 ベイズ誤り確率の上限および下限
5.5 ベイズ誤り確率の推定法 式(5.85),(5.88)より,以下のようにベイズ誤り確率の上限値と 下限値がわかる. � � , � ≦ ,
≦ � ′ { � , � ′ } (5.89) このことから,上限と下限で挟み撃ちすることによって ベイズ誤り確率を推定することができる. 60 〔2〕 ベイズ誤り確率の上限および下限
5.5 ベイズ誤り確率の推定法 しかし,実際の応用においては期待値計算を直接行うことはできない ので,下限値,上限値は以下の方法で求める. 下限値:再代入法(R法) 学習パターンで識別器を設計し,同じ学習パターンでテストする. 上限値:L法 − で学習し, でテストするという手順をi
= 1,2, … , について行 う. 61 〔2〕 ベイズ誤り確率の上限および下限
5.5 ベイズ誤り確率の推定法 しかし,前述R法,L法の推定精度も,特徴の次元数によって精 度が大きく変化する むやみに特徴数を増やすことは識別機の設計だけでなく,特徴の 評価をも困難にする 62 〔2〕 ベイズ誤り確率の上限および下限
5.5 ベイズ誤り確率の推定法 63 〔2〕 ベイズ誤り確率の上限および下限
5.5 ベイズ誤り確率の推定法 64 〔2〕 ベイズ誤り確率の上限および下限
5.5 ベイズ誤り確率の推定法 65 〔2〕 ベイズ誤り確率の上限および下限
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![5.4 ベイズ誤り確率と最近傍決定則 2つのクラス1 , 2 が1次元特徴空間上の区間[0,1]上に分布し, 両クラスの事前確率が 1 = 2](https://files.speakerdeck.com/presentations/e6a121e689e74d928a888b6b257151fa/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}