追加学習なしでの精度改善 A Distractor-Aware Memory for Visual Object Tracking with SAM2 [Videnovic+, CVPR25] テキストによるオブジェクト指定 SAMWISE: Infusing Wisdom in SAM2 for Text-Driven Video Segmentation [Cuttano+, CVPR25] 1 2 3 まとめ 4
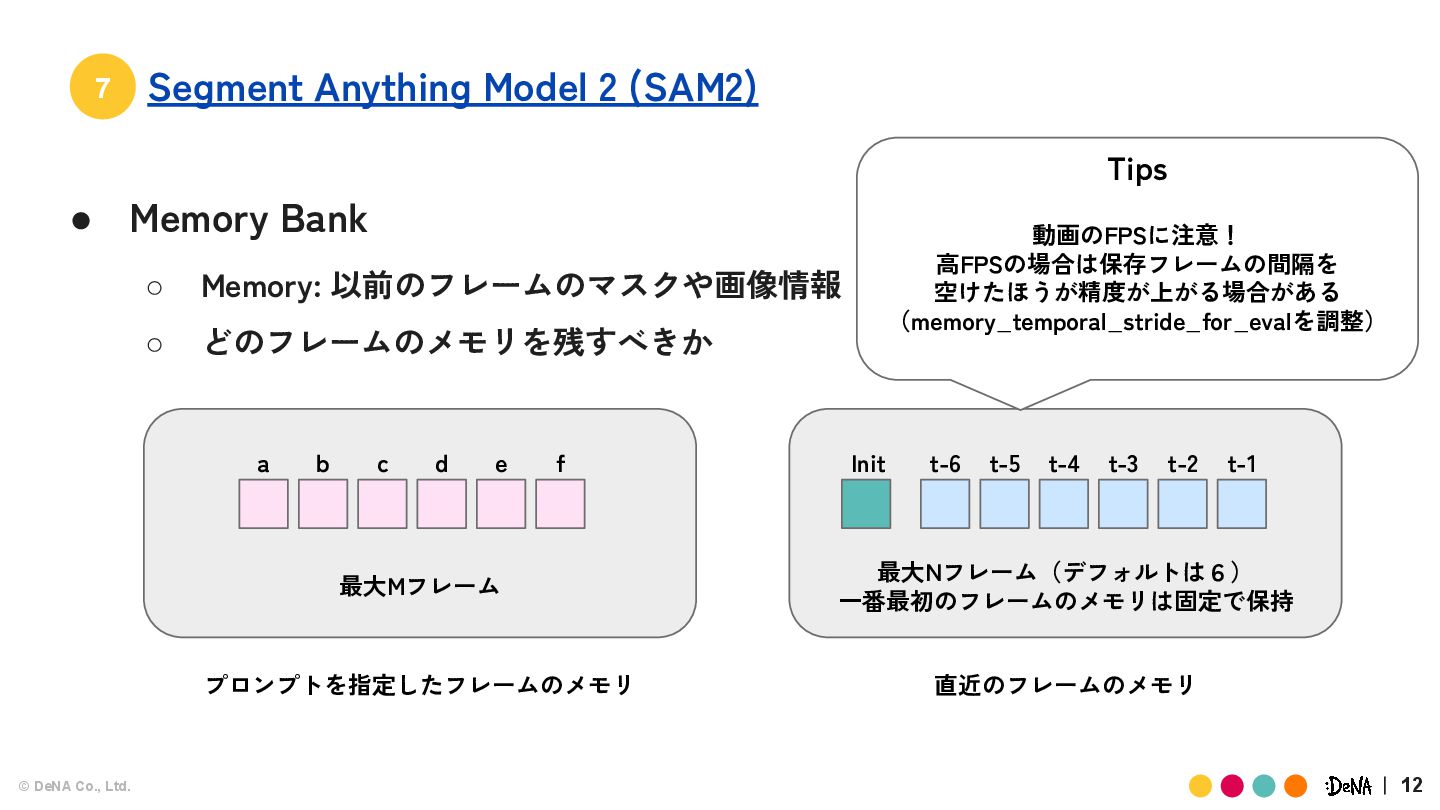
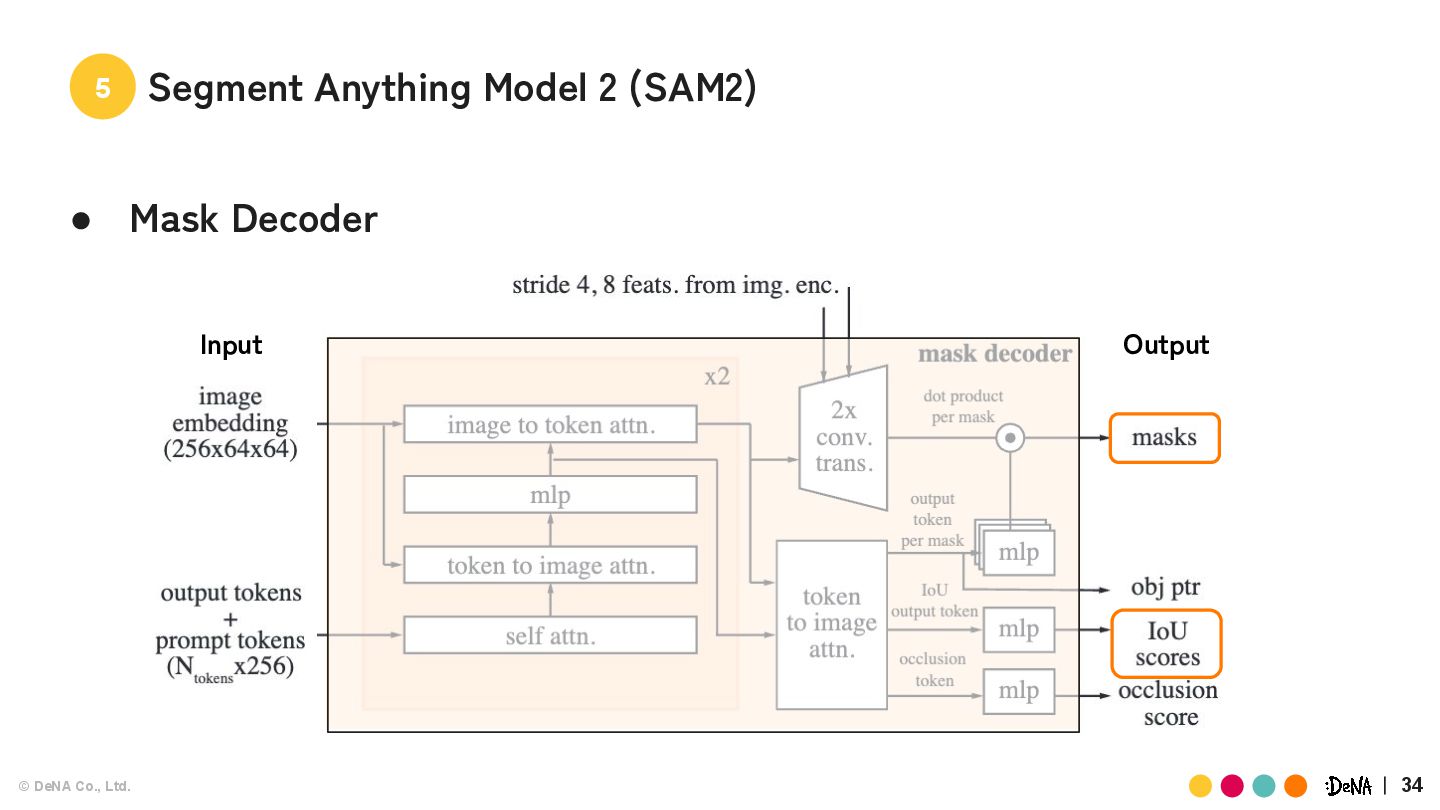
(SAM2) • Memory Bank ◦ Memory: 以前のフレームのマスクや画像情報 ◦ どのフレームのメモリを残すべきか プロンプトを指定したフレームのメモリ 直近のフレームのメモリ 最大Mフレーム 最大Nフレーム(デフォルトは6) 一番最初のフレームのメモリは固定で保持 Init t-6 t-5 t-4 t-3 t-2 t-1 a b c d e f Tips 動画のFPSに注意! 高FPSの場合は保存フレームの間隔を 空けたほうが精度が上がる場合がある (memory_temporal_stride_for_evalを調整)
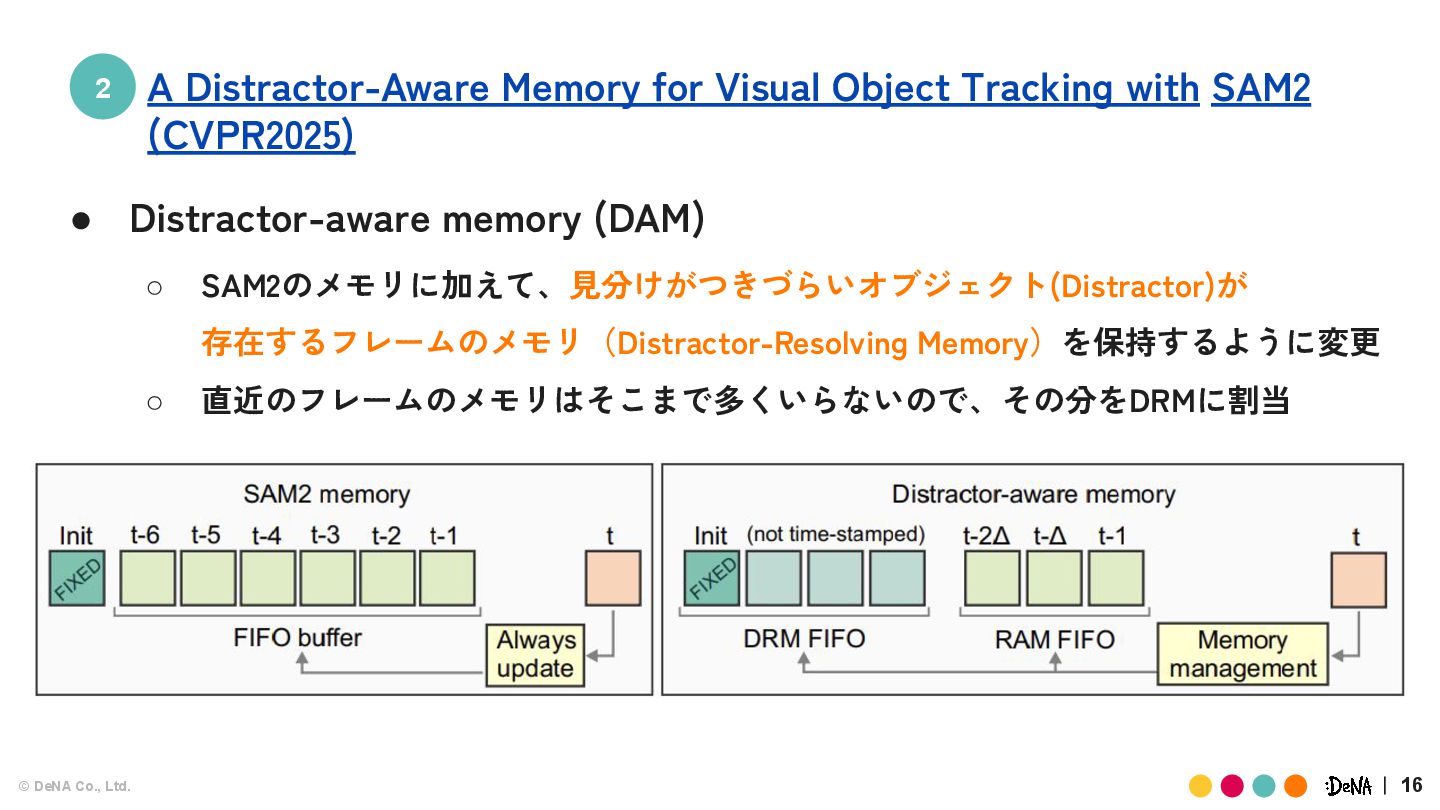
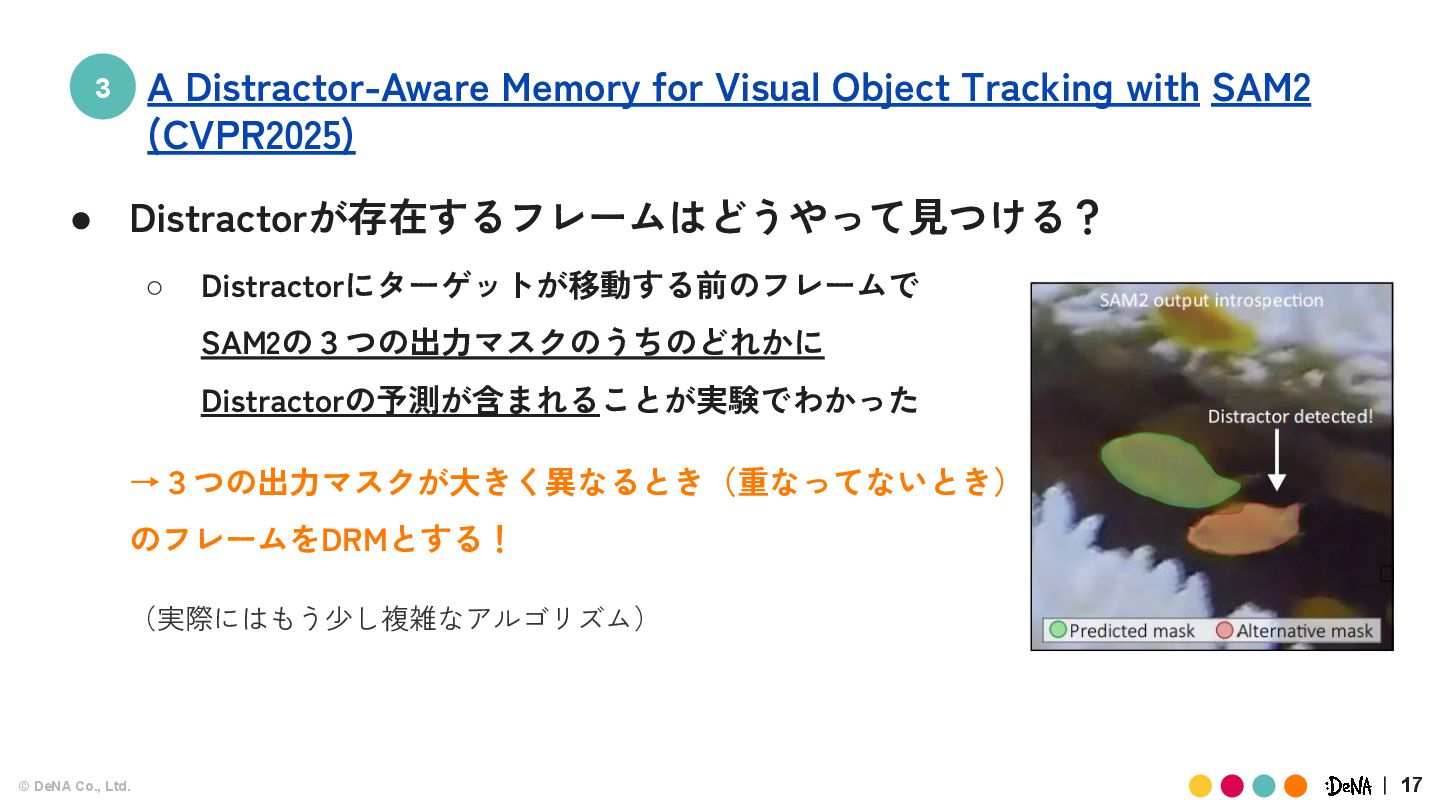
SAM2の3つの出力マスクのうちのどれかに Distractorの予測が含まれることが実験でわかった →3つの出力マスクが大きく異なるとき(重なってないとき) のフレームをDRMとする! (実際にはもう少し複雑なアルゴリズム) A Distractor-Aware Memory for Visual Object Tracking with SAM2 (CVPR2025)
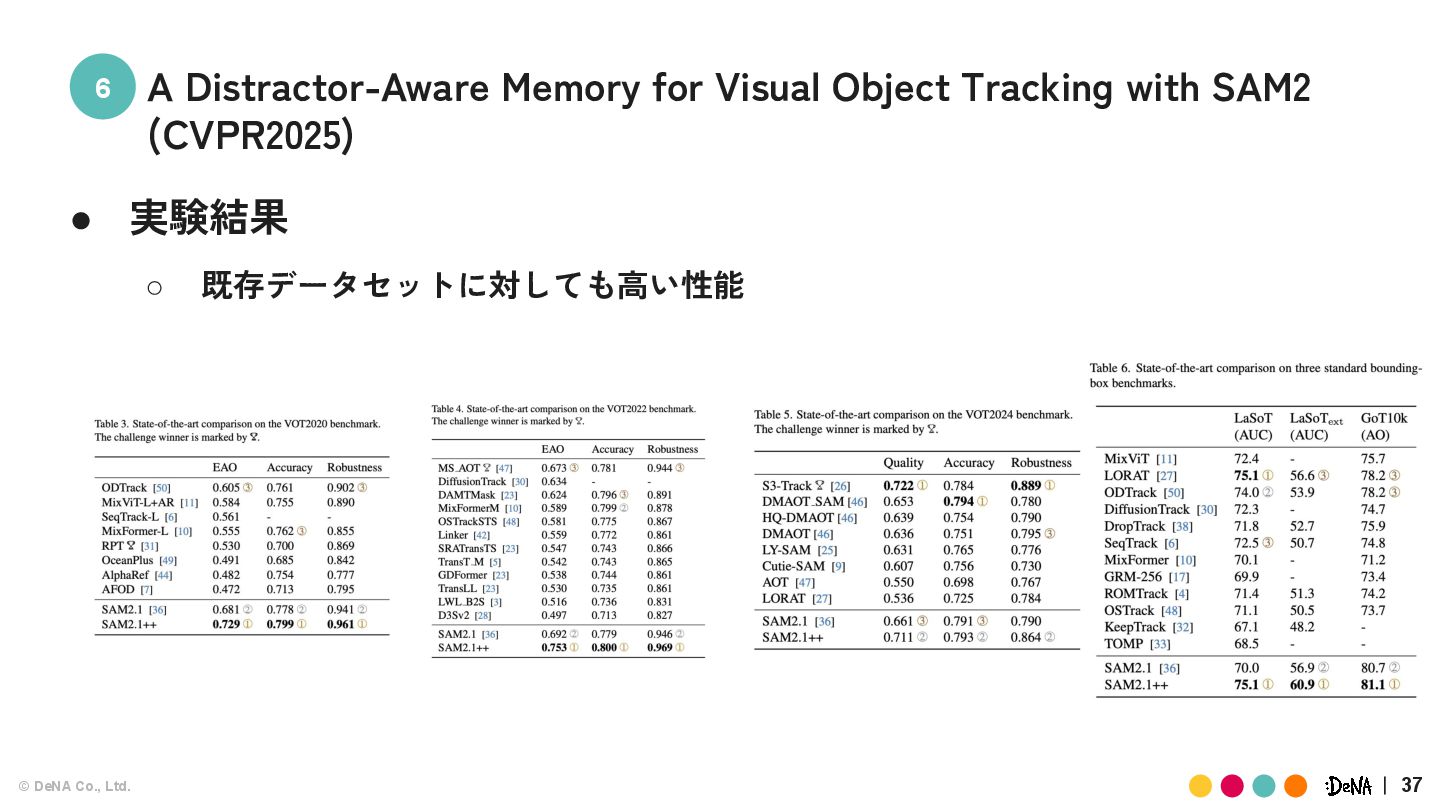
既存のトラッキングベンチマークデータセットは簡単な例が多く Distractorが存在するような状況のデータが過小評価される ◦ 以下のようにDistractorが存在するようなデータを既存のデータセットから 半自動的に抽出 A Distractor-Aware Memory for Visual Object Tracking with SAM2 (CVPR2025)
{kind=link}
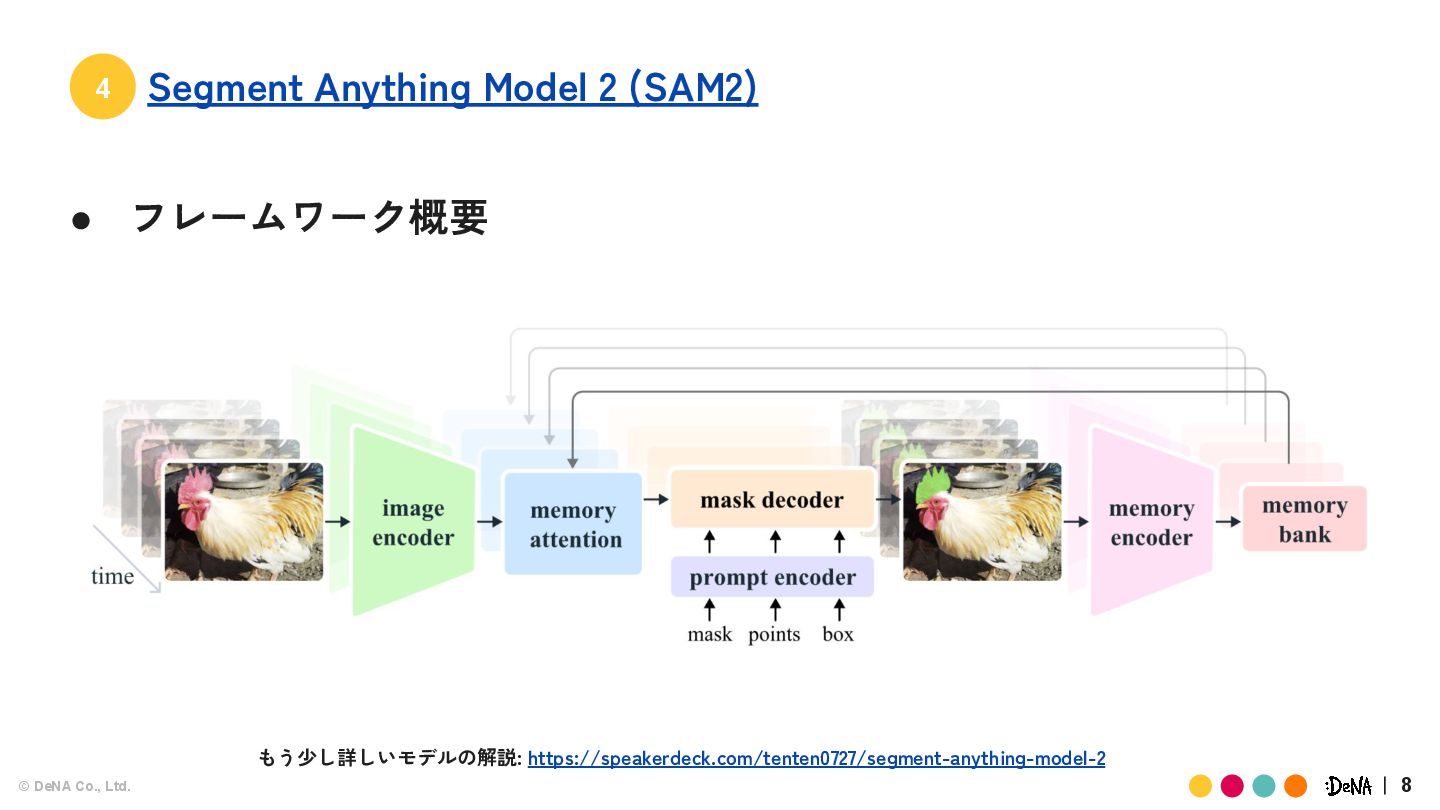
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
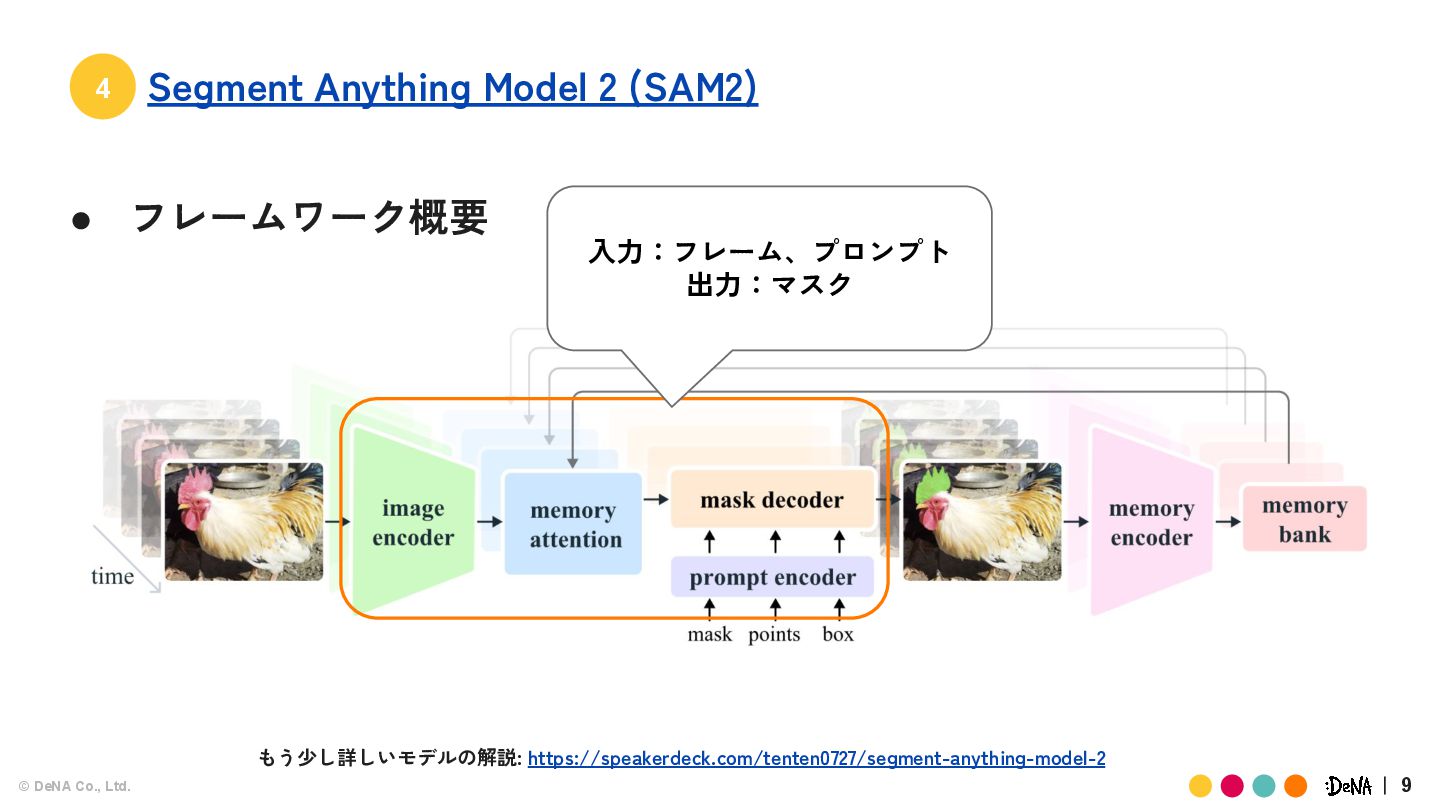
{kind=link}
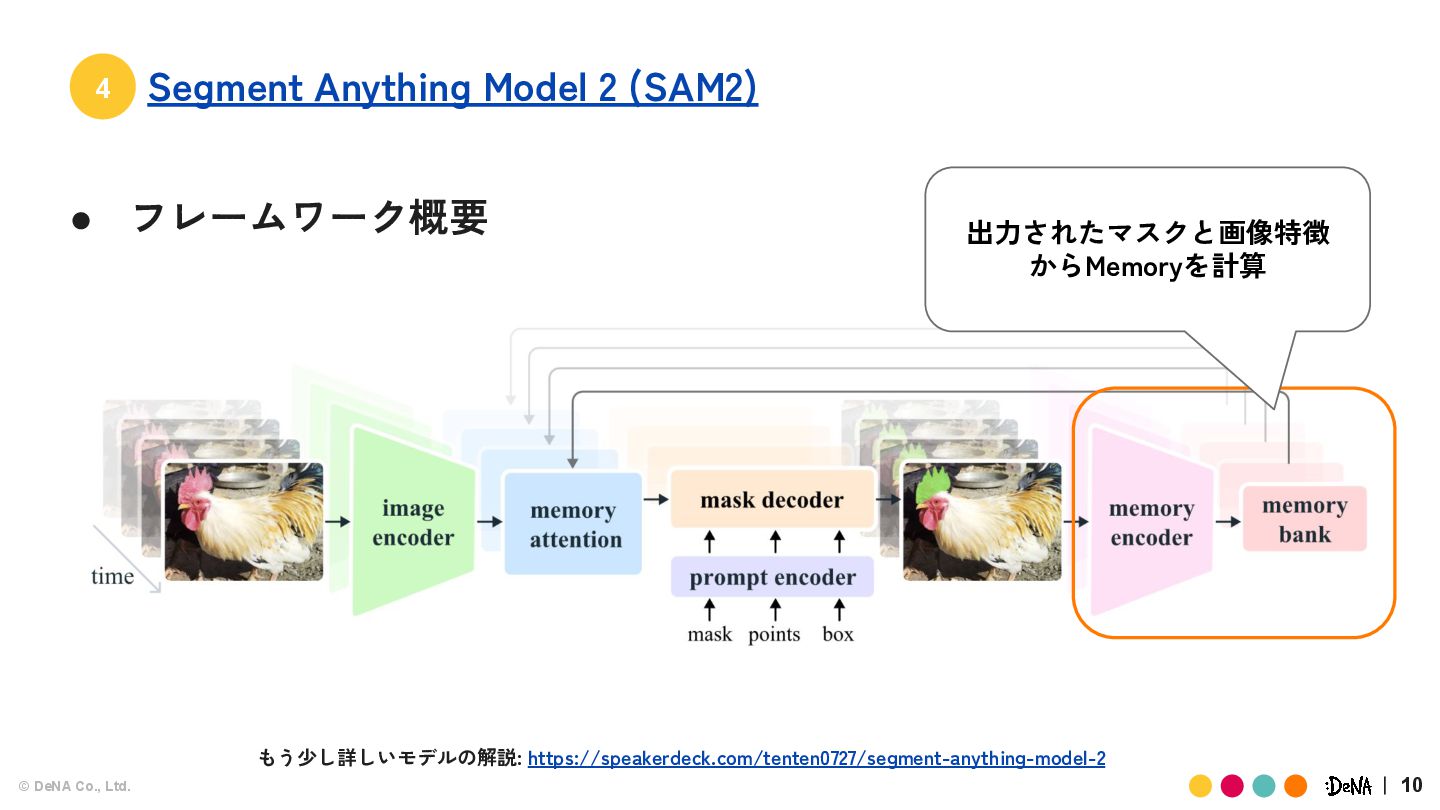
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
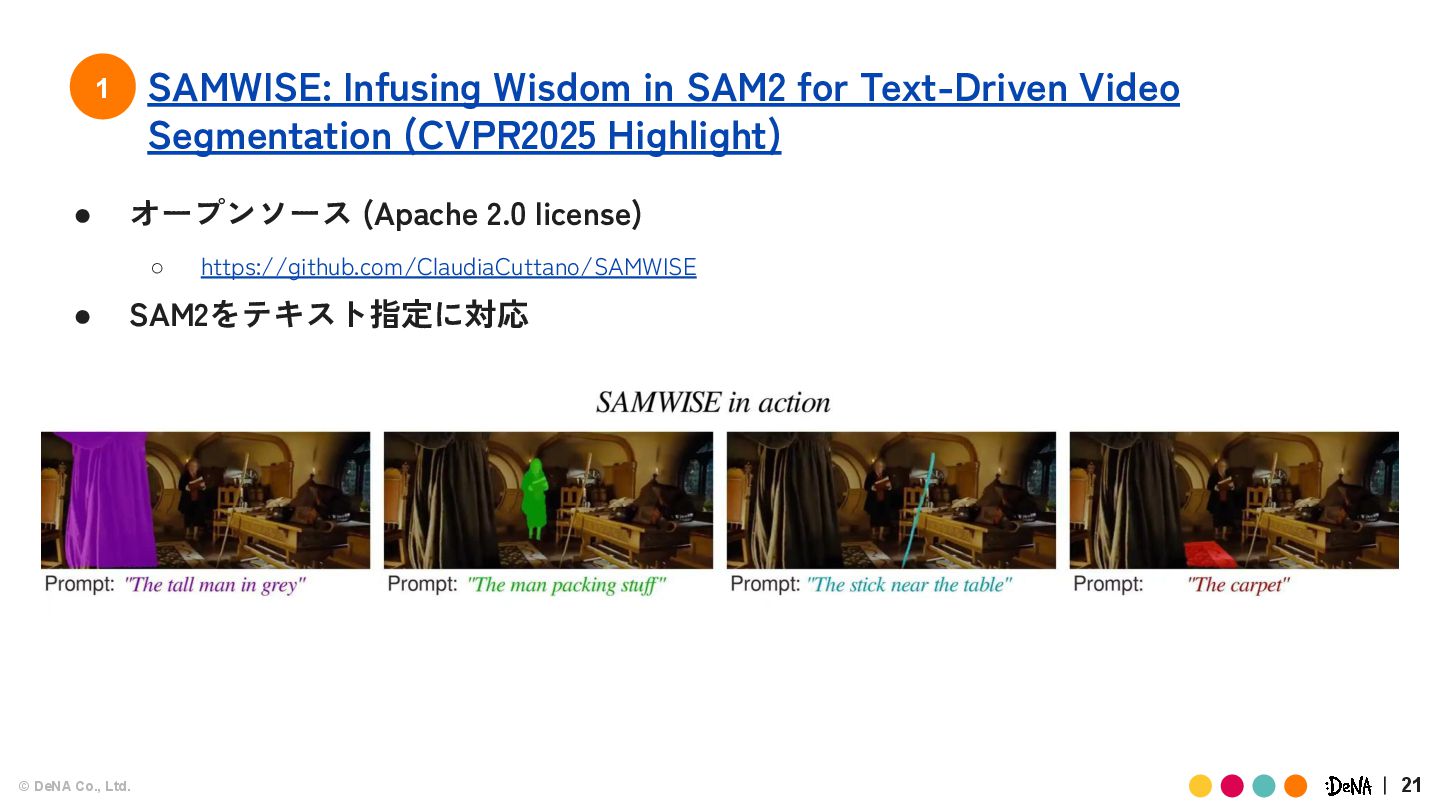{kind=link}
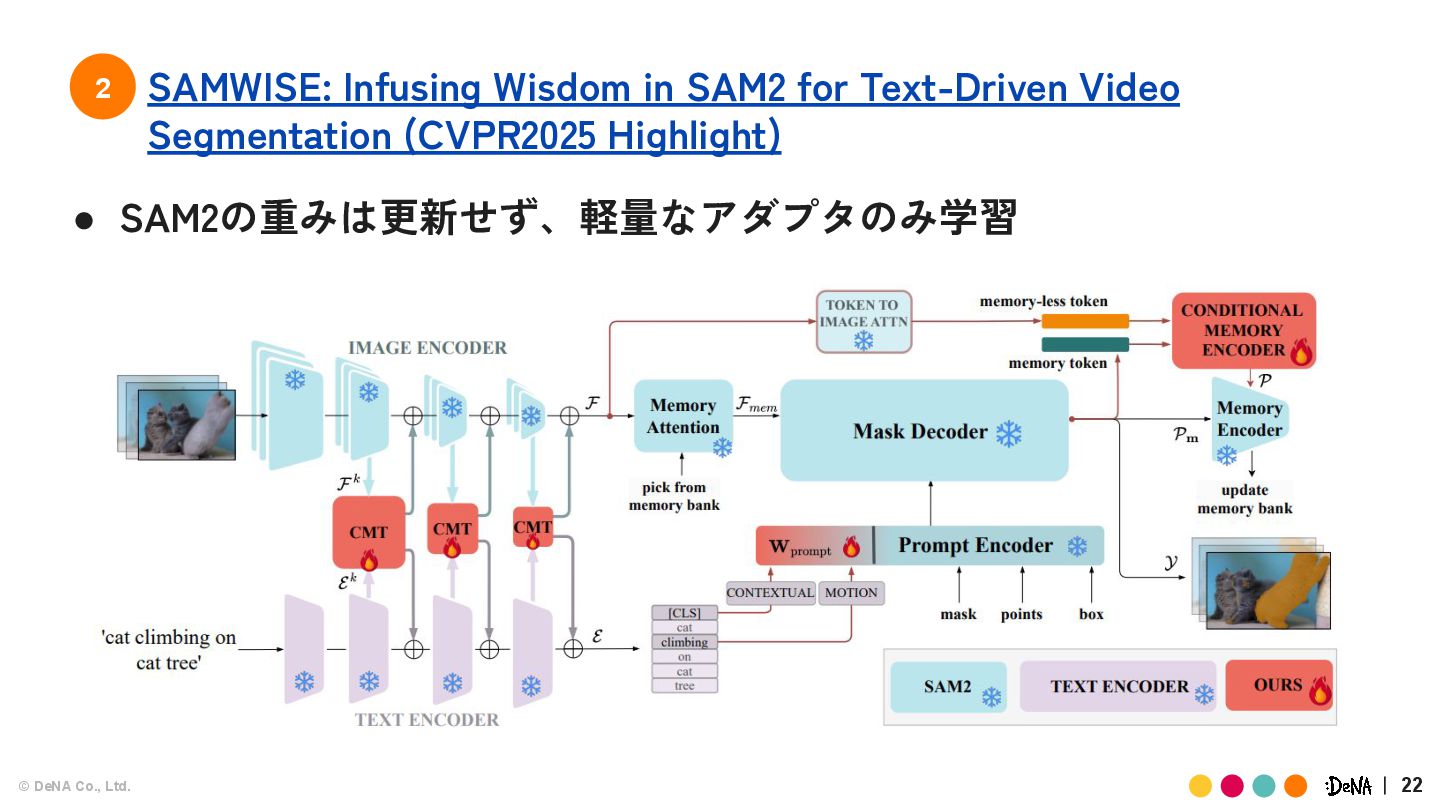{kind=link}
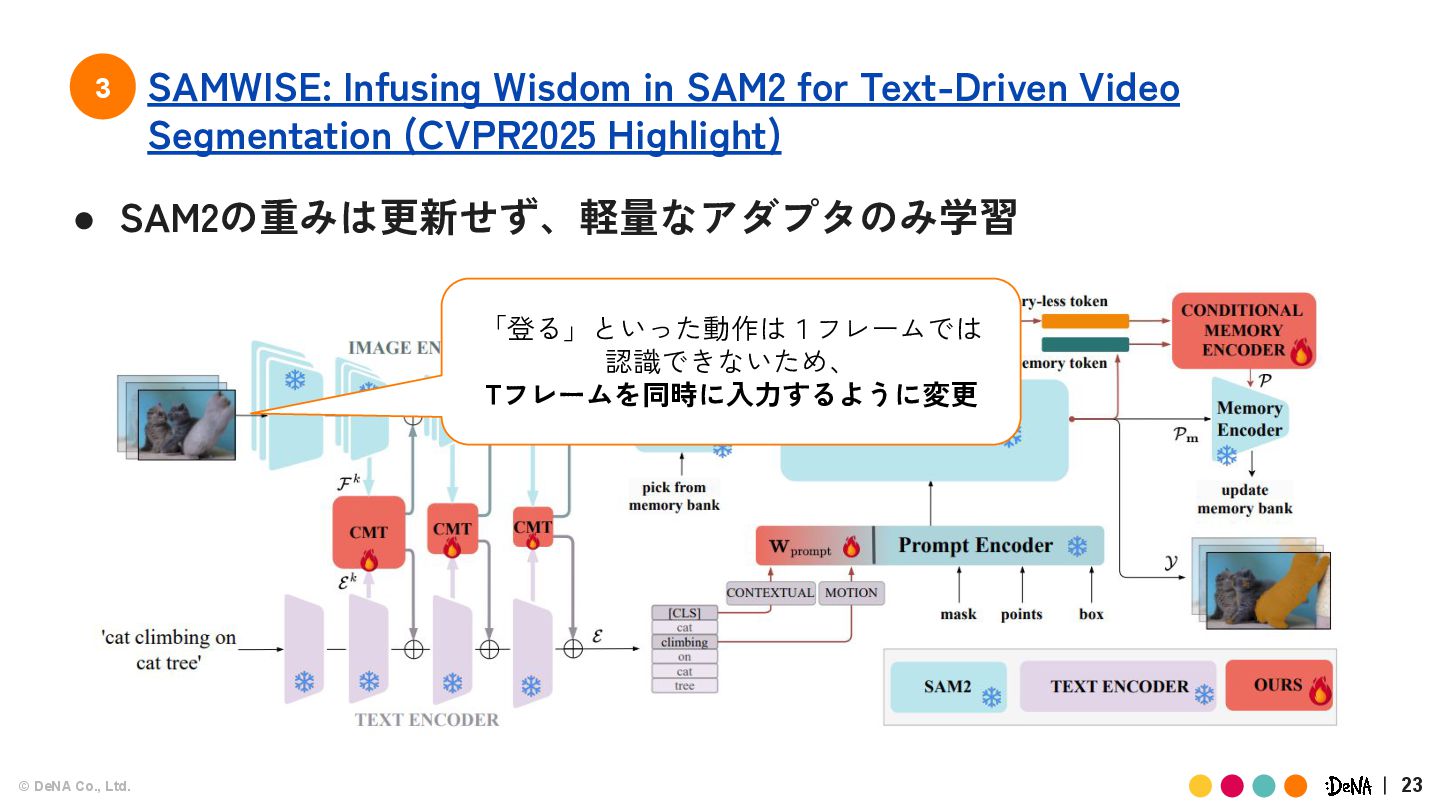{kind=link}
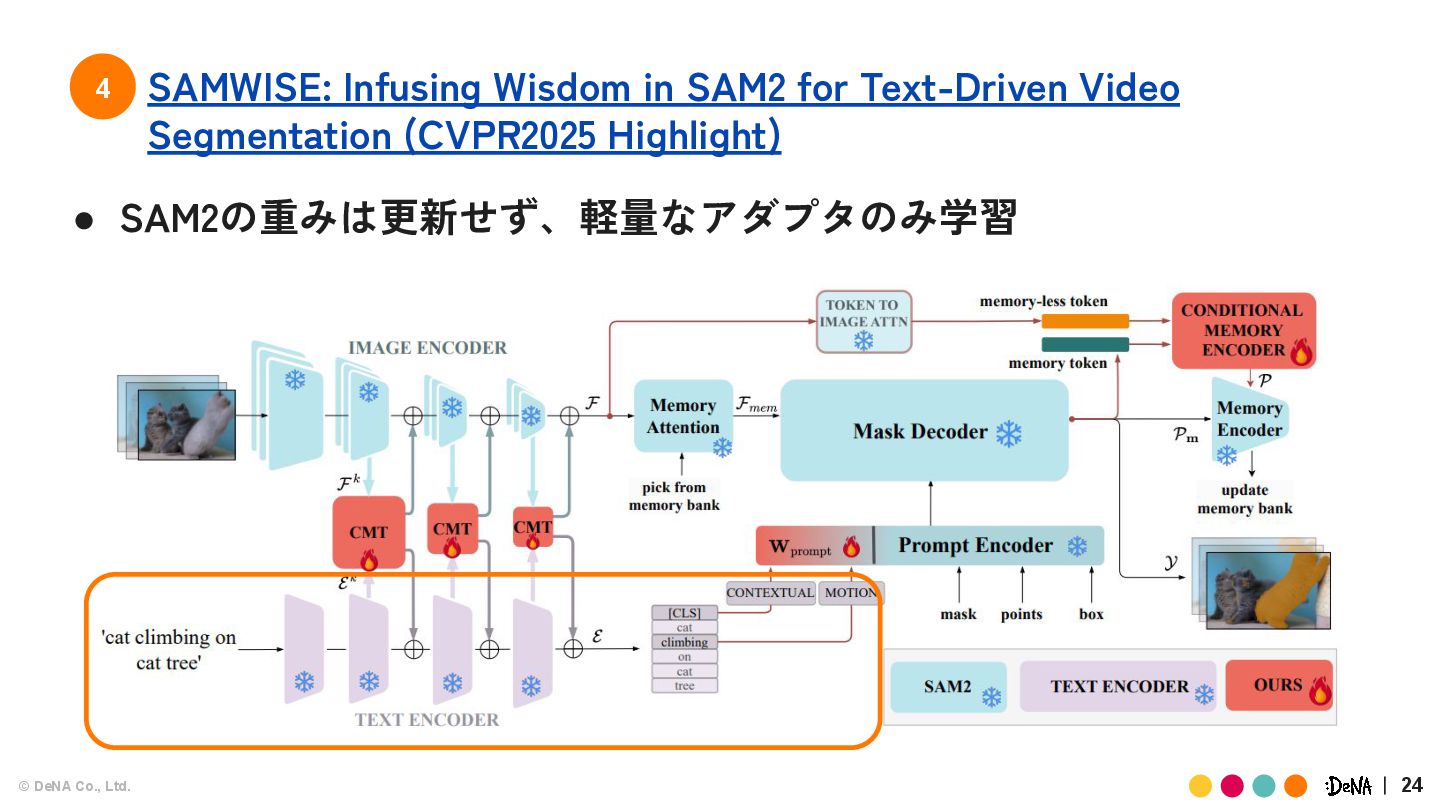{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}