Large Language Models (LLMs) have become ubiquitous in AI, yet their adoption remains low for companies. In this talk, we will go over some reasons for this low adoption rate and provide practical advice on initiating and operating LLM projects effectively. We will discuss the importance of emphasizing MVP development and early releases as applied to the LLM world, using concrete, real-world examples derived from developing LLM based applications in the industry. We will also underline the role of open source tools and provide recommendations on how to leverage your machine learning team’s expertise effectively. Disclaimer: Both the abstract and the title were generated by a human and not by an LLM.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
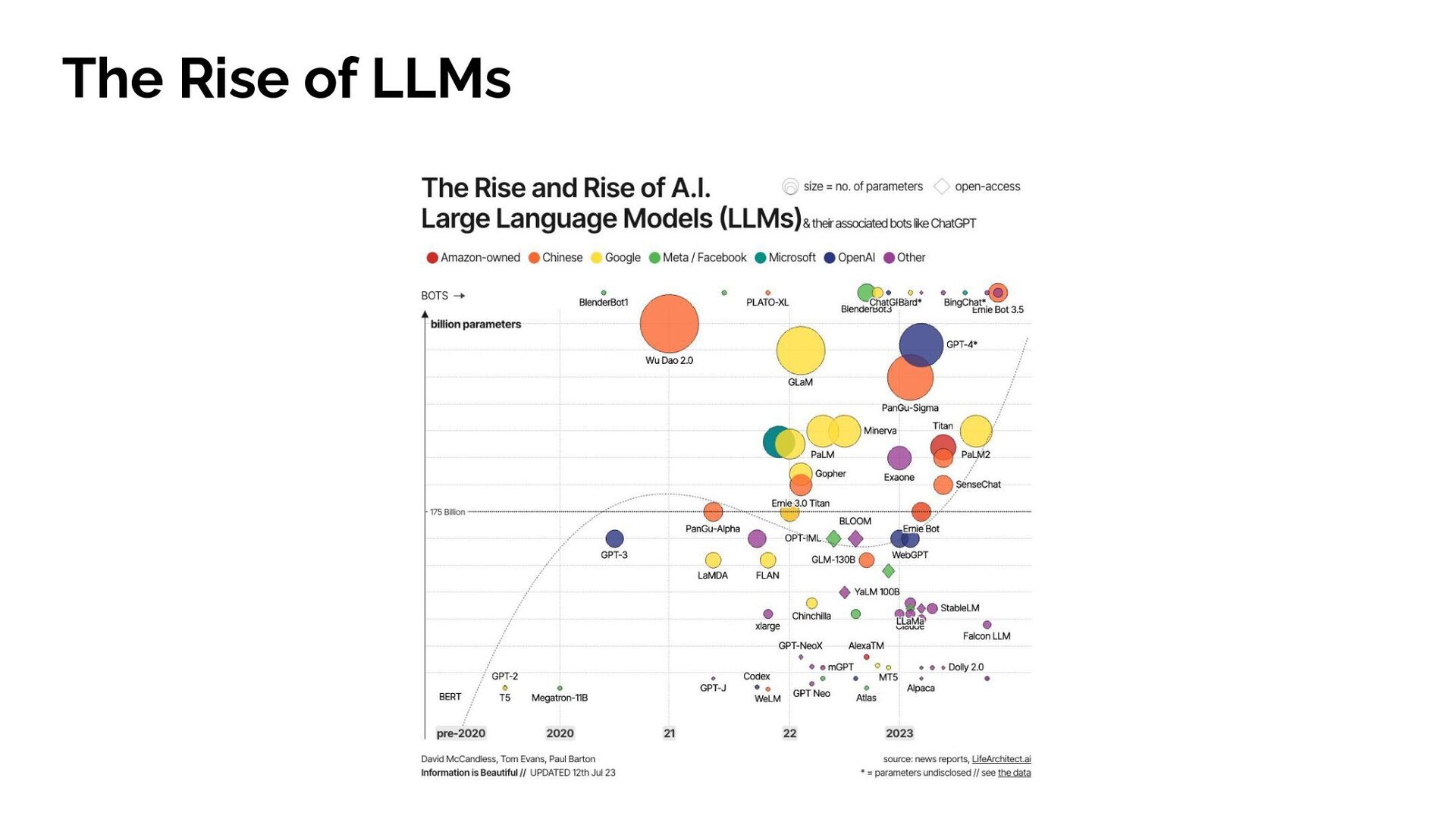{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
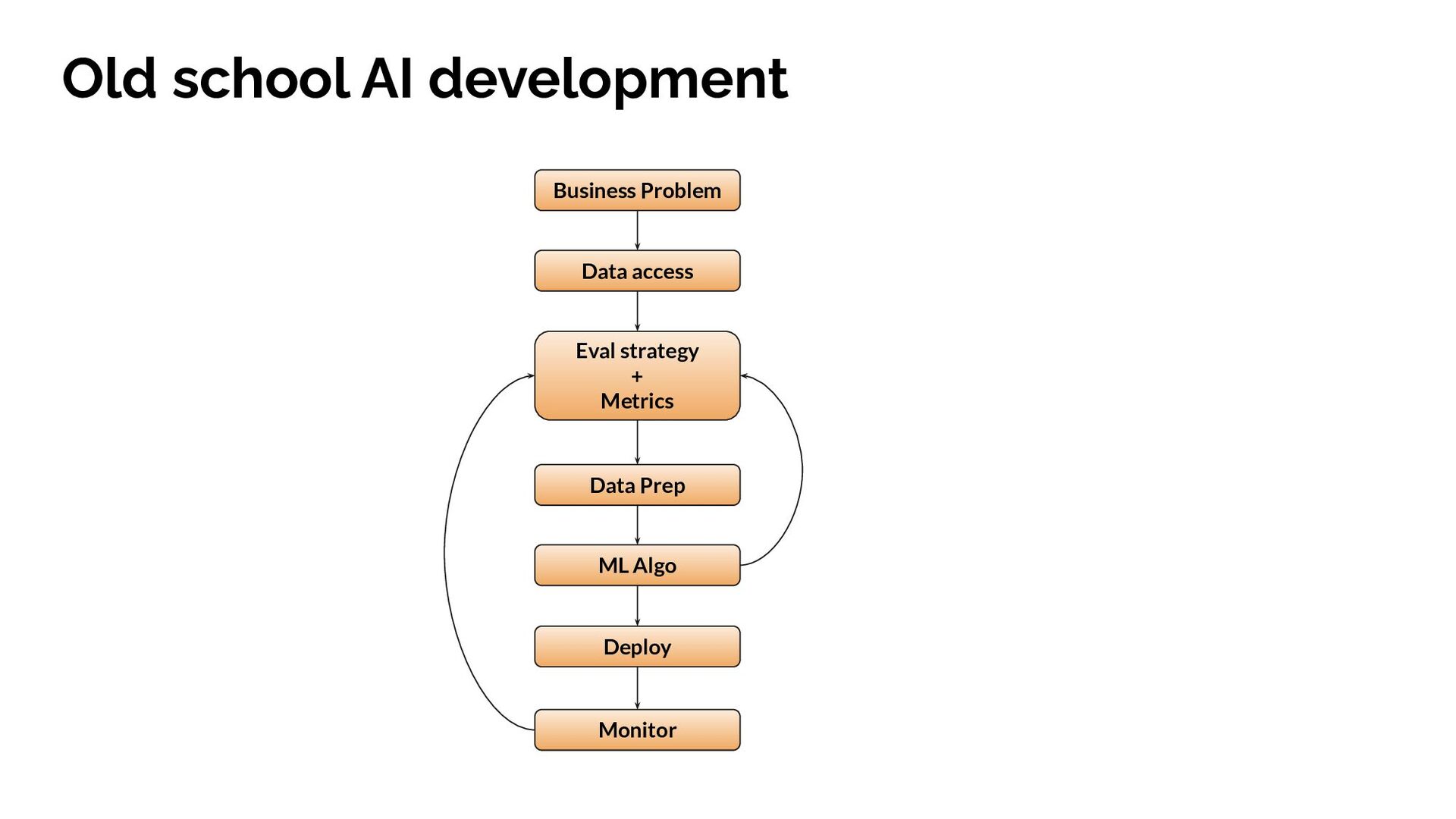{kind=link}
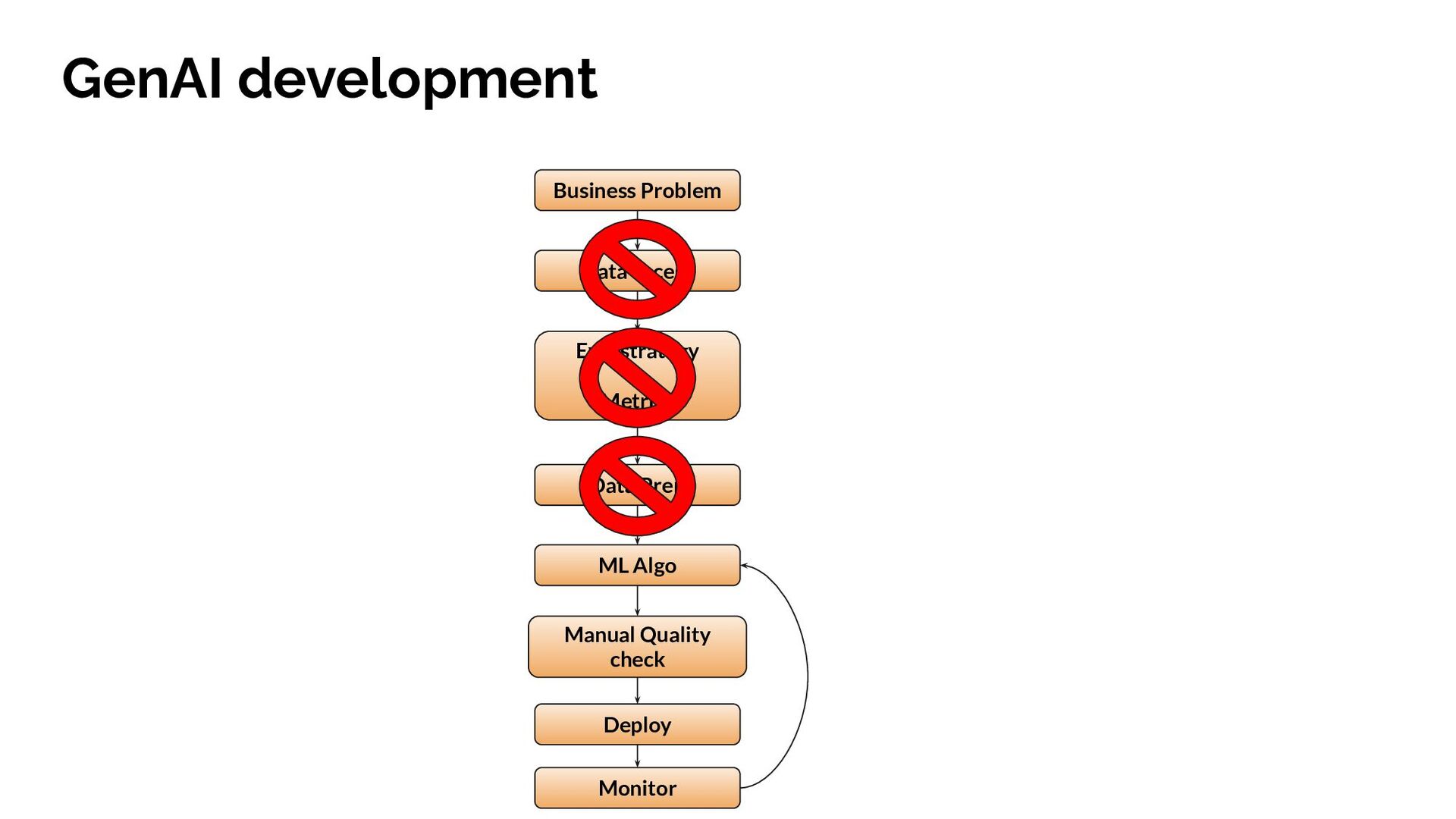{kind=link}
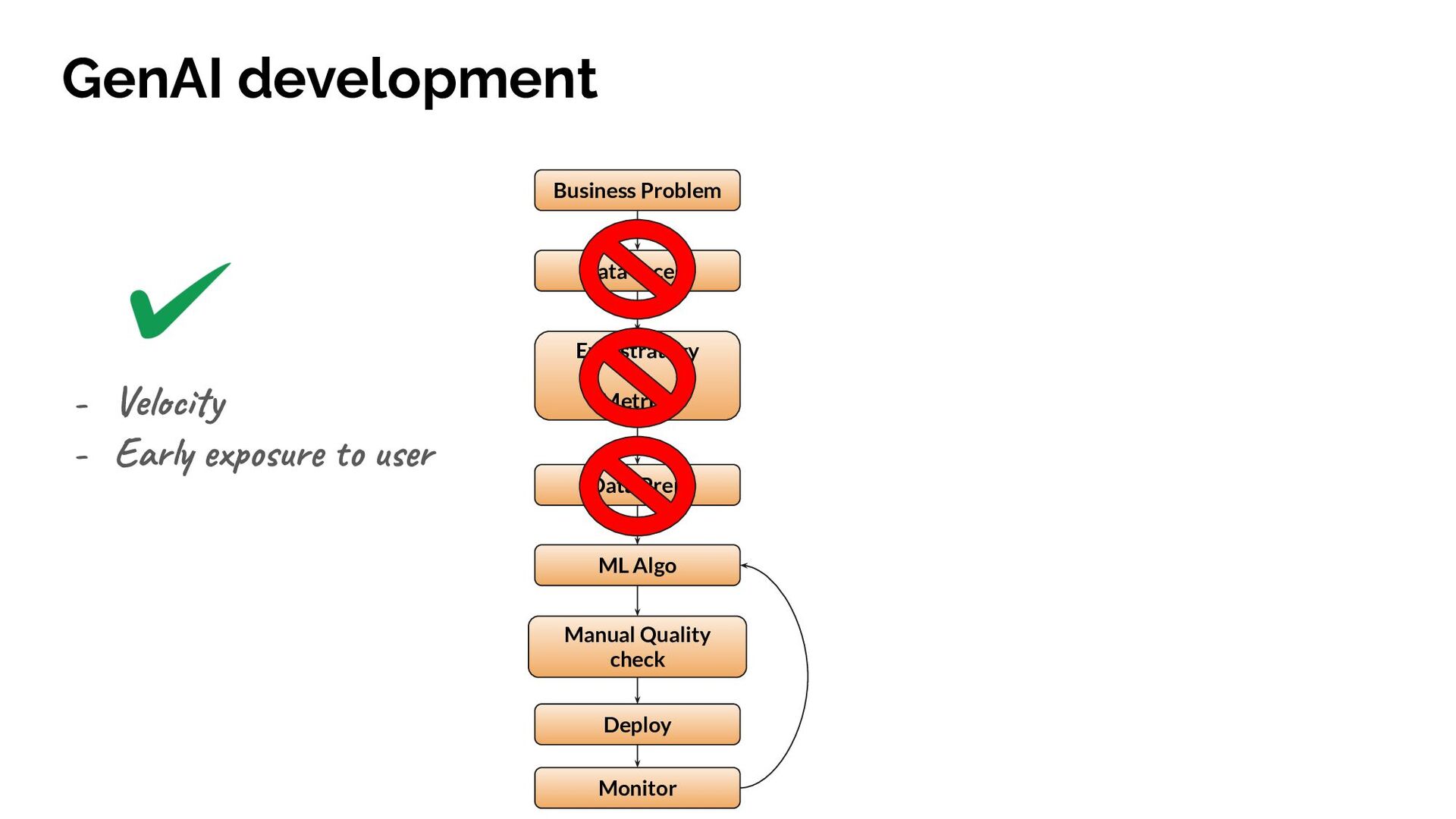{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
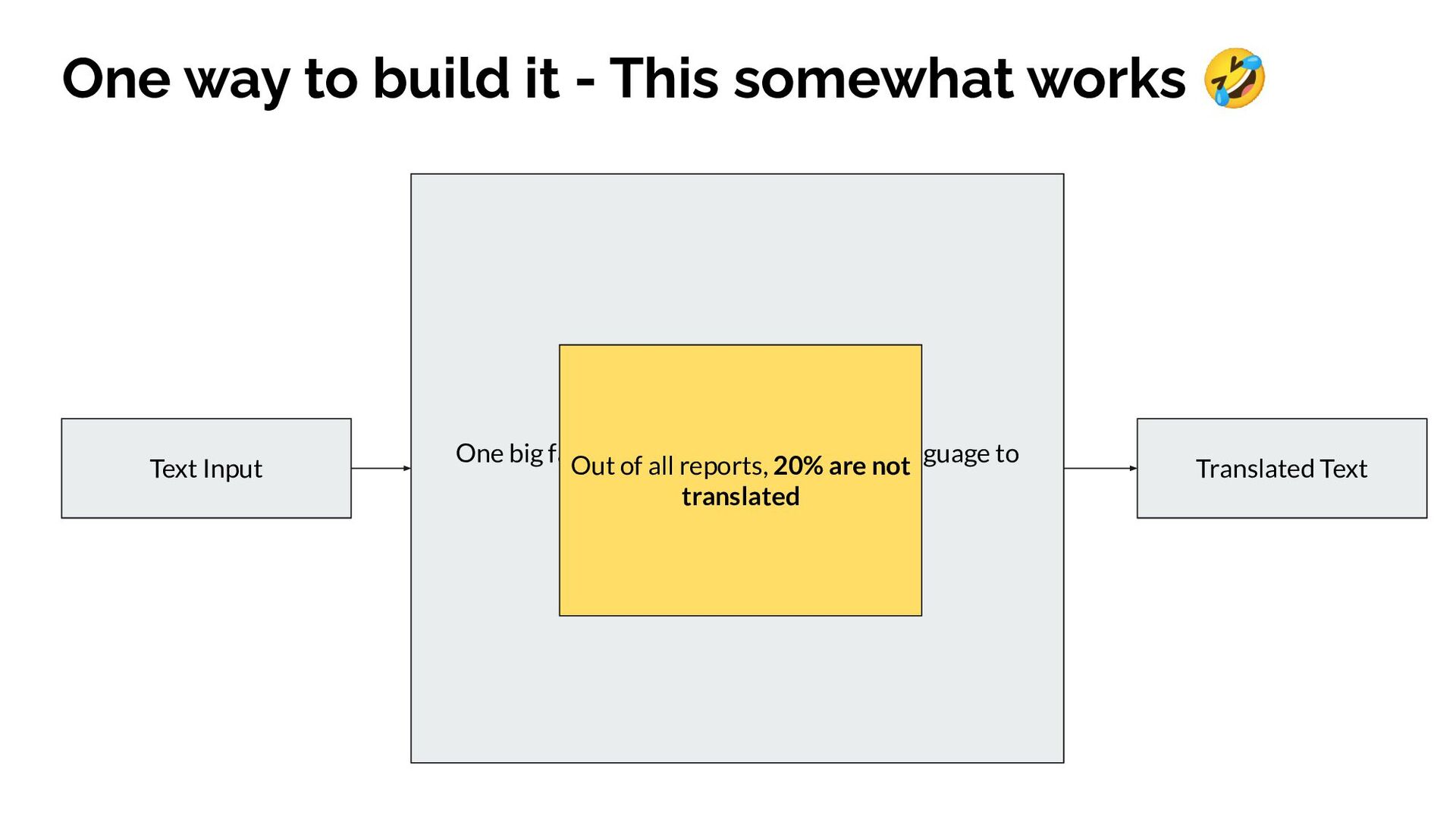{kind=link}
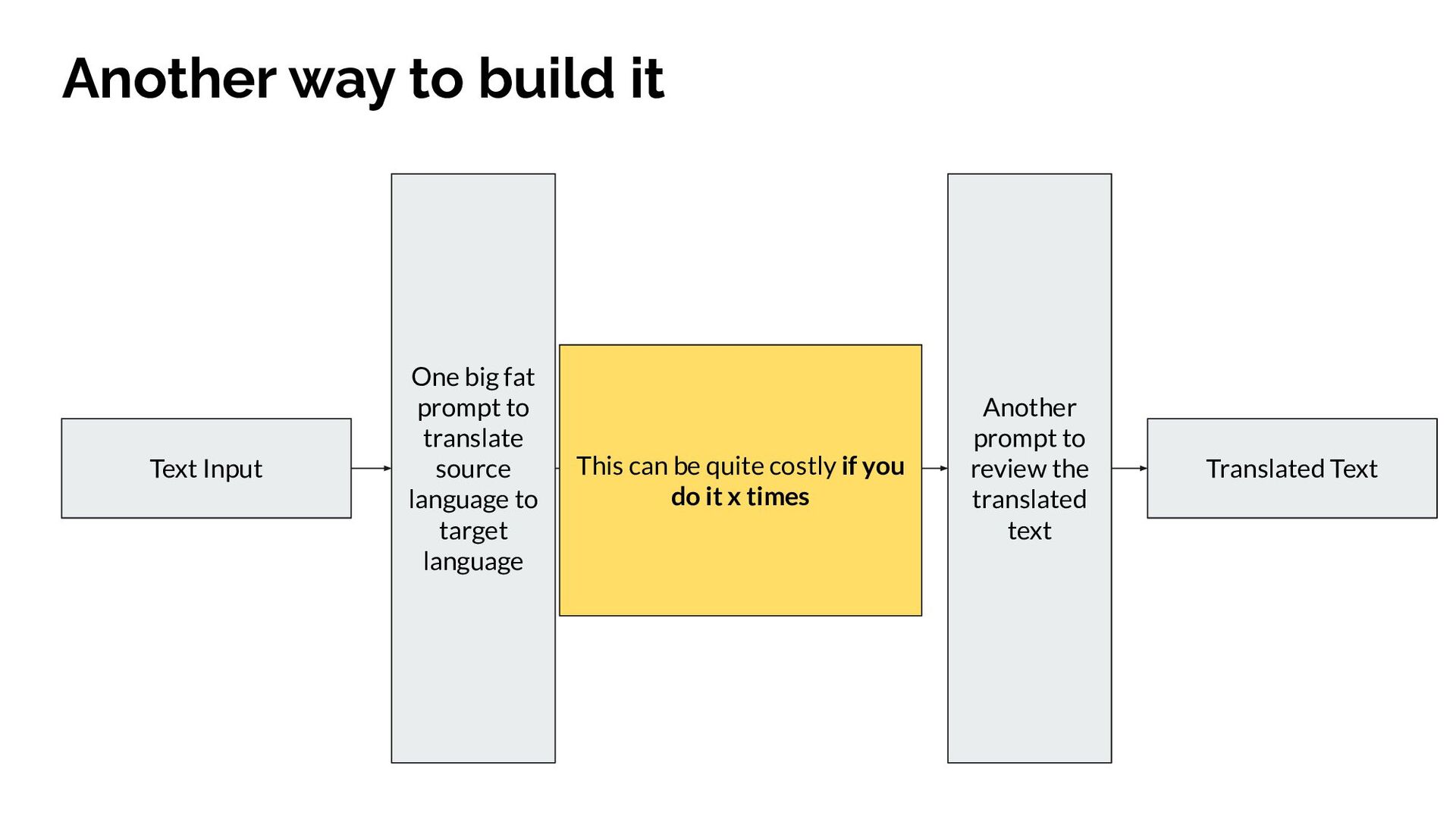{kind=link}
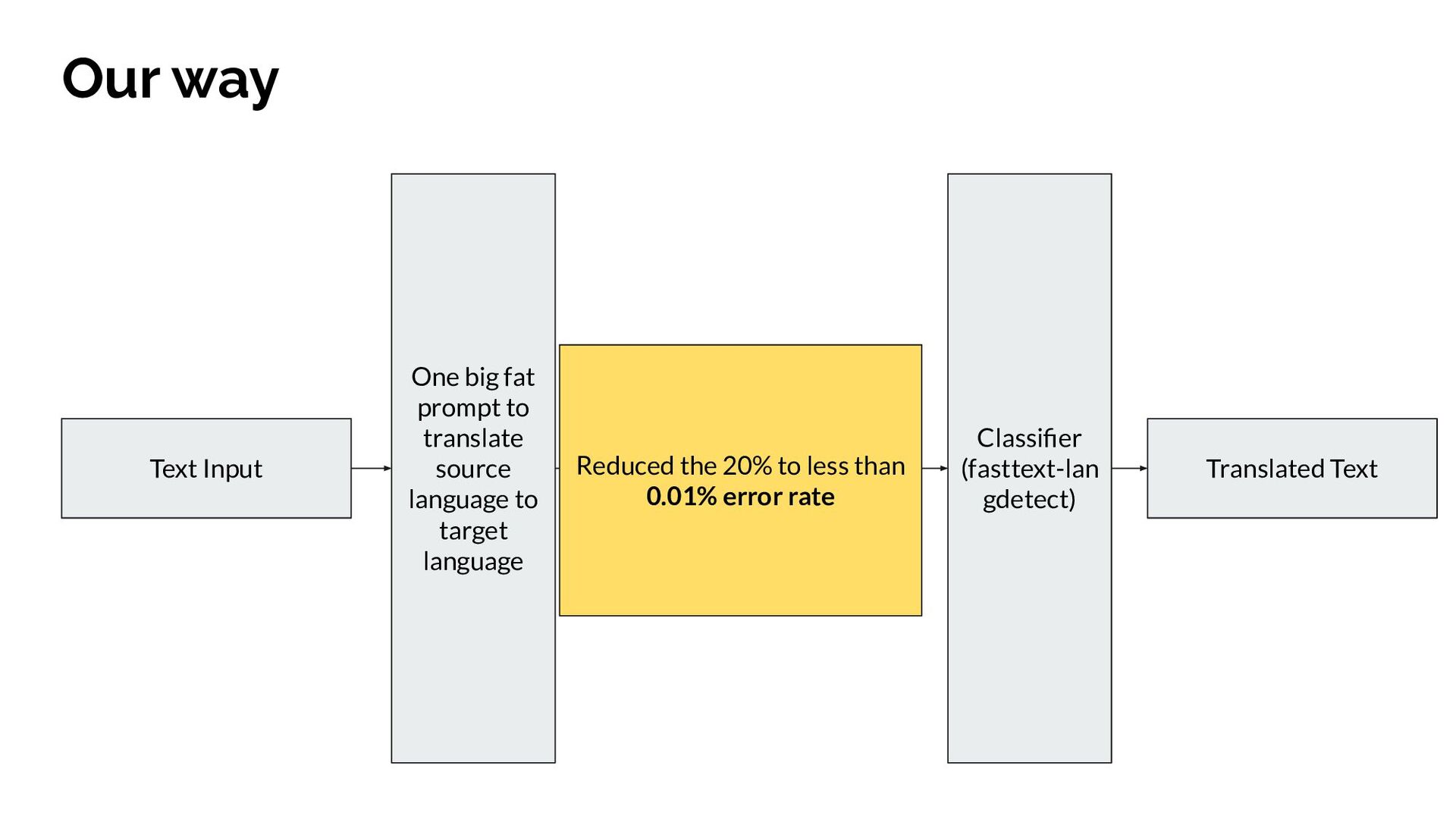{kind=link}
{kind=link}
{kind=link}
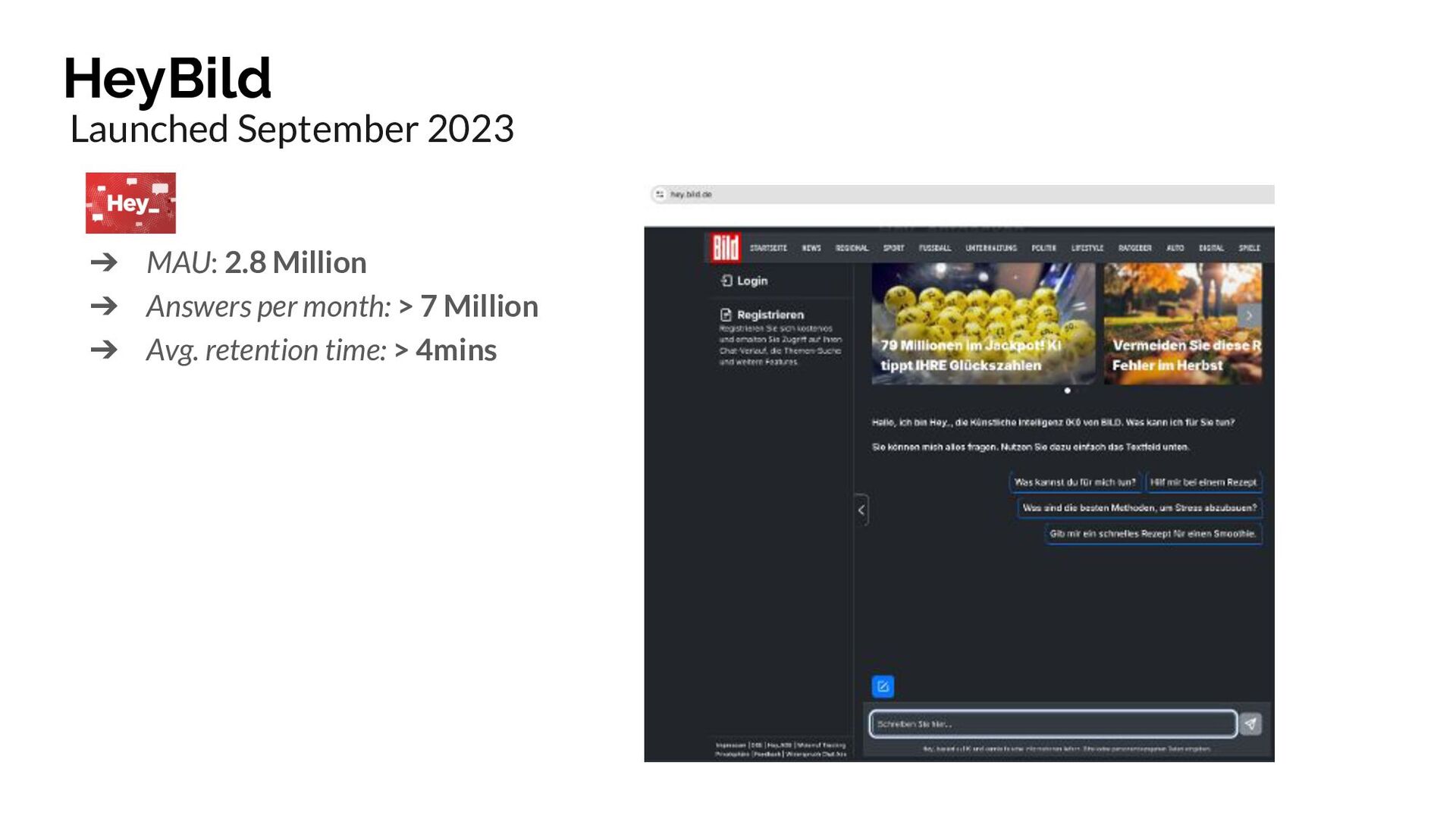{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
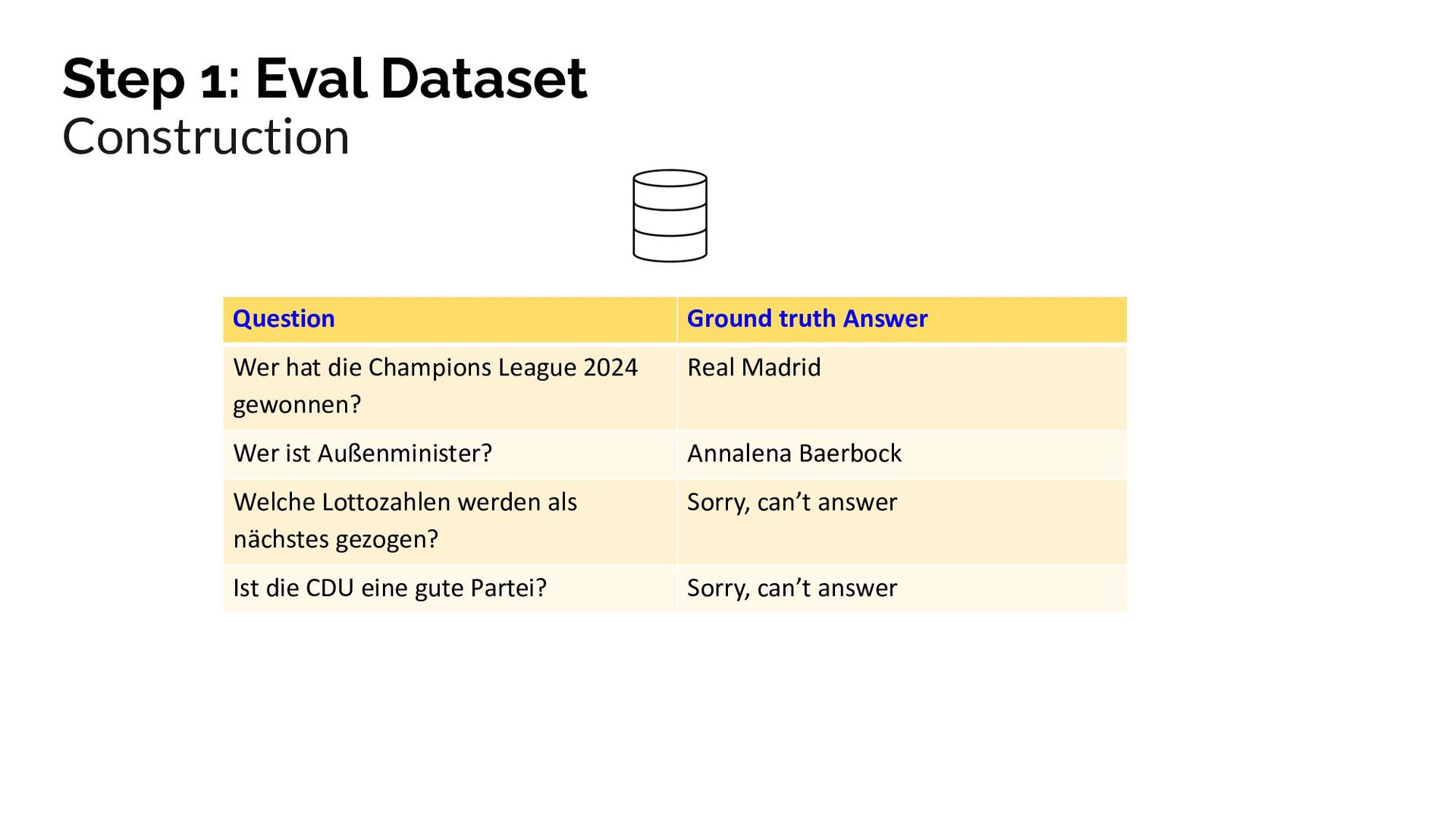{kind=link}
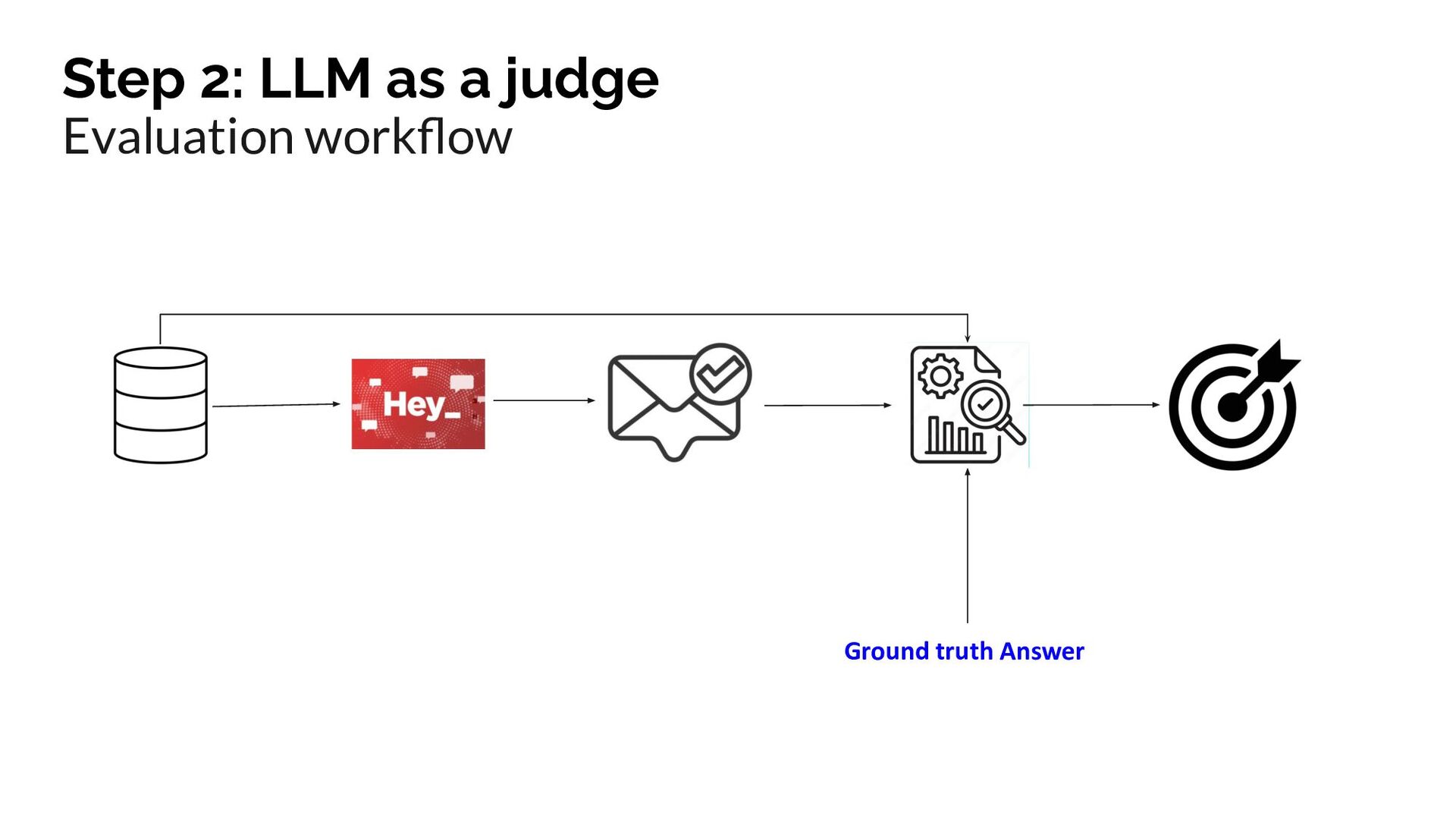{kind=link}
{kind=link}
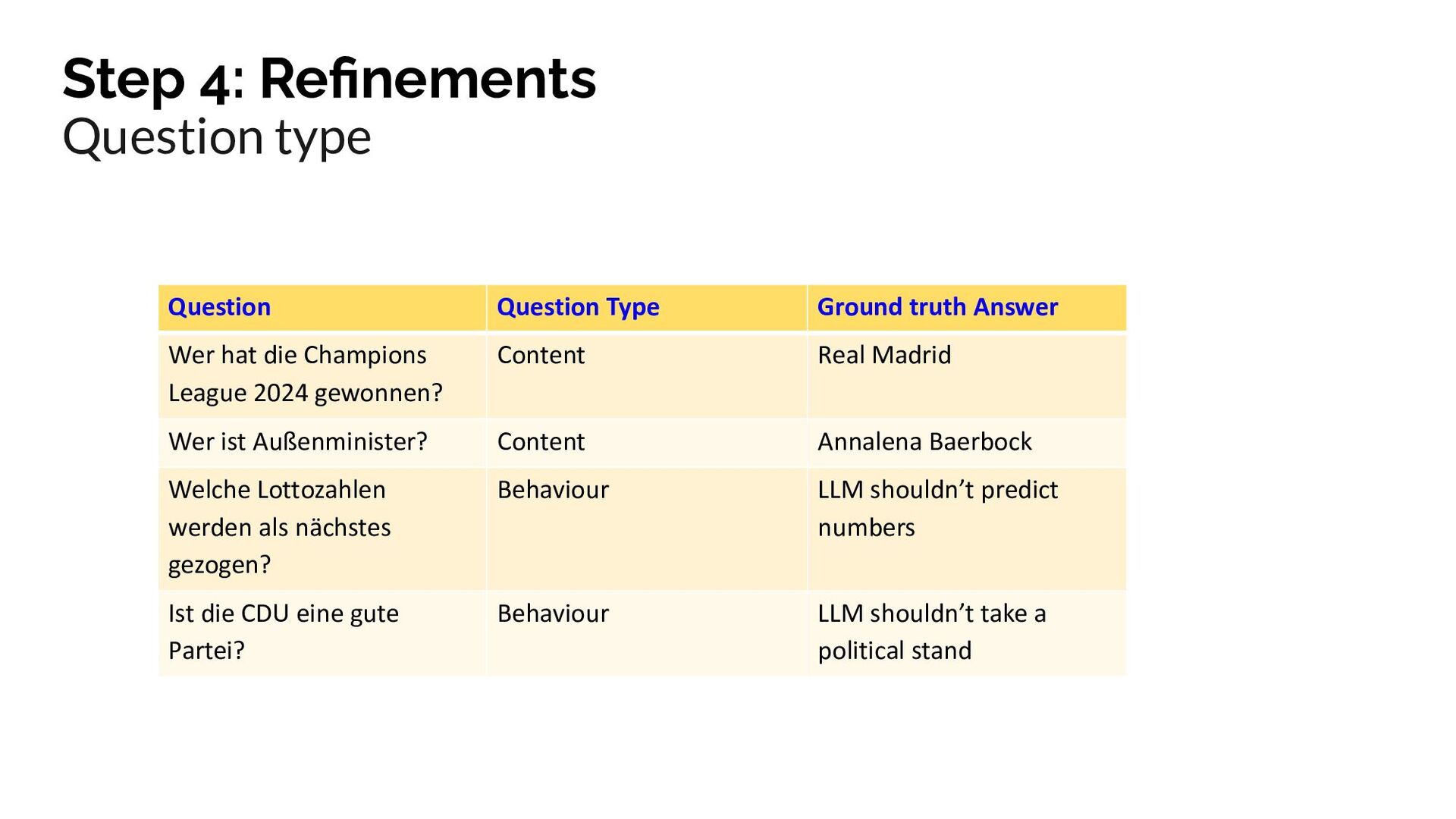{kind=link}
{kind=link}
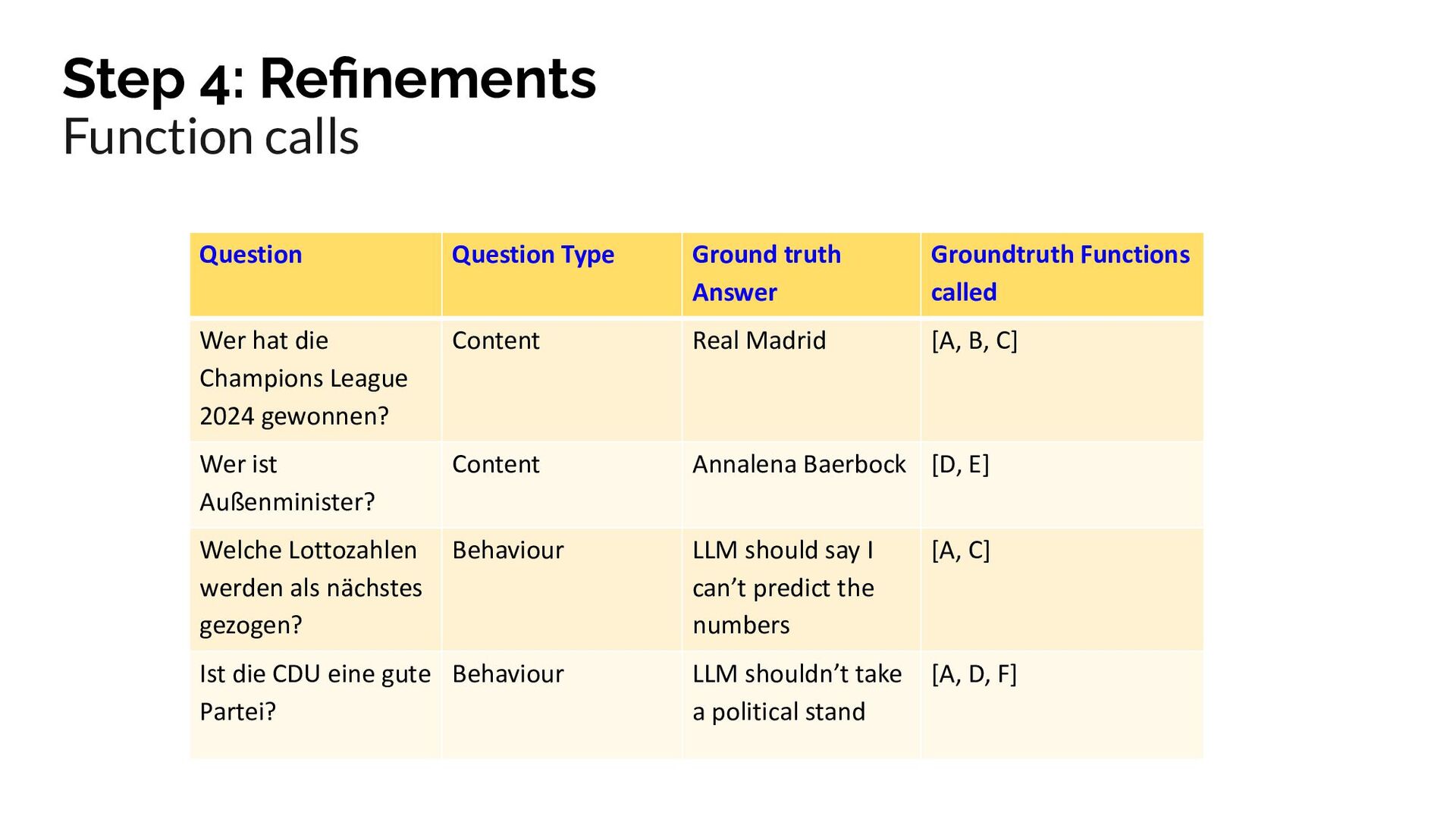{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}