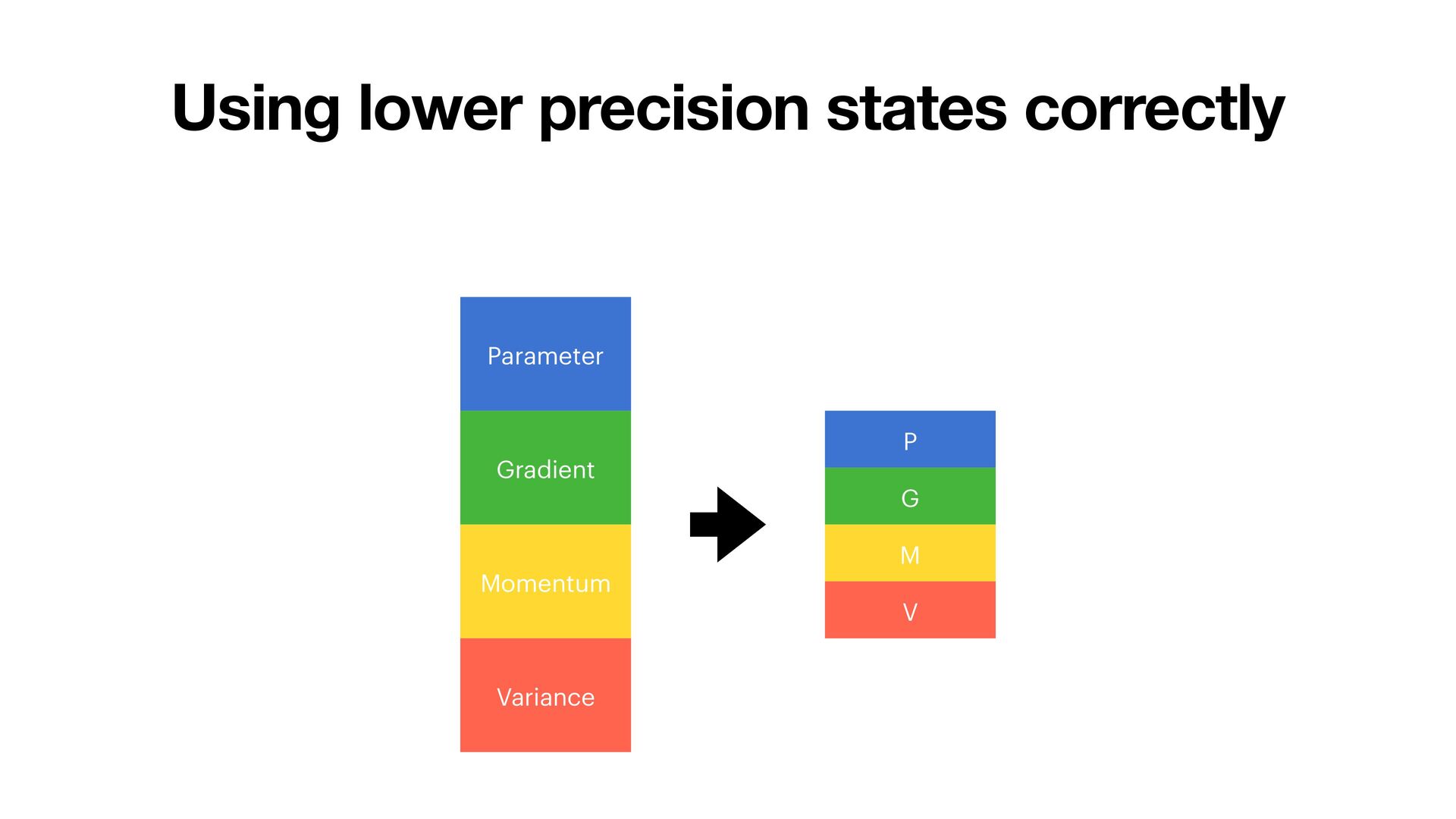
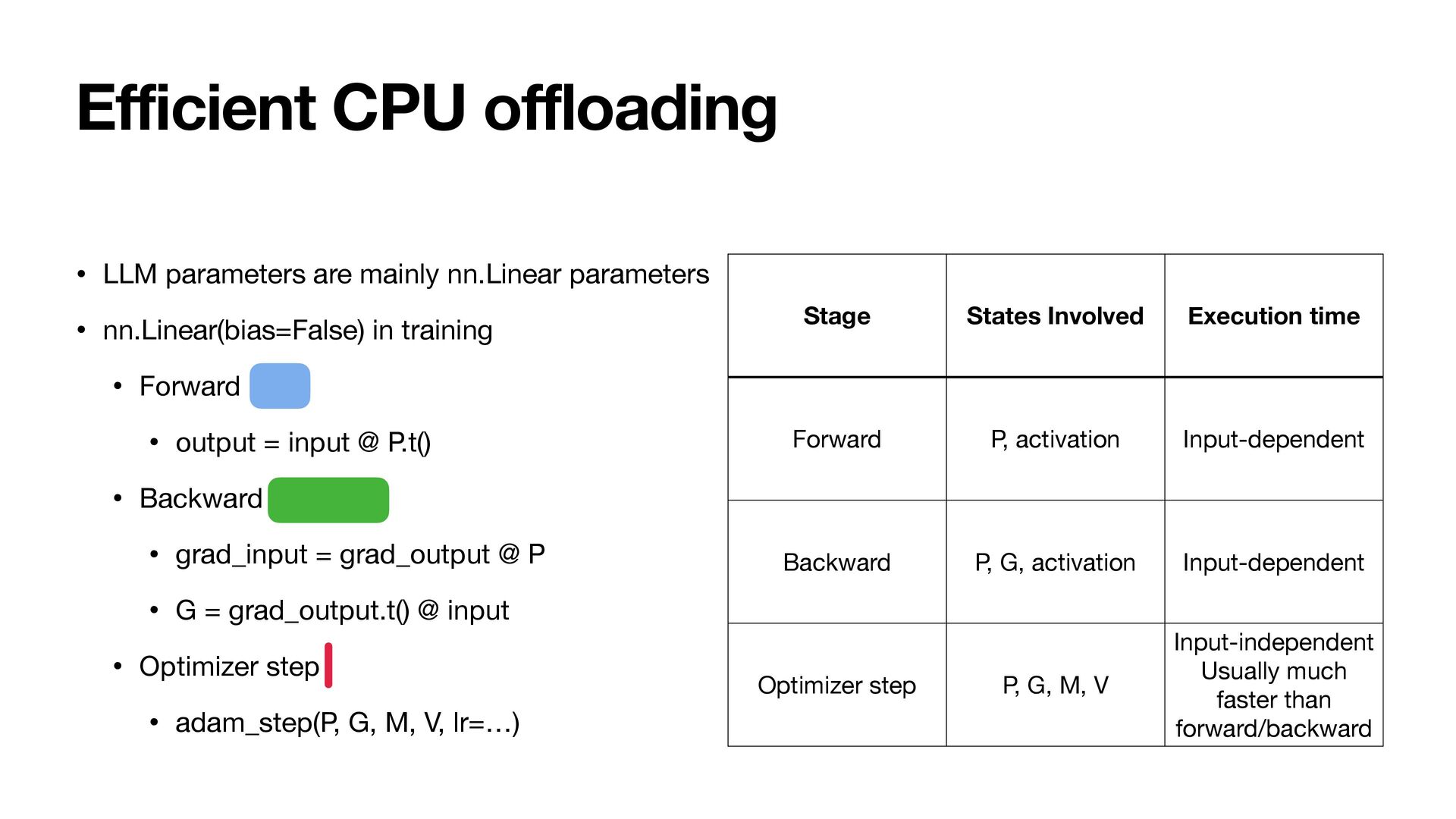
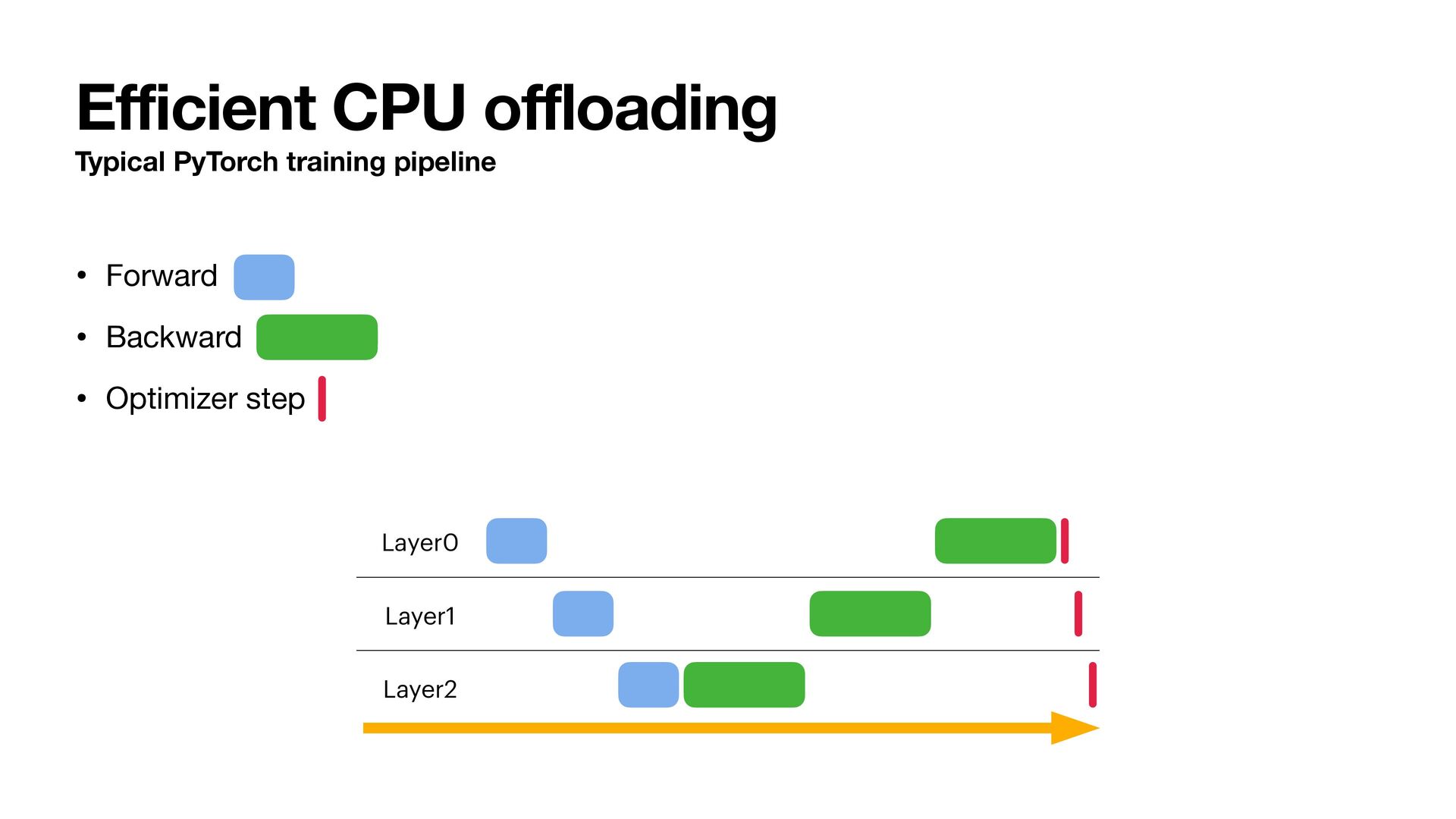
could: • Train 7B models on single RTX 4090 (24GB) • 14B on 48G GPUs • 32B on 80G/96G GPUs • With full quality • Full-parameter training, no compromise (LoRA, QLoRA, etc.) • Standard Adam • How? Two key techniques: 1. Using lower precision states (50% reduction) 2. E ffi cient CPU o ff l oading (75% reduction)
bytes • Gradient: 4 bytes • Momentum: 4 bytes • Variance: 4 bytes • For a 7B model: . • Does not fi t in single A100 80G • amp.autocast(cache_enabled=False) does not help • FP32 (M, V) + FP16 (P, G) + FP32 (master P) -> 16 bytes/param • Our approach: 1. Using lower precision (BFloat16) correctly -> 8 bytes/param 2. O ffl oading states to CPU e ffi ciently -> 2 bytes/param 7 × 16 = 112GB
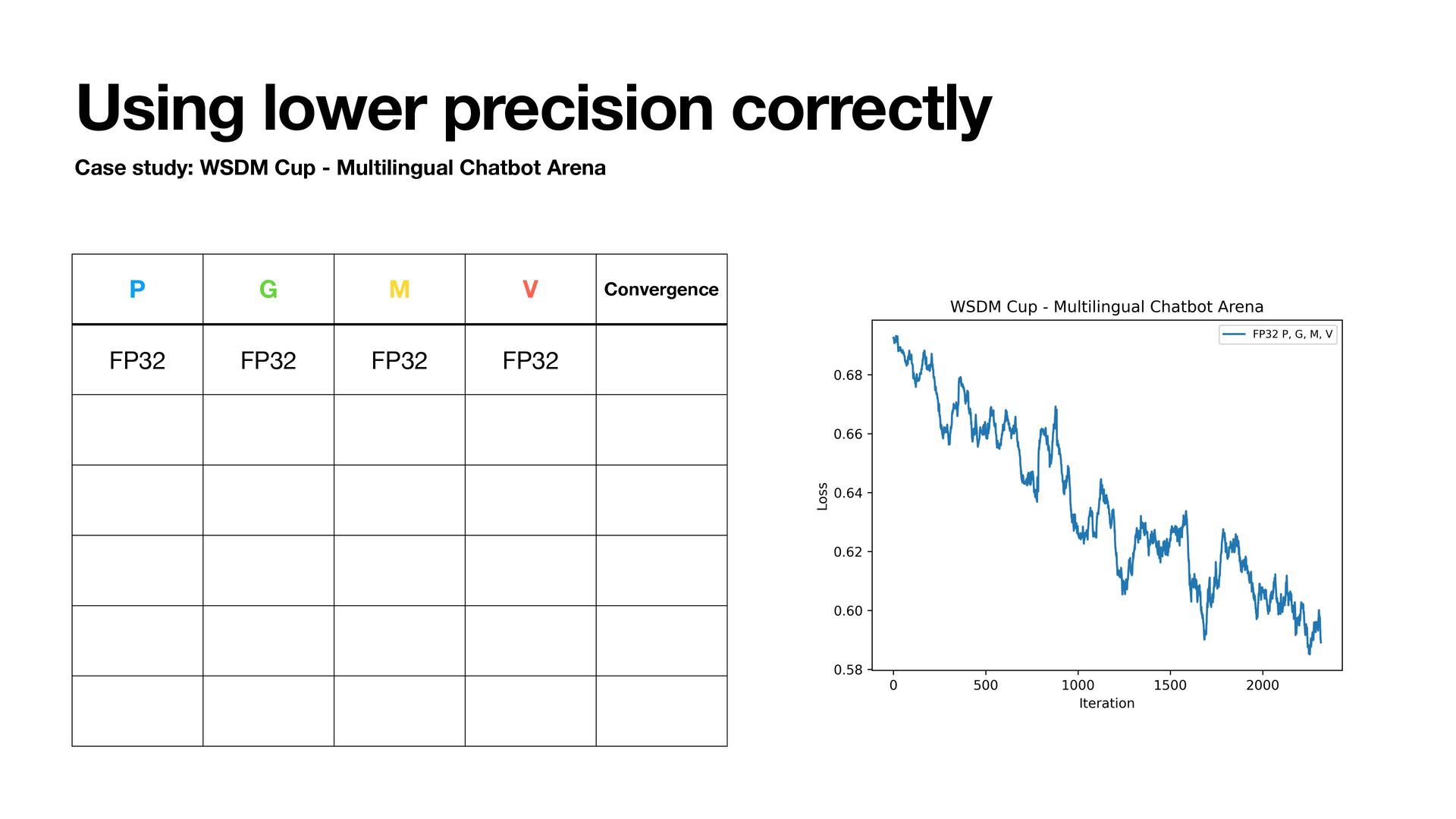
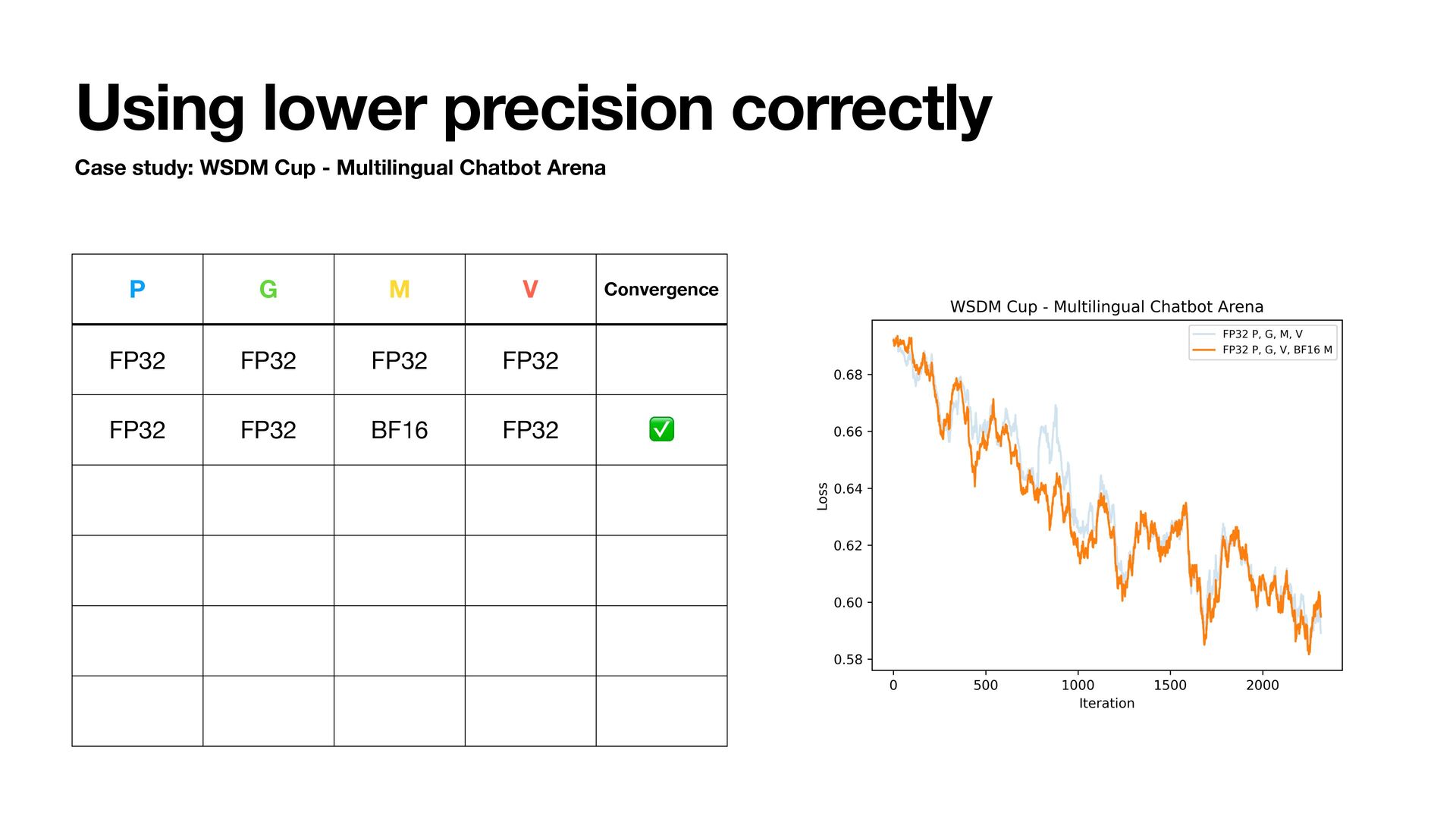
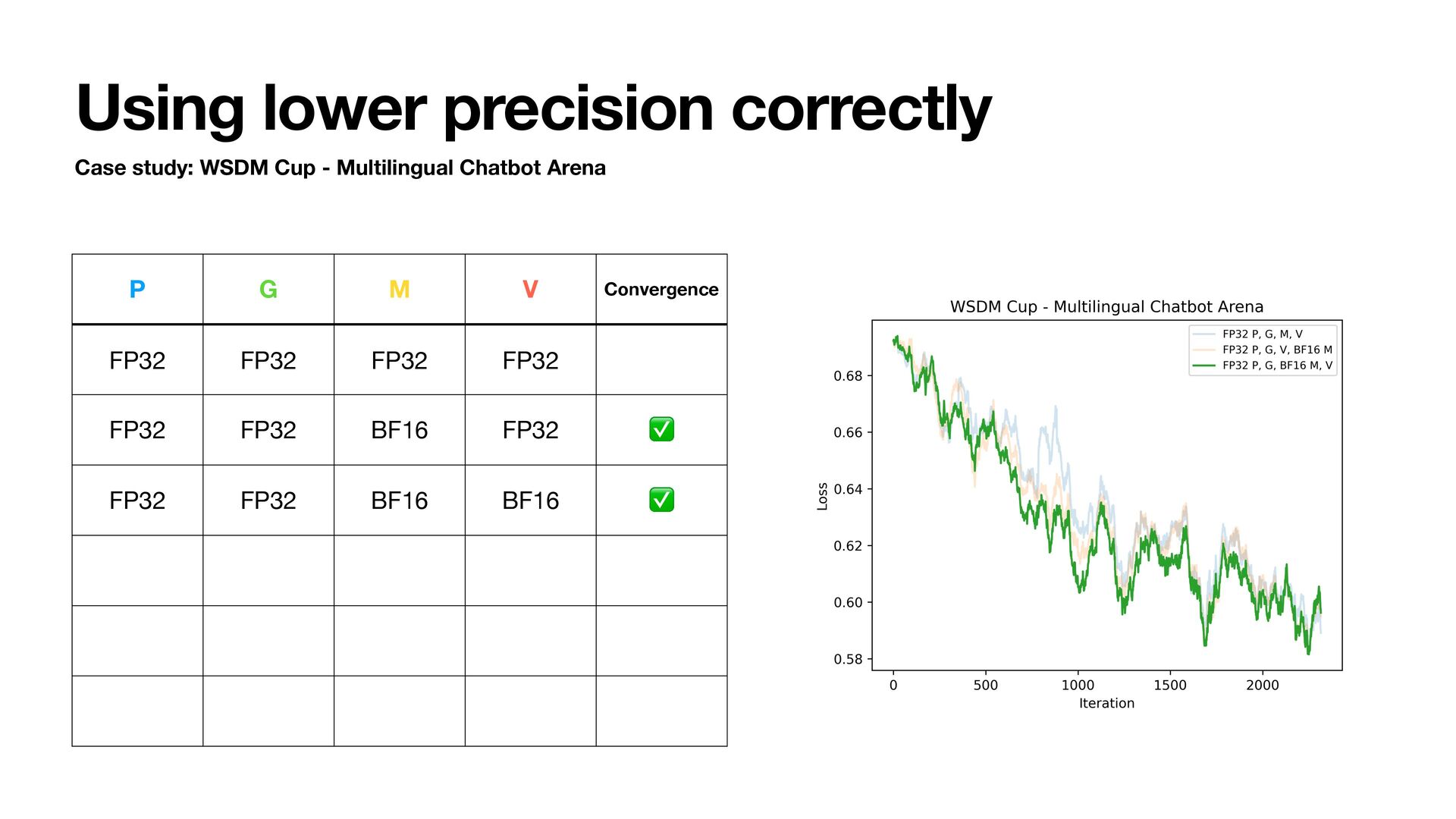
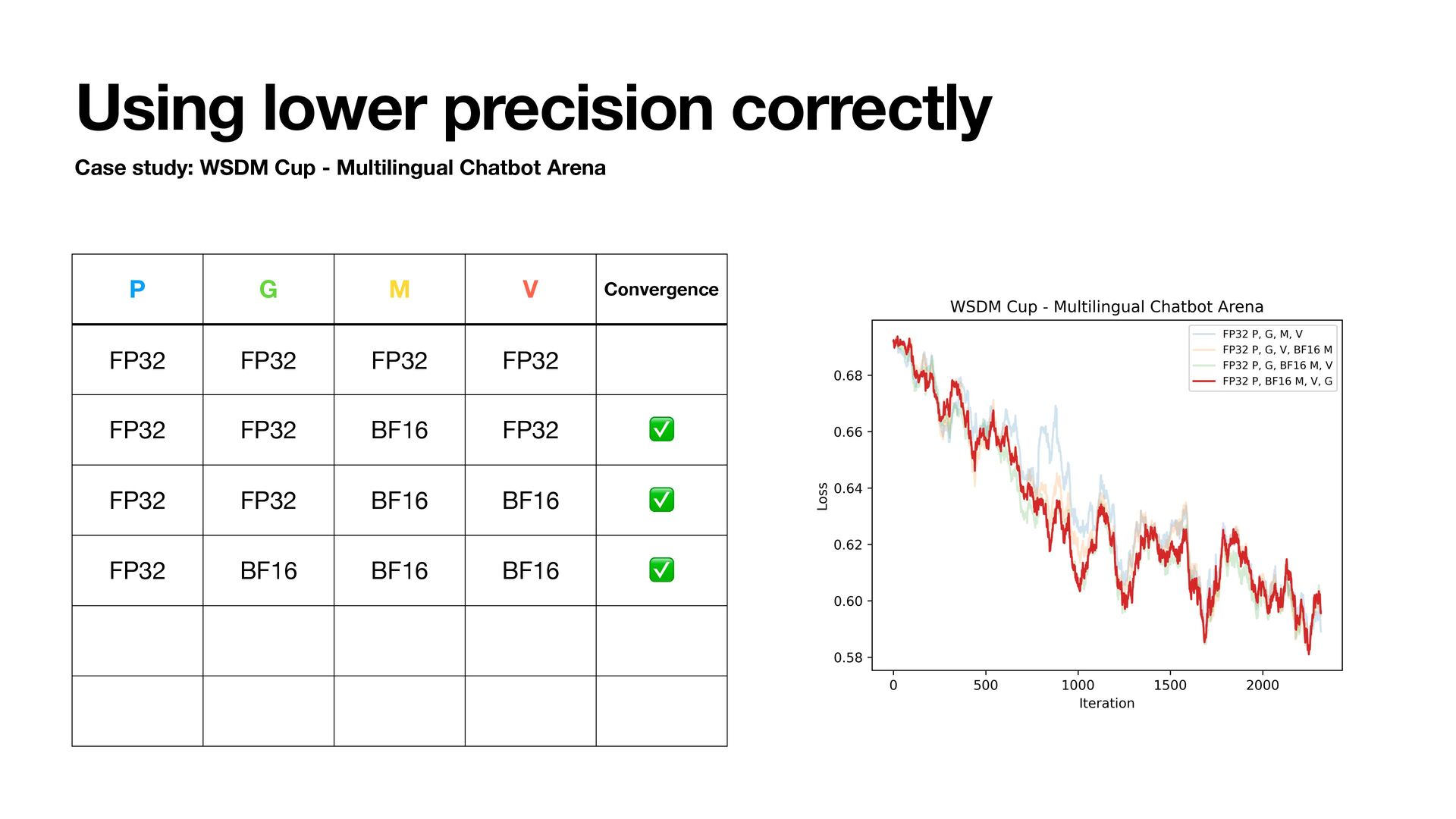
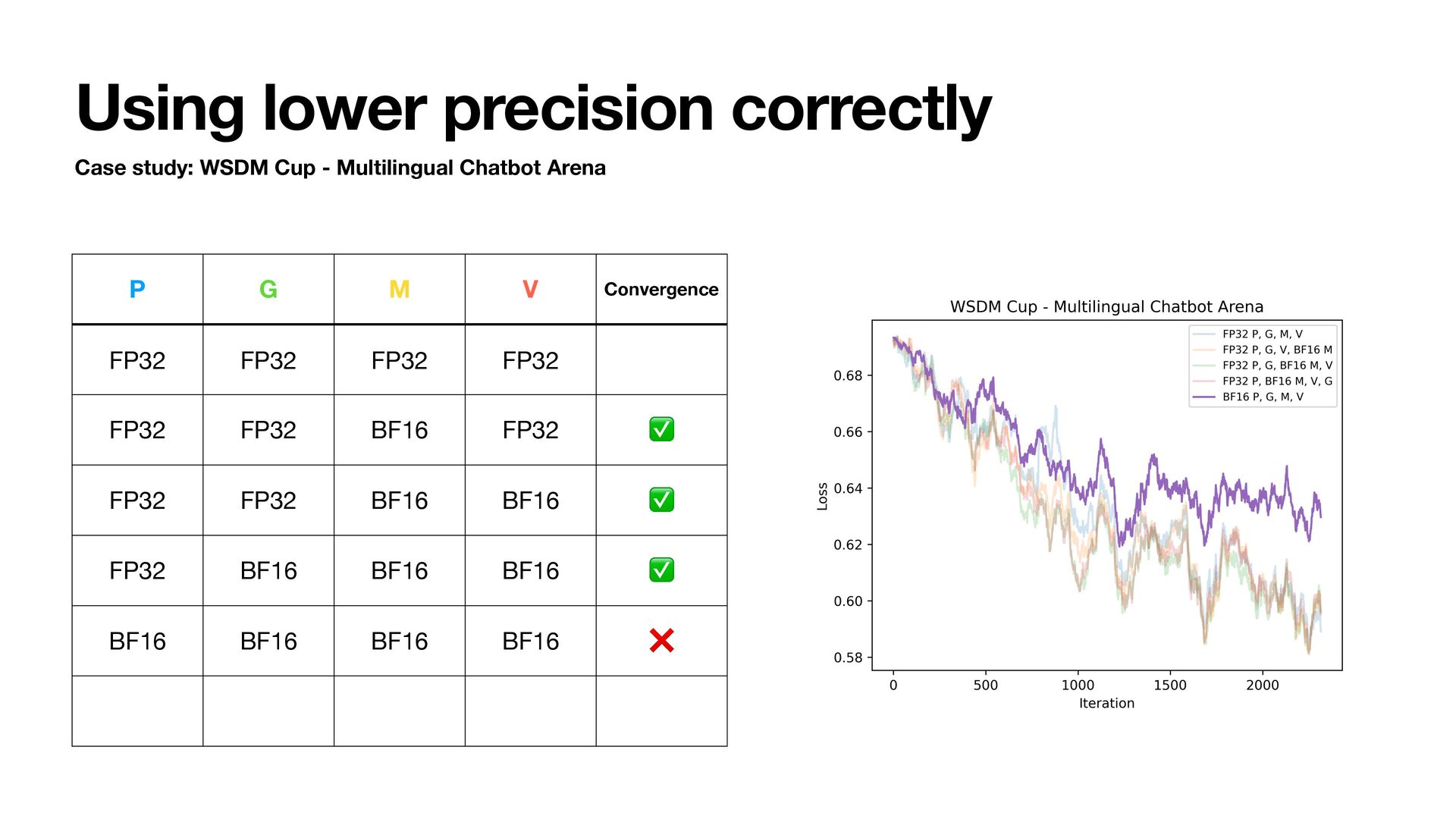
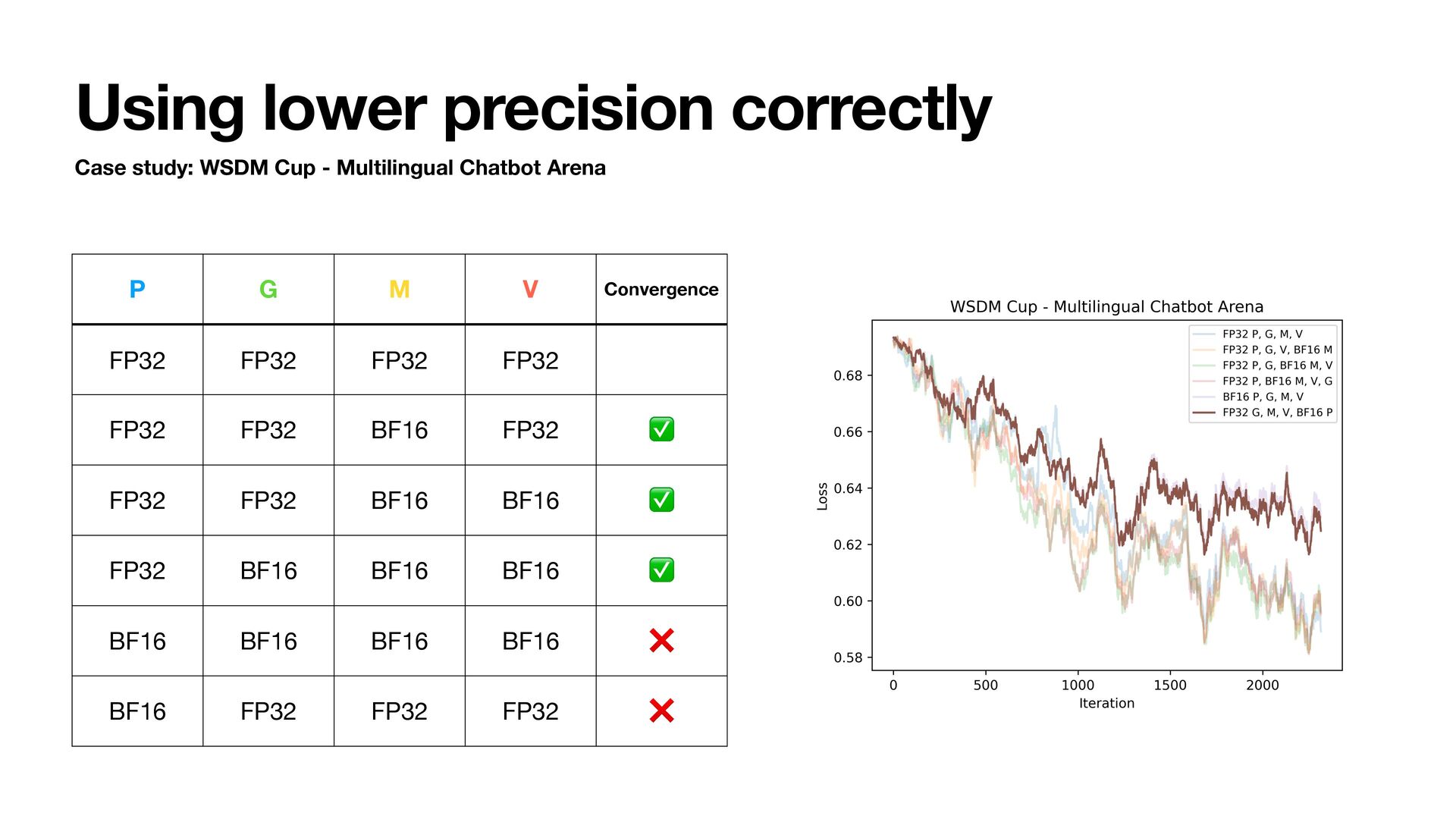
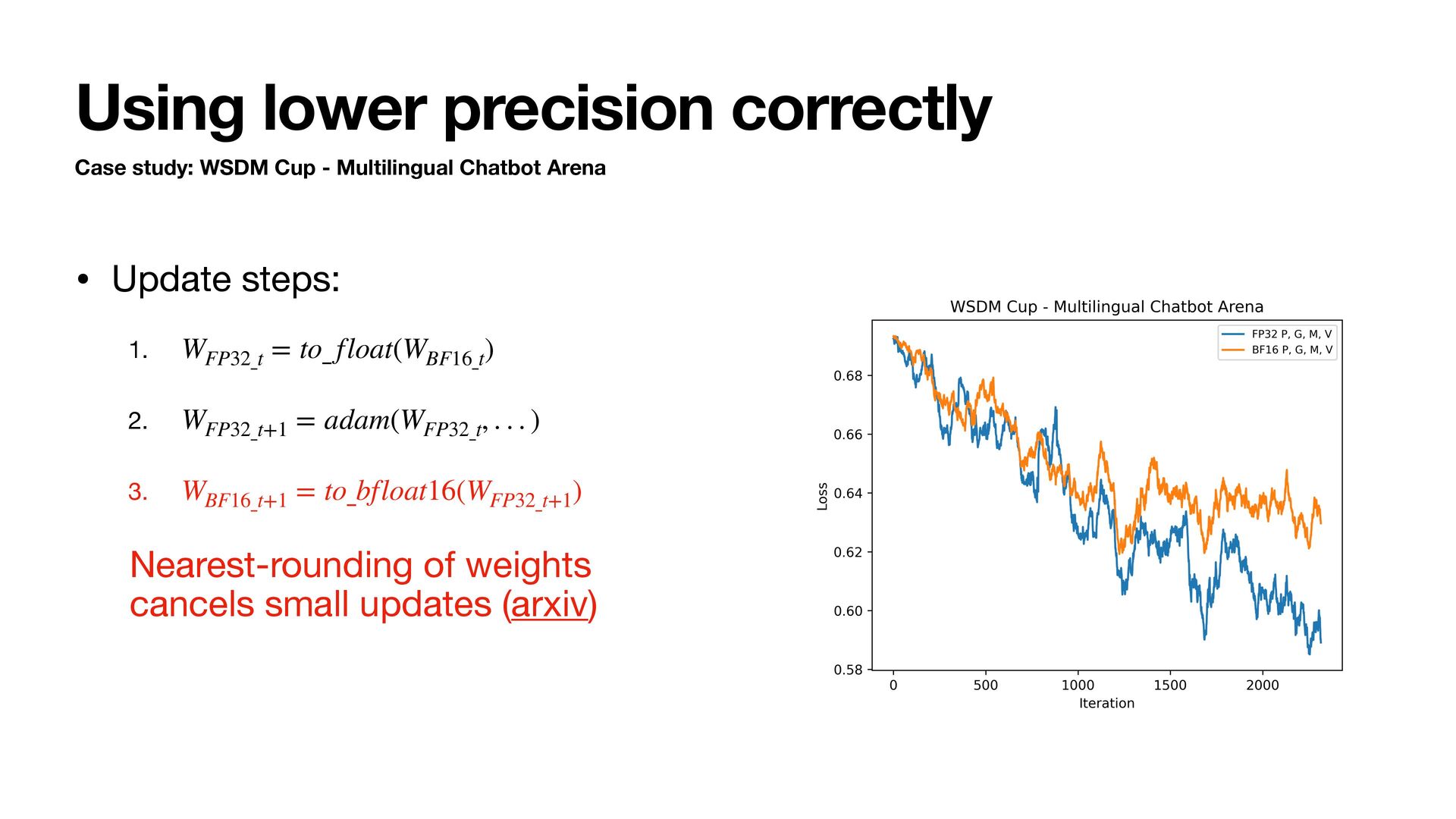
- Multilingual Chatbot Arena • Qwen2.5-1.5B • Train for 1 epoch and track training loss • Try using BFloat16 to store states • Adam step uses fl oat32 internally • Lower bits are possible but we are focusing on BFloat16 today
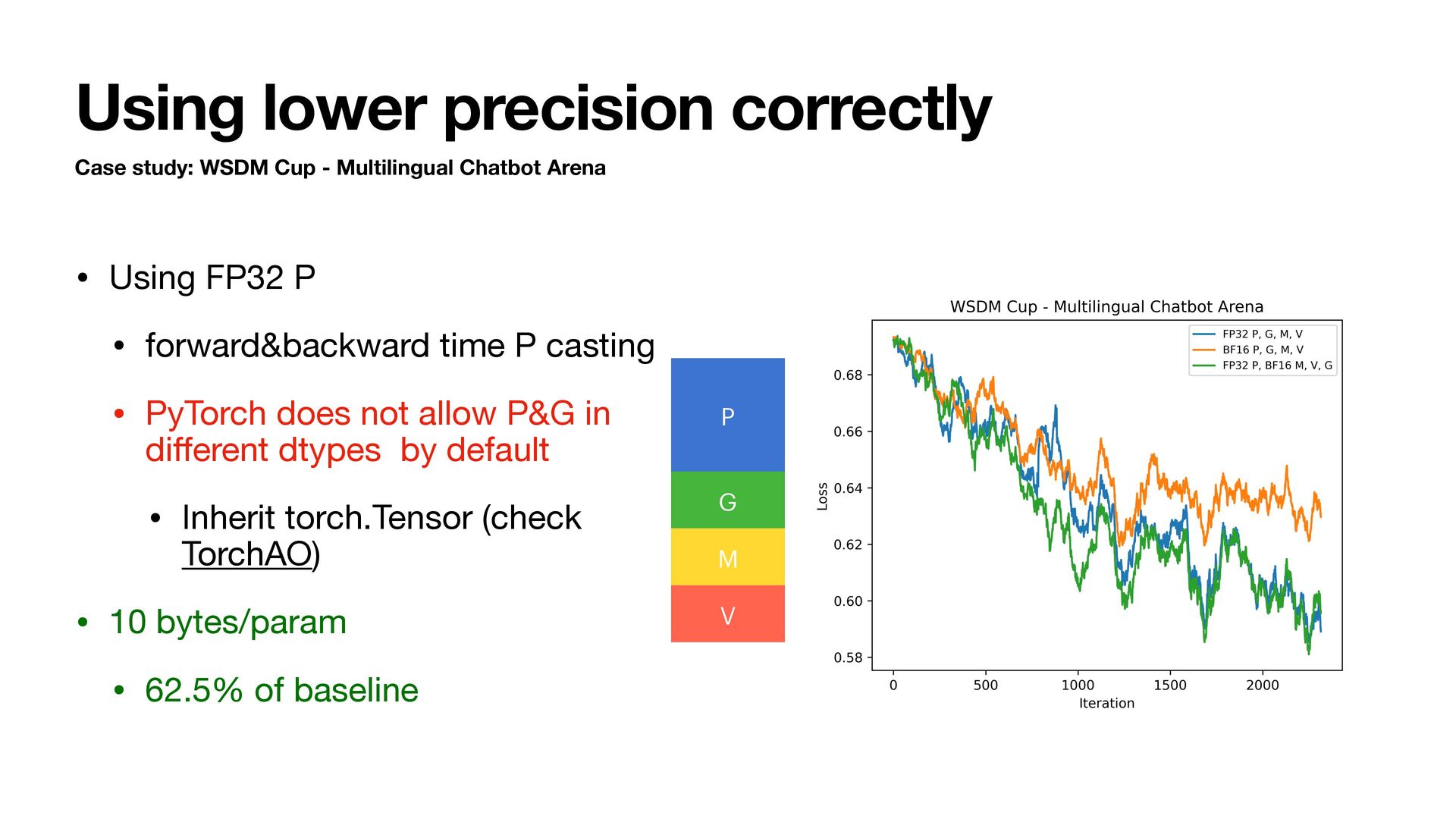
Chatbot Arena • Using FP32 P • forward&backward time P casting • PyTorch does not allow P&G in di ff erent dtypes by default • Inherit torch.Tensor (check TorchAO) • 10 bytes/param • 62.5% of baseline P G M V
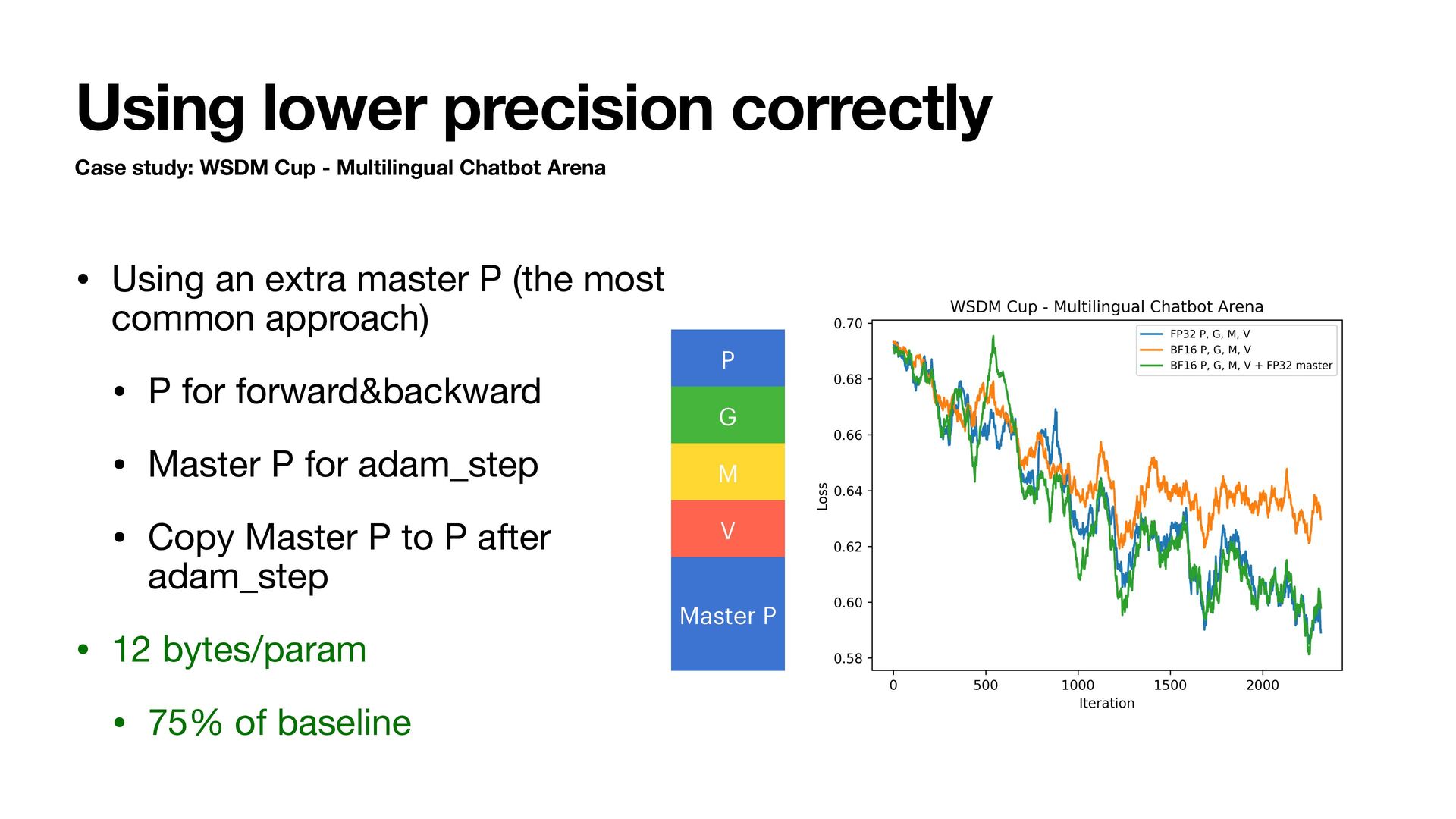
Chatbot Arena • Using an extra master P (the most common approach) • P for forward&backward • Master P for adam_step • Copy Master P to P after adam_step • 12 bytes/param • 75% of baseline P G M V Master P
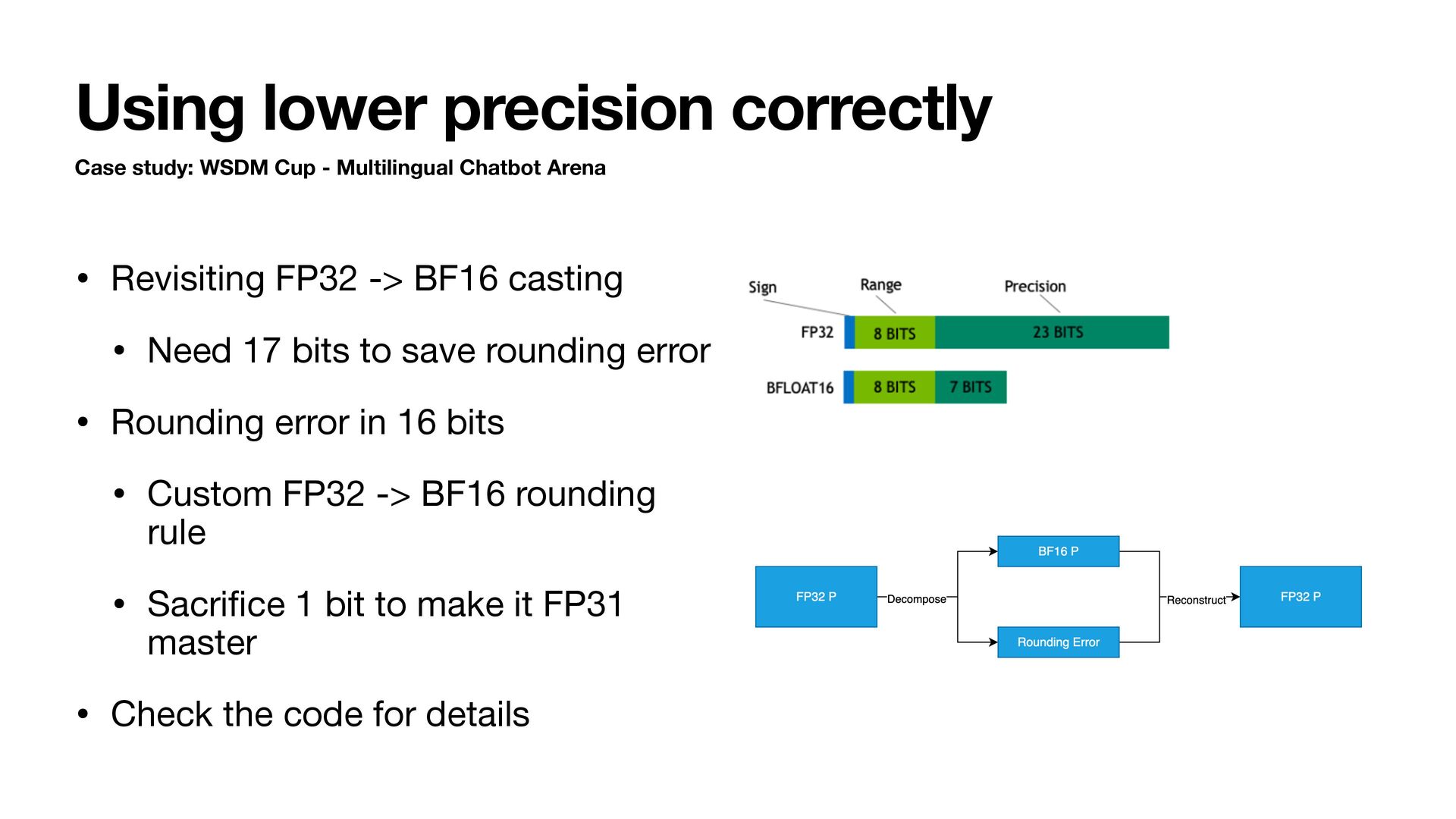
Chatbot Arena • Revisiting FP32 -> BF16 casting • Need 17 bits to save rounding error • Rounding error in 16 bits • Custom FP32 -> BF16 rounding rule • Sacri fi ce 1 bit to make it FP31 master • Check the code for details
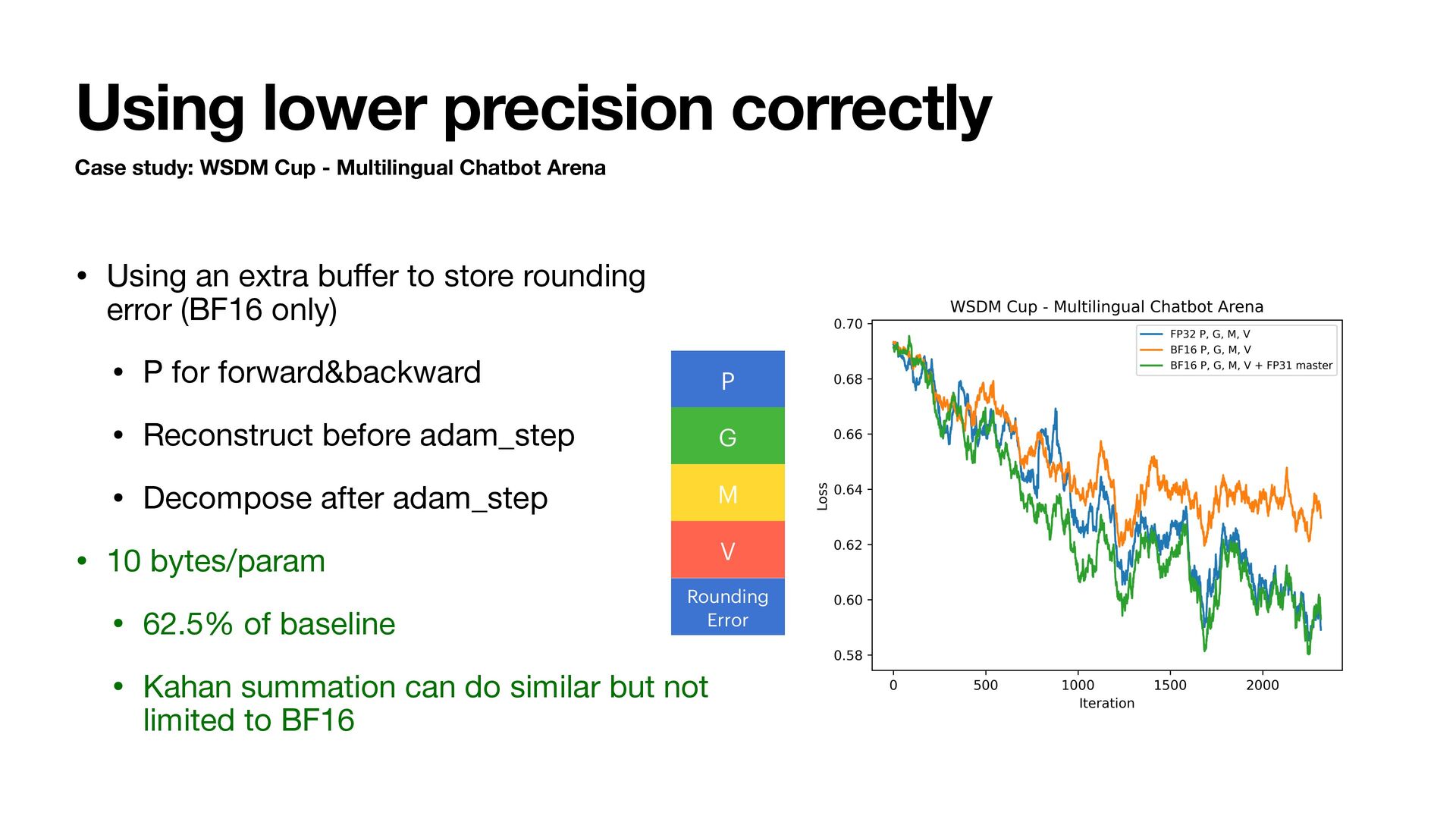
Chatbot Arena • Using an extra bu ff er to store rounding error (BF16 only) • P for forward&backward • Reconstruct before adam_step • Decompose after adam_step • 10 bytes/param • 62.5% of baseline • Kahan summation can do similar but not limited to BF16 P G M V Rounding Error
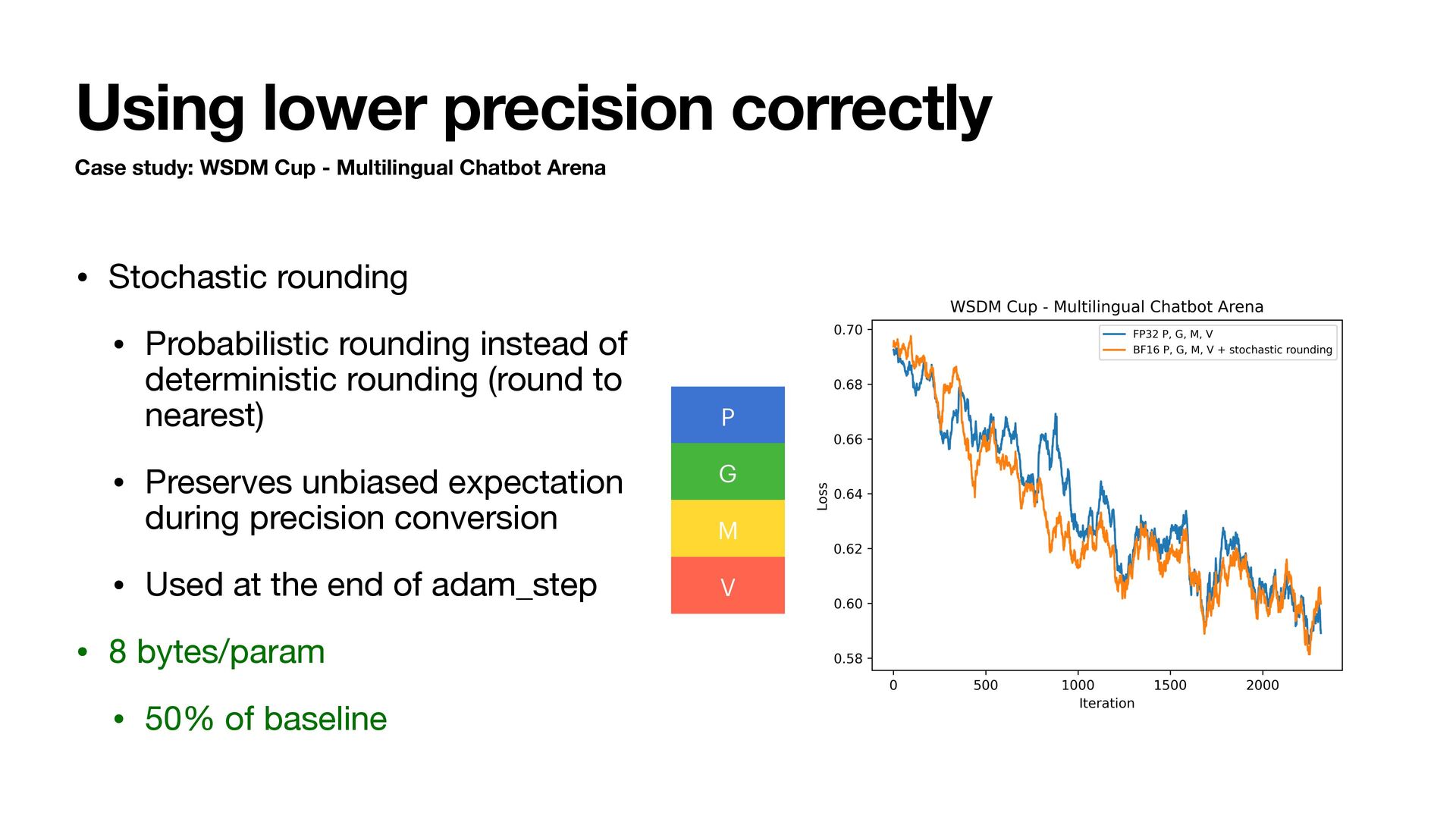
Chatbot Arena • Stochastic rounding • Probabilistic rounding instead of deterministic rounding (round to nearest) • Preserves unbiased expectation during precision conversion • Used at the end of adam_step • 8 bytes/param • 50% of baseline P G M V
states • Optimizer implementation may fail when all states are in BF16 • PagedAdam(model.b fl oat16().parameters()) fails to converge • With BF16 and stochastic rounding, we can reduce states VRAM to 8 bytes/param • 56GB states when training a 7B Model • single A100/H100/RTX Pro 6000 Blackwell • Simply all BF16, no autocast, no grad scaler • Can we do better? For • 24G VRAM: RTX 3090/RTX 4090/RTX 5090 • 48G VRAM: RTX A6000/RTX 6000Ada
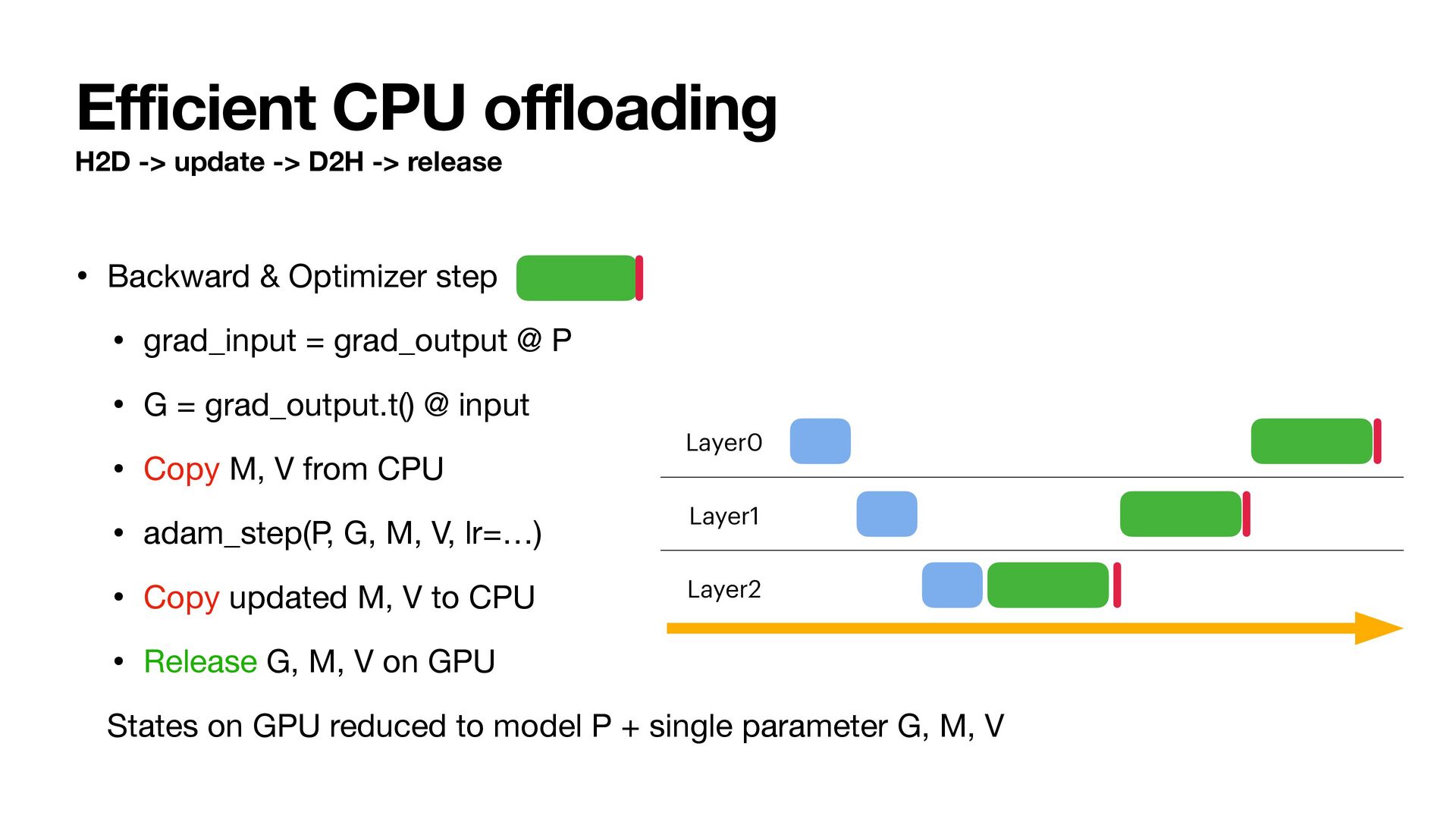
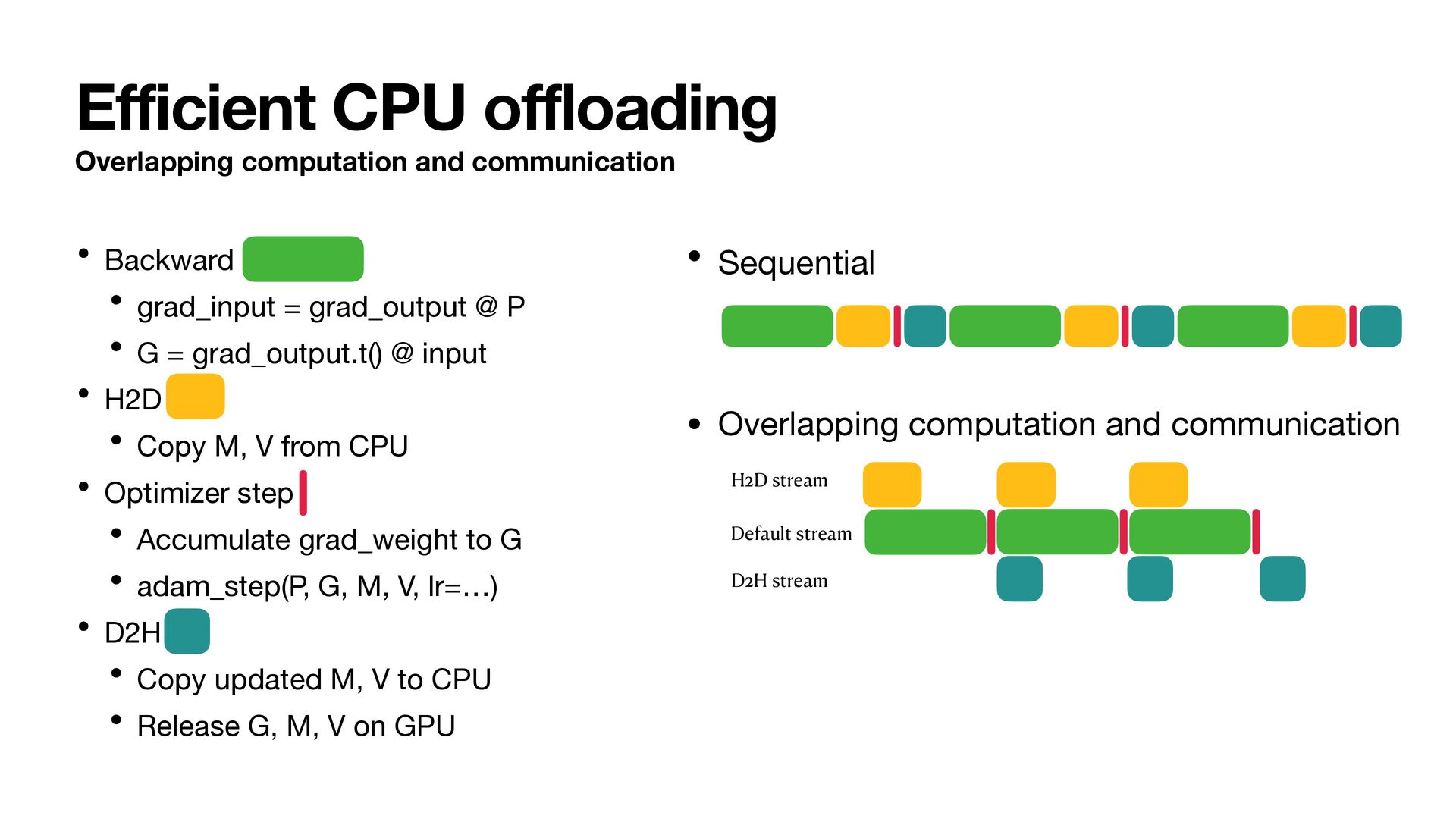
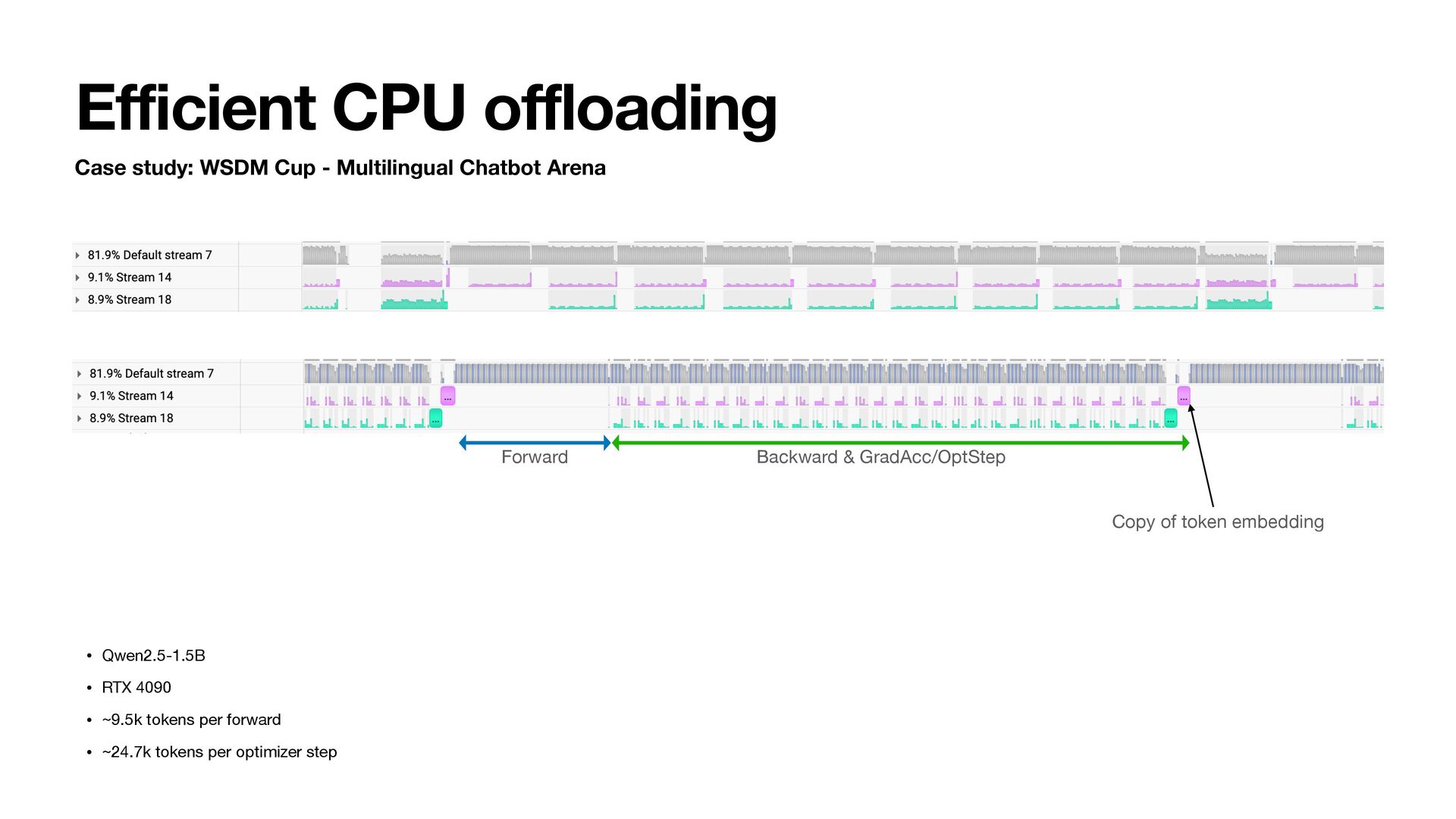
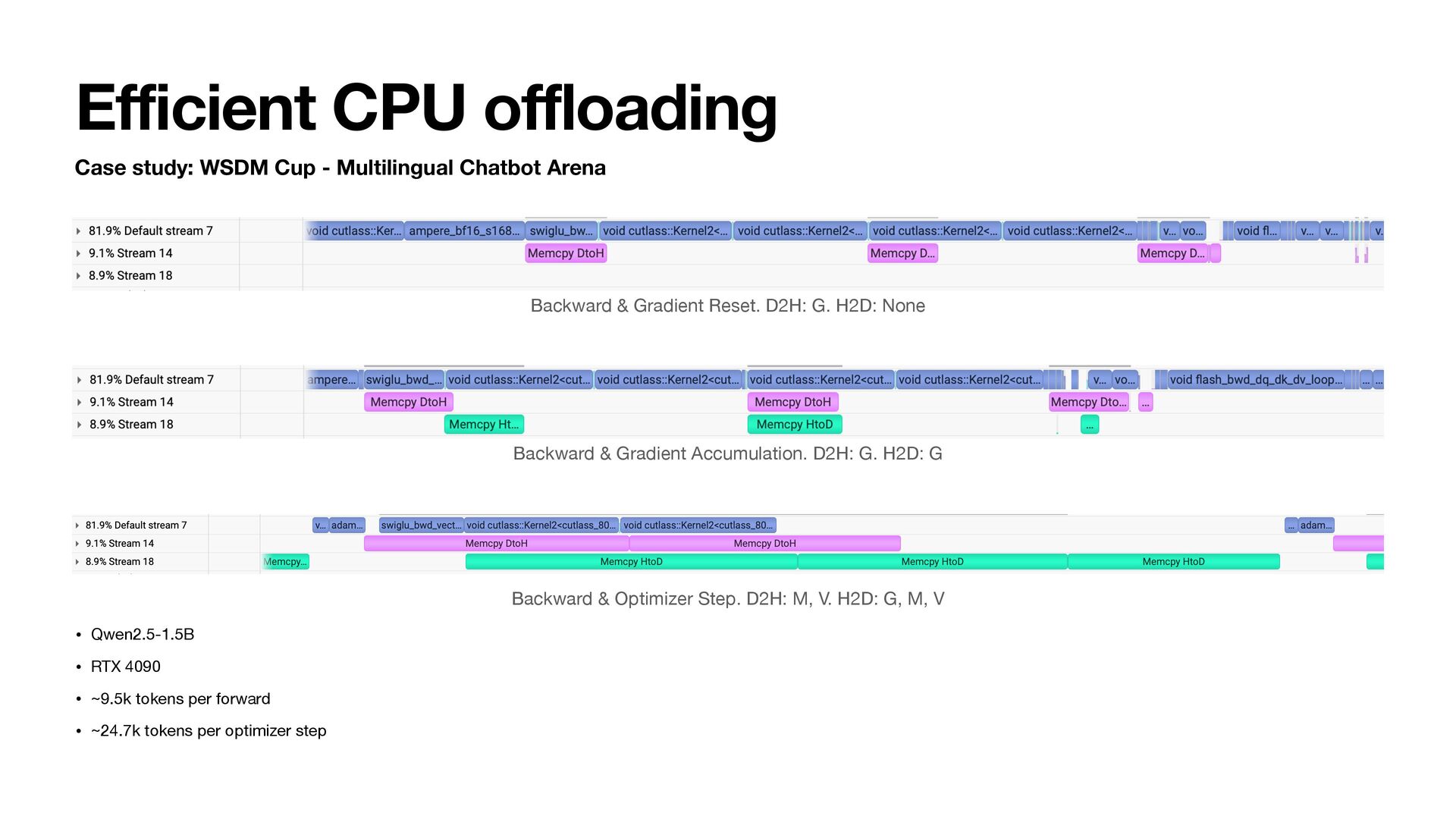
• Backward & Optimizer step • grad_input = grad_output @ P • G = grad_output.t() @ input • Copy M, V from CPU • adam_step(P, G, M, V, lr=…) • Copy updated M, V to CPU • Release G, M, V on GPU States on GPU reduced to model P + single parameter G, M, V Layer0 Layer1 Layer2
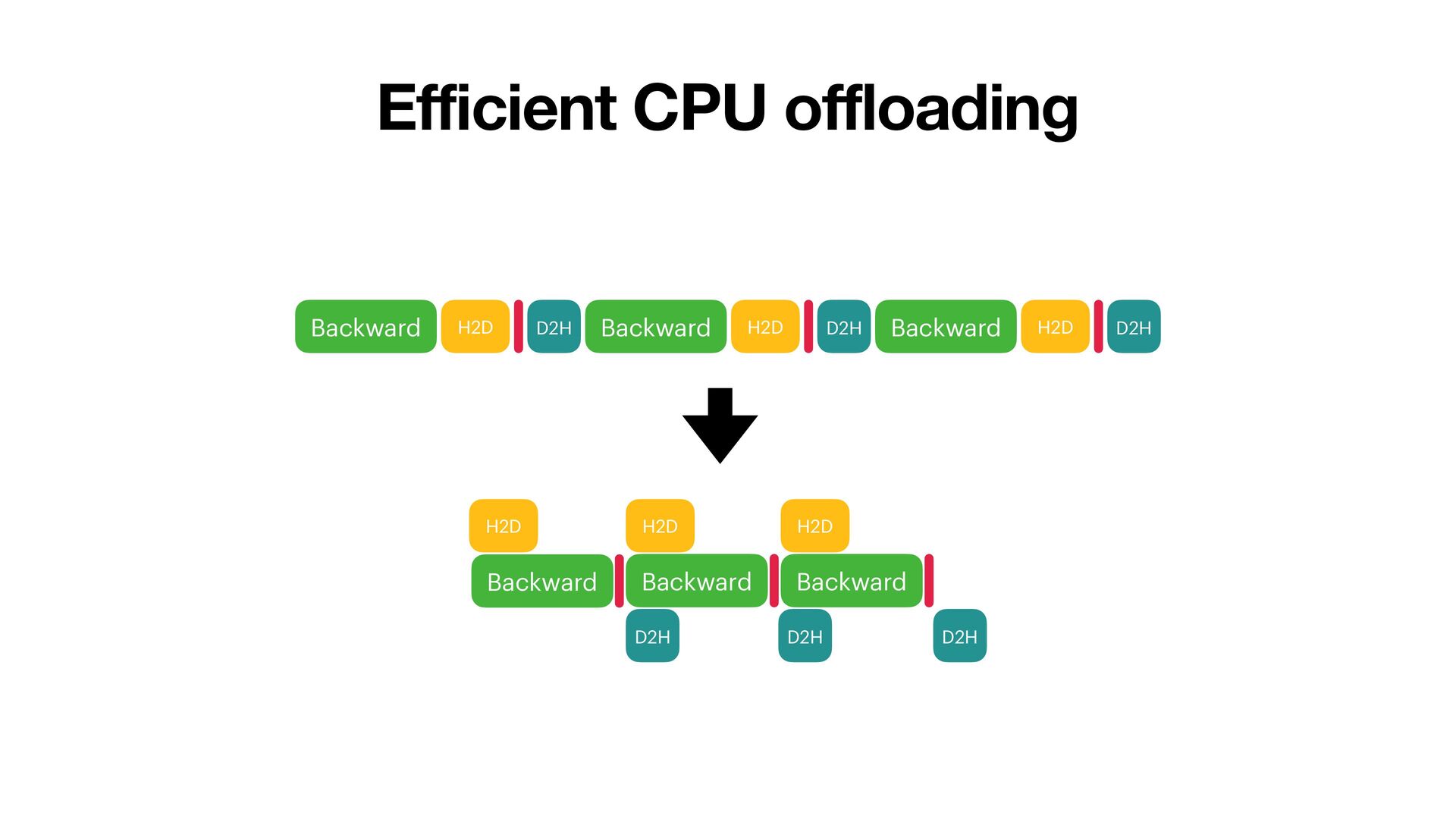
grad_input = grad_output @ P • G = grad_output.t() @ input • H2D • Copy M, V from CPU • Optimizer step • Accumulate grad_weight to G • adam_step(P, G, M, V, lr=…) • D2H • Copy updated M, V to CPU • Release G, M, V on GPU • Sequential • Overlapping computation and communication Default stream H2D stream D2H stream
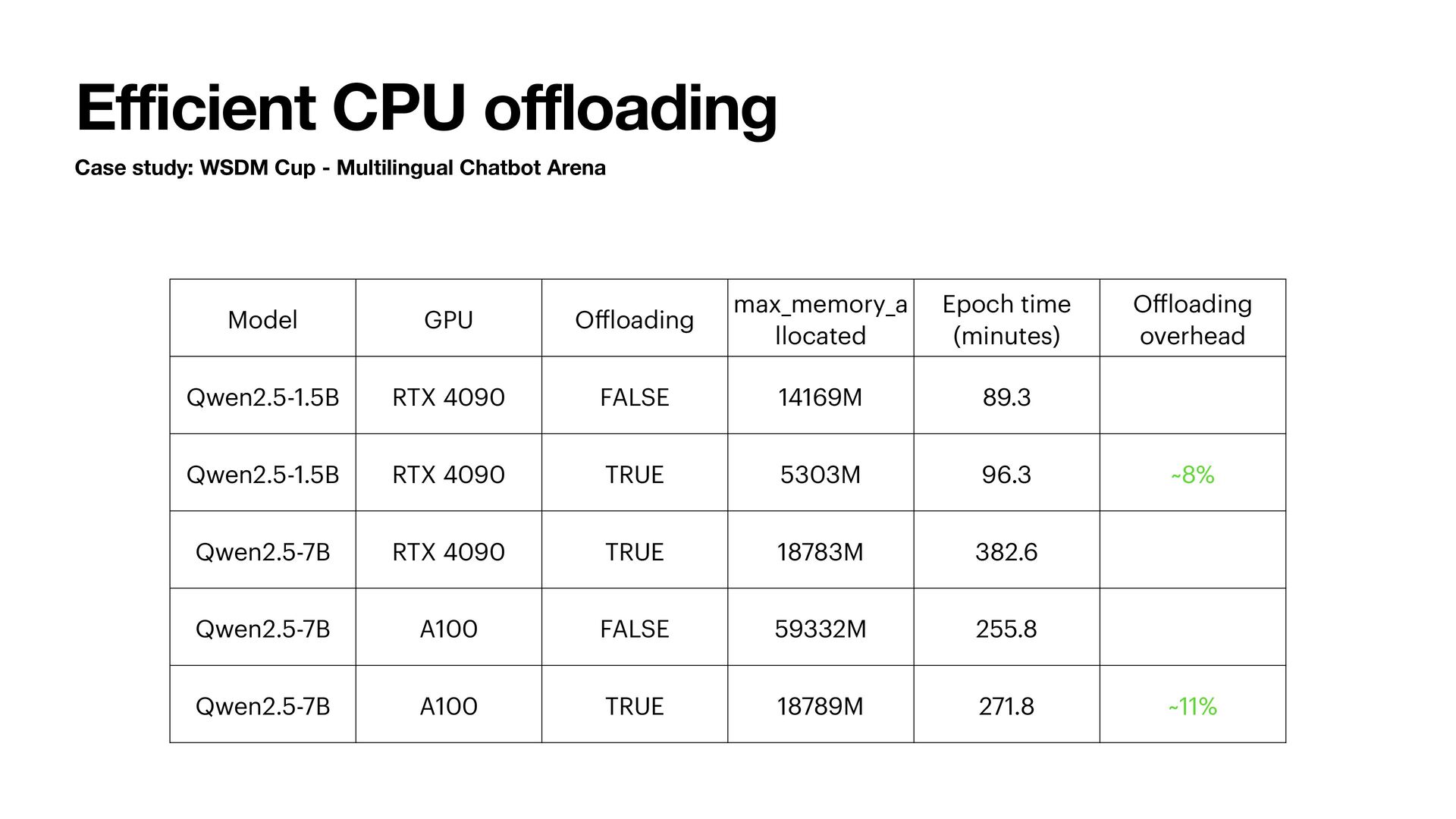
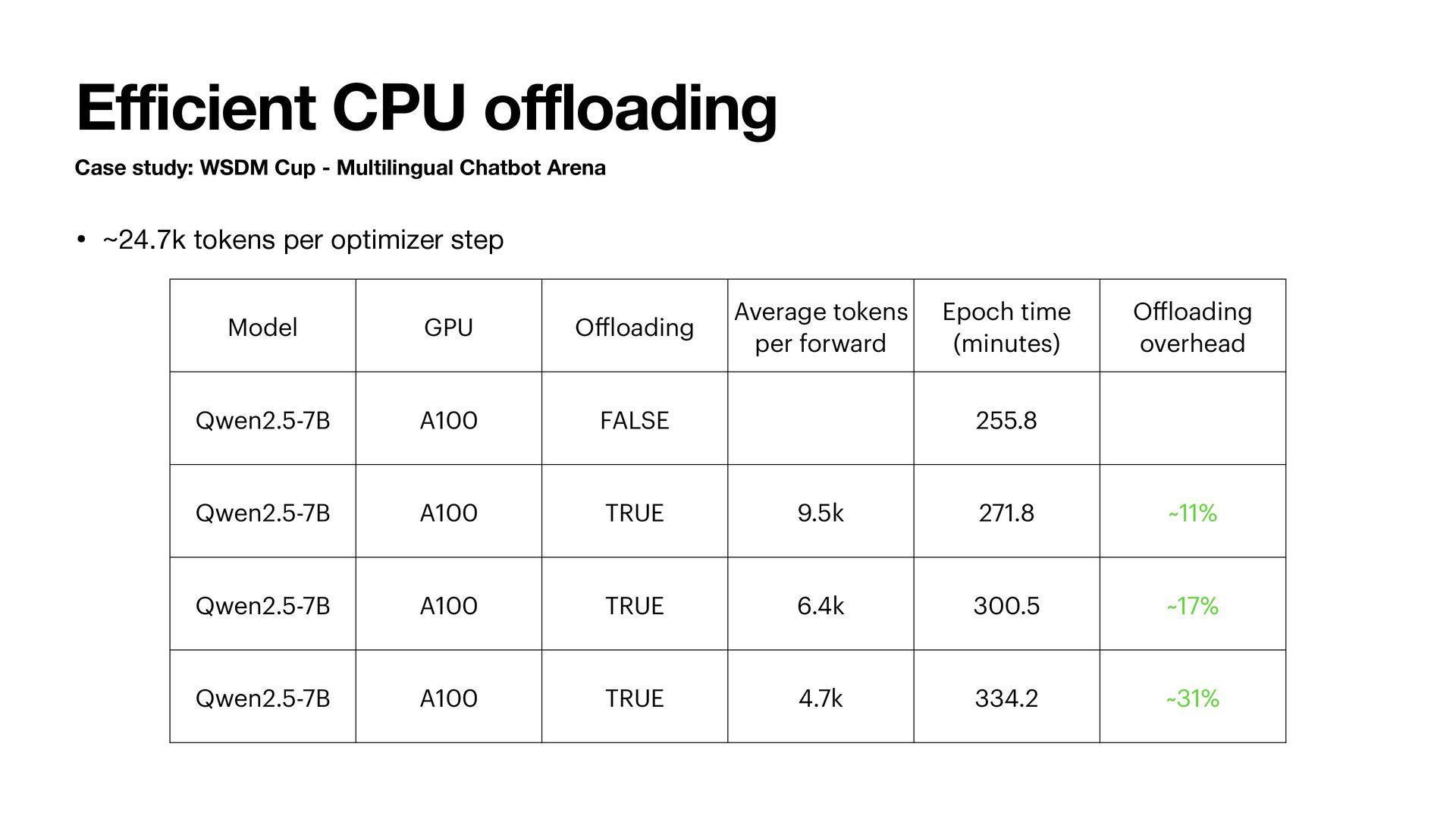
Arena Backward & Gradient Accumulation. D2H: G. H2D: G • Qwen2.5-1.5B • RTX 4090 • ~9.5k tokens per forward • ~24.7k tokens per optimizer step Backward & Optimizer Step. D2H: M, V. H2D: G, M, V Backward & Gradient Reset. D2H: G. H2D: None
oading using CPU adam_step • Pros • M, V kept on CPU, less H2D (P) and D2H (G) transfer • Cons • Fused CPU SIMD adam_step is fast, but still much slower than GPU adam_step • Fused CPU adam_step does not handle BF16 properly (FP32 master, stochastic rounding, etc.) • Some does not support gradient accumulation
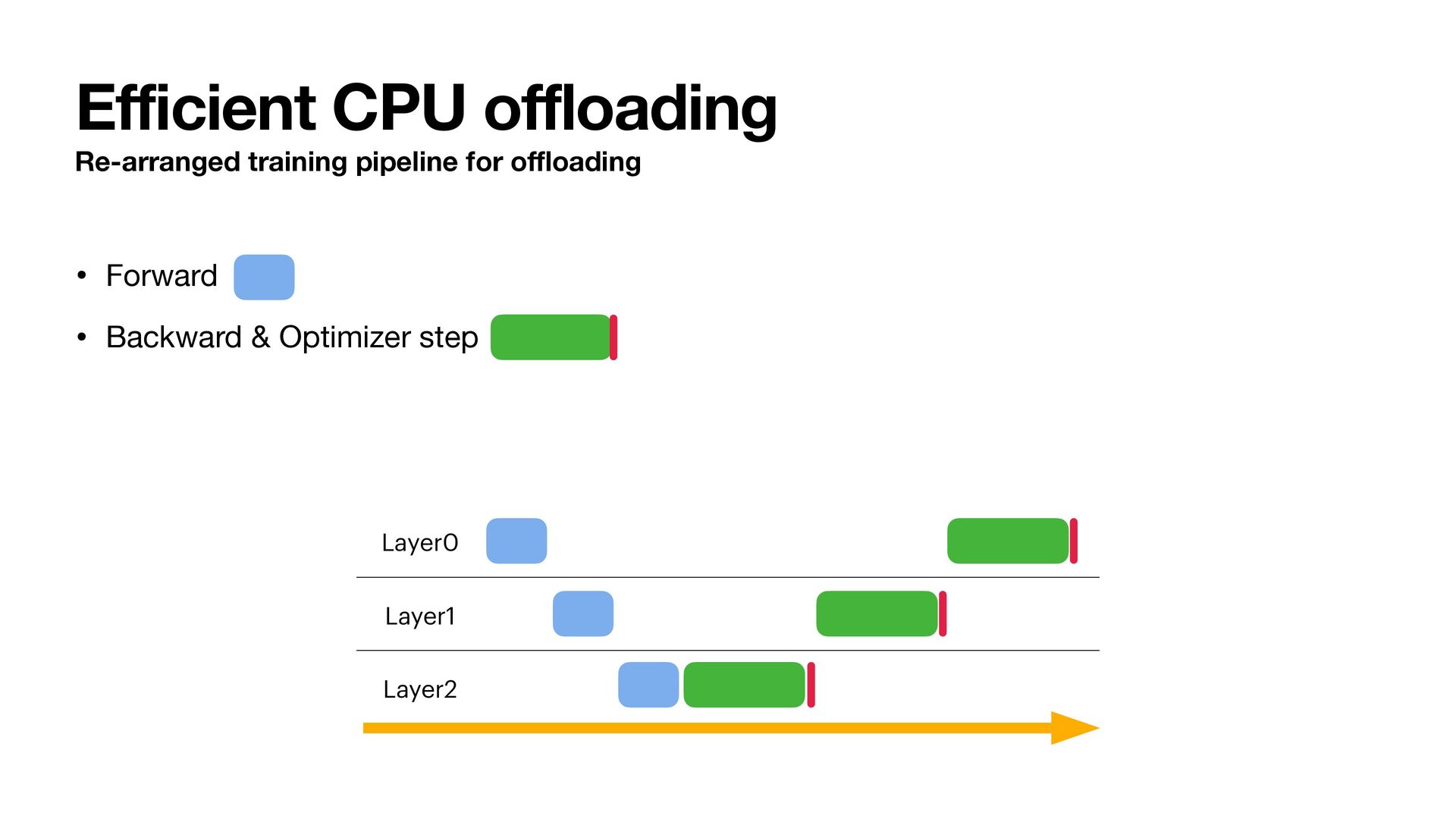
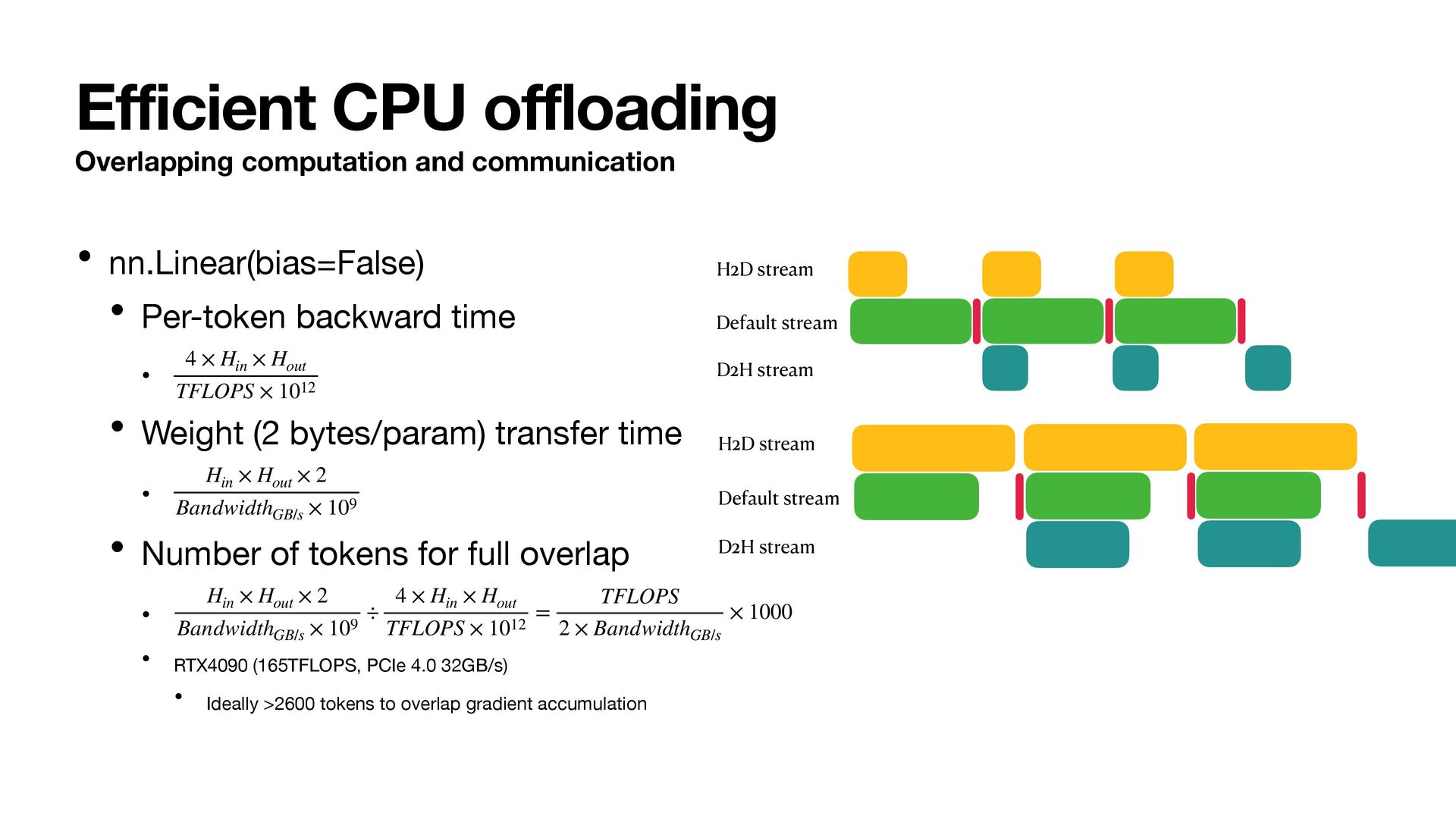
to CPU, we reduced states VRAM by 75% • By overlapping state transfer and computation, we can hide the overhead of o ffl oading • State VRAM requirement is now 2 bytes/param (BF16 P) + single parameter G, M, V. That is almost 12.5% of baseline.
(~9k tokens per forward, ~25k tokens per optimizer step) • RTX 5090 versus RTX 4090 • 2x transfer (PCIe 5.0) • 1.3x compute Less tokens to overlap compute/transfer, more o ffl oading friendly than 4090 • GH200 • $1.49/hour on Lambda Cloud • 96G VRAM, 480GB of LPDDR5X (training 32B models) • NVLink-C2C, >330GB/s H2D, D2H transfer • Fast even without computation communication overlap • More than 3x compute compared to A100 Perfect fi t for training with o ff l oading. Training a 32B model on GH200 + o ff l oading is much faster than A100x4 + FSDP full shard
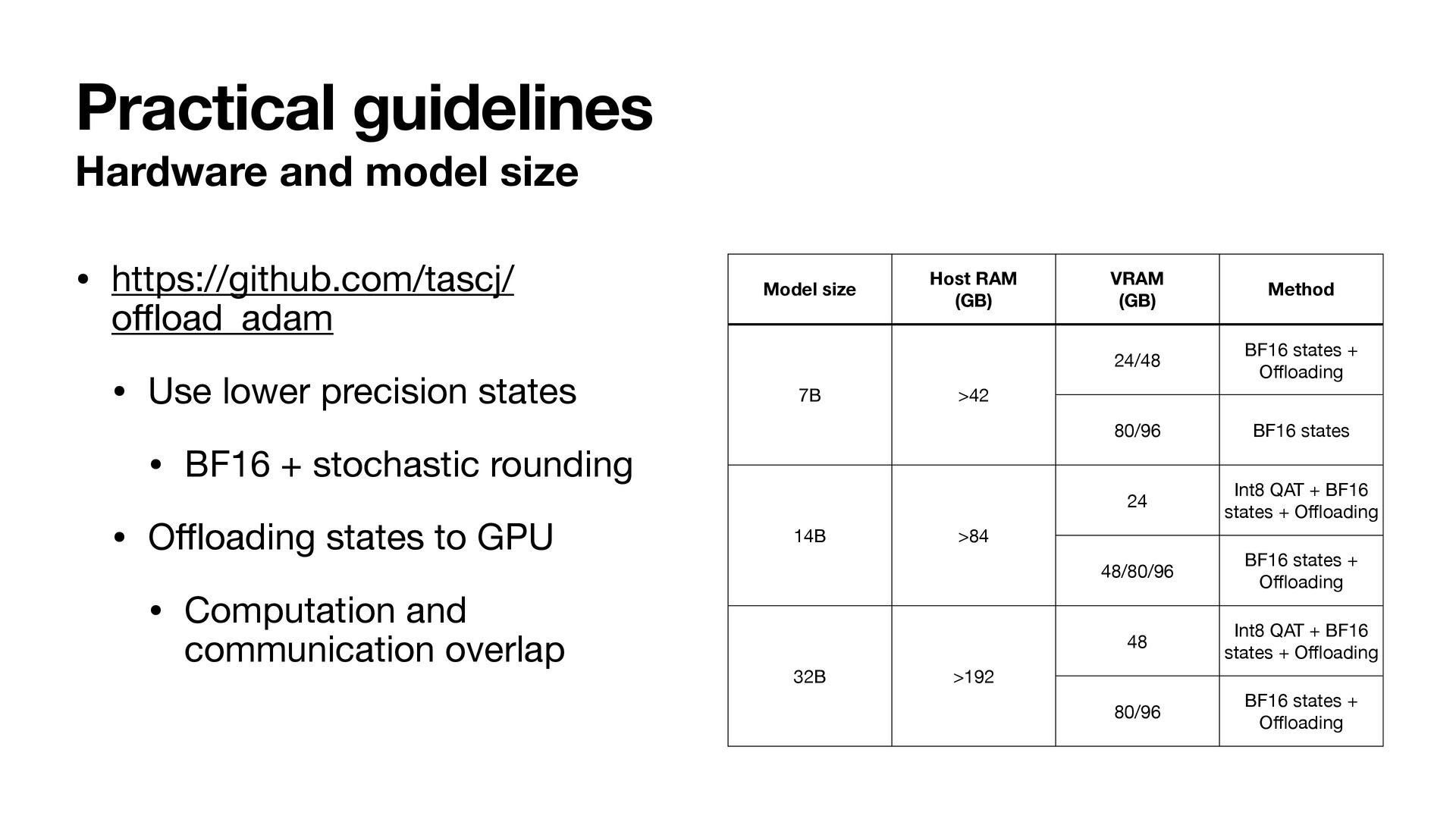
oad_adam • Use lower precision states • BF16 + stochastic rounding • O ffl oading states to GPU • Computation and communication overlap Model size Host RAM (GB) VRAM (GB) Method 7B >42 24/48 BF16 states + O ffl oading 80/96 BF16 states 14B >84 24 Int8 QAT + BF16 states + O ffl oading 48/80/96 BF16 states + O ffl oading 32B >192 48 Int8 QAT + BF16 states + O ffl oading 80/96 BF16 states + O ffl oading
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}