Share
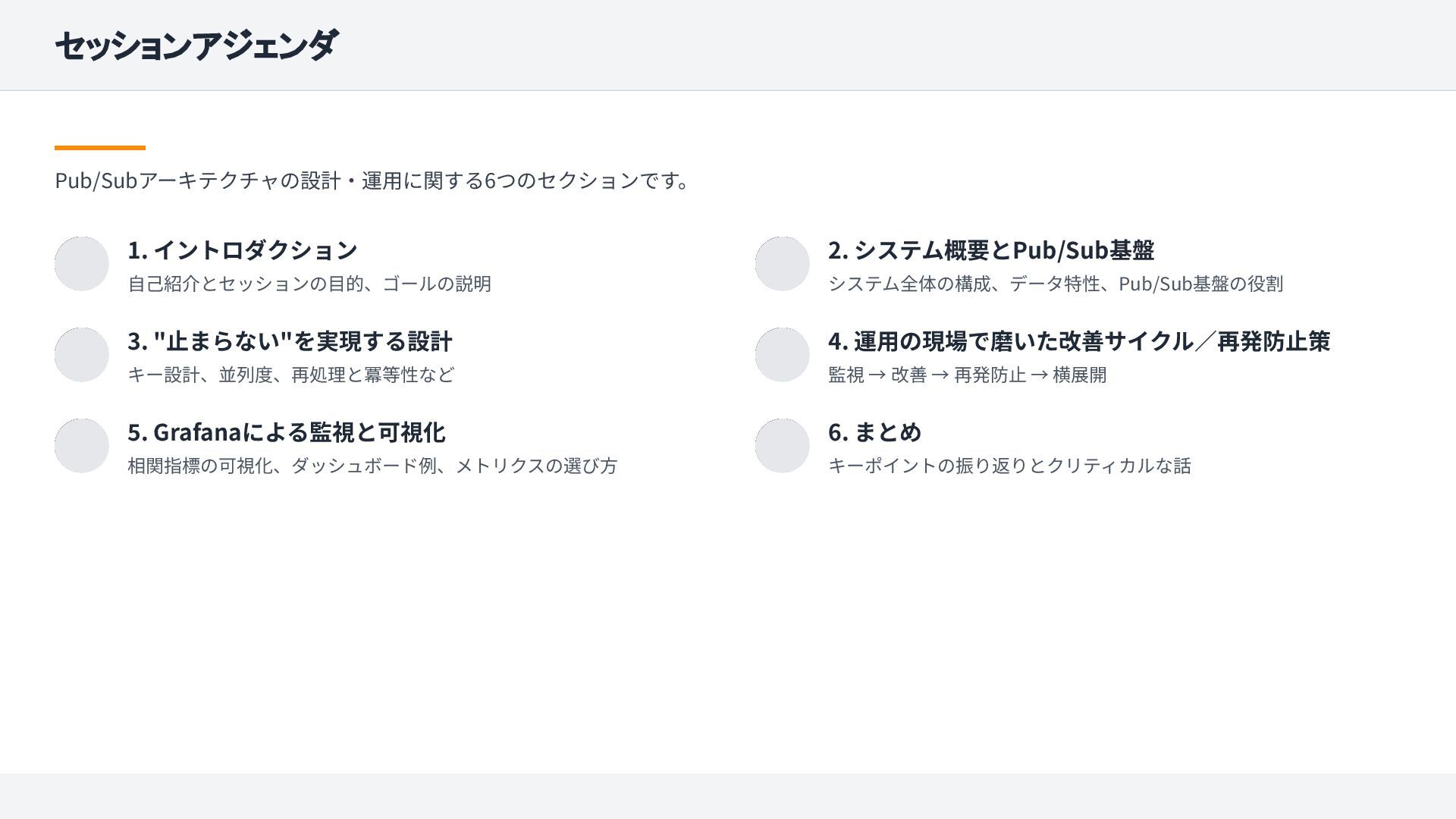
JJUG CCC 2025 Fall で登壇したセッションの資料です。 Java と MQ(Apache Pulsar)で構築した Pub/Sub 基盤を題材に、 「止まらないバッチ/大量データ処理」を支える設計・運用・監視のポイントを紹介します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Kubernetesでのグレースフルシャットダウン Kubernetes設定の重要点 lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 10"]](https://files.speakerdeck.com/presentations/6508e1e8074041188cdc16db28171df1/slide_39.jpg){kind=link}
![Kubernetesでのグレースフルシャットダウン Kubernetes設定の重要点 lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 10"]](https://files.speakerdeck.com/presentations/6508e1e8074041188cdc16db28171df1/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
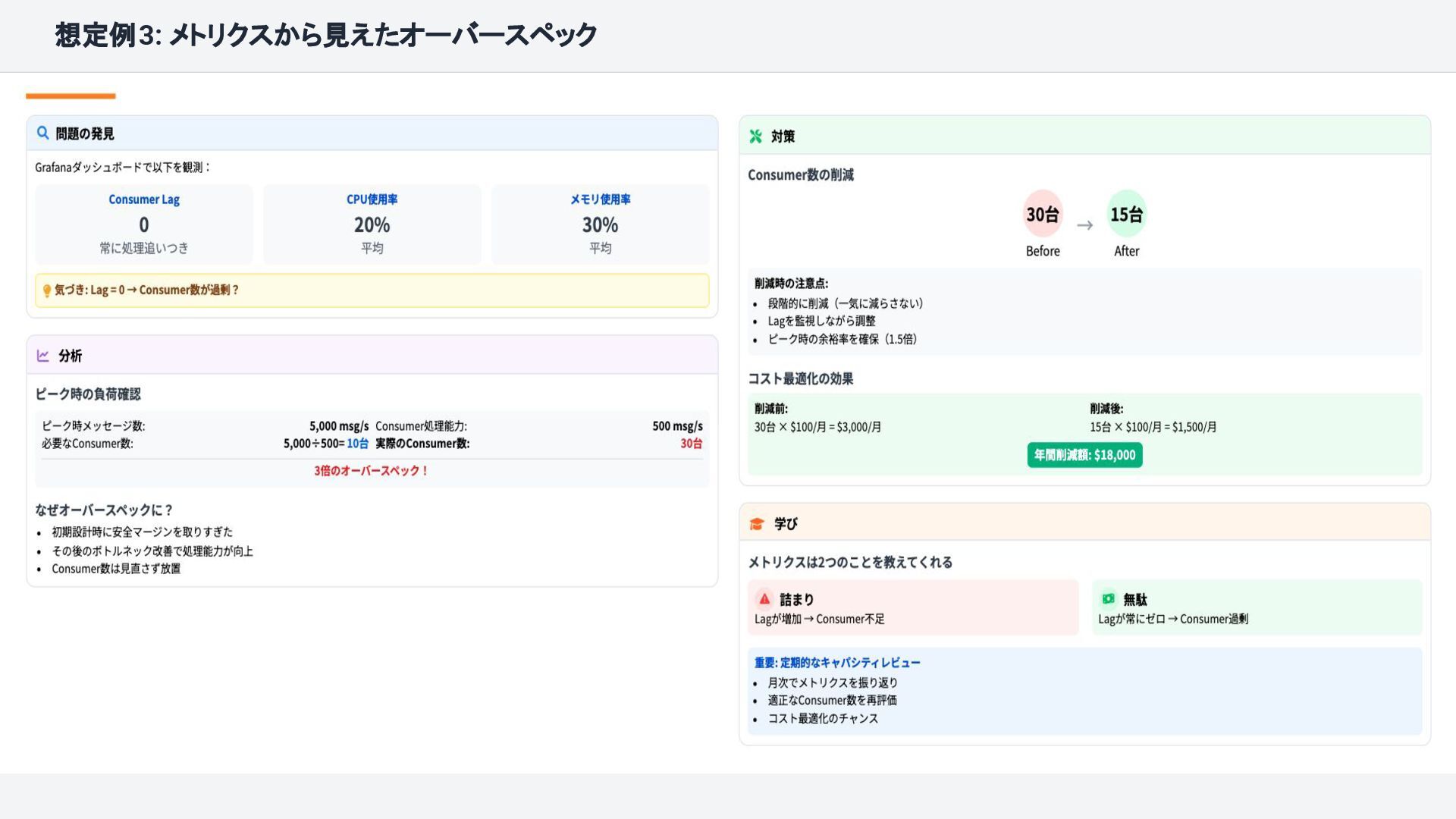{kind=link}
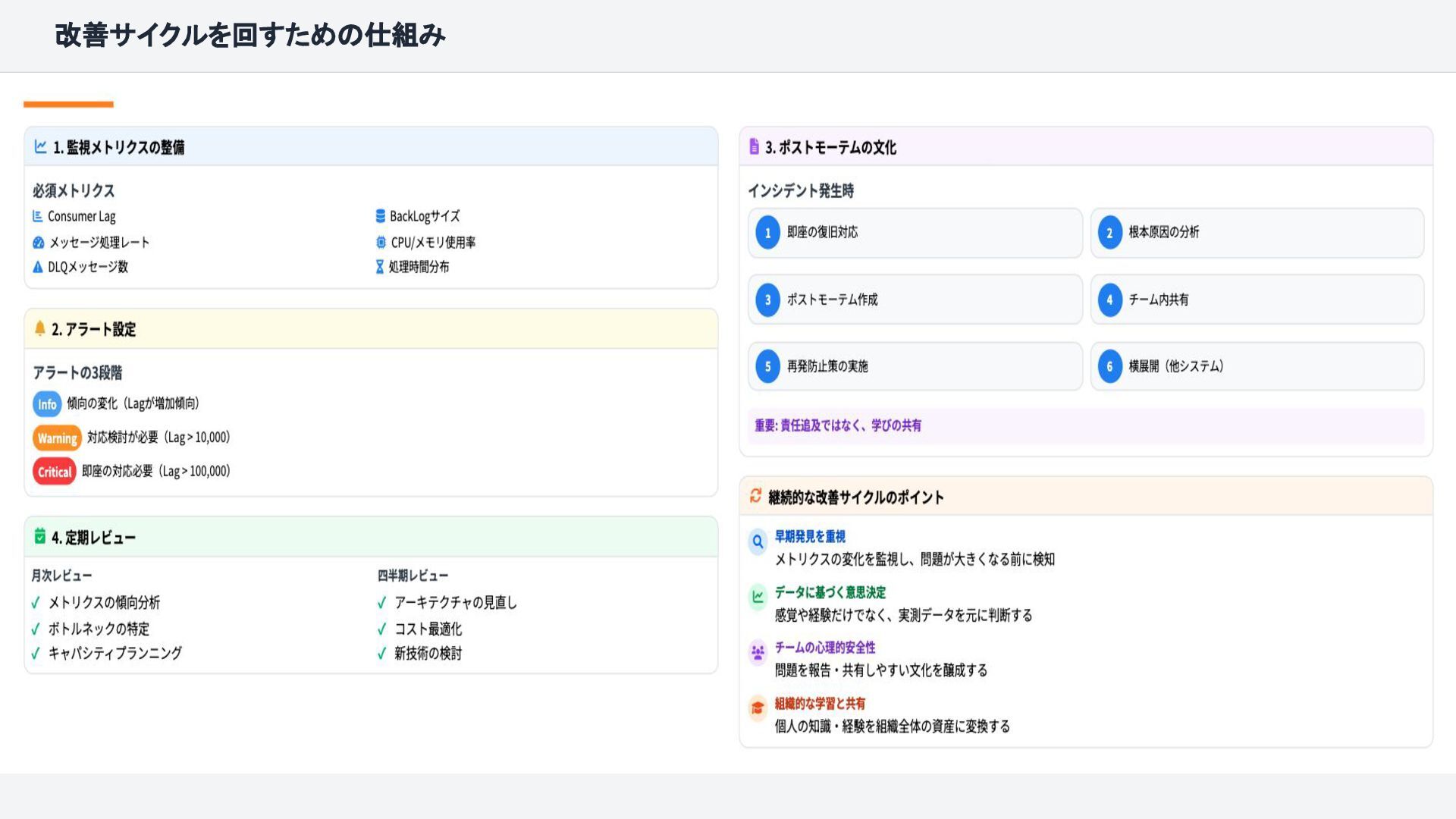{kind=link}
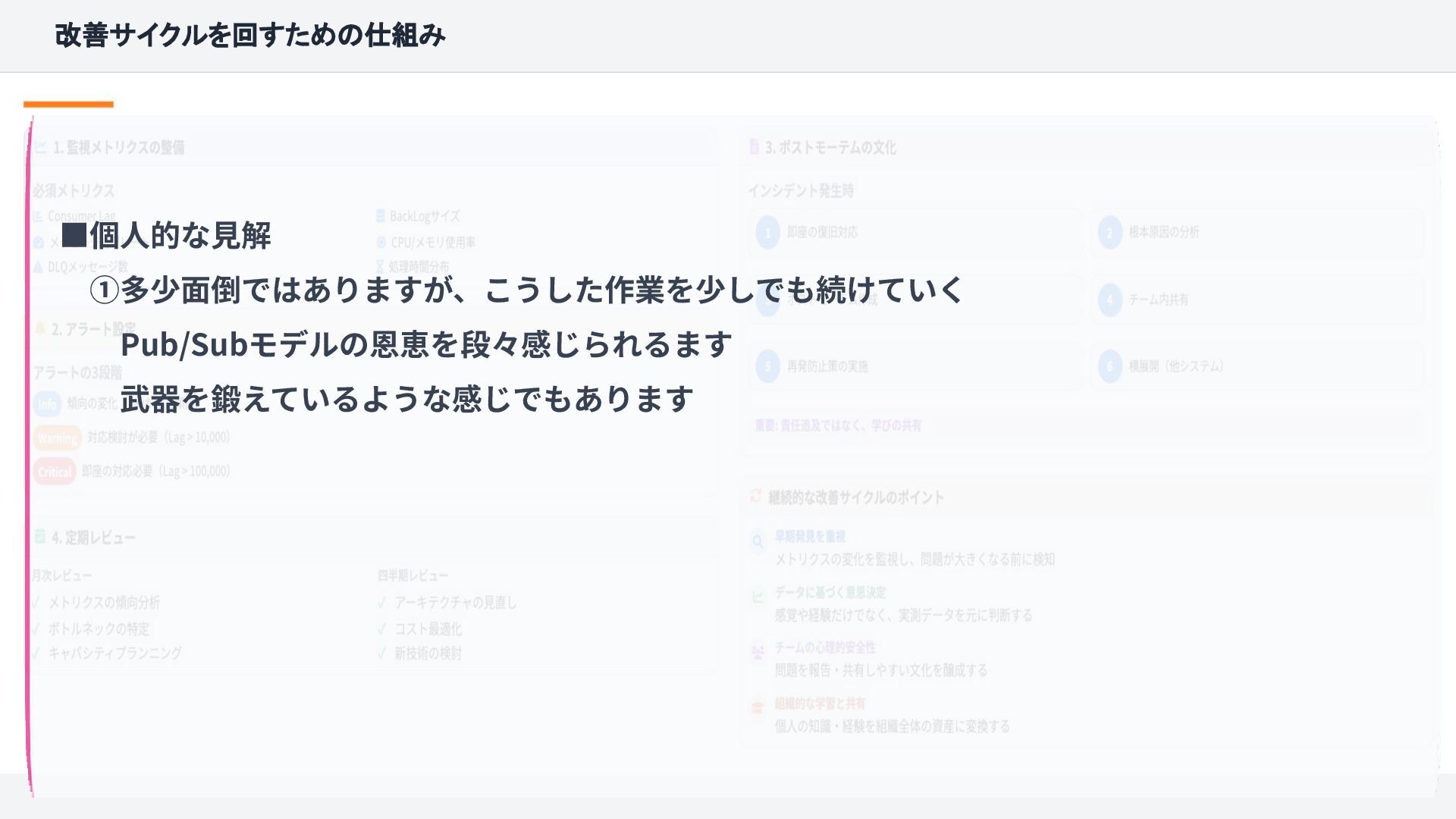{kind=link}
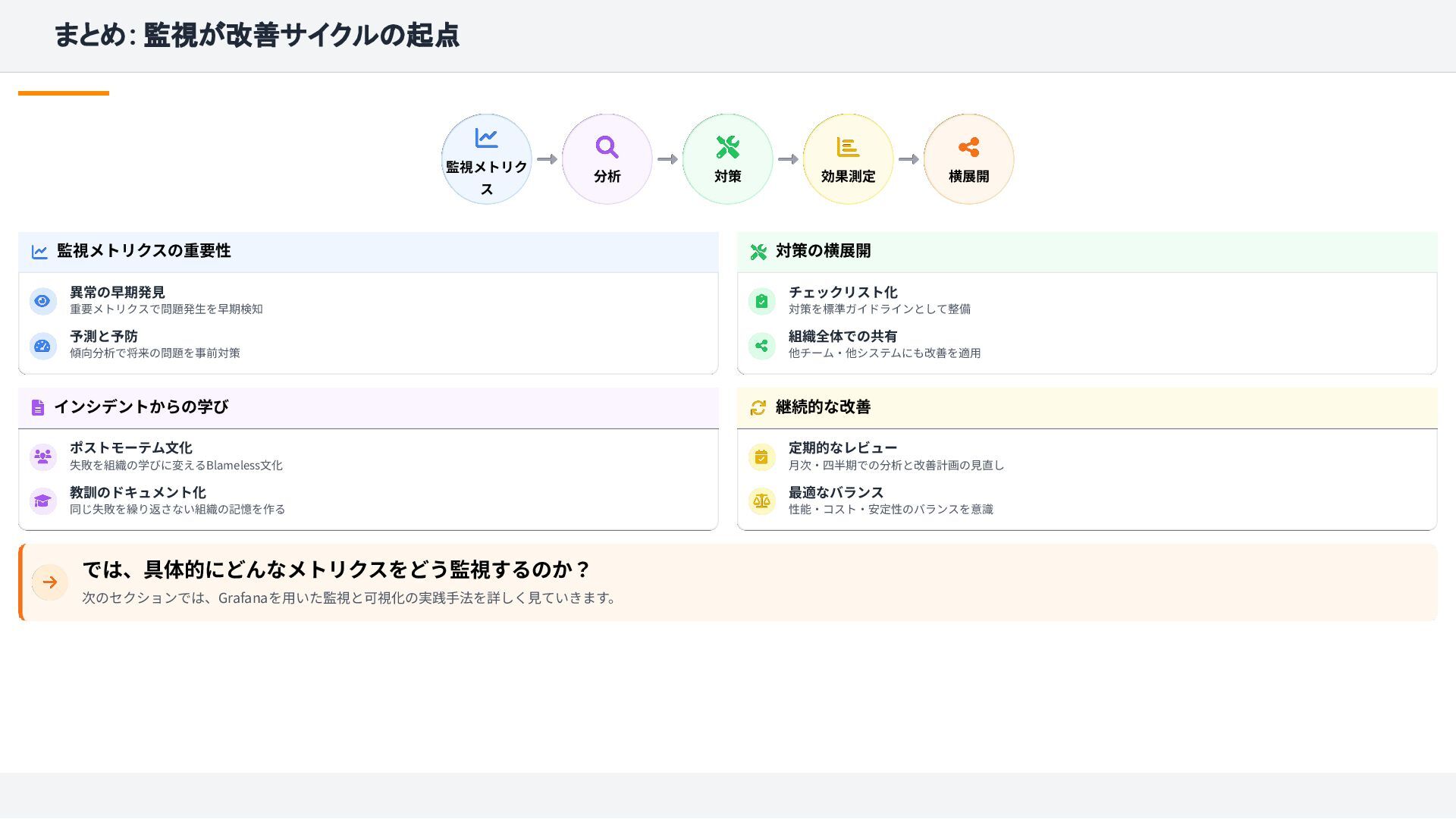{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
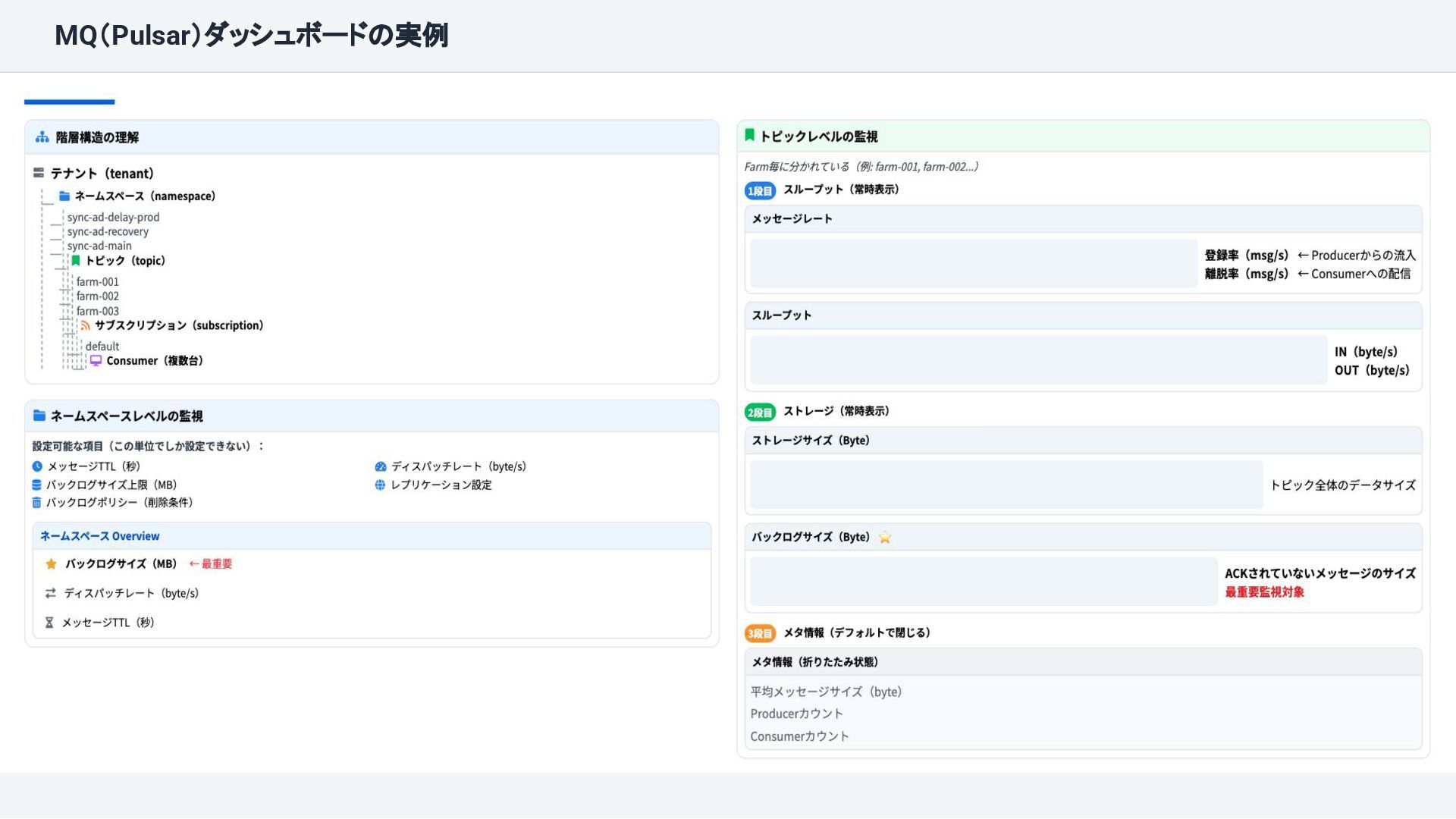{kind=link}
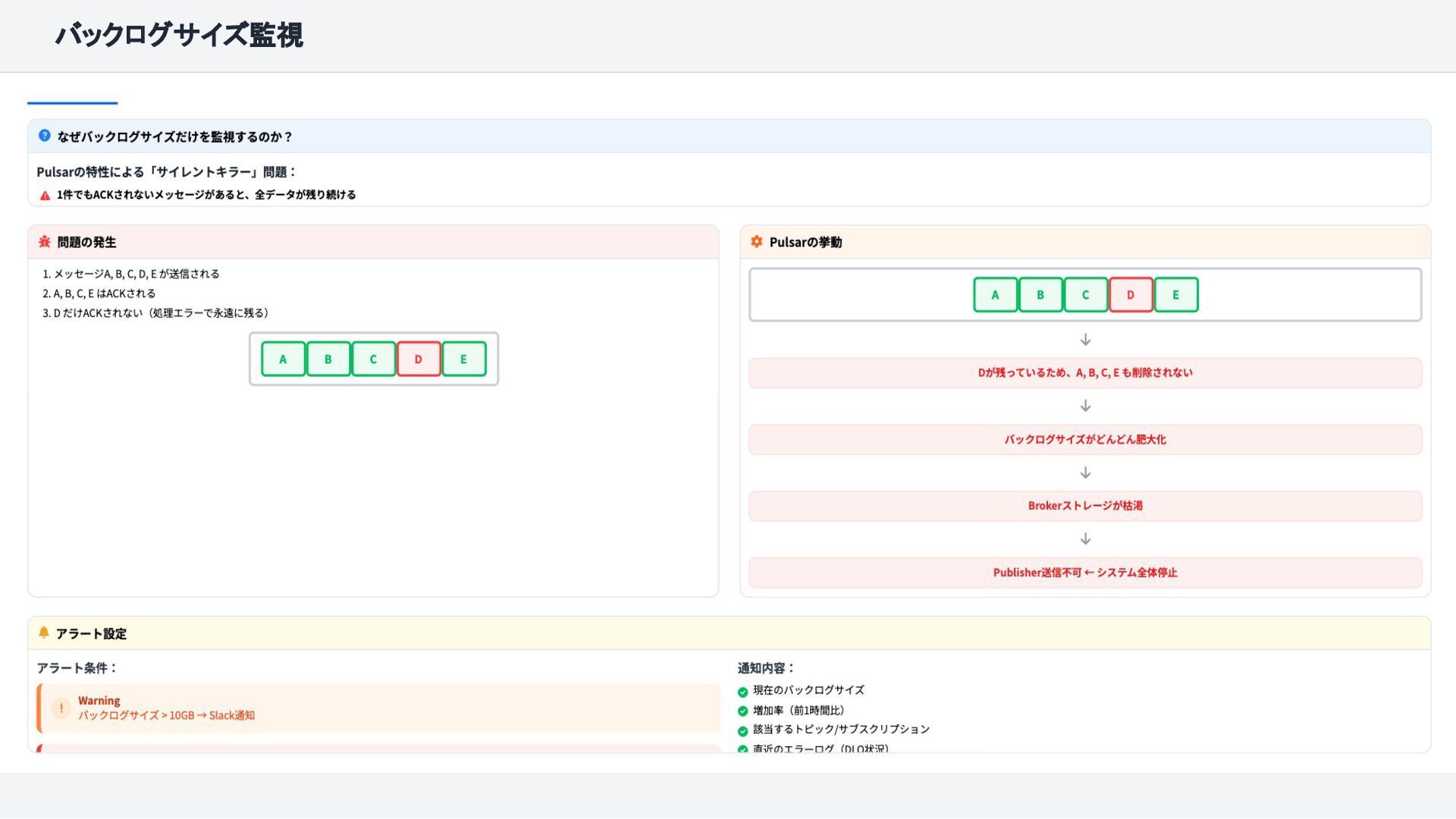{kind=link}
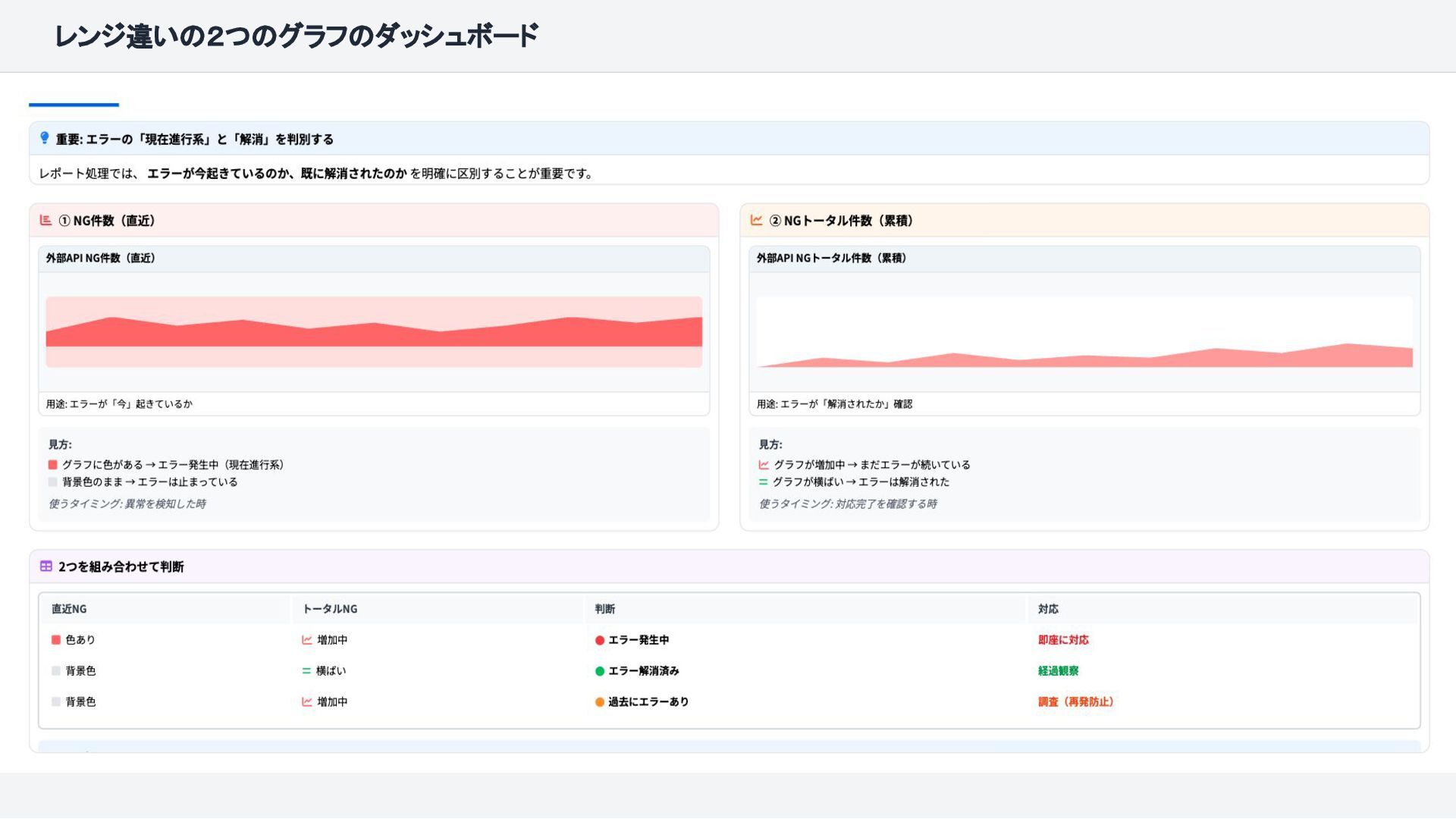{kind=link}
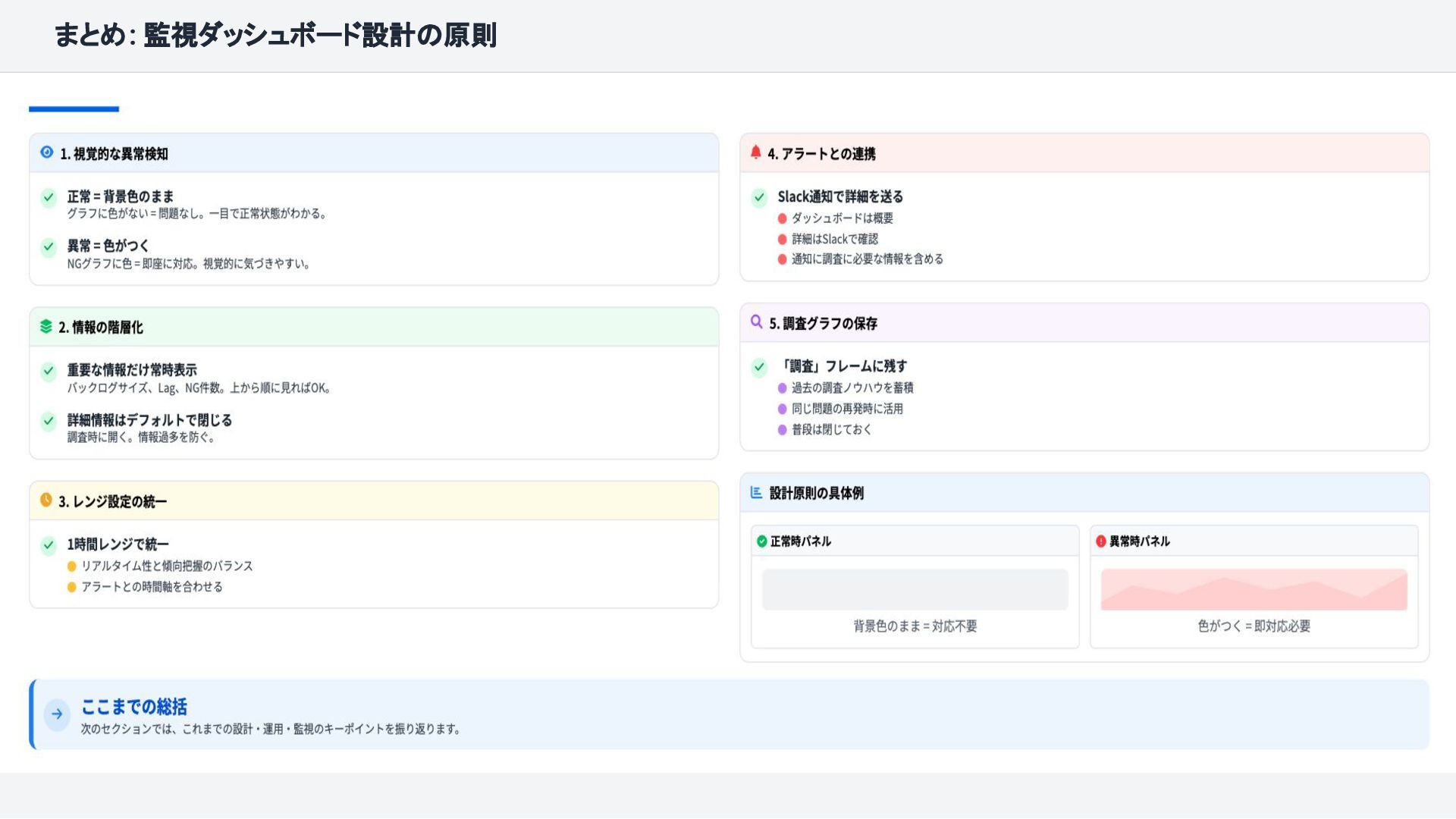{kind=link}
{kind=link}
{kind=link}
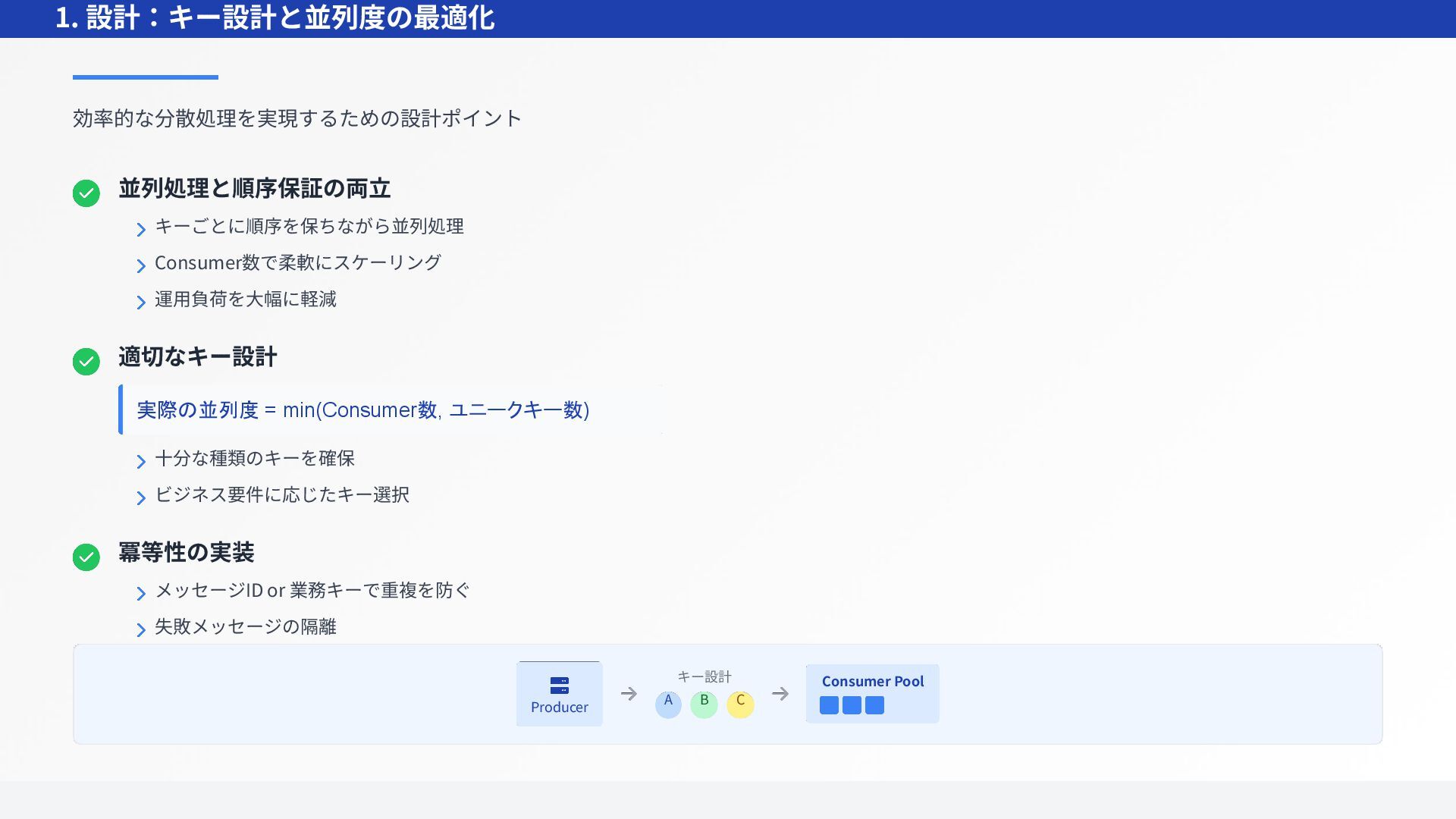{kind=link}
{kind=link}
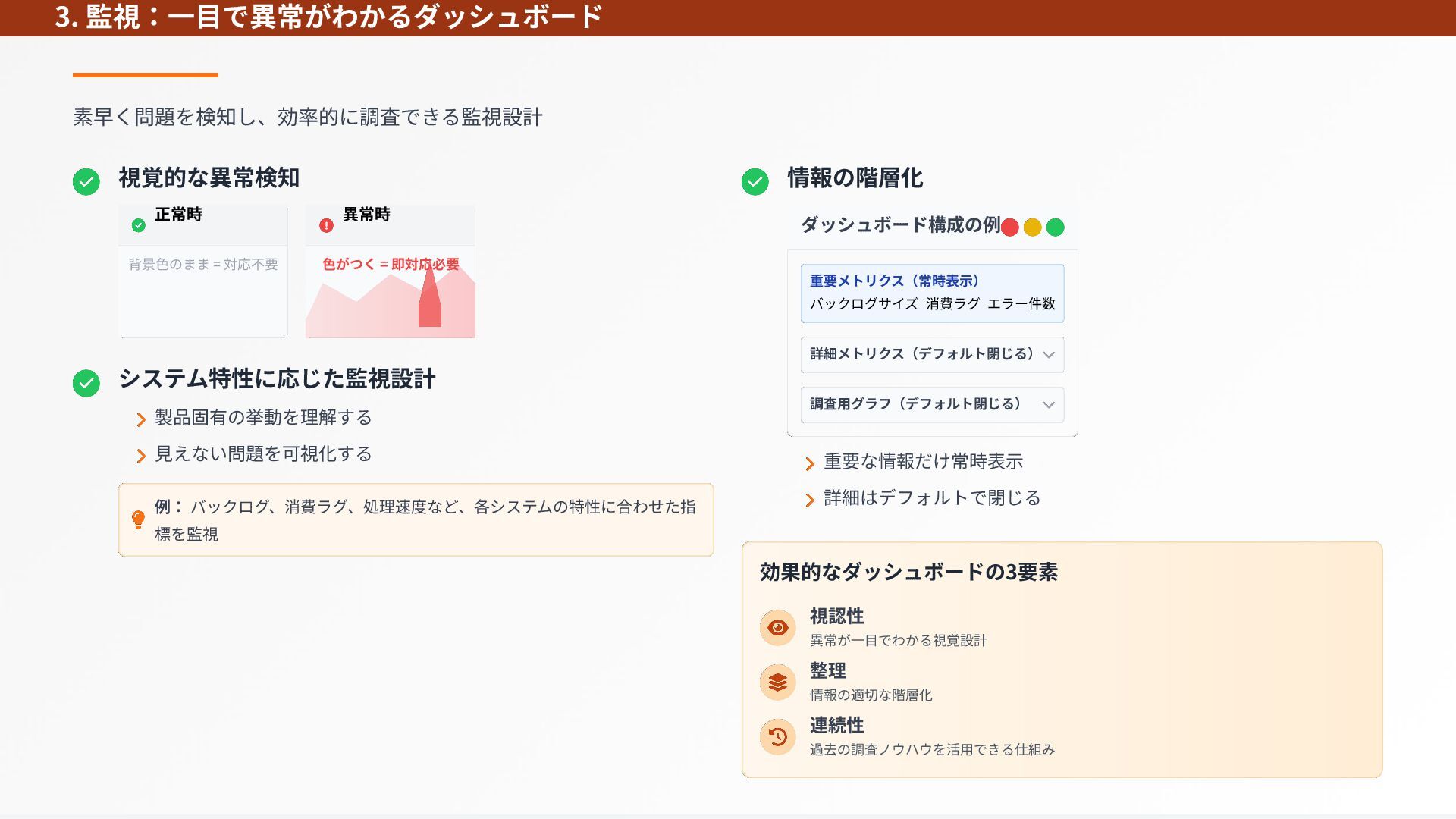{kind=link}
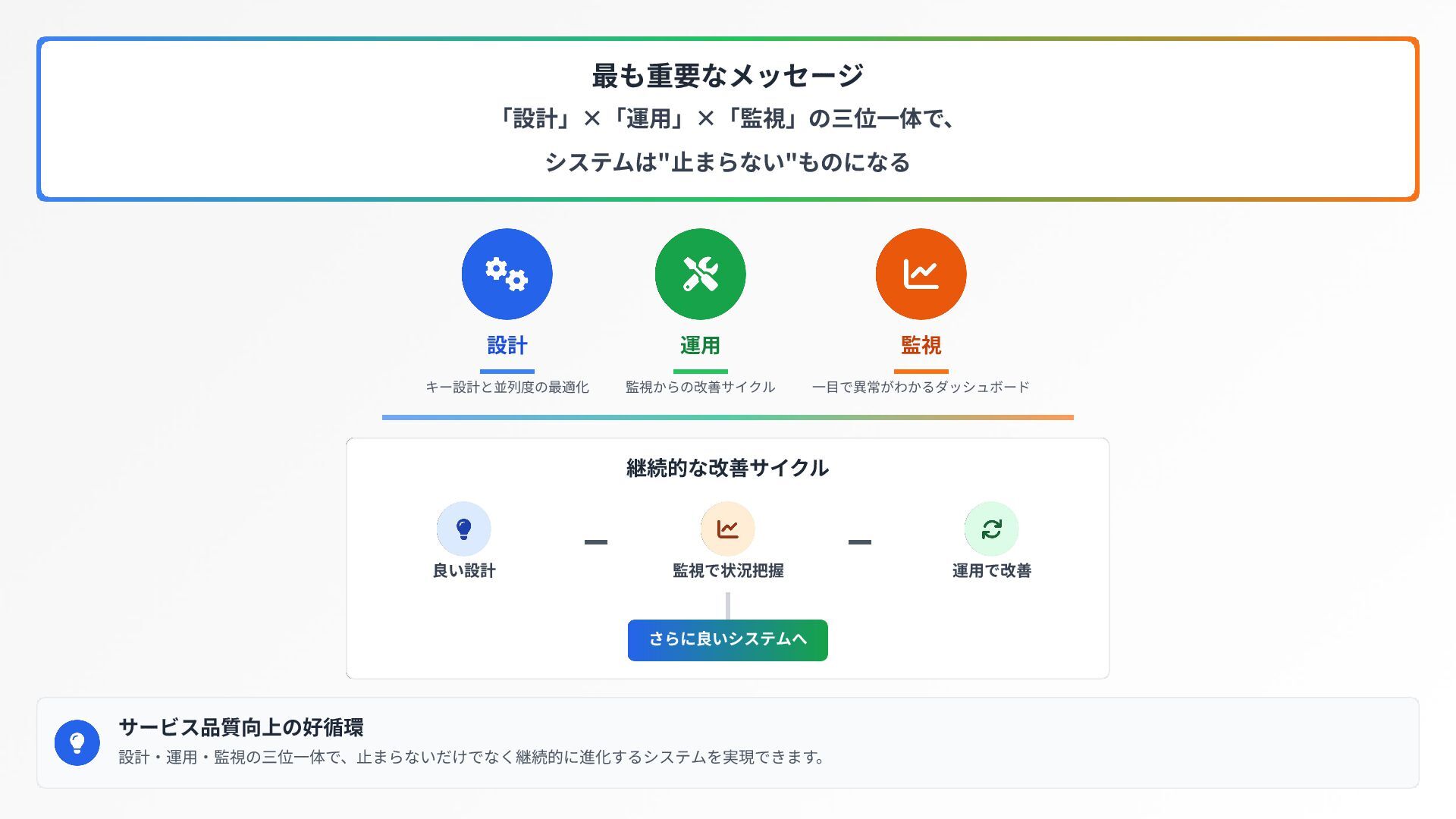{kind=link}
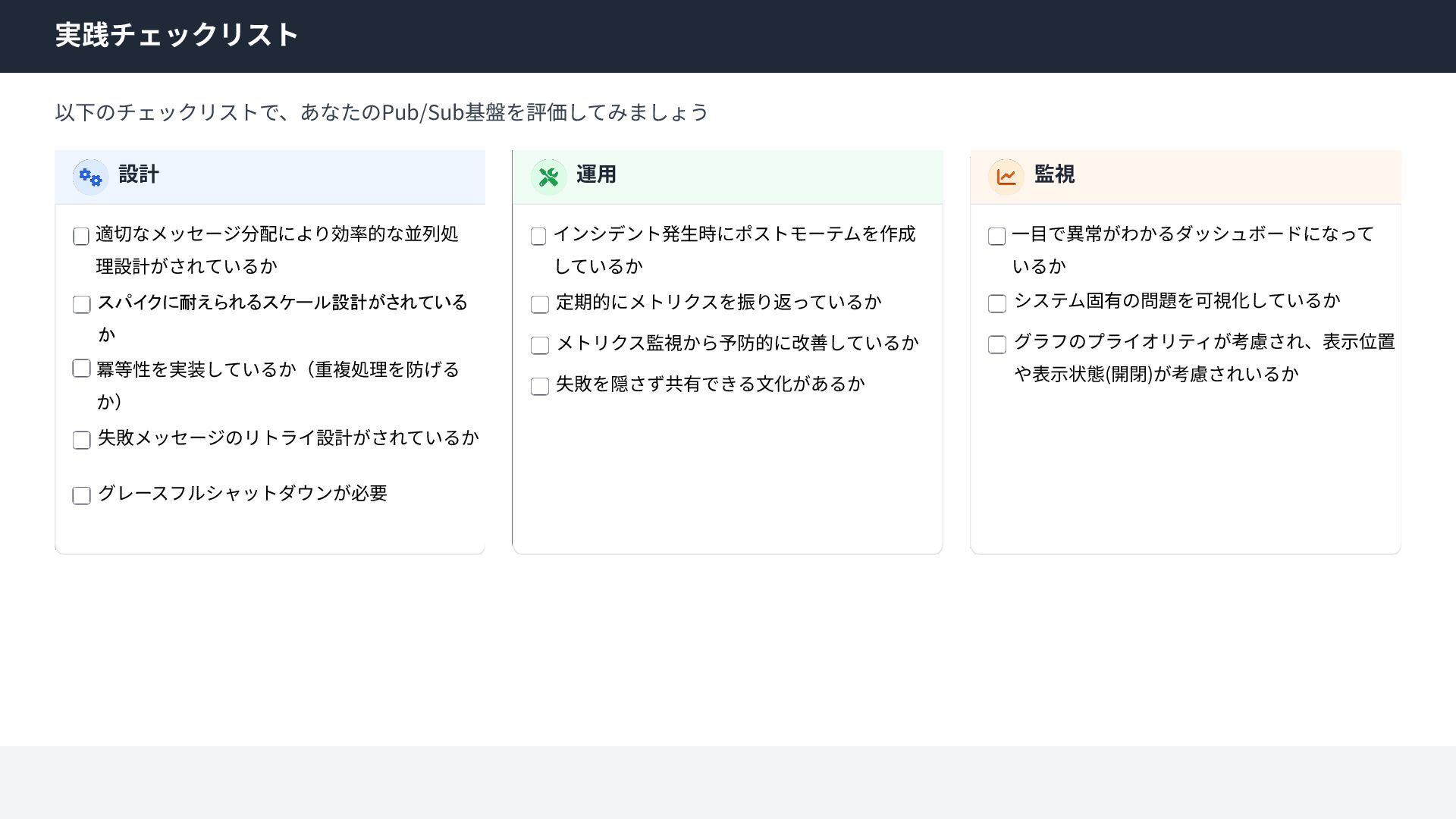{kind=link}
{kind=link}
{kind=link}
{kind=link}