• 従来の予測モデルでは何のデータを扱っているか不明なままI/Oの関係性からタスクを解いてい た⼀⽅、LIFTでは⽤いる変数が何であるかを⾃然⾔語で教えてタスクを解くことが可能 → 特徴量の名前を付けて学習することで性能向上に貢献 • Iris: 97%, MNIST: 98% , F-MNIST: 90%! (W/O Names) “When we have x1 = 1, x2 = 23, x3 = 3, x4 = 1, x5 = 19, what should be y value?” (Correct-Names I) “When we have native speaker=English speaker, course instructor=23, course=3, semester=summer, class size=19, how is the teaching performance?”
LangChainは、外部ツール(Python、電卓、Web検索、データベース)と連携できる ◦ LangChainもライブラリの総称 ◦ 元論⽂など ▪ ReAct: Synergizing Reasoning and Acting in Language Models ▪ Measuring and Narrowing the Compositionality Gap in Language Models
Model • 現在の⽣成系のトレンド(2020年のDDPM以降) • 複雑な分布x0を徐々に簡単な分布(ノイズ)xTに変換 • 各ステップで逆変換を与えるような過程を学習させることでノイズ除去ができる • ノイズから画像を復元できるように(これら⽣成時にテキスト情報などをconditionalな情報として ⼊れて、狙った画像を⽣成させる) photograph of an astronaut riding a horse
• OpenAIによるCLIP[Radford et al., 2021]などの登場により、テキストと画像の類似度が測れ るだけでなく、画像からテキストの⽣成によるZero-shot Learningも可能に CLIP: Connecting Text and Images [Radford et al., 2021]
• 有名な3モデル(Imagen, DALL-E2, Stable Diffusion)による⽣成画像の⽐較 ◦ 提案ベンチマークDrawBenchにあるプロンプトを使って画像⽣成 ◦ どれだけテキストに忠実か、リアルに近いかで評価→Imagenの出⼒が⼀番良い Imagen DALL-E2 Stable Diffusion(2.1) Hovering cow abducting aliens. A black apple and a green backpack.
モデル例 ◦ Diffsound︓拡散モデルを使ってテキストからオーディオ(10秒)を⽣成 ◦ Riffusion︓⾳楽のスペクトグラムを画像と⾒なしてテキストから⾳楽を⽣成 ▪ Stable Diffusionをスペクトログラムを⽣成するようファインチューニング funk bassline with a jazzy saxophone solo
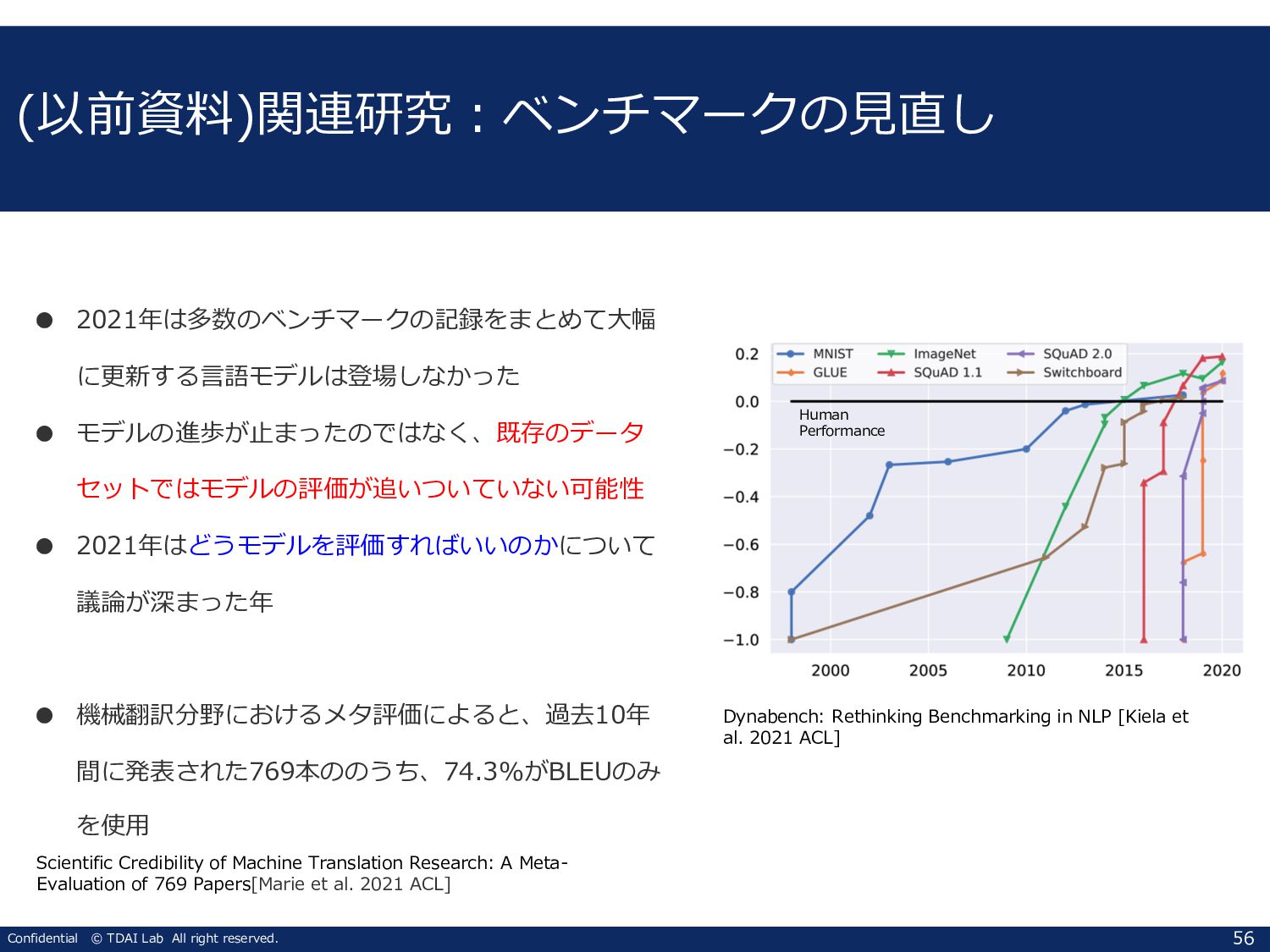
TDAI Lab All right reserved. 59 (以前資料)関連研究︓Beyond Accuracy: Behavioral Testing of NLP Models with CHECKLIST • ACL 2020 Best Paper • 従来はtrain-test-validationでのみ精度評価が⾏われることが⼀般的 • そこでチェックリストを設けることで多⾯的に性能を評価しようという試み ◦ Min Func Test︓ユニットテスト的な発想 ◦ INVariance︓摂動に対する出⼒の頑健さ(⼊⼒が多少変わっても出⼒はかわらない) ◦ DIRectional︓出⼒を変えるような変更で出⼒が変わるか
TDAI Lab All right reserved. 60 AIにAI⽤評価データを作成 • Discovering Language Model Behaviors with Model-Written Evaluations ◦ https://arxiv.org/abs/2212.09251 • LLMを⽤いてLLMの評価⽤データセットを作成した研究
Mission ⼤量のデータと最新のアルゴリズムの掛け合わせに より《今まで⼈間には分からなかったこと、データ に眠る隠れた価値の発⾒》を⾏う Vision “Augment Intelligence”(拡張知能) : The combination of HumanExpertise & MachineLearning that goes far beyond just individuals & AI Empower Your Mind using Artificial Intelligence
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}