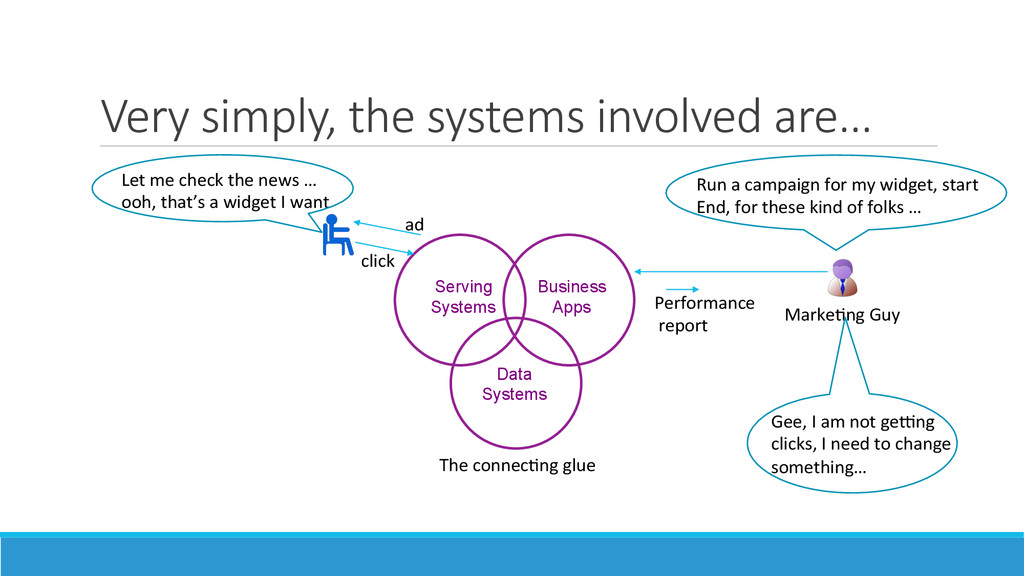
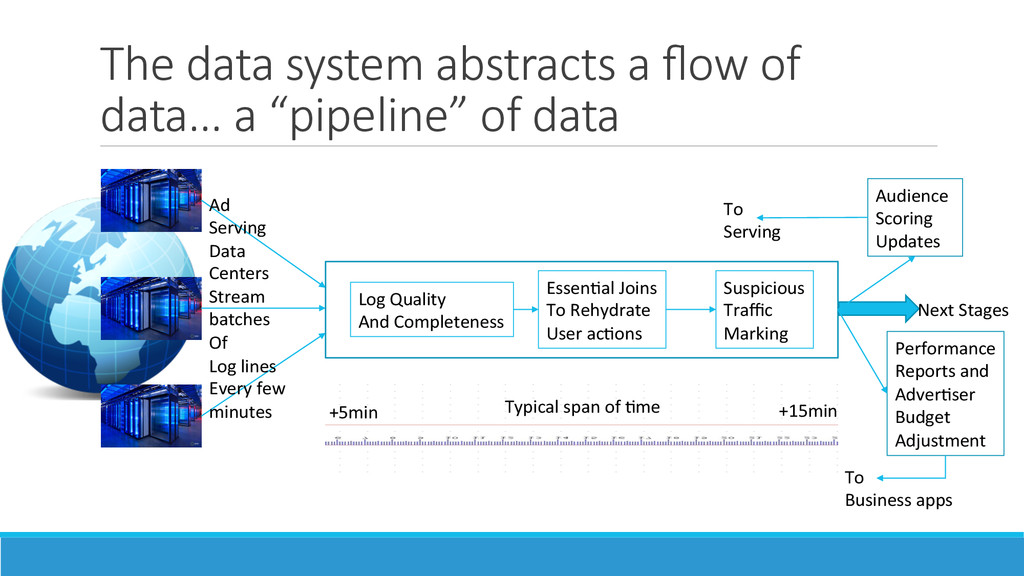
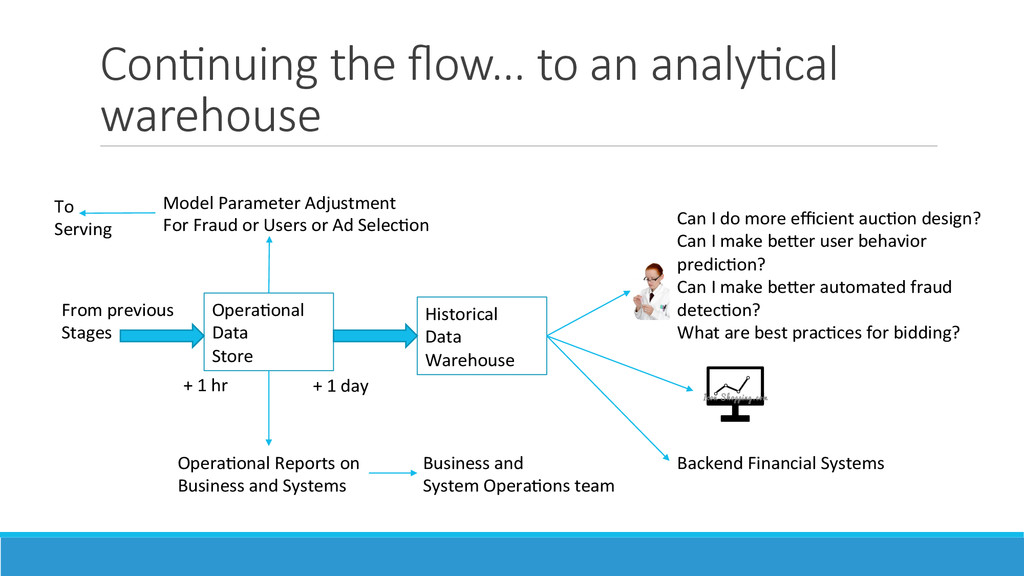
paid search adver>sements had become a dominant mone>za>on method in Internet search companies: ◦ Adver>sers liked that they paid for these adver>sements only when they were clicked – the age of “pay for performance” marke>ng had begun ◦ The cost per click (CPC) was decided by the bid placed by the adver>ser on the keywords in the search – however, only the top bidders were shown ini%ally. Later, this was replaced by a ranking of the top “expected revenue”, considering the recent history of clicks on each of the paid search adver>sements ◦ Given a handful of search companies, the adver>sers did not worry about losing an “opportunity” if they picked the right keywords and budget alloca>on among search companies usually by running some trials. 2. The world of adver>sing on web pages (display adver>sing) was however wildly different. There were so many web publishers, and liUle knowledge of who was surfing to which web page and when. 3. Most important to understand that adver%sers run product “marke>ng campaigns” for actual human eye-‐ balls. While they care about the web page or search results so that they don’t get associated with “disreputable” stuff, they don’t care that much more. They want their “demographic” from some>mes specific “geo” loca>ons, over a specified period of >me without repeatedly reaching and “>ring” the same person. The most important concepts for them are “reach” and “frequency”.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}