Today Who am I and what is this about? At Work: [email protected] On line: www.linkedin.com/in/chrisalmond/ www.twitter.com/calmo Session Description: Hadoop has quickly evolved into the system of choice for storing and processing Big Data, and is now widely used to support mission- critical applications that operate within a ‘data lake’ style infrastructures. A critical requirement of such applications is the need for continuous operation even in the event of various system failures. This requirement has driven adoption of multi-data center Hadoop architectures, a.k.a geo-distributed or global Hadoop. In this session we will provide a brief introduction to WANdisco, then dig into how our Non-Stop Hadoop solution addresses real world use cases, and also a show live demonstration of Non-Stop namenode operation across two WAN connected hadoop clusters.
Background • WANdisco: Wide Area Network Distributed Computing – Enterprise ready, high availability software solutions that enable globally distributed organizations to meet today’s data challenges of secure storage, scalability and availability • Leader in tools for software engineers – Subversion – Apache Software Foundation sponsor • Highly successful IPO, London Stock Exchange, June 2012 (LSE:WAND) • US patented active-active replication technology granted, November 2012 • Global locations – San Ramon (CA) – Chengdu (China) – Tokyo (Japan) – Boston (MA) – Sheffield (UK) – Belfast (UK)
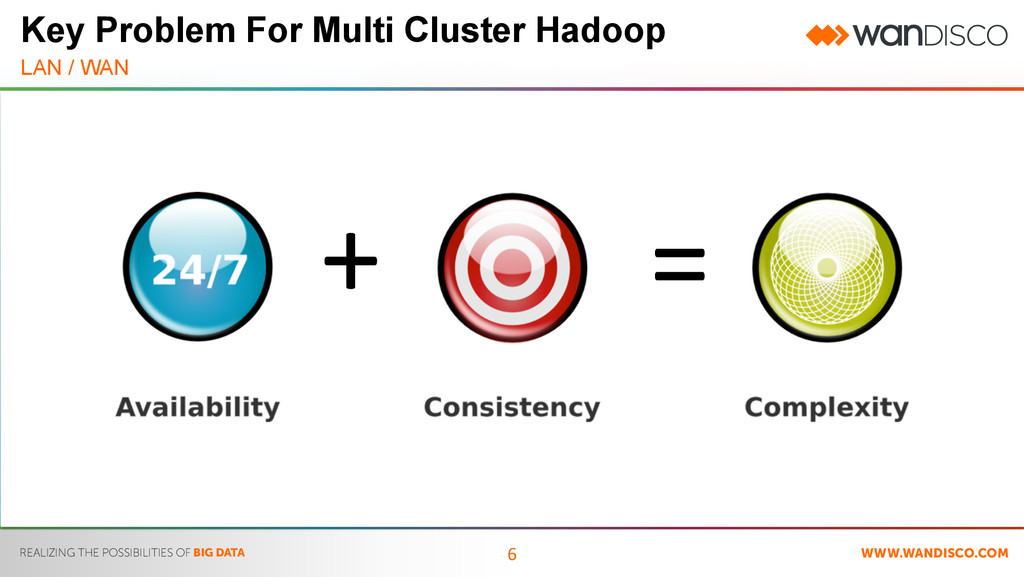
Require Continuous Availability – SLA’s, Regulatory Compliance • Require HDFS to be Deployed Globally – Share Data Between Data Centers – Data is Consistent and Not Eventual • Ease Administrative Burden – Reduce Operational Complexity – Simplify Disaster Recovery – Lower RTO/RPO • Allow Maximum Utilization of Resource – Within the Data Center – Across Data Centers Enterprise Ready Hadoop Characteristics of Mission Critical Applications
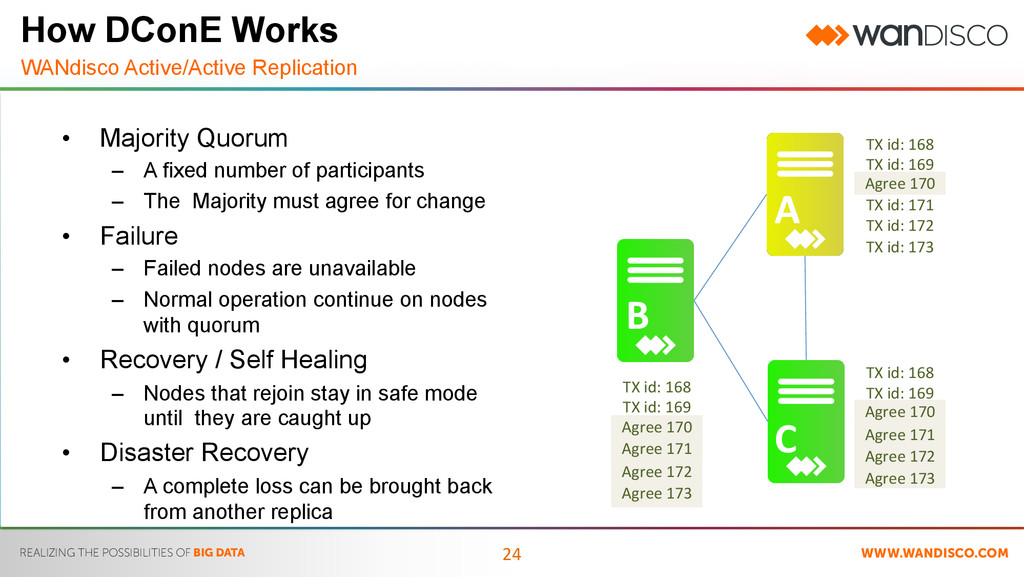
Standby • Inefficient utilization of resource – Journal Nodes – ZooKeeper Nodes – Standby Node • Performance Bottleneck • Still tied to the beeper • Limited to LAN scope Active / Active • All resources utilized – Only NameNode configuration – Scale as the cluster grows – All NameNodes active • Load balancing • Set resiliency (# of active NN) • Global Consistency Breaking Away from Active/Passive What’s in a NameNode
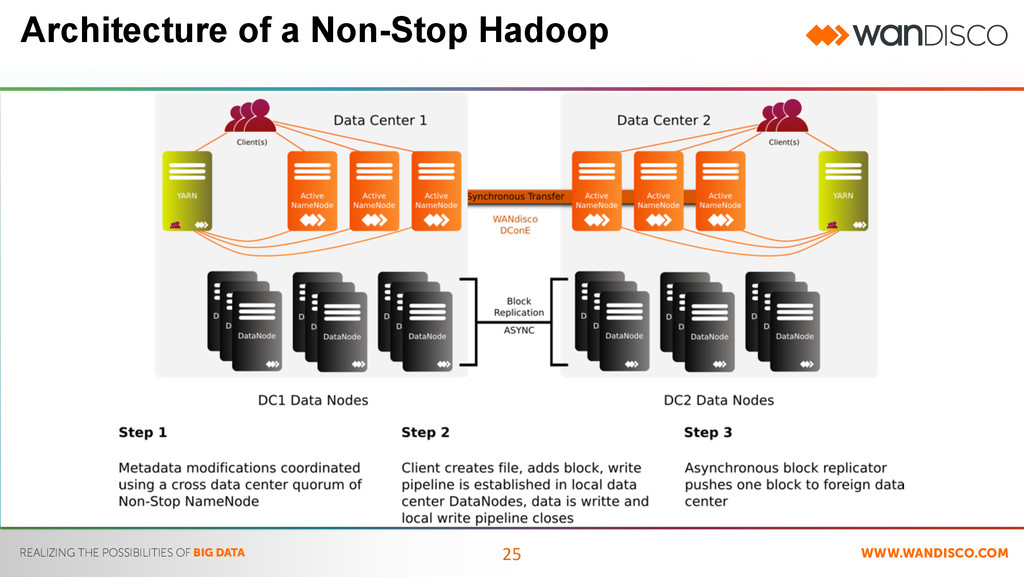
Datacenter • Idle Resource – Single Data Center Ingest – Disaster Recovery Only • One way synchronization – DistCp • Error Prone – Clusters can diverge over time • Difficult to scale > 2 Data Centers – Complexity of sharing data increases Active / Active • DR Resource Available – Ingest at all Data Centers – Run Jobs in both Data Centers • Replication is Multi-Directional – active/active • Absolute Consistency – Single HDFS spans locations • ‘N’ Data Center support – Global HDFS allows appropriate data to be shared Breaking Away from Active/Passive What’s in a Data Center
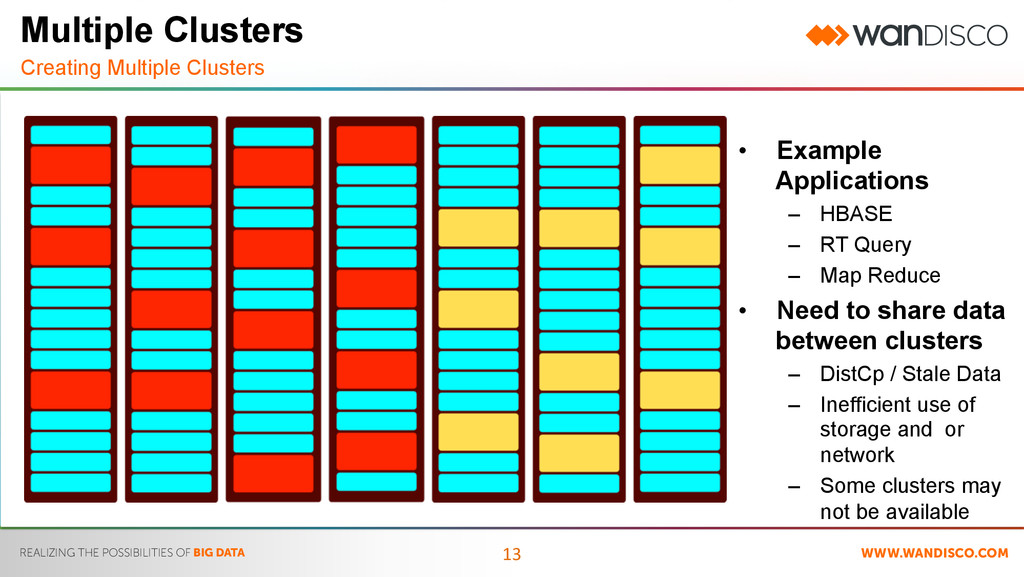
Multiple Clusters • Example Applications – HBASE – RT Query – Map Reduce • Need to share data between clusters – DistCp / Stale Data – Inefficient use of storage and or network – Some clusters may not be available Multiple Clusters
Datacenter Hadoop Disaster Recovery WAN REPLICATION Absolute Consistency Maximum Resource Use Lower Recovery Time/Point Replicate Only What You Want BeEer UHlizaHon of Power/Cooling Lower TCO LAN Speed Performance
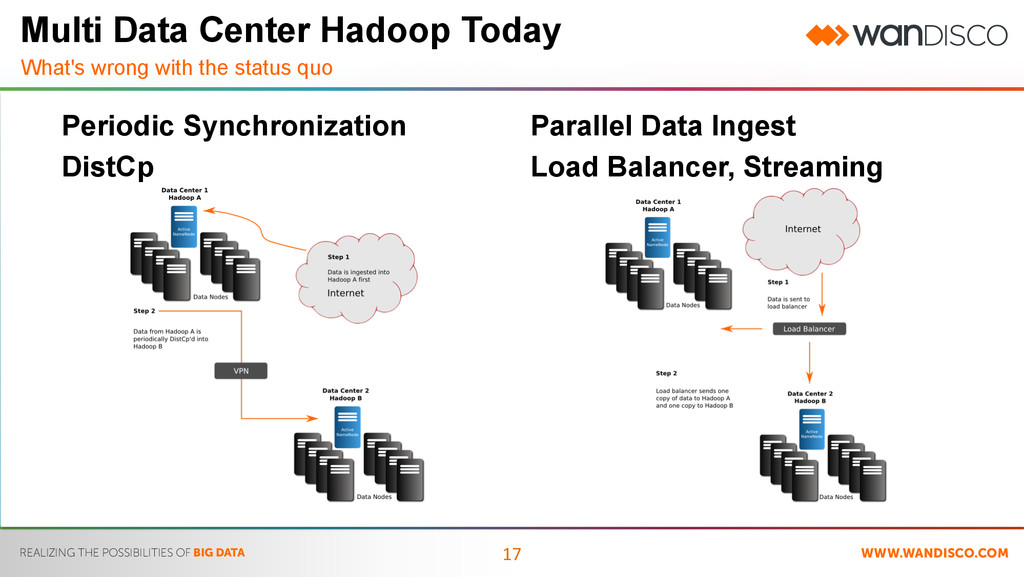
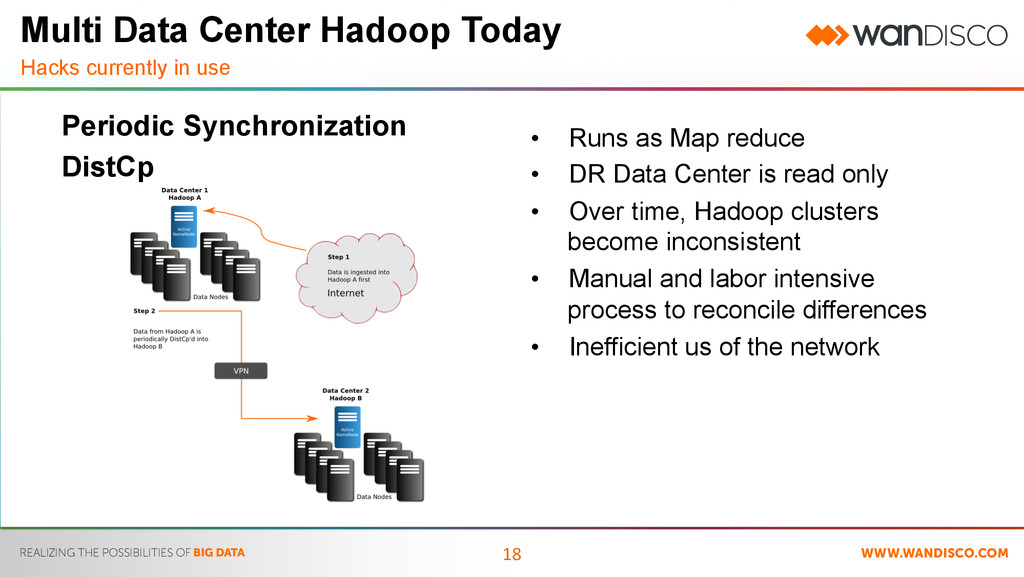
Synchronization DistCp Multi Data Center Hadoop Today Hacks currently in use • Runs as Map reduce • DR Data Center is read only • Over time, Hadoop clusters become inconsistent • Manual and labor intensive process to reconcile differences • Inefficient us of the network
Data Ingest Load Balancer, Flume Multi Data Center Hadoop Today Hacks currently in use • Hiccups in either of the Hadoop cluster causes the two file systems to diverge • Potential to run out of buffer when WAN is down • Requires constant attention and sys-admin hours to keep running • Data created on the cluster is not replicated • Use of streaming technologies (like flume) for data redirection are only for streaming
Distributed Coordination Engine • WANdisco’s patented WAN capable paxos implementation – Mathematically proven – Provides distributed co-ordination of File system metadata • Active/Active (All locations) • Create, Modify, Delete • Shared nothing (No Leader) • No restrictions on distance between datacenters – US Patent granted for time independent implementation of Paxos • Not based on SAN block device synchronization such as EMC SRDF – SAN block replication has distance limits resulting from the inability of file systems such as NTFS and ext4 to tolerate long RTTs to block storage – Possible distribution of corrupted blocks
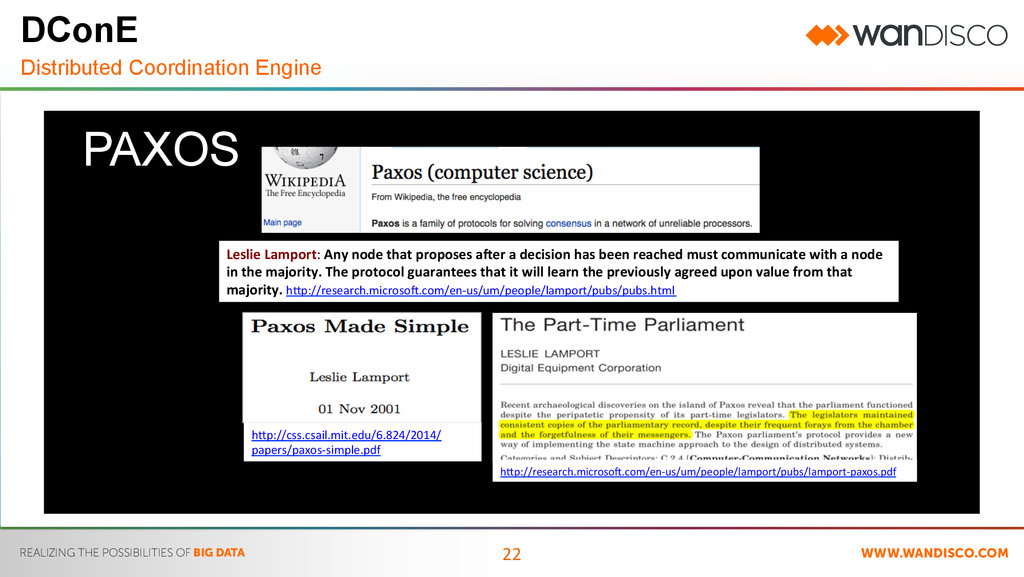
Distributed Coordination Engine • WANdisco’s patented WAN capable paxos implementation – Mathematically proven – Provides distributed co-ordination of File system metadata • Active/Active (All locations) • Create, Modify, Delete • Shared nothing (No Leader) • No restrictions on distance between datacenters – US Patent granted for time independent implementation of Paxos • Not based on SAN block device synchronization such as EMC SRDF – SAN block replication has distance limits resulting from the inability of file systems such as NTFS and ext4 to tolerate long RTTs to block storage – Possible distribution of corrupted blocks PAXOS Paxos is a family of protocols for solving consensus in a network of unreliable processors. Consensus is the process of agreeing on one result among a group of participants. This problem becomes difficult when the participants or their communication medium may experience failures.
Distributed Coordination Engine • WANdisco’s patented WAN capable paxos implementation – Mathematically proven – Provides distributed co-ordination of File system metadata • Active/Active (All locations) • Create, Modify, Delete • Shared nothing (No Leader) • No restrictions on distance between datacenters – US Patent granted for time independent implementation of Paxos • Not based on SAN block device synchronization such as EMC SRDF – SAN block replication has distance limits resulting from the inability of file systems such as NTFS and ext4 to tolerate long RTTs to block storage – Possible distribution of corrupted blocks PAXOS Leslie Lamport: Any node that proposes aDer a decision has been reached must communicate with a node in the majority. The protocol guarantees that it will learn the previously agreed upon value from that majority. hEp://research.microsoW.com/en-‐us/um/people/lamport/pubs/pubs.html hEp://research.microsoW.com/en-‐us/um/people/lamport/pubs/lamport-‐paxos.pdf hEp://css.csail.mit.edu/6.824/2014/ papers/paxos-‐simple.pdf
Distributed Coordination Engine • WANdisco’s patented WAN capable paxos implementation – Mathematically proven – Provides distributed co-ordination of File system metadata • Active/Active (All locations) • Create, Modify, Delete • Shared nothing (No Leader) • No restrictions on distance between datacenters – US Patent granted for time independent implementation of Paxos • Not based on SAN block device synchronization such as EMC SRDF – SAN block replication has distance limits resulting from the inability of file systems such as NTFS and ext4 to tolerate long RTTs to block storage – Possible distribution of corrupted blocks PAXOS “Contrary to conventional wisdom, we were able to use Paxos to build a highly available system that provides reasonable latencies for interactive applications while synchronously replicating writes across geographically distributed datacenters.“ http://www.cidrdb.org/cidr2011/Papers/ CIDR11_Paper32.pdf …
Data is as current as possible (no periodic synchs) • Doesn’t require monitoring and consistency checking • Virtually zero downtime to recover from regional data center failure • Regulatory compliance Use Case: Disaster Recovery Use Cases
Ingest and analyze anywhere • Analyze Everywhere – Fraud Detection – Equity Trading Information – New Business – Etc… • Backup Datacenter(s) can be used for work – No idle resource Use Case: Multi Data-Center Ingest and multi-tenant workloads
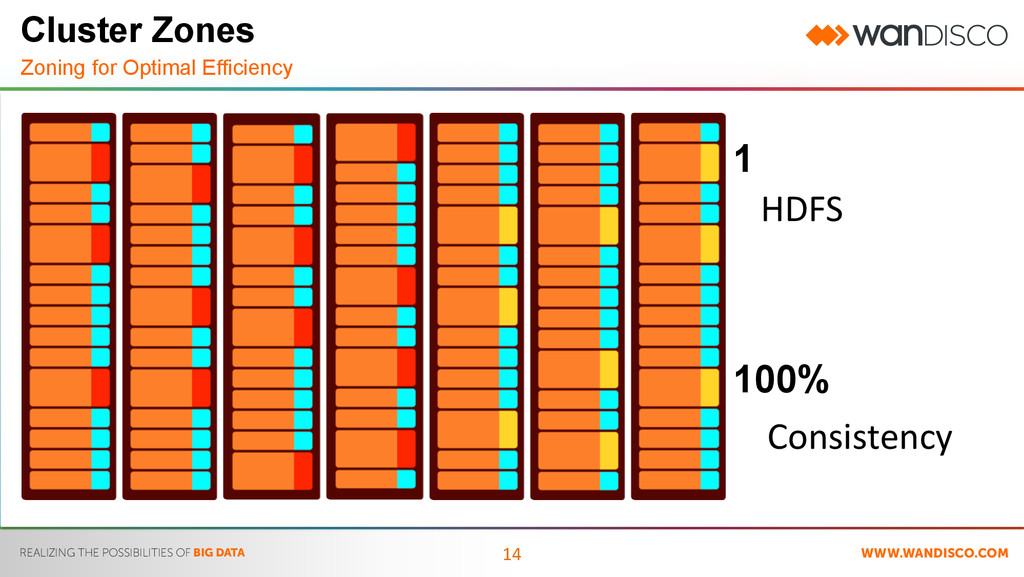
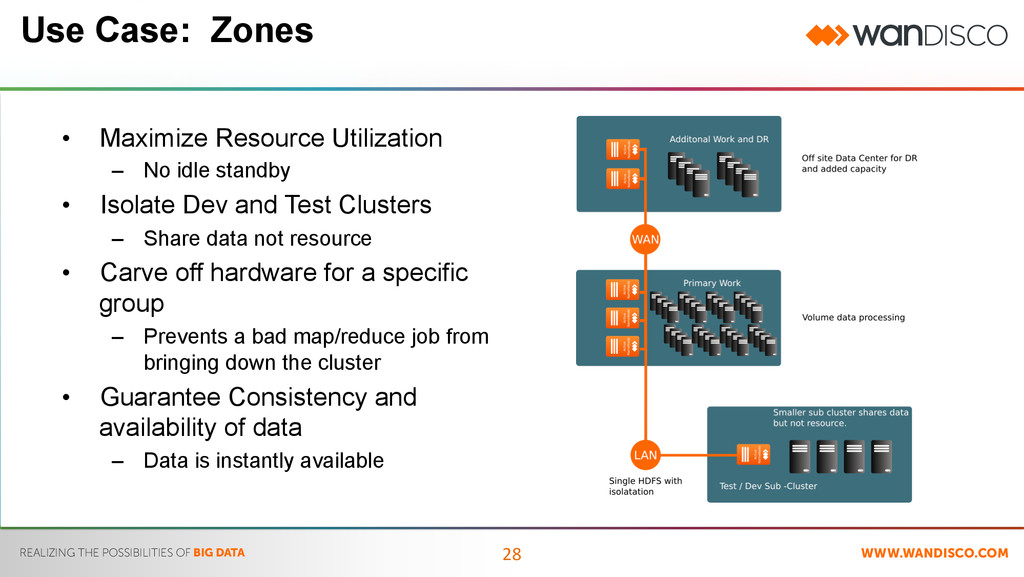
Maximize Resource Utilization – No idle standby • Isolate Dev and Test Clusters – Share data not resource • Carve off hardware for a specific group – Prevents a bad map/reduce job from bringing down the cluster • Guarantee Consistency and availability of data – Data is instantly available Use Case: Zones
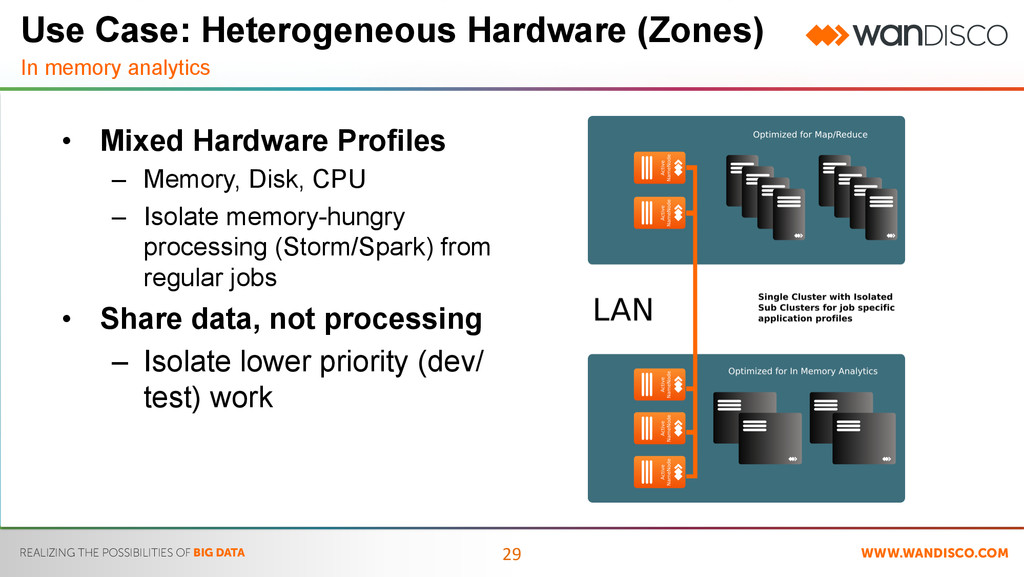
Mixed Hardware Profiles – Memory, Disk, CPU – Isolate memory-hungry processing (Storm/Spark) from regular jobs • Share data, not processing – Isolate lower priority (dev/ test) work Use Case: Heterogeneous Hardware (Zones) In memory analytics
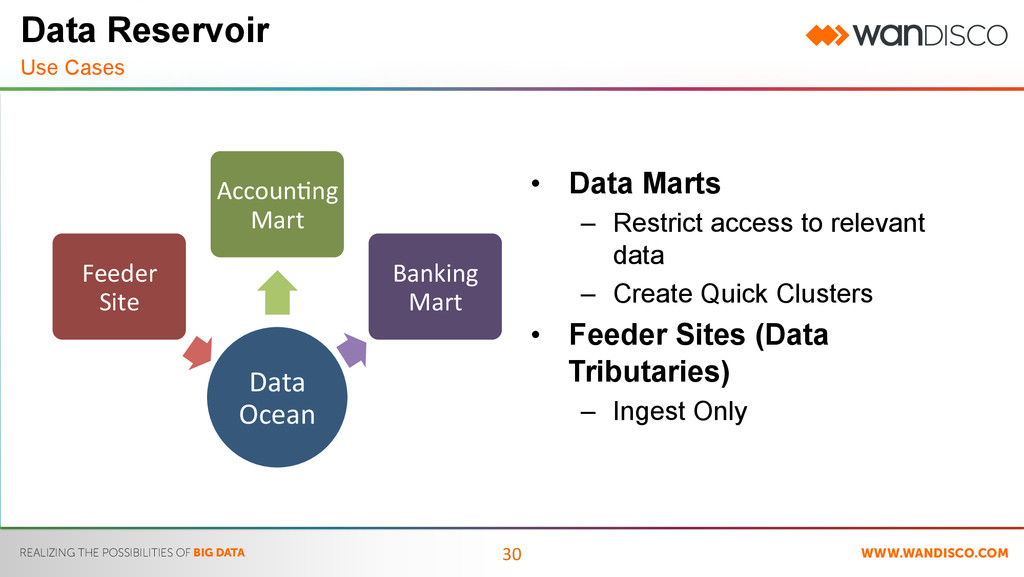
Ocean Feeder Site AccounHng Mart Banking Mart • Data Marts – Restrict access to relevant data – Create Quick Clusters • Feeder Sites (Data Tributaries) – Ingest Only Data Reservoir Use Cases
Basel III – Consistency of Data • Data Privacy Directive – Data Sovereignty • data doesn’t leave country of origin Compliance RegulaHon Guidelines Regulatory Compliance
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}