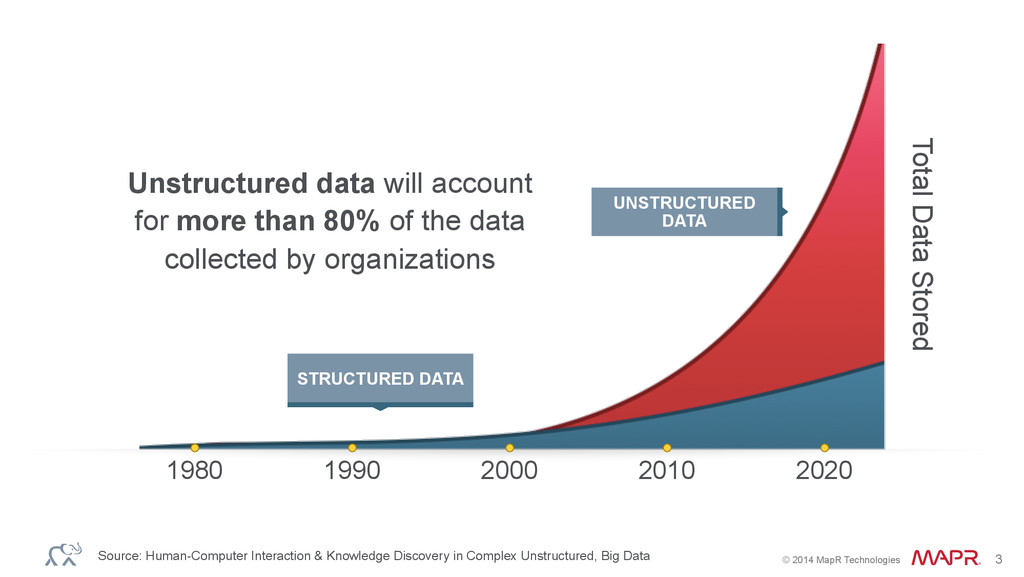
1980 2000 2010 1990 2020 Unstructured data will account for more than 80% of the data collected by organizations Source: Human-Computer Interaction & Knowledge Discovery in Complex Unstructured, Big Data Total Data Stored
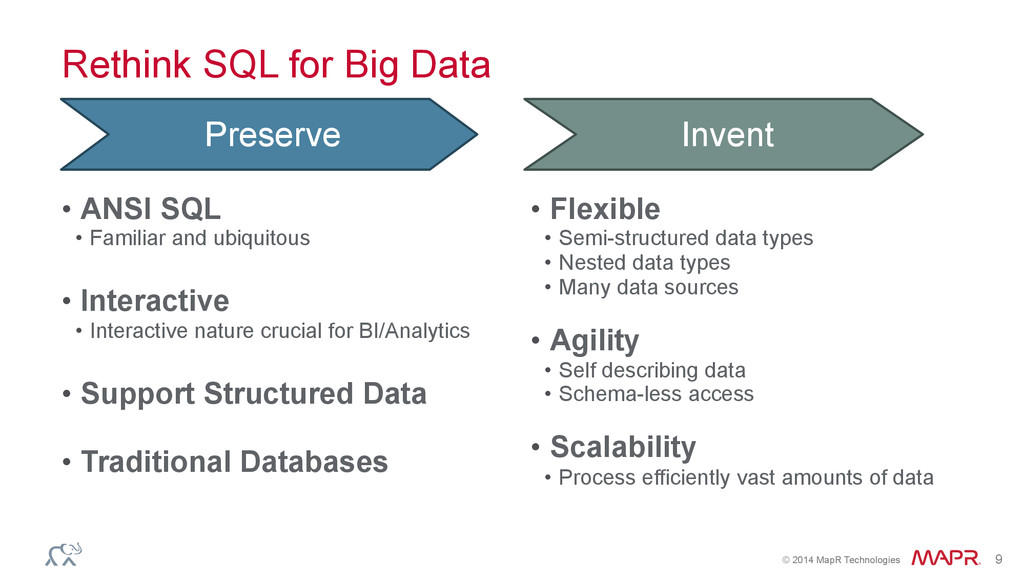
Data • ANSI SQL • Familiar and ubiquitous • Interactive • Interactive nature crucial for BI/Analytics • Support Structured Data • Traditional Databases • Flexible • Semi-structured data types • Nested data types • Many data sources • Agility • Self describing data • Schema-less access • Scalability • Process efficiently vast amounts of data Preserve Invent
on Hadoop is limited select * from A where exists ( select 1 from B where B.b < 100 ); Did you know Apache HIVE cannot compute this query? – e.g. Hive, Impala, Spark SQL
handled at all select cf.month, cf.year from hbase.table1; • Did you know normal SQL cannot handle the above? • Nor can HIVE and its variants like Impala, Shark? • Because there’s no meta-store definition available
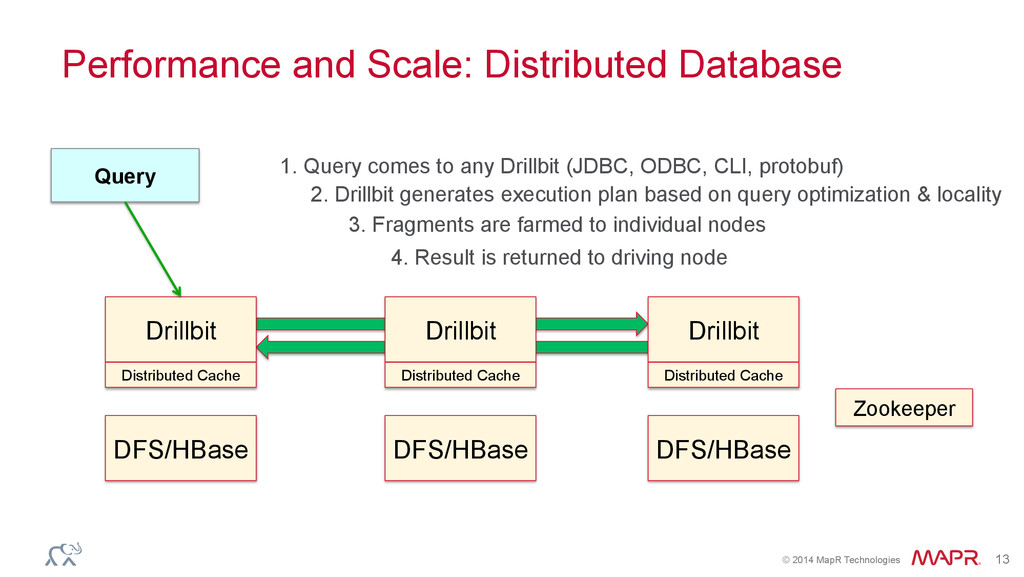
Database Zookeeper DFS/HBase DFS/HBase DFS/HBase Drillbit Distributed Cache Drillbit Distributed Cache Drillbit Distributed Cache Query 1. Query comes to any Drillbit (JDBC, ODBC, CLI, protobuf) 2. Drillbit generates execution plan based on query optimization & locality 3. Fragments are farmed to individual nodes 4. Result is returned to driving node
Spill Capability • Random access: sort without copy or restructuring • Avoids serialization/deserialization • Off-heap (no GC woes when lots of memory) • Full specification + off-heap + batch – Enables C/C++ operators (fast!) • Read/write to disk – when data larger than memory DISK Drill Bit Memory overflow uses disk
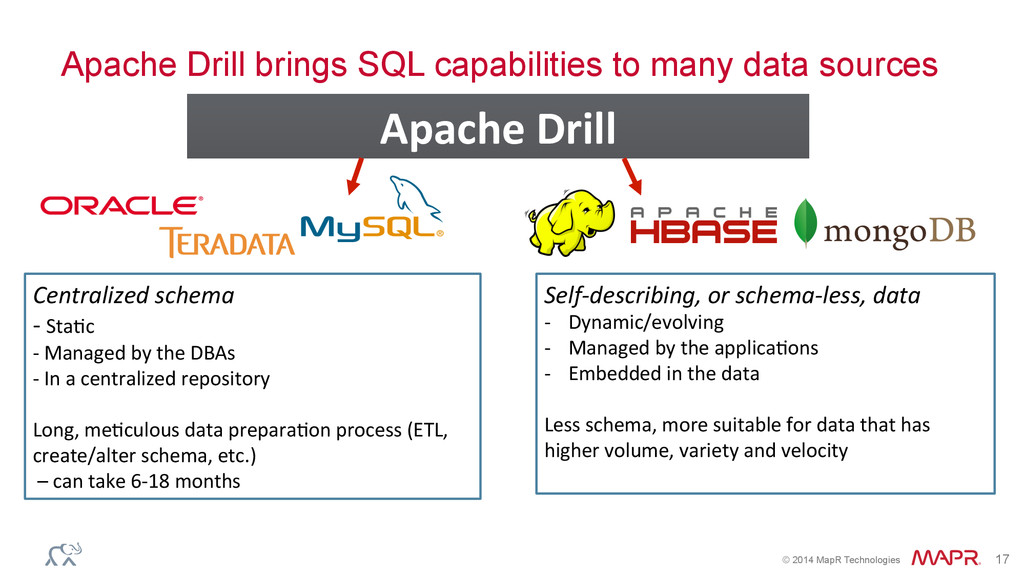
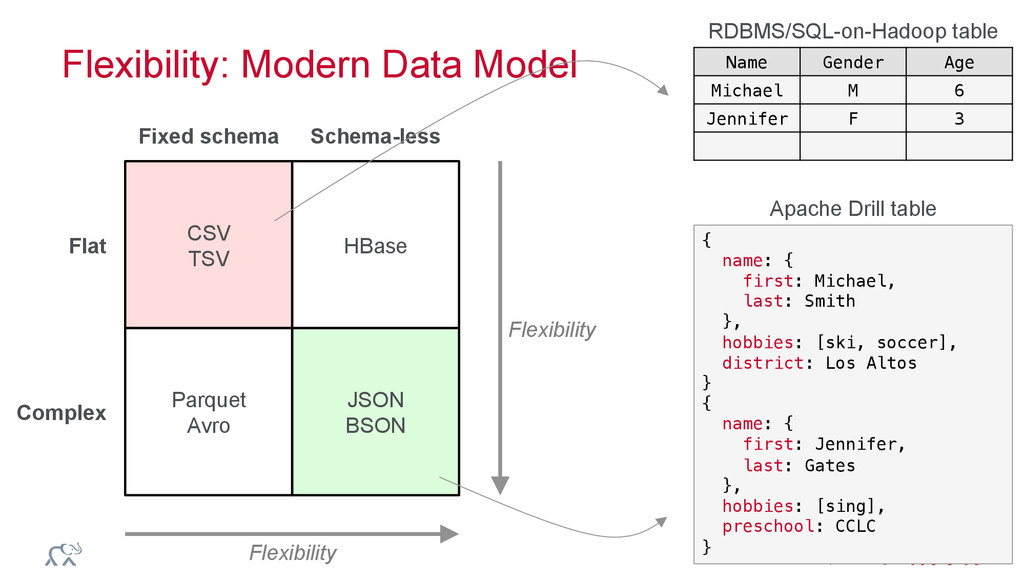
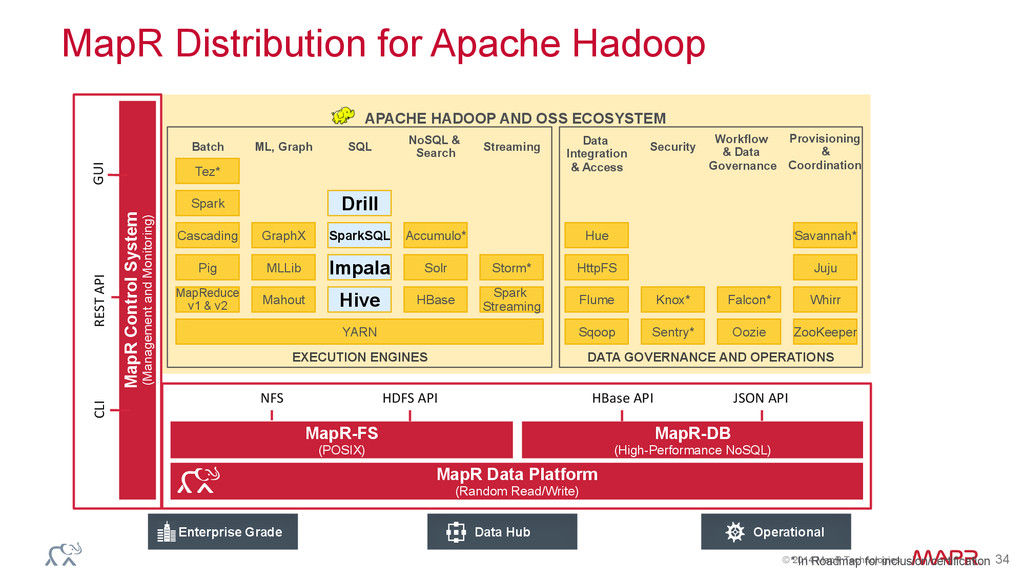
capabilities to many data sources Centralized schema -‐ Sta&c -‐ Managed by the DBAs -‐ In a centralized repository Long, me&culous data prepara&on process (ETL, create/alter schema, etc.) – can take 6-‐18 months Self-‐describing, or schema-‐less, data -‐ Dynamic/evolving -‐ Managed by the applica&ons -‐ Embedded in the data Less schema, more suitable for data that has higher volume, variety and velocity Apache Drill
“NAME”: “Fairmont San Francisco”, “DESCRIPTION”: “Historic grandeur…”, “AVG_REVIEWER_SCORE”: “4.3”, “AMENITY”: {“TYPE”: “gym”, DESCRIPTION: “fitness center” }, {“TYPE”: “wifi”, “DESCRIPTION”: “free wifi”}, “RATE_TYPE”: “nightly”, “PRICE”: “$199”, “REVIEWS”: [“review_1”, “review_2”], “ATTRACTIONS”: “Chinatown”, } JSON Drill Flexible Schema Management HotelID AmenityID 1 1 1 2 ID Type Descriptio n 1 Gym Fitness center 2 Wifi Free wifi Drill doesn’t require any schema definitions to query data making it faster to get insights from data for users. Drill leverages schema definitions if exists.
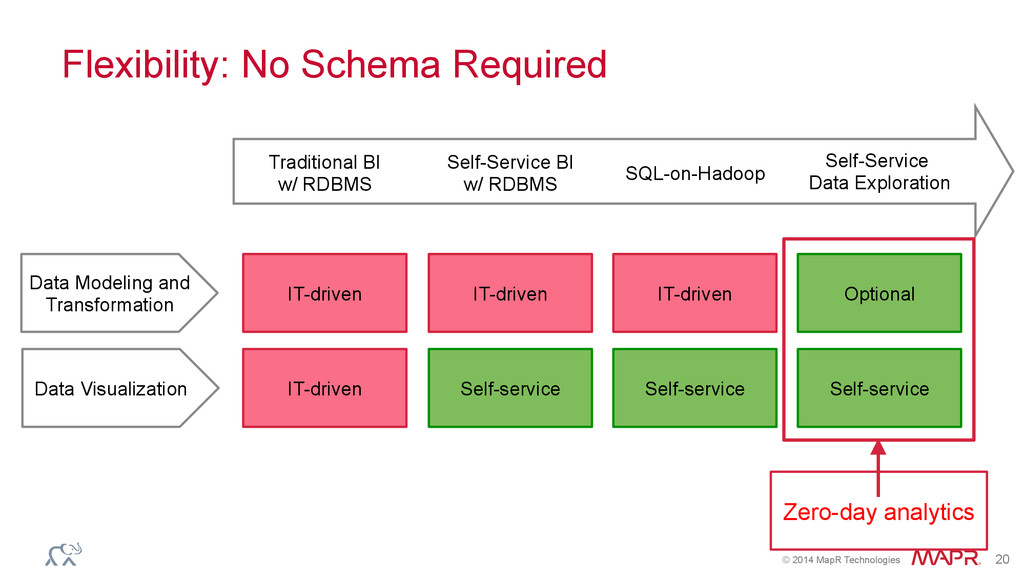
Data Modeling and Transformation Data Visualization IT-driven IT-driven IT-driven Self-service IT-driven Self-service Optional Self-service Traditional BI w/ RDBMS Self-Service BI w/ RDBMS SQL-on-Hadoop Self-Service Data Exploration Zero-day analytics
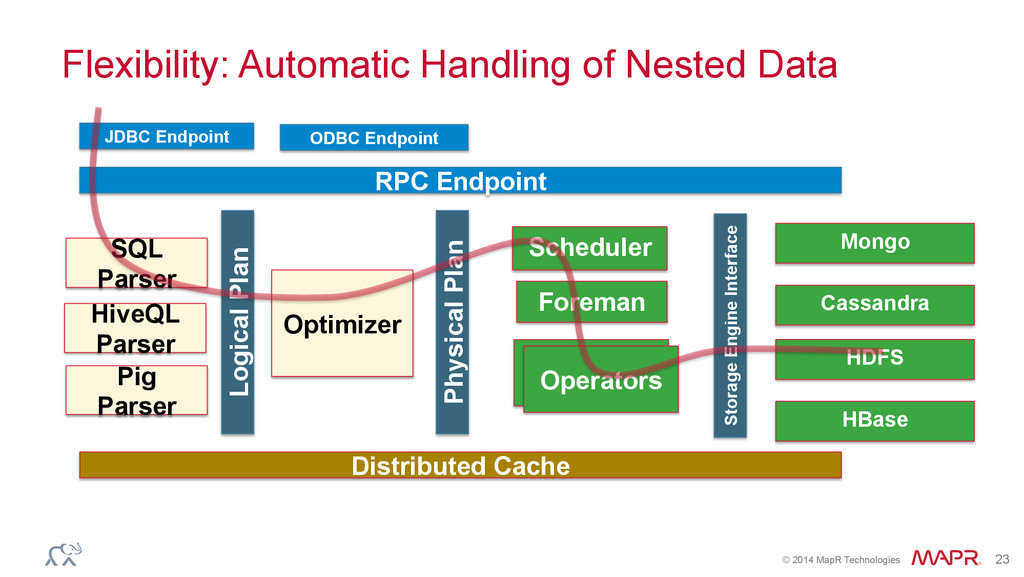
the Fly • Schema can change over course of query • Operators are able to reconfigure themselves on schema change events – Minimize flexibility overhead – Support more advanced execution optimization based on actual data characteristics
mean? • No ETL • Reach out directly to the particular table/file • As long as the permissions are fine, you can do it • No need to have the meta-data – None needed
on the fly • JSON • CSV • ORC (ie, all Hive types) • Parquet • HBase tables • … can combine them Select USERS.name, USERS.emails.work from dfs.logs.`/data/logs` LOGS, dfs.users.`/profiles.json` USERS, where LOGS.uid = USERS.uid and errorLevel > 5 order by count(*);
• Low latency queries on Hive tables • Support for 100s of Hive file formats • Ability to reuse Hive UDFs • Support for multiple Hive metastores in a single query
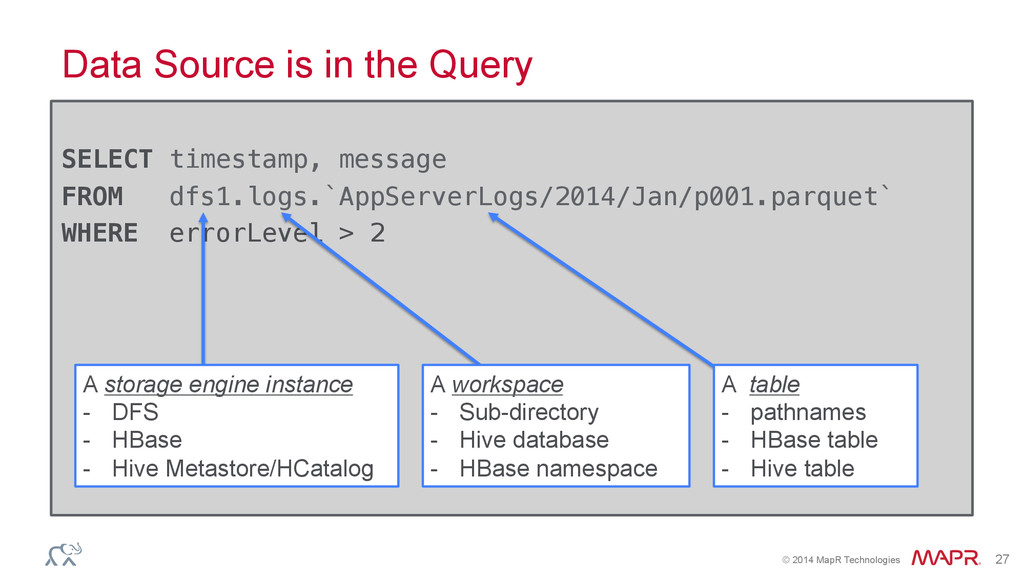
FROM dfs1.logs.`AppServerLogs/2014/Jan/p001.parquet` ! WHERE errorLevel > 2! Data Source is in the Query A storage engine instance - DFS - HBase - Hive Metastore/HCatalog A workspace - Sub-directory - Hive database - HBase namespace A table - pathnames - HBase table - Hive table
file select errorLevel, count(*) from dfs.logs.`/AppServerLogs/2014/Jan/ part0001.parquet` group by errorLevel; // On the entire data collection: all years, all months select errorLevel, count(*) from dfs.logs.`/AppServerLogs` group by errorLevel Examples: Can be an entire directory tree
number of tweets per customer, where the customers are in Hive, and their tweets are in HBase. Note that the hbase data has no meta-data information select c.customerName, hb.tweets.count from hive.CustomersDB.`Customers` c join hbase.user.`SocialData` hb on c.customerId = convert_from( hb.rowkey, UTF-8); Examples: De-centralized metadata
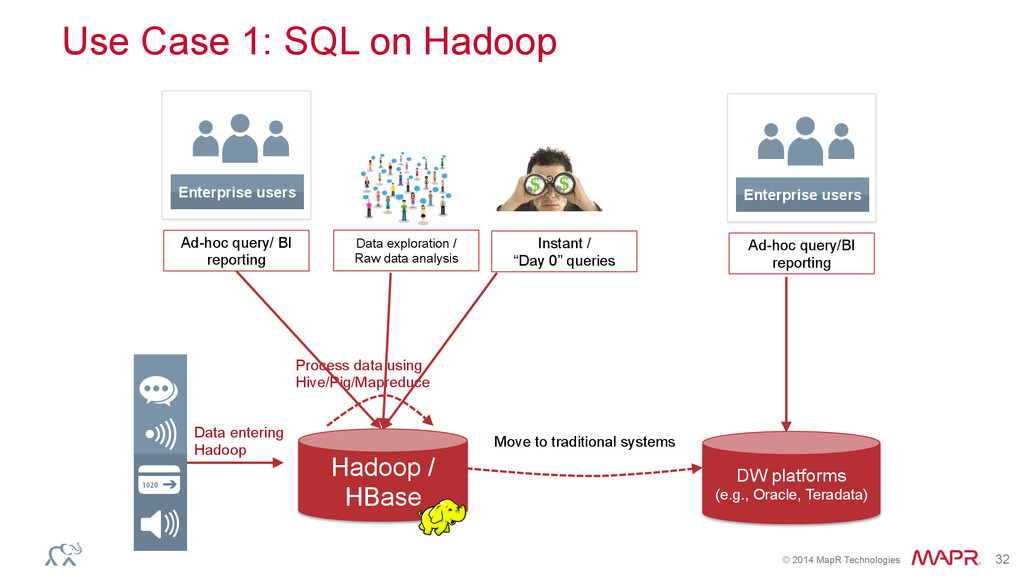
/ HBase DW platforms (e.g., Oracle, Teradata) Move to traditional systems Use Case 1: SQL on Hadoop Process data using Hive/Pig/Mapreduce Data exploration / Raw data analysis Enterprise users Ad-hoc query/BI reporting Enterprise users Ad-hoc query/ BI reporting Instant / “Day 0” queries
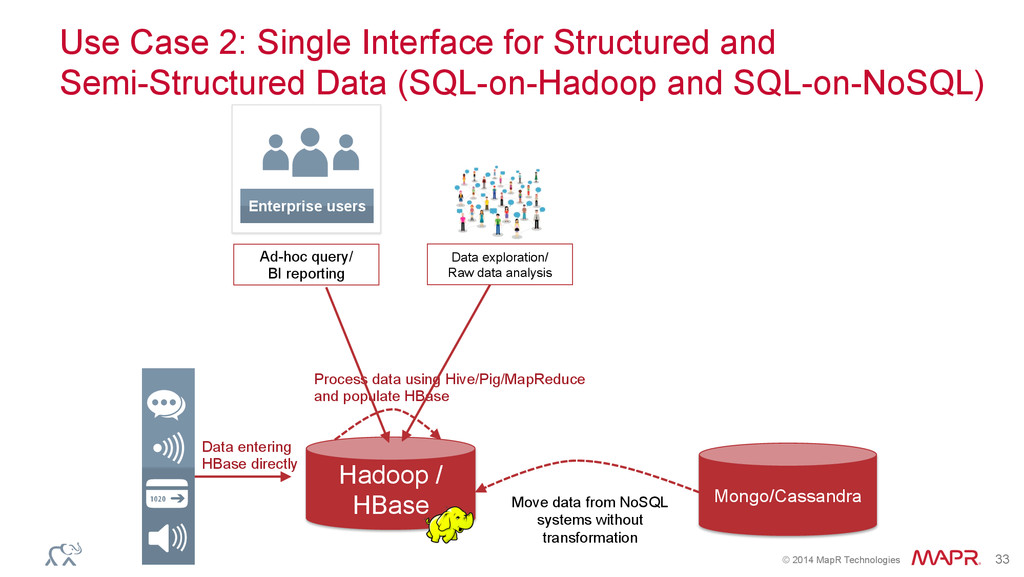
Hadoop / HBase Mongo/Cassandra Move data from NoSQL systems without transformation Use Case 2: Single Interface for Structured and Semi-Structured Data (SQL-on-Hadoop and SQL-on-NoSQL) Process data using Hive/Pig/MapReduce and populate HBase Data exploration/ Raw data analysis Enterprise users Ad-hoc query/ BI reporting
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}