Applications & Platforms since 2007 • Twitter handle: @nmotgi • Previously • Architect & Engineering Lead C.O.R.E @ Yahoo! • Altera and FedEx Who am I ?
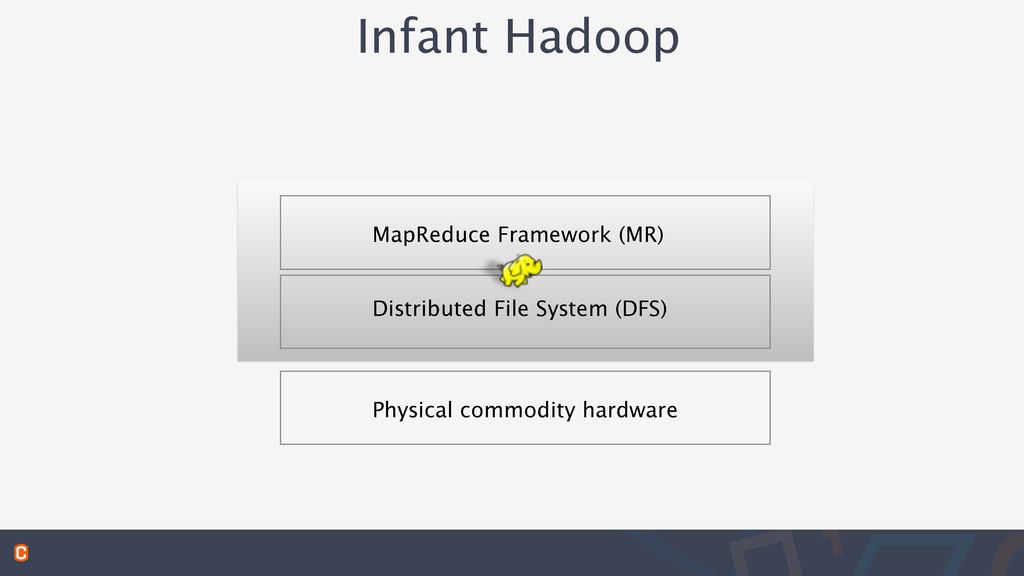
• Mul-=users,%with%queues,%priori-es,%etc…% HDFS%–%Hadoop%Distributed%File%System% • Data%replicated%on%3%computers% • Automa9cally%replaces%lost%data%/% computers% • Very%high%bandwidth,%not%IOPs%op9mized% • Scalable • Efficient storage and processing of petabytes of data • Scale linearly by adding commodity hardware • Reliable • Ability to self heal on hardware failures • Flexible • Store all types of data in many formats • Economical • Open Source - no vendor lock-in • Commodity hardware Storage Processing
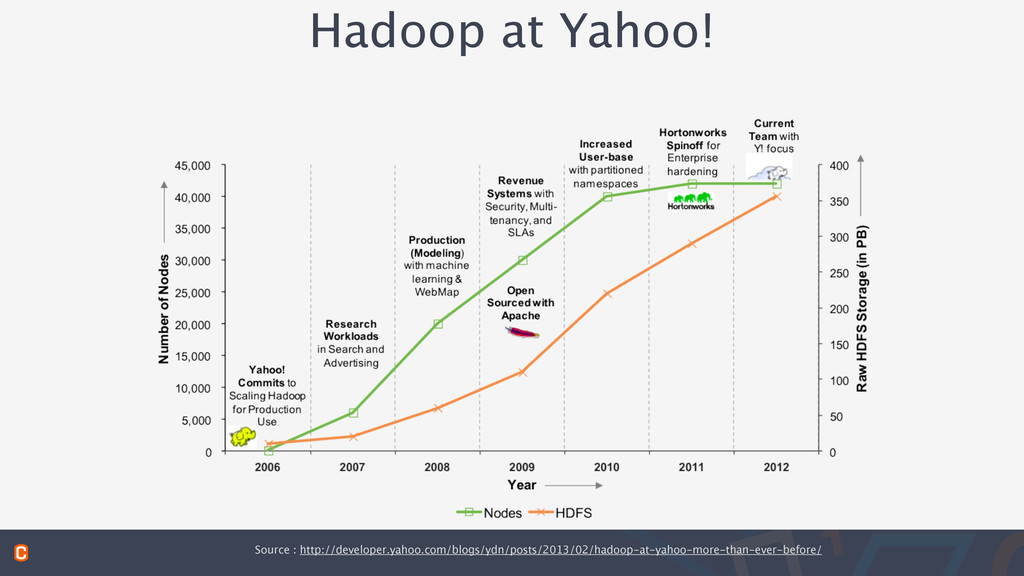
(GFS) and MapReduce papers • 2005 • Yahoo staffs Juggernaut, open source DFS & MapReduce • Differentiate via Open Source contributions • Avoid building proprietary systems that will be obsolesced • Leverage wider community for building one infrastructure • Doug Cutting starts Nutch DFS & MapReduce and joins Yahoo! • 2006 • Hadoop is born! - Science clusters were launched as early POC • Yahoo! commits to Hadoop and scaling Hadoop • Yahoo starts a Hadoop team
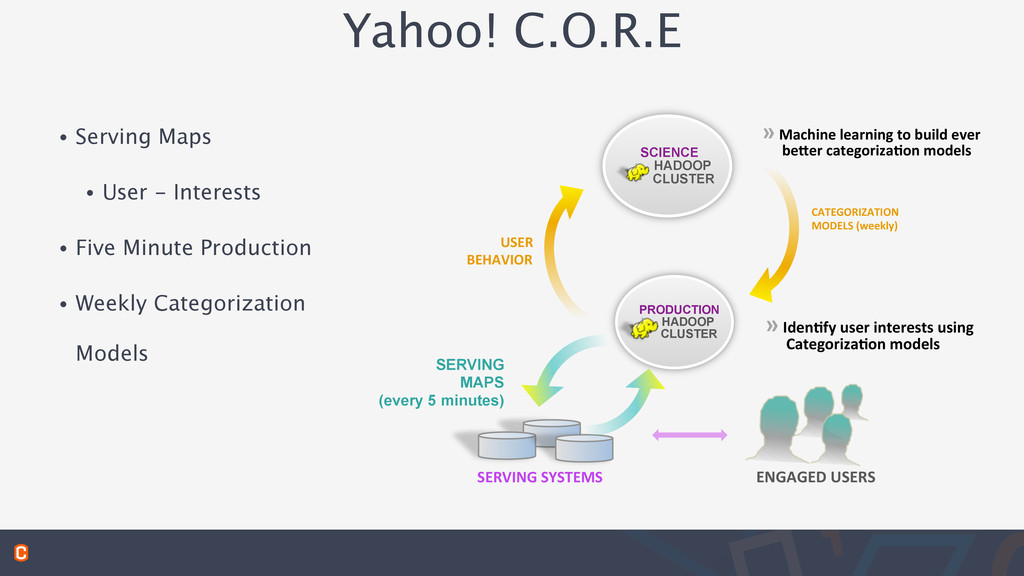
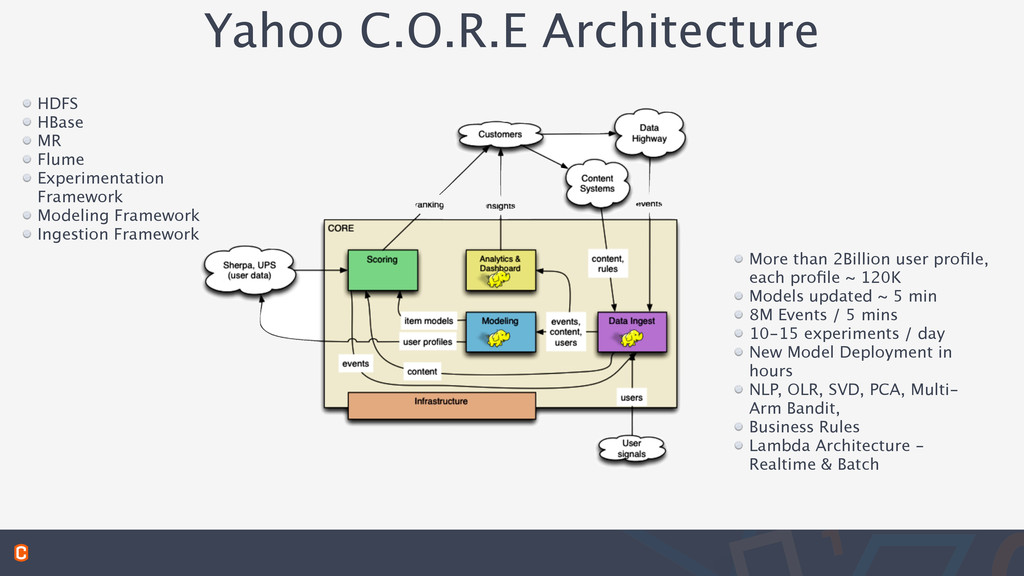
Framework Ingestion Framework More than 2Billion user profile, each profile ~ 120K Models updated ~ 5 min 8M Events / 5 mins 10-15 experiments / day New Model Deployment in hours NLP, OLR, SVD, PCA, Multi- Arm Bandit, Business Rules Lambda Architecture - Realtime & Batch
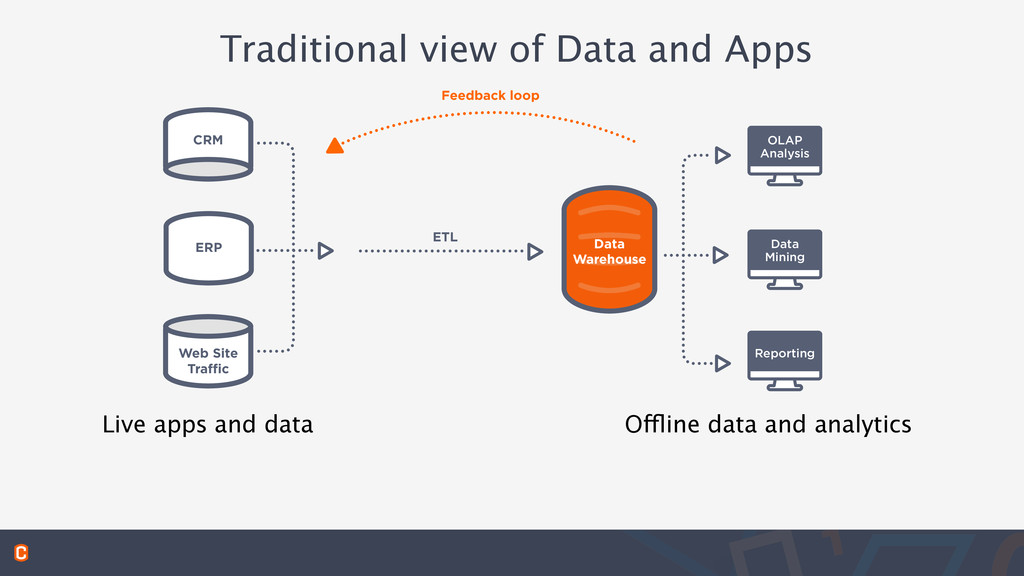
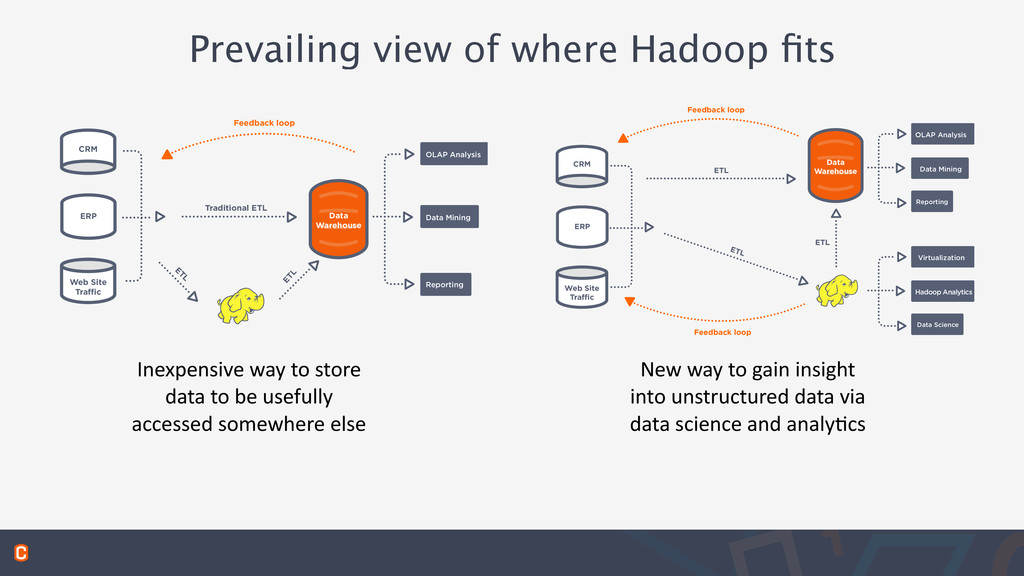
data to be usefully accessed somewhere else New way to gain insight into unstructured data via data science and analy:cs Data Warehouse CRM Web Site Traffic ERP Feedback loop Traditional ETL ETL ETL Reporting Data Mining OLAP Analysis CRM Web Site Traffic ERP Data Warehouse Feedback loop Feedback loop ETL ETL ETL Reporting Data Science Virtualization Hadoop Analytics Data Mining OLAP Analysis
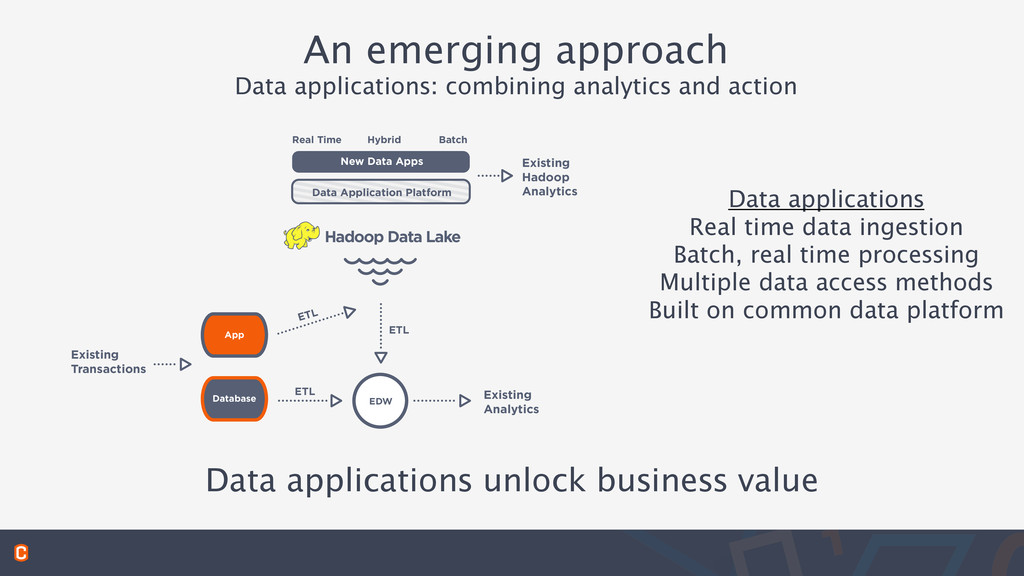
applications Real time data ingestion Batch, real time processing Multiple data access methods Built on common data platform Data applications unlock business value EDW Existing Transactions Real Time Hybrid Batch Hadoop Data Lake Existing Analytics Existing Hadoop Analytics App Database ETL ETL ETL Data Application Platform New Data Apps
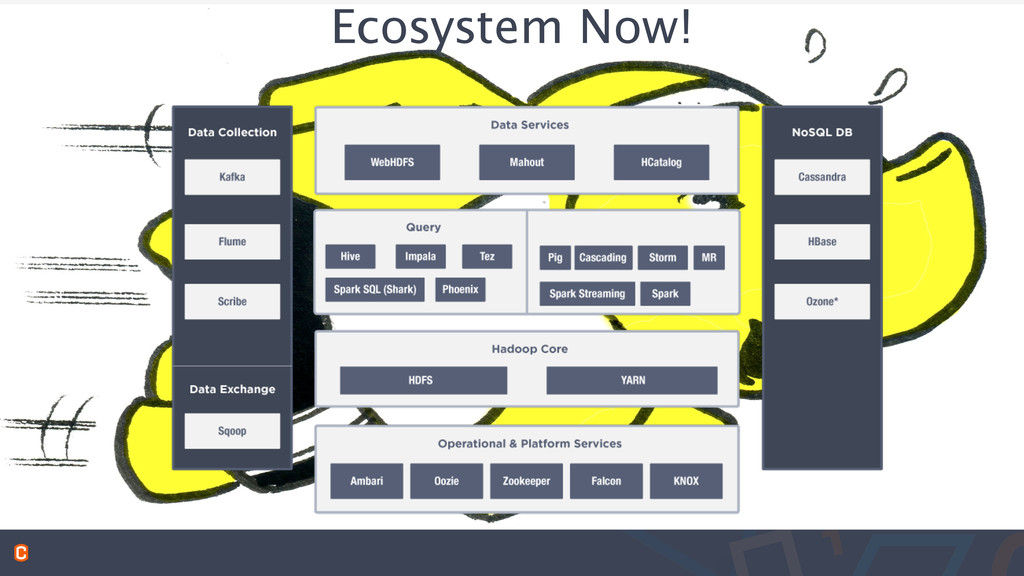
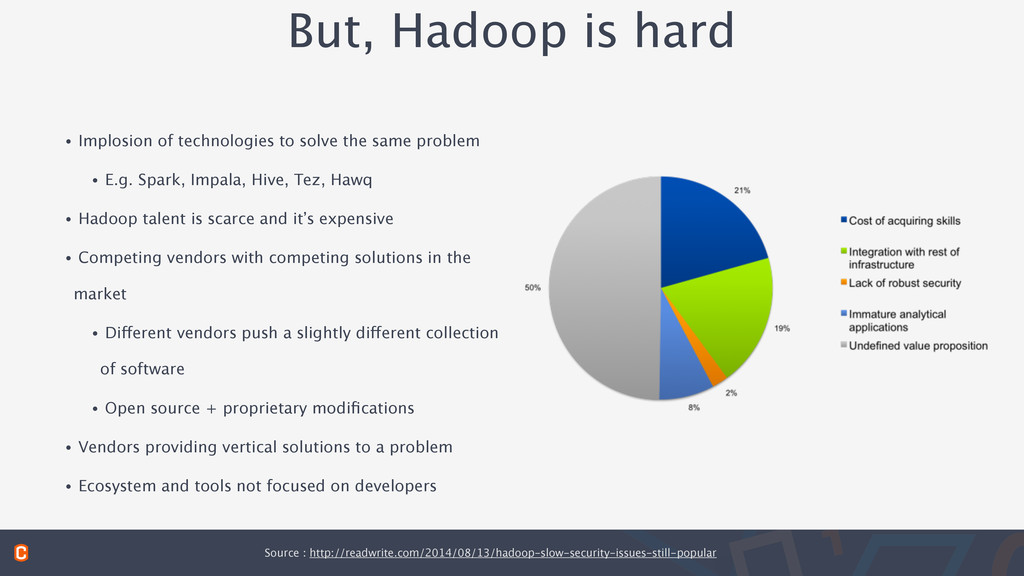
the same problem • E.g. Spark, Impala, Hive, Tez, Hawq • Hadoop talent is scarce and it’s expensive • Competing vendors with competing solutions in the market • Different vendors push a slightly different collection of software • Open source + proprietary modifications • Vendors providing vertical solutions to a problem • Ecosystem and tools not focused on developers Source : http://readwrite.com/2014/08/13/hadoop-slow-security-issues-still-popular
Big data developers • Data ingestion/ETL blocks progress • Security and governance requirements • Integration code or building core system services • Time needed for testing, production, deployment • Time to market / Time to value
a=b, c=d > update meta a=e, c=e, x=y > set dataset <name> ttl <time> > truncate dataset <name> > delete dataset <name> > create dataset <name> with meta a=b, c=d > ingest event '<event>' with meta x=y, u=v into dataset <name> > ingest events from file <path-to-file> with meta x=y, u=v into dataset <name> > ingest file /data/file.csv of type CSV with meta a=b, c=d into dataset <name> > ingest file /data/file.txt of type TXT with meta a=b, c=d into dataset <name> > ingest file /data/file.avro of type AVRO with meta a=b, c=d into dataset <name> > create dataset <name> with meta a=b, c=d > attach kafka to <name> with properties a=b, c=d as <pipe> > start pipe <pipe> > stop pipe <pipe> > dettach <pipe> > attach twitter to <name> with properties a=b, c=d as <pipe> > attach jms to <name> with properties a=b, c=d as <pipe> > create dataset <name> with meta a=b, c=d > ingest events from file <path-to-file> into dataset <name> > create view on dataset <name> as <view-name> with schema '<json schema>' > run query "SELECT f1, f2, f3 FROM view-name" > schedule query “INSERT INTO <dataset> SELECT f1, f2, f3 FROM view-name” to run every 1 hour Push Data Pull Data Explore Data Manage Data
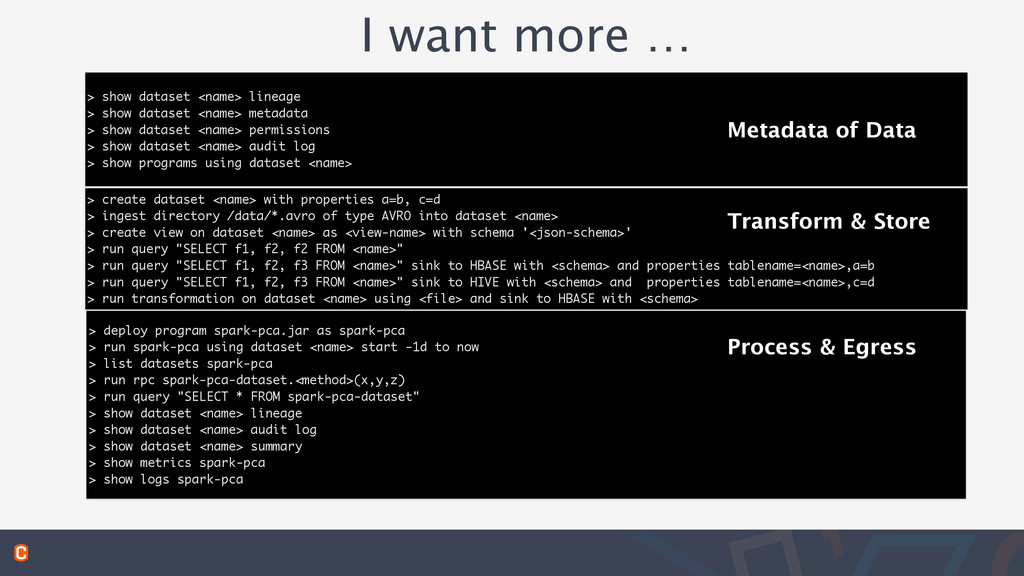
> show dataset <name> permissions > show dataset <name> audit log > show programs using dataset <name> > create dataset <name> with properties a=b, c=d > ingest directory /data/*.avro of type AVRO into dataset <name> > create view on dataset <name> as <view-name> with schema '<json-schema>' > run query "SELECT f1, f2, f2 FROM <name>" > run query "SELECT f1, f2, f3 FROM <name>" sink to HBASE with <schema> and properties tablename=<name>,a=b > run query "SELECT f1, f2, f3 FROM <name>" sink to HIVE with <schema> and properties tablename=<name>,c=d > run transformation on dataset <name> using <file> and sink to HBASE with <schema> > deploy program spark-pca.jar as spark-pca > run spark-pca using dataset <name> start -1d to now > list datasets spark-pca > run rpc spark-pca-dataset.<method>(x,y,z) > run query "SELECT * FROM spark-pca-dataset" > show dataset <name> lineage > show dataset <name> audit log > show dataset <name> summary > show metrics spark-pca > show logs spark-pca I want more … Metadata of Data Transform & Store Process & Egress
Real-time streaming for the real world Clusters with a click CASK DATA APP PLATFORM cdap.io coopr.io tigon.io Thread Abstraction on YARN Transaction for Apache HBase tephra.io
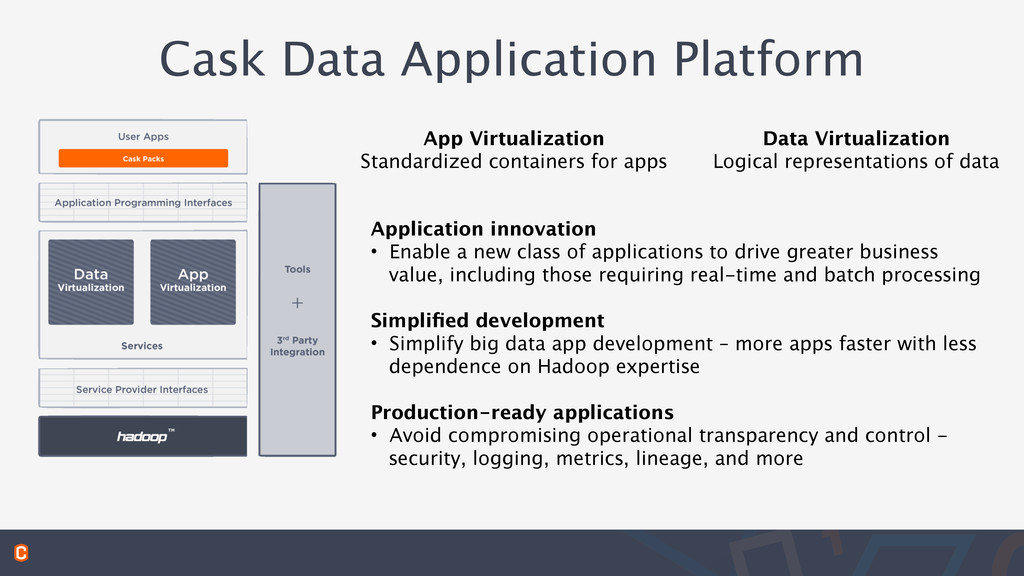
class of applications to drive greater business value, including those requiring real-time and batch processing Simplified development • Simplify big data app development – more apps faster with less dependence on Hadoop expertise ! Production-ready applications • Avoid compromising operational transparency and control - security, logging, metrics, lineage, and more Data Virtualization Logical representations of data App Virtualization Standardized containers for apps
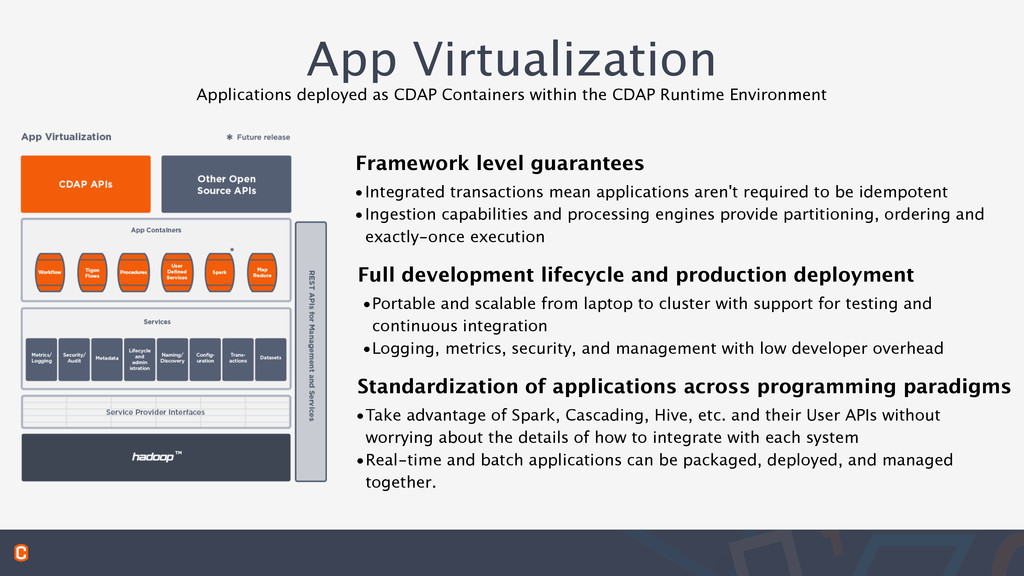
within the CDAP Runtime Environment Streams for data ingestion Reusable libraries for common Big Data access patterns Data available to multiple applications and different paradigms •Supports Kafka, Flume, REST, and custom implemented protocols •Time-stamped, ordered and horizontally scalable •Secondary indexes, Time Series, Key-Value, Objects, Geospatial, OLAP Cube and more •Libraries expose each pattern as RPCs, Batch Scans, and SQL Tables •Unified batch and real-time processing with the same data used concurrently by MapReduce, Hive, Spark, Flows and more •Expose data as REST services to quickly enable data as a service
Runtime Environment Framework level guarantees Full development lifecycle and production deployment Standardization of applications across programming paradigms •Integrated transactions mean applications aren't required to be idempotent •Ingestion capabilities and processing engines provide partitioning, ordering and exactly-once execution •Portable and scalable from laptop to cluster with support for testing and continuous integration •Logging, metrics, security, and management with low developer overhead •Take advantage of Spark, Cascading, Hive, etc. and their User APIs without worrying about the details of how to integrate with each system •Real-time and batch applications can be packaged, deployed, and managed together.
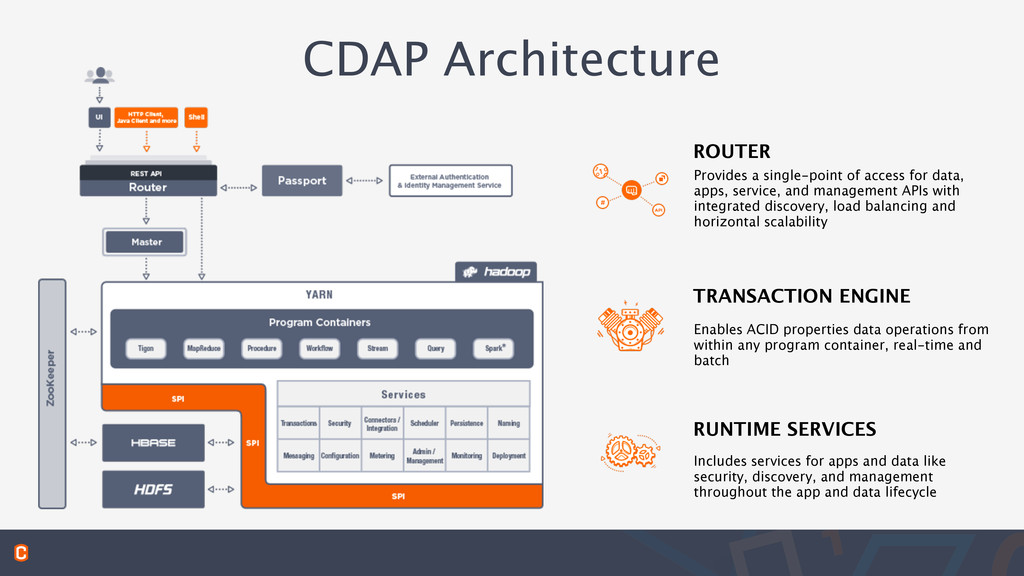
service, and management APIs with integrated discovery, load balancing and horizontal scalability ROUTER TRANSACTION ENGINE RUNTIME SERVICES Enables ACID properties data operations from within any program container, real-time and batch Includes services for apps and data like security, discovery, and management throughout the app and data lifecycle
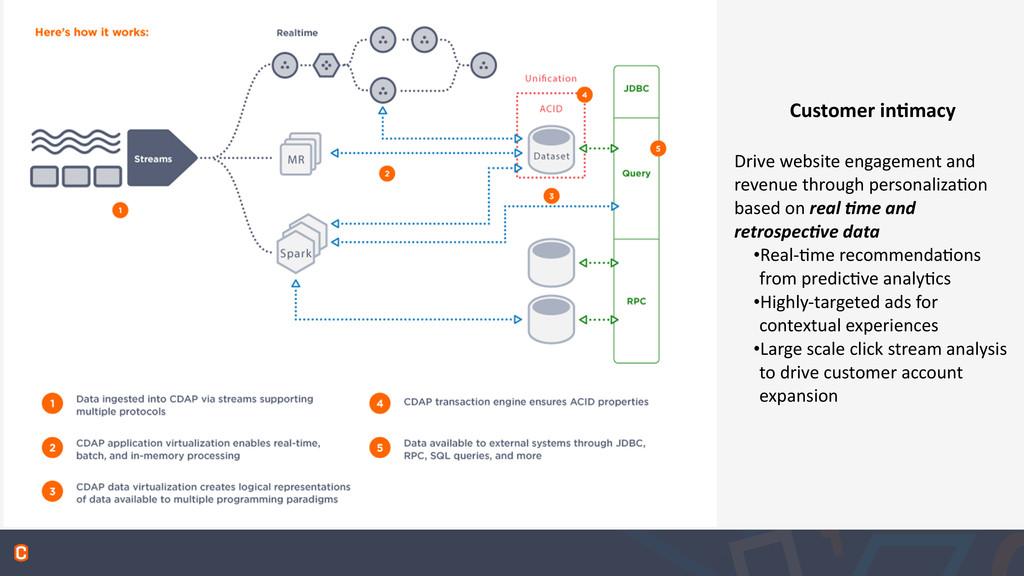
revenue through personaliza:on based on real &me and retrospec&ve data •Real-‐:me recommenda:ons from predic:ve analy:cs •Highly-‐targeted ads for contextual experiences •Large scale click stream analysis to drive customer account expansion
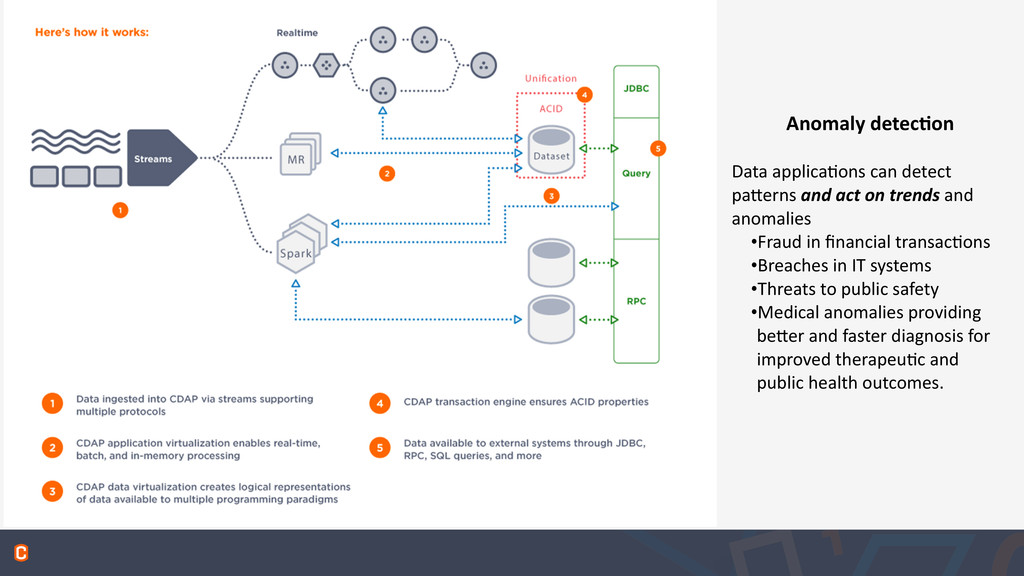
paBerns and act on trends and anomalies •Fraud in financial transac:ons •Breaches in IT systems •Threats to public safety •Medical anomalies providing beBer and faster diagnosis for improved therapeu:c and public health outcomes.
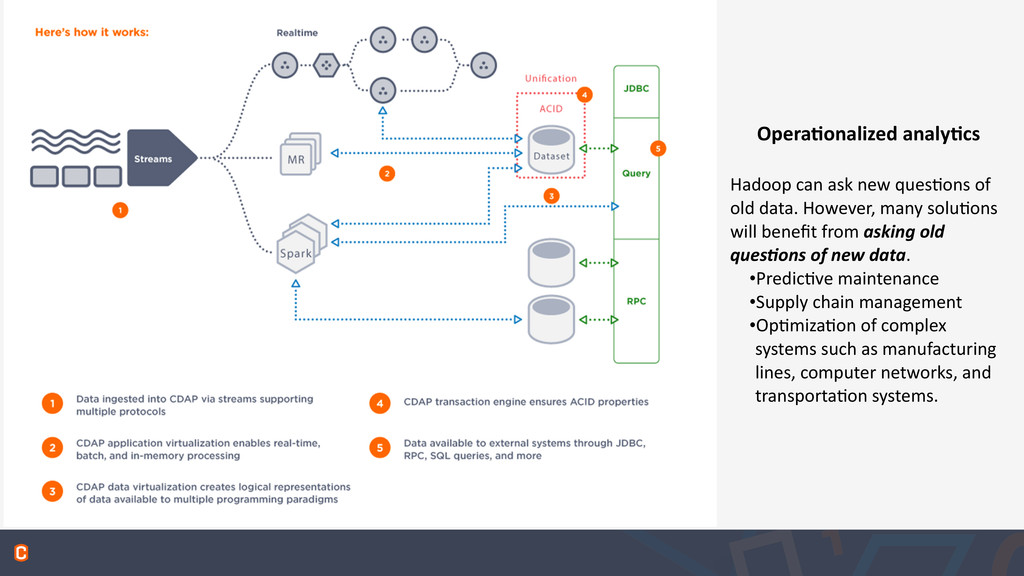
old data. However, many solu:ons will benefit from asking old ques&ons of new data. •Predic:ve maintenance •Supply chain management •Op:miza:on of complex systems such as manufacturing lines, computer networks, and transporta:on systems.
Group : [email protected] IRC : #cdap Group : [email protected] IRC : #coopr Group : [email protected] IRC : #tephra Group : [email protected] IRC : #tigon Clone it, Build it, Play with it Website : http://cdap.io Website : coopr.io Website : tephra.io Website: tigon.io OR http://cask.co/downloads and Play with it ! http://coo.pr OR Contribute and help us make it better @nmotgi
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}