Дмитрий Кашицын (HDsoft) дает обзор LLVM.
В этом докладе мы кратко расскажем о таком звере, как LLVM, о котором много кто слышал, но немногие щупали. Что такое компилятор на самом деле? Чем LLVM отличается от других компиляторов? Как в LLVM происходит компиляция программы, как работают оптимизации? Наконец, какой путь проходит программа от разбора исходного текста до генерации исполняемого файла?
Лекция будет обзорной и не потребует от слушателей глубоких знаний теории компиляторов.
Подробности — на http://techtalks.nsu.ru
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
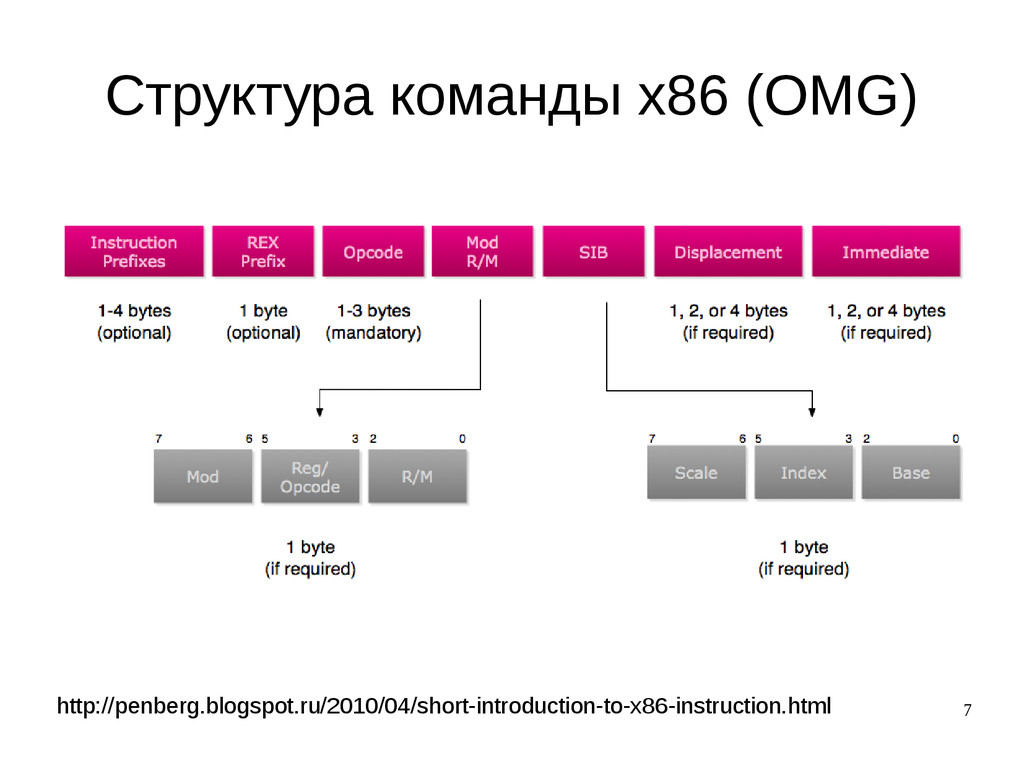{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
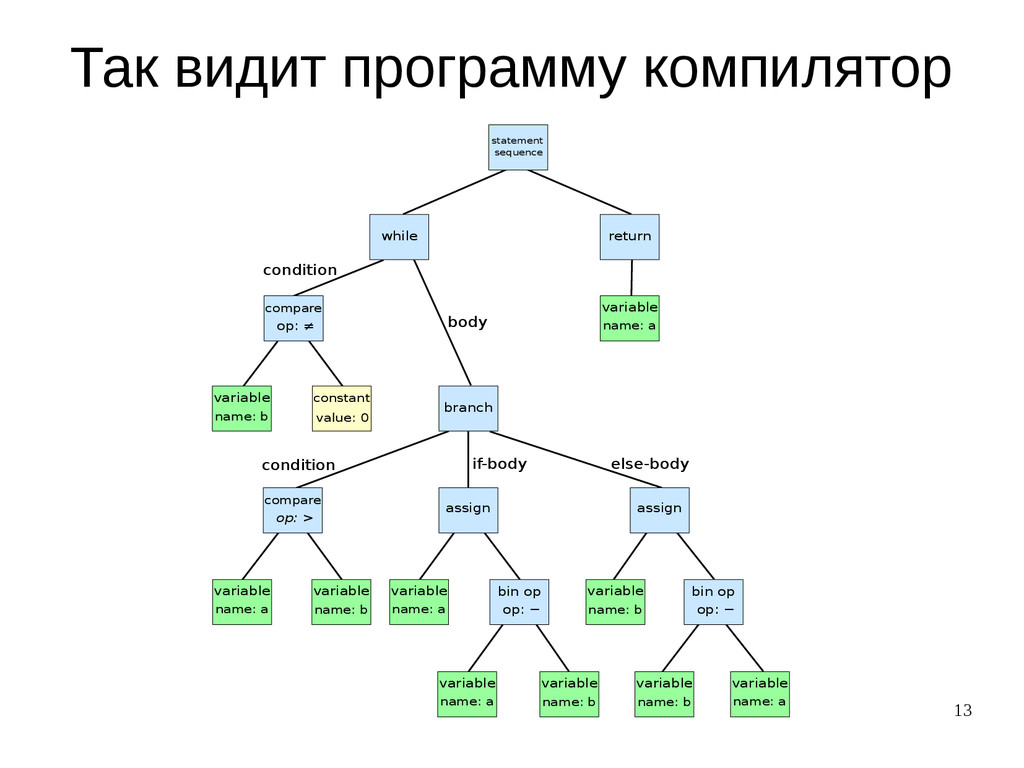{kind=link}
{kind=link}
{kind=link}
![16 Входной файл для flex (огрызок) whitespace [ \r\n\t]* number](https://files.speakerdeck.com/presentations/4405196d8c0c48b5b9c94d71ffdf51f5/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
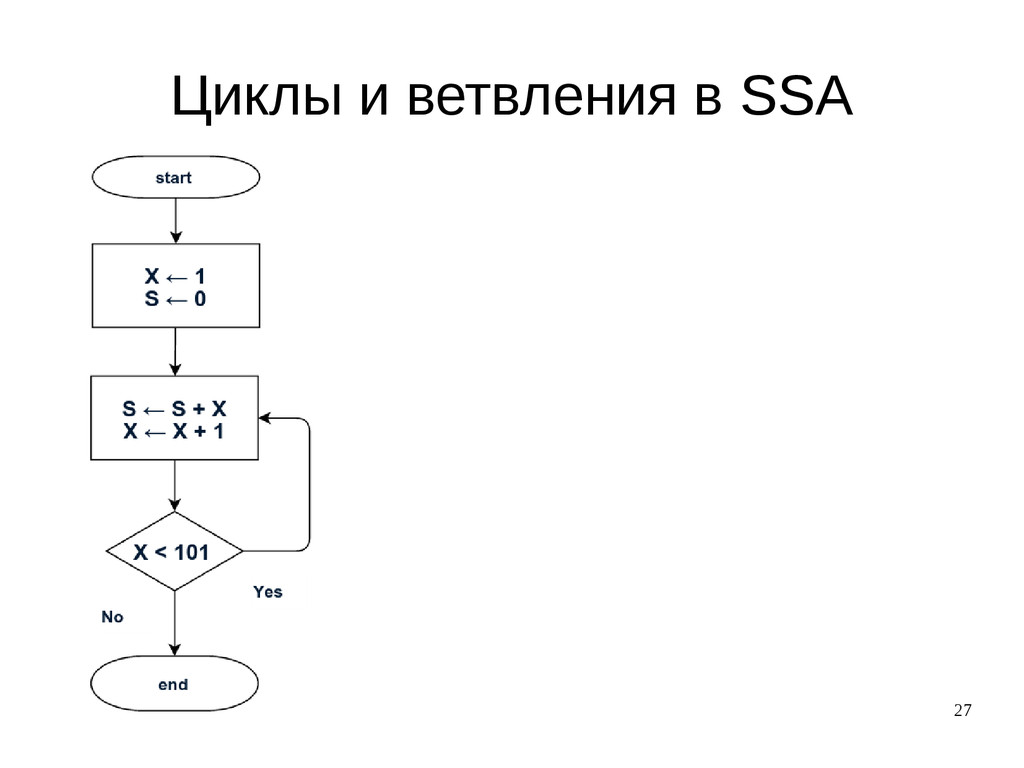{kind=link}
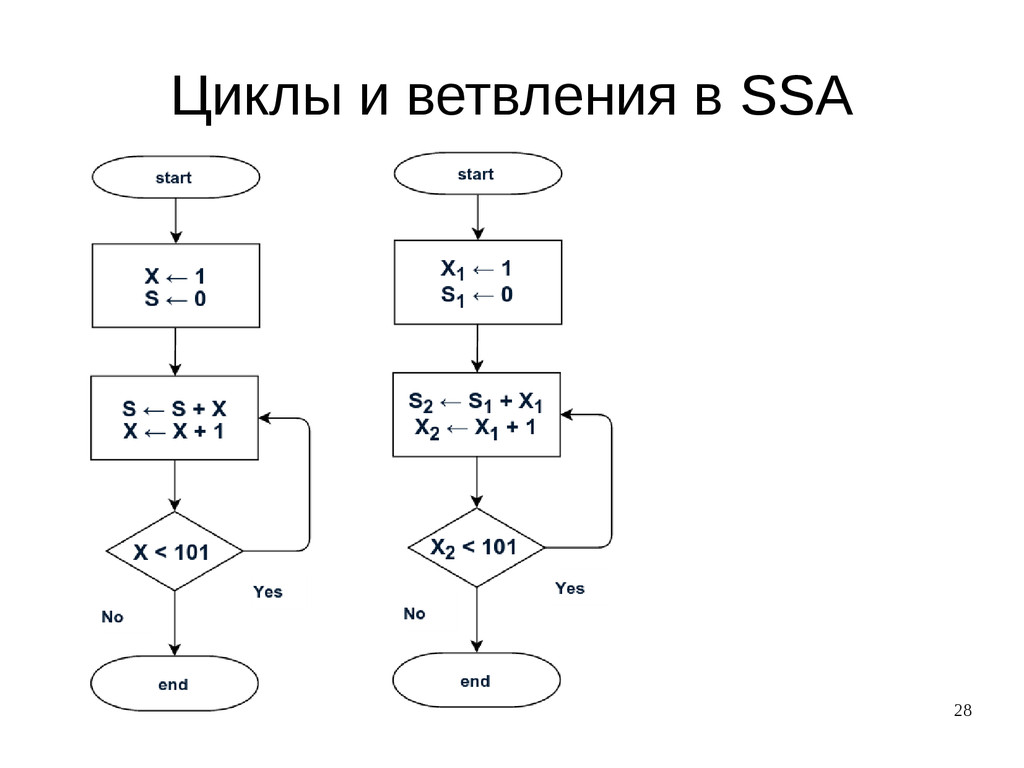{kind=link}
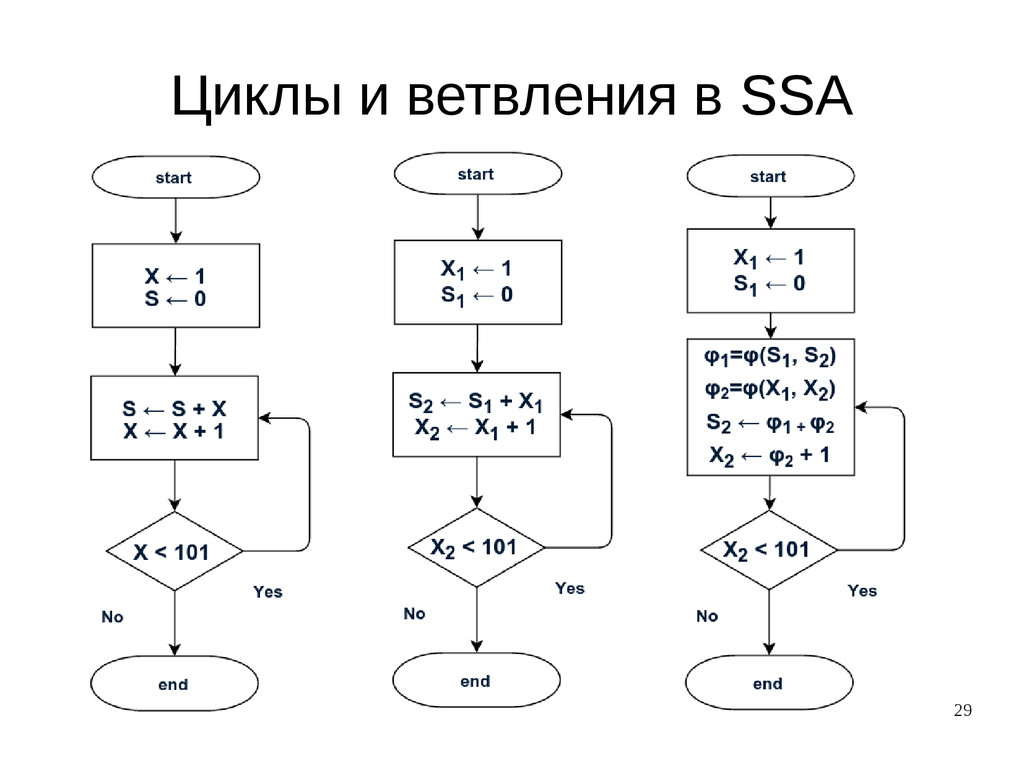{kind=link}
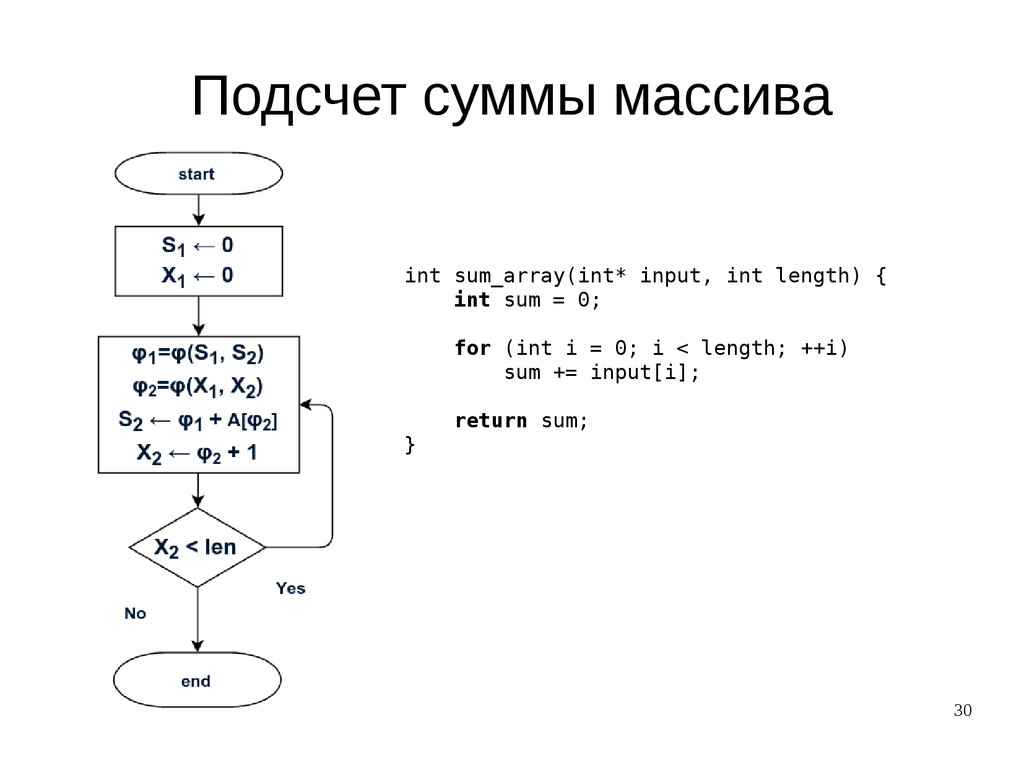{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}