обучение. • Все модели описаны единым языком (см. Bishop Model Based Machine Learning) • Мощный и выразительный язык теории вероятностей • Позволяет строить модели, которые можно исследовать вероятностными методами 4
, моделируем машинным обучением. К нам пришли множество клиентов Как посчитать возможные убытки? Можно заранее рассчитать с помощью стохастического моделирования! p(y|x) y x Xclients RISK = ∑ x∈Xclients λx,y p(y|x) 5
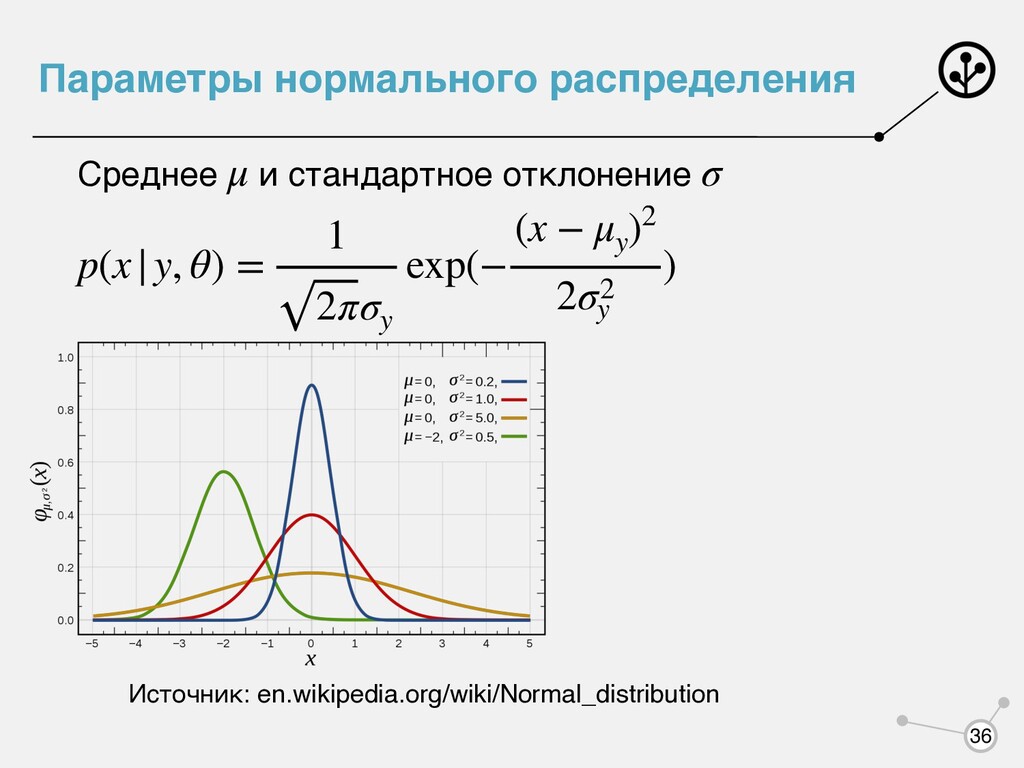
Обучающая выборка взята случайно и независимо из этого распределения — априорная вероятность класса — правдоподобие объекта — апостериорная вероятность класса — обоснованность (evidence) объекта A priori (латынь) — от предшествующего A posteriori (латынь) — из последующего p(x, y) p(y) y p(x|y) x p(y|x) y p(x) x 6
ошибки алгоритма на объекте с ответом . Функционал среднего риска — мат. ожидание функции потерь Какая связь с эмпирическим риском? L(a, x, y) a x y R(a) = ∫ ∫ L(a, x, y)p(x, y)dxdy a* = argmin R(a) 9
наша стохастическая оценка среднего риска, так как мы не знаем истинного распределения! Почему просто не оптимизировать всегда средний риск? Q(a, X, Y) = 1 N ∑N i=1 L(a, xi , yi ), xi ∈ X, yi ∈ Y a* = argmin Q(a, Xtrain , Ytrain ) R(a) = ∫ ∫ L(a, x, y)p(x, y)dxdy a* = argmin R(a) 10
вид совместного распределения! • Если бы знали, то мы бы учились брать интегралы, а не занимались машинным обучением :) • Если бы знали, то машинное обучение было бы решенной задачей. Как же быть? 11
совместное распределение знать и не нужно, достаточно только знать апостериорное распределение • Но мы его тоже не знаем аналитически! Значит у нас возникает задача оценки плотности распределения • Для регрессии есть аналогичный подход, разберите дома p(y|x) 12
вероятностной моделью, если он моделирует совместное распределение 2. Дискриминативной вероятностной моделью, если он моделирует апостериорное распределение 3. Дискриминативной моделью, если он моделирует только функцию Приведите примеры a(x) p(x, y) p(y|x) y = f(x) 14
KNN, SVM, деревья Генеративные вероятностные модели — еще не проходили, на этой лекции будет наивный байесовский классификатор! Какие плюсы и минусы дискриминативных и генеративных моделей? 15
дискриминативных моделей: • Намного проще учить (что проще, научить модель отличать Ван Гога от Дега или научиться отличать, но еще уметь рисовать картину каждого художника?) • Из-за этого, как правило, в типовых задачах работают лучше Плюсы генеративных моделей: • Более общие • Легко работают с пропущенными значениями признаков • Легко находить выбросы • Способны генерировать новые объекты Зачем генерировать объекты? p(x, y) = p(y|x)p(x) p(y|x) p(x) 16
• Получать объекты с нужными свойствами (например, молекулы, которые борются с определенными болезнями) • Для датасета для другой модели • Для отладки модели 17
их исследовать. • Мы должны оптимизировать средний риск, но из-за того, что у нас нету совместного распределения, мы считаем эмпирический. • Оптимальный классификатор этот тот, который возвращает класс с наибольшей вероятностью (регрессор смотрим дома) • Бывают генеративные и дискриминативные модели. Генеративные моделируют , поэтому позволяют генерировать новые объекты p(y|x) p(x) 18
сделать оценку «Насколько вероятно, что целевая переменная равна классу при условии, что этот объект имеет вектор весов » Считаем такую вероятность по обучающей выборке! Удобно ли считать такую вероятность напрямую? a*(x) = argmax y∈Y p(y|x) y x 20
что этот объект имеет вектор весов при условии, что целевая переменная равна классу » Как оценить ? p(y|x) = p(x|y)p(y) p(x) a*(x) = argmax y∈Y p(y|x) = argmax y∈Y p(x|y)p(y) p(x) = argmax y∈Y p(x|y)p(y) x y p(y) 21
похож на объекты из класса , которые мы видели на обучении. • — насколько этот класс популярен Зачем тогда вообще нужен ? Почему бы не брать просто a*(x) = argmax y∈Y p(y|x) = argmax y∈Y p(x|y)p(y) p(x|y) x y p(y) p(y) argmax y∈Y p(x|y) 23
на объекты из класса , которые мы видели на обучении. Учимся оценивать далее • — позволяет уменьшить переобучение, то есть регуляризация . Уже умеем оценивать через долю класса a*(x) = argmax y∈Y p(y|x) = argmax y∈Y p(x|y)p(y) p(x|y) x y p(y) 24
какой процент точек из обучающей выборки лежит в окрестности оцениваемого значения. 2. Параметрический — предполагаем, что наше распределение из параметрического семейства. Настраиваем параметры распределения по обучающей выборке. 3. Восстановление из смеси распределений — предполагаем, что наше распределение смесь параметрических распределений. На этой лекции обсудим первые два варианта. p(x|y) 25
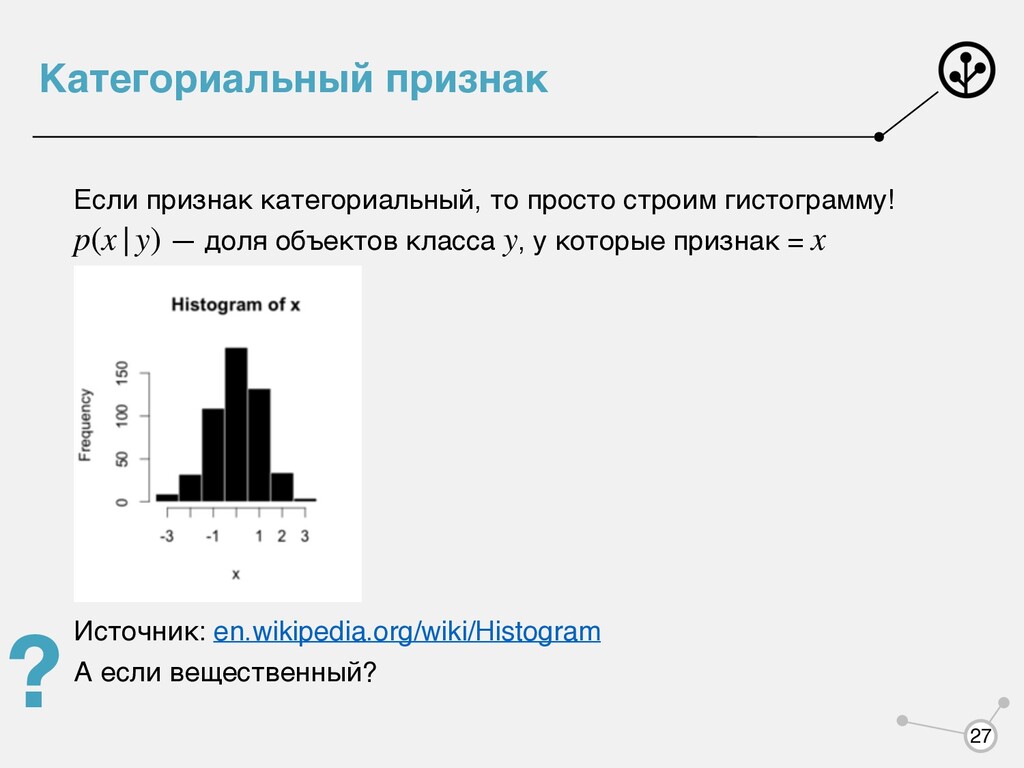
класса принимает значение признака (функция от ) Для простоты считаем, что у нас один признак. Основная идея — посмотрим, сколько объектов на обучающей выборке из класса принимает такое значение или близкое. p(x|y) y x x y 26
дискретизируем вещественный признак с помощью окна ширины , а потом считаем долю точек класса, которые попали в это окно! Что в таком подходе может не устраивать? h 28
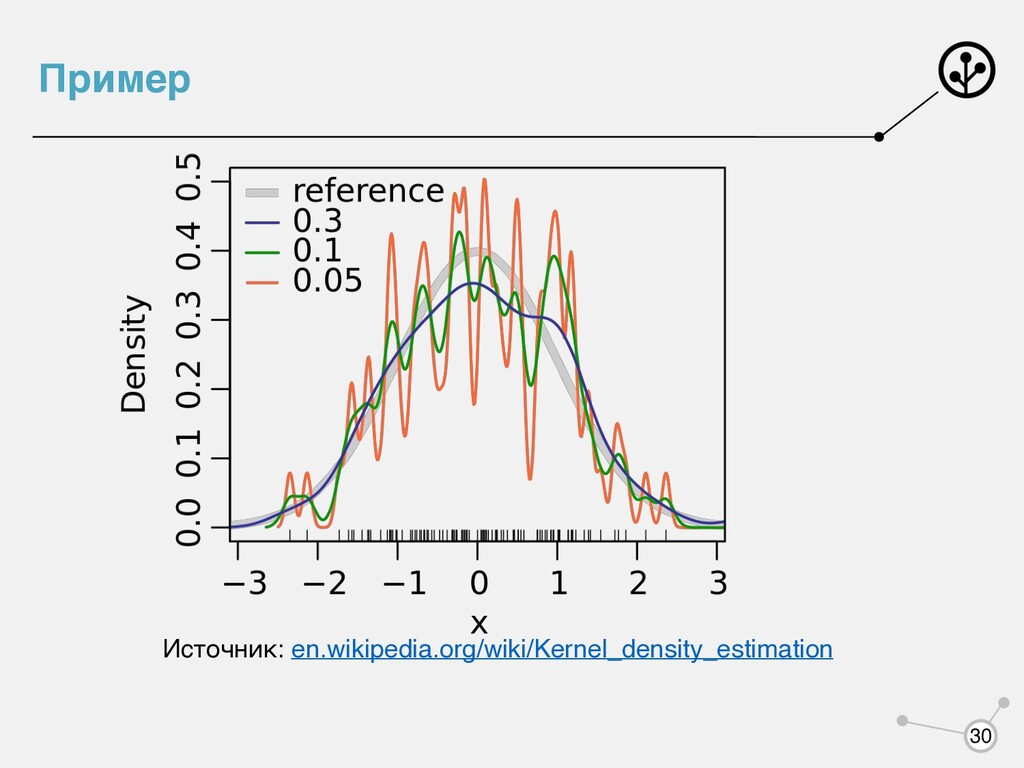
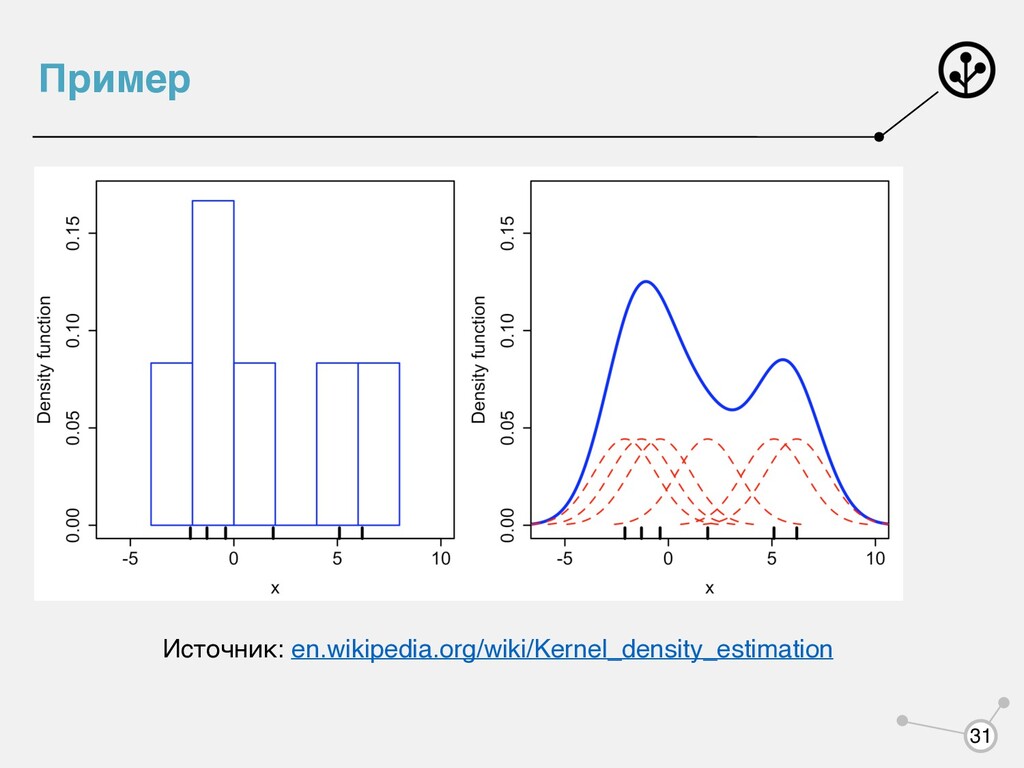
парзеновского окна: где - четная нормированная функция, которую называют ядром. Например, Гауссовское — p(x|y) = 1 2Nh N ∑ i=1 (|x − xi | < h)[yi = y] p(x|y) = 1 Nh N ∑ i=1 K( x − xi h )[yi = y] K K(r) = (2π)−0.5exp(− 1 2 r2) 29
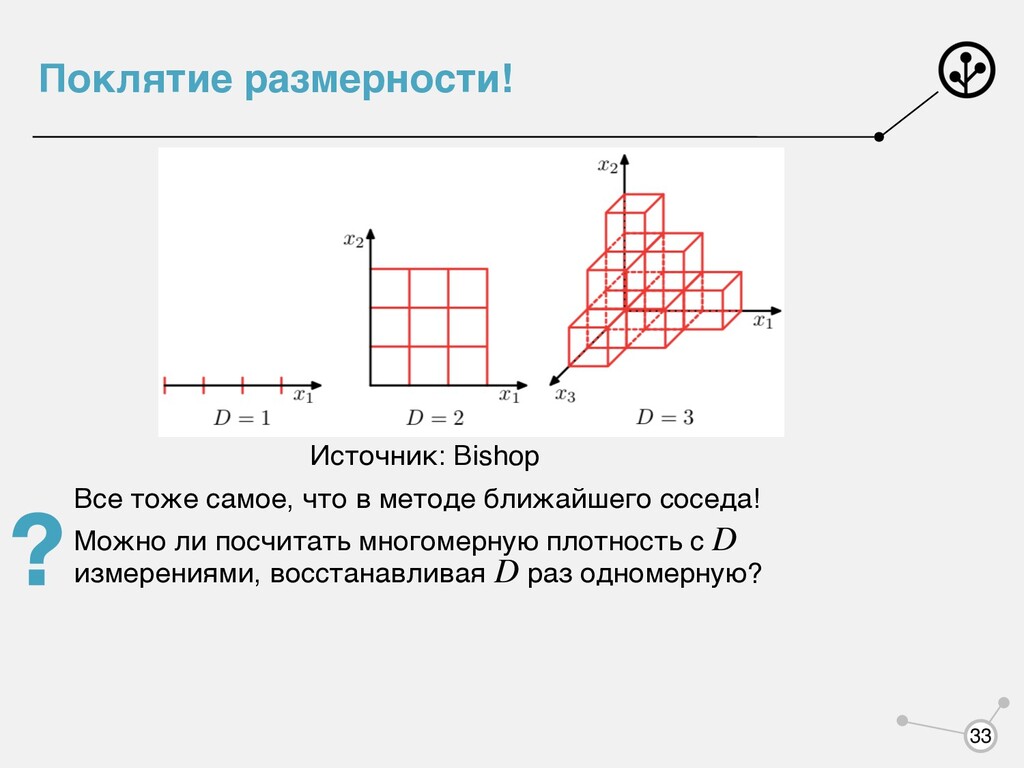
признаков. 2 варианта восстановить плотность многомерного распределения: • Восстанавливать в лоб многомерную плотность (проклятие размерности) • Перейти от многомерной плотности к одномерным , где — число признаков Предположение алгоритма наивного байеса — признаки независимы при условии целевой переменной p(x|y) x p(x|y) = D ∏ j=1 p(xj |y) D 34
класса принимает значение признака (функция от ) Для простоты считаем, что у нас один признак. Основная идея — предположим, что наше лежит в каком-то параметрическом семействе распределений , где — параметры, а затем находим параметры, используя метод максимума правдоподобия. Какие параметры у одномерного нормального распределения? p(x|y) y x x p(x|y) p(x|y, θ) θ 35
выборку максимально правдоподобно! Случайная величина — число луж во дворе Параметр — (был дождь, поливали двор, ничего не было) Выходите на улицу видите выборку — кругом лужи! Чему максимально вероятно равна ? η θ θ 37
правдоподобия, то есть вероятность пронаблюдать выборку, если все объекты берутся независимо: С суммой, как правило, удобнее работать. (Почему?) Правильные параметры те, которые максимизируют L(θ) = p(X|θ) = N ∏ i=1 p(xi |θ) log L(θ) = N ∑ i=1 log p(xi |θ) L(θ) 38
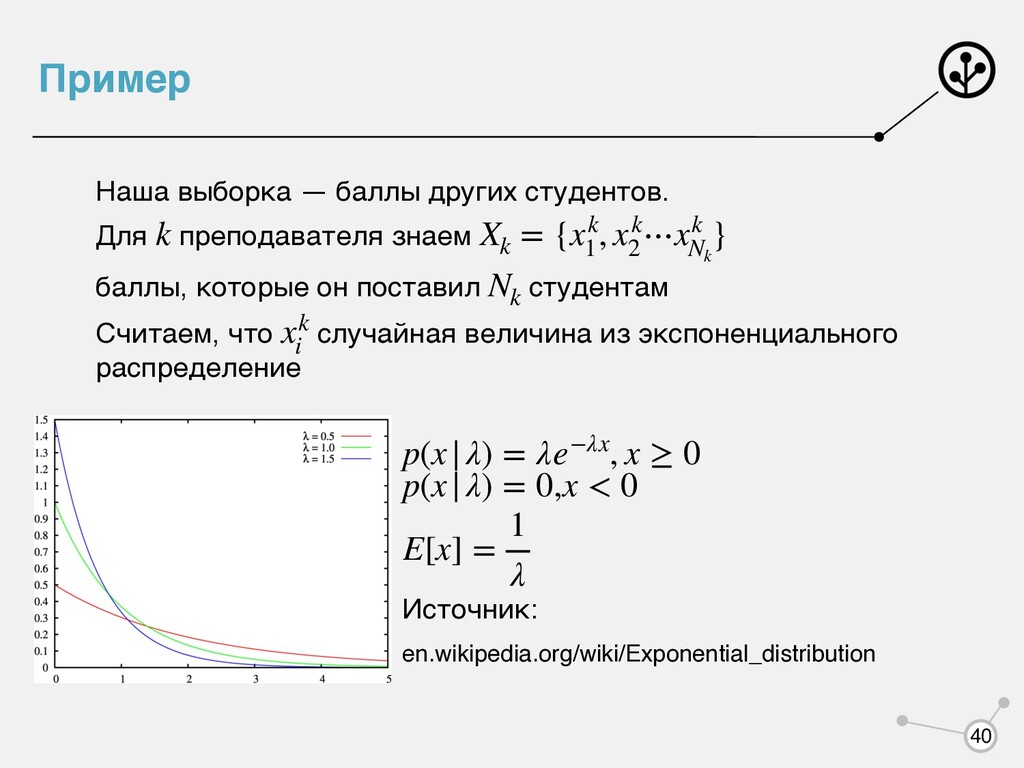
баллы, которые он поставил студентам Считаем, что случайная величина из экспоненциального распределение p Источник: en.wikipedia.org/wiki/Exponential_distribution k Xk = {xk 1 , xk 2 ⋯xk Nk } Nk xk i p(x|λ) = λe−λx, x ≥ 0 p(x|λ) = 0,x < 0 E[x] = 1 λ 40
преподавателя! , где , Просто средние баллы, которые поставил преподаватель! Выбираем того, у кого это среднее максимально. λk L(λk ) = p(Xk |λk ) = N ∏ i=1 p(xi |λk ) p(xi |λk ) = λk e−λk xi log L(λk ) = N ∑ i=1 log p(xi |λk ) = N ∑ i=1 (log λk − λk xi ) = N log λk − λk N ∑ i=1 xi ∂ log L(λk ) ∂λk = N λk − N ∑ i=1 xi = 0 λk = Nk ∑N i=1 xi E[xk ] = 1 λk = ∑Nk i=1 xi Nk 41
нашли параметр , то есть теперь, мы можем посчитать плотность вероятности в любой точке Для классификации для каждого из класса считаем Потом применяем оптимальное байесовское правило: λ p(x|yk , λk ) = λk e−λk x 42 a*(x) = argmax k p(x|yk )p(yk ) = argmax k λk e−λk xp(yk )
Таким образом восстанавливаем плотность для булевых признаков. log L(θ) = N ∑ i=1 yi log θ + (1 − yi )log(1 − θ) ∂ log L(θ) ∂θ = N ∑ i=1 yi θ − 1 − yi 1 − θ = N ∑ i=1 yi − θyi − θ + θyi θ(1 − θ) = 0 N ∑ i=1 (yi − θ) = N ∑ i=1 yi − Nθ = 0 θ = ∑N i=1 yi N a*(x) = argmax k p(yk )θ[k=1](1 − θ)[k=0] 46
берем не одномерную плотность, а многомерную и точно так же с помощью ММП находим параметры. • Или используем предположение алгоритма наивного байеса Будут ли проблемы при параметрическом восстановлении многомерной плотности? p(x|y) = D ∏ j=1 p(xj |y) 47
гарантии на оптимальность метода максимального правдоподобия только для случая, когда Если это не так, он может не сойтись к истинному значению, а в многомерных распределениях параметров больше. n d → ∞ 48
много маленьких, то есть шанс выйти за машинную точность. Но логарифм монотонная функция, так что прологарифмируем. Теперь мы складываем отрицательные числа, что для машины сильно проще. a*(x) = argmax y∈Y p(y|x) = argmax y∈Y p(x|y)p(y) p(x|y) = D ∏ j=1 p(xj |y) a*(x) = argmax y∈Y p(y) D ∏ j=1 p(xj |y) a*(x) = argmax y∈Y [log p(y) + D ∑ j=1 log p(xj |y)] 49
признаки берем бинарных признаков «имеется ли это слово в письме» На обучении для каждой бинарной фичи считаем плотность, как для распределения Бернулли: — процент спамовских (класс ) / нормальных писем со словом Хотим посчитать предсказание для тестового письма. Чему будет равно , если хотя бы одно слово из тестового письма не присутствовала в письмах со спамом? a*(x) = argmax y∈Y p(y) D ∏ j=1 p(xj |y) D p(xj |y) S xj p(yspam ) D ∏ j=1 p(xj |yspam ) 50
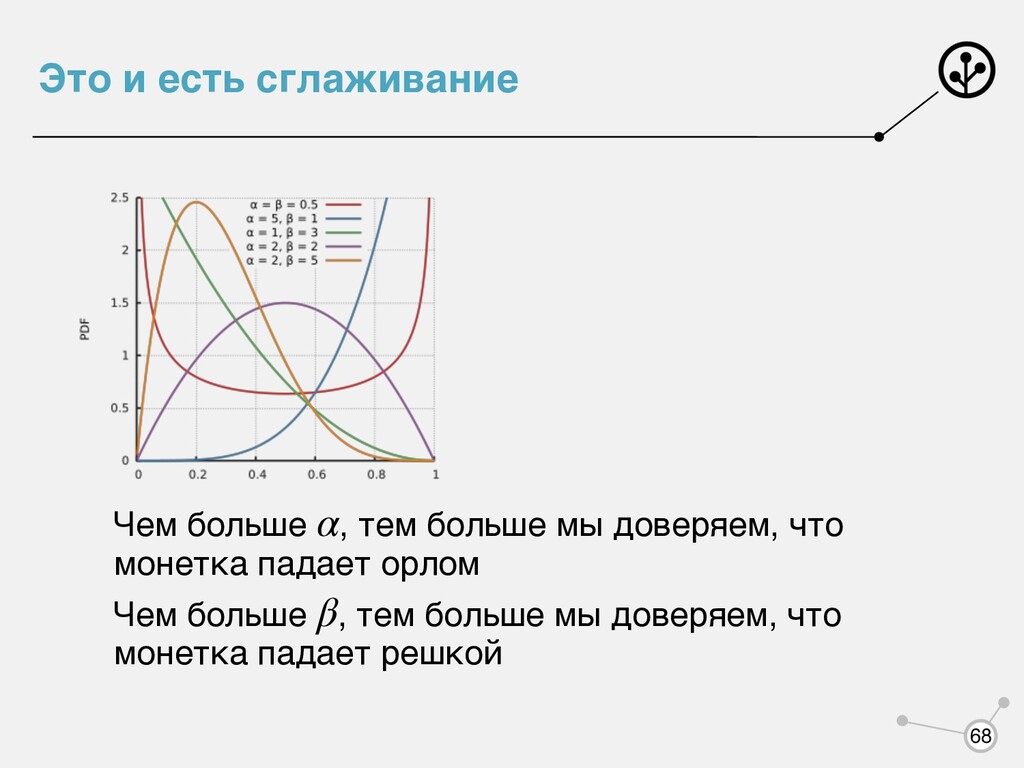
при гипотезе условной независимости равна нулю! При восстановлении плотности для категориальных признаков нужно проводить сглаживание — доля спамовских документов встречалось слово — сглаживание Лапласа Считаем, что есть фейковые документов, среди которых спамовские Почему вообще нужно сглаживание? Если в классе спама не было такого слова, значит вероятность 0 и все! p(x|yspam ) θj = ∑N i=1 [yi ∈ S][xi,j = 1] Ns j θj = ∑N i=1 [yi ∈ S][xi,j = 1] + α Ns + α + β α + β α 51
конечной выборке. Задача по своей природе некорректно поставленная. Ну вот не попалось нам на обучении спамовское письмо со словом «серобуромалиновый», но это не значит, что спамеры сознательно избегают этого слова. Сглаживание — способ борьбы с переобучением, то есть своеобразная регуляризация Можно ли подобрать на обучающей выборке? α, β 52
на обучающей выборке посчитали, что слово «серобуромалиновый» не встречается в классе спам, понятное дело, если вы зарегуляризуете это с помощью , то на обучении будет только хуже. Настраивать только на валидации! α, β 53
по классам 2. Оценили , как долю данного класса в обучающей выборке для каждого класса 3. Решили, как будем считать A. Непараметрически B. Параметрически В лоб восстанавливаем многомерную плотность Используем предположение условной независимости 4. Посчитали и умножили на для каждого класса 5. Взяли класс с максимальным значением p(y) p(x|y) p(x|y) p(y) a*(x) = argmax y∈Y p(y|x) = argmax y∈Y p(x|y)p(y) 54 Совмещаем все вместе
классификатора A. — априорную вероятность класса B. — правдоподобие объекта в классе • Вспомнили, что такое метод максимума правдоподобия, научились им оценивать параметры распределений • Вспомнили, что такое логлосс • Узнали, что такое сглаживание и как оно помогает с переобучением p(y) p(x|y) 55
обучения • Позволяет получить важные практические результаты (например, вараиционный дропаут) • Все параметры модели описываются вероятностными распределениями таким образом • Использование формулы Байеса для оценки параметров нашей модели • Расчет для оптимального предсказания θ p(y|x, θ) 57
работаем с эмпирическими данными! • В данных могут быть аномальные объекты • Мы не полностью описываем явление, выбирая какие-то признаки. • В признаках будут ошибки • Наша модель не полностью описывает данные Это все объективное незнание! Закон природы есть, но мы не можем записать его точно. Мы все это можем задать с помощью вероятностных распределений. 58
о параметрах Провели эксперименты (собрали выборку), посчитали: — насколько вероятно получить такие результаты экспериментов? — насколько вообще наши исходы вероятны? Обновили наши представления о параметрах по формуле Байеса А если провели еще серию экспериментов? p(θ|X) = p(X|θ)p(θ) p(X) p(θ) p(X|θ) p(X) p(θ|X) 59
и снова пересчитайте по формуле Байеса! Таким образом мы вообще не теряем информации, просто итеративно обновляем распределение на параметры по формуле Байеса. Очень удобно, когда, применив формула Байеса, мы остались в том же классе распределений, какое было априорным. Такие распределения называют сопряженным. p(θ|X) = p(X|θ)p(θ) p(X) = p(X|θ)p(θ) ∫ p(X|θ)p(θ)dθ 60
правдоподобия может дать неадекватную оценку Свойства ММП: • Состоятельность (оценка сходится по вероятности к истинному значению) • Асимптотическая нормальность (оценка распределена нормально) • Асимптотическая эффективность (обладает наименьшей дисперсией среди всех состоятельных асимптотически нормальных оценок) При У нас тут BigData. И зачем все это? n → ∞ 62
Каждый из них надо оценить! Тогда нужно, чтобы: , а это даже для BigData неправда. Но если параметров мало, а данных много, то байесовский подход переходит в ММП: апостериорное распределение ведет себе как дельта функция в точке максимума правдоподобия. n d → ∞ 63
подход нам позволяет напрямую влиять на решение, выбирая prior. Это уменьшает переобучение. θML = ∑N i=1 yi N θMAP = ∑N i=1 yi + α − 1 N + α + β − 2 α, β α = 2,β = 2 θMAP = ∑N i=1 yi + 1 N + 2 67 Это и есть сглаживание
Правдоподобие: Когда моделировали монетку, считали что: , если , если То есть каждый бросок мы раньше никак не описывали, считали их все равнозначными. Но мы то знаем, что у броска есть признаки, которые описывают бросок. Например, начальная скорость, стартовый угол, угловая скорость и т.д. Тут то мы и переходим к задаче двухклассовой классификации! L(θ) = N ∏ i=1 p(yi |x, θ) p(yi |x, θ) = θ yi = 1 p(yi |x, θ) = 1 − θ yi = 0 69
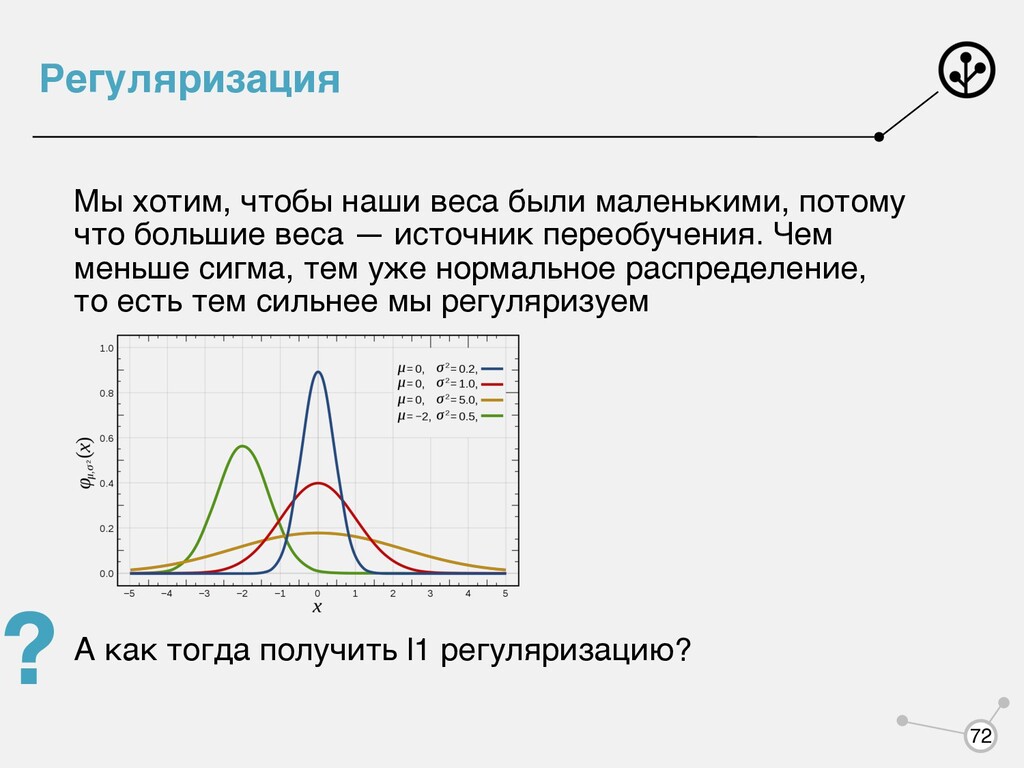
большие веса — источник переобучения. Чем меньше сигма, тем уже нормальное распределение, то есть тем сильнее мы регуляризуем А как тогда получить l1 регуляризацию? 72
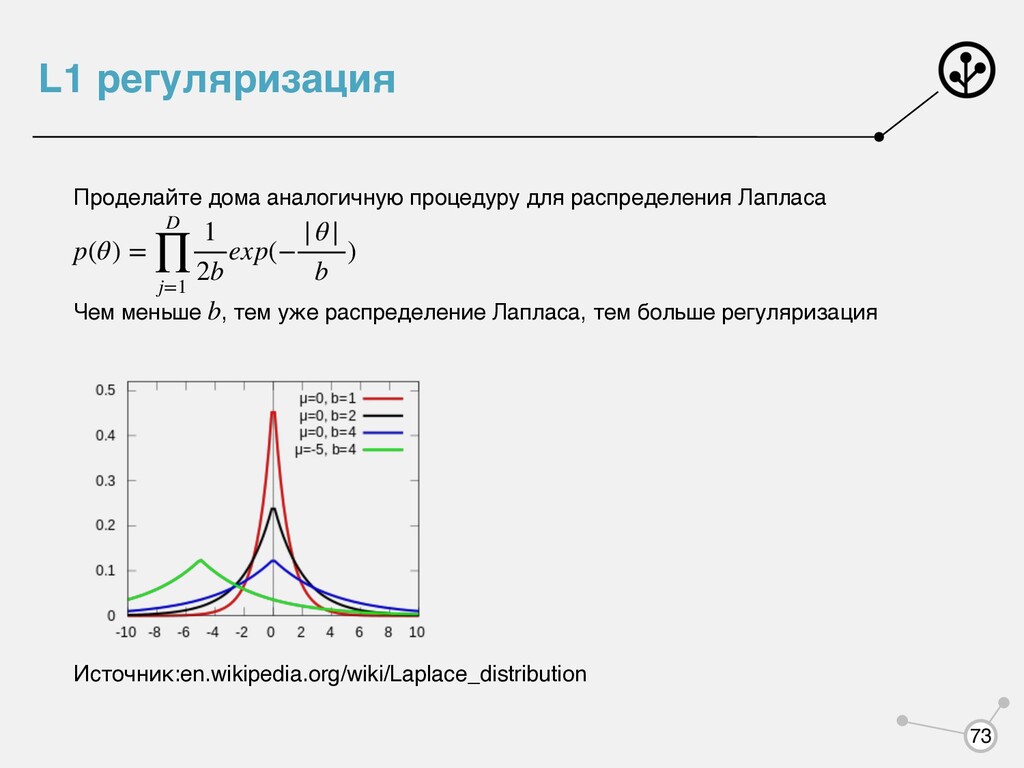
меньше , тем уже распределение Лапласа, тем больше регуляризация Источник:en.wikipedia.org/wiki/Laplace_distribution p(θ) = D ∏ j=1 1 2b exp(− |θ| b ) b 73
что наблюдали выборку из единиц и нулей. Для регрессии мы наблюдаем вещественное значение. Предположим, что мы нашей моделью можем восстанавливаем нашу переменную с точностью до нормального шума, то есть каждый Распределен нормально со средним в точке и с какой-то дисперсией Правдоподобие: Говорим, что — вот и линейная регрессия , находим оптимум аналитически или градиентным спуском Как добавить сюда регуляризацию? a(x, θ) y a(x, θ) σ2 p(y|x, θ) = 1 2πσ exp(− (y − a(x, θ))2 2σ2 ) L(θ) = N ∏ i=1 p(yi |xi , θ) = 1 2πσ N ∏ i=1 exp(− (y − a(x, θ))2 2σ2 ) log L(θ) = C − N ∑ i=1 (y − a(x, θ))2 a(x, θ) = xTθ θML = argmax log L(θ) 74
ММП к MAP оценке. Если нормально, то будет L2 Если по Лапласу, то будет L1 Дома проведите выкладки! θMAP = argmaxL(θ)p(θ) = argmax log L(θ) + log p(θ) p(θ) p(θ) 75
Наивный вариант: взять моду этого распределения и подставить в формулу модели . Но мода распределения не всегда лучший вариант! Источник: en.wikipedia.org/wiki/Mode_(statistics) p(θ|X) = p(X|θ)p(θ) p(X) = p(X|θ)p(θ) ∫ p(X|θ)p(θ)dθ θMAP p(y|x, θ) 76
(которое требует оптимальный Байесовский классификатор) Для линейной регрессии можно посчитать. Посмотрите внимательно: Это просто усреднение предсказаний модели с разными параметрами с весом, который равен вероятности параметров! Это ансамбль моделей. p(y|x) p(y|x, Xtrain ) = ∫ p(y|x, θ)p(θ|Xtrain )dθ 77
задачи: • Метод релевантных векторов • Вариационный дропаут • Байесовский автокодировщик • Байесовская оптимизация • etc Однако, в большинстве задач его применить тяжело: • Никто не знает, как правильно задавать априорное распределение. • Если prior и likelihood не сопряжены, то аналитически ничего не посчитается. • Численные методы вычислительно трудоемкие • Проще собрать больше данных/больше признаков, чем использовать полный байесовский вывод 78
обучению • Сравнили байесовский подход с приниципом максимума правдоподобия • Провели вероятностную интерпретацию для линейных моделей • Научились делать оптимальное предсказание • Байесовский подход позволяет решать практические задачи, однако полный байесовский вывод на практике применять очень тяжело 79
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}