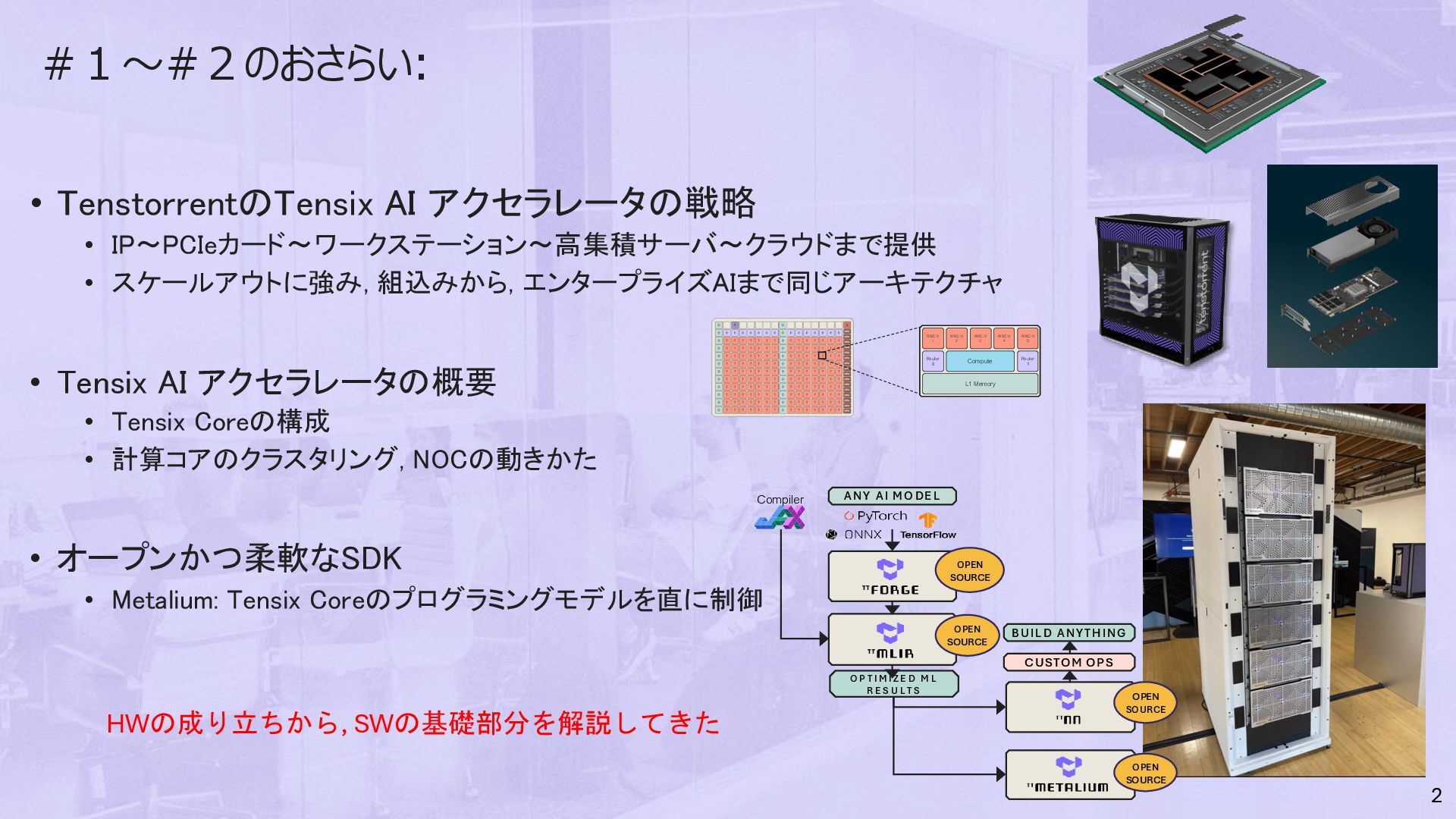
エンタープライズAIまで同じアーキテクチャ • Tensix AI アクセラレータの概要 • Tensix Coreの構成 • 計算コアのクラスタリング, NOCの動きかた • オープンかつ柔軟なSDK • Metalium: Tensix Coreのプログラミングモデルを直に制御 2 ANY AI MO DE L OPEN SOURCE OPEN SOURCE O P T I M I ZE D M L R E S U L T S CUSTOM OPS BUILD ANYTHING OPEN SOURCE OPEN SOURCE Compiler HWの成り立ちから, SWの基礎部分を解説してきた
problems with tt-inference-server: 1. Tenstorrent SW stack is complicated to build and is not packaged for easy consumption 2. We need a method of serving models for: a. Powering applications b. Simplifying model execution c. Integrating with industry standard deployment technologies d. Facilitating model performance benchmarking and accuracy evaluation 3. Need a way to encapsulate model configuration, a lot of setup is required: a. Environment variables b. Software version dependencies c. Model-specific runtime arguments d. Device configuration and topology 4. Enable local model serving 5. Need a standardized codebase for measuring model performance and accuracy 6. Need a tool to aid in application-level model regression testing (CI)
setup is required - ModelSpec captures all model configuration in serializable artefact - ModelSpec is consumed by Docker images How tt-inference-server solves these problems
- Provides a CLI that can: a. Run local inference servers in Docker containers b. Setup host dependencies (model weights, ModelSpec, persistent volumes, etc) c. Run performance benchmarks against running inference servers d. Run accuracy evaluations against running inference servers How tt-inference-server solves these problems
- Encapsulates measuring model performance and accuracy into parameterizable Python scripts that are executed by the CLI How tt-inference-server solves these problems
(CI) - CLI is used by CI workflows to measure model performance and accuracy with the newest versions of SW How tt-inference-server solves these problems
images which can be used to deploy our models with standard orchestration technologies (kubernetes). The CLI serves to template Docker run commands and abstract model configuration details from the user. The challenge with using the Docker images comes with knowing all the arguments and variables to set.
the ModelSpec. The ModelSpec is a simple object that contains all model configuration Here is an example for meta-llama/Llama-3.3-70B-Instruct on Galaxy - https://gist.github.com/bgoelTT/37bd2af4ea3a9cd8ee57e85513a65227
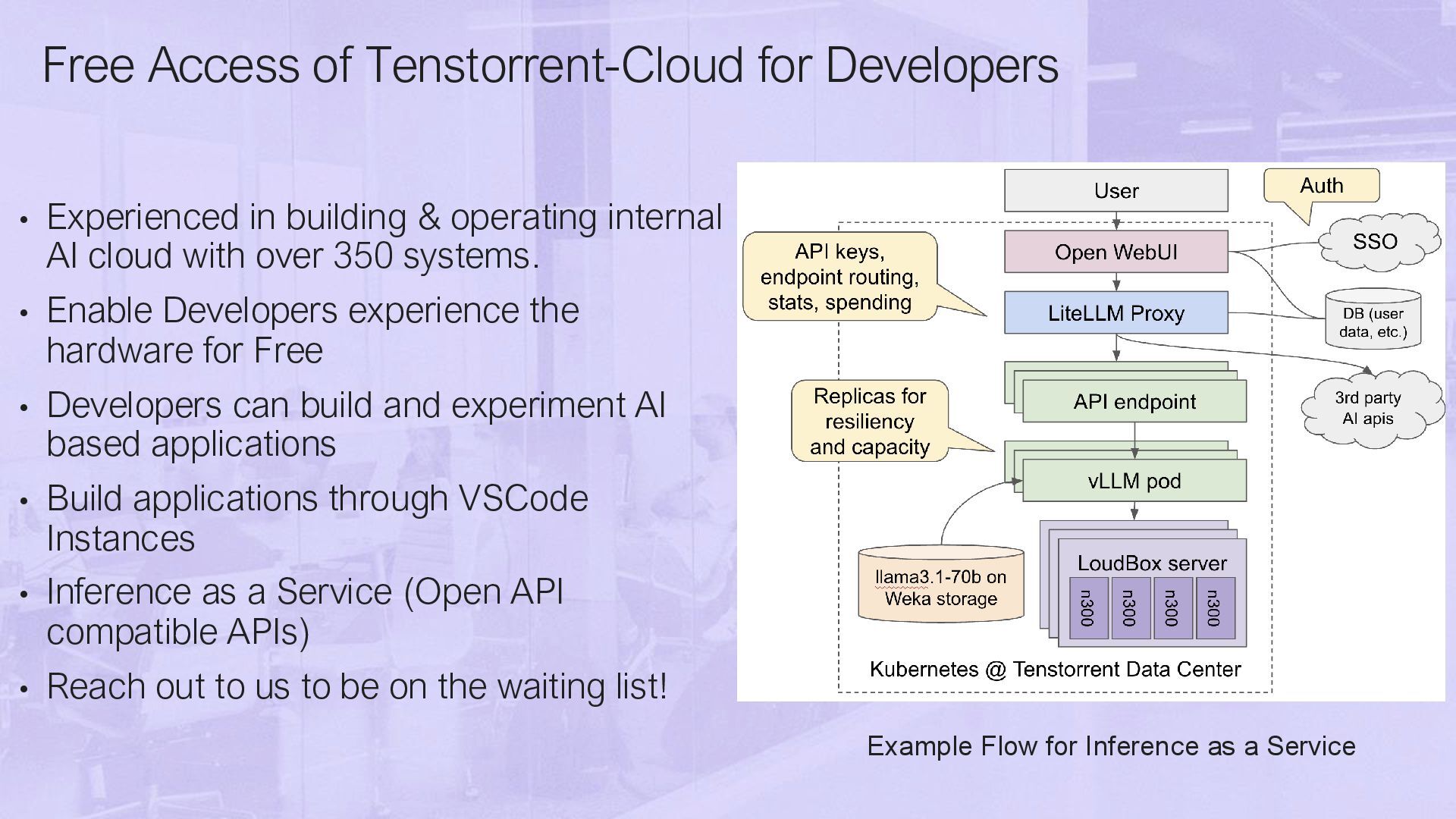
& operating internal AI cloud with over 350 systems. • Enable Developers experience the hardware for Free • Developers can build and experiment AI based applications • Build applications through VSCode Instances • Inference as a Service (Open API compatible APIs) • Reach out to us to be on the waiting list! Example Flow for Inference as a Service
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![tt-inference-server Overview September 10, 2025 Ben Goel - [email protected]](https://files.speakerdeck.com/presentations/82b9faea131644679b5c1b7409eb55ac/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}