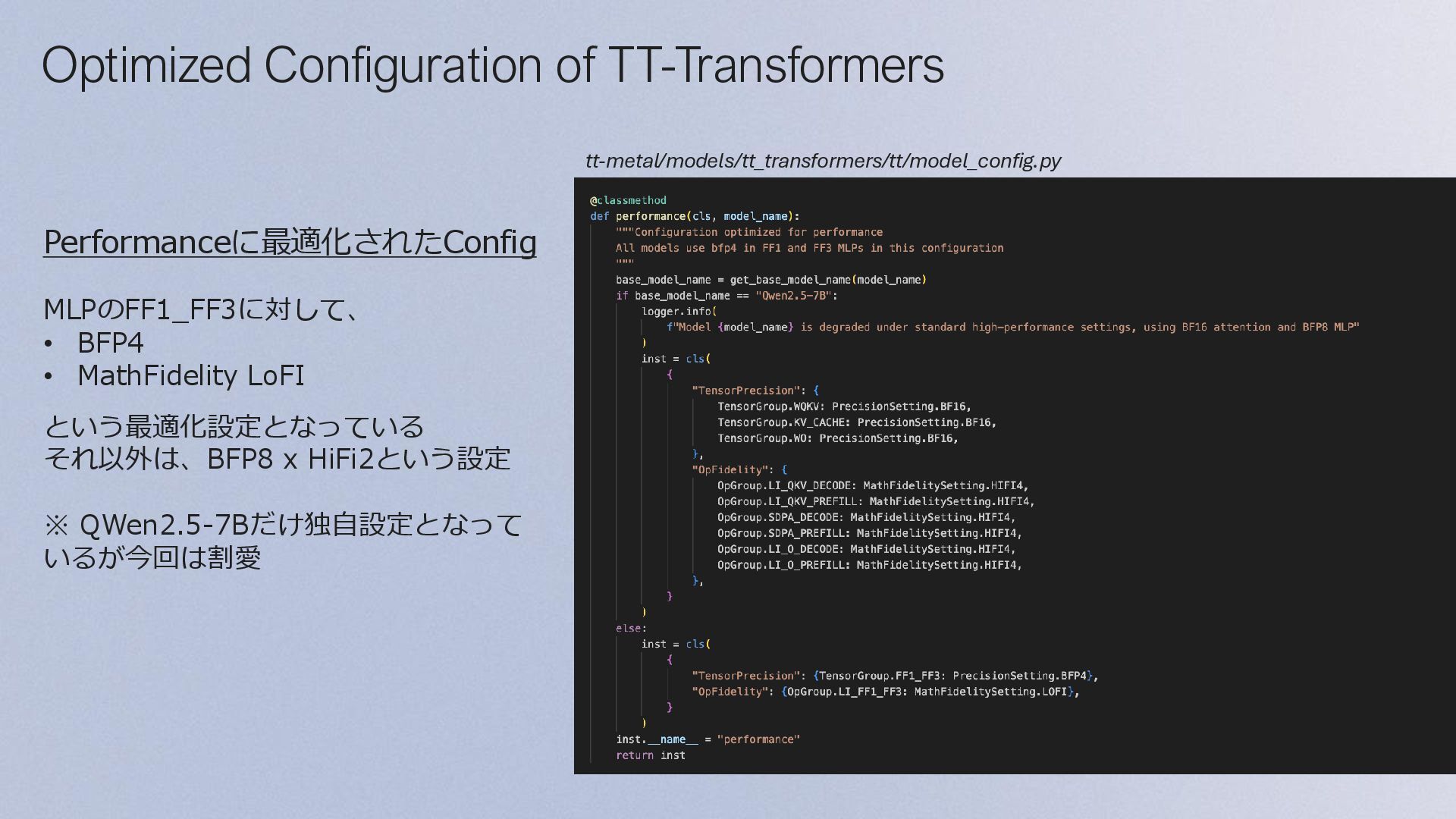
e a a a e e g e a a 3 a e e g e a a 1 Block Floating Point Math Fidelity GroupingしてExponentを共通化することで圧縮したData Format 5bit x 7bitの乗算器が1Cycleで計算できる それ以上のサイズは最大4Stepsに分けて計算することで精度を担保 1~2Stepsで計算をストップさせることで高速化が可能
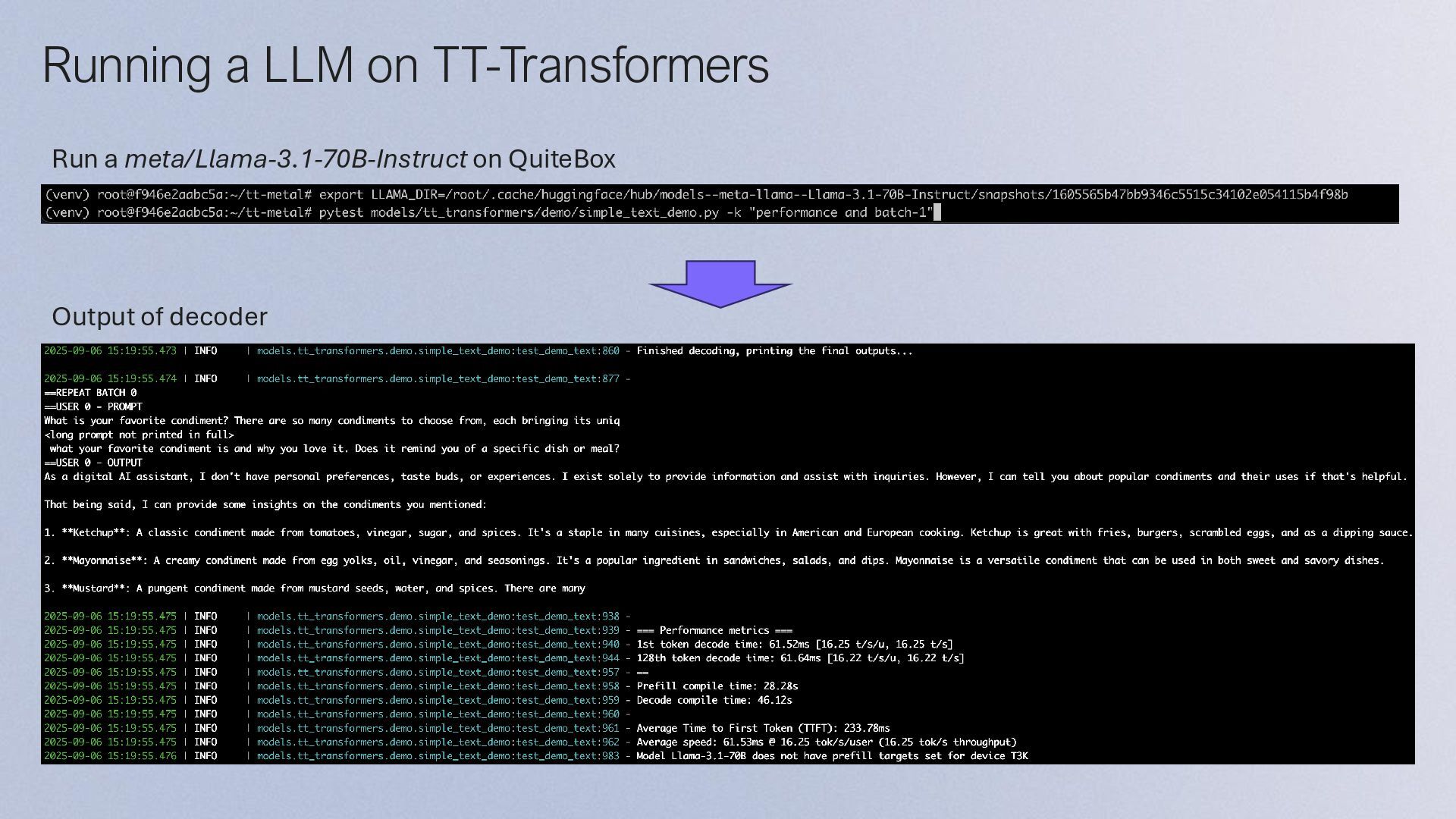
TTNN • Step2: Install python dependencies of TT-Transformers • Step3: Download weights of LLM • Step4: Set `HF_MODEL` or `LLAMA_DIR` environment variable • Step5: Run the tt-transformers
Llama70B on QuiteBox, single batch with 32 prompts • Run a Llama-3.1 70B on Galaxy (Wormhole x32) • TT_LLAMA_TEXT_VER: tt-metalのGalaxy用の実装を指定 • --override_tt_config: Tenstorrent専用の設定値 • Run a Llama3.2 11B Vision model
{kind=link}
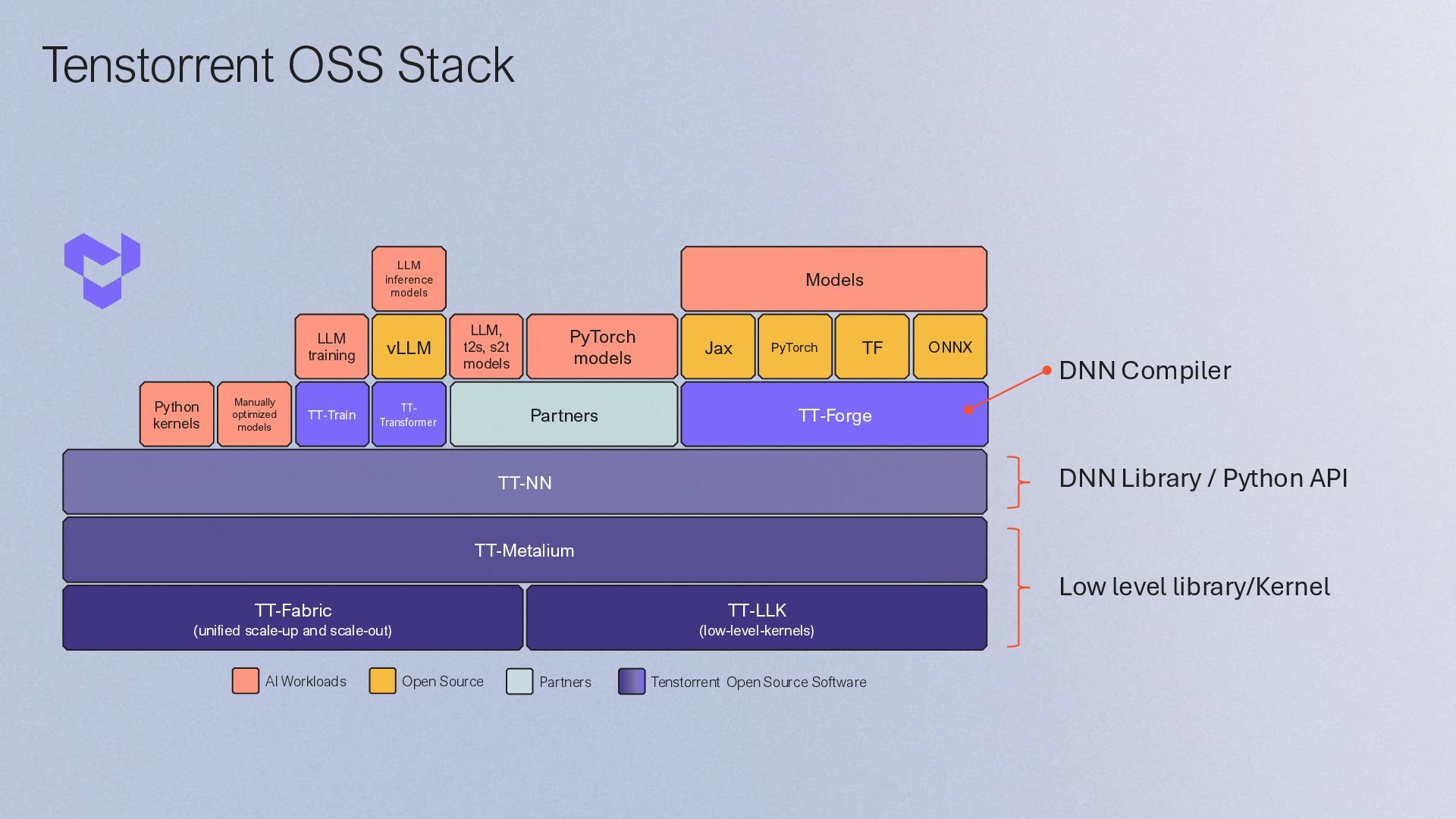{kind=link}
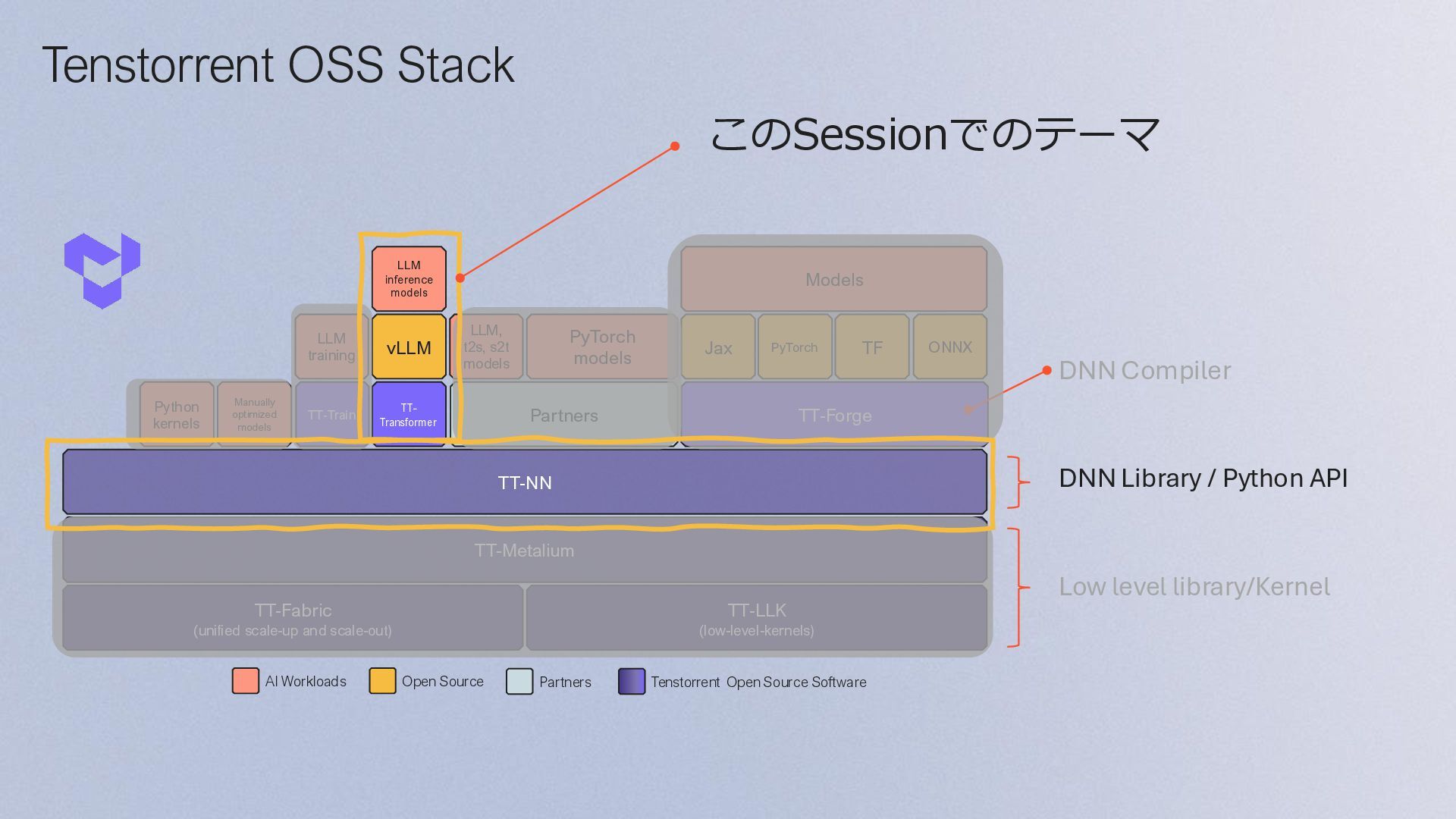{kind=link}
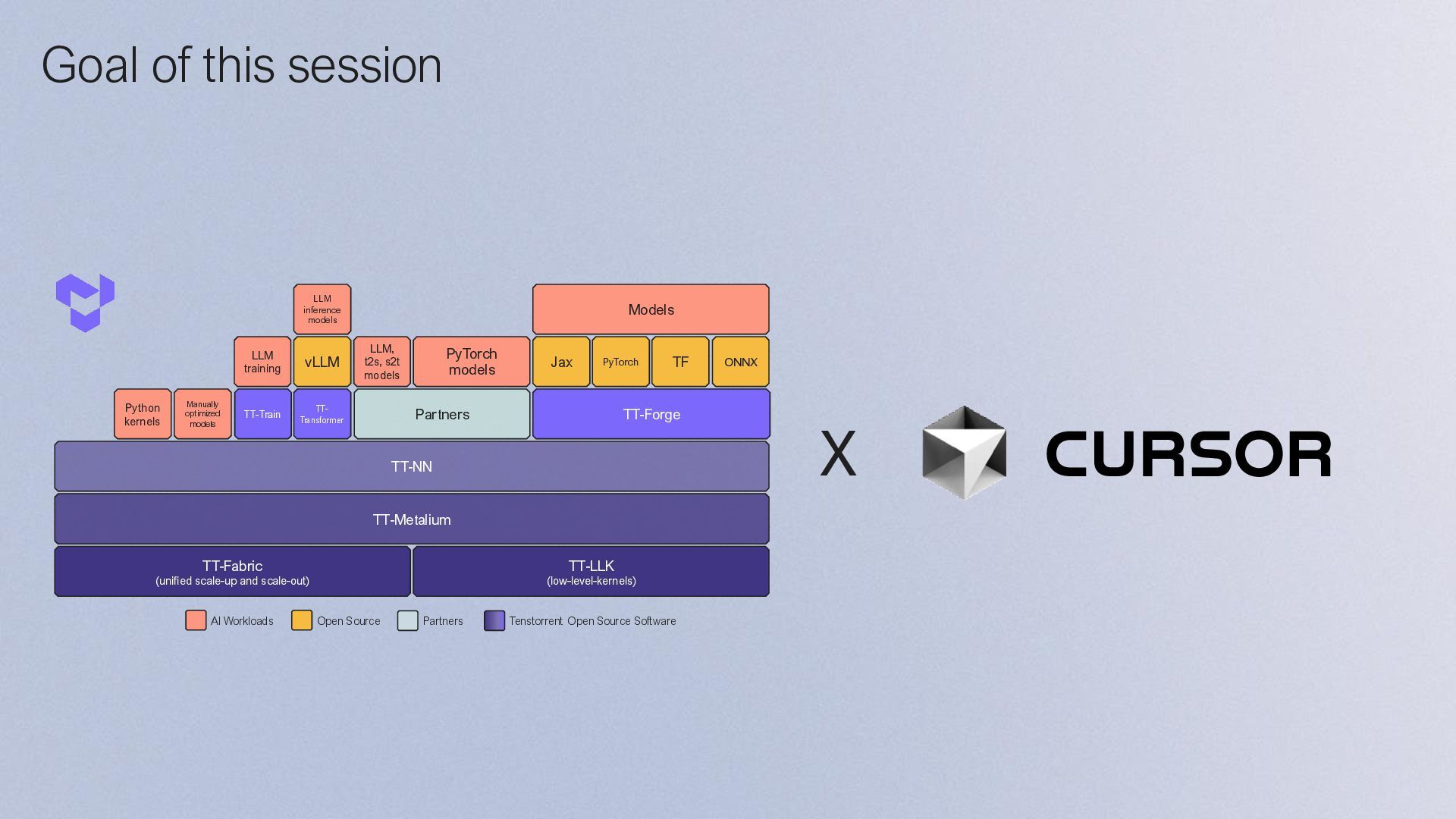{kind=link}
{kind=link}
{kind=link}
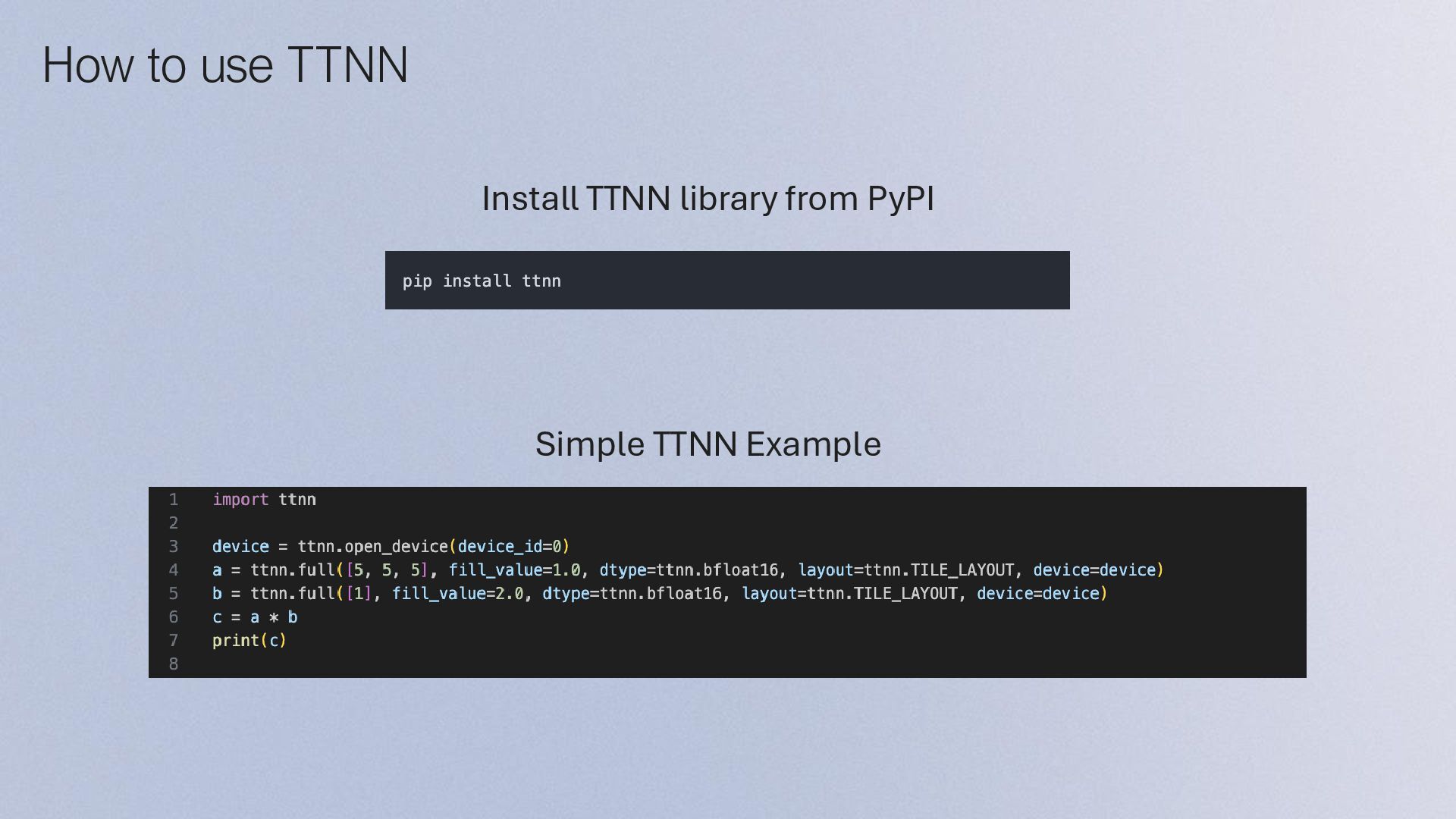{kind=link}
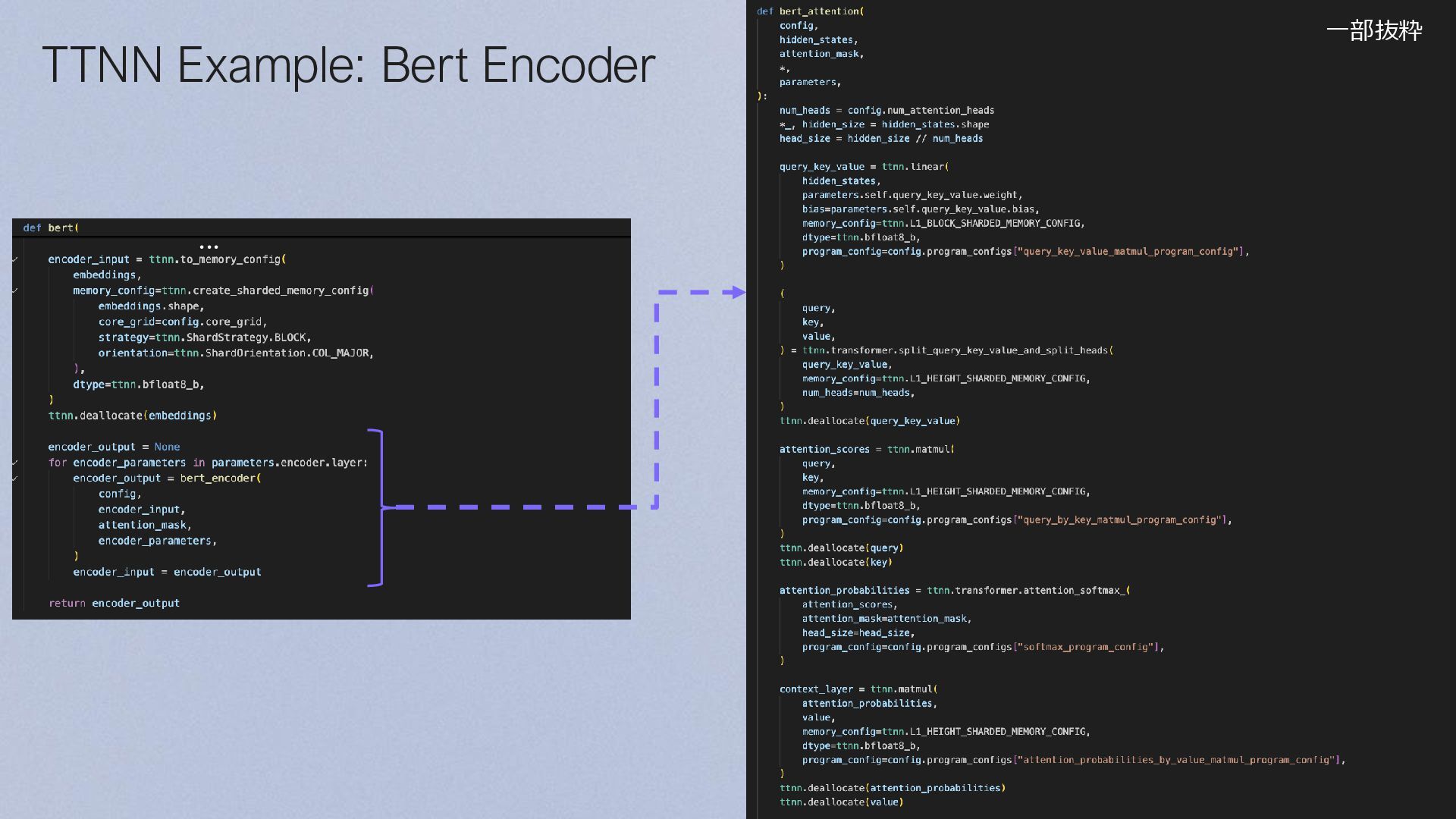{kind=link}
{kind=link}
{kind=link}
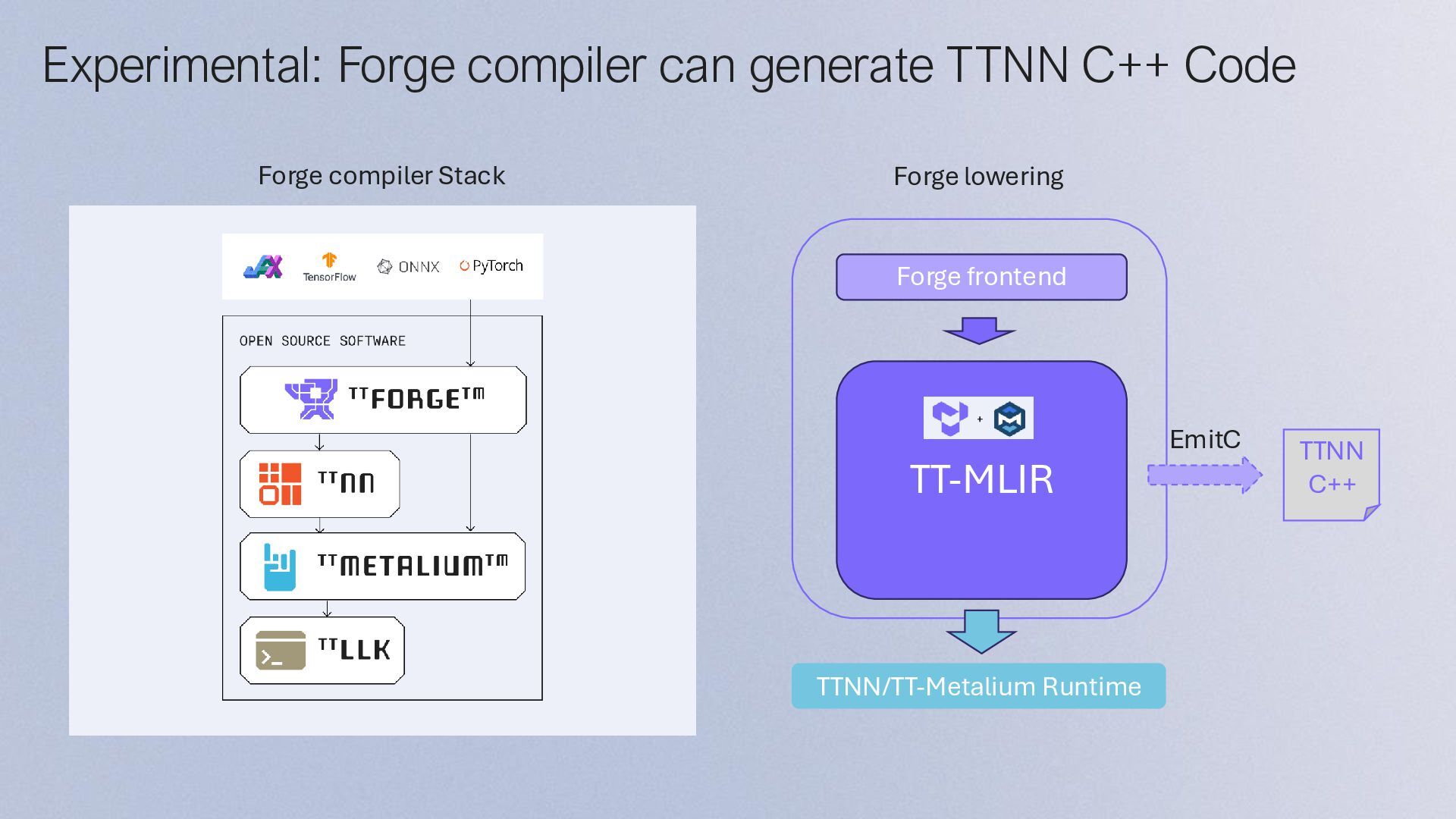{kind=link}
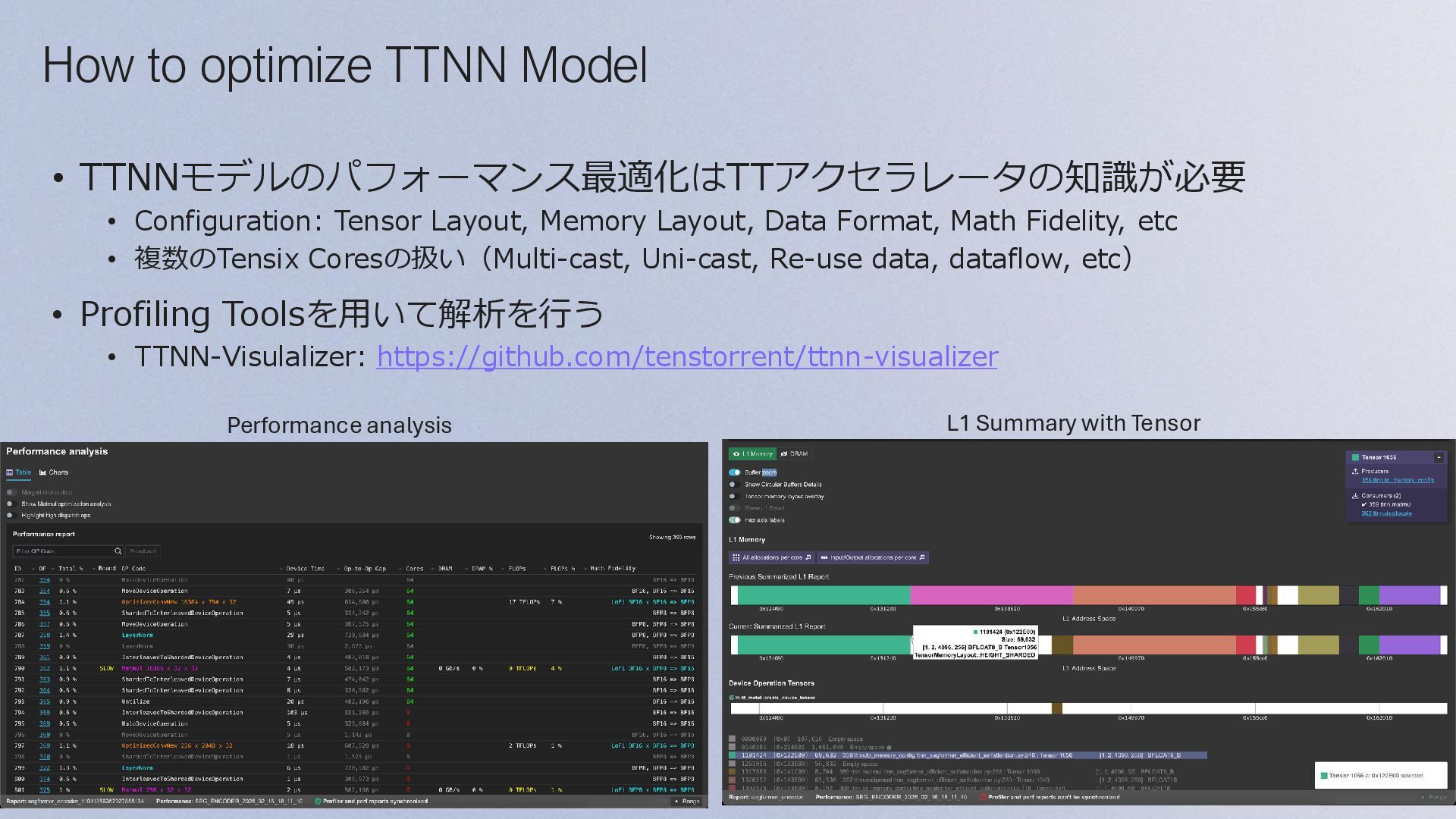{kind=link}
![Configuration: Tensor Layout Page 0 = [0,0 to 0,63] Page](https://files.speakerdeck.com/presentations/e1efa7cc63634b1a810a7b787102c5ef/slide_12.jpg){kind=link}
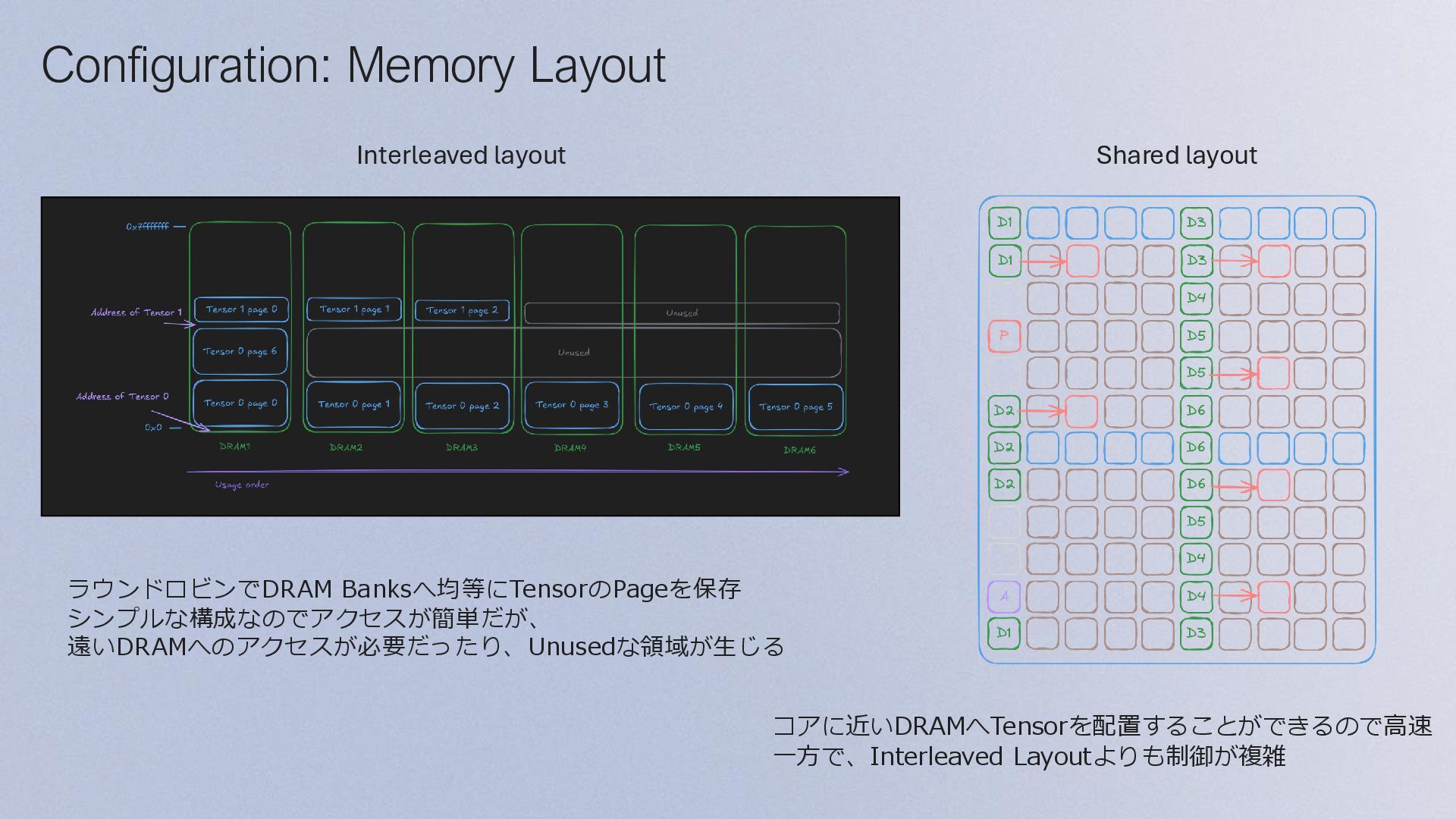{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
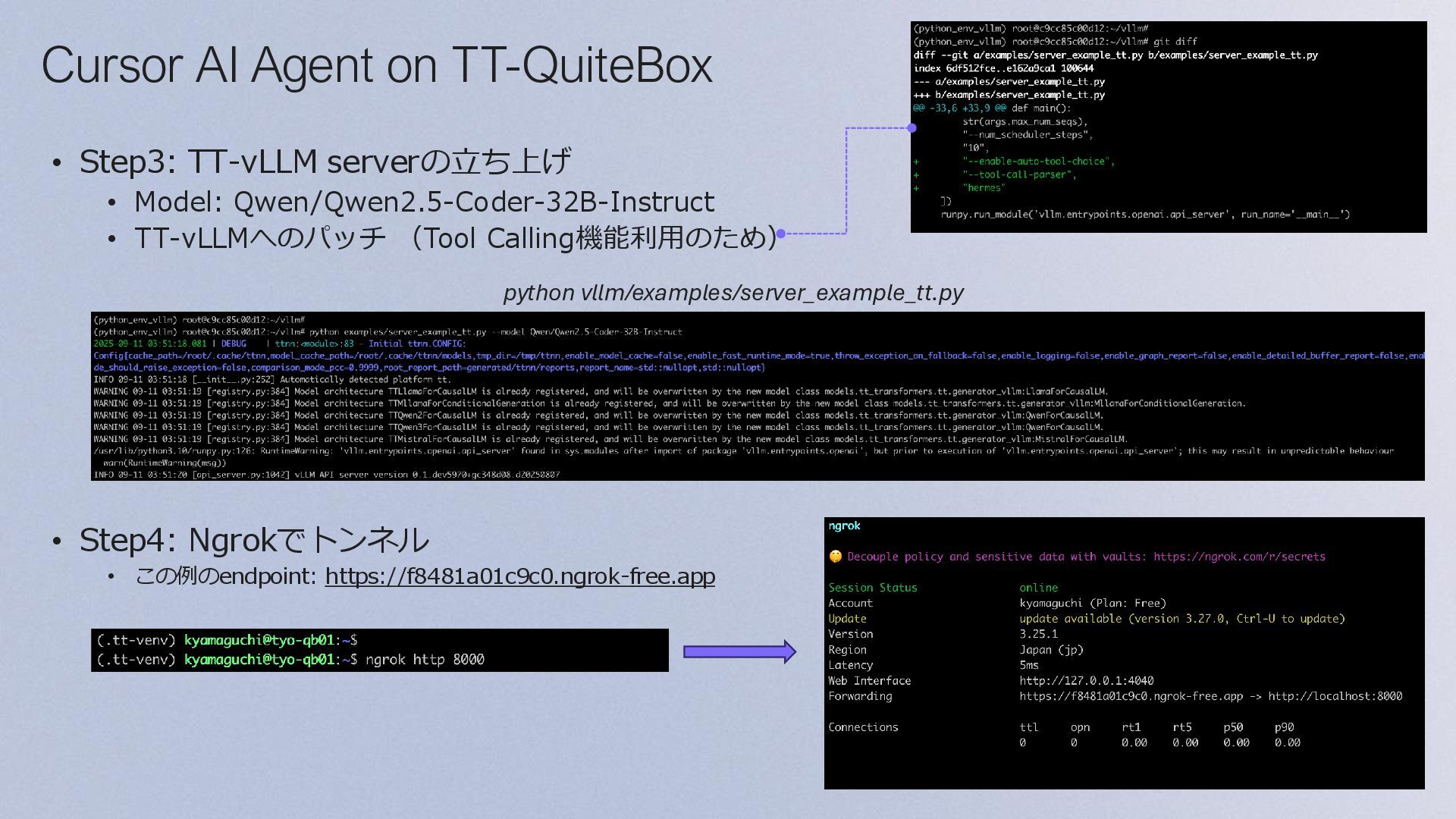{kind=link}
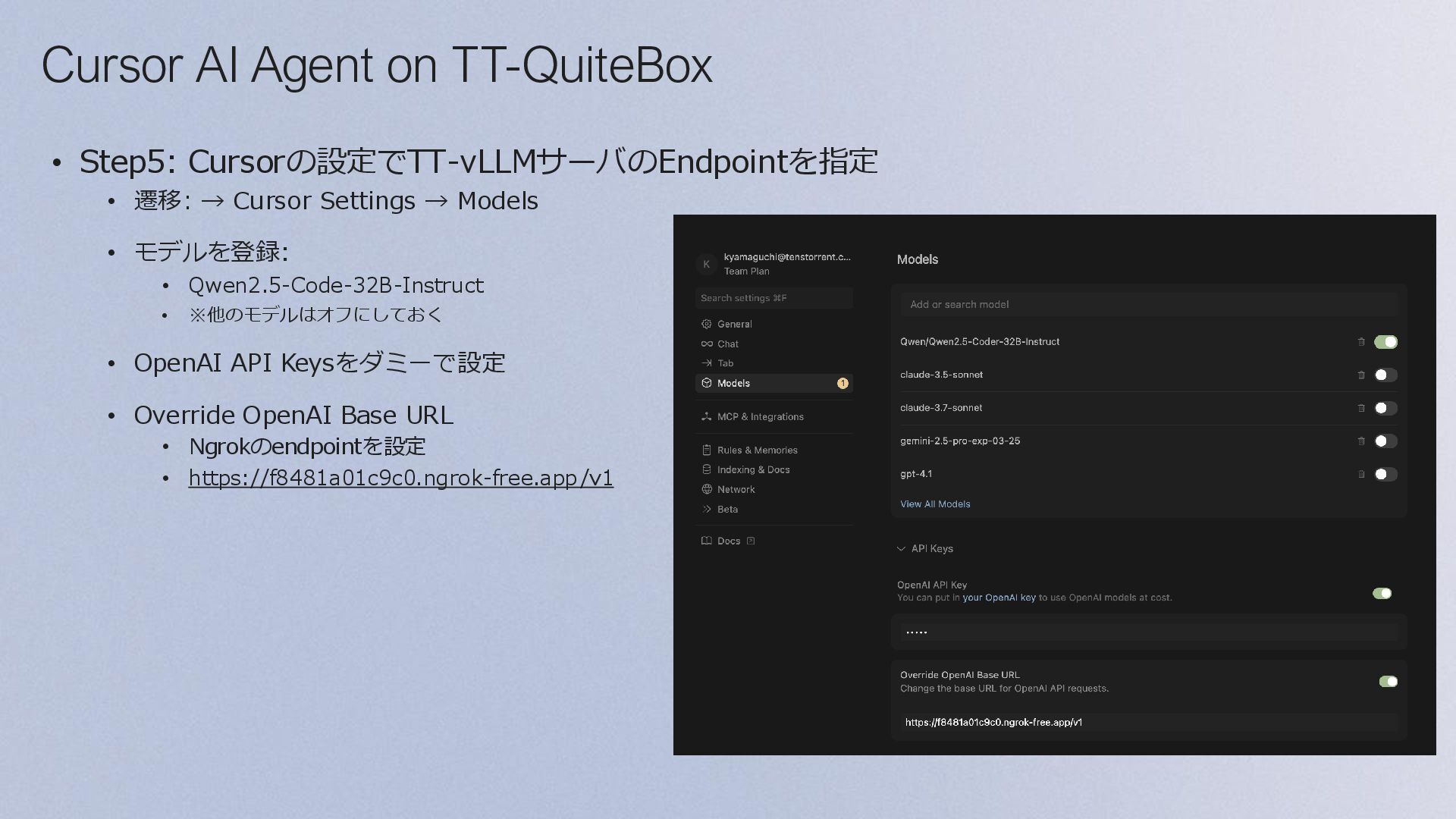{kind=link}
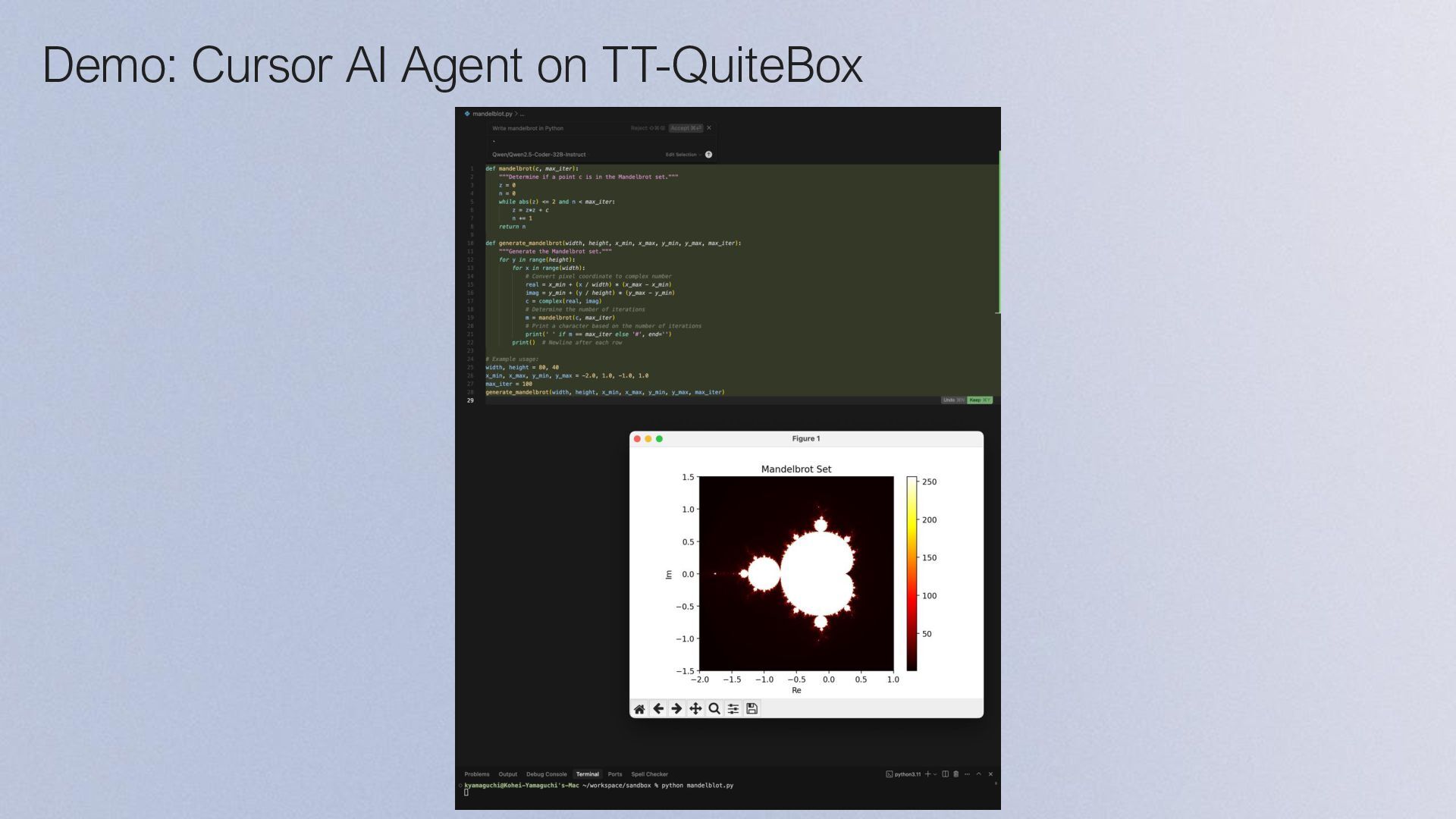{kind=link}
{kind=link}
{kind=link}
{kind=link}