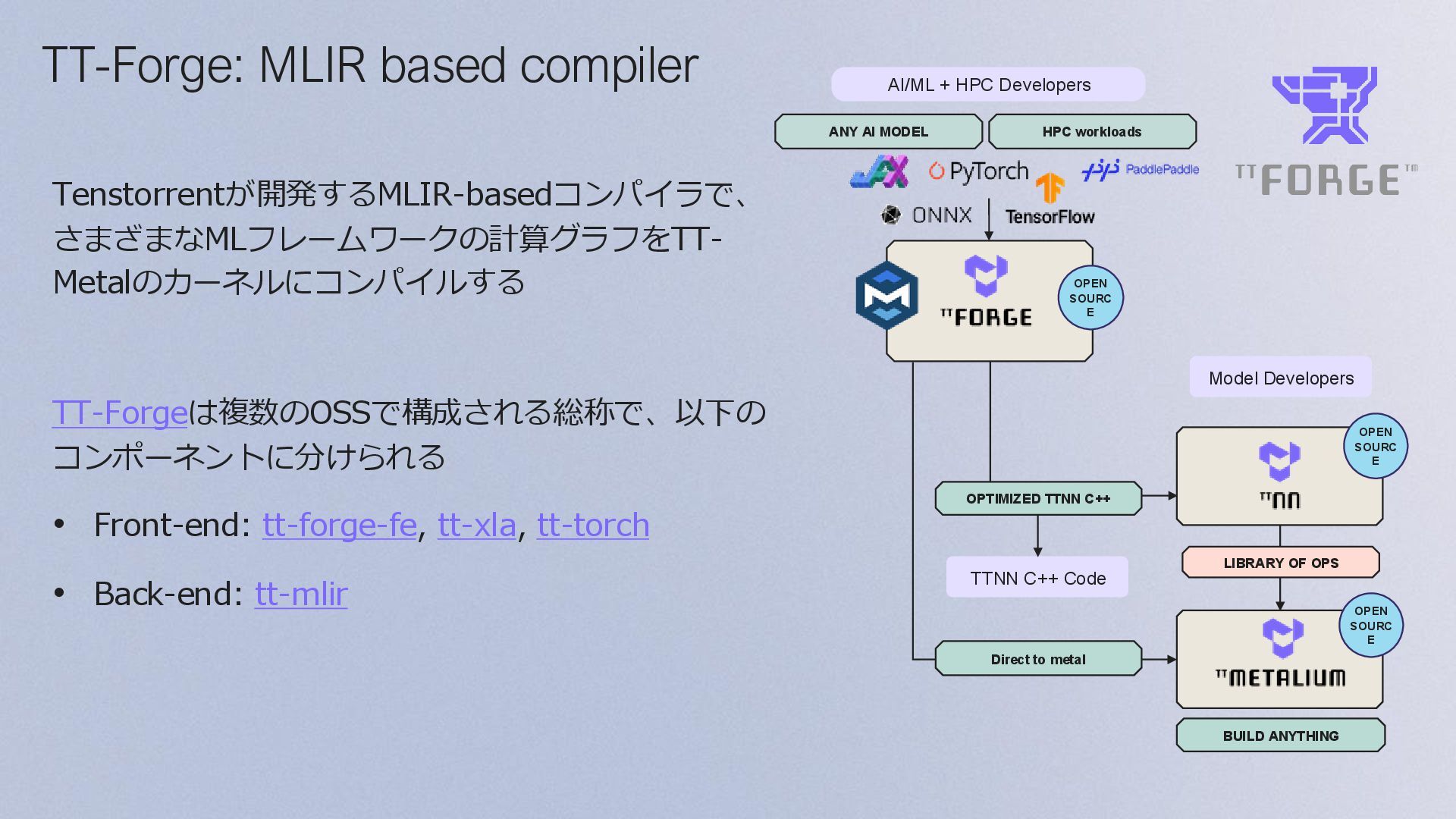
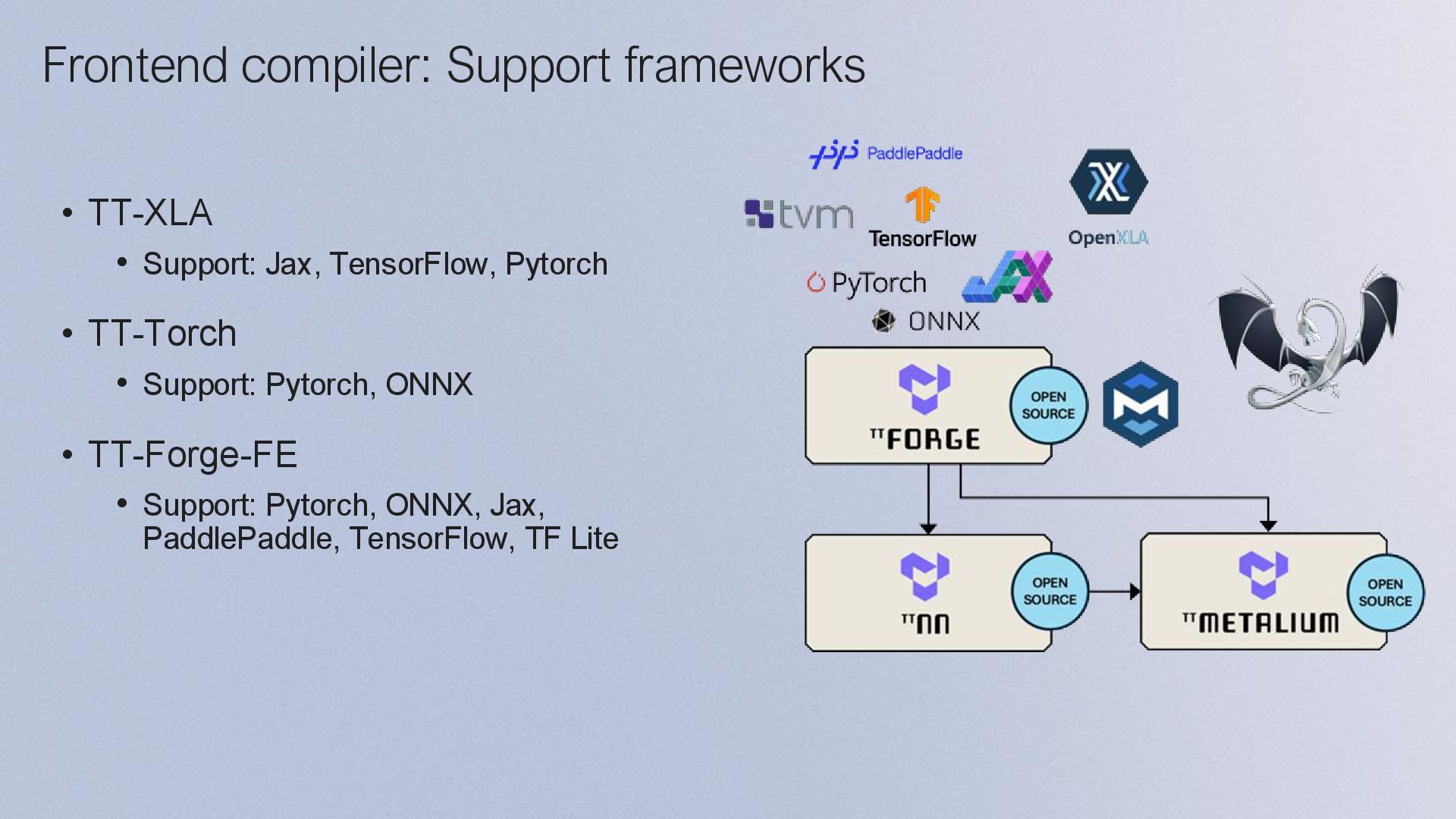
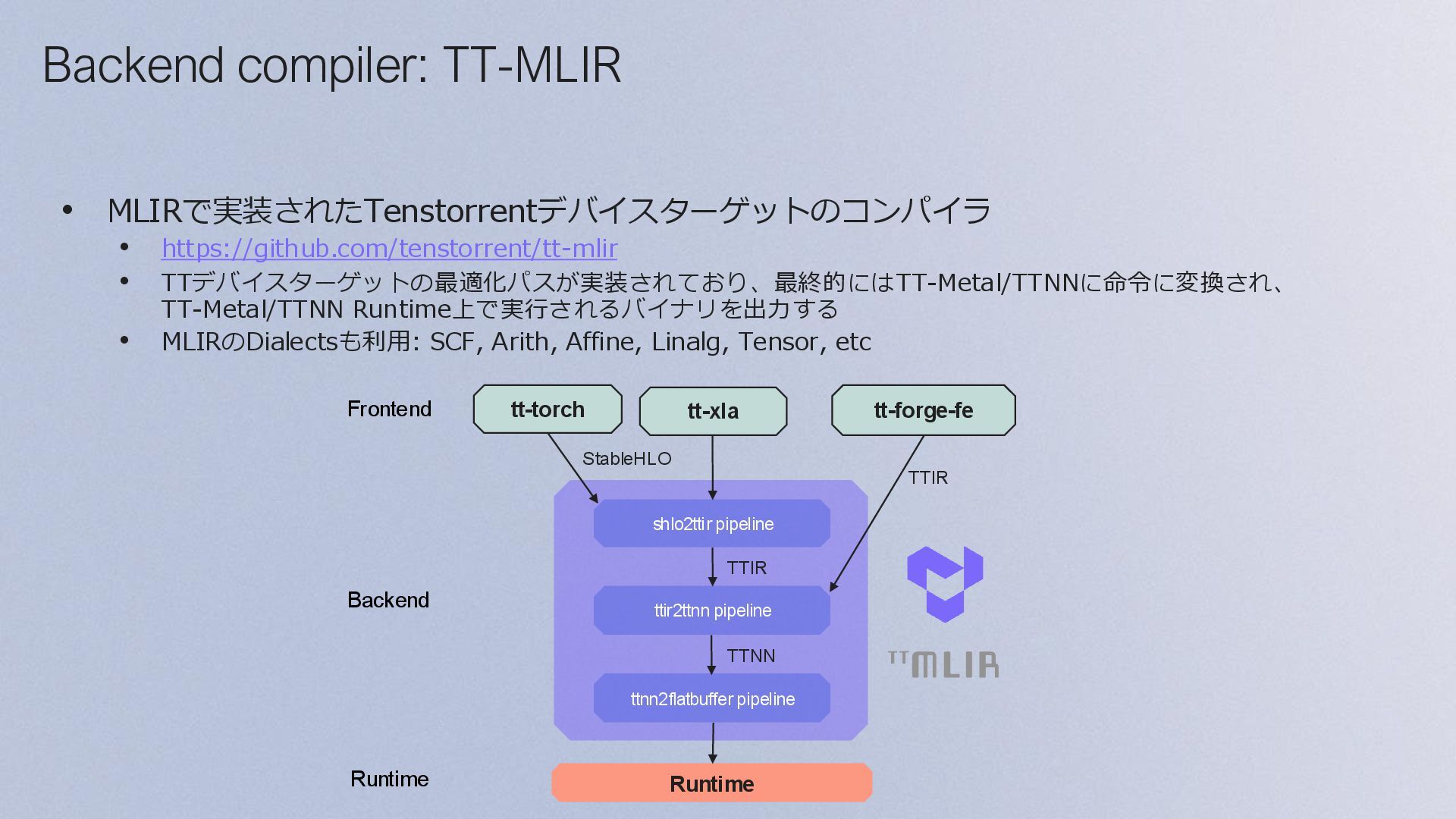
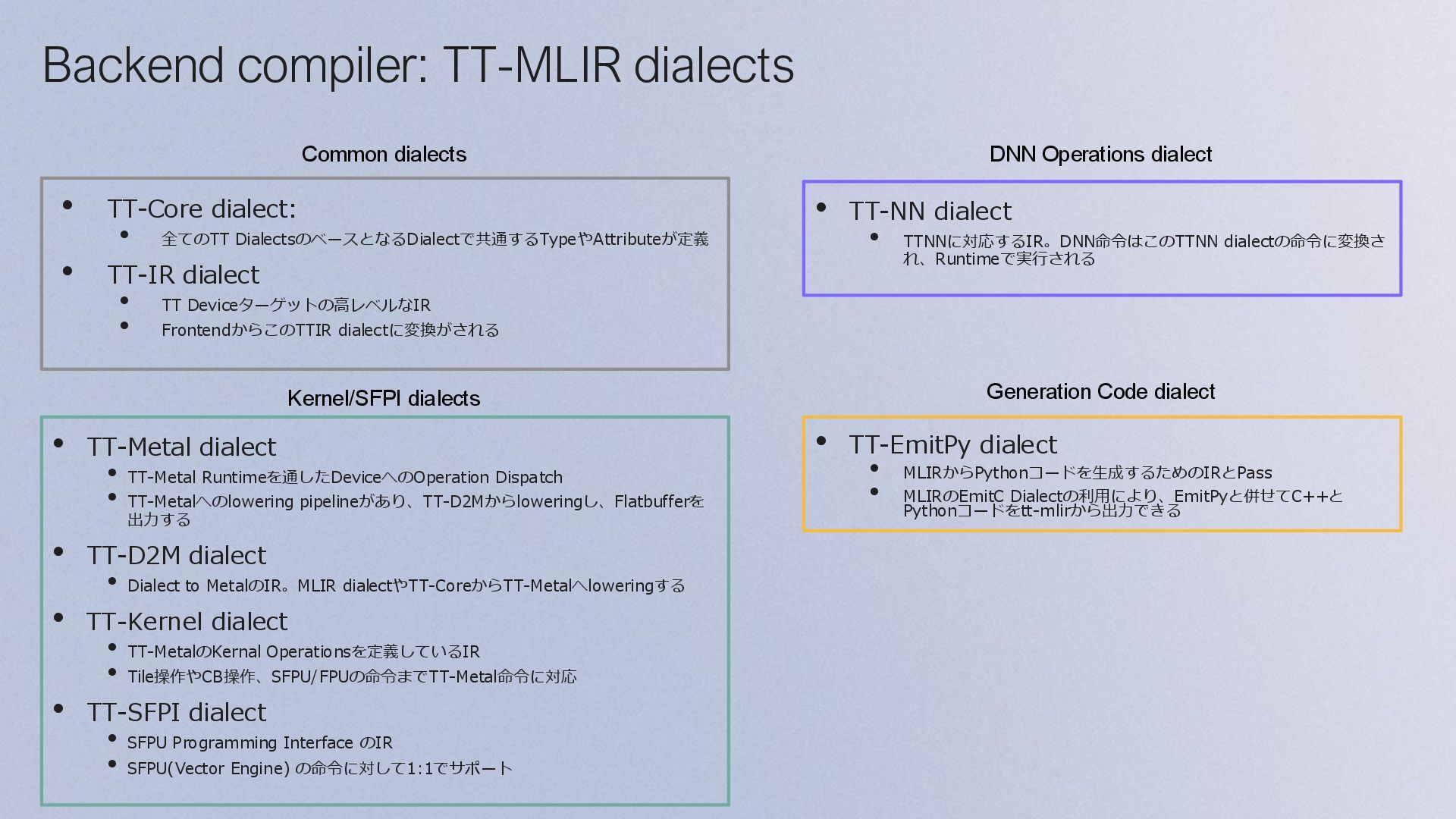
+ HPC Developers Model Developers Direct to metal OPTIMIZED TTNN C++ BUILD ANYTHING LIBRARY OF OPS OPEN SOURC E TTNN C++ Code HPC workloads TT-Forge: MLIR based compiler Tenstorrentが開発するMLIR-basedコンパイラで、 さまざまなMLフレームワークの計算グラフをTT- Metalのカーネルにコンパイルする TT-Forgeは複数のOSSで構成される総称で、以下の コンポーネントに分けられる • Front-end: tt-forge-fe, tt-xla, tt-torch • Back-end: tt-mlir
• Multiple framework support • Everything from TT-Buda + • Designed for extendibility and integrations • Native integration with Tenstorrent’s entire AI stack (TT-NN, TT-Metalium, etc.) • More advanced tooling, visualizers, profilers, code generation, and more! From TT-BUDA to TT-Forge From 2024
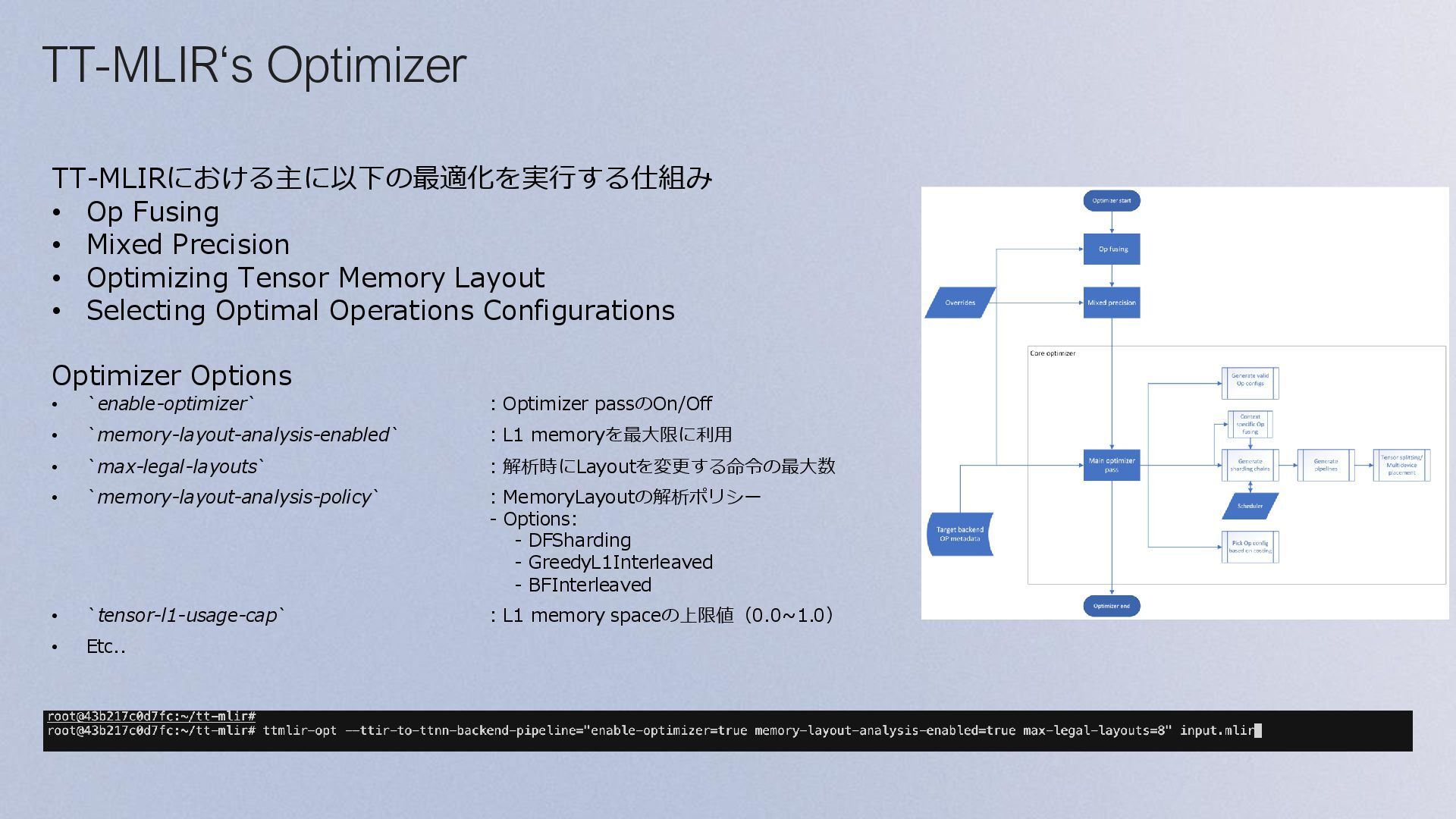
broad compatibility and flexibility across diverse AI workloads with the ability to expand to future frameworks. Performance TT-Forge provides optimized compilation and execution and with our custom dialects, maximizes inference and training performance on Tenstorrent's hardware. Also, we enable further manual tuning using our GUI tools to squeeze out the last few drops of performance out of your workloads. Tooling TT-Forge’s toolchain streamlines ML model compilation, optimization, and execution. Including MLIR-based compilation and runtime inspection, memory and compute profilers as well as a graph visualizer, these tools enable efficient development, debugging, and performance tuning on Tenstorrent hardware. What is TT-Forge
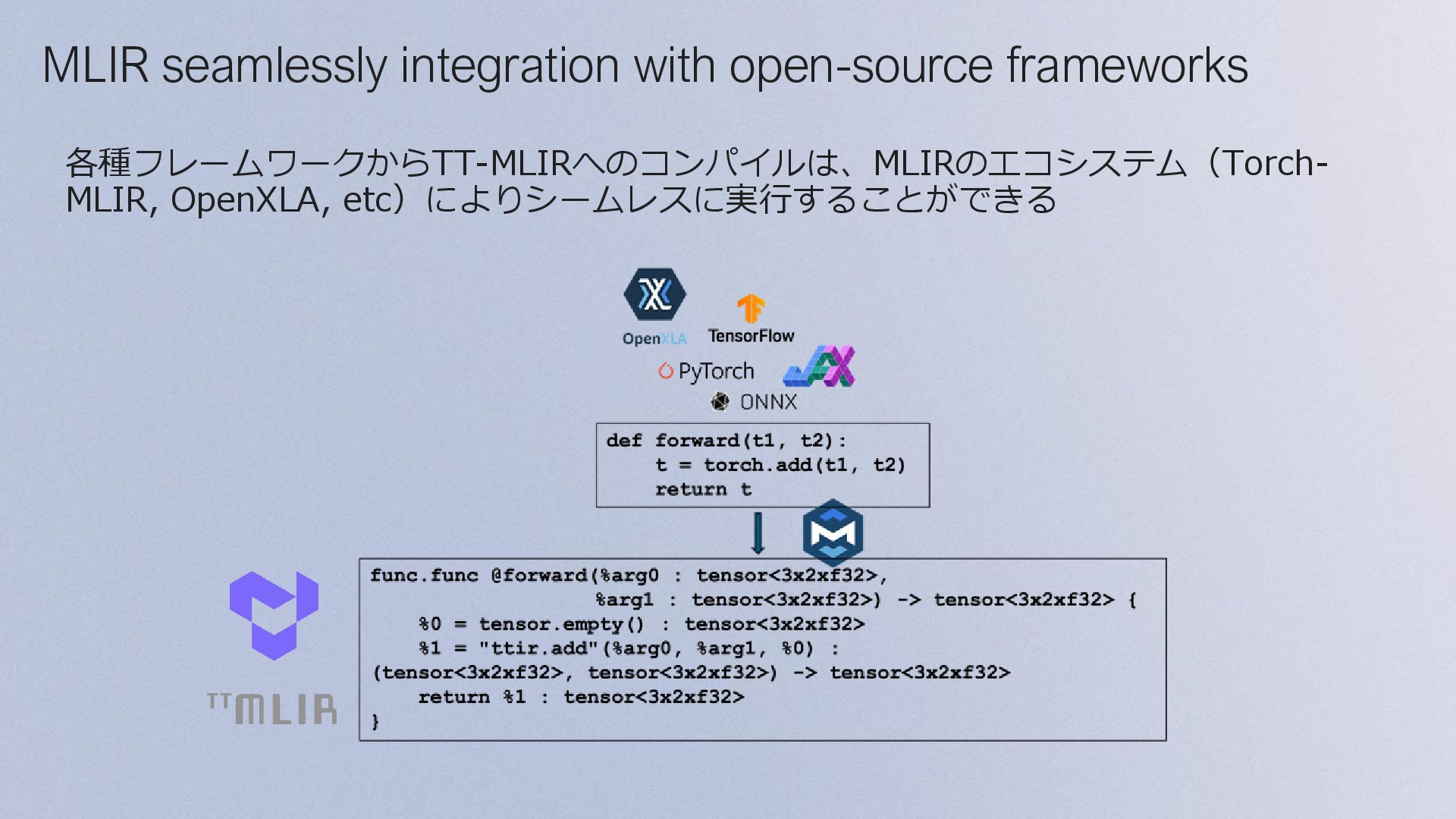
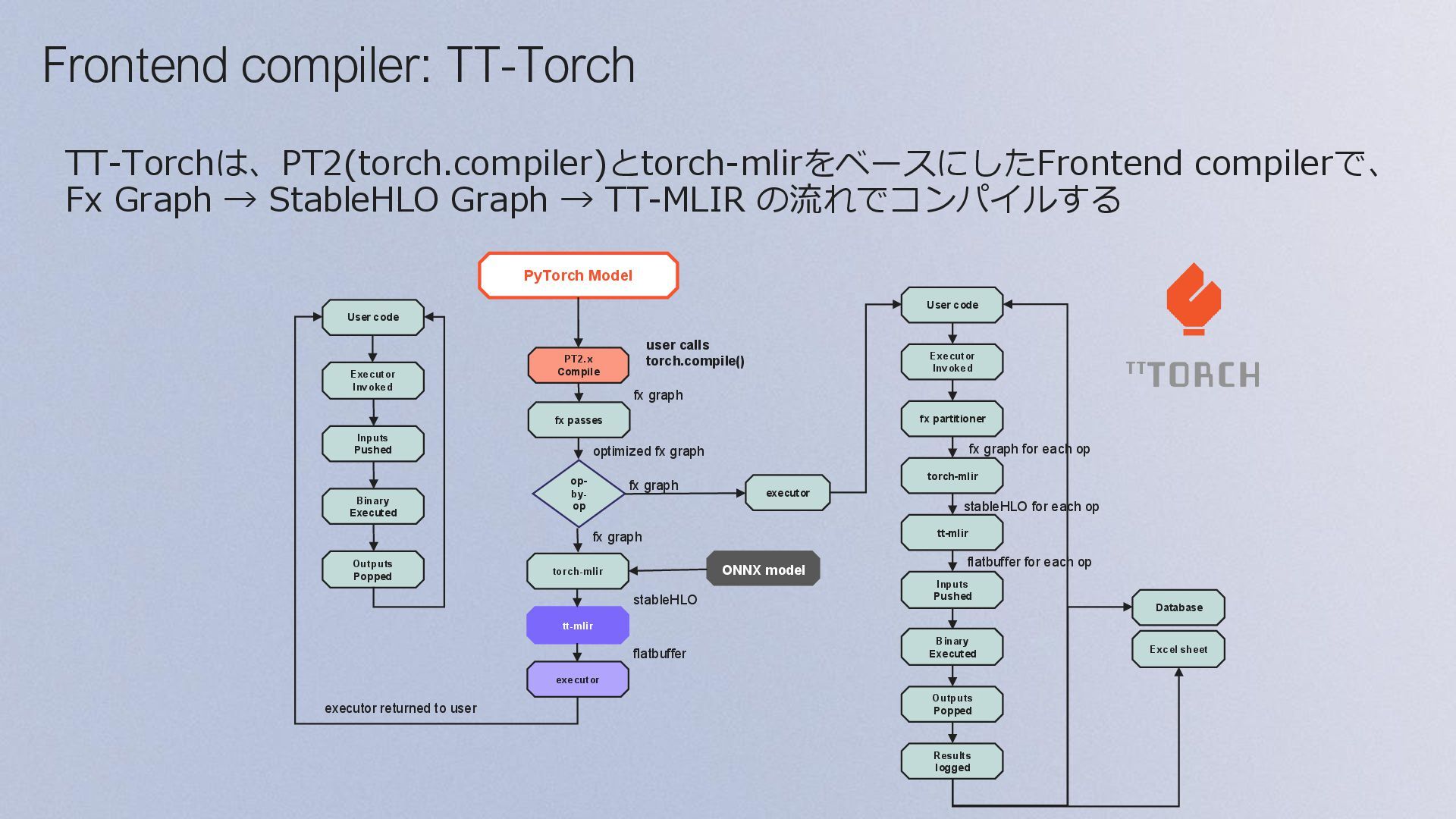
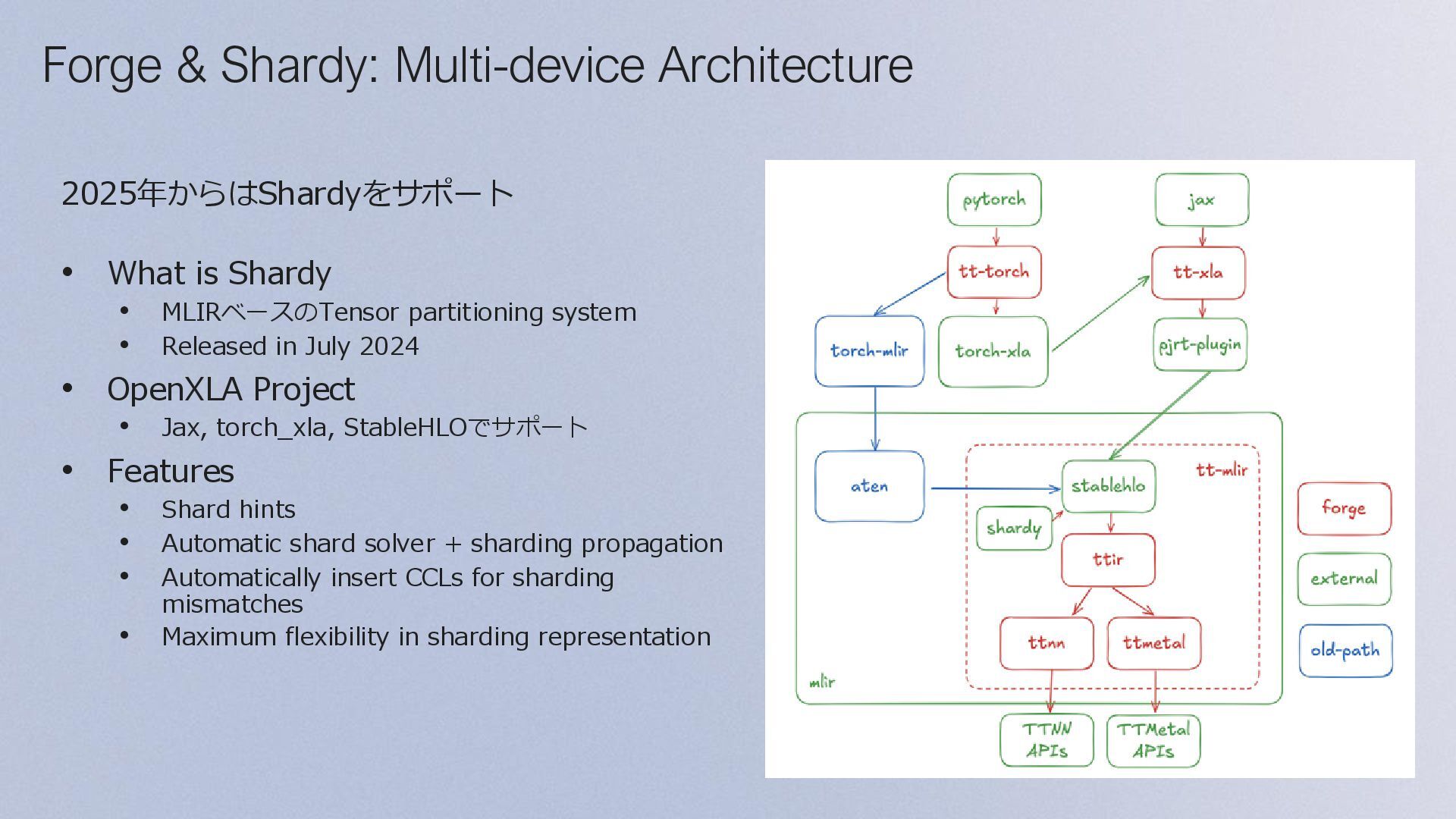
Binary Executed PT2.x Compile fx passes torch-mlir tt-mlir executor executor op- by- op User code Executor Invoked fx partitioner tt-mlir torch-mlir Inputs Pushed Outputs Popped Binary Executed Results logged Database Excel sheet optimized fx graph fx graph fx graph ONNX model stableHLO flatbuffer stableHLO for each op fx graph for each op flatbuffer for each op executor returned to user user calls torch.compile() fx graph Frontend compiler: TT-Torch TT-Torchは、PT2(torch.compiler)とtorch-mlirをベースにしたFrontend compilerで、 Fx Graph → StableHLO Graph → TT-MLIR の流れでコンパイルする
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
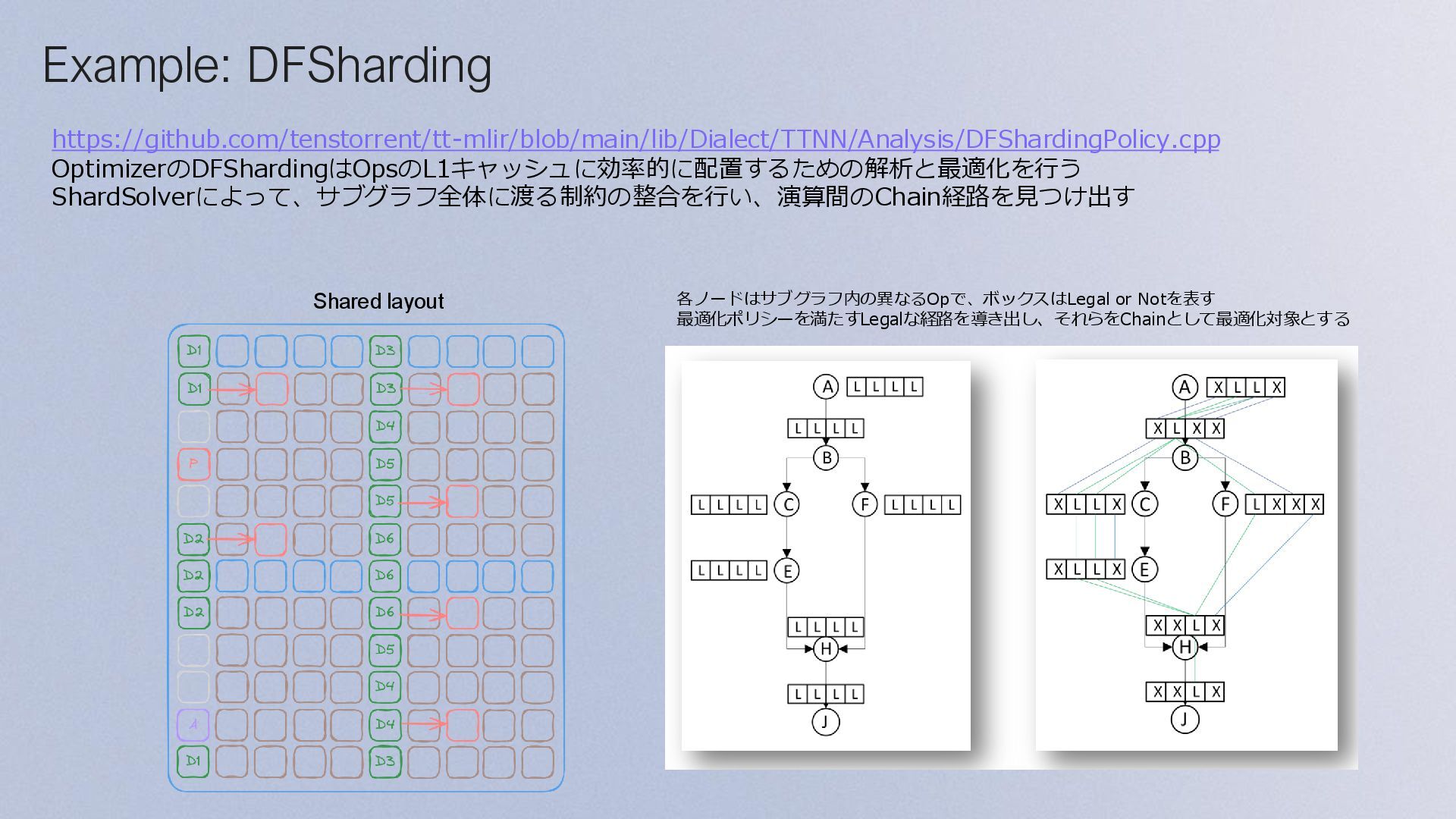{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
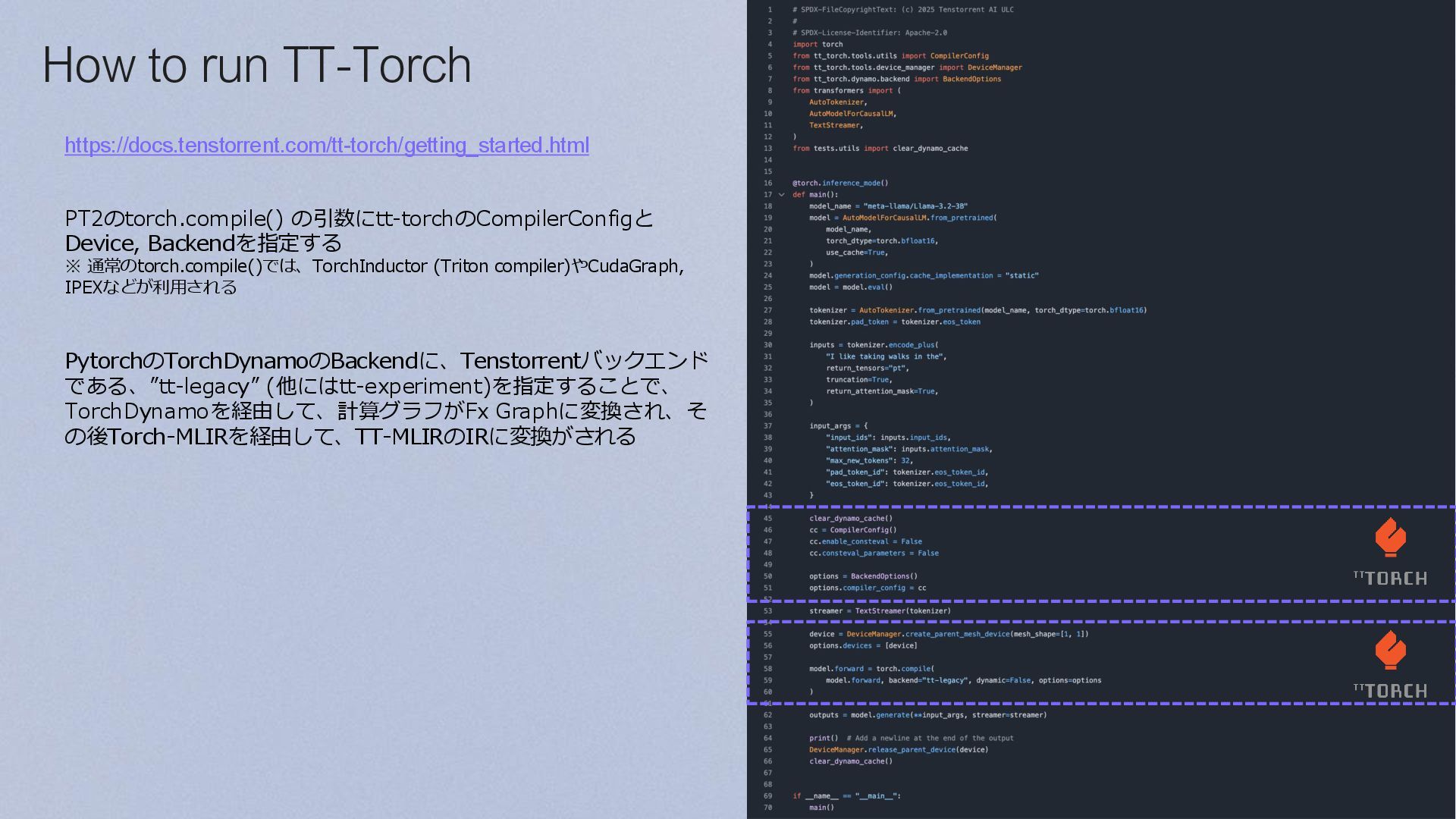{kind=link}
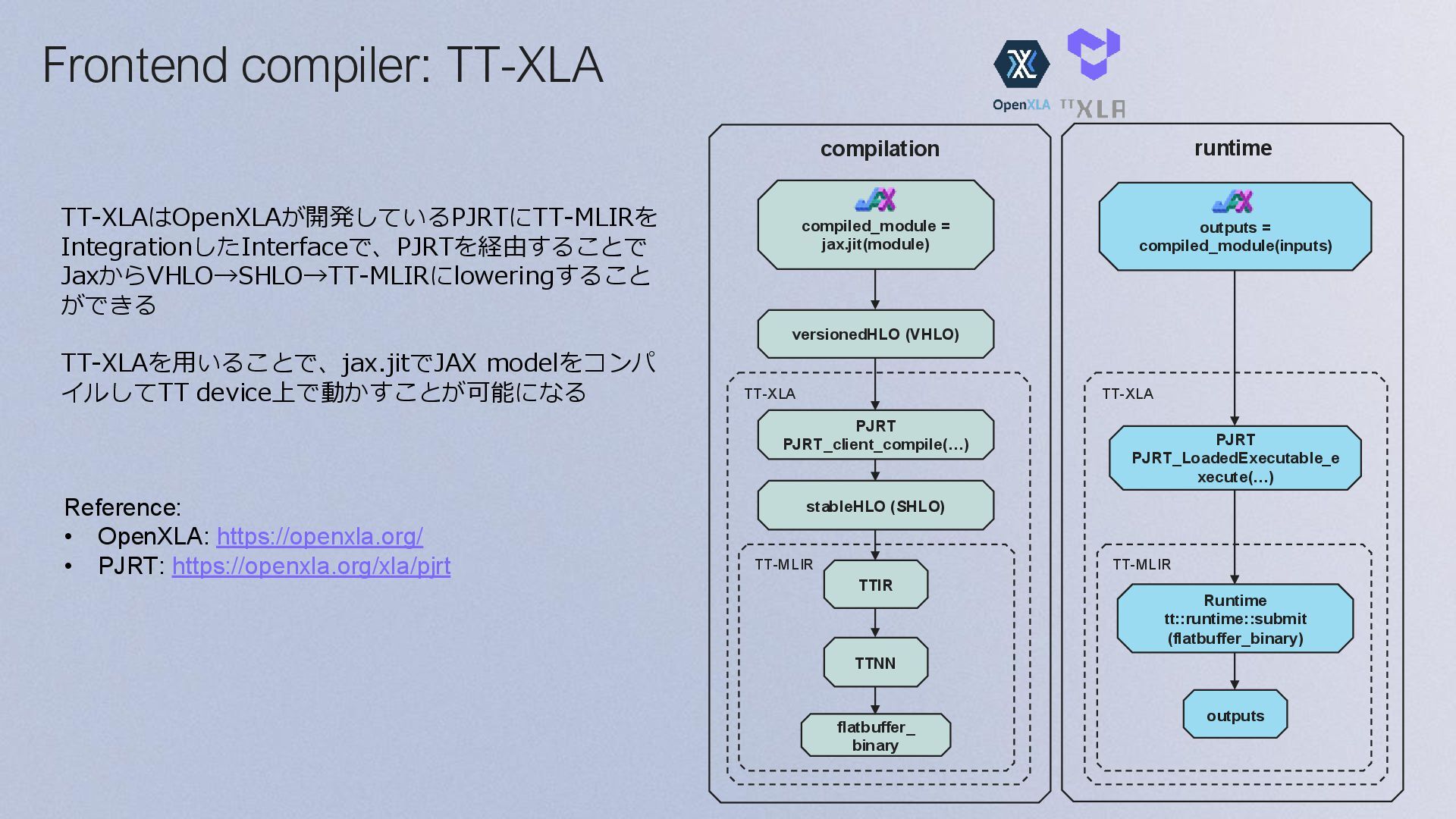{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}