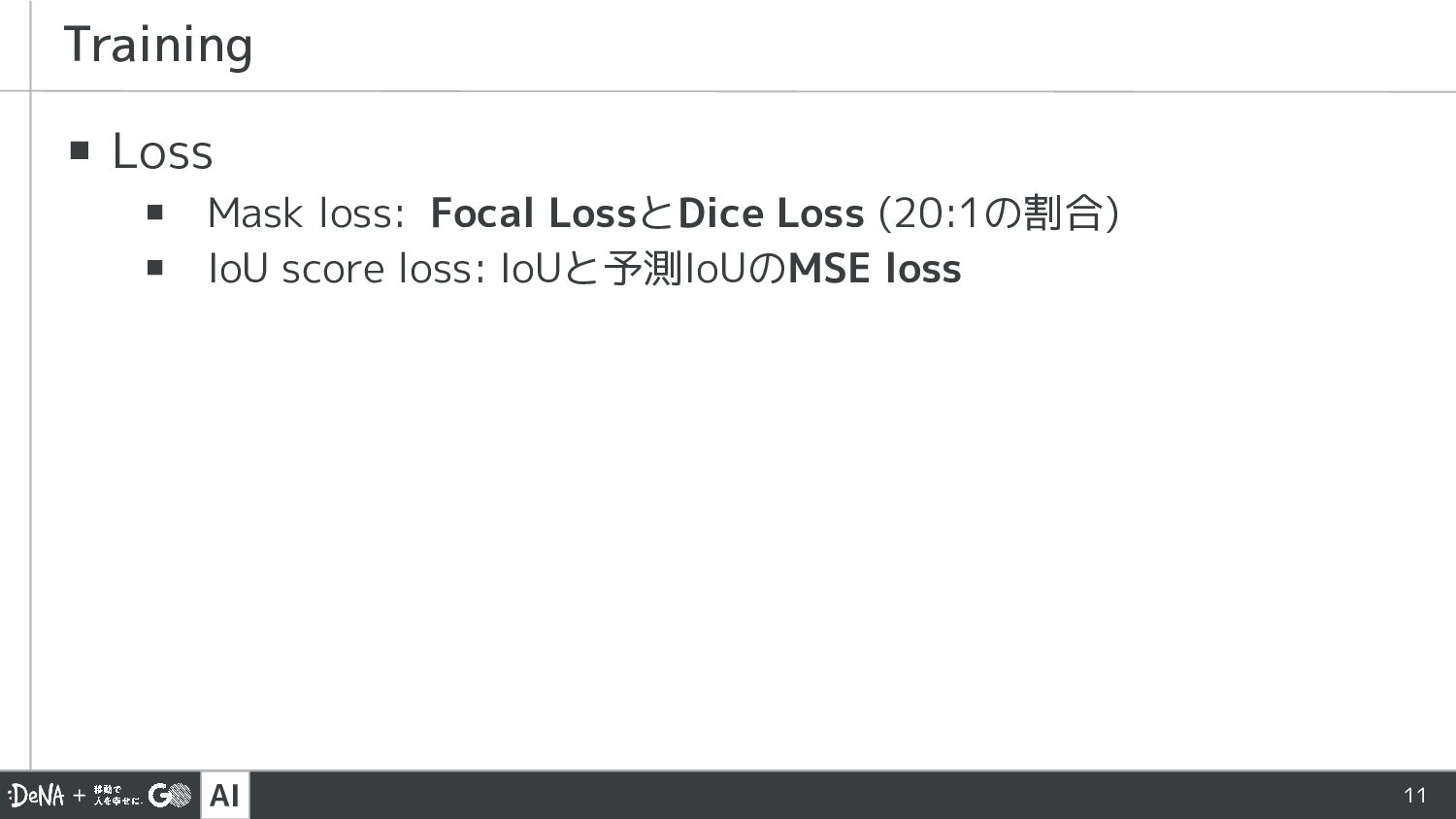
SA-1Bデータセットも公開 ▪ 1100万枚の画像 ▪ 10億以上のマスク ▪ アノテーション⇄モデル改善の サイクルを回すことで人の作業を 徐々に減らし、データを増やす Segment Anything Model (SAM)とは A. Kirillov, et al., "Segment anything," in Proc. of ICCV'23.
et al., "Hiera: A hierarchical vision transformer without the bells-and-whistles," in Proc. of ICML'23. • 複数解像度の特徴量を抽出できる Hiera Image Encoder[1]に変更 • SAM2で追加された 動画に対応するためのメモリ機構
{kind=link}
{kind=link}
{kind=link}
{kind=link}
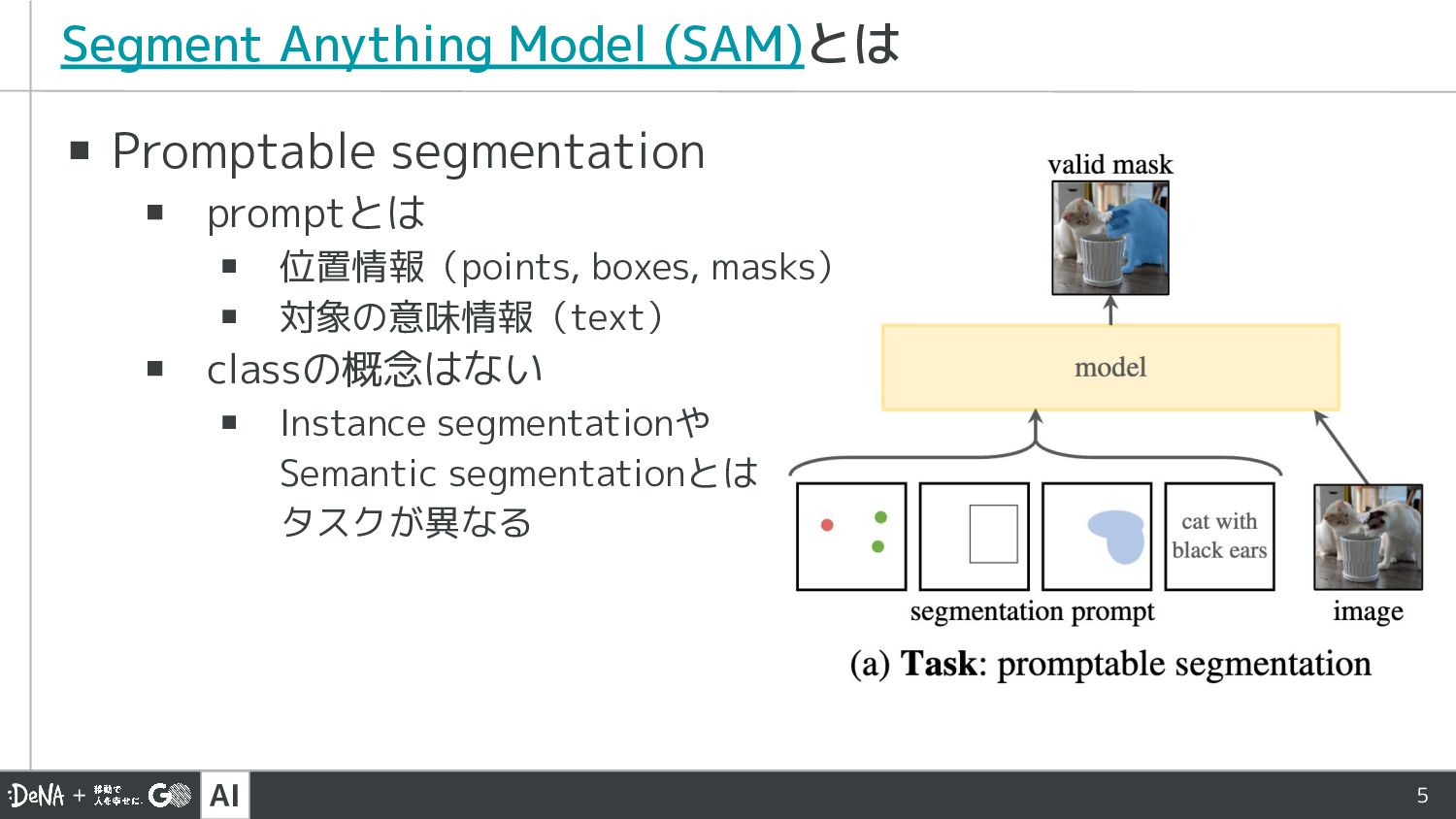{kind=link}
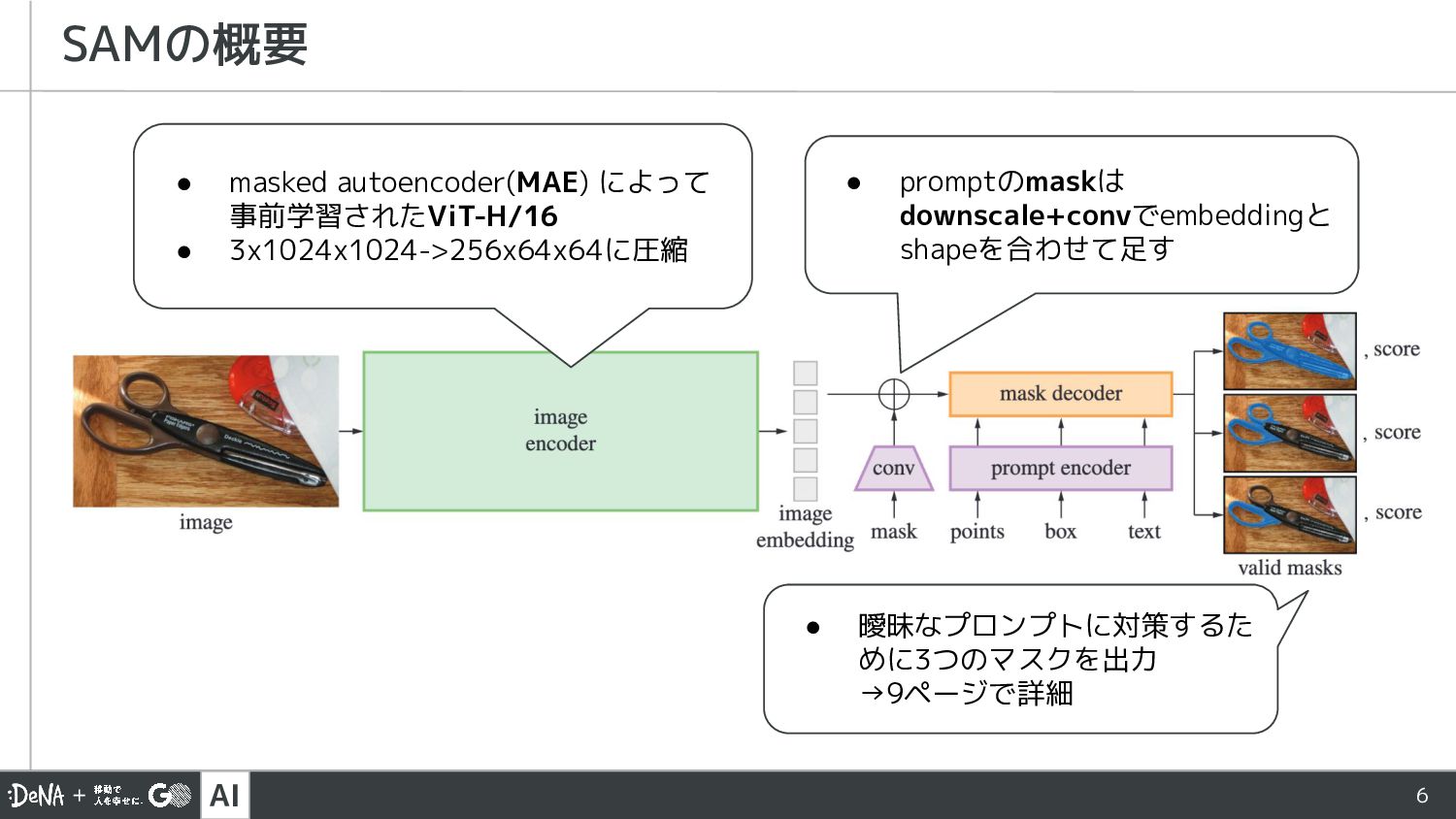{kind=link}
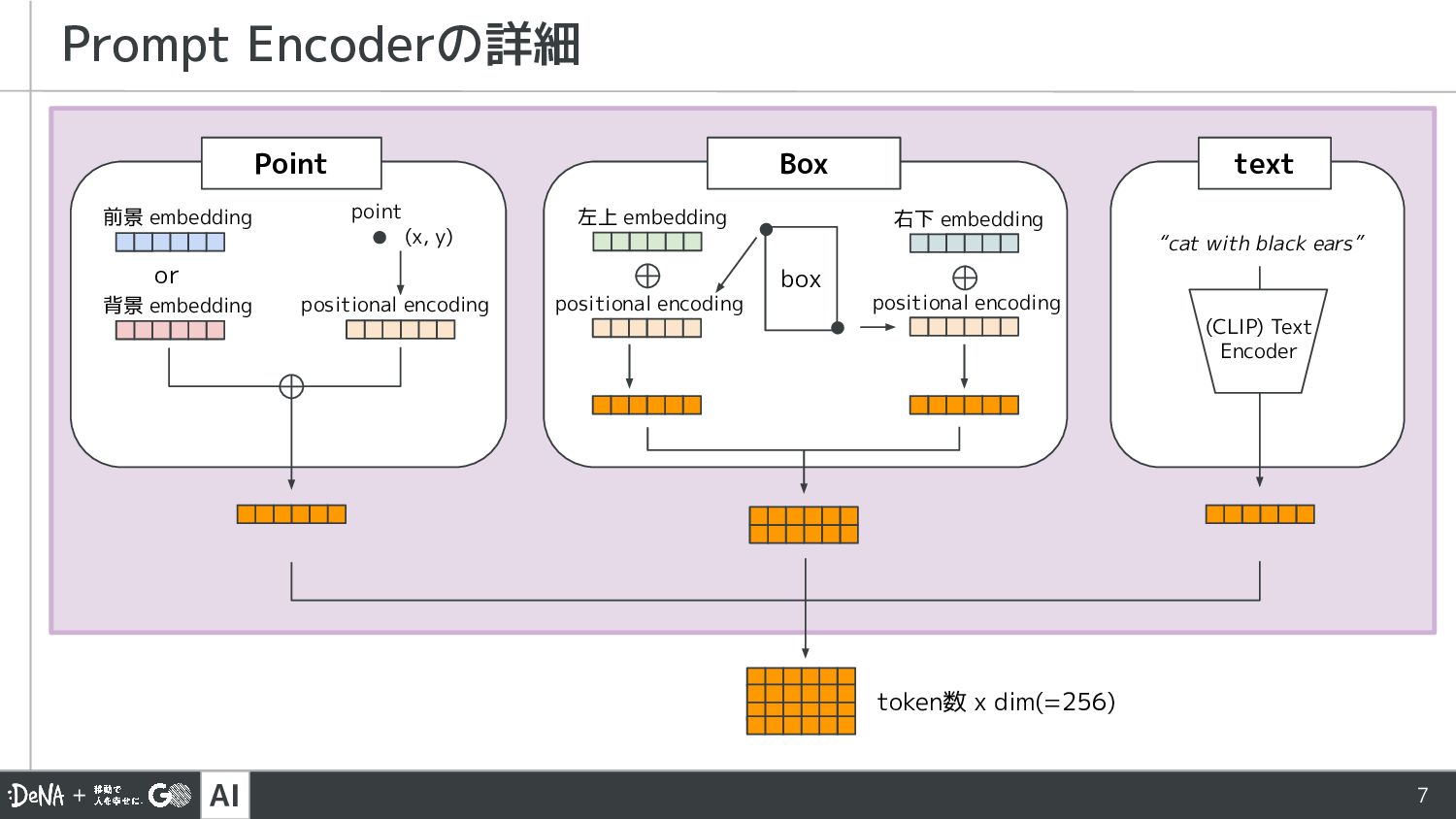{kind=link}
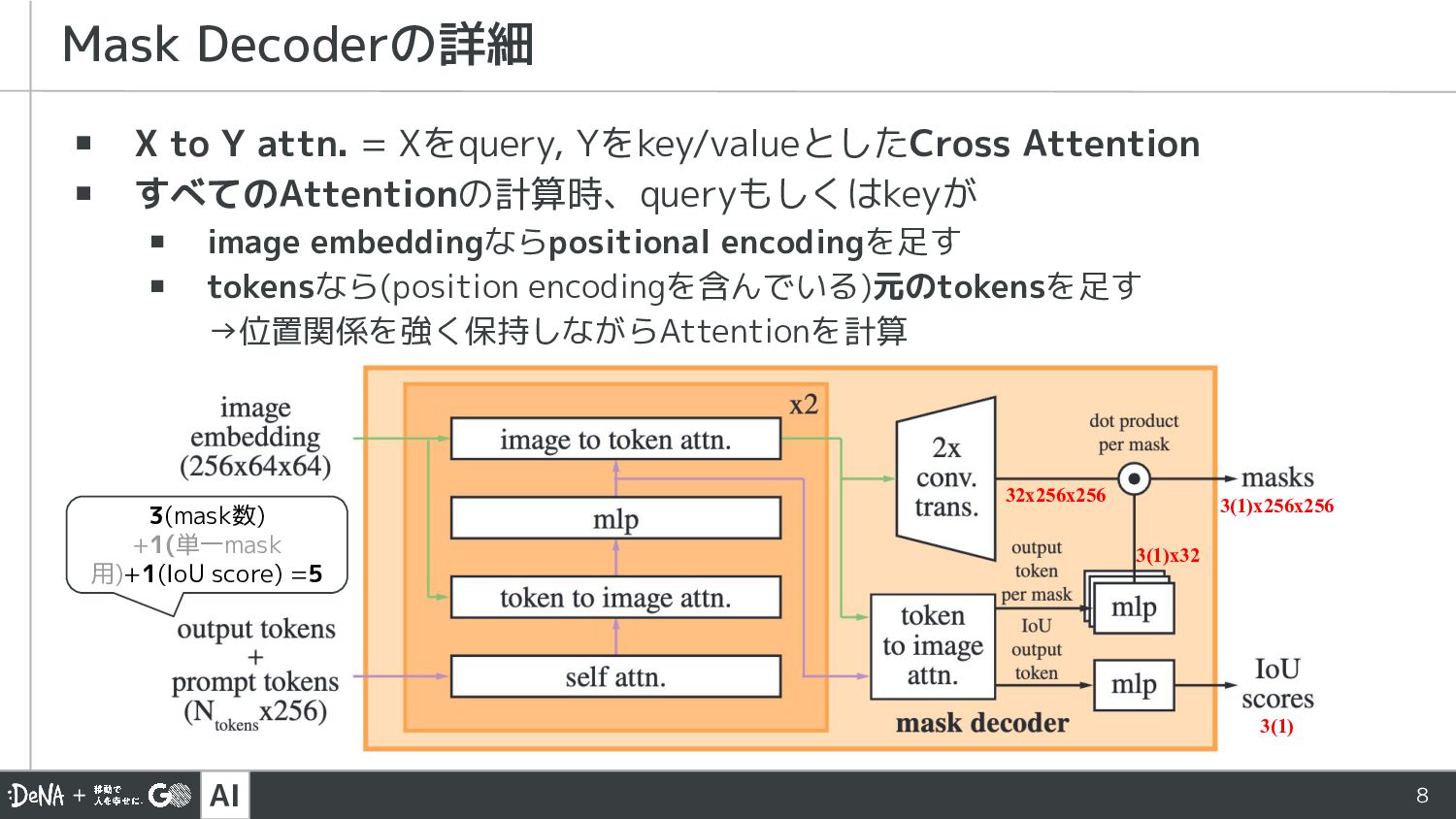{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
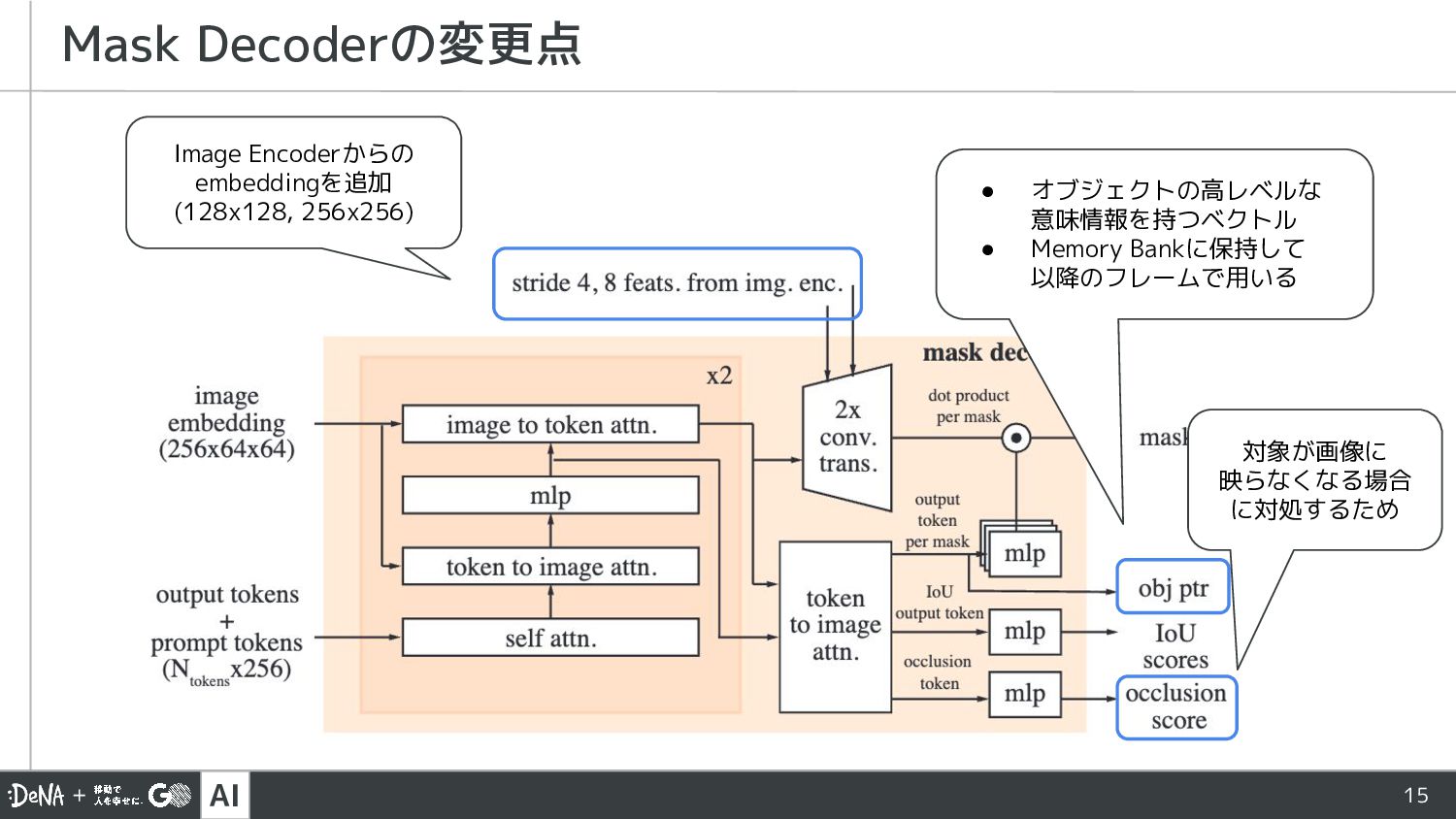
![AI 14 SAM2の概要 • Prompt encoderは SAMと同様 [1] C. Ryali,](https://files.speakerdeck.com/presentations/abb0e7ea3697458a82b604a0bd86e01e/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}