Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
メタデータ同期に潜んでいた問題 〜 Cache Stampede 時の Cycle Wait ...
Search
LINEヤフーTech (LY Corporation Tech)
PRO
March 02, 2026
Technology
280
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
メタデータ同期に潜んでいた問題 〜 Cache Stampede 時の Cycle Wait を⾒つけた話
2026年2月24日に開催された「YugabyteDB Japan Meetup #7」での発表資料です。
LINEヤフーTech (LY Corporation Tech)
PRO
March 02, 2026
More Decks by LINEヤフーTech (LY Corporation Tech)
See All by LINEヤフーTech (LY Corporation Tech)
No More Log Digging 〜AIを一次調査係にする アラートレビュー改善〜
lycorptech_jp
PRO
0
54
実践!既存 Project への AI-Driven Development 適用〜 一ヶ月で Project 唯一のフロントエンドエンジニアを作り出せ〜
lycorptech_jp
PRO
0
380
AIが実装を自走する時代の認知負債との戦い
lycorptech_jp
PRO
2
1.1k
AIと1000本ノックしてたどり着いた、最速のプロダクト開発 ~toC向けAIエージェントUXを、動く選択肢とAIキャパシティで設計する~
lycorptech_jp
PRO
1
110
プライバシー保護の理論と実践
lycorptech_jp
PRO
1
270
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
680
Business ID Integration at LY Corporation : Phased Migration for a B2B authentication platform with Tens of Millions of Users
lycorptech_jp
PRO
0
55
LINE Messaging: From Active-Standby to Active-Active Multi-DC Architecture
lycorptech_jp
PRO
0
85
LY Corporation's implementation of Confidential VM ensuring privacy for AI features
lycorptech_jp
PRO
0
97
Other Decks in Technology
See All in Technology
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
610
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
930
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
260
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
1k
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
360
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
520
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
450
そのドキュメント、自動化しませんか?
yuksew
1
410
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
310
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
380
どこまでAIに任せるか 〜確率論と決定論の境界決定〜
shukob
0
440
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
440
Featured
See All Featured
We Have a Design System, Now What?
morganepeng
55
8.2k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
620
Why Our Code Smells
bkeepers
PRO
340
58k
How GitHub (no longer) Works
holman
316
150k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
New Earth Scene 8
popppiees
3
2.4k
Transcript
© LY Corporation メタデータ同期に潜んでいた問題 ~ Cache Stampede 時の Cycle Wait
を見つけた話 YugabyteDB Japan Meetup #7 LT 24th February 2026 TAKAMI Torao
自己紹介 (About Me) 1 鷹見虎男 TAKAMI Torao LINE 開発 ::
Messaging Platform 開発 :: Platform Storage :: Storage Lab Software Engineer ◆ 専門: ソフトウェア設計・開発 ◆ 経歴: 元金融系SI開発, JavaPress 特集, Web系開発, 分散処理基盤, ブロックチェーン開発 ◆ 興味: (構造的|確率的|分散|暗号) アルゴリズム, 認知行動科学 ◆ 趣味: 旅行, ドライブ, 映画, 文房具, コーヒー, Rust, Scala
ALTER TABLE … GRANT ALL PRIVILEGES ON … メタ情報更新 (DDL/DCL)
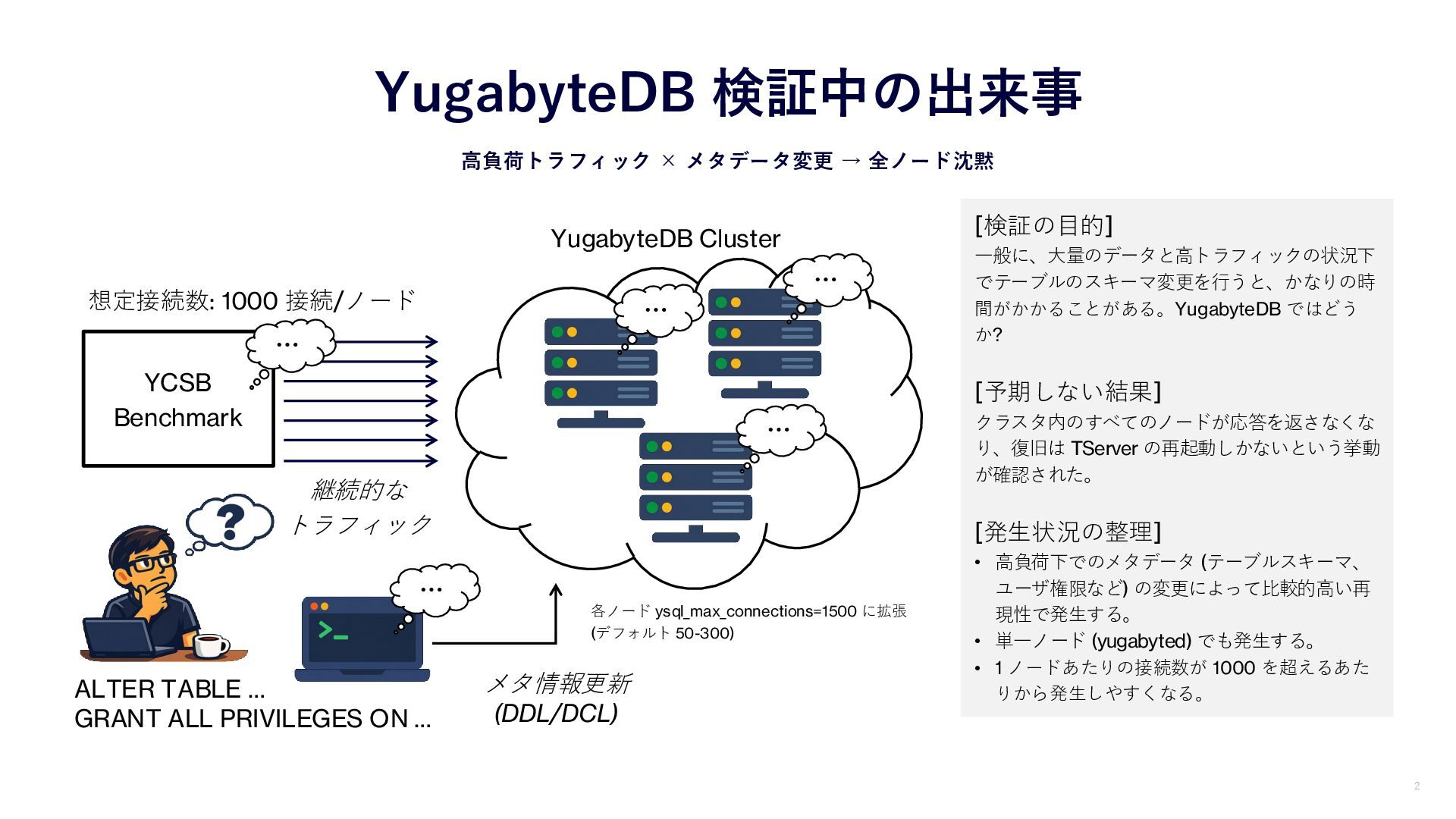
YugabyteDB 検証中の出来事 高負荷トラフィック × メタデータ変更 → 全ノード沈黙 YCSB Benchmark 2 各ノード ysql_max_connections=1500 に拡張 (デフォルト 50-300) 想定接続数: 1000 接続/ノード [検証の目的] 一般に、大量のデータと高トラフィックの状況下 でテーブルのスキーマ変更を行うと、かなりの時 間がかかることがある。YugabyteDB ではどう か? [予期しない結果] クラスタ内のすべてのノードが応答を返さなくな り、復旧は TServer の再起動しかないという挙動 が確認された。 [発生状況の整理] • 高負荷下でのメタデータ (テーブルスキーマ、 ユーザ権限など) の変更によって比較的高い再 現性で発生する。 • 単一ノード (yugabyted) でも発生する。 • 1 ノードあたりの接続数が 1000 を超えるあた りから発生しやすくなる。 継続的な トラフィック YugabyteDB Cluster … … … … …
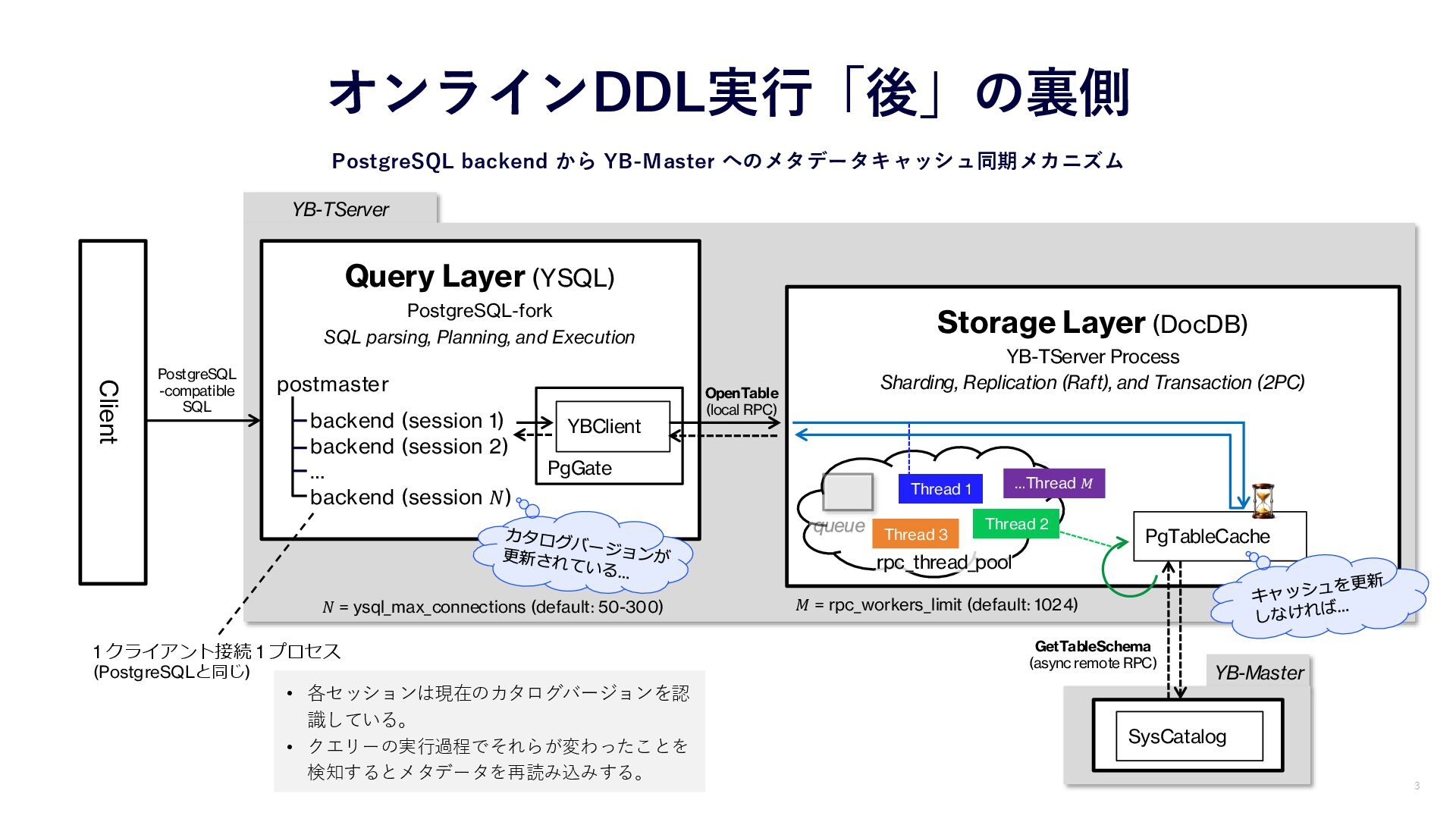
YB-Master YB-TServer オンラインDDL実行「後」の裏側 PostgreSQL backend から YB-Master へのメタデータキャッシュ同期メカニズム Client Query
Layer (YSQL) PostgreSQL-fork SQL parsing, Planning, and Execution postmaster backend (session 1) backend (session 2) … backend (session 𝑁) 1 クライアント接続 1 プロセス (PostgreSQLと同じ) 𝑁 = ysql_max_connections (default: 50-300) PgGate YBClient 𝑀 = rpc_workers_limit (default: 1024) SysCatalog PostgreSQL -compatible SQL 3 Storage Layer (DocDB) YB-TServer Process Sharding, Replication (Raft), and Transaction (2PC) PgTableCache rpc_thread_pool Thread 2 Thread 1 Thread 3 …Thread 𝑀 OpenTable (local RPC) GetTableSchema (async remote RPC) • 各セッションは現在のカタログバージョンを認 識している。 • クエリーの実行過程でそれらが変わったことを 検知するとメタデータを再読み込みする。
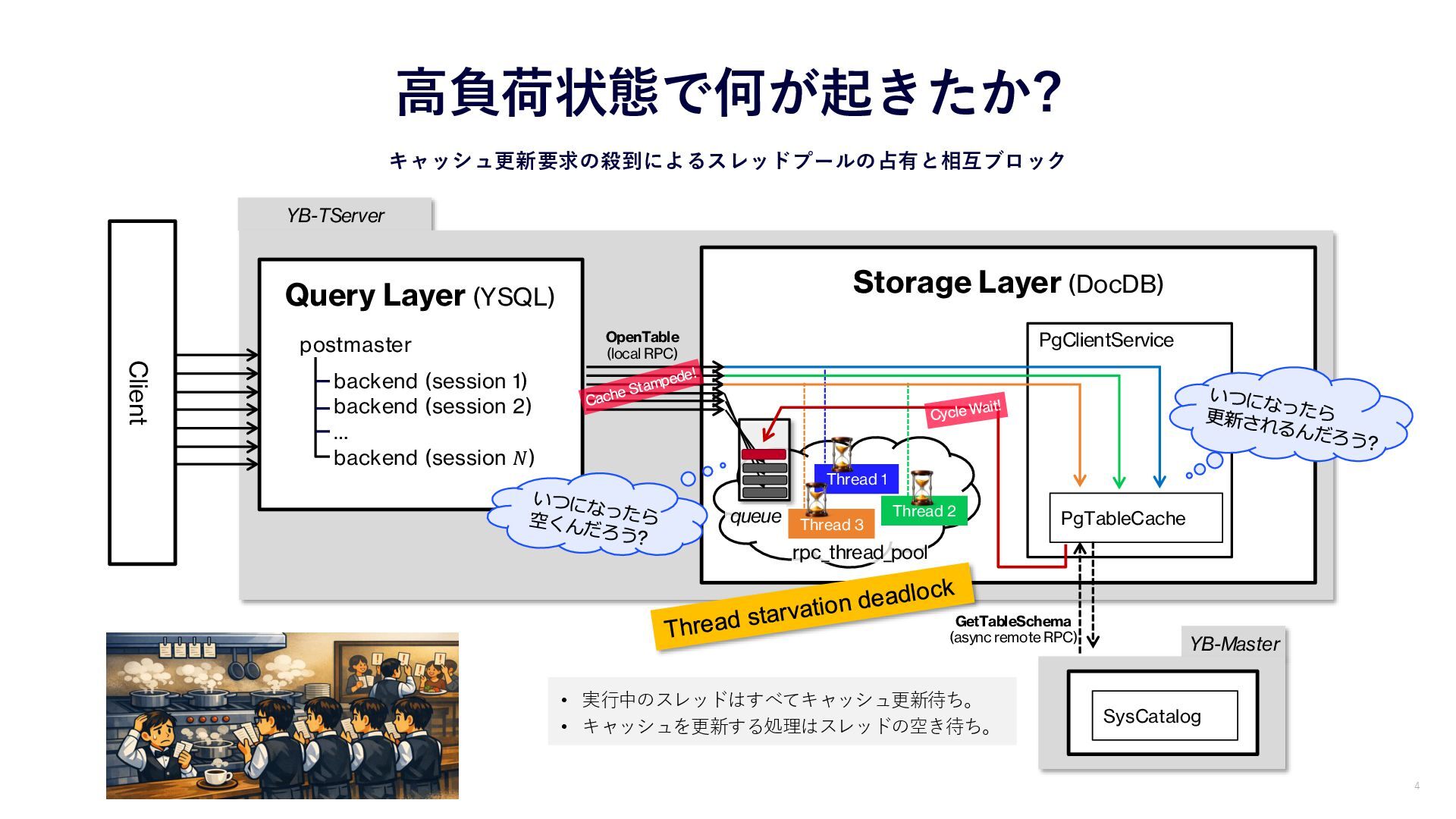
YB-Master YB-TServer Client Query Layer (YSQL) postmaster backend (session 1)
backend (session 2) … backend (session 𝑁) 高負荷状態で何が起きたか? キャッシュ更新要求の殺到によるスレッドプールの占有と相互ブロック Storage Layer (DocDB) PgClientService PgTableCache rpc_thread_pool SysCatalog GetTableSchema (async remote RPC) 4 Thread 2 Thread 1 Thread 3 OpenTable (local RPC) queue • 実行中のスレッドはすべてキャッシュ更新待ち。 • キャッシュを更新する処理はスレッドの空き待ち。
5 1024個中、1023個のス レッドが同じ場所で止 まっている。 TServer の Web UI 最先発のスレッド?
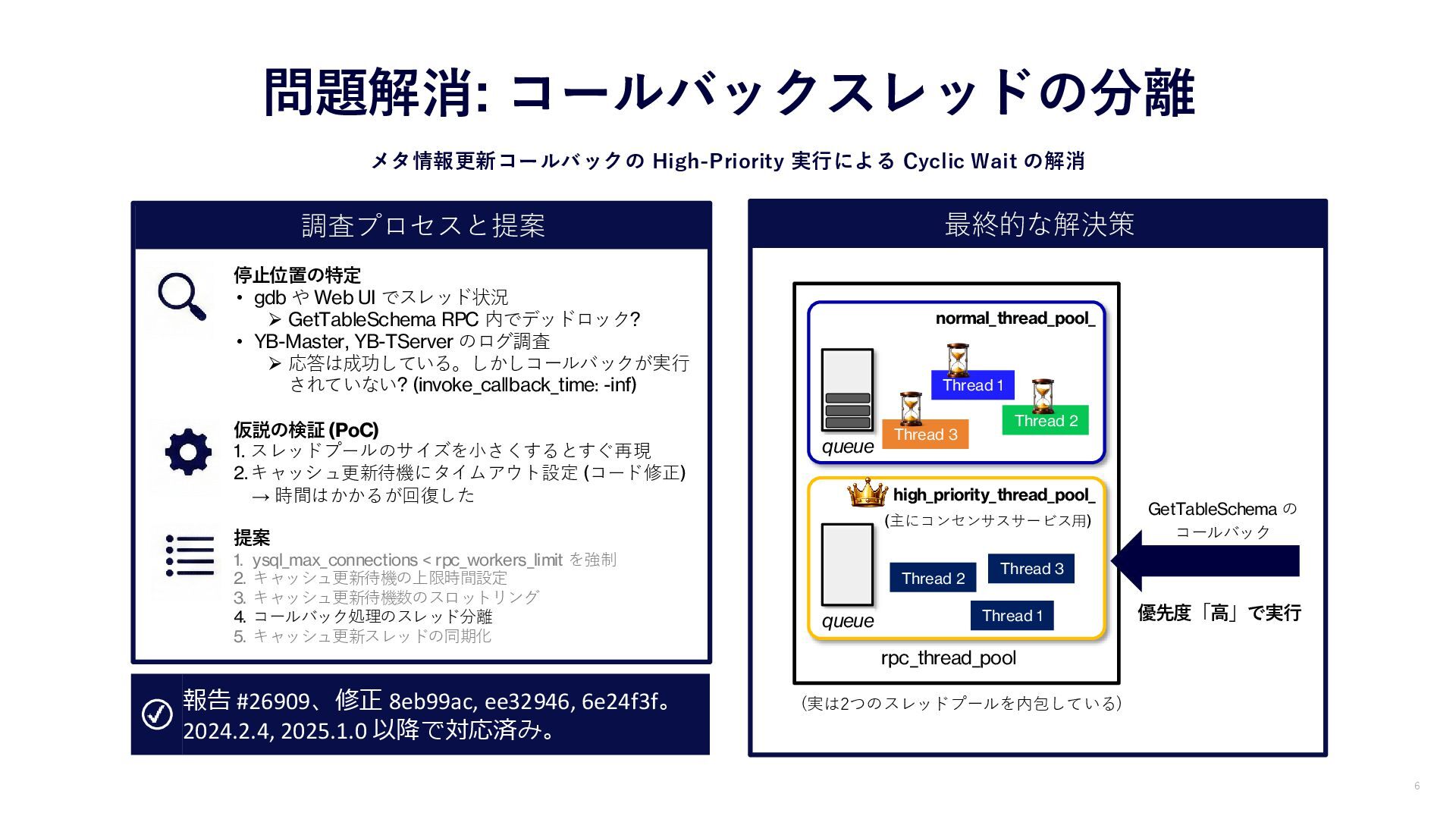
調査プロセスと提案 最終的な解決策 normal_thread_pool_ 問題解消: コールバックスレッドの分離 メタ情報更新コールバックの High-Priority 実行による Cyclic Wait
の解消 6 rpc_thread_pool Thread 2 Thread 1 Thread 3 queue high_priority_thread_pool_ Thread 2 Thread 1 Thread 3 queue (主にコンセンサスサービス用) 停止位置の特定 • gdb や Web UI でスレッド状況 ➢ GetTableSchema RPC 内でデッドロック? • YB-Master, YB-TServer のログ調査 ➢ 応答は成功している。しかしコールバックが実行 されていない? (invoke_callback_time: -inf) 仮説の検証 (PoC) 1. スレッドプールのサイズを小さくするとすぐ再現 2.キャッシュ更新待機にタイムアウト設定 (コード修正) → 時間はかかるが回復した 提案 1. ysql_max_connections < rpc_workers_limit を強制 2. キャッシュ更新待機の上限時間設定 3. キャッシュ更新待機数のスロットリング 4. コールバック処理のスレッド分離 5. キャッシュ更新スレッドの同期化 報告 #26909、修正 8eb99ac, ee32946, 6e24f3f。 2024.2.4, 2025.1.0 以降で対応済み。 GetTableSchema の コールバック 優先度「高」で実行 (実は2つのスレッドプールを内包している)
7 状況分析と仮説検証 複雑な事象もログとアーキテ クチャの分析から仮説を立て、 PoCで検証を実施。結果とし て主因の特定と具体的な改善 案を伴う、実効性の高い問題 報告に繋がりました。 迅速かつ抜本的な対応 即座に
priority:high でトリ アージされました。表面的な 対処ではなく、アーキテク チャレベルの抜本的な改修が 速やかに行われた Yugabyte チームの対応に感謝します。 難題に挑む仲間を募集 内部アーキテクチャに踏み込 んだ課題解決を通じ、大規模 分散ストレージ基盤の構築を 進めています。分散システム の深い理解と実践に興味のあ る方を歓迎します。 一ノ矢は避けられない。しかし二ノ矢は打ち落とさなければならない。 ~ サンユッタ・ニカーヤ「矢の経」~ LY00093 www.lycorp.co.jp/ja/recruit/career/job-categories/ly00093/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}