Share
1. atmaCup#2上位解法 2. XGBoost概要 3. XGBoostの気持ちから見た上位解法
コンペ自体の概要は下記URLをご覧ください https://atma.hatenablog.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
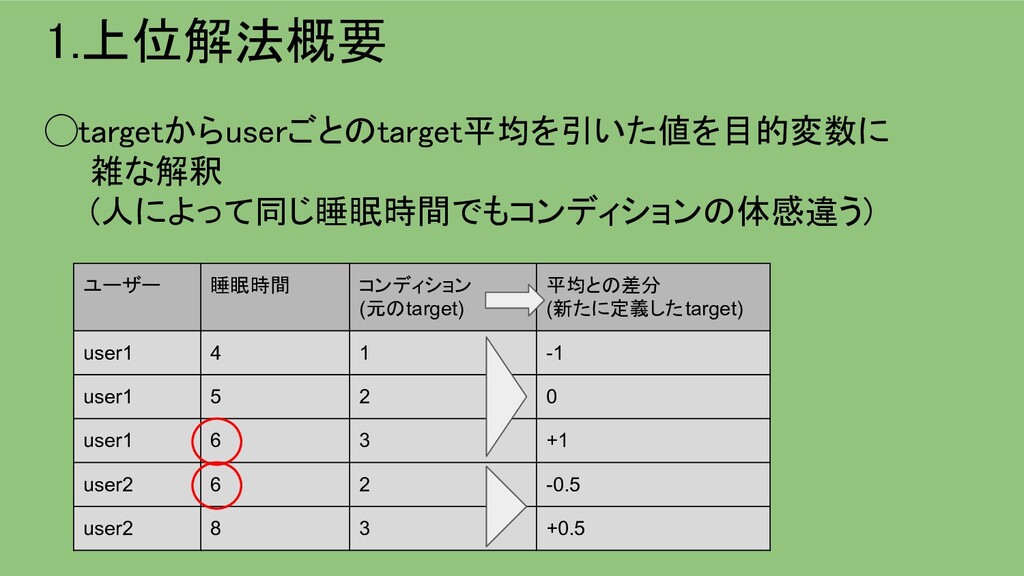{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
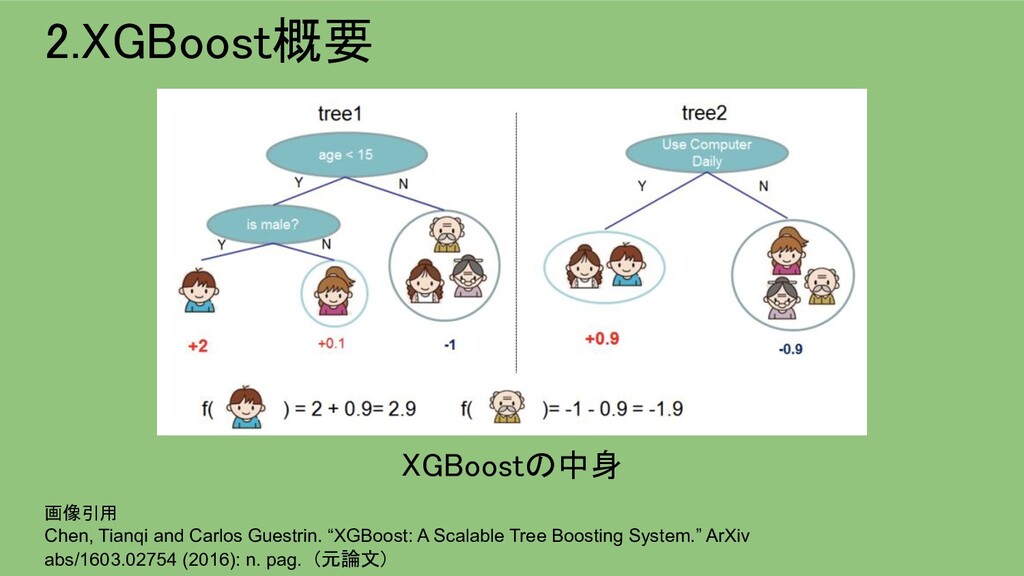{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
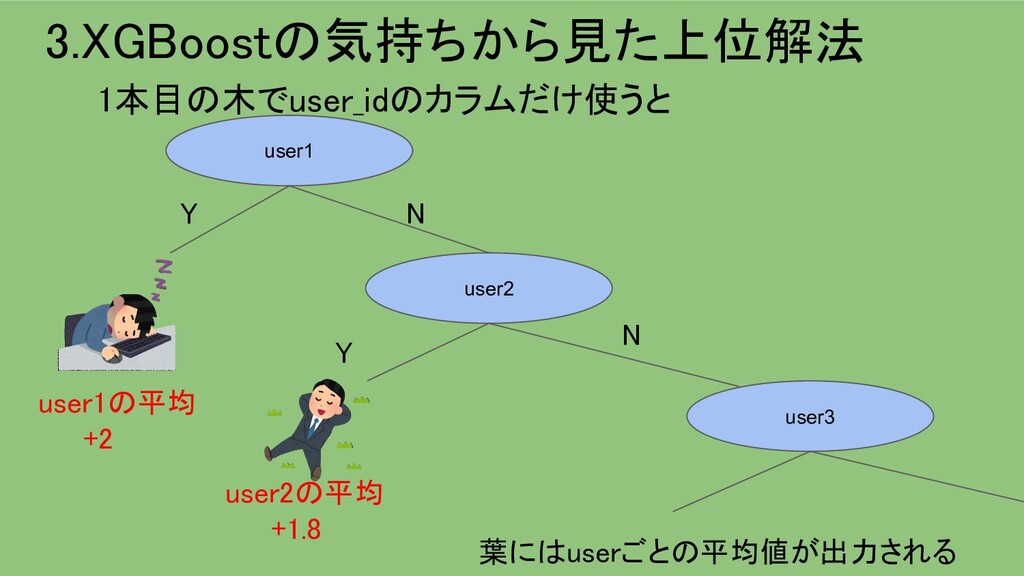{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}