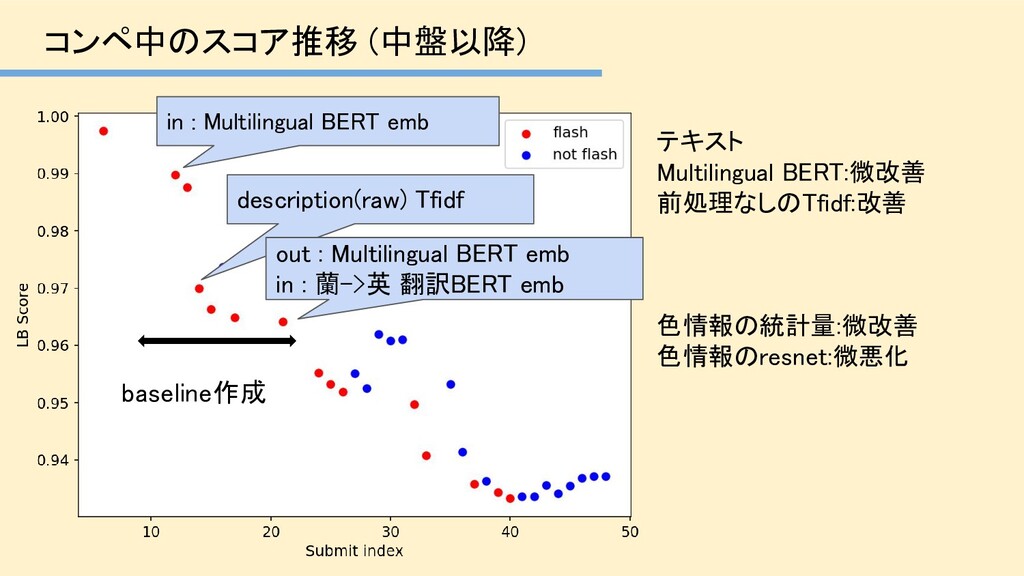
'The Avenue of Birches, Jan Hackaert, 1660 - 1685’ ->[英] ’The Avenue of Birches, Jan Hackaert, 1660 - 1685’ [蘭] 'Struik in bloei, Richard Tepe (attributed to), c. 1900 - c. 1930' -> [英] ’Strike in bloom, Richard Tepe (attributed to), c. 1900 - c. 1930’ 英語を入力しても英語をそのまま返してくれるので雑に使える 効いたText特徴量:翻訳
dataset 例) ・EN->FR->EN ・EN->DE->EN [英] 'The Avenue of Birches, Jan Hackaert, 1660 - 1685’ ->[仏] ’L'Avenue des Bouleaux, Jan Hackaert, 1660-1685 ’ ->[英] ‘Avenue des Bouleaux, Jan Hackaert, 1660-1685’ (ここではGoogle翻訳を使用) 効いたText特徴量:翻訳 (余談)
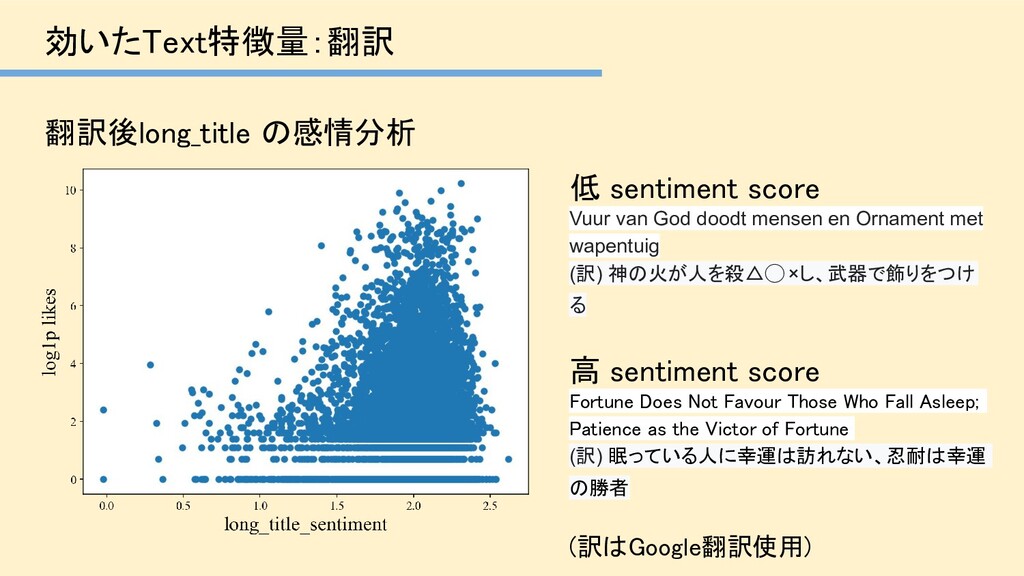
mensen en Ornament met wapentuig (訳) 神の火が人を殺△◯ ×し、武器で飾りをつけ る 高 sentiment score Fortune Does Not Favour Those Who Fall Asleep; Patience as the Victor of Fortune (訳) 眠っている人に幸運は訪れない、忍耐は幸運 の勝者 (訳はGoogle翻訳使用)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![効いた特徴量 特徴量重要度Top ([Public 2nd/Private 2nd] LGBM single model solution)](https://files.speakerdeck.com/presentations/57ae503b355b409bbfd1df4fc2ea7ccc/slide_23.jpg){kind=link}
{kind=link}
![複数言語を含んだTextカラムに対して事前学習済みBERTモデルから 文章の分散表現を得たい (<CLS> tokenのベクトル) [英] 'The Avenue of Birches, Jan](https://files.speakerdeck.com/presentations/57ae503b355b409bbfd1df4fc2ea7ccc/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
![テキストの翻訳(蘭->英) Helsinki-NLP/opus-mt-nl-en · Hugging Face 例) long_titleの翻訳 [英]](https://files.speakerdeck.com/presentations/57ae503b355b409bbfd1df4fc2ea7ccc/slide_28.jpg){kind=link}
![テキストの翻訳はDataAugumentation目的で用いられることが多い [Toxic Comment Classification Challenge] A simple technique for extending](https://files.speakerdeck.com/presentations/57ae503b355b409bbfd1df4fc2ea7ccc/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}