Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Bayesian Causal Inference with PyMC
Search
Tetsuro Shimada
November 02, 2023
Technology
3.8k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Bayesian Causal Inference with PyMC
Tetsuro Shimada
November 02, 2023
More Decks by Tetsuro Shimada
See All by Tetsuro Shimada
ビジネスデータ分析
tetchi
0
250
Evidence Based Policy Making (EBPM)
tetchi
0
110
グラフカルモデルによる統計的因果推論入門
tetchi
3
6.3k
予約データから未来の客数を予測する:第22回 Machine Learning 15minutes! / Predict number of customers in restaurants
tetchi
1
480
Other Decks in Technology
See All in Technology
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
170
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
140
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
1
270
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
2
530
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.3k
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
280
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
25
11k
OPENLOGI Company Profile for engineer
hr01
1
74k
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
610
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
510
Multicaで30個のミニプロジェクトをAIエージェント運用して見えてきたこと
eiei114
1
620
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Featured
See All Featured
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
500
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
3
360
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
57k
A Tale of Four Properties
chriscoyier
163
24k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Faster Mobile Websites
deanohume
310
32k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
How to Ace a Technical Interview
jacobian
281
24k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Transcript
AI 2023.11.02 島田 哲朗 GO株式会社 Bayesian Causal Inference with PyMC
AI 2 項目 01|機械学習と因果推論のタスクの違い 02|因果効果とは? 03|Bayesian Causal Inference 04|介入のシミュレーション
AI 3 ▪ 参考資料 https://www.kyoritsu- pub.co.jp/book/b10003865.html https://www.asakura.co.jp/d etail.php?book_code=12781 https://youtu.be/b47wmTdcICE?si=oOTUPNYp7eKLy1nq
AI 4 01 機械学習と因果推論のタスクの違い
AI 5 ▪ 自動車のボディに塗装する際に、塗着率を高める工程条件 を把握したい ▪ 希釈率を変化させたときに、塗着率はどうなるか? ビジネス課題 変数 説明
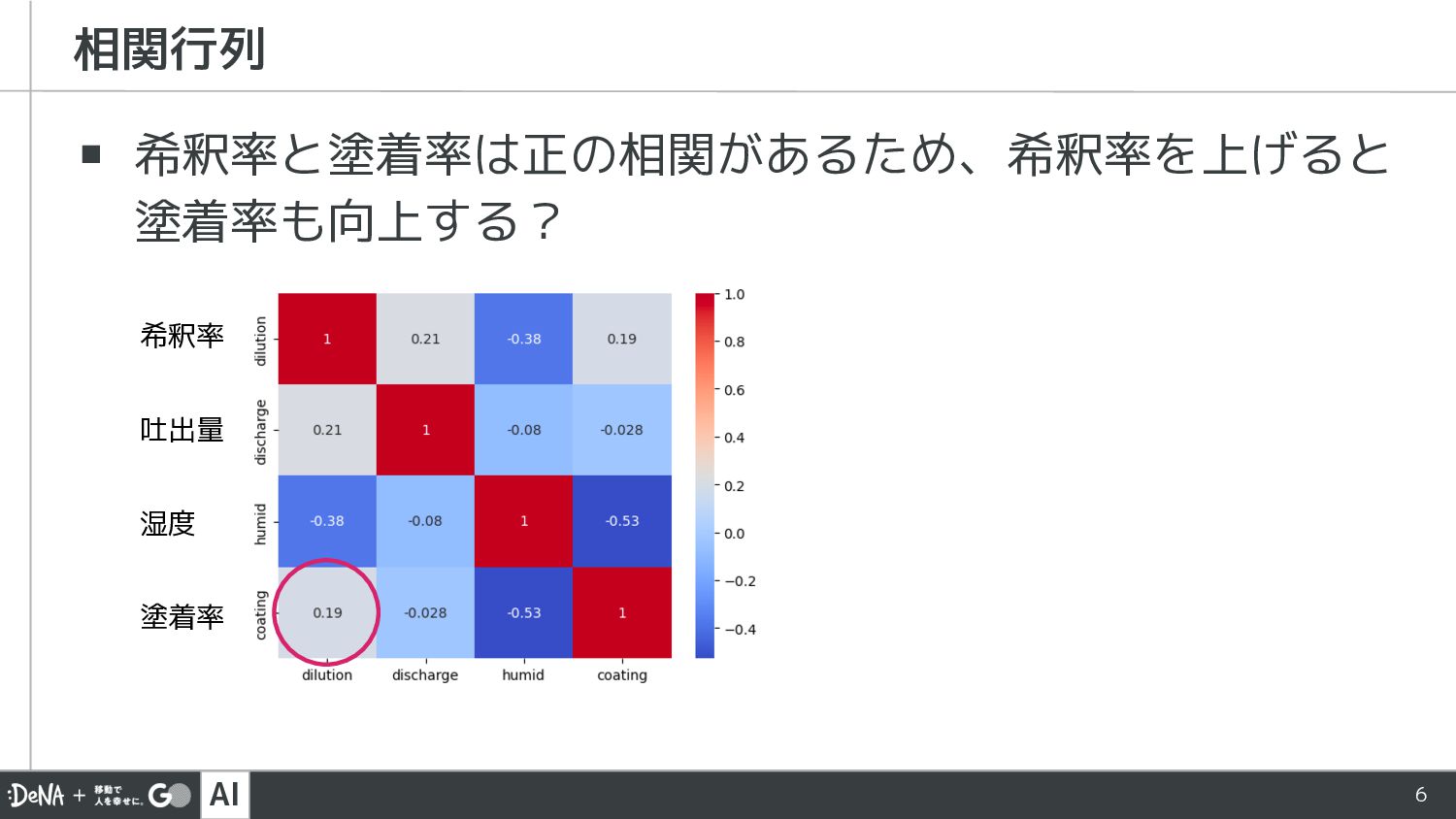
希釈率 塗料をどの程度希釈するか 吐出量 スプレーガンからどの程度塗料が出るか 湿度 空気中の湿度 塗着率 塗料が皮膜としてどの程度定着するか
AI 6 ▪ 希釈率と塗着率は正の相関があるため、希釈率を上げると 塗着率も向上する? 相関行列 希釈率 吐出量 湿度 塗着率
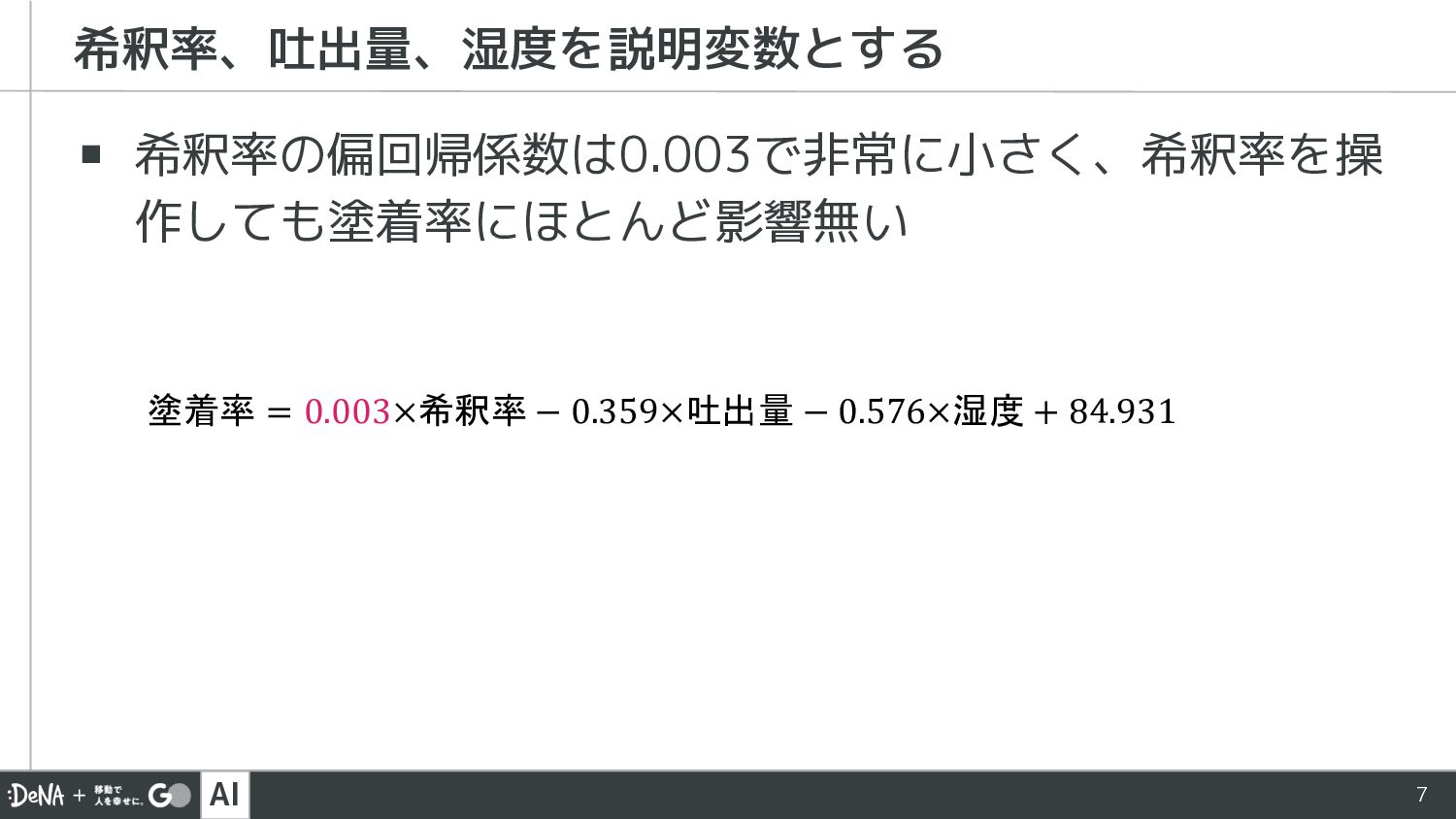
AI 7 ▪ 希釈率の偏回帰係数は0.003で非常に小さく、希釈率を操 作しても塗着率にほとんど影響無い 希釈率、吐出量、湿度を説明変数とする 塗着率 = 0.003×希釈率 −
0.359×吐出量 − 0.576×湿度 + 84.931
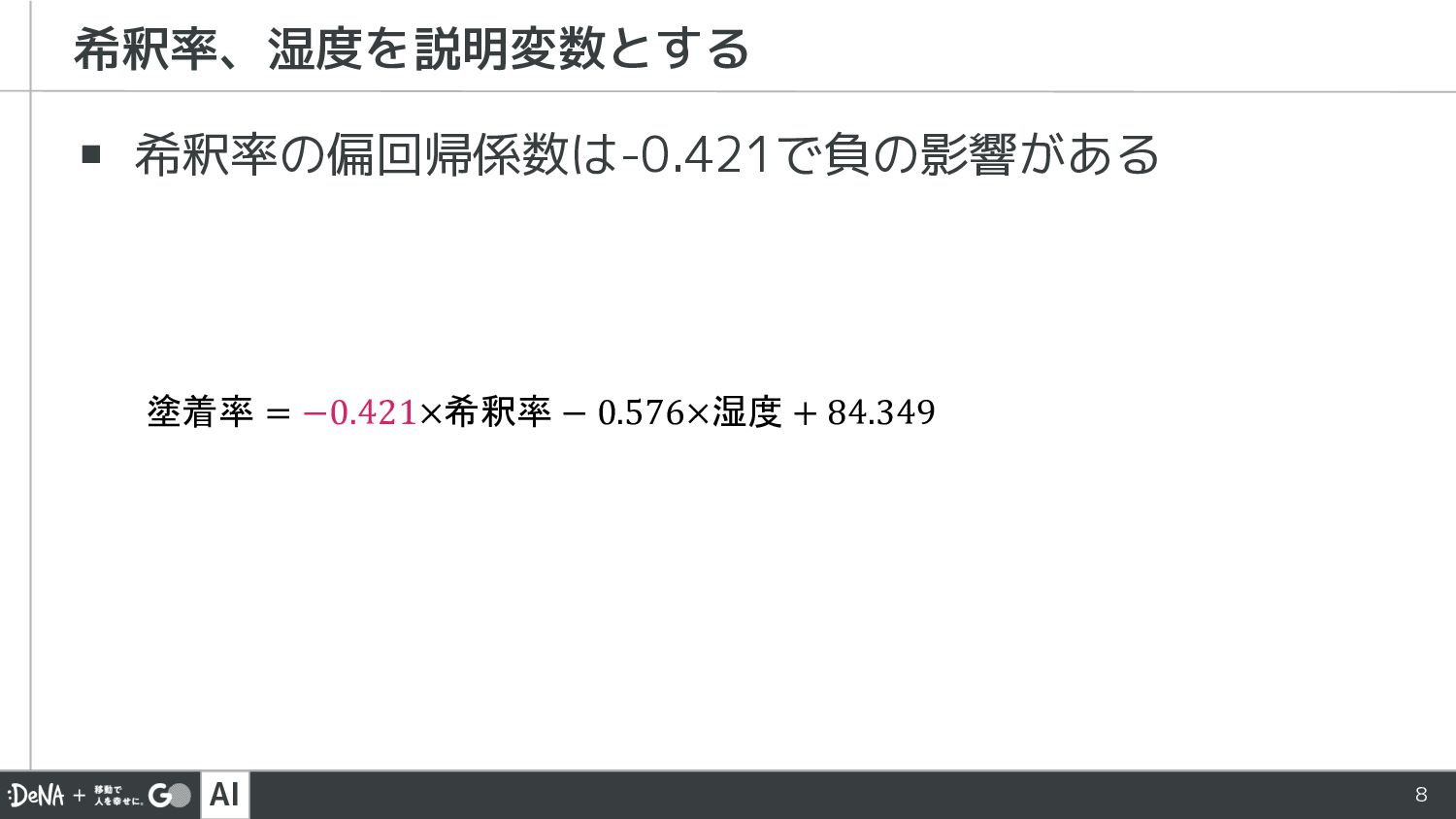
AI 8 ▪ 希釈率の偏回帰係数は-0.421で負の影響がある 希釈率、湿度を説明変数とする 塗着率 = −0.421×希釈率 − 0.576×湿度
+ 84.349
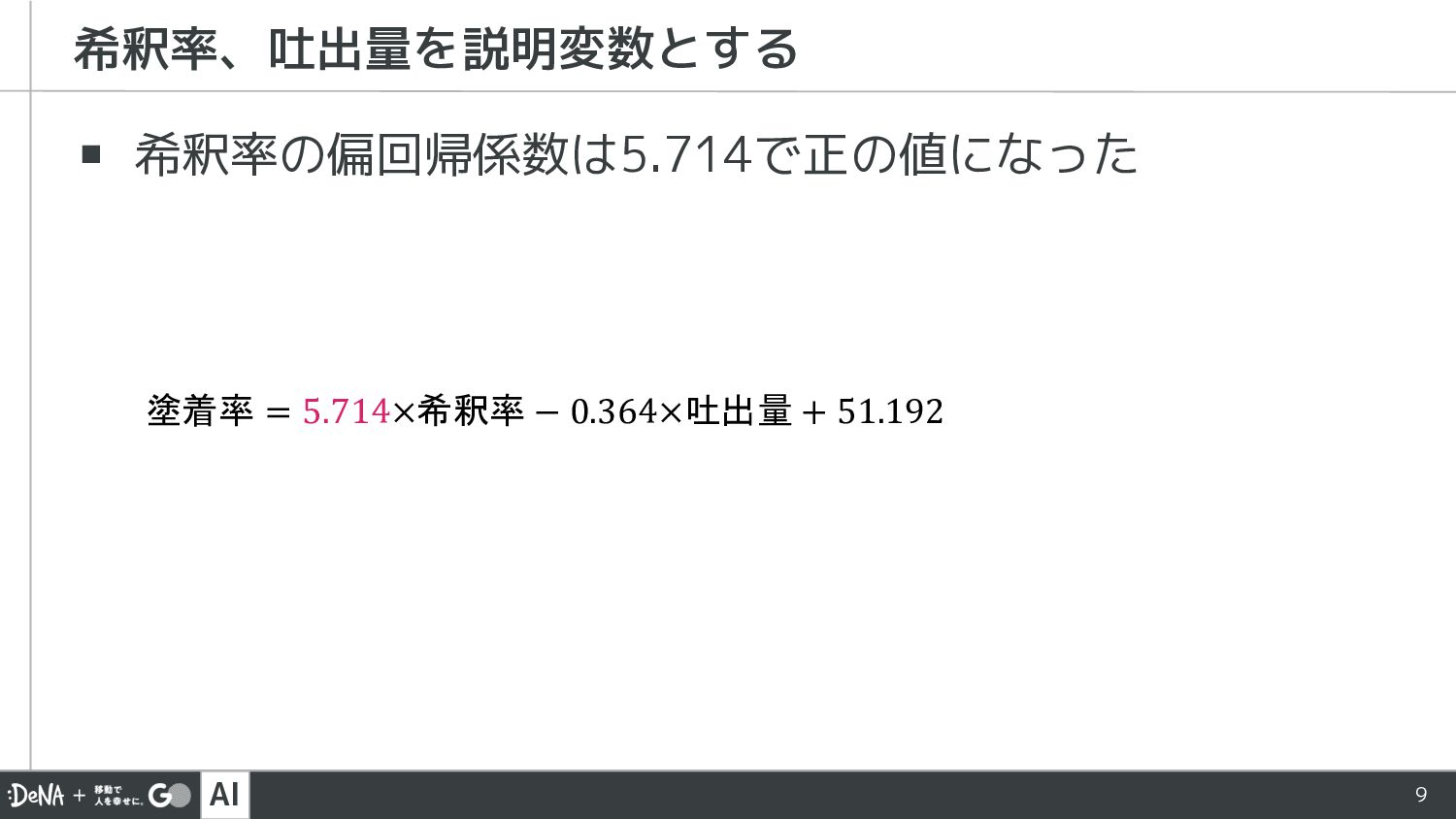
AI 9 ▪ 希釈率の偏回帰係数は5.714で正の値になった 希釈率、吐出量を説明変数とする 塗着率 = 5.714×希釈率 − 0.364×吐出量
+ 51.192
AI 10 ▪ 塗着率の真値と予測値の差分が小さいモデルを採用する? どのモデルを選択すれば良いのだろうか? 塗着率 = 0.003×希釈率 − 0.359×吐出量
− 0.576×湿度 + 84.931 塗着率 = −0.421×希釈率 − 0.576×湿度 + 84.349 塗着率 = 5.714×希釈率 − 0.364×吐出量 + 51.192
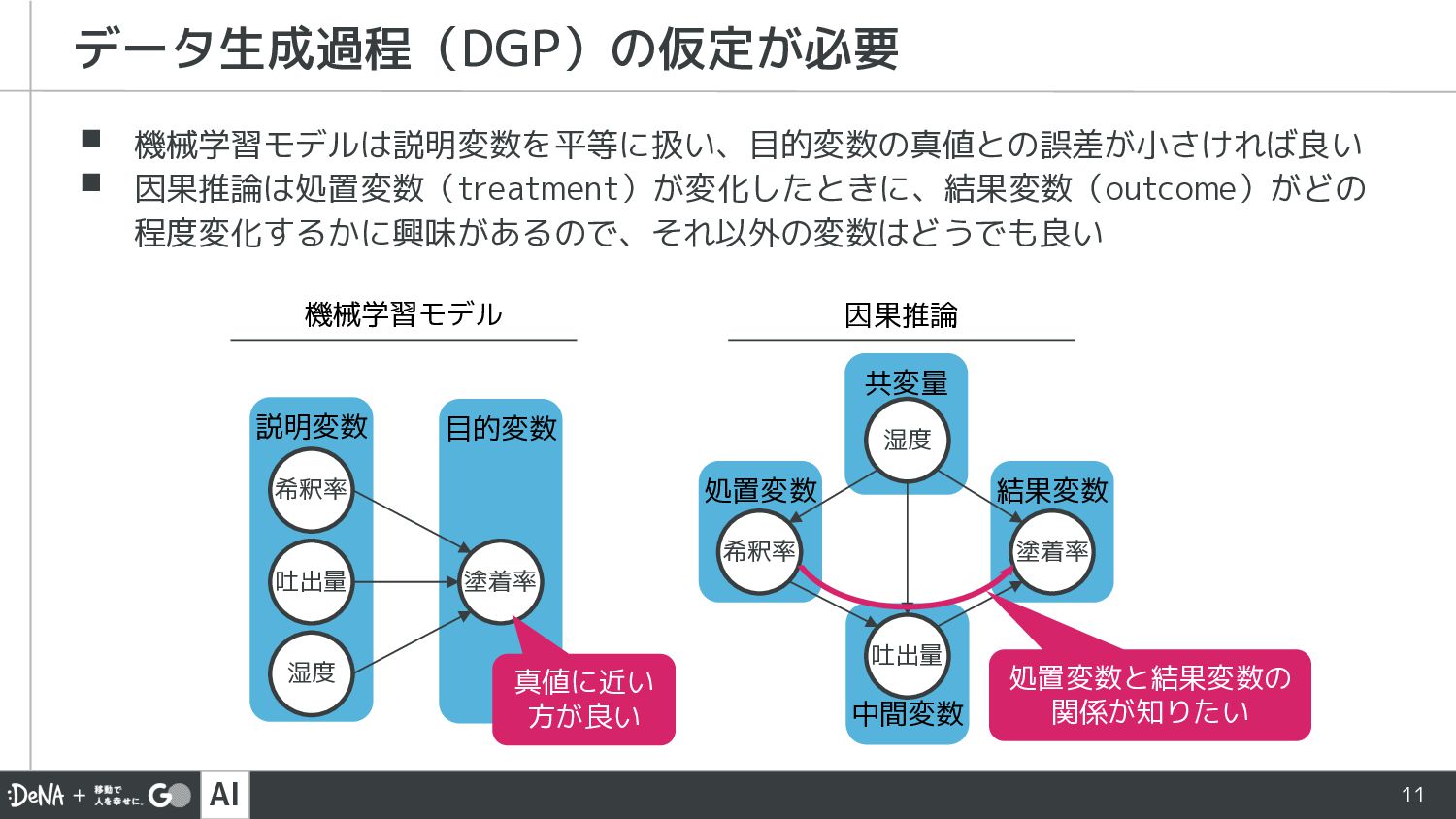
AI 中間変数 結果変数 処置変数 共変量 目的変数 11 ▪ 機械学習モデルは説明変数を平等に扱い、目的変数の真値との誤差が小さければ良い ▪
因果推論は処置変数(treatment)が変化したときに、結果変数(outcome)がどの 程度変化するかに興味があるので、それ以外の変数はどうでも良い データ生成過程(DGP)の仮定が必要 機械学習モデル 因果推論 説明変数 塗着率 希釈率 吐出量 湿度 塗着率 希釈率 吐出量 湿度 真値に近い 方が良い 処置変数と結果変数の 関係が知りたい
AI 12 ▪ 「湿度」は入れて、「吐出量」は入れてはいけない ▪ 処置変数に入ってくるpathを全てブロックする必要 ▪ 希釈率を上げるとおそらく粘度が下がるので、塗着率が下がる データ生成過程(DGP)の仮説が必要 塗着率
希釈率 吐出量 湿度 参考:グラフカルモデルによる統計的因果推論入門 - Speaker Deck 塗着率 = −0.421×希釈率 − 0.576×湿度 + 84.349
AI 13 02 因果効果とは?
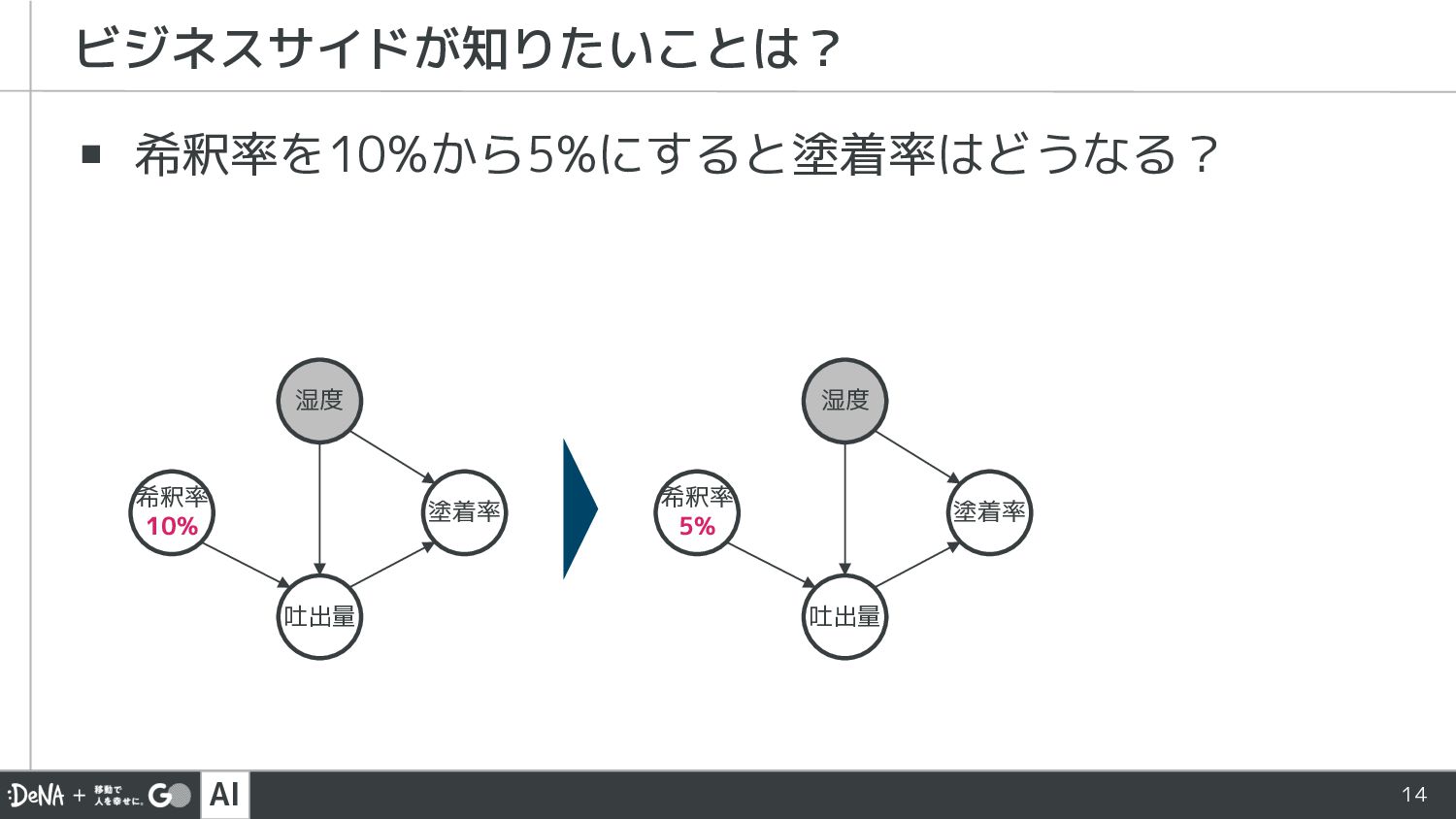
AI 14 ▪ 希釈率を10%から5%にすると塗着率はどうなる? ビジネスサイドが知りたいことは? 塗着率 希釈率 10% 吐出量 湿度
塗着率 希釈率 5% 吐出量 湿度
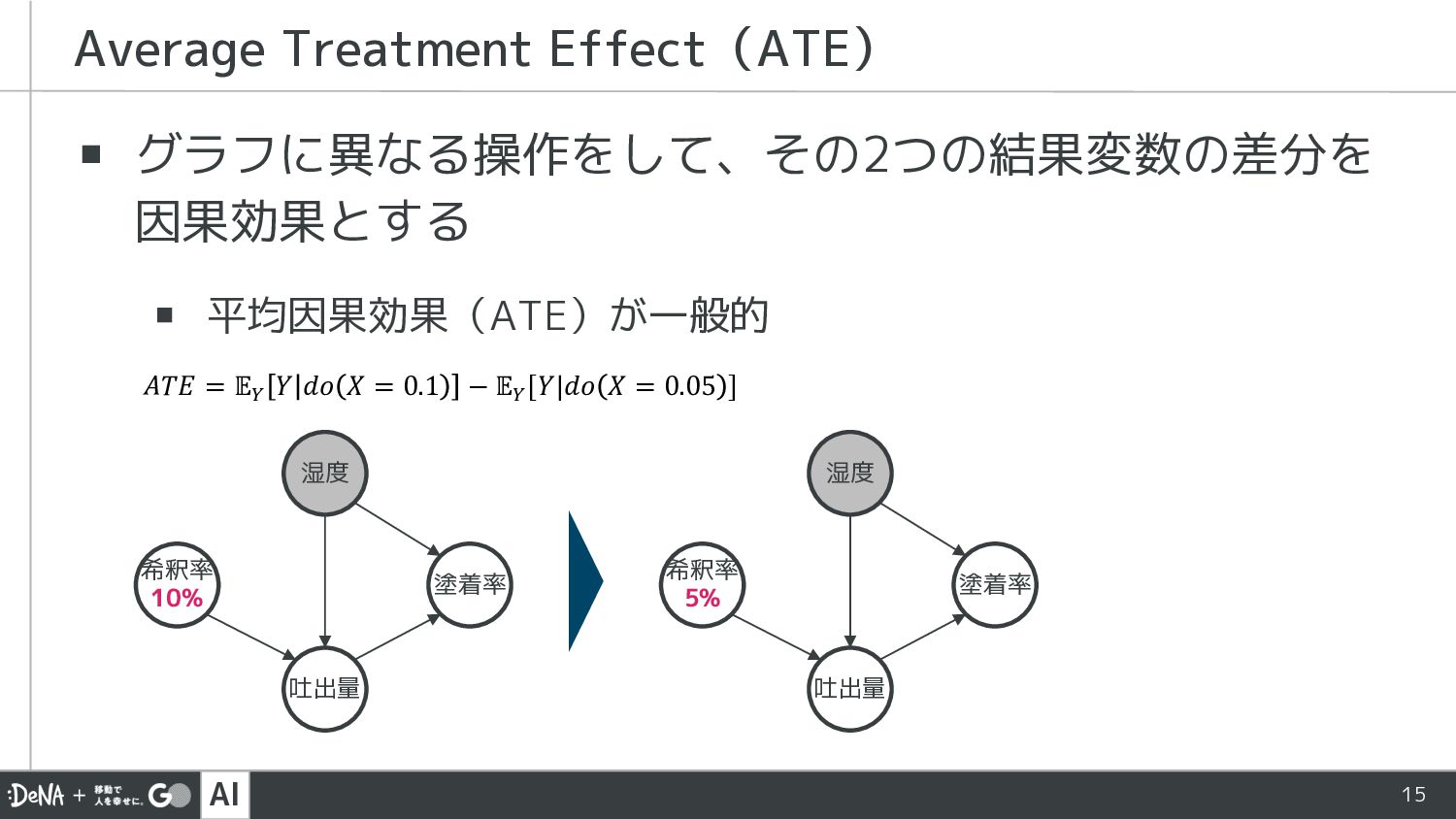
AI 15 ▪ グラフに異なる操作をして、その2つの結果変数の差分を 因果効果とする ▪ 平均因果効果(ATE)が一般的 Average Treatment Effect(ATE)
𝐴𝑇𝐸 = 𝔼! 𝑌 𝑑𝑜 𝑋 = 0.1 − 𝔼! [𝑌|𝑑𝑜 𝑋 = 0.05 ] 塗着率 希釈率 10% 吐出量 湿度 塗着率 希釈率 5% 吐出量 湿度
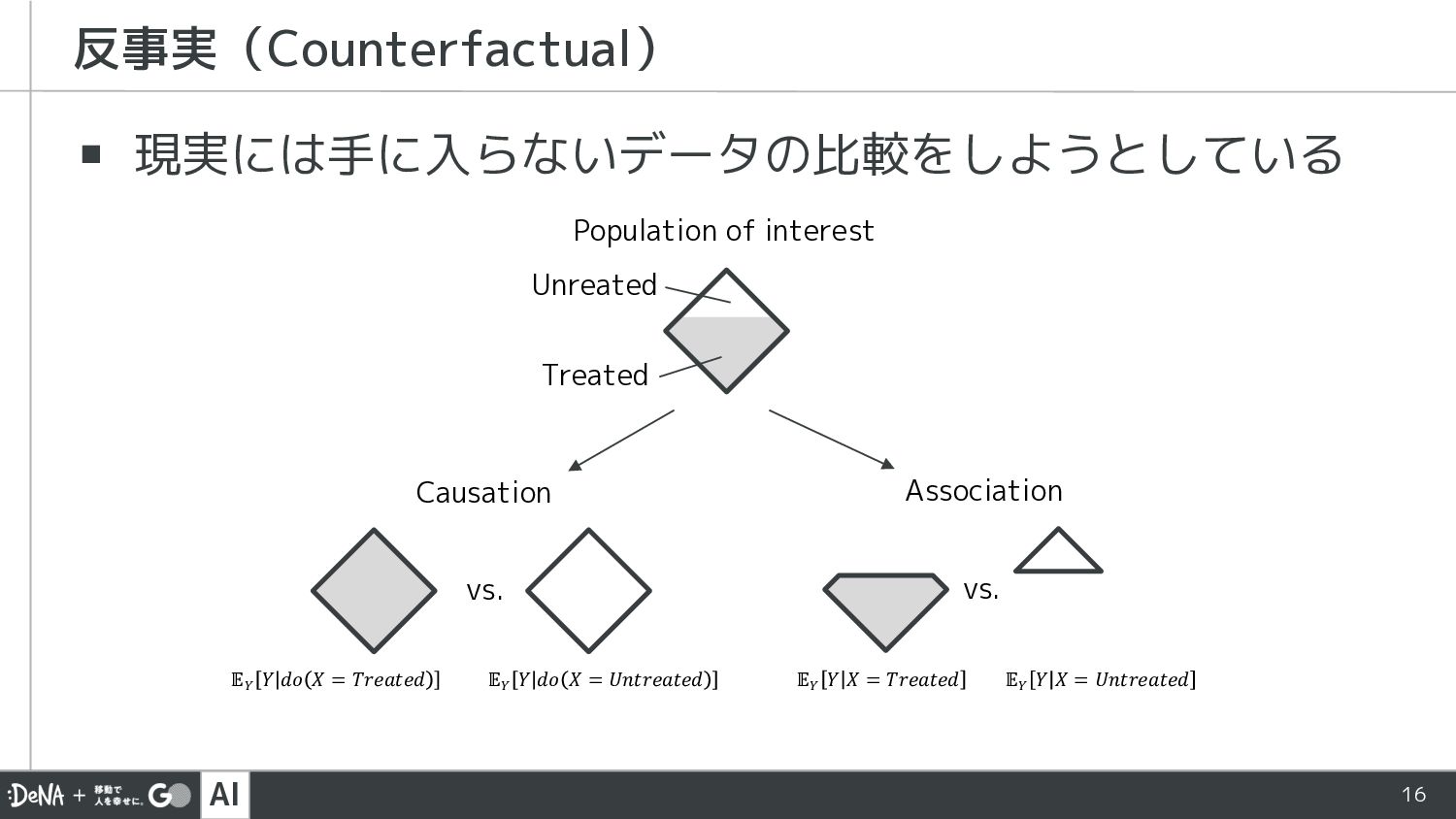
AI 16 ▪ 現実には手に入らないデータの比較をしようとしている 反事実(Counterfactual) Population of interest Treated Unreated
𝔼! 𝑌 𝑑𝑜 𝑋 = 𝑇𝑟𝑒𝑎𝑡𝑒𝑑 vs. 𝔼! 𝑌 𝑑𝑜 𝑋 = 𝑈𝑛𝑡𝑟𝑒𝑎𝑡𝑒𝑑 Causation vs. Association 𝔼! 𝑌 𝑋 = 𝑇𝑟𝑒𝑎𝑡𝑒𝑑 𝔼! 𝑌 𝑋 = 𝑈𝑛𝑡𝑟𝑒𝑎𝑡𝑒𝑑
AI 17 03 Bayesian Causal Inference
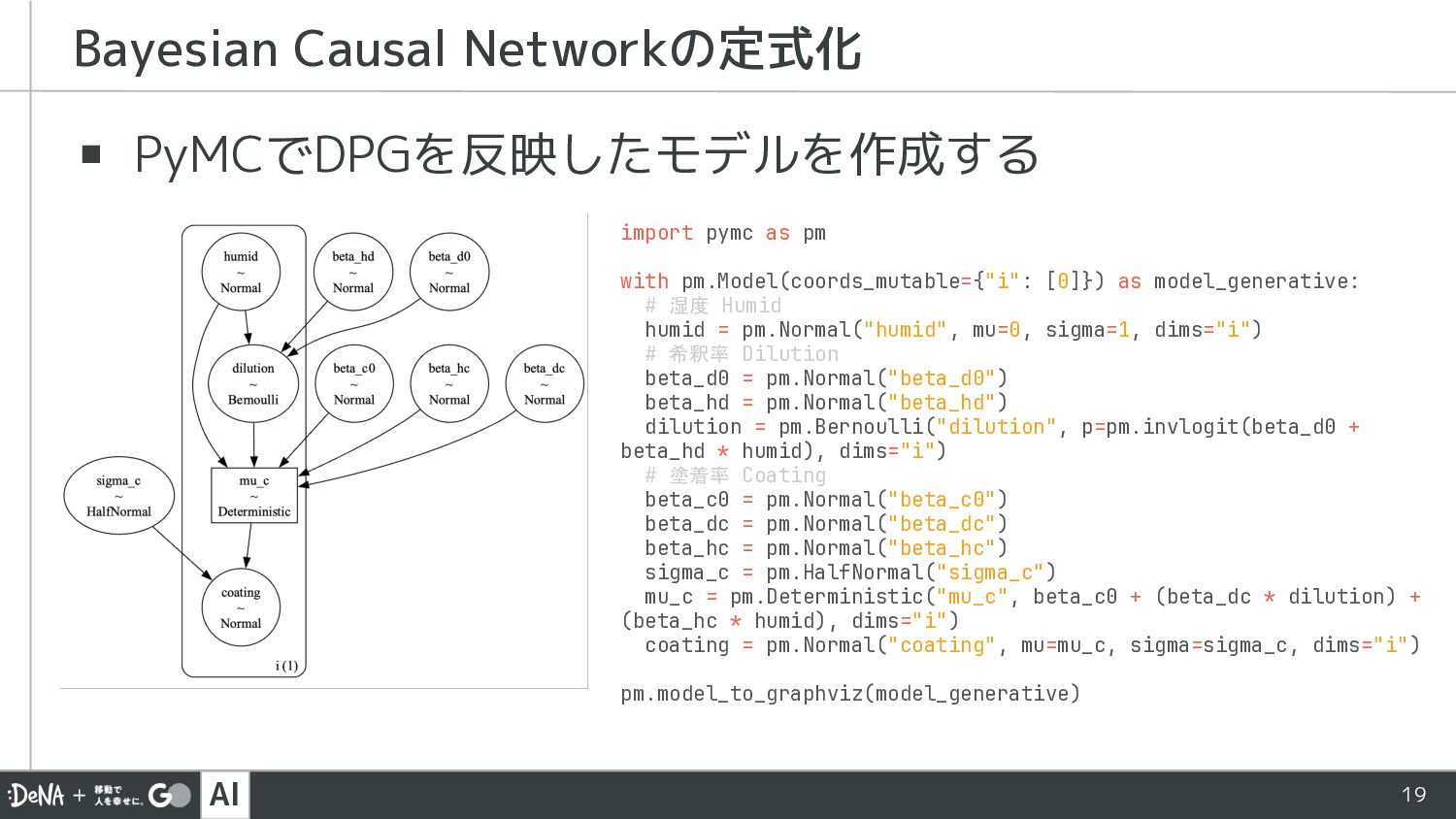
AI 18 ▪ データ生成過程をDAGにして、ノード間の確率的な関係 を式に変換する ▪ DAGでは外生変数が省略されていることに注意 Bayesian Causal Networkの定式化
塗着率 希釈率 湿度 湿度:𝐻𝑢𝑚𝑖𝑑~𝑁𝑜𝑟𝑚𝑎𝑙 0, 1 希釈率:𝐷𝑖𝑙𝑢𝑡𝑖𝑜𝑛~𝐵𝑒𝑟𝑛𝑜𝑢𝑙𝑙𝑖(𝐼𝑛𝑣𝐿𝑜𝑔𝑖𝑡(𝛽! + 𝛽"! ×𝐻𝑢𝑚𝑖𝑑)) 塗着率:𝐶𝑜𝑎𝑡𝑖𝑛𝑔~𝑁𝑜𝑟𝑚𝑎𝑙(𝛽# + 𝛽!# ×𝐷𝑖𝑙𝑢𝑡𝑖𝑜𝑛 + 𝛽"# ×𝐷𝑖𝑙𝑢𝑡𝑖𝑜𝑛, 𝜎# ) ベータ分布が望ましいですが、実験の都合上、正規分布にさせてください
AI 19 ▪ PyMCでDPGを反映したモデルを作成する Bayesian Causal Networkの定式化 import pymc as
pm with pm.Model(coords_mutable={"i": [0]}) as model_generative: # 湿度 Humid humid = pm.Normal("humid", mu=0, sigma=1, dims="i") # 希釈率 Dilution beta_d0 = pm.Normal("beta_d0") beta_hd = pm.Normal("beta_hd") dilution = pm.Bernoulli("dilution", p=pm.invlogit(beta_d0 + beta_hd * humid), dims="i") # 塗着率 Coating beta_c0 = pm.Normal("beta_c0") beta_dc = pm.Normal("beta_dc") beta_hc = pm.Normal("beta_hc") sigma_c = pm.HalfNormal("sigma_c") mu_c = pm.Deterministic("mu_c", beta_c0 + (beta_dc * dilution) + (beta_hc * humid), dims="i") coating = pm.Normal("coating", mu=mu_c, sigma=sigma_c, dims="i") pm.model_to_graphviz(model_generative)
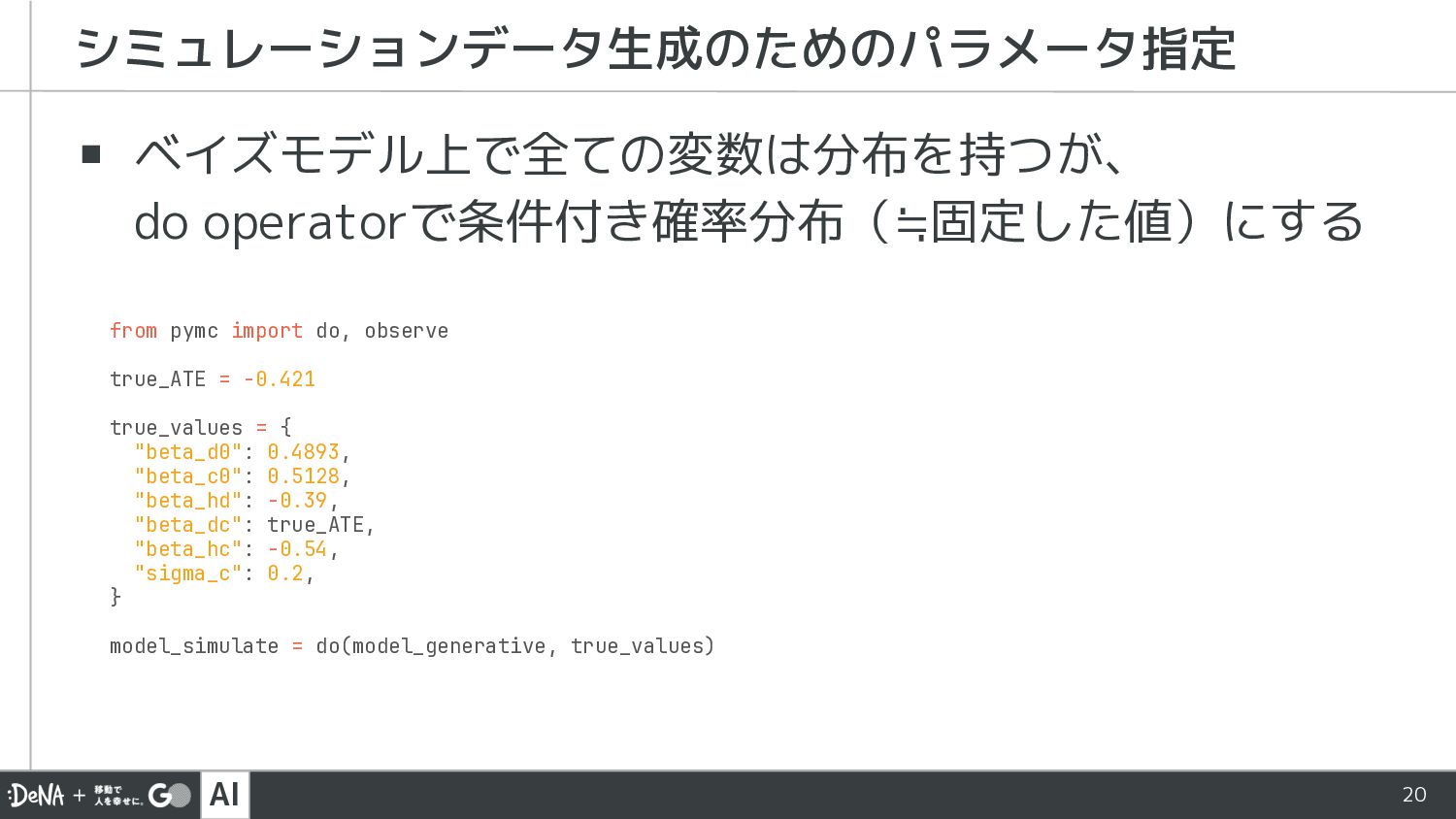
AI 20 ▪ ベイズモデル上で全ての変数は分布を持つが、 do operatorで条件付き確率分布(≒固定した値)にする シミュレーションデータ生成のためのパラメータ指定 from pymc import
do, observe true_ATE = -0.421 true_values = { "beta_d0": 0.4893, "beta_c0": 0.5128, "beta_hd": -0.39, "beta_dc": true_ATE, "beta_hc": -0.54, "sigma_c": 0.2, } model_simulate = do(model_generative, true_values)
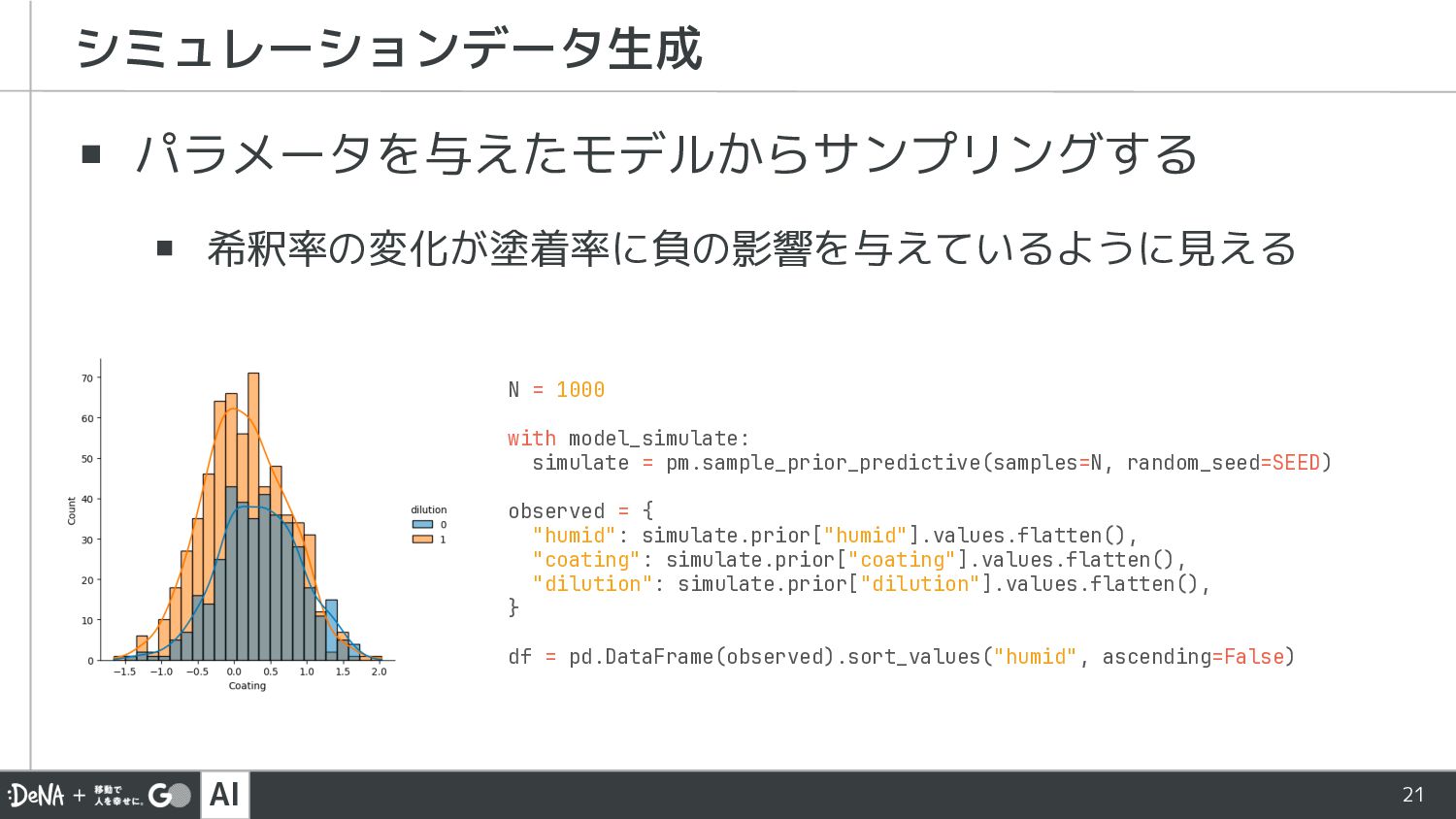
AI 21 ▪ パラメータを与えたモデルからサンプリングする ▪ 希釈率の変化が塗着率に負の影響を与えているように見える シミュレーションデータ生成 N = 1000
with model_simulate: simulate = pm.sample_prior_predictive(samples=N, random_seed=SEED) observed = { "humid": simulate.prior["humid"].values.flatten(), "coating": simulate.prior["coating"].values.flatten(), "dilution": simulate.prior["dilution"].values.flatten(), } df = pd.DataFrame(observed).sort_values("humid", ascending=False)
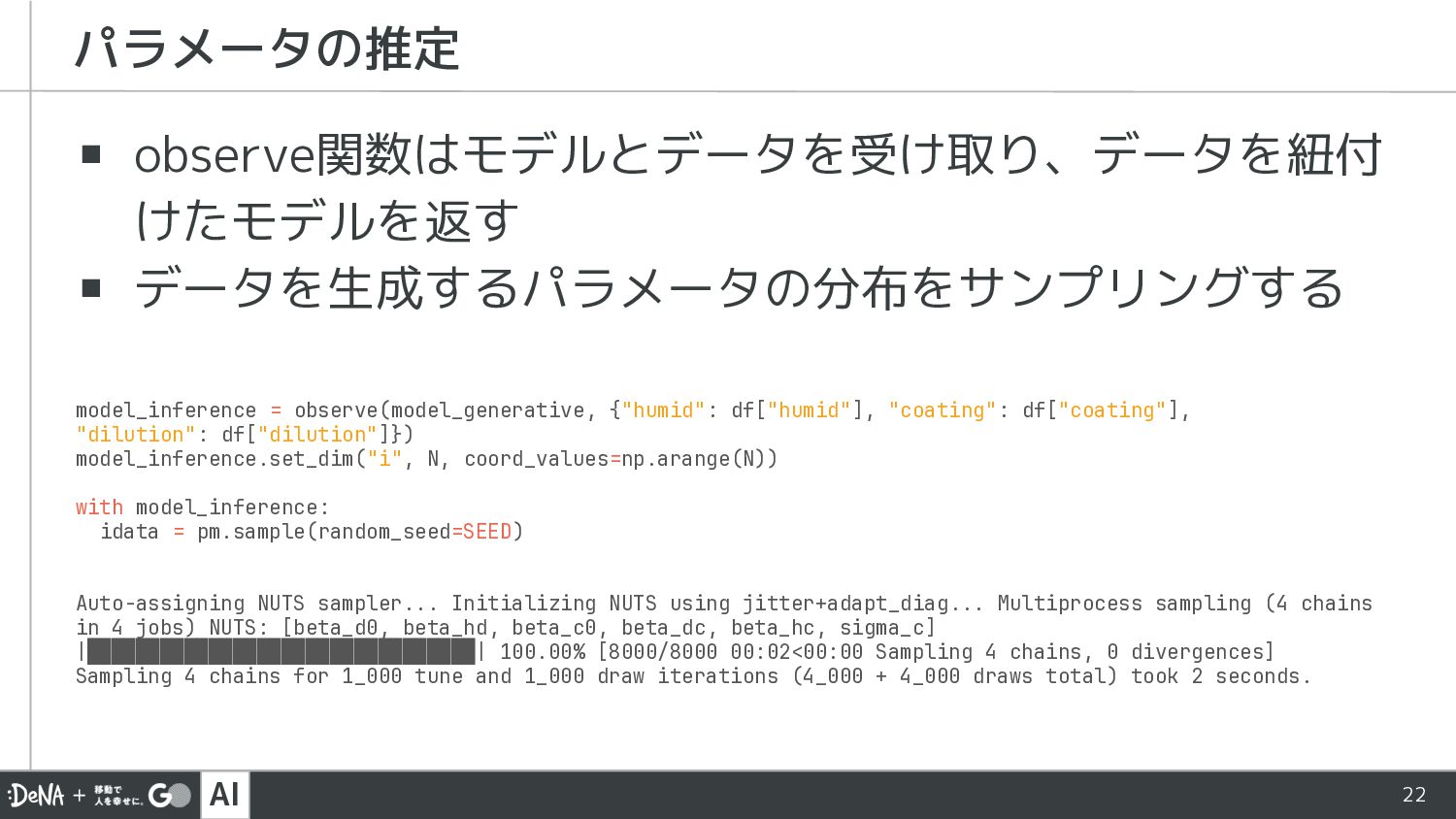
AI 22 ▪ observe関数はモデルとデータを受け取り、データを紐付 けたモデルを返す ▪ データを生成するパラメータの分布をサンプリングする パラメータの推定 model_inference =
observe(model_generative, {"humid": df["humid"], "coating": df["coating"], "dilution": df["dilution"]}) model_inference.set_dim("i", N, coord_values=np.arange(N)) with model_inference: idata = pm.sample(random_seed=SEED) Auto-assigning NUTS sampler... Initializing NUTS using jitter+adapt_diag... Multiprocess sampling (4 chains in 4 jobs) NUTS: [beta_d0, beta_hd, beta_c0, beta_dc, beta_hc, sigma_c] |████████████████████████████████| 100.00% [8000/8000 00:02<00:00 Sampling 4 chains, 0 divergences] Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
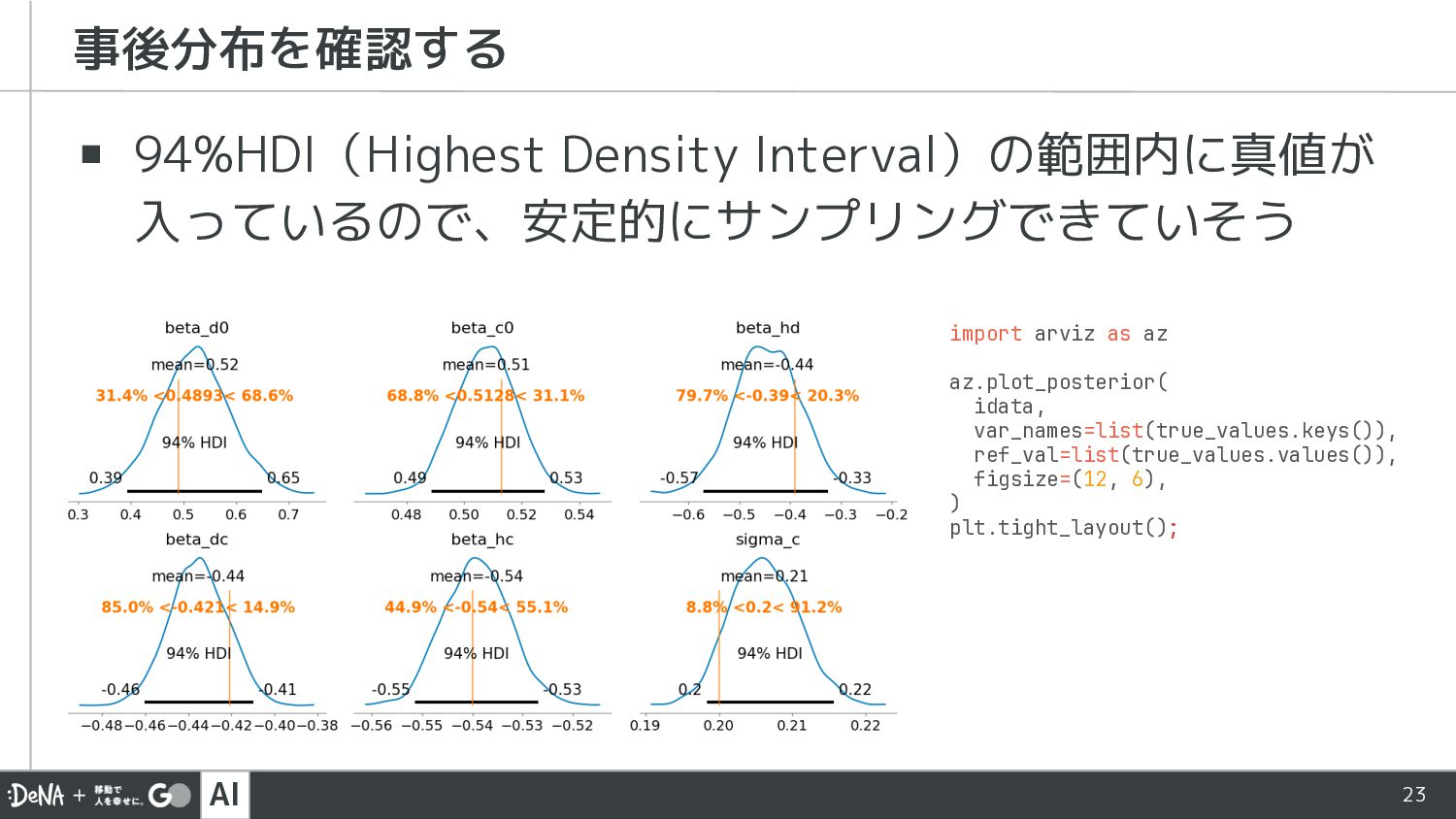
AI 23 ▪ 94%HDI(Highest Density Interval)の範囲内に真値が 入っているので、安定的にサンプリングできていそう 事後分布を確認する import arviz
as az az.plot_posterior( idata, var_names=list(true_values.keys()), ref_val=list(true_values.values()), figsize=(12, 6), ) plt.tight_layout();
AI 24 04 介入のシミュレーション
AI 25 ▪ 「もし、全データで希釈率が1だったら?」という反事実 のシナリオをシミュレーションすることができる 反事実のデータを生成する # 湿度を観測データに置き換えてサンプリングされないようにする model_counterfactual =
do(model_inference, {"humid": df["humid"]}) # Generate models with dilution=0 and dilution=1 model_d0 = do(model_counterfactual, {"dilution": np.zeros(N, dtype="int32")}, prune_vars=True) model_d1 = do(model_counterfactual, {"dilution": np.ones(N, dtype="int32")}, prune_vars=True) 𝐴𝑇𝐸 = 𝔼#$%&'() 𝑐𝑜𝑎𝑡𝑖𝑛𝑔 𝑑𝑜 𝑑𝑖𝑙𝑢𝑡𝑖𝑜𝑛 = 1 − 𝔼#$%&'() [𝑐𝑜𝑎𝑡𝑖𝑛𝑔|𝑑𝑜 𝑑𝑖𝑙𝑢𝑡𝑖𝑜𝑛 = 0 ]
AI 26 ▪ ATEは-0.44と推定 反事実のデータからATEを推定する # Sample new coating data
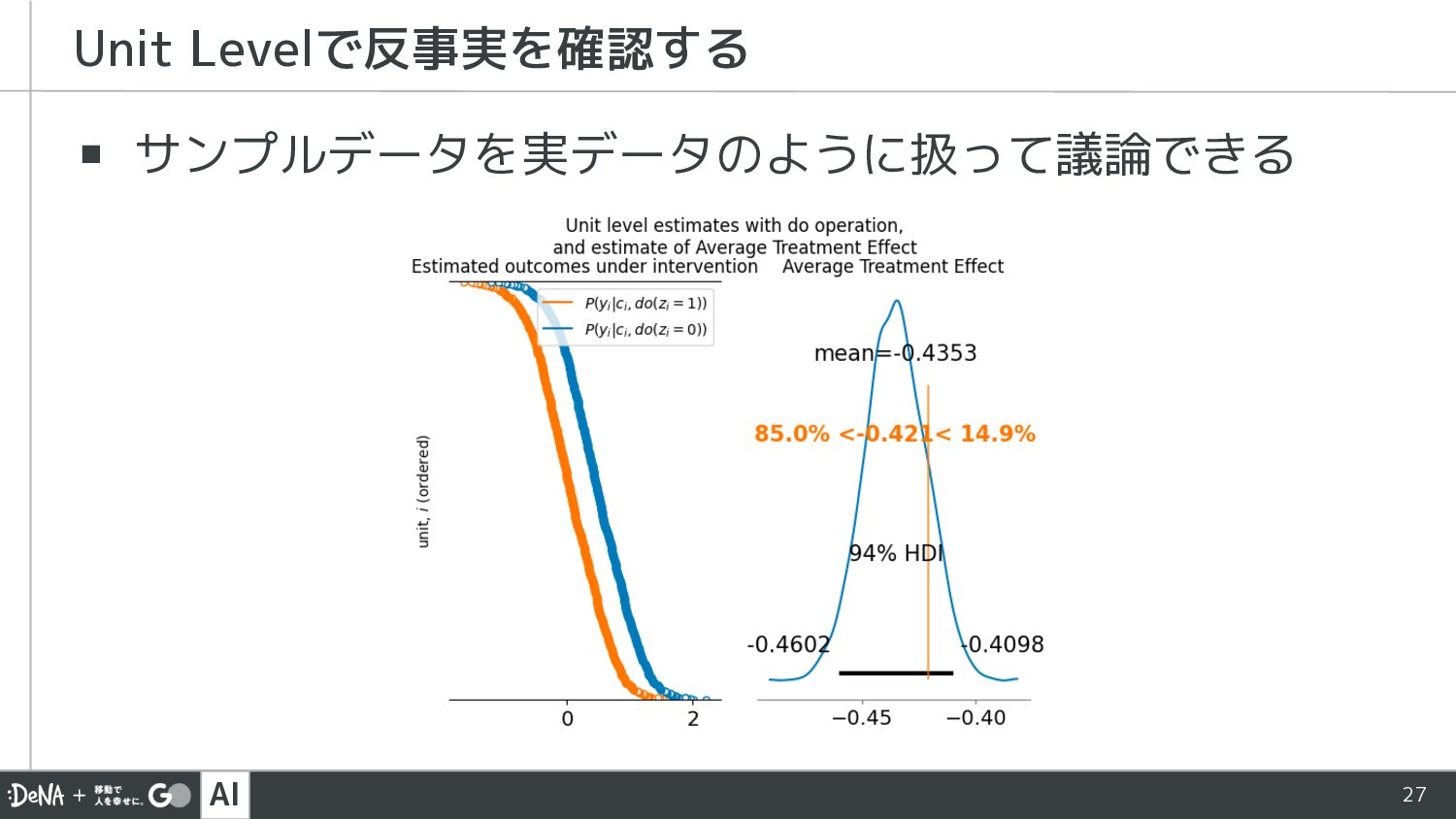
assuming dilution = 0: P(coating | humid, do(dilution=0)) idata_d0 = pm.sample_posterior_predictive( idata, model=model_d0, predictions=True, var_names=["mu_c"], random_seed=SEED, ) # Sample new coating data assuming dilution = 1: P(coating | humid, do(dilution=1)) idata_d1 = pm.sample_posterior_predictive( idata, model=model_d1, predictions=True, var_names=["mu_c"], random_seed=SEED, ) # calculate estimated ATE ATE_est = idata_d1.predictions - idata_d0.predictions print(f"Estimated ATE = {ATE_est.mu_c.mean().values:.2f}") Estimated ATE = -0.44
AI 27 ▪ サンプルデータを実データのように扱って議論できる Unit Levelで反事実を確認する
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}