スマホアプリ IoT 外部データ Data Warehouse Data Marts BI (Business Intelligence) 分析 ML 推論結果 データソース データレイク データウェアハウス CRM/SFA データアクセス アプリDB 分析DB RDB データウェアハウスモダナイゼーション:https://www.slideshare.net/GoogleCloudPlatformJP/cloud-onair-20191017/GoogleCloudPlatformJP/cloud-onair-20191017 ビッグデータ時代の計算機統計学と計算環境:https://www.jstage.jst.go.jp/article/jscswabun/30/2/30_229/_pdf 加工
Bengio氏率いるカナダのQuebec AI InstituteのMilaで作成 ▪ グラフィカルモデルから入るため理解しやすい ▪ Data Science for Economics ▪ https://madina-k.github.io/dse_mk2021/landing-page.html ▪ オランダTilburg Universityの因果推論のコース ▪ 機械学習と因果推論の対比が多く、機械学習から入った人には良い ▪ Causal Inference for The Brave and True ▪ https://matheusfacure.github.io/python-causality-handbook/landing-page.html ▪ American Economic AssociationでJoshua Angrist、Alberto Abadie、 Christopher Waltersの講演内容を元に作成されたオープンソースのコンテンツ オンラインコンテンツ
▪ https://www.gsb.stanford.edu/faculty-research/centers- initiatives/sil/research/methods/ai-machine-learning/short-course ▪ Stanford Graduate School of Businessで開催されたコース オンラインコンテンツ
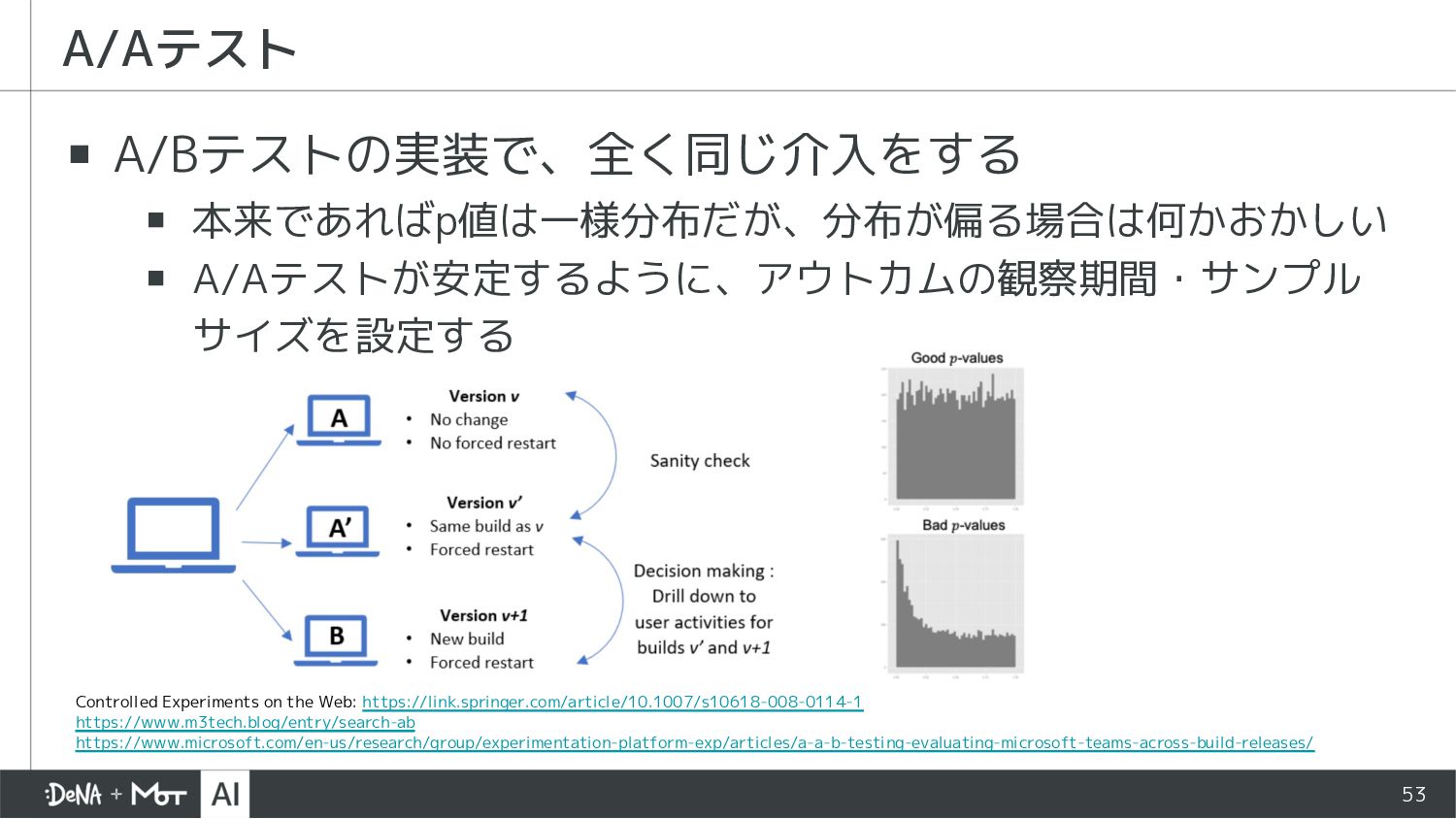
Experiments on the Web: https://link.springer.com/article/10.1007/s10618-008-0114-1 https://www.m3tech.blog/entry/search-ab https://www.microsoft.com/en-us/research/group/experimentation-platform-exp/articles/a-a-b-testing-evaluating-microsoft-teams-across-build-releases/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
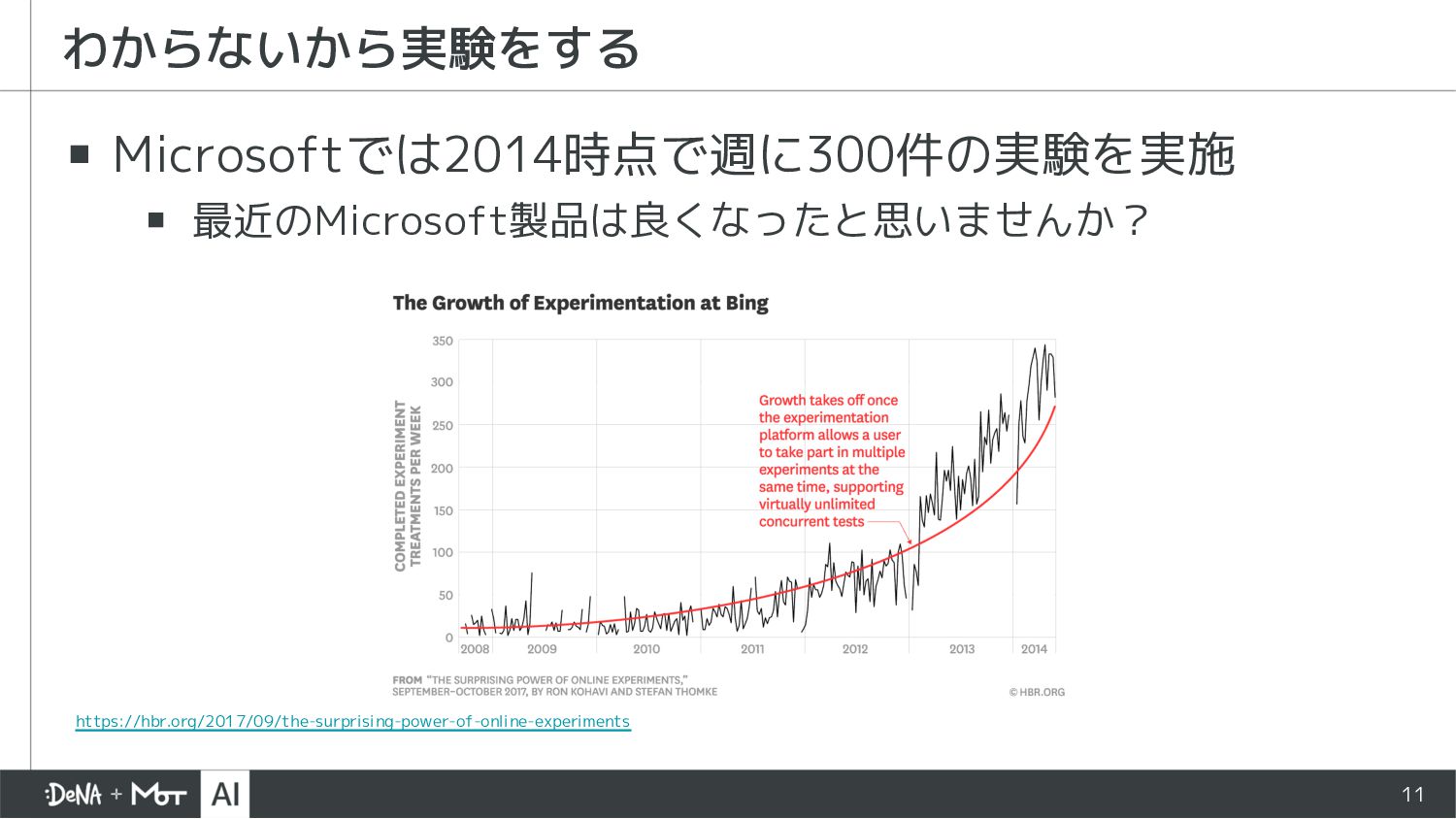{kind=link}
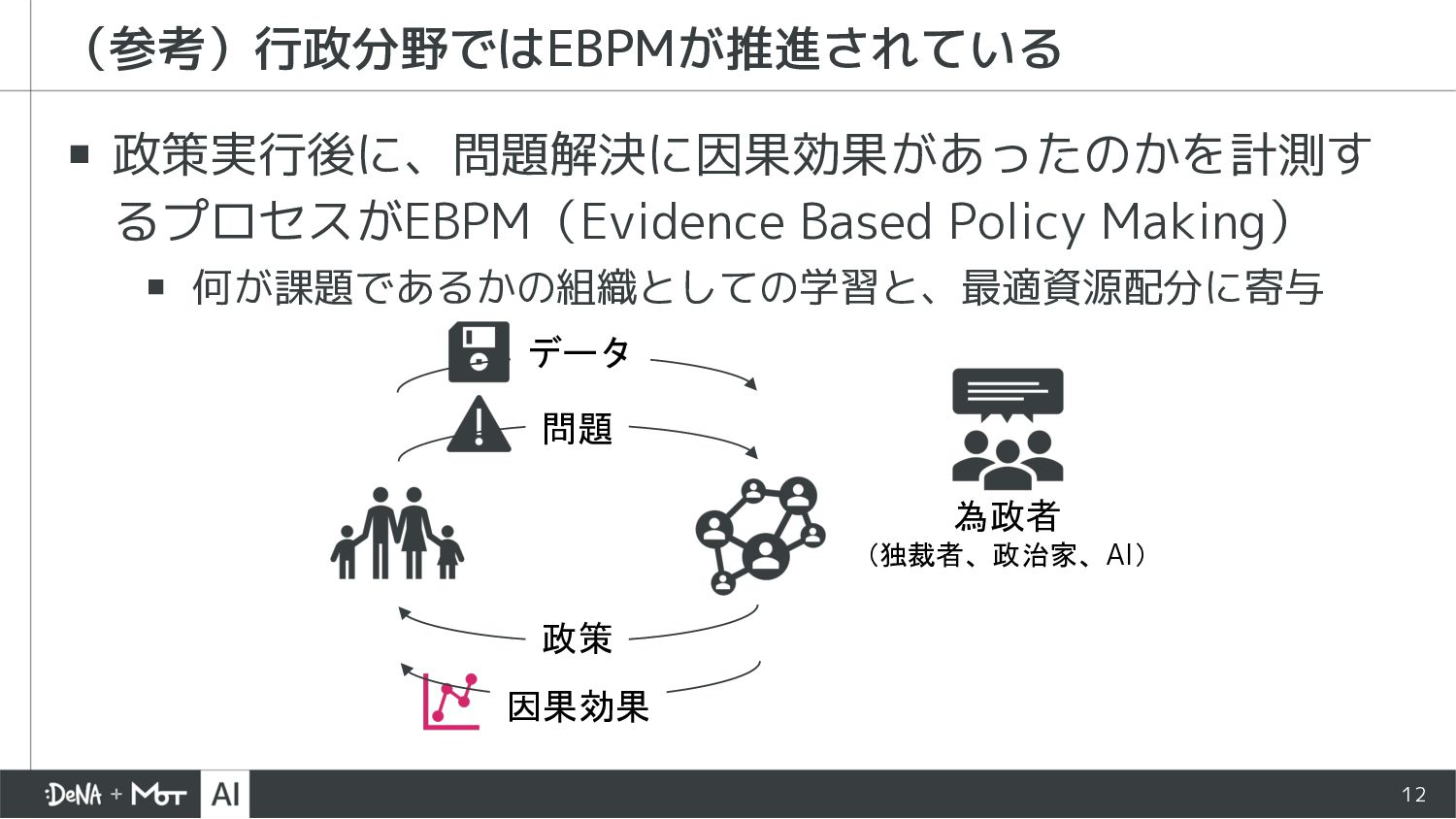{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
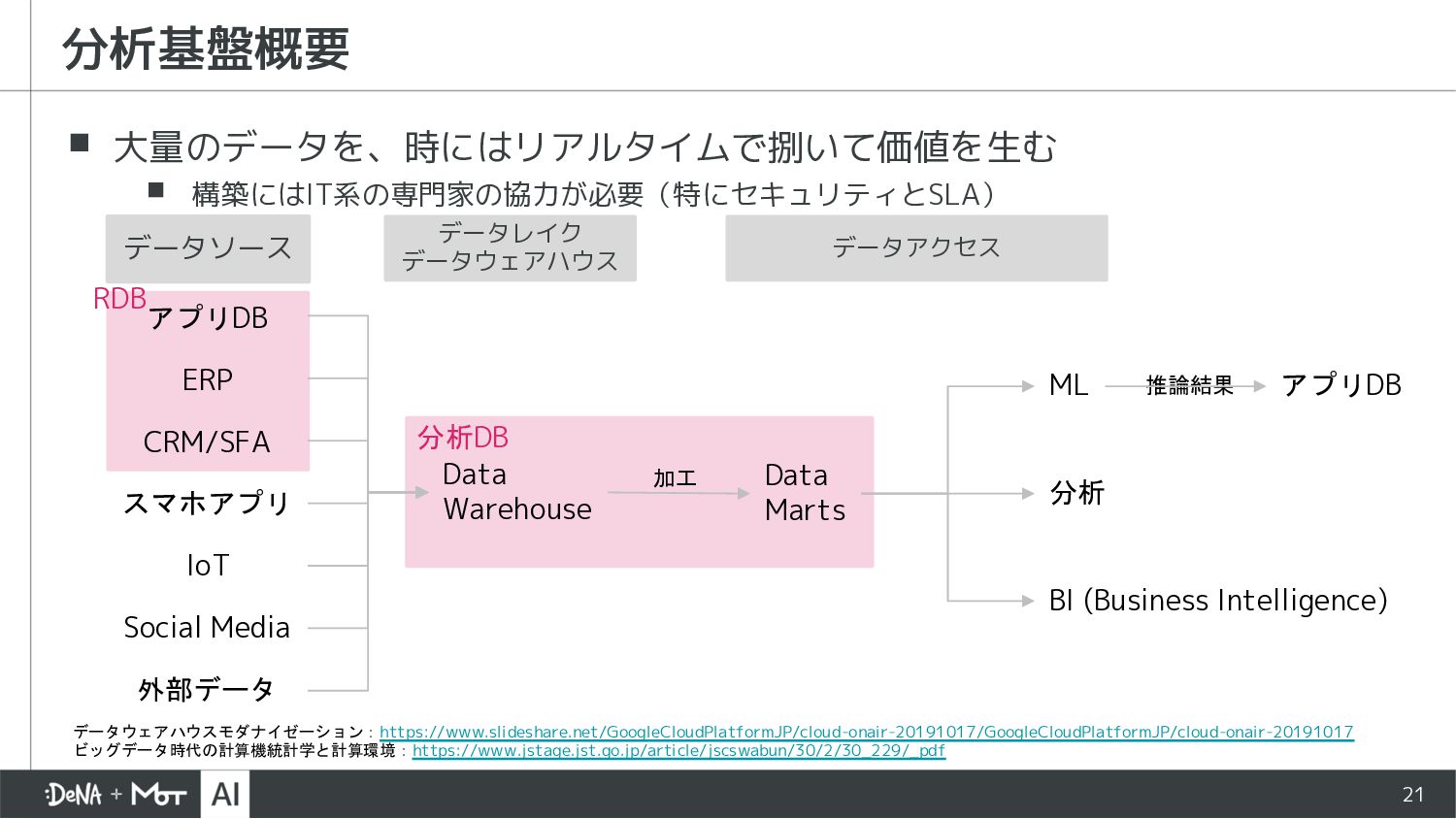{kind=link}
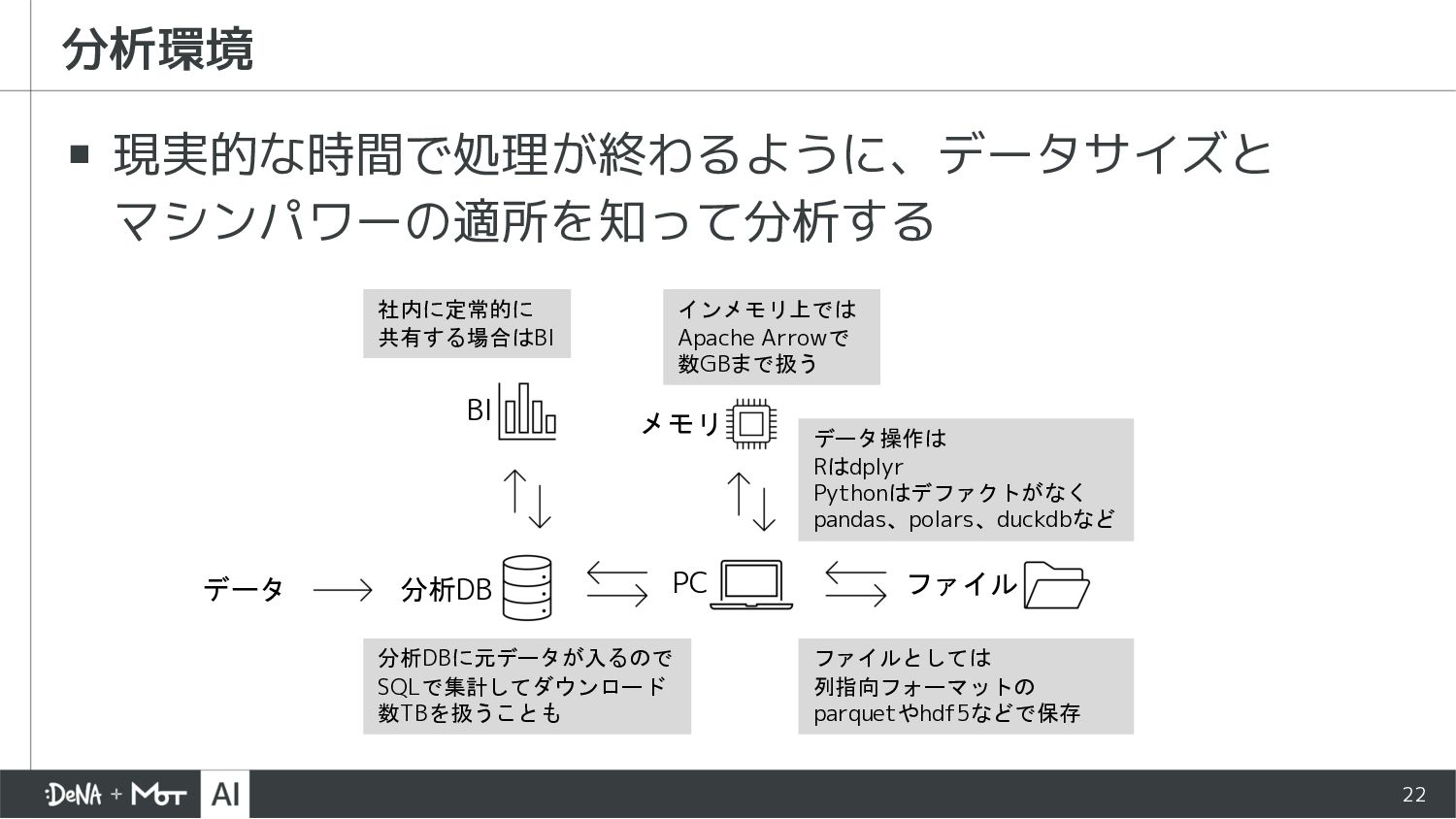{kind=link}
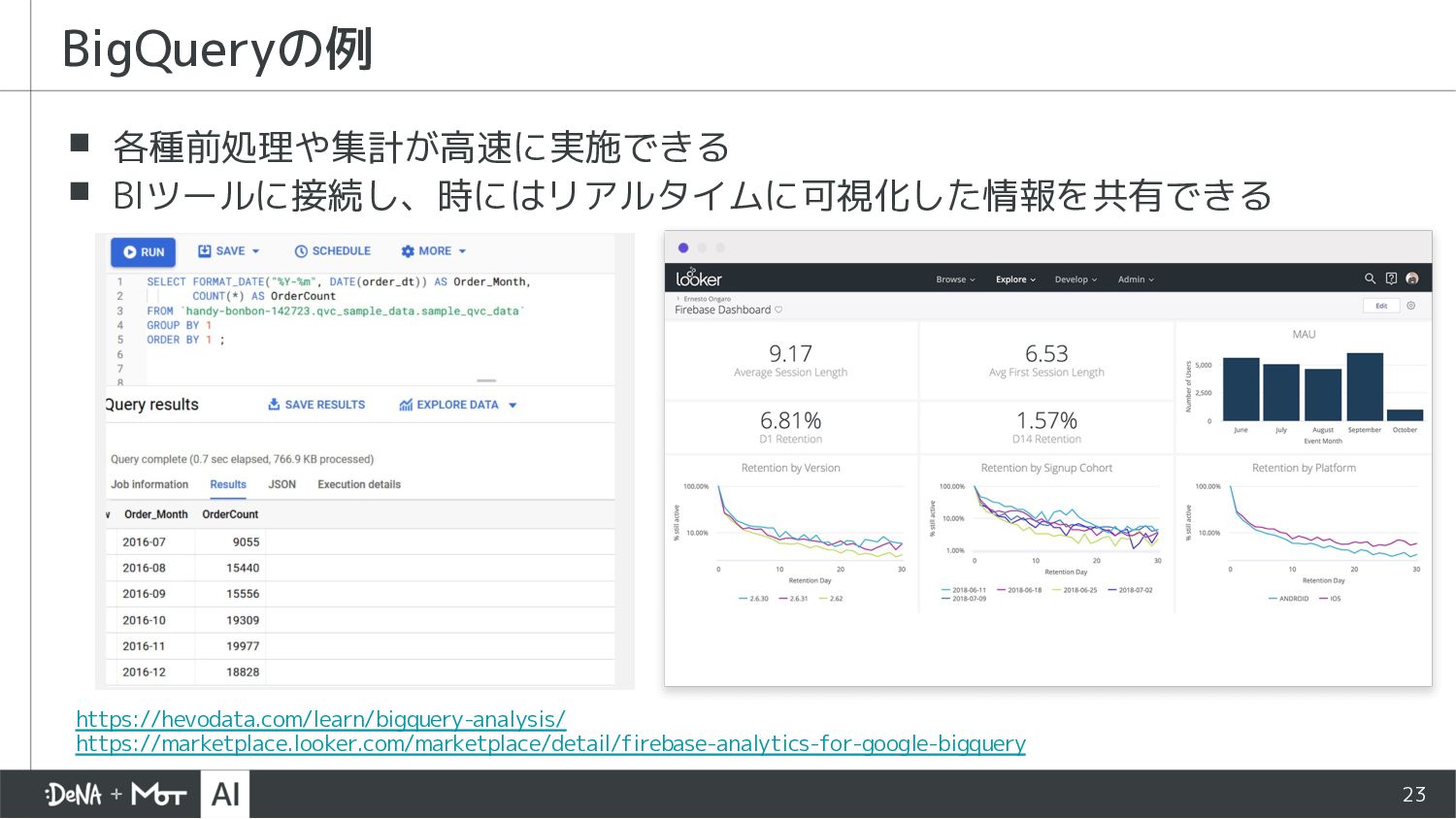{kind=link}
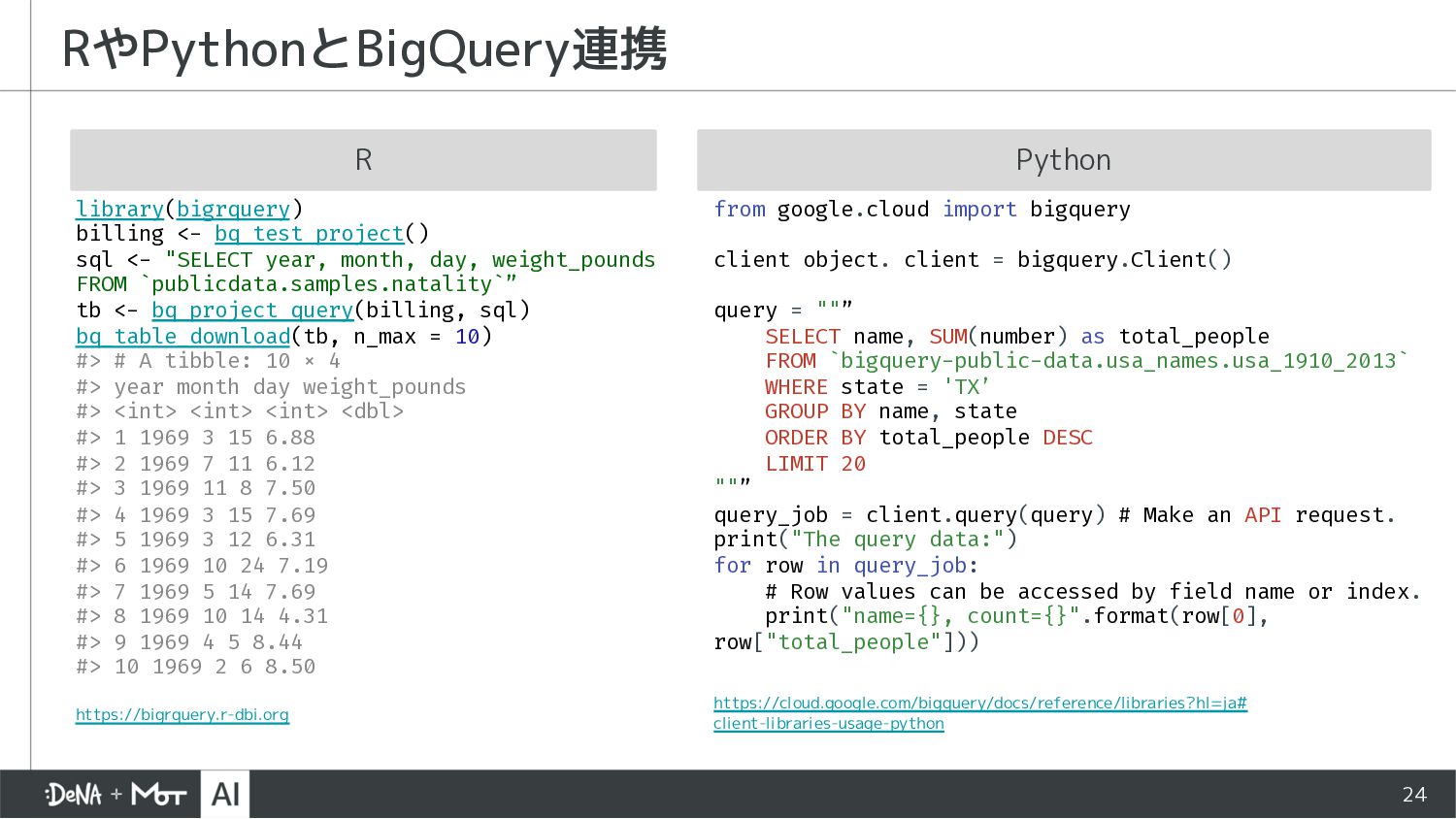{kind=link}
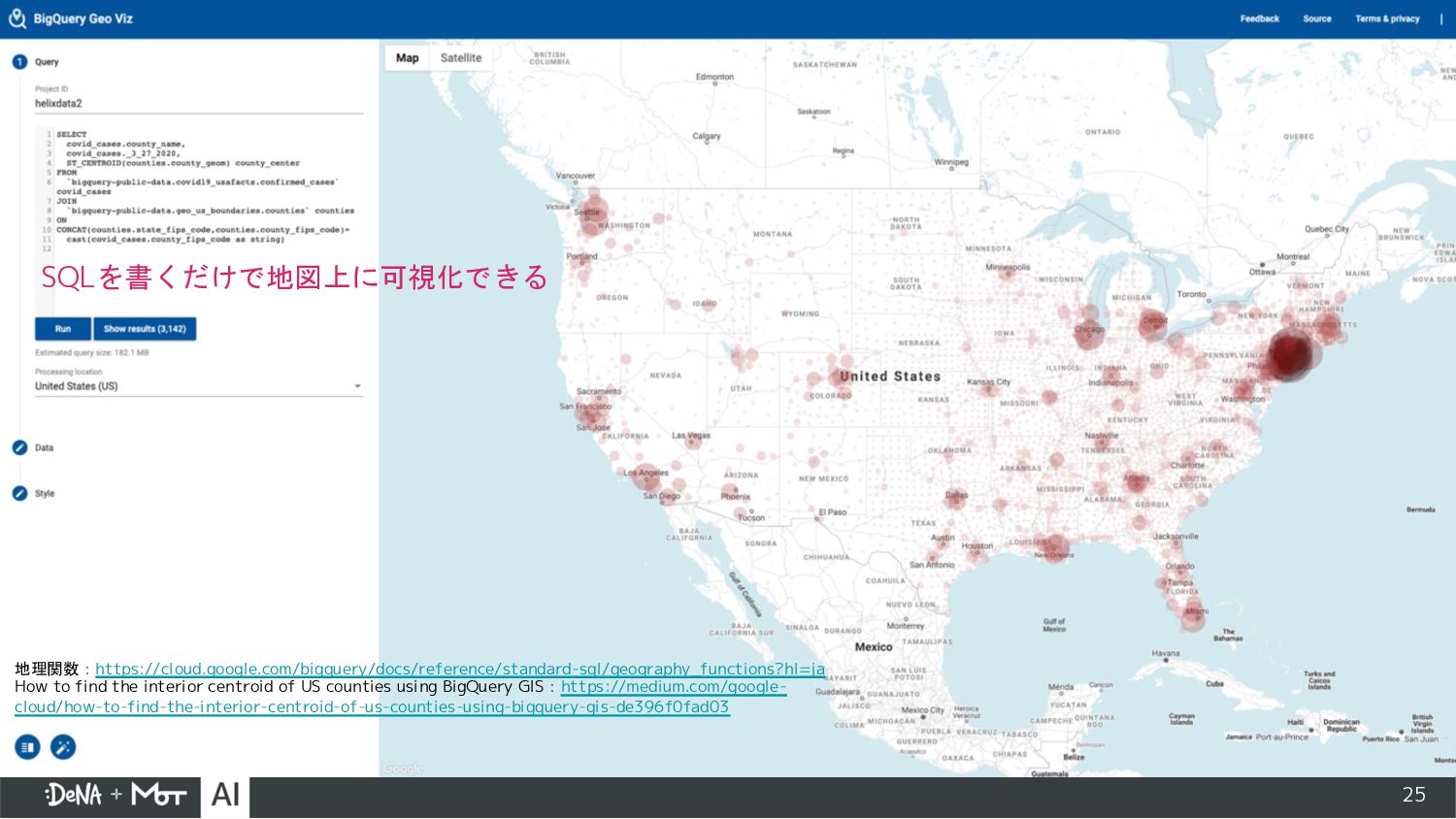{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
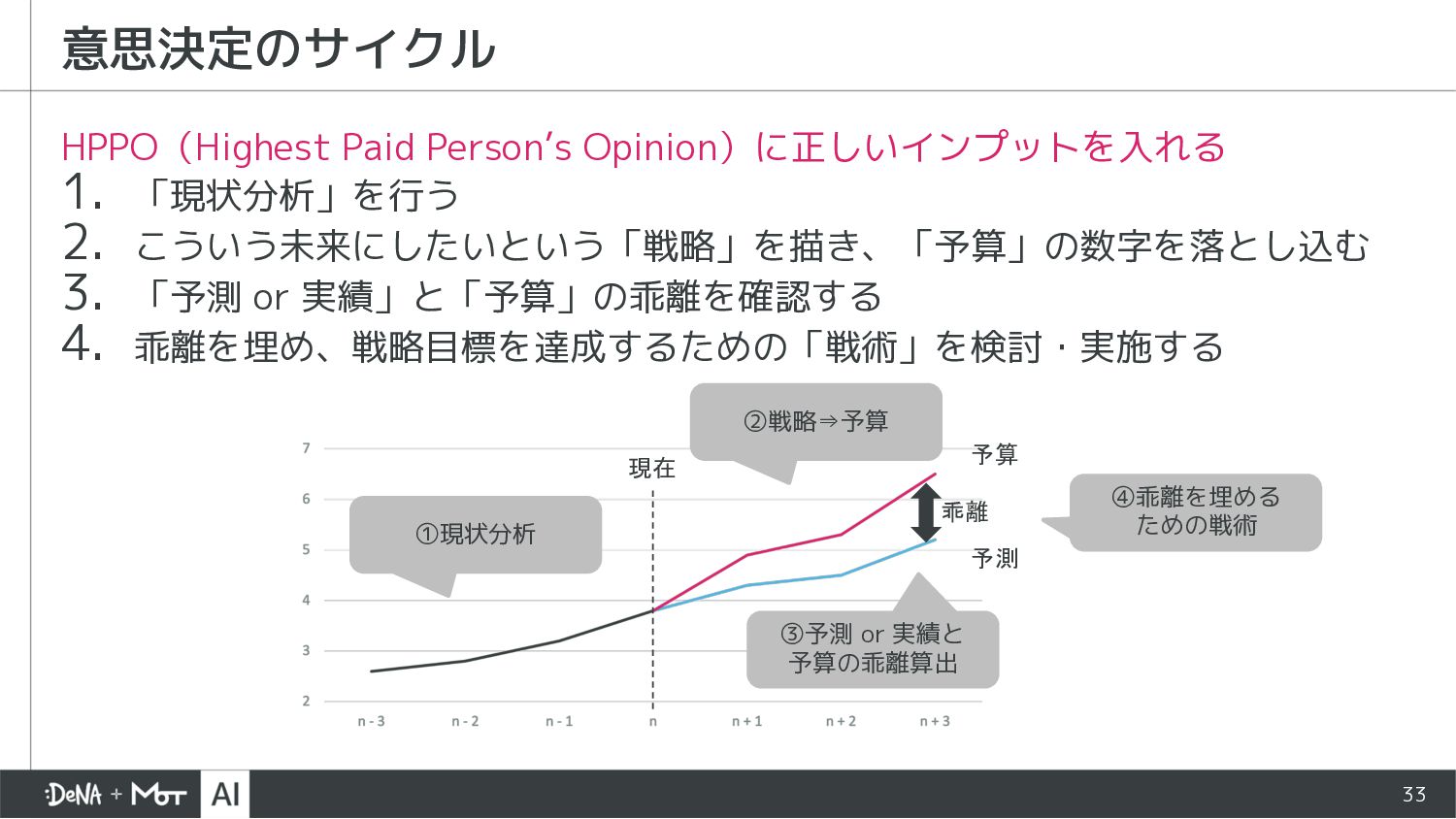{kind=link}
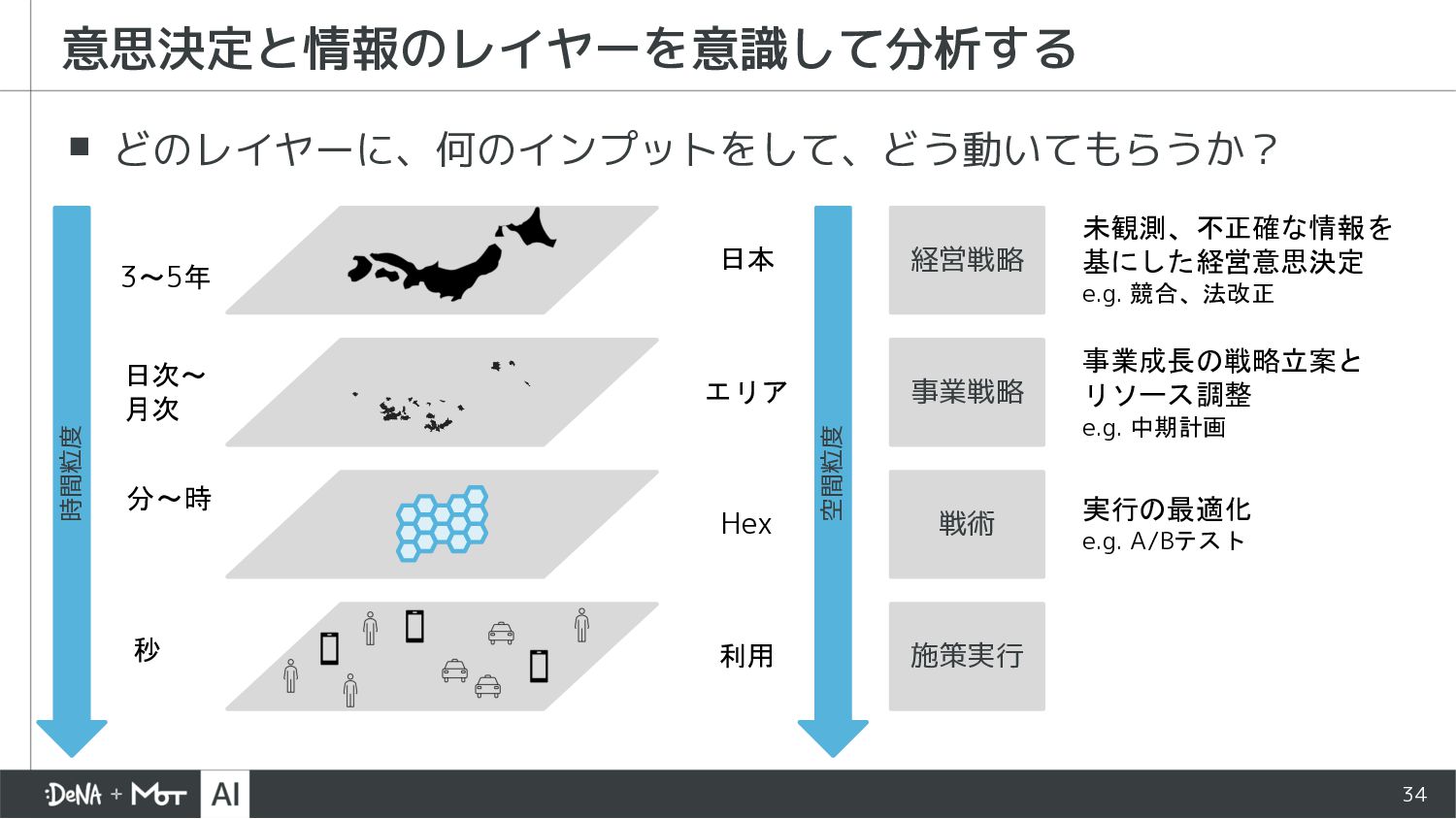{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
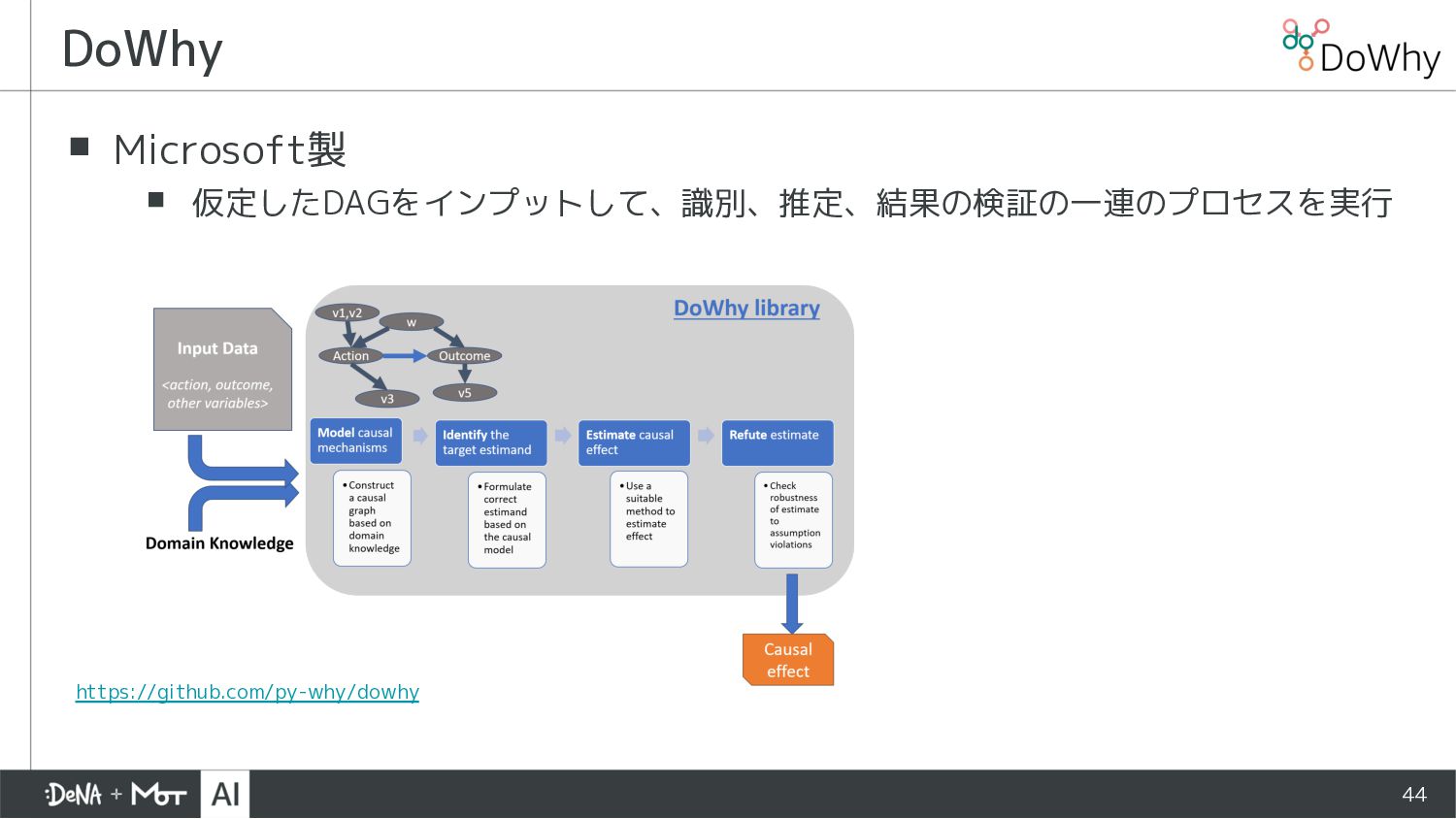{kind=link}
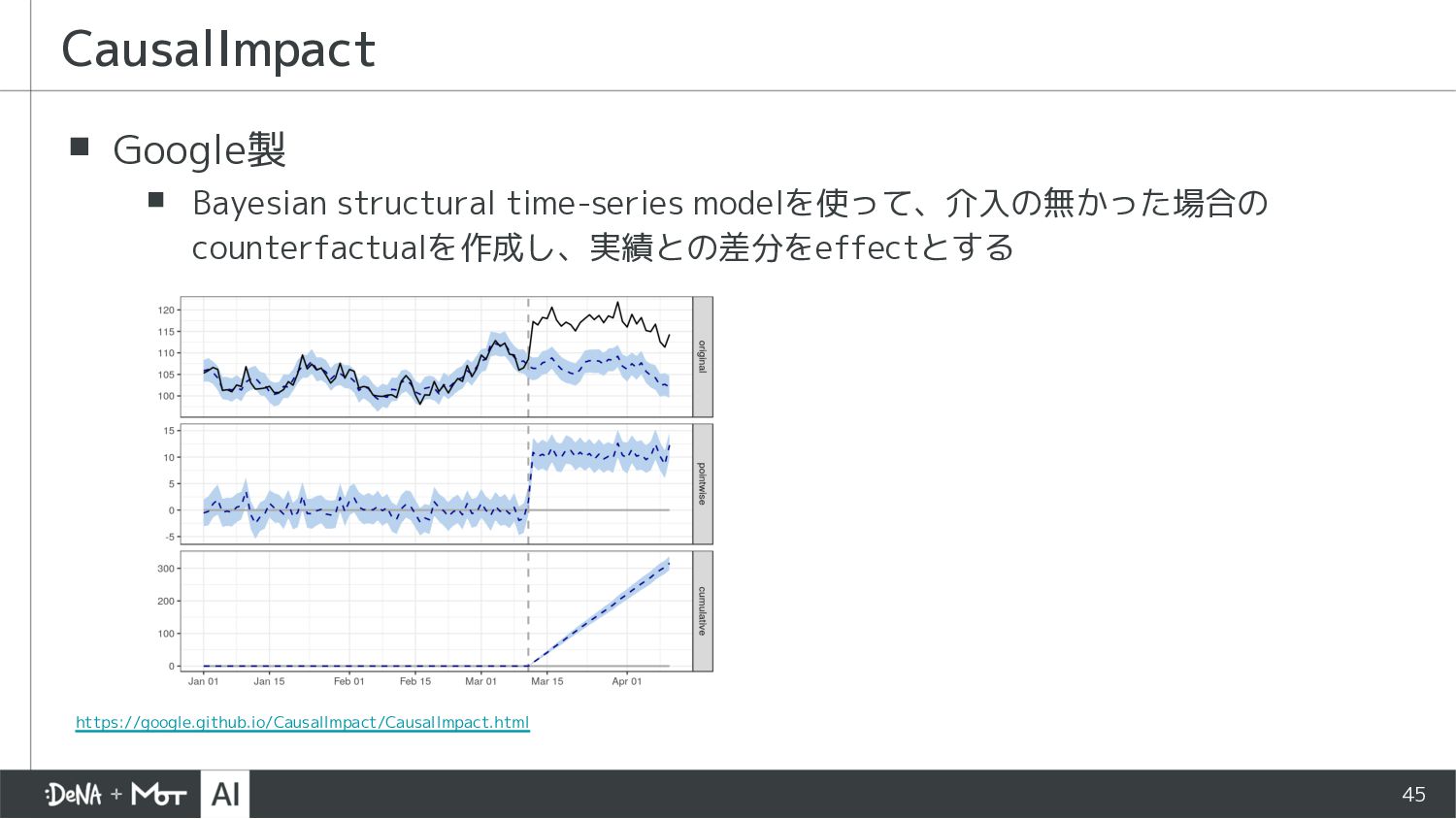{kind=link}
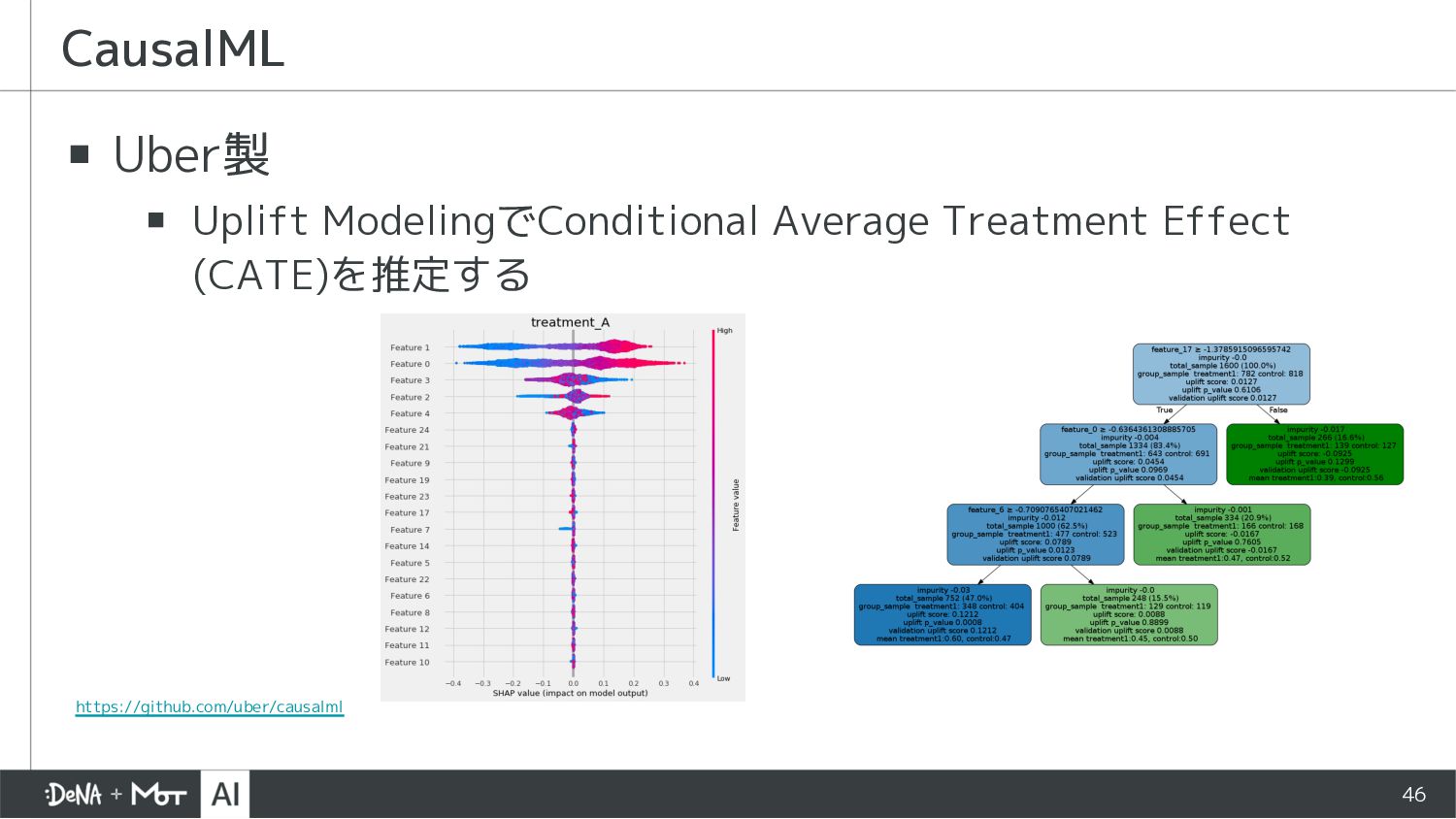{kind=link}
{kind=link}
{kind=link}
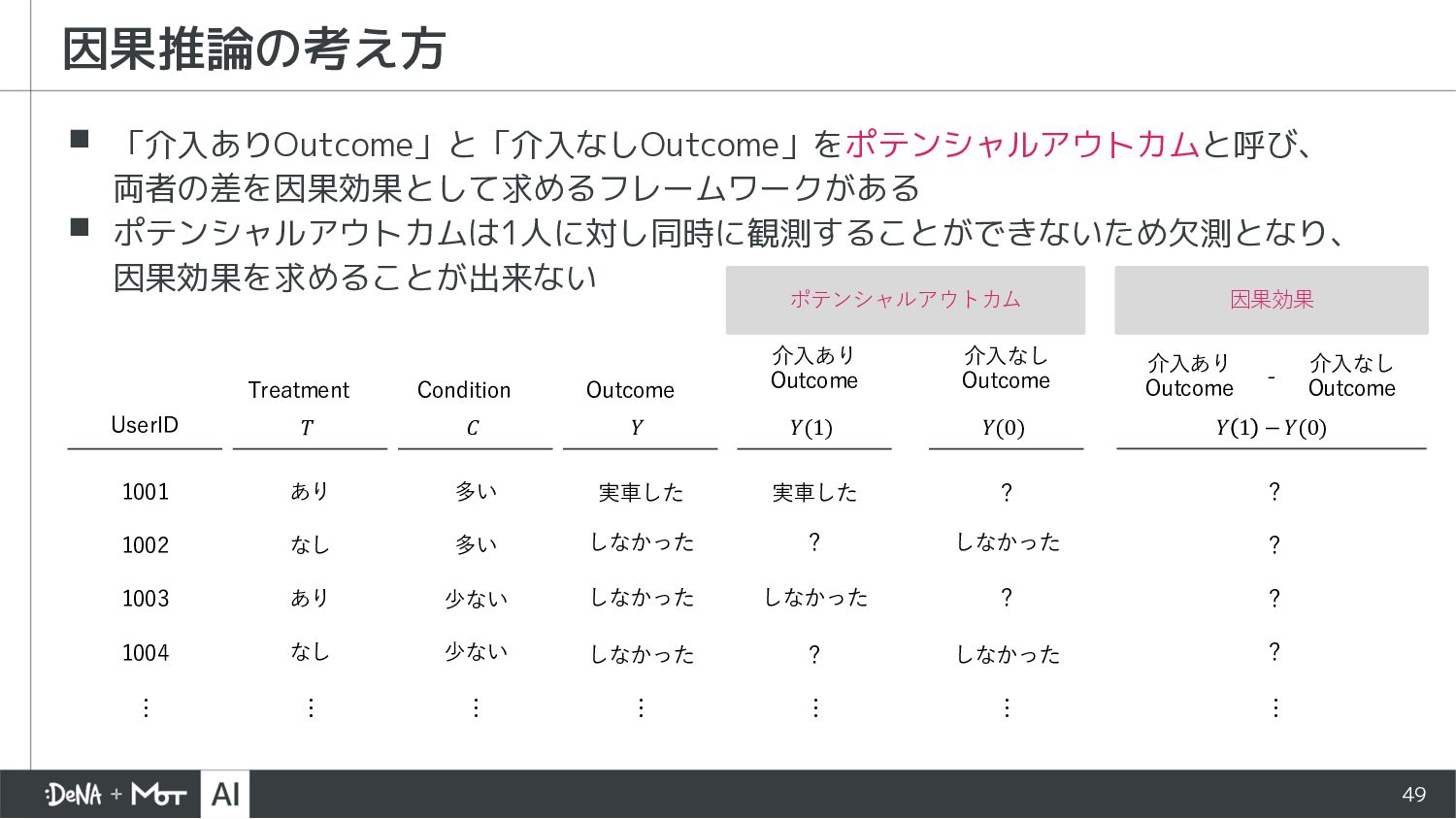{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
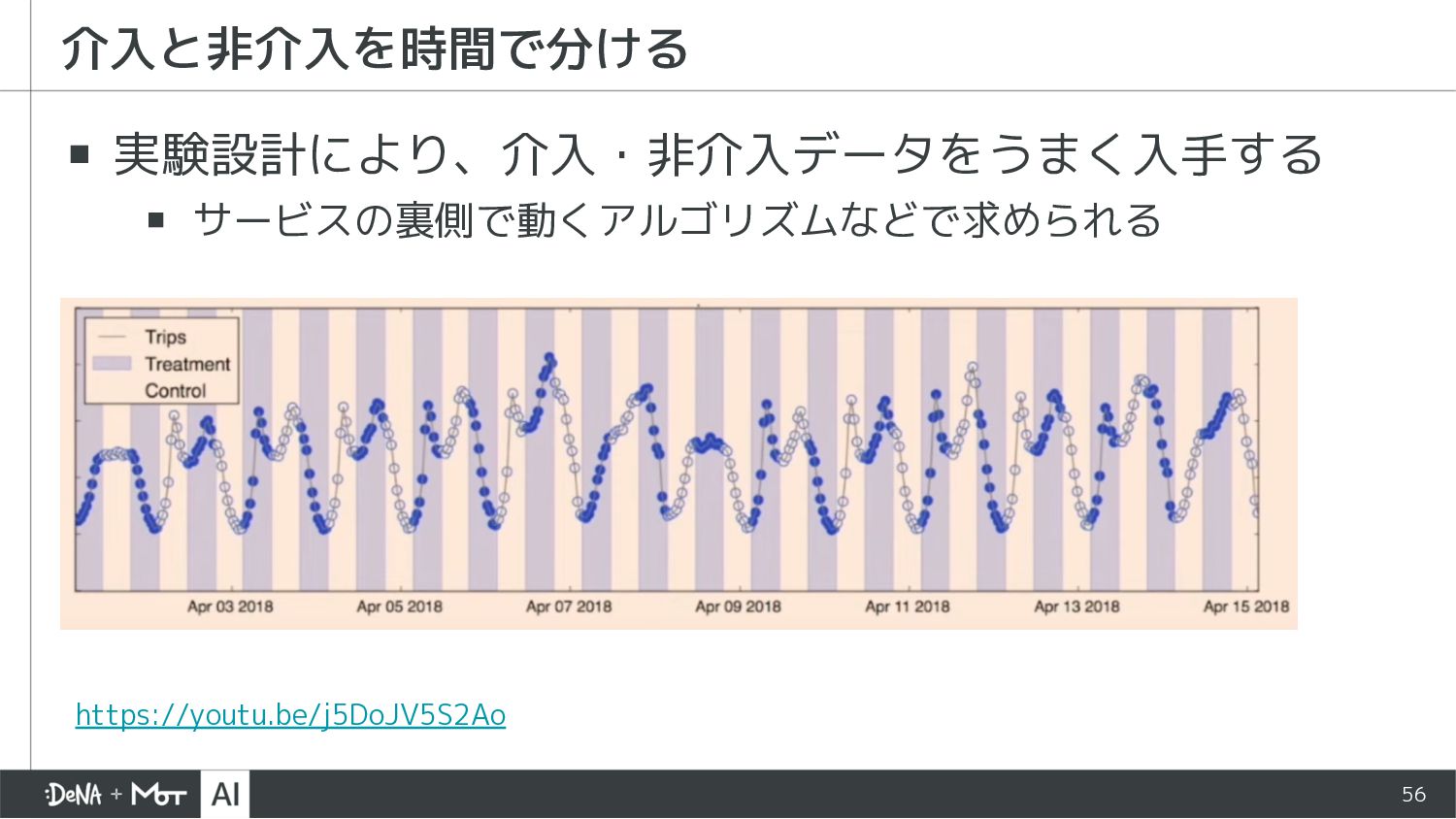{kind=link}
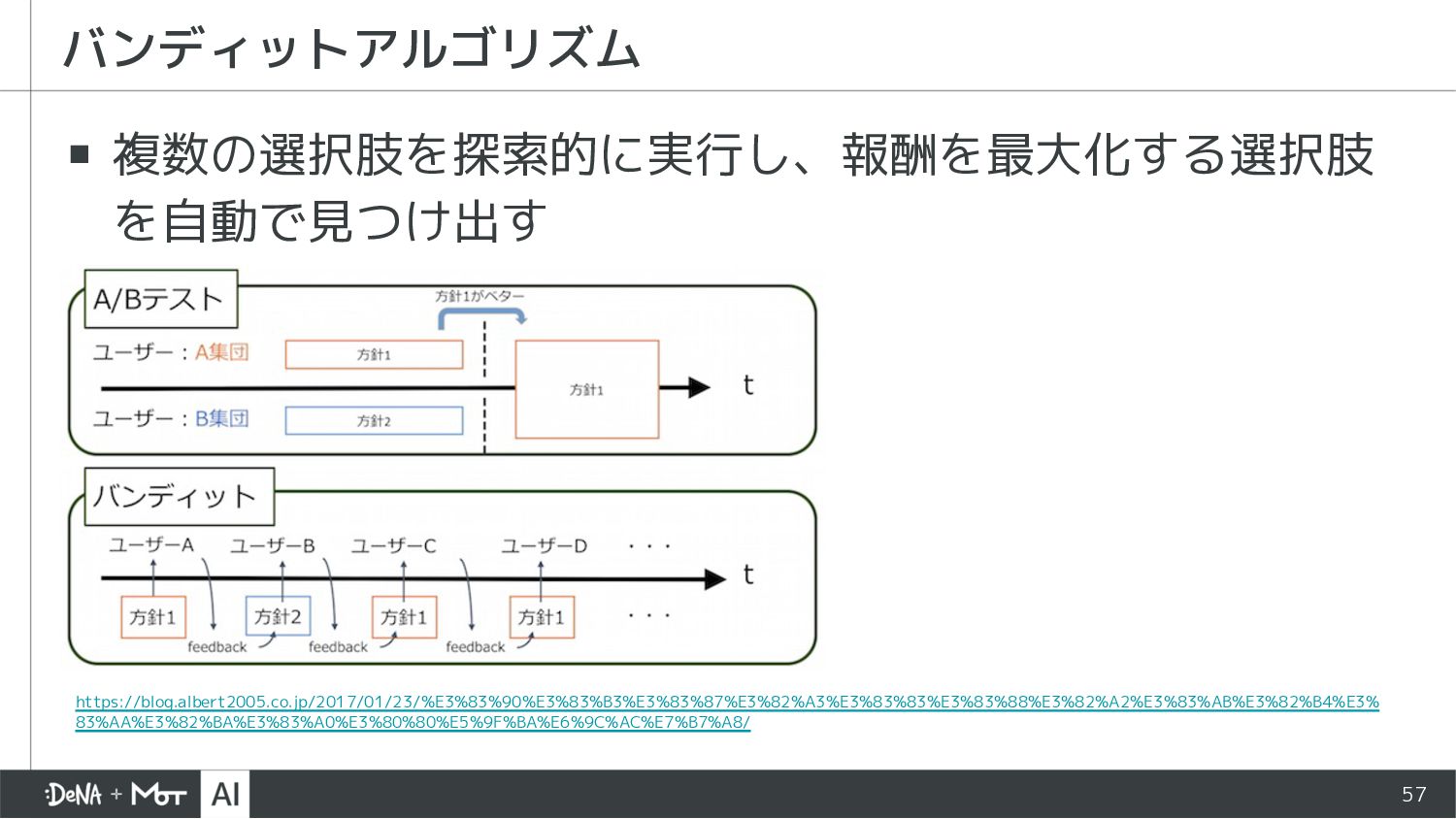{kind=link}
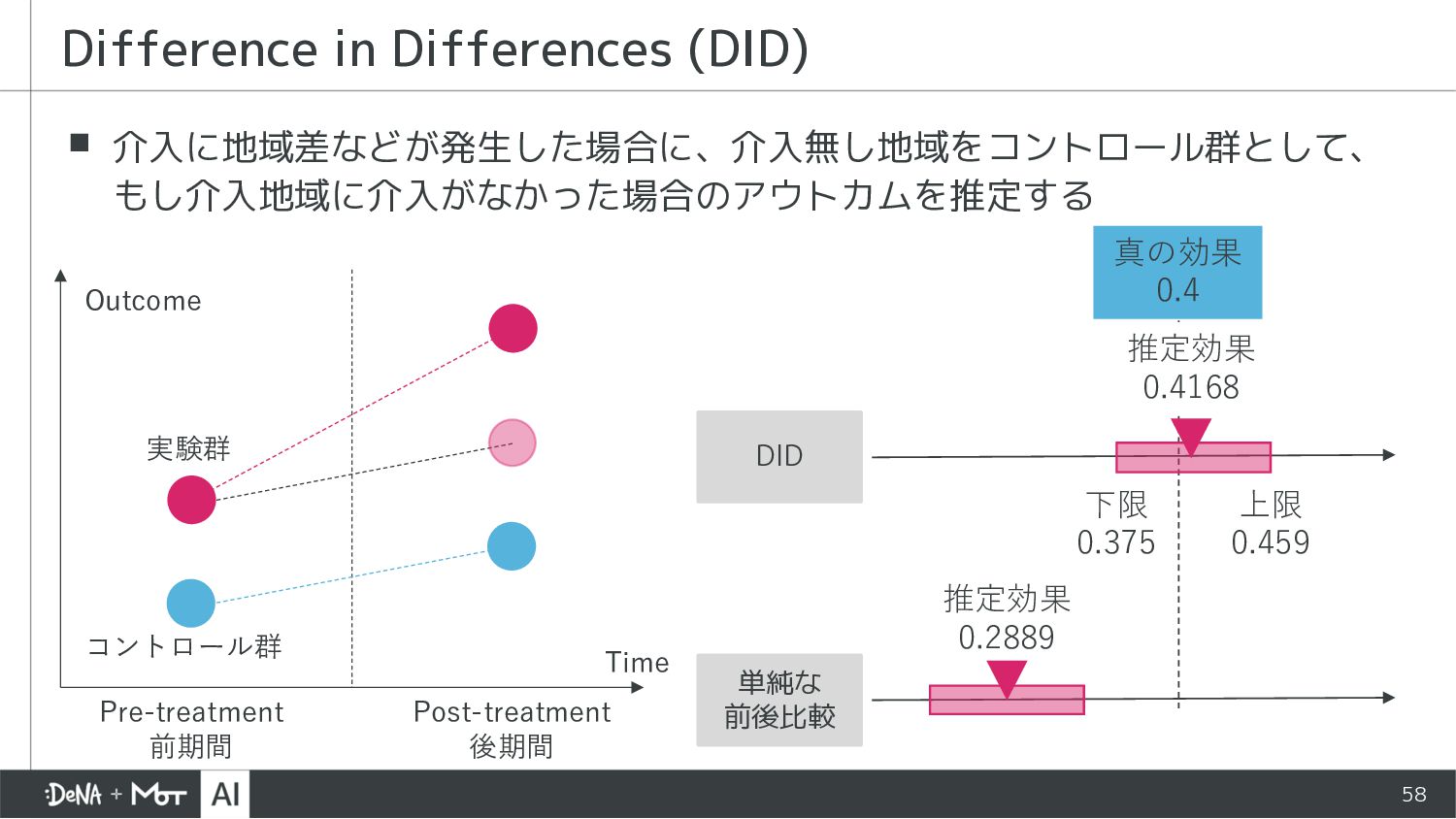{kind=link}
{kind=link}
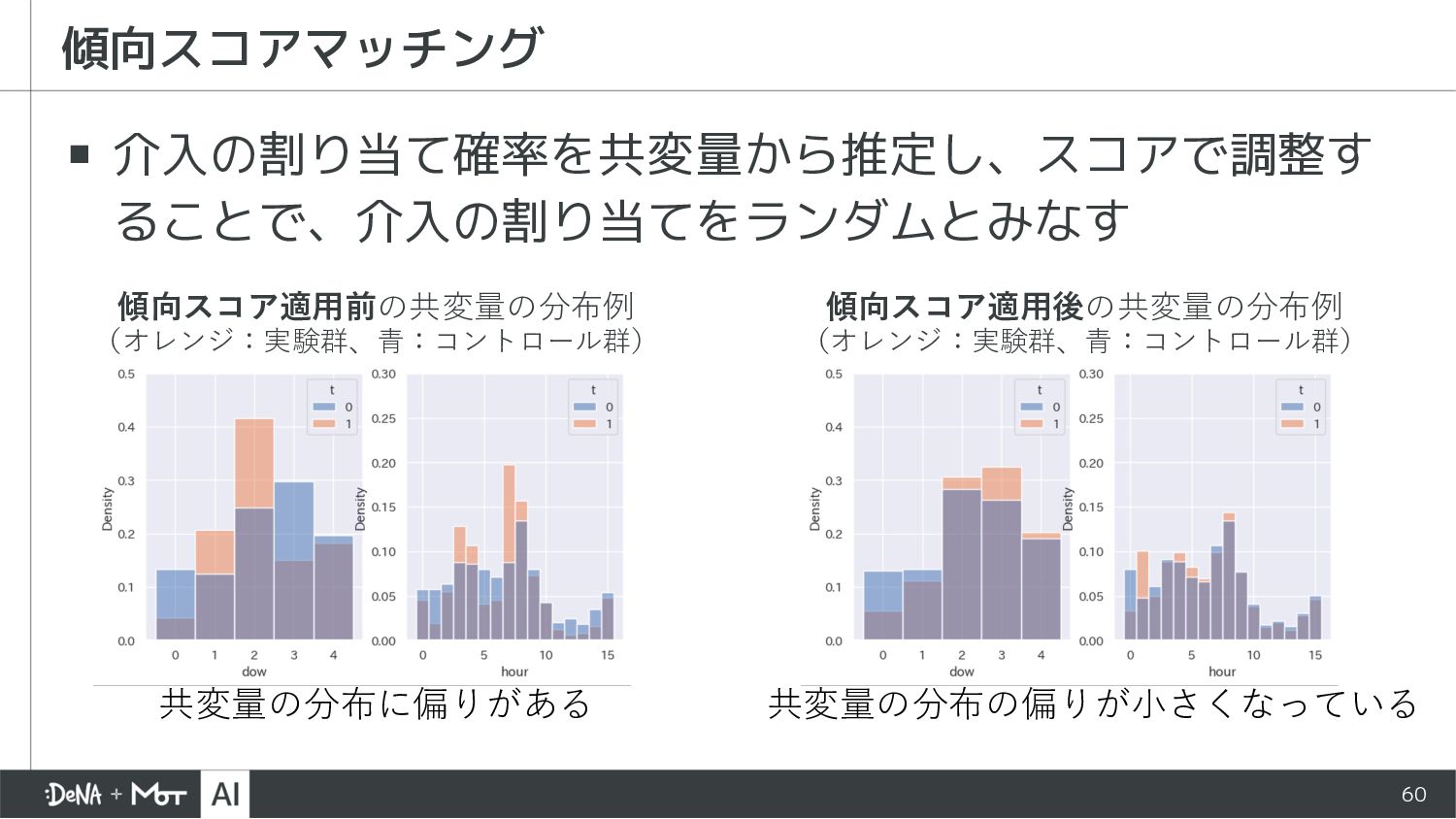{kind=link}
{kind=link}