get some attention and your scaling story begins. Some kinds of data start to grow really quickly. You find hotspots, track down the queries that aren’t so fast, and you add an index in your database to make that query faster. Rinse, repeat. Most apps don’t go past this point.
continues to grow, you’ll find yourself extracting indexes into specialized storage. You’ll replace indexed queries (or queries that are difficult to index) with caches like Memcache, Redis, or maybe something custom.
point, your application will accrue more work than you’d really want to do during a transaction/request. That’s when you want to go slightly asynchronous, queue work up and process it out-of-process. Delayed Job is a great way to start, then move up to something like Resque or Rabbit MQ.
caches and queues, it’s important to start thinking about the observability of your data. Depending on how you read and write data, you can get confusing results depending on timing. The good news is, lots of distributed databases are explicit about this, so it’s easy to read about. The bad news is, it’s a bit of brain-bender.
your second database, you need a gem to connect to it. This is usually a pretty simple task; there’s usually a widely preferred library for your database. The main caveat is if you’re not on MRI or you’re trying to go non-blocking; in this case, you’ll want to take more care to in selecting a library.
up inventing a configuration file for it. Mostly I see people doing something like `database.yml`, but plain-old-Ruby works great too. Make sure you make it easy to configure different environments. Don’t worry about avoiding global references to connections, it hasn’t seemed to hurt us on Gowalla.
time to use it in application code. We’ve been using direct access from a global variable in Gowalla and it hasn’t bit us. I’d like to see us adopt something like redis-objects, toystore, etc. to do domain modeling against our uses of Memcached, Redis, etc. but it’s definitely not something that is holding us back.
using your new database it’s time to deploy. Get your ops person to set up the database, figure out exactly which steps you need to roll the new code out in production, and then go for it.
while, it will end up that you need to rejigger how your data is stored. Absent migrations ala AR, you’ve got a couple options. One is read-repair, where you make your application code resilient to different versions of a data structure and only update it on writes. Another is to version the key you’re storing data with and increment the key version when you change the structure.
another level of tactics that’s really important as you’re mixing your persistence cocktail. It’s easy to develop anxiety as you get close to deploying your new database. There’s so much to go wrong, so much uncertainty. You need the tactics that allow you to overcome THE FEAR.
with extremely low stakes. New features, or features you’re not sure you always need work great. The important part is that it’s something with low risk. Low risk means you can push the envelope a bit, which is exactly what adding a new database involves.
training wheels in place, you need to know how things are working. You need numbers on how often things happen and how much time it takes when they do happen. Use Scout, RPM, or log inspection for this. You’ll also want to log things you’re unsure about. Log profusely, and get handy with grep, sed, and awk for digesting those logs.
to use your new database for critical features, you can ease into it with two techniques. Start off by writing data to your existing database _and_ the new one. Once you’ve got the new writes debugged and working, start doing reads from it but discarding the results. Debug, optimize, and remove the double write, only using the new system. Success!
doesn’t work out so well. In this case, you want the ability to turn features on and off willy-nilly. Feature toggles make this really easy. Branching in code isn’t the prettiest thing, but it’s a great safety net. The other great thing about toggles is you can roll out to more and more users, making it easy to ease a feature in, rather than hoping it works the first time.
course, is iteration. Depending on the scope of your project, it could be weeks or month before the new thing is the thing. Everyday, move the ball forward. Everyday, make it better. Everyday, figure out how to make the next step without shooting yourself in the foot. Everyday, deliver business value.
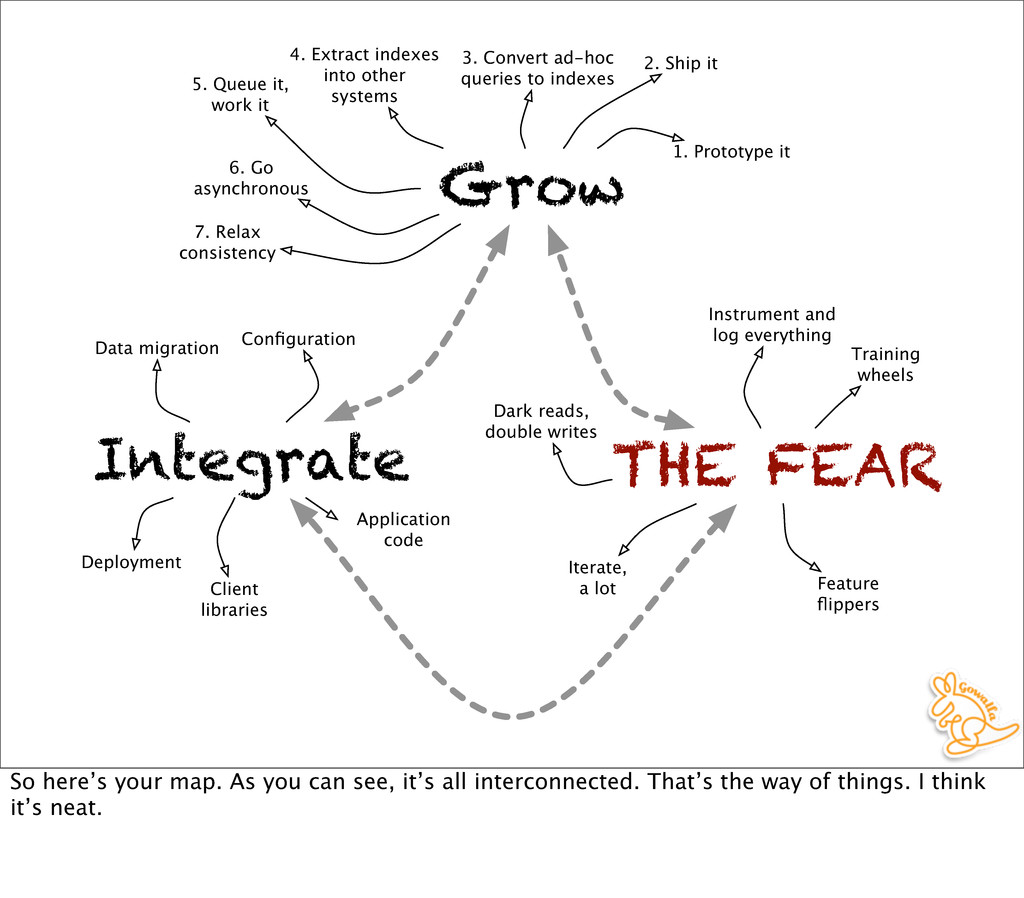
Iterate, a lot Instrument and log everything Integrate Configuration Deployment Client libraries Application code Data migration Grow 1. Prototype it 2. Ship it 3. Convert ad-hoc queries to indexes 5. Queue it, work it 4. Extract indexes into other systems 6. Go asynchronous 7. Relax consistency So here’s your map. As you can see, it’s all interconnected. That’s the way of things. I think it’s neat.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}