This was a talk given by Tim Williamson and Emil Eifrem at Strata + Hadoop World NYC on September 28, 2016:
http://conferences.oreilly.com/strata/hadoop-big-data-ny/public/schedule/detail/52052
Abstract
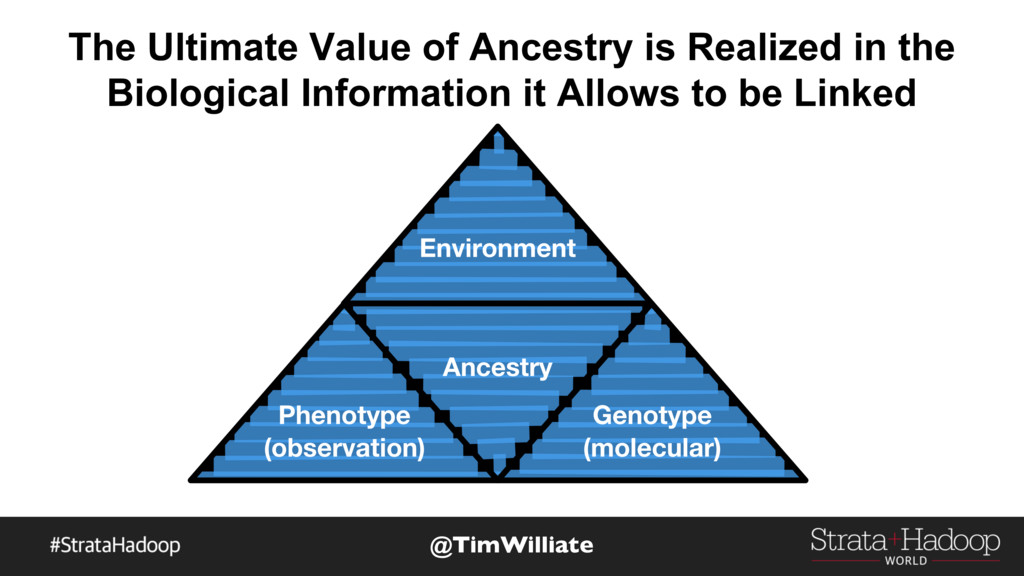
Enterprises that pursue data-driven operations and decisions are approaching the conclusion that graph analysis capabilities will yield critical competitive advantages. However, for this impact to be fully realized, the results of any graph analysis must be available, in real time, to operational applications, data scientists, and developers across the enterprise.
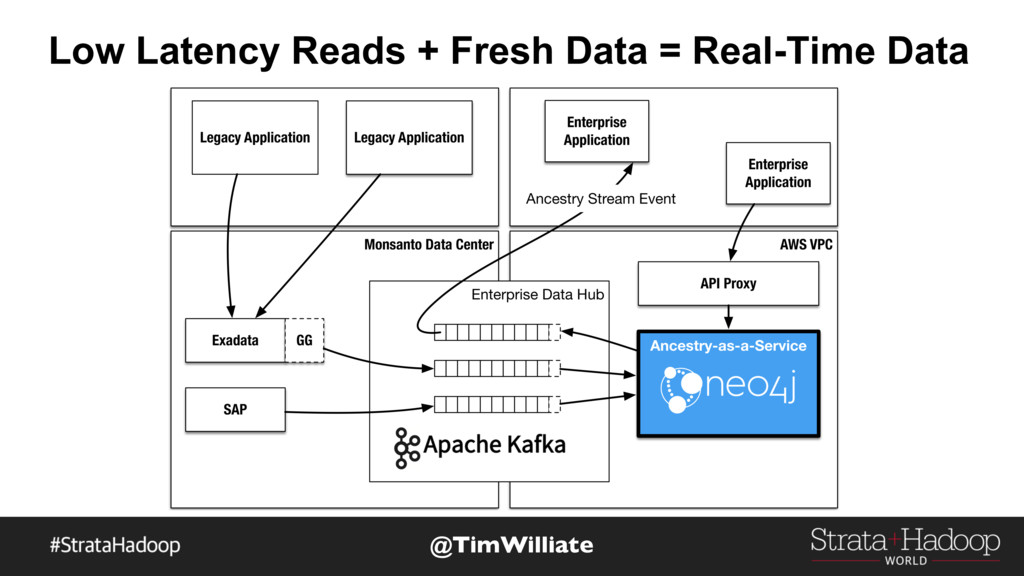
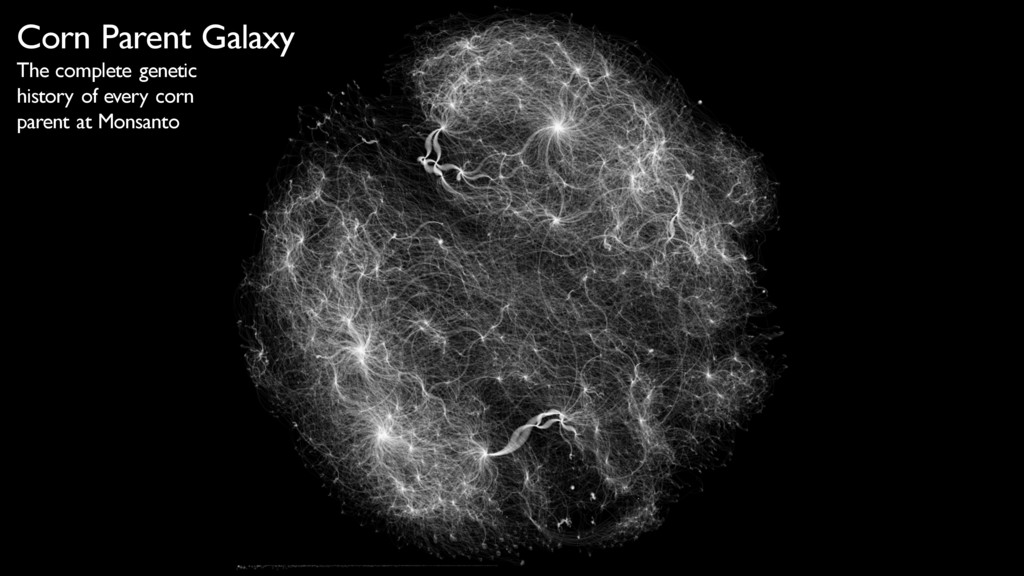
Monsanto previously attempted graph analysis using both RDBMS-based and offline batch processing techniques. In the process, Monsanto found that some couldn’t drill sufficiently deeply to result in the necessary insights; others were limited in their expressibility and therefore general usefulness outside of the data science lab; and still others weren’t able to provide answers in a short enough amount of time to be useful to the business. Monsanto finally selected a graph database used alongside a broader tech stack that includes Apache Kafka, Spark, and Oracle. This stack allows Monsanto to not just derive but also operationalize insights that have allowed it to shorten R&D cycles, better understand the dynamics of its business, and carry out certain of types of science in silico.
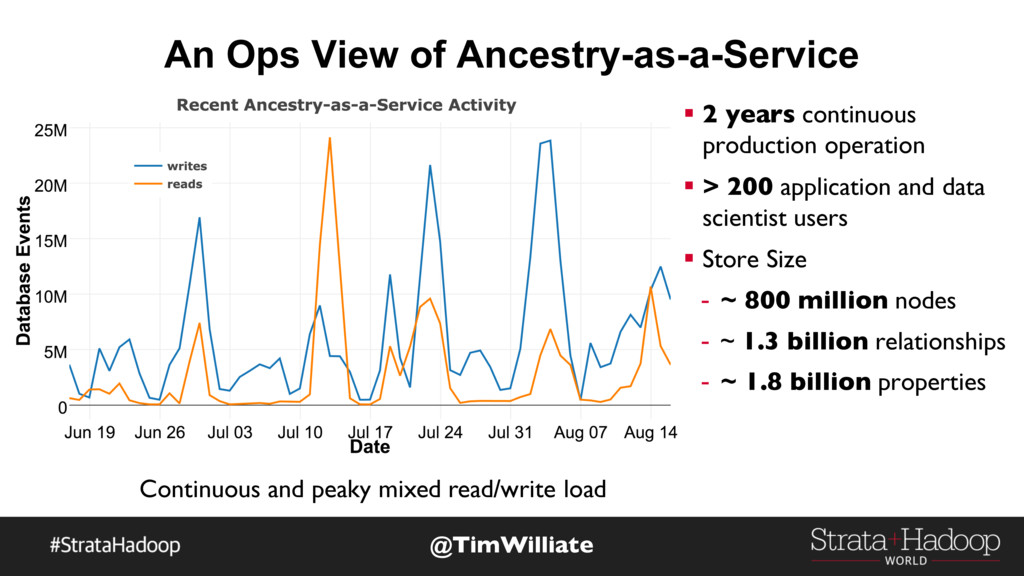
Tim Williamson and Emil Eifrem draw on Monsanto’s real-world experience to explain how organizations can use graph databases to operationalize insights from big data. Tim and Emil discuss Monsanto’s big data stack, using examples from Monsanto’s substantial experience with graphs, and describe the service-oriented graph architecture that has already handled over one billion requests and is available to over 150 developers, data scientists, and applications throughout Monsanto.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}