Slides from a talk given at GraphConnect San Francisco, 21 October 2015
http://graphconnect.com/speaker/tim-williamson/
Video of this talk can be found on YouTube:
https://youtu.be/6KEvLURBenM
Abstract:
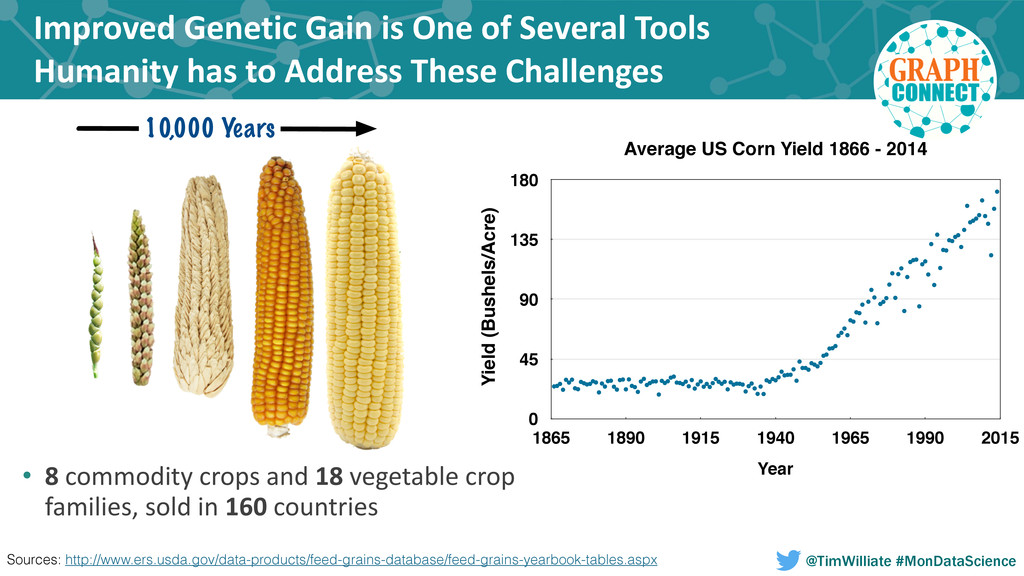
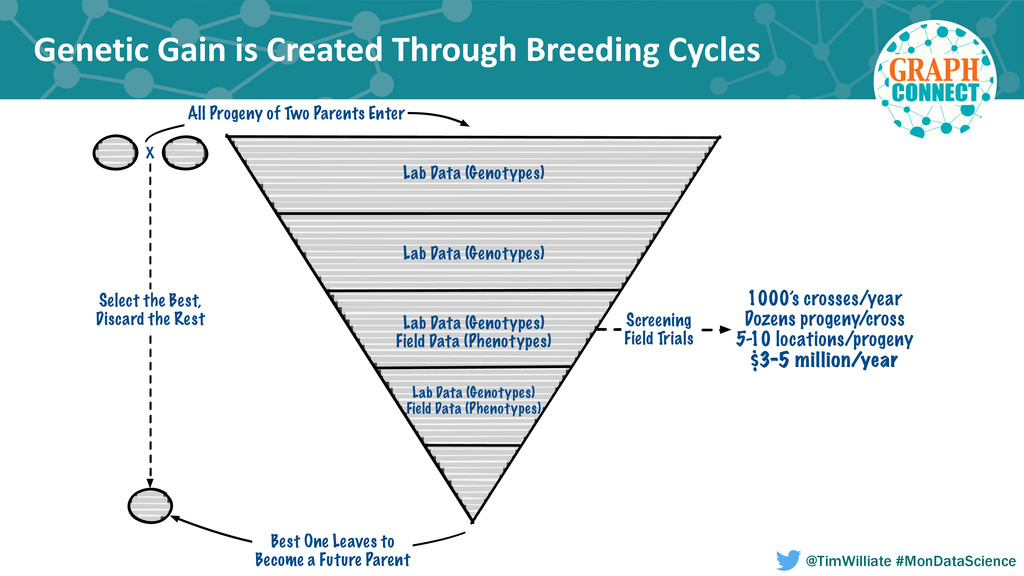
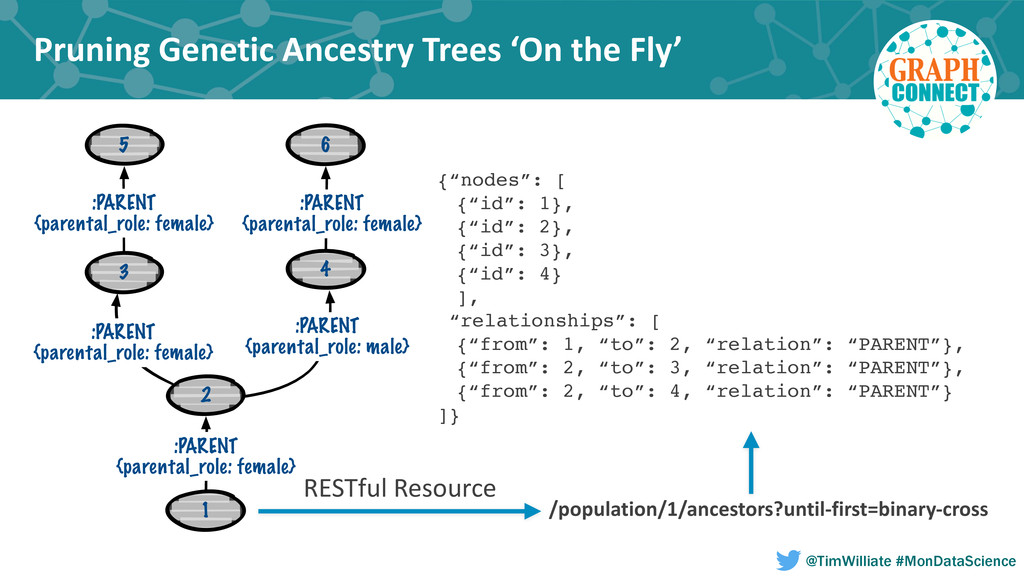
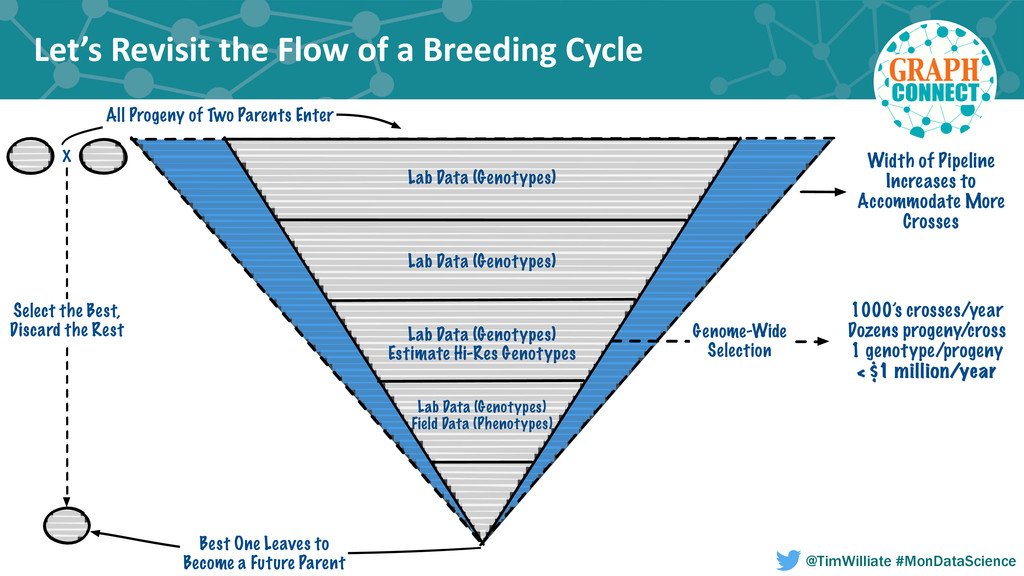
Modern agriculture has seen only four major transformations in the last century that started with the hybridization of crops including corn and the development of biotech traits; both of which dramatically improved farm productivity and profitability. More recently the application of molecular techniques to crop development combined with a nondestructive seed sampling process called seed chipping have increased the rate of yield gain in new hybrids and varieties of row crops such as corn, soybeans and cotton. The agricultural industry is currently in the midst of an information revolution that will enable farmers globally to meet the growing need for food, fuel and fiber as the world population climbs to 10 billion and a greater fraction shifts to an animal based diet. This information revolution requires the near real-time integration of multiple disparate data sources including ancestry, genomic, market and grower data. Each one of these data sources spans one or more decades and are complex in and of themselves. An example is the movement of seeds through the product development pipeline, beginning at the earliest recorded discovery breeding cross, and ending with the most recent commercialized products. Historically the constraints of modeling and processing this data within a relational database has made drawing inferences from this dataset complex and computationally infeasible at the scale required for modern analytics uses such as prescriptive breeding and genome-wide selection.
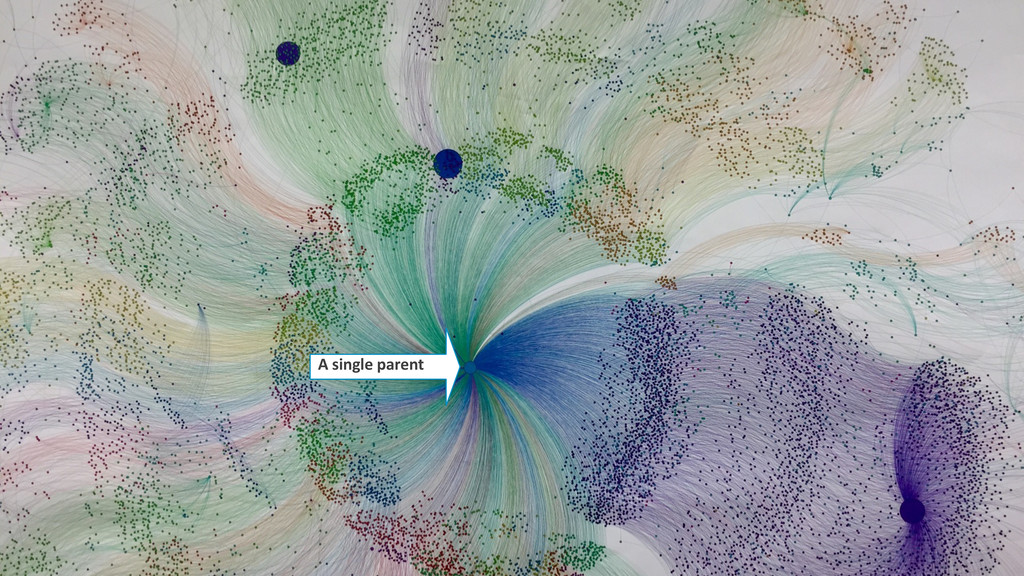
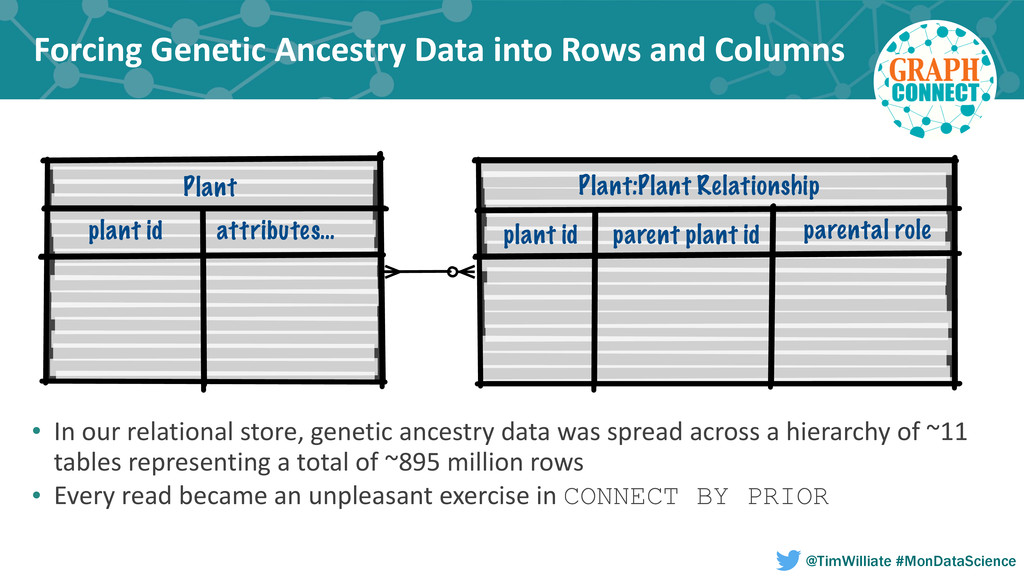
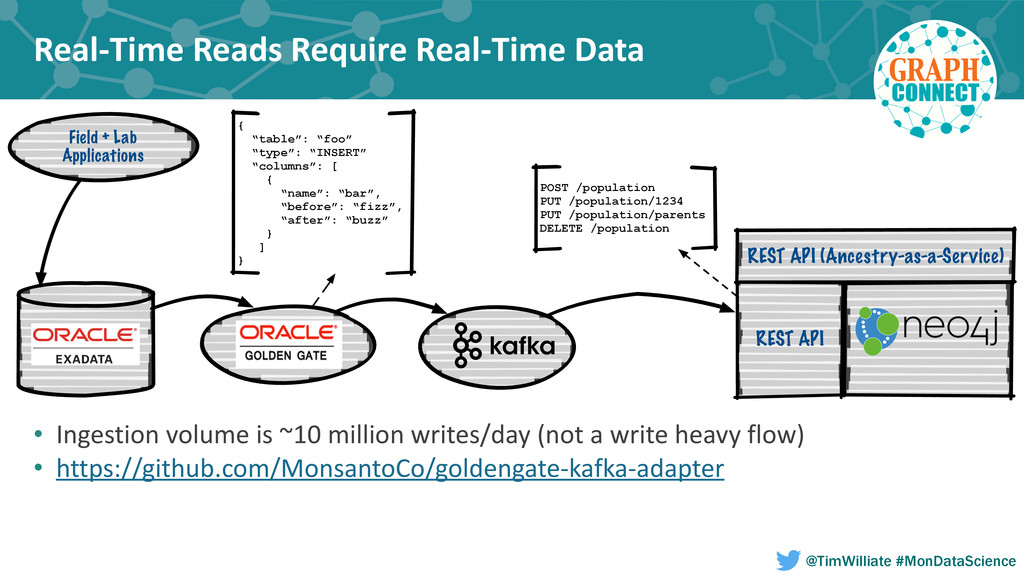
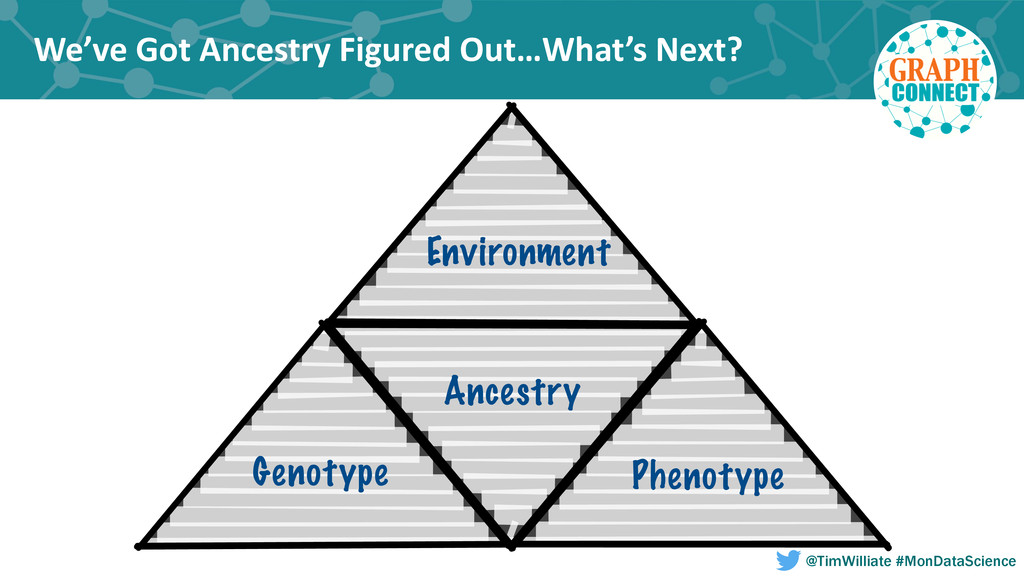
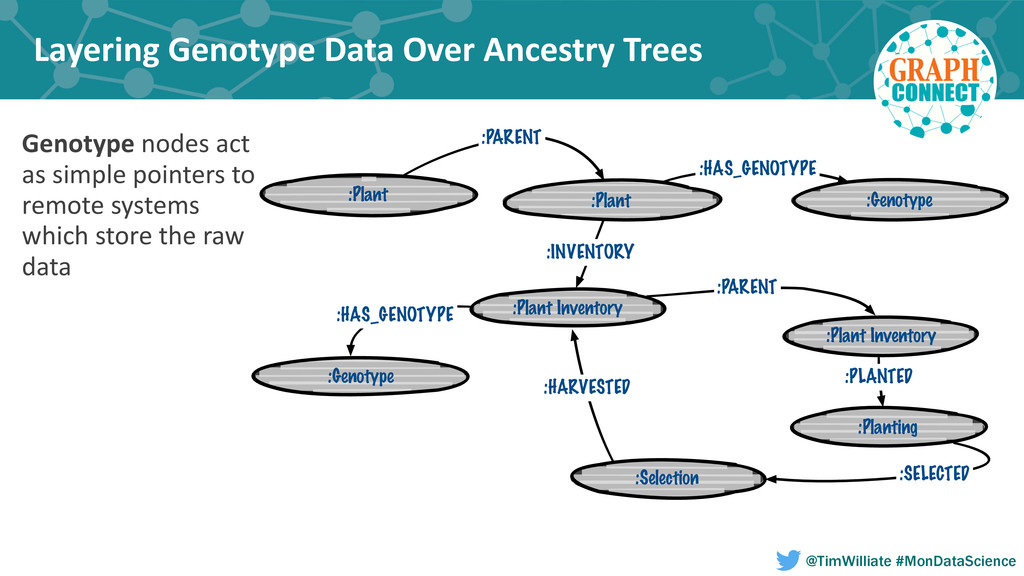
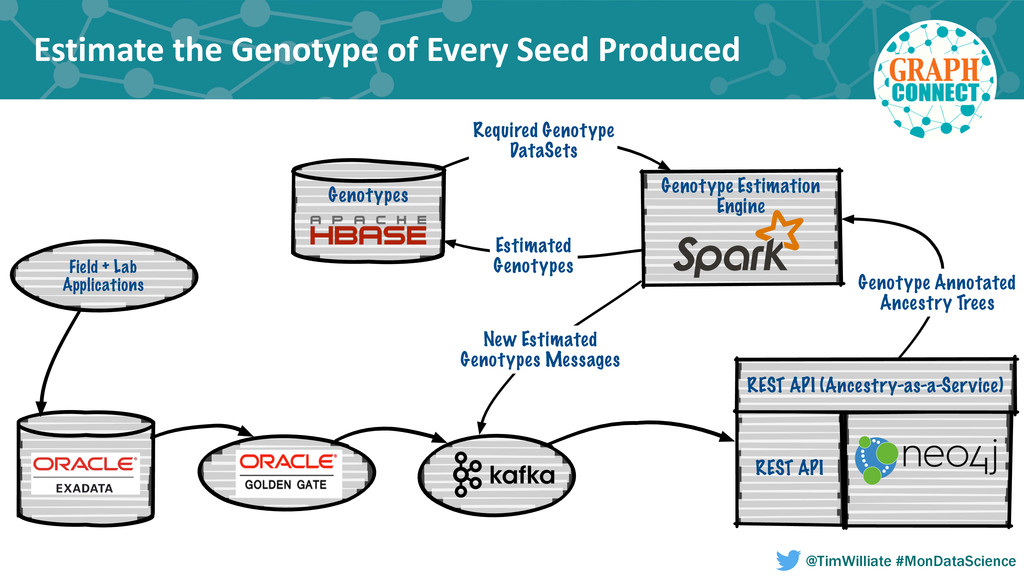
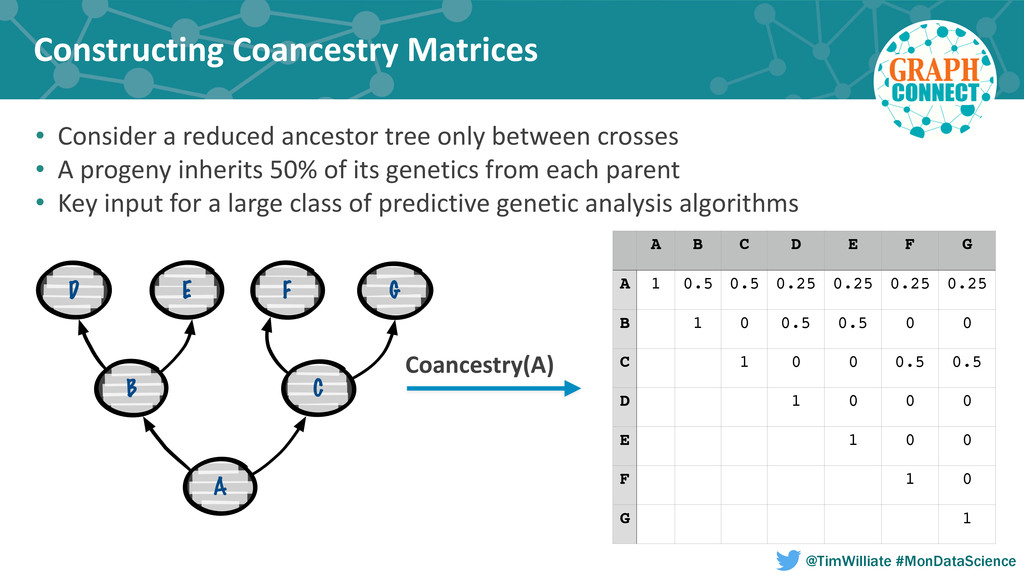
In this talk we present how we leveraged a polyglot environment, with a graph database implemented in Neo4j at the core, to enable this shift in agricultural product development. We will share examples of how the transformation of our genetic ancestry dataset into a graph has replaced months of computational effort. Our approach to polyglot persistence will be discussed via our use of a distributed commit log, Apache Kafka, to feed our graph store from sources of live transactional data. Finally, we will touch upon how we are using these technologies to annotate our genetic ancestry dataset with molecular genomics data in order to build a computational platform capable of imputing the genotype of every seed produced during new product development.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}