CD で設定を配布するような場合は特に注意 ▶ 設定のリロードを使っていると、次の再起動時で失敗 5 level=error error loading config from \"/etc/prometheus/config/ prometheus.yml\": one or more errors occurred while applying the new configuration (--config.file=\"/etc/prometheus/config/prometheus.yml\")"
![Prometheus Meetup Tokyo Takashi Kusumi <[email protected]> Unit Testing for Prometheus](https://files.speakerdeck.com/presentations/2eb55c5b309a43aaa215d04df6e2ff79/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
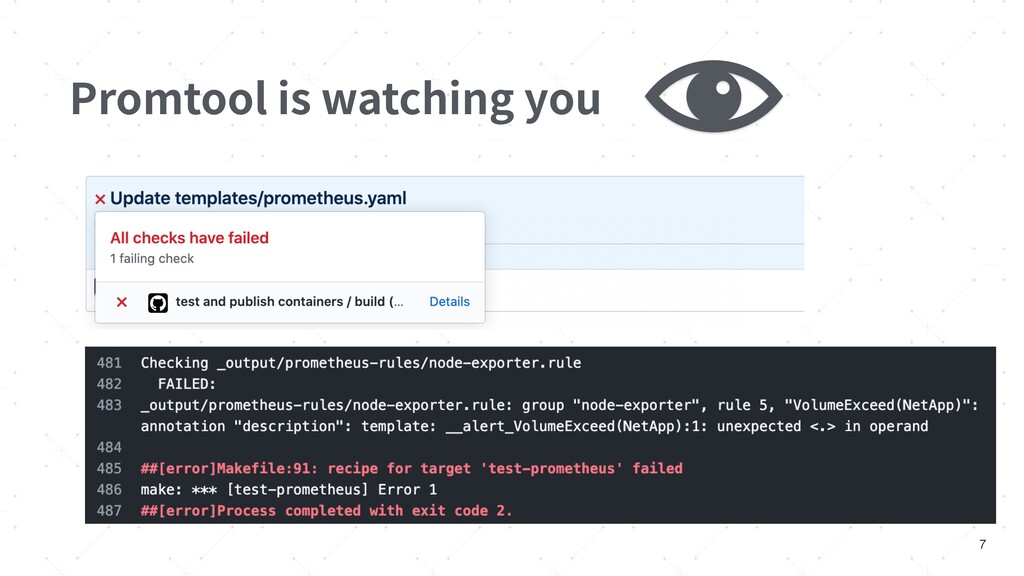{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
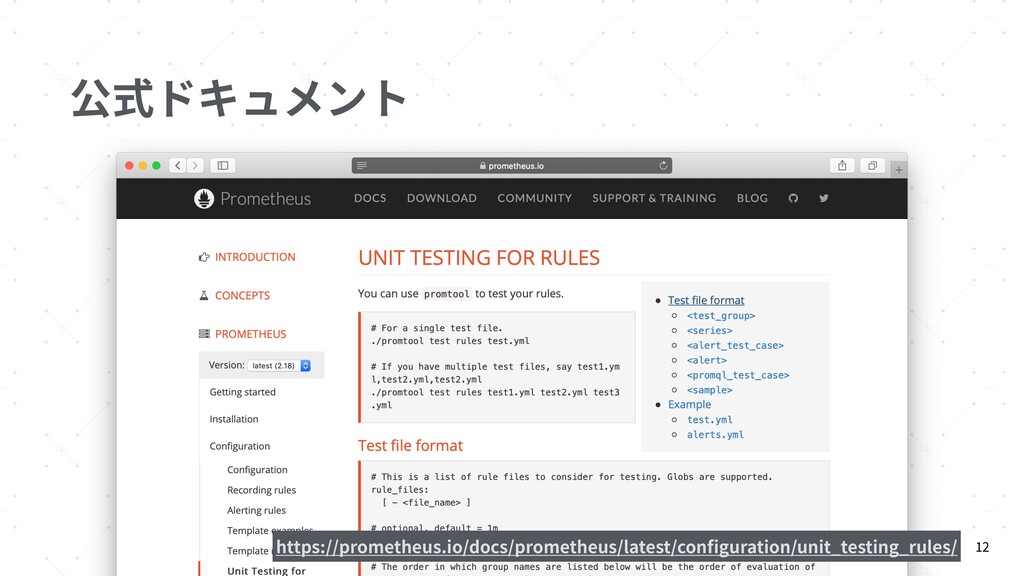{kind=link}
{kind=link}
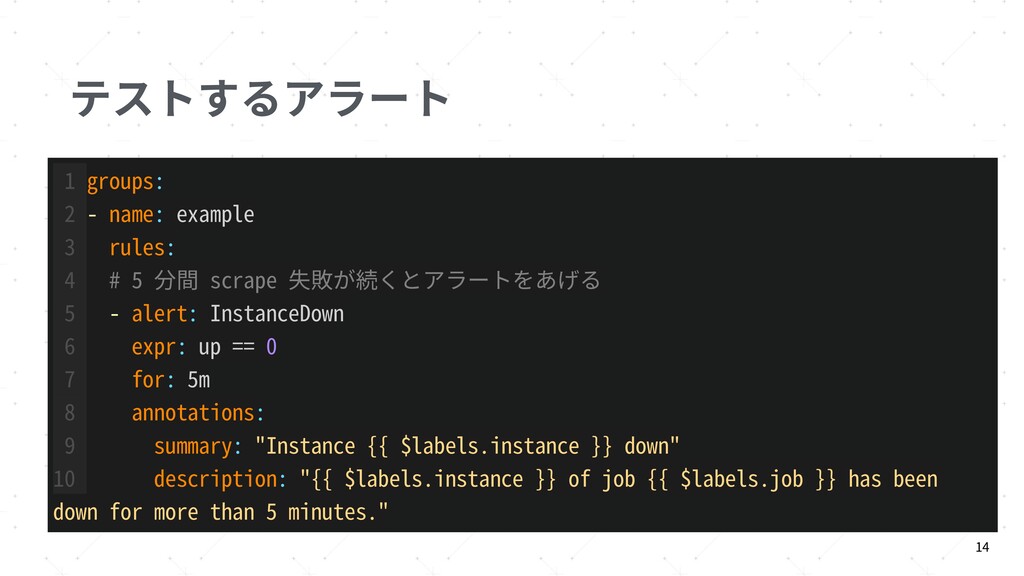{kind=link}
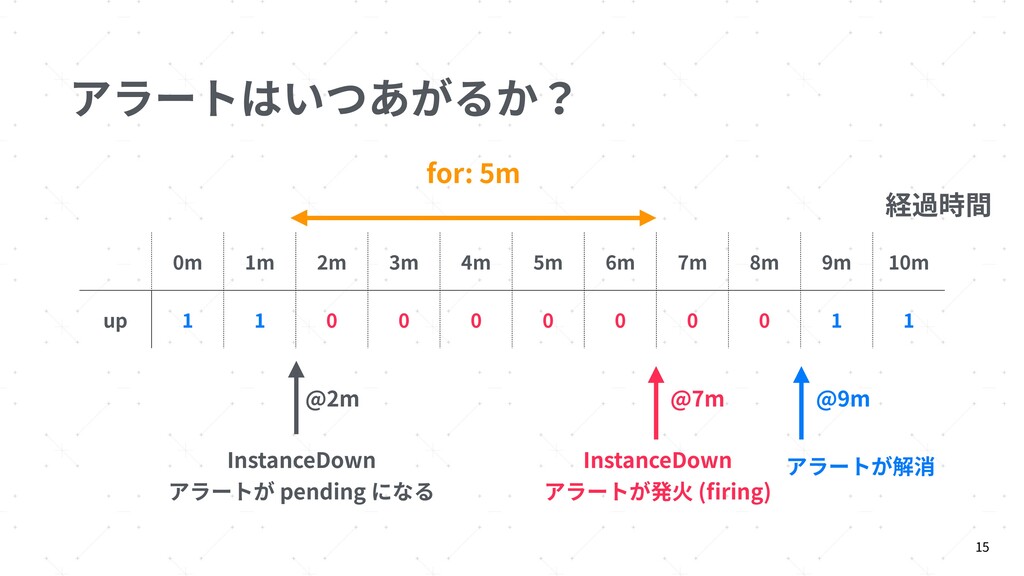{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
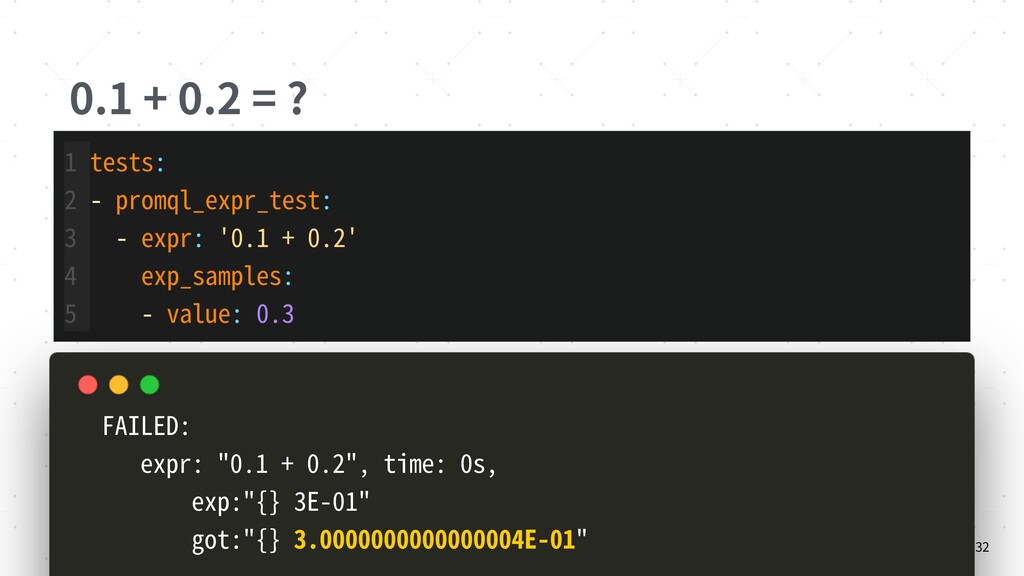{kind=link}
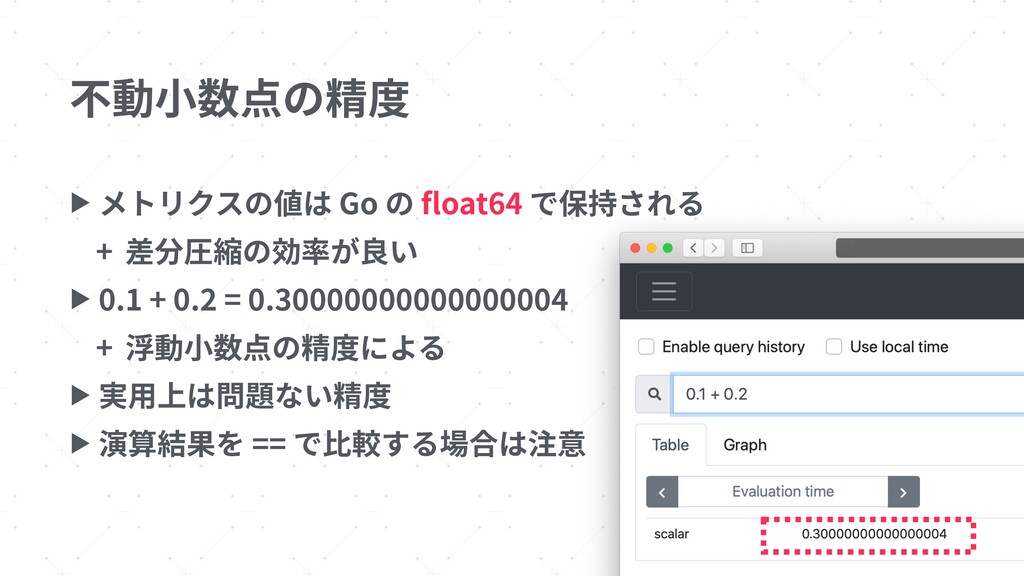{kind=link}
{kind=link}
{kind=link}
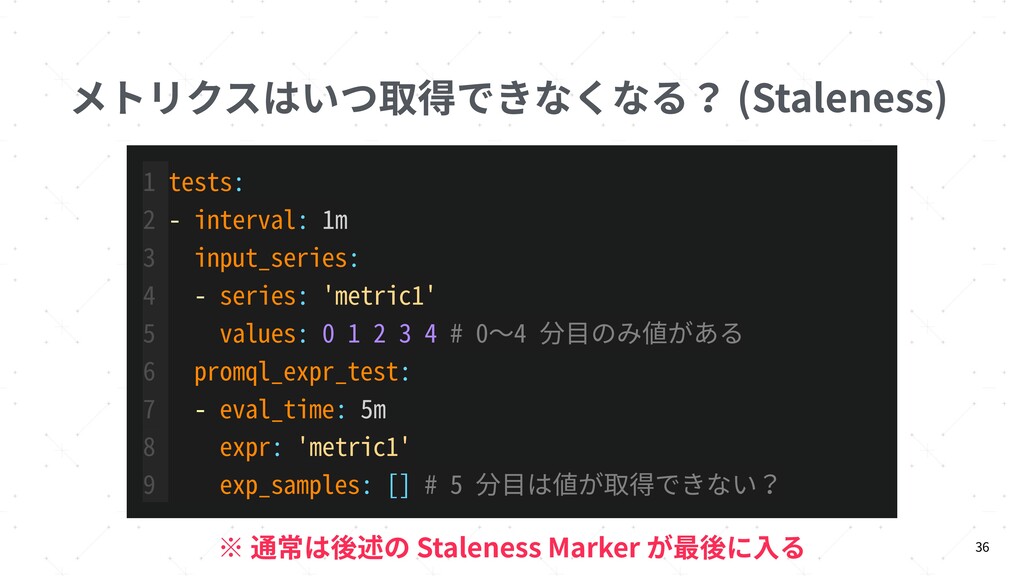{kind=link}
{kind=link}
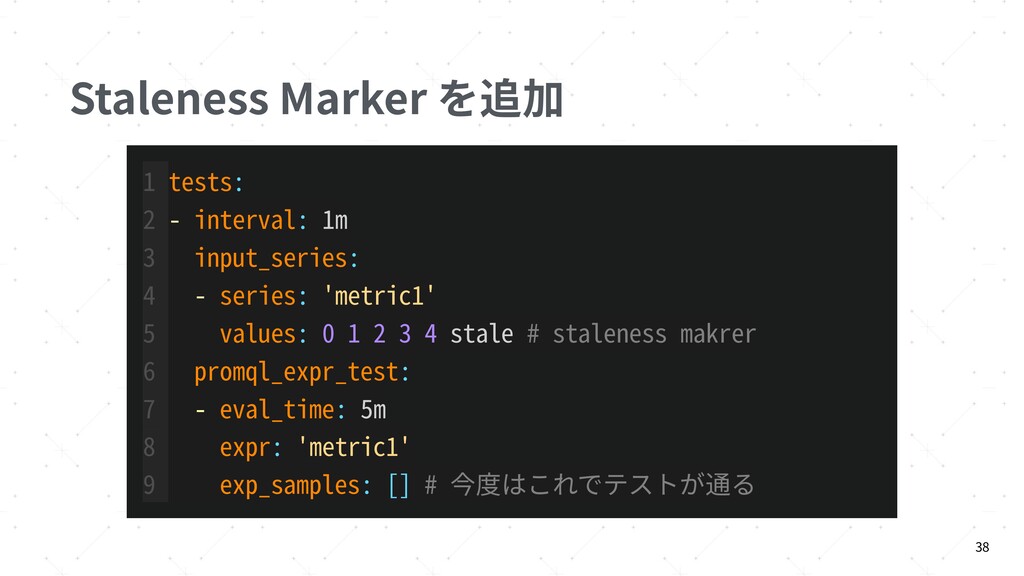{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}