Presented at the 5th NIRICT Workshop on GPU Computing Research in the Netherlands
http://fmttools.ewi.utwente.nl/NIRICT_GPGPU/events.html
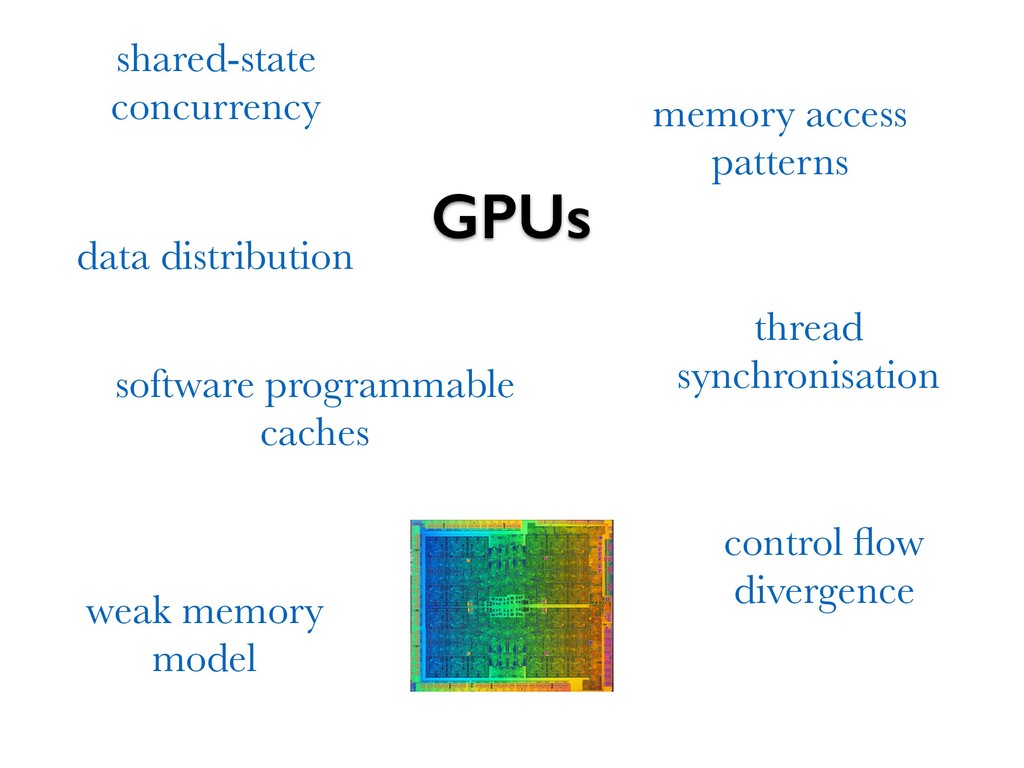
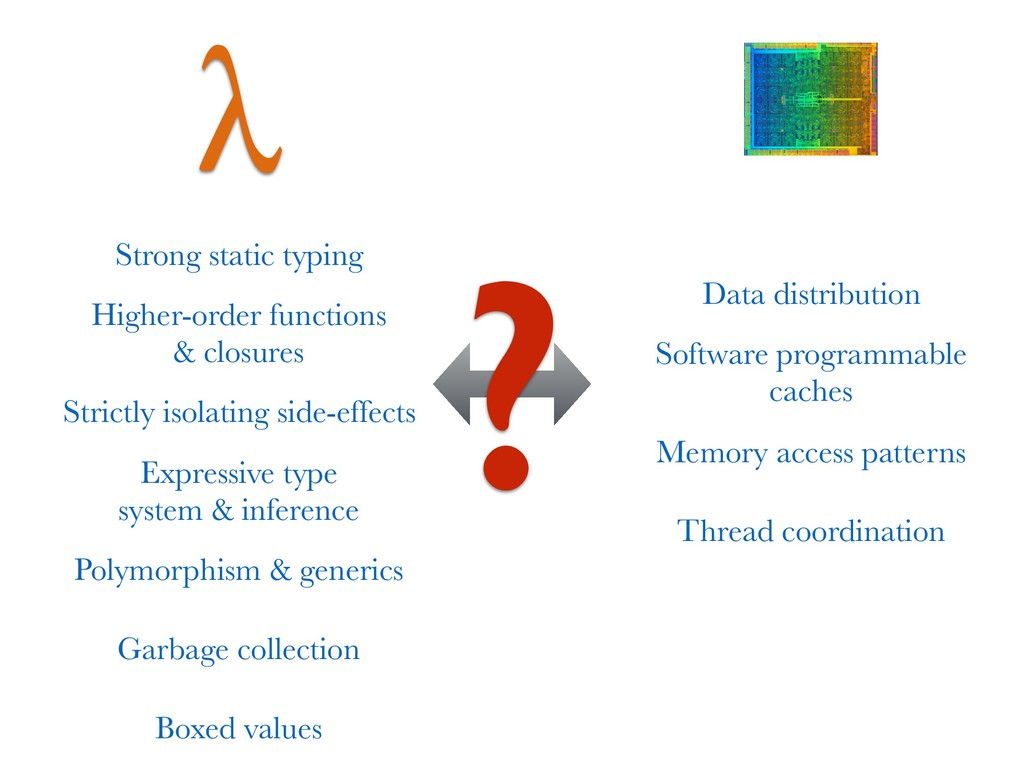
Graphics processing units (GPUs), while primarily designed to support the efficient rendering of computer graphics, are increasingly finding their highly-parallel architectures being used to tackle demanding computational problems in many non-graphics domains. However, GPU applications typically need to be programmed at a very low level, and their specialised hardware requires expert knowledge in order to be used effectively. These barriers make it difficult for domain scientists to leverage GPUs in their applications, without first becoming GPU programming experts.
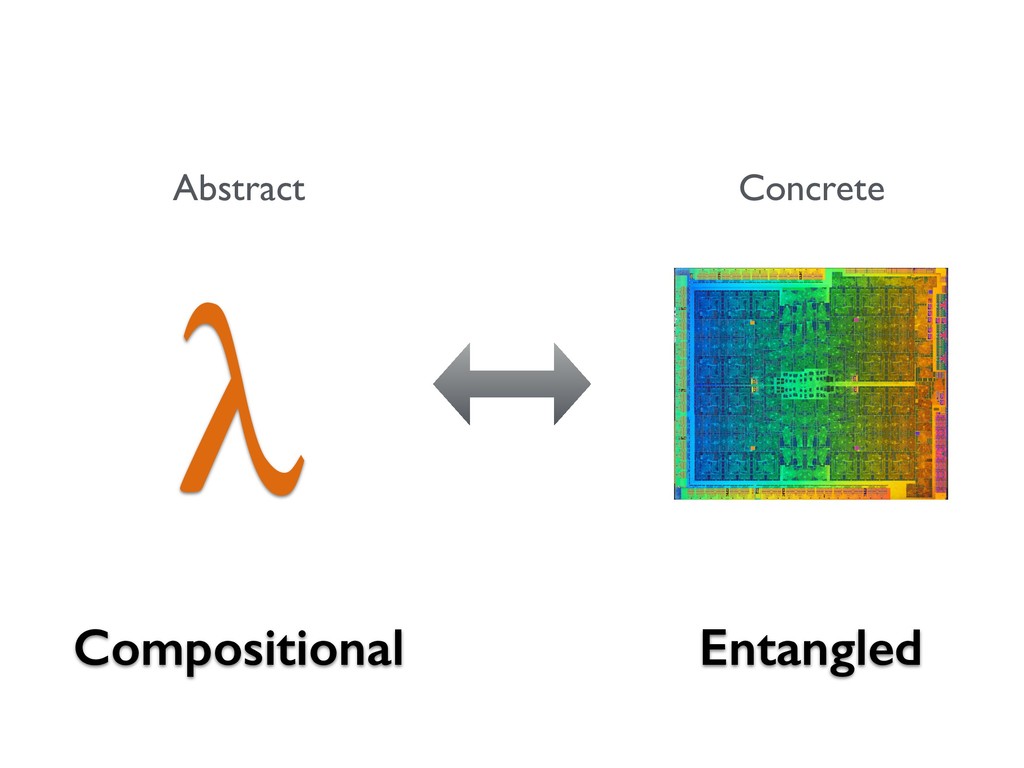
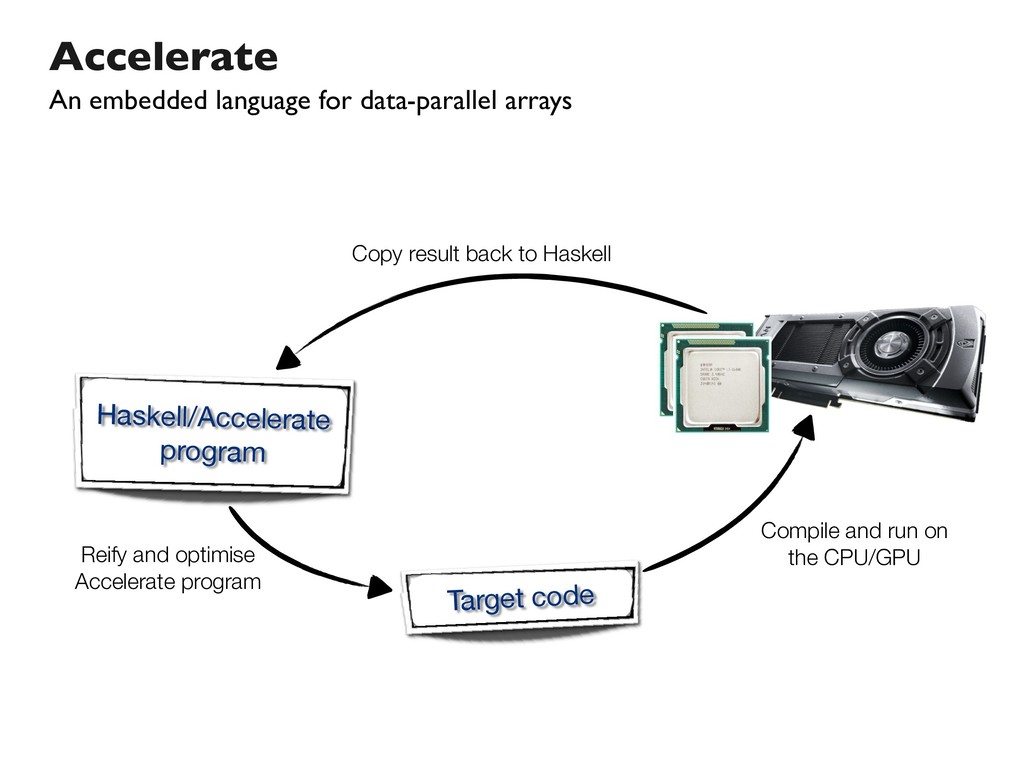
This talk discusses our work on the programming language _Accelerate_, in which computations are expressed in a high-level functional style, but compile down to efficient low-level GPU code. While high-level programming abstractions are typically viewed as creating barriers to high performance code, if used correctly we can instead leverage these abstractions to guide the user towards efficient parallel implementations of their programs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
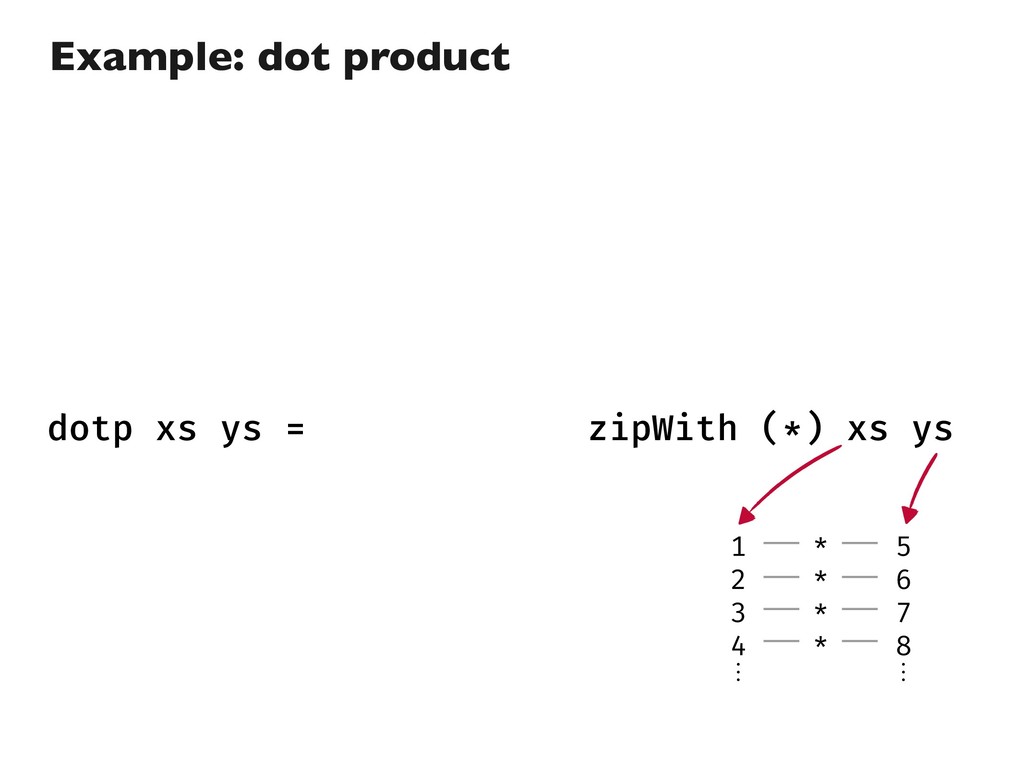
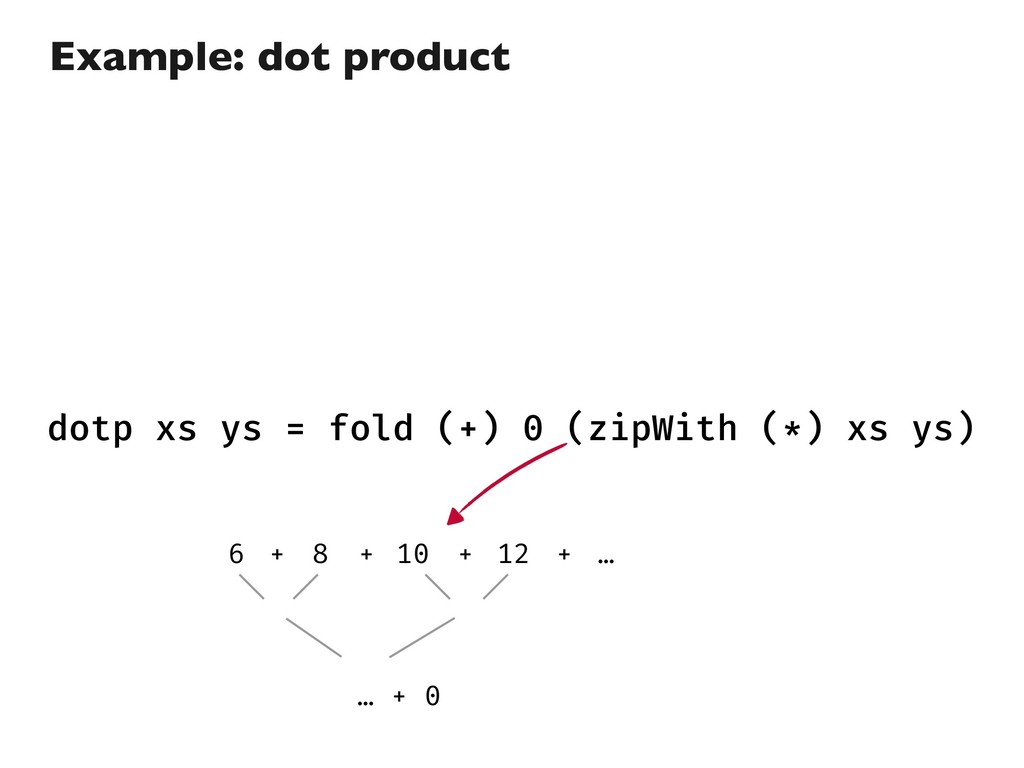
![import Prelude dotp :: Num a => [a] -> [a]](https://files.speakerdeck.com/presentations/533de42881cf4d5090a284efd3fd493b/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
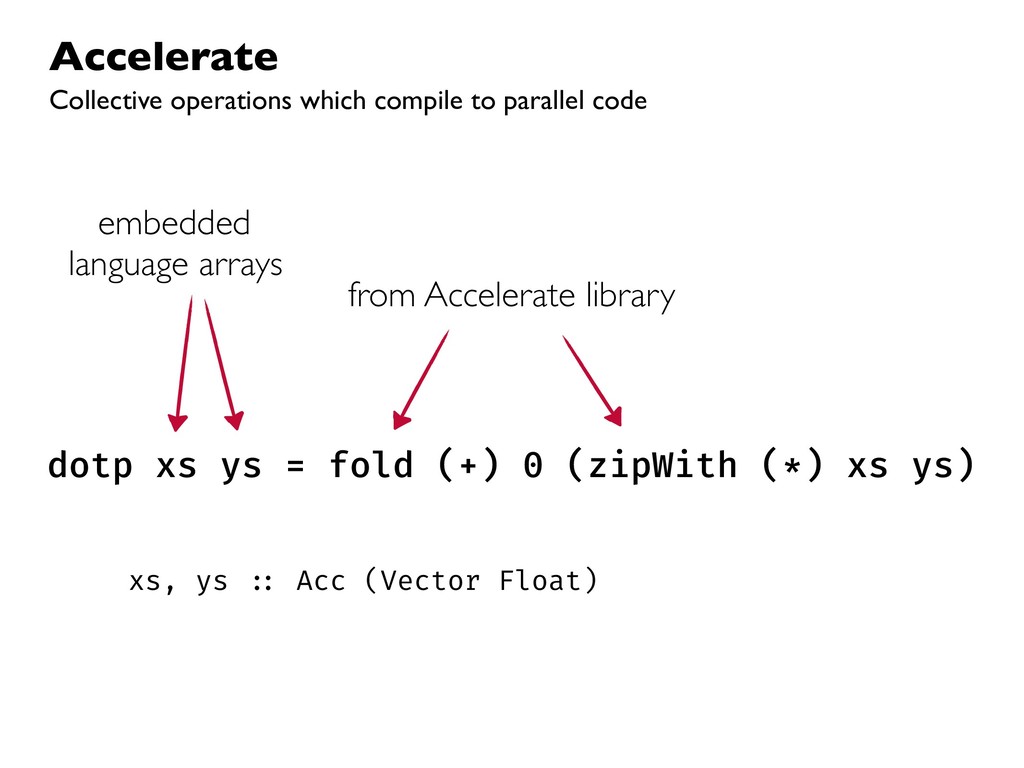{kind=link}
{kind=link}
{kind=link}
{kind=link}
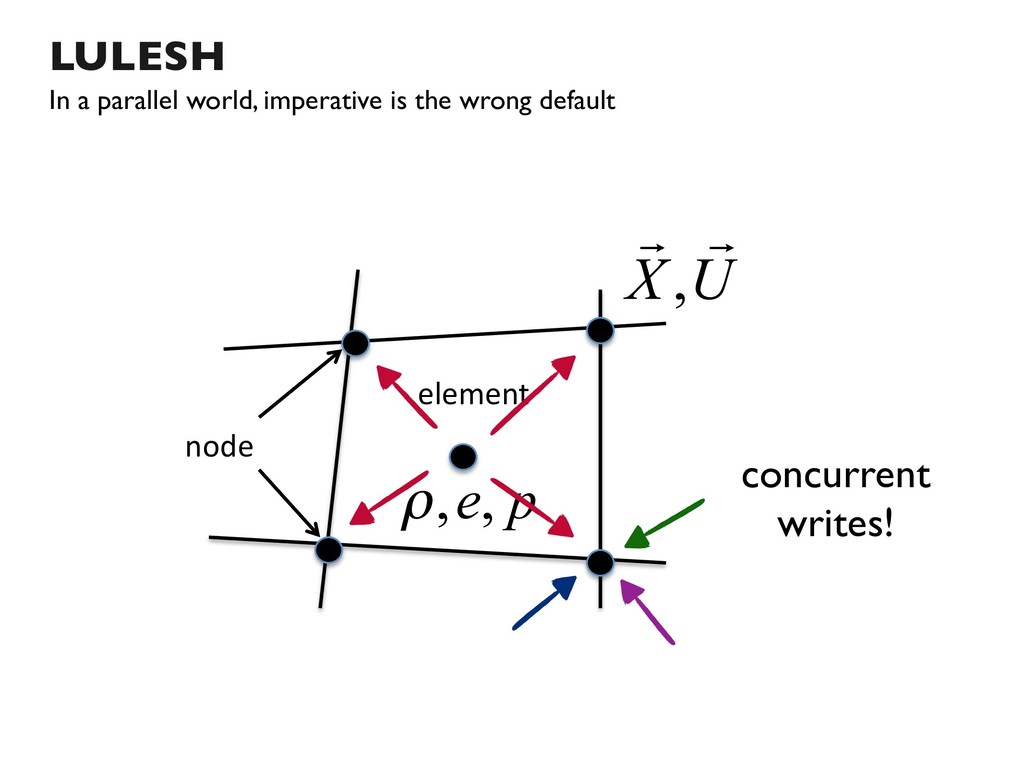{kind=link}
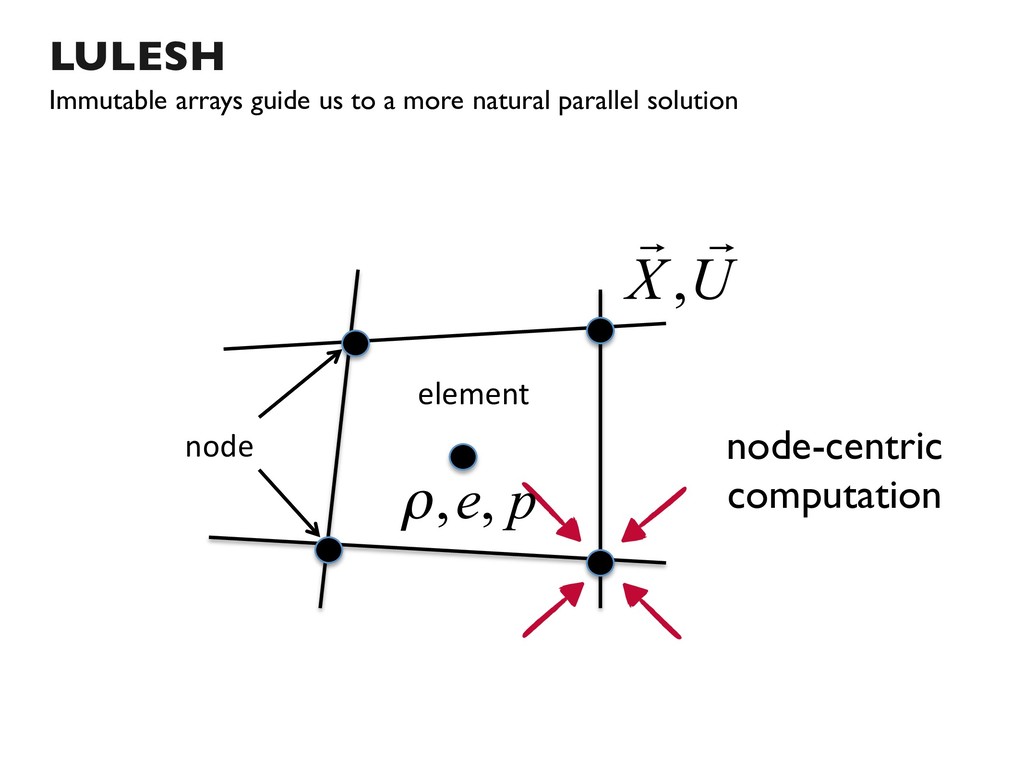{kind=link}
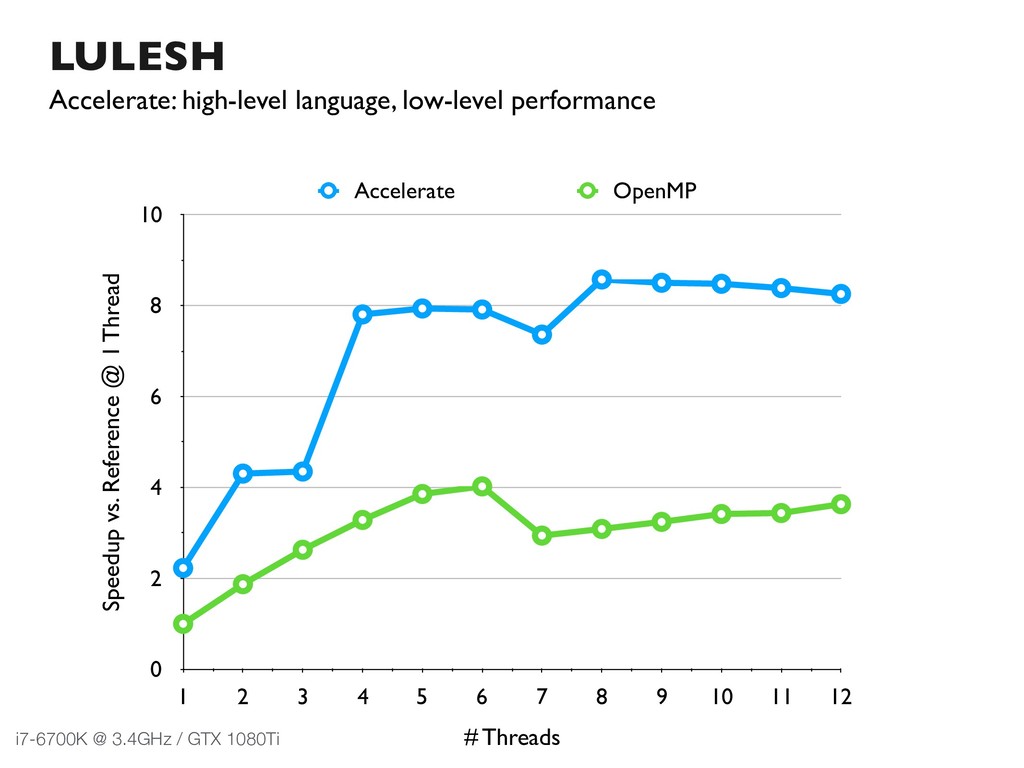{kind=link}
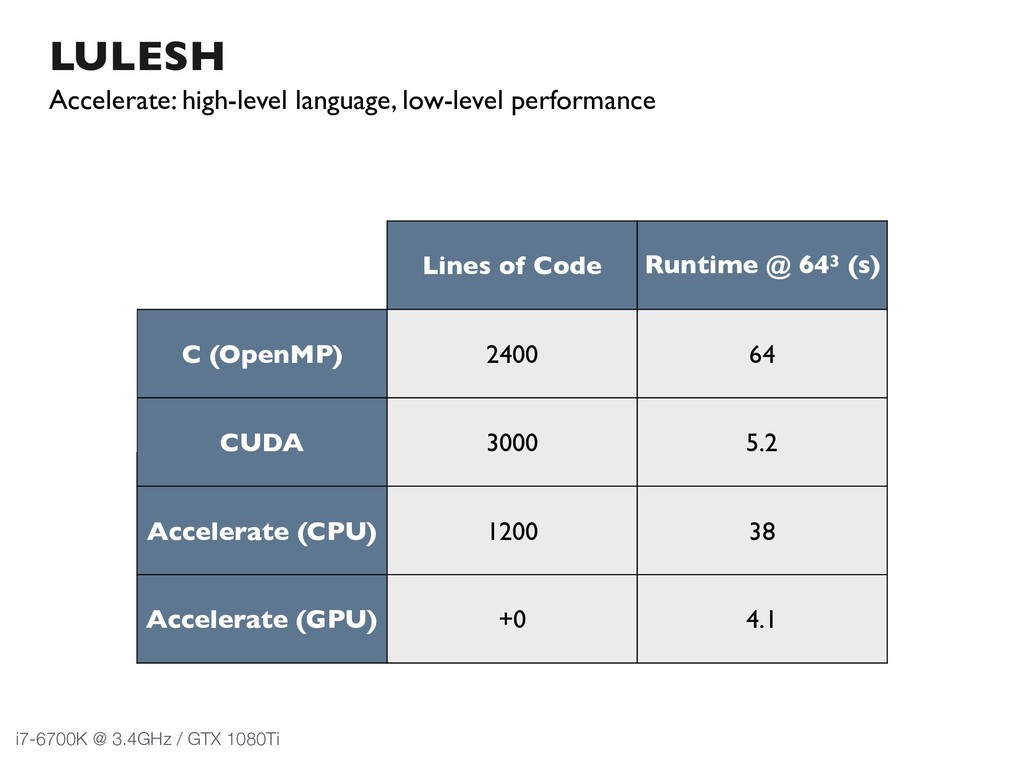{kind=link}
{kind=link}
{kind=link}
{kind=link}