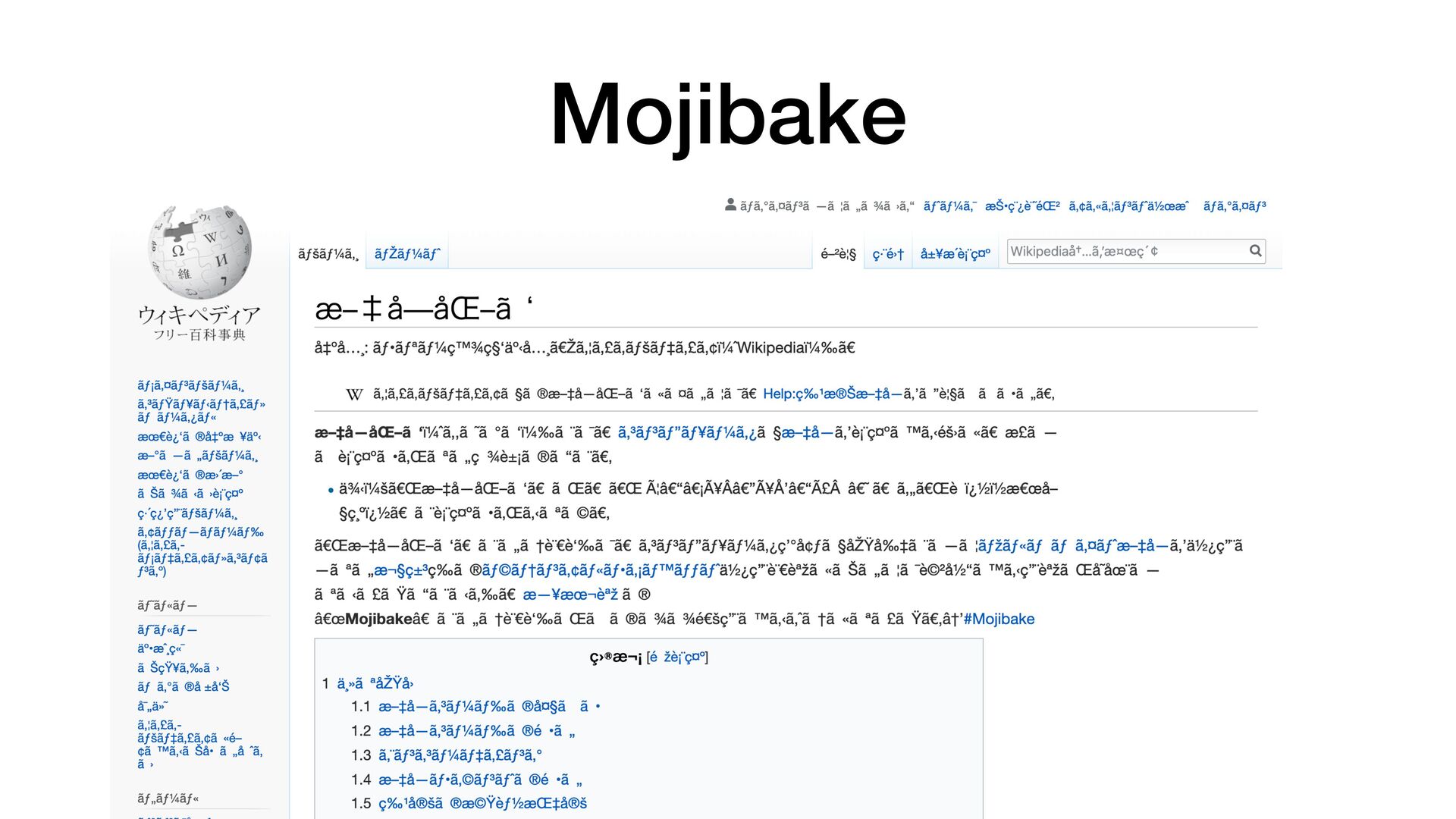
können nur Zahlen • Strom/Kein Strom. Computer arbeiten mit 0 und 1 (noch) • 👉 Alles in einem Computer ist eine Binärfolge • 👉 Computer können kein Text. Text ist für uns
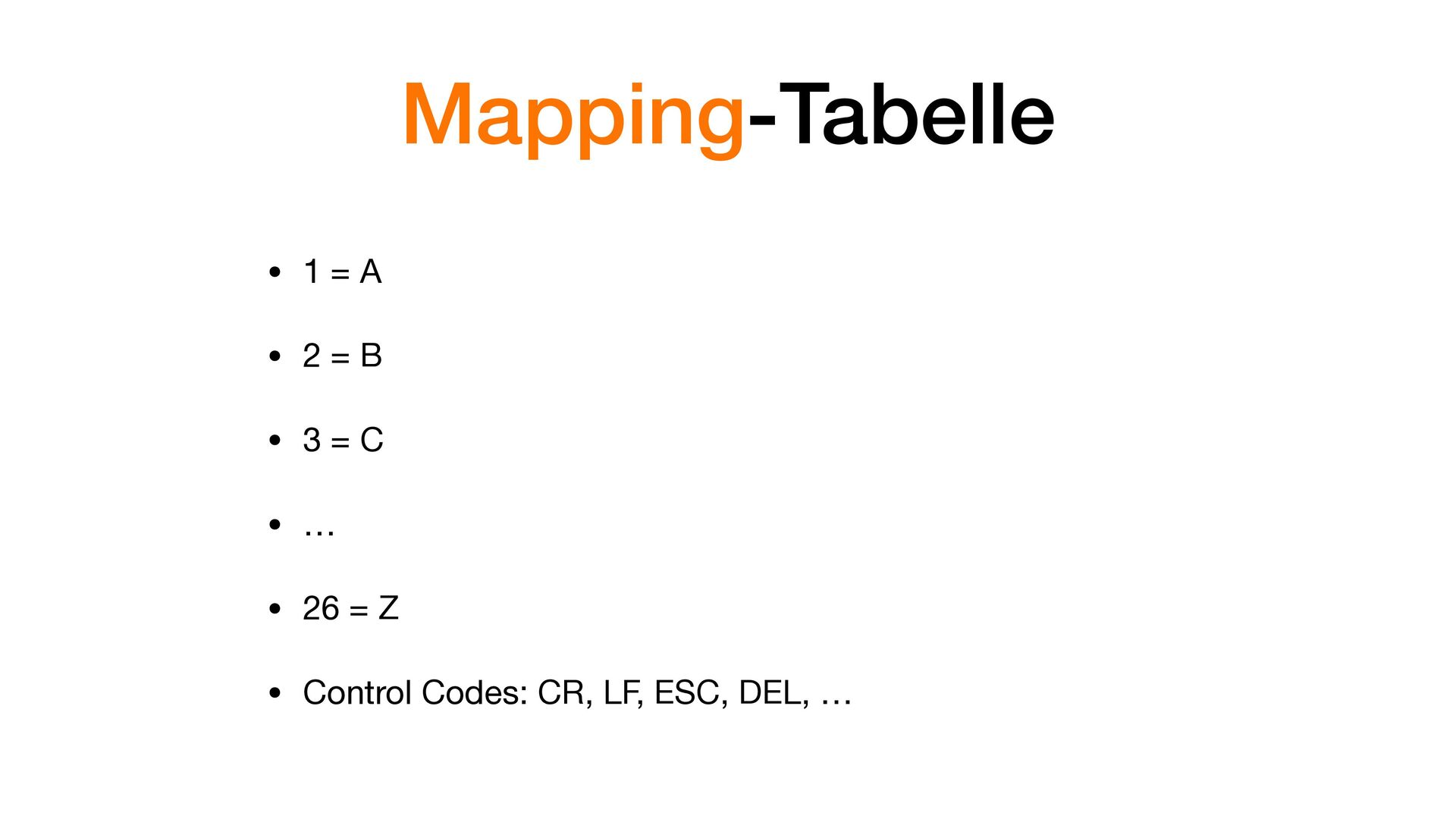
Nichts anderes als eine grosse Mapping-Tabelle • Klärt die Frage: «Wie übersetze ich ein Zeichen in Binärcode für den Computer?» • «Übersetzen» ➡ «encodieren» • «Zurückübersetzen» ➡ «decodieren»
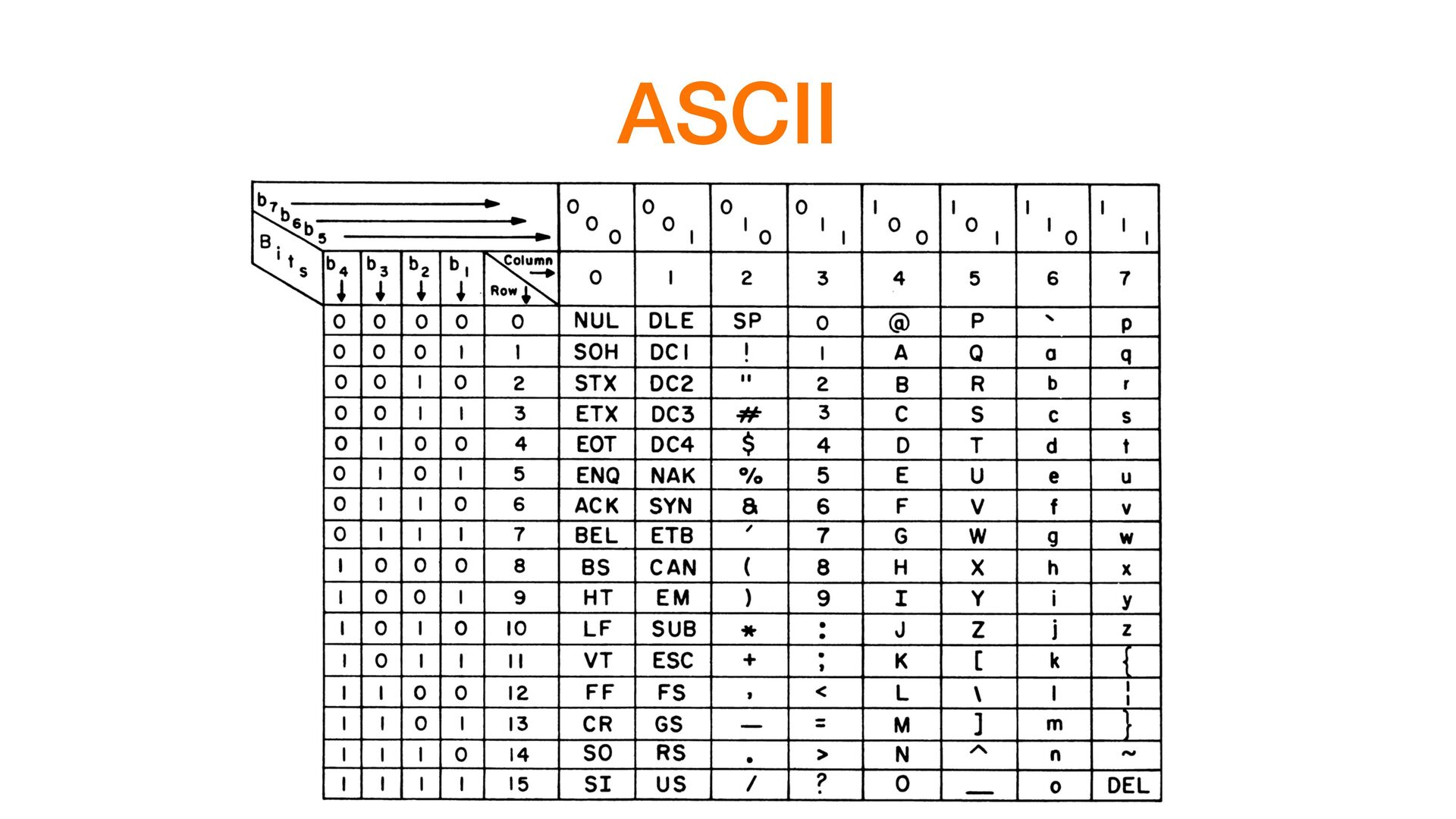
«Mapping-Tabelle» von 128 Zeichen • Jedes Zeichen wird mit 1 Byte encodiert (7 Bit reichen) • Gross- zu Kleinschreibung ist 1 Bit-Shift • C = 67 = 0100 0011 • c = 99 = 0110 0011
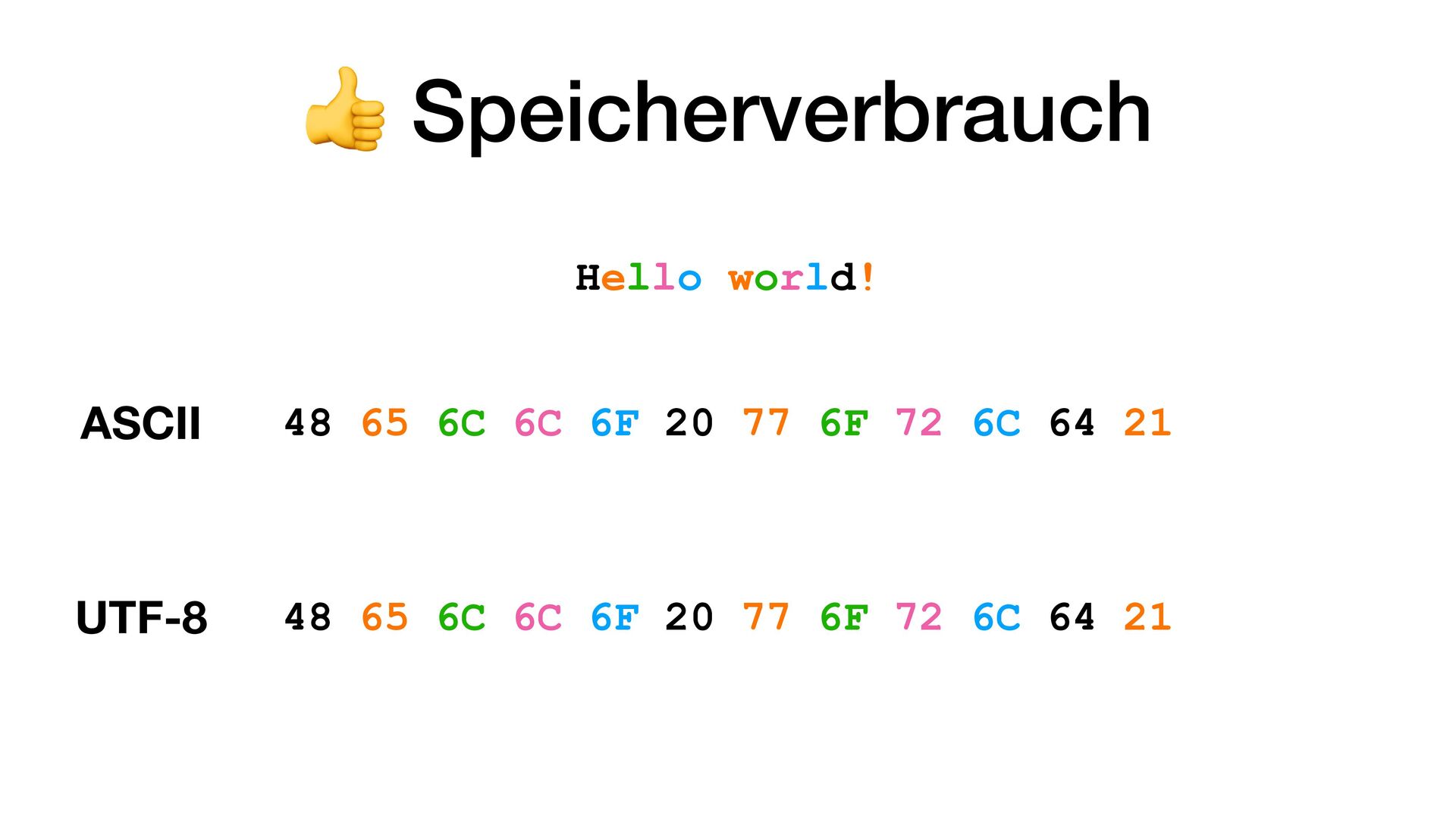
• ISO 8859-5: Kyrillisches Alphabet • ISO 8859-7: Griechische Schrift • Windows-1252: Erweiterung von ISO 8859-1 mit weiteren Zeichen • EBCDIC (Extended Binary Coded Decimal Interchange Code) • Shift JIS (Shift Japanese Industrial Standard) • UTF-8, UTF-16, UTF-32
ja noch Platz für zusätzliche Zeichen in einem Byte.» • Erste 128 Zeichen identisch mit ASCII • Natürliche Evolution von ASCII • Vor allem westeuropäische Sprachen: ä, ö, ü, ß, ñ, ¿, ¡, é, ê, ó, ø, …
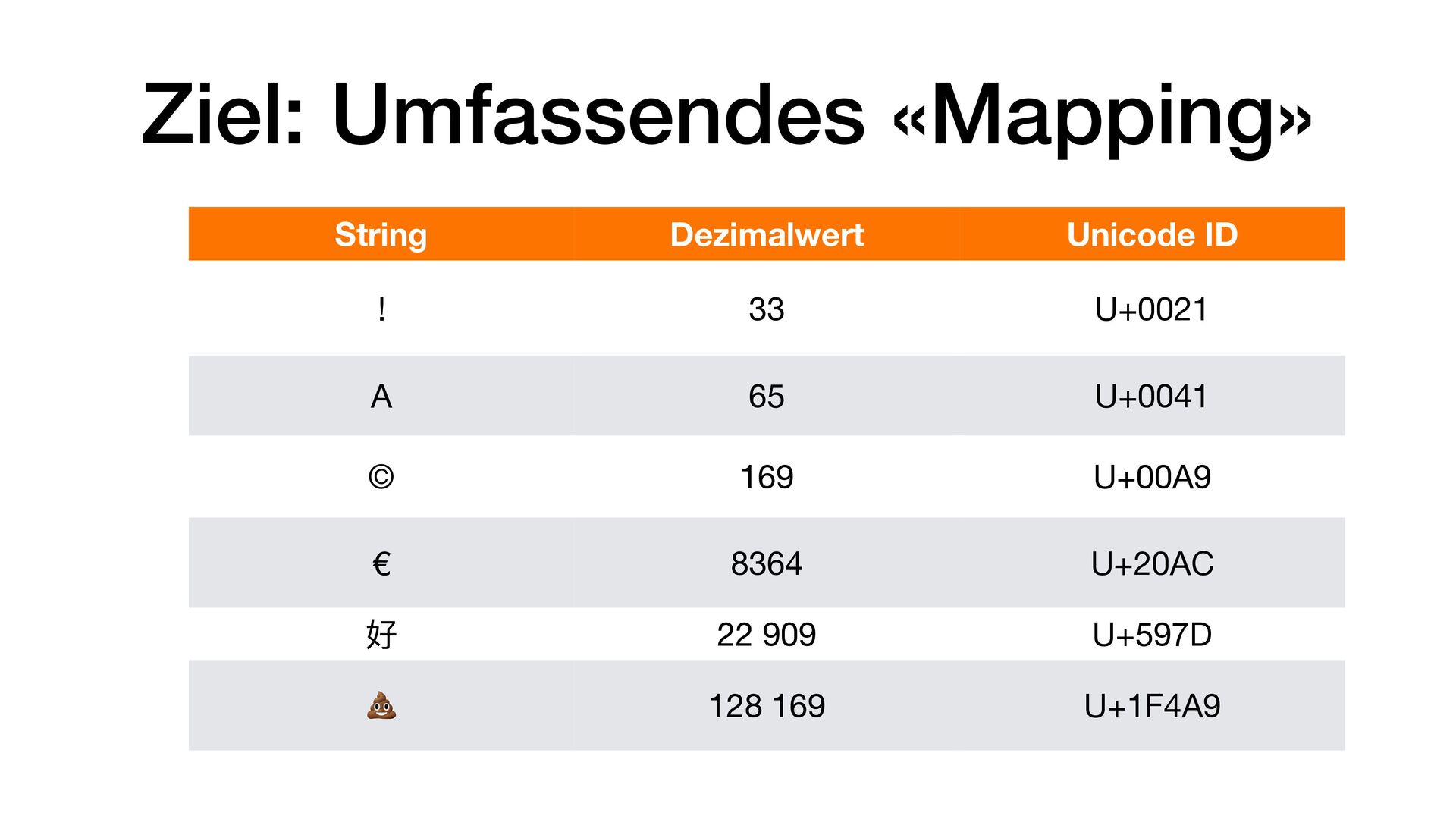
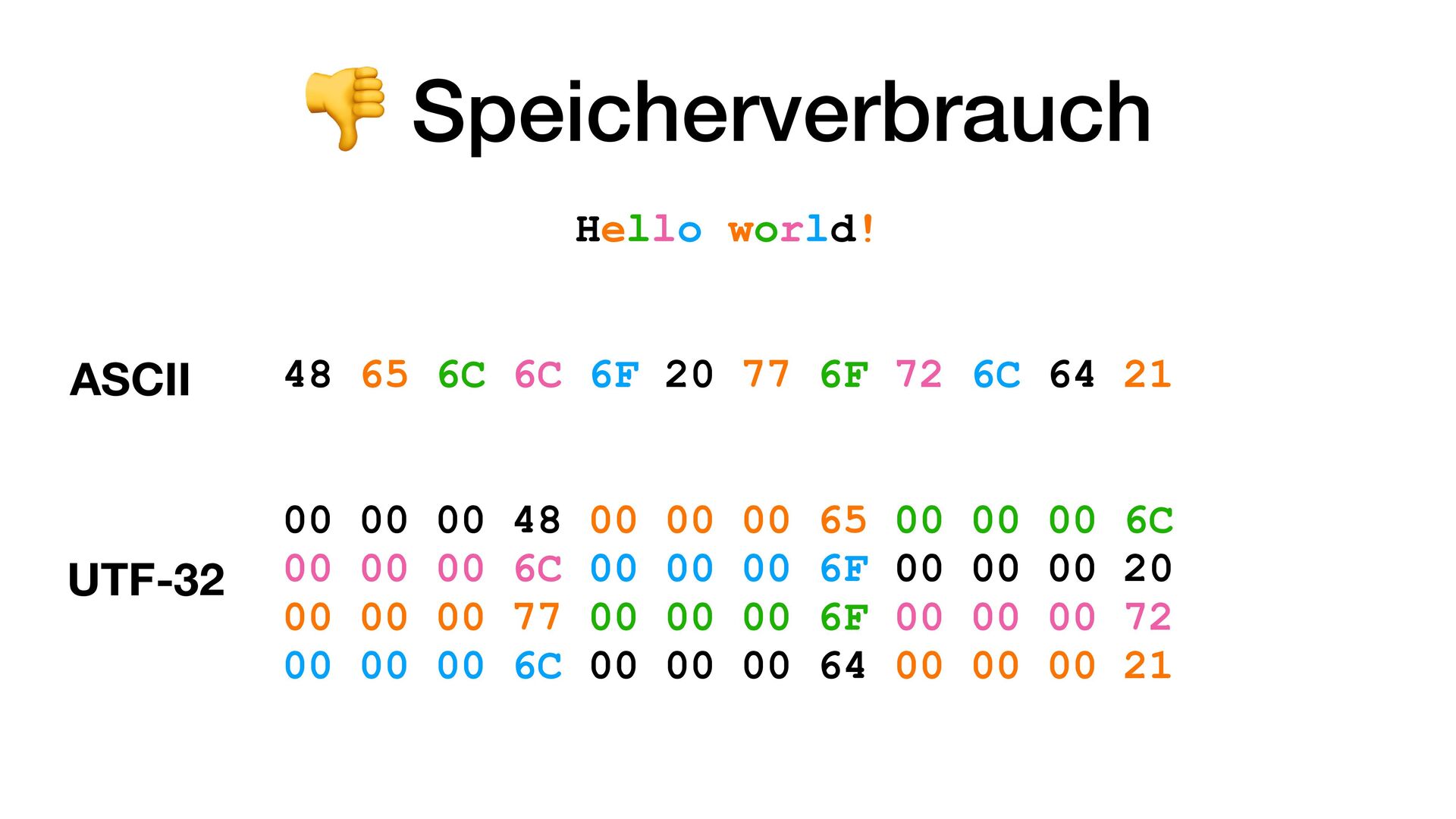
• Version 1 im Oktober 1991 mit 7.161 Zeichen • Version 6 im Oktober 2010 mit Emojis und 109.242 Zeichen • Version 16 im September 2024 mit 154.998 Zeichen • Der aktuelle Codespace liegt zwischen U+0000 bis U+10FFFF Bietet also Platz für 1.114.111 Zeichen bzw. Codepoints
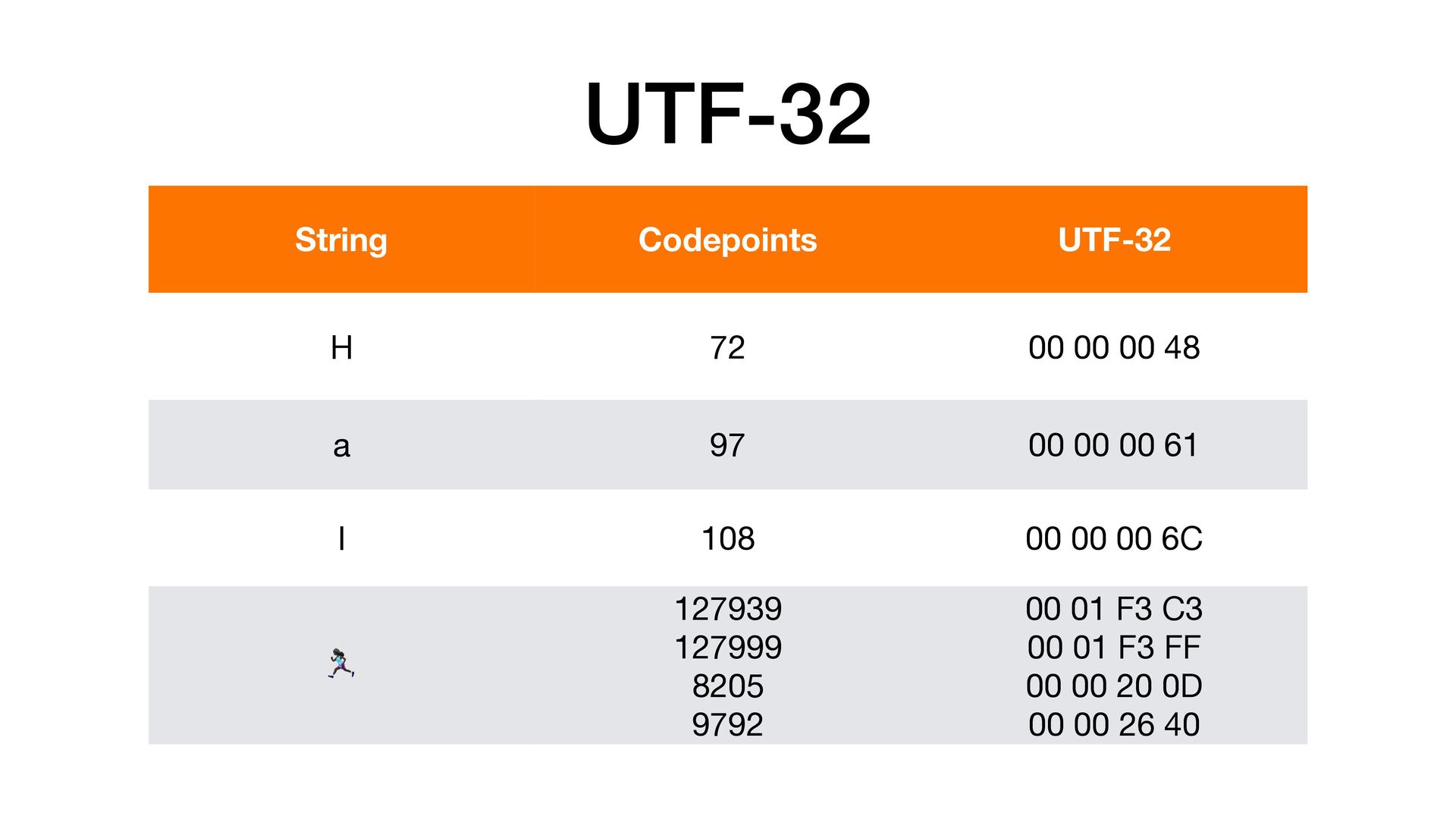
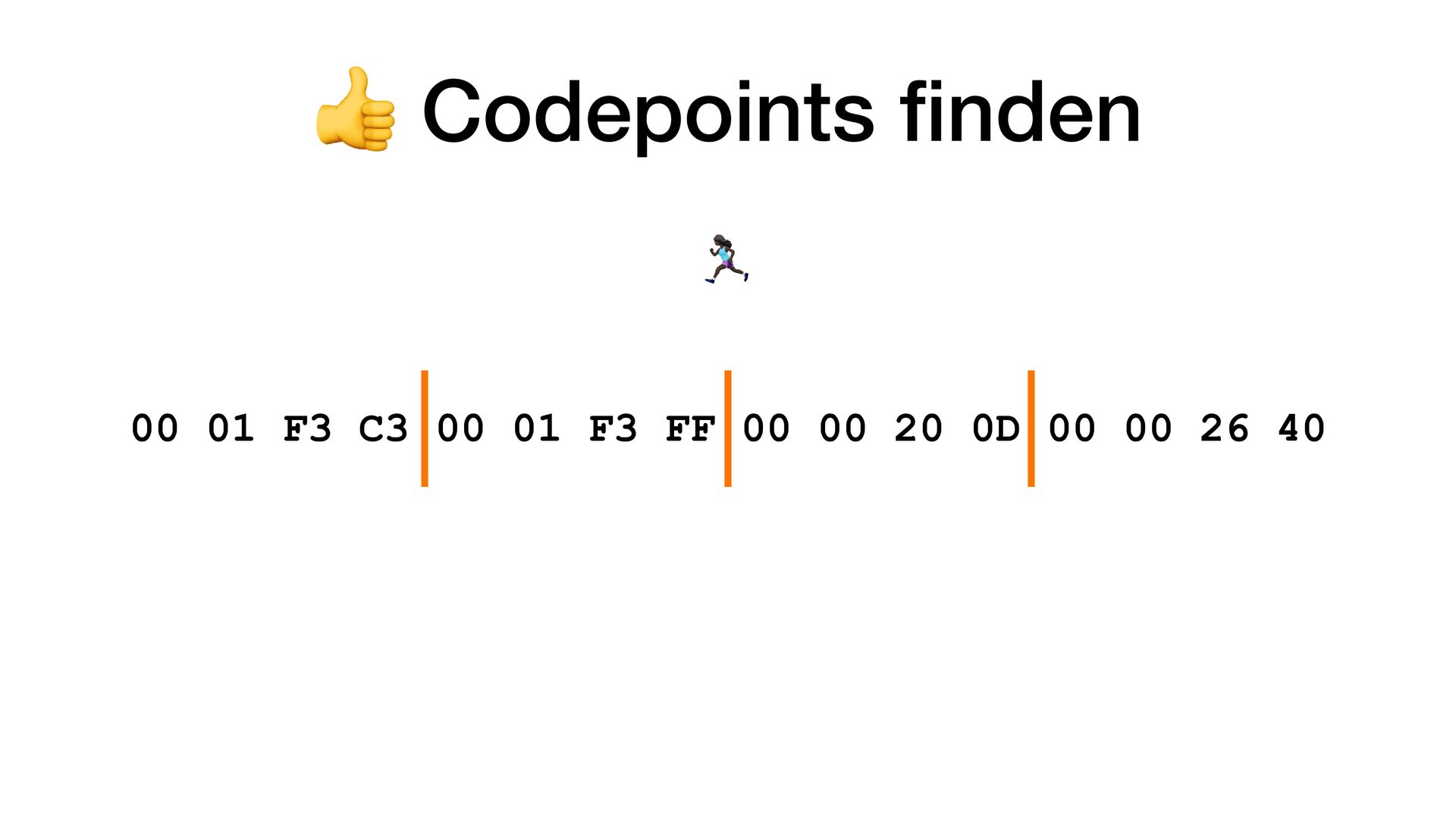
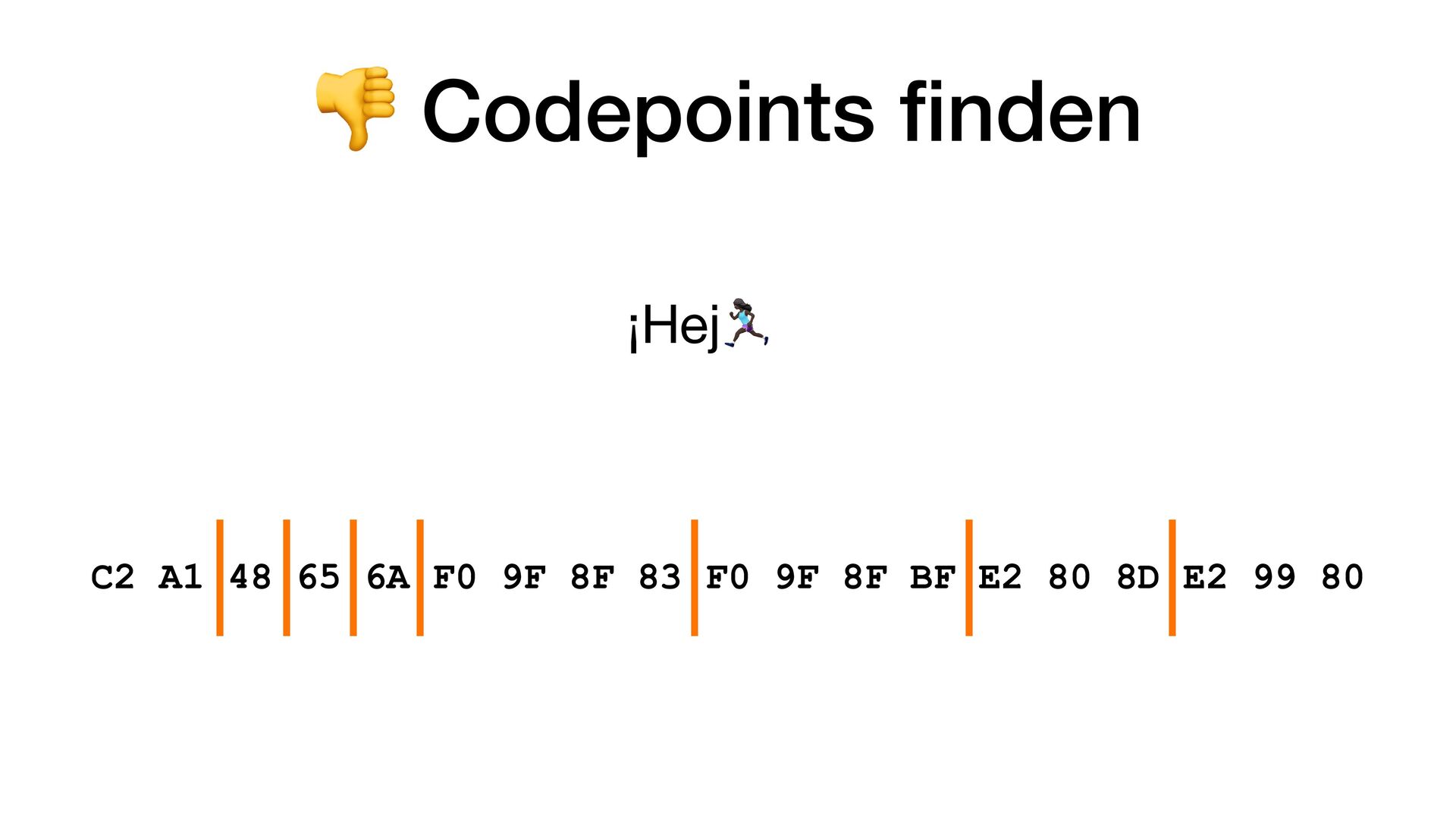
pro Codepoint. Aber warum 4 Bytes? • Wir haben doch gesehen, dass 21 Bit genug wären? • Wie weiss ein Parser, wann ein Codepoint anfängt und wann er aufhört? Also ob er jetzt bspw. 1 Byte oder 4 Bytes lesen soll?
• Führendes Byte startet mit 0xxxxxxx • Codepoint braucht 2 Bytes • Führendes Byte startet mit 110xxxxx • Das 2. Byte startet immer mit 10xxxxxx • Codepoint braucht 3 Bytes • Führendes Byte startet mit 1110xxxx • Die Bytes 2 und 3 starten mit 10xxxxxx • Codepoint braucht 4 Bytes • Führendes Byte startet mit 11110xxx • Die Bytes 2, 3 und 4 starten mit 10xxxxxx
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}