Share
機械学習プロフェッショナルシリーズの「深層学習による自然言語処理」の輪読会の第3回資料。
4章「言語処理特有の深層学習の発展」
https://learn-stats-ml.connpass.com/event/242216/
Natural Language Processing by Deep Learning section04
{kind=link}
{kind=link}
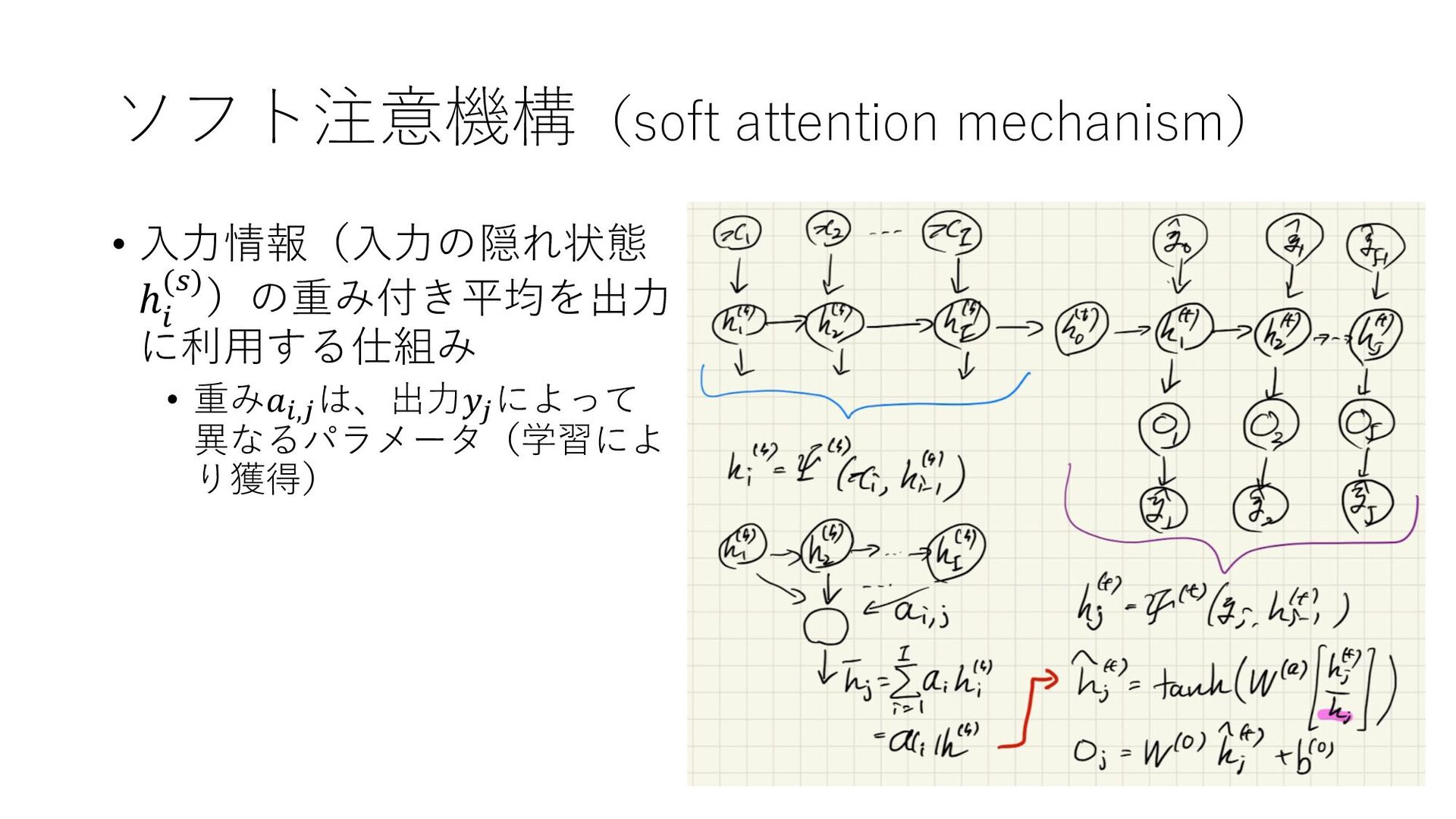
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
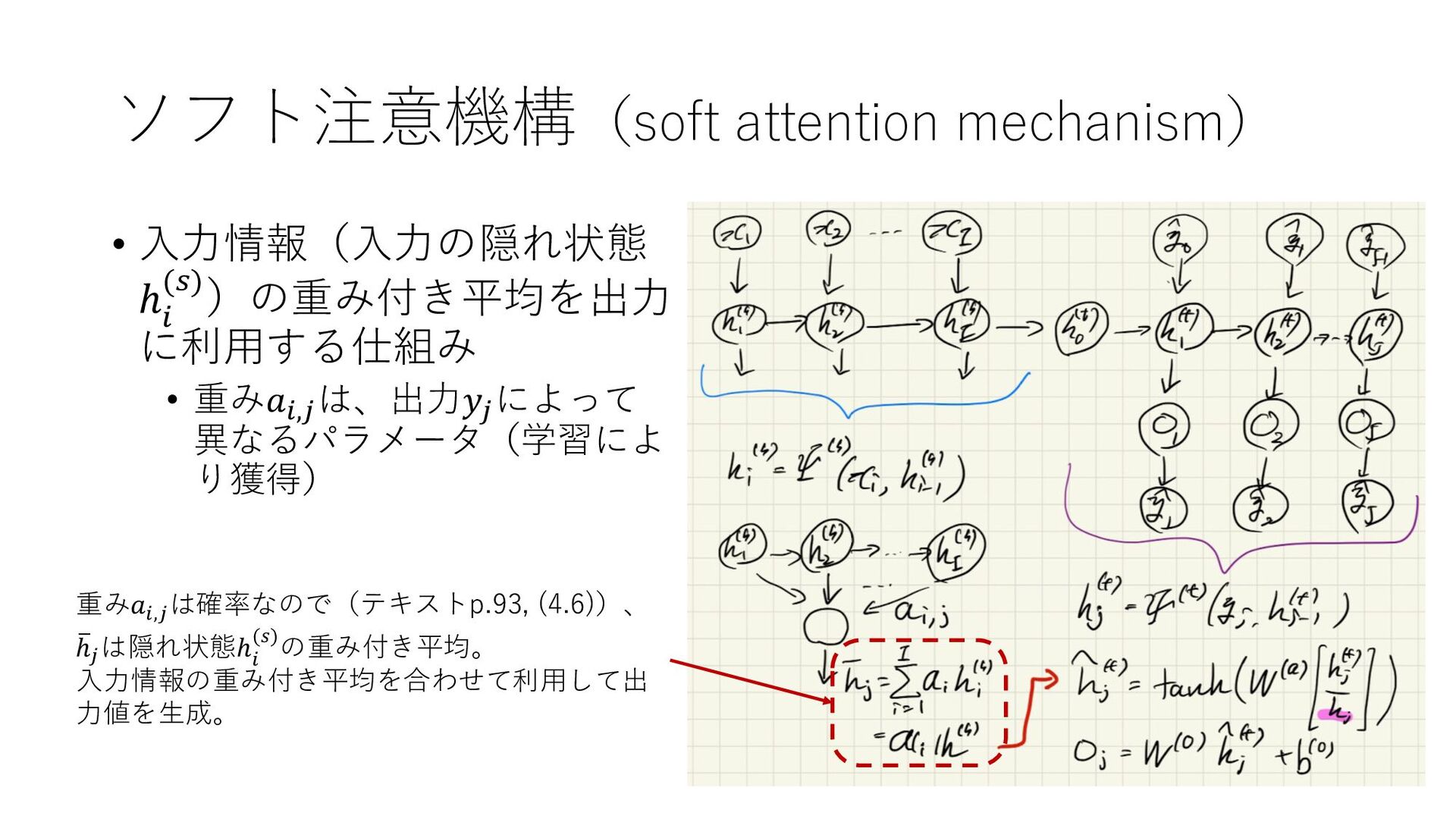{kind=link}
{kind=link}
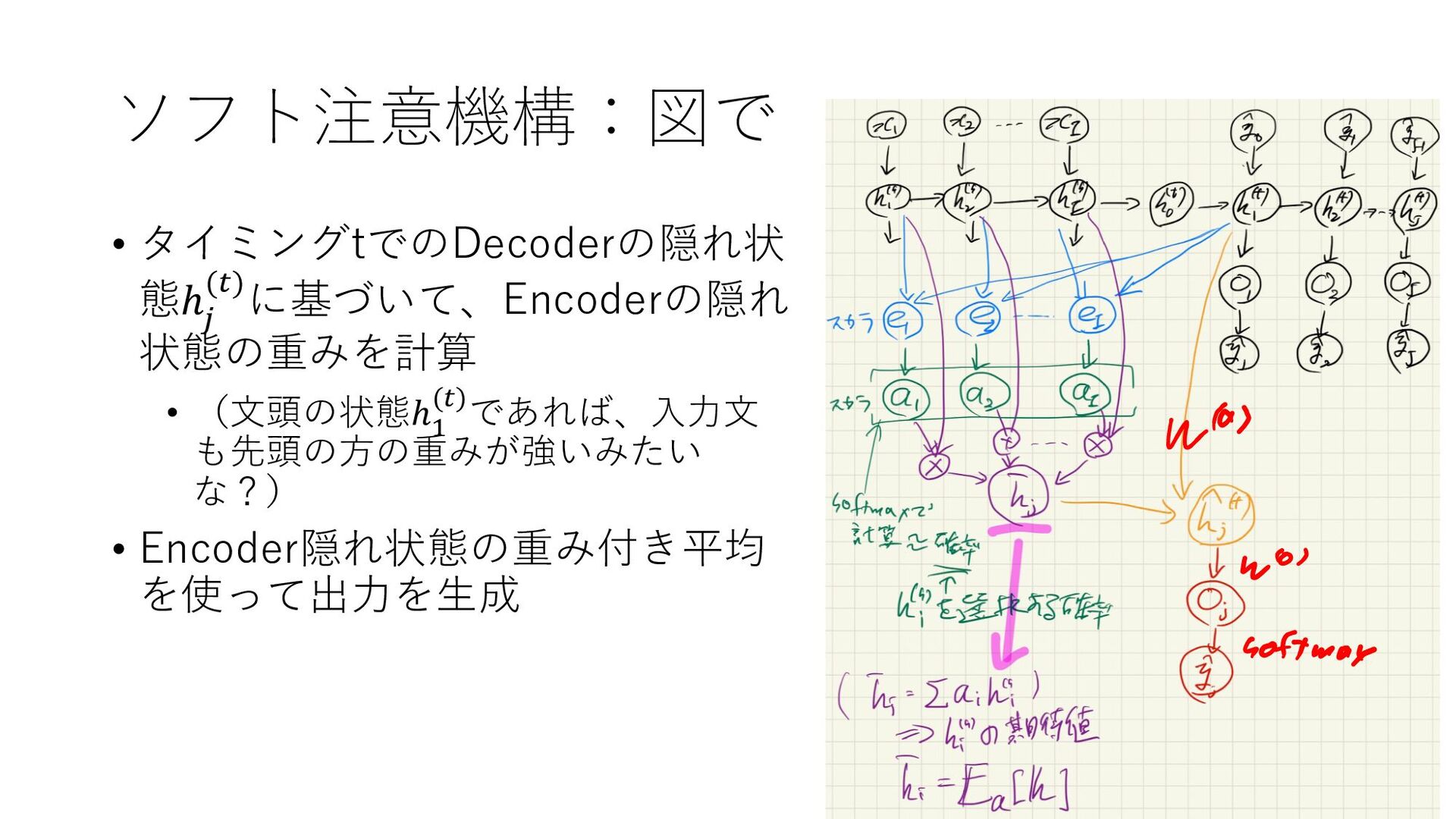{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
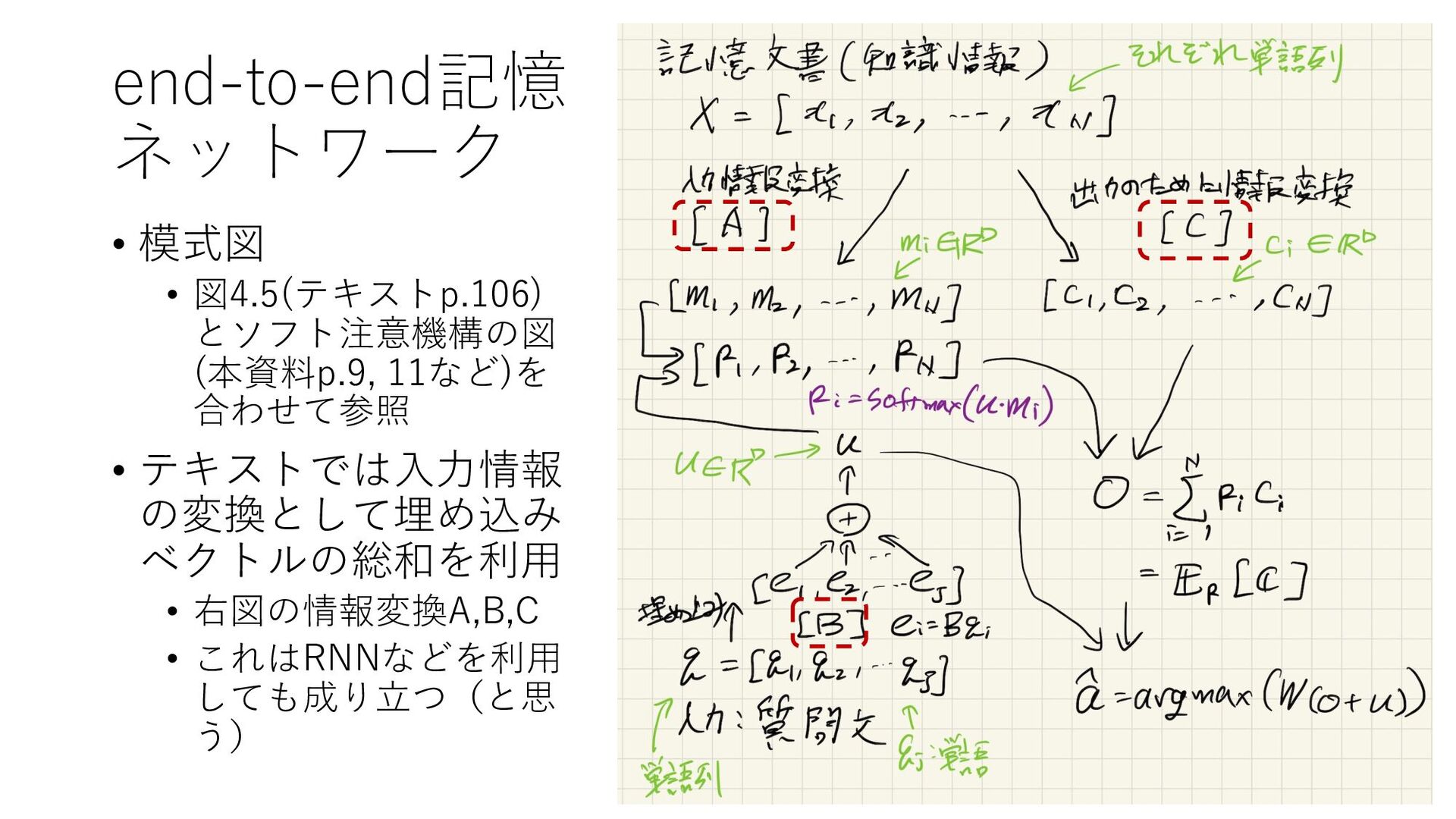{kind=link}
{kind=link}
{kind=link}
{kind=link}
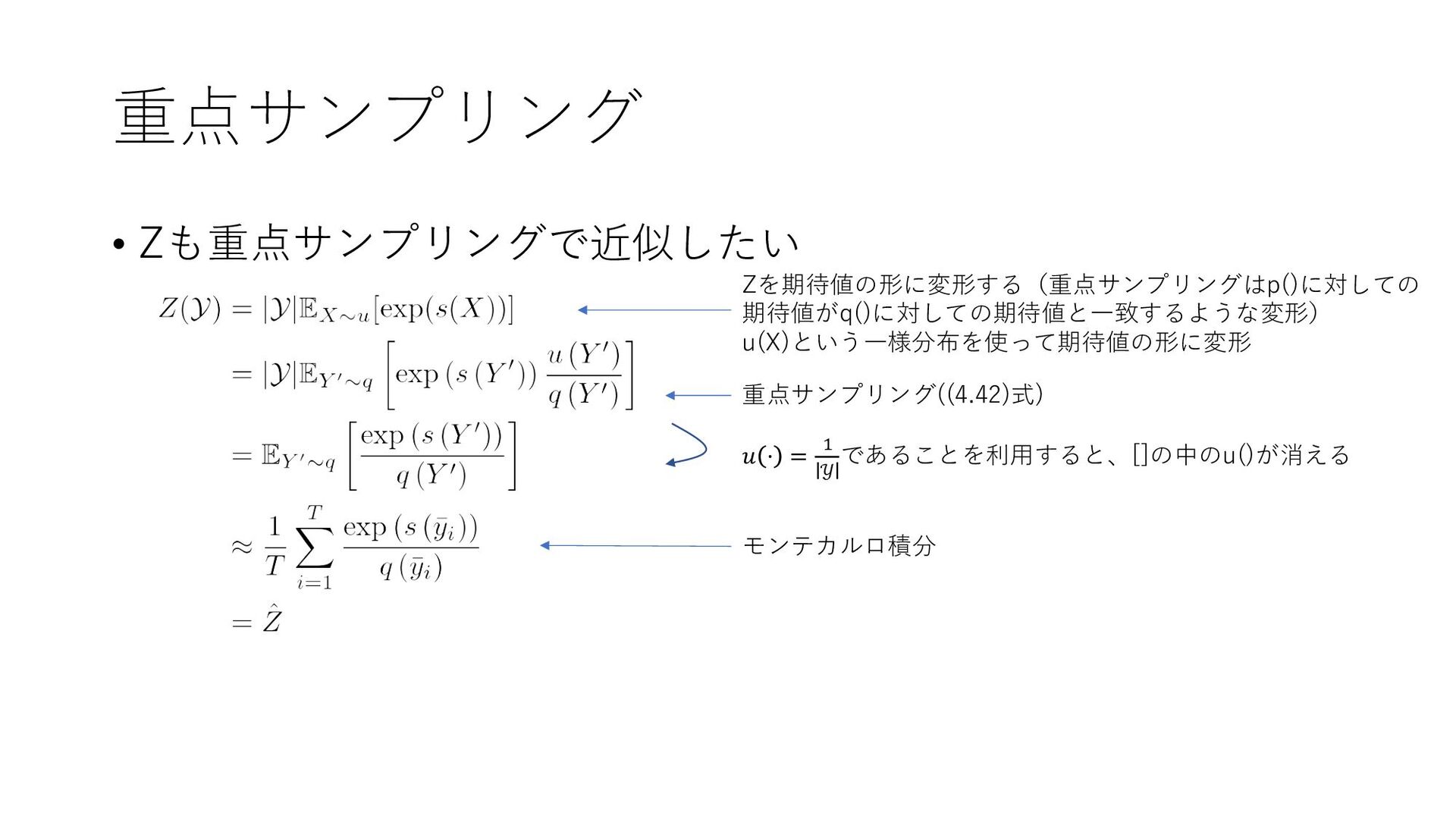{kind=link}
![重点サンプリング • 最終的な近似結果 求めたいのはこれ (4.33)式から (4.48)式 モンテカルロ積分 []の中は(4.47)式(素直に計算すれば導出できる) 最終的に、損失関数はこうなる((4.49)式) 9](https://files.speakerdeck.com/presentations/16fb42d06d79436b9dd12fd555c58db5/slide_29.jpg){kind=link}
{kind=link}
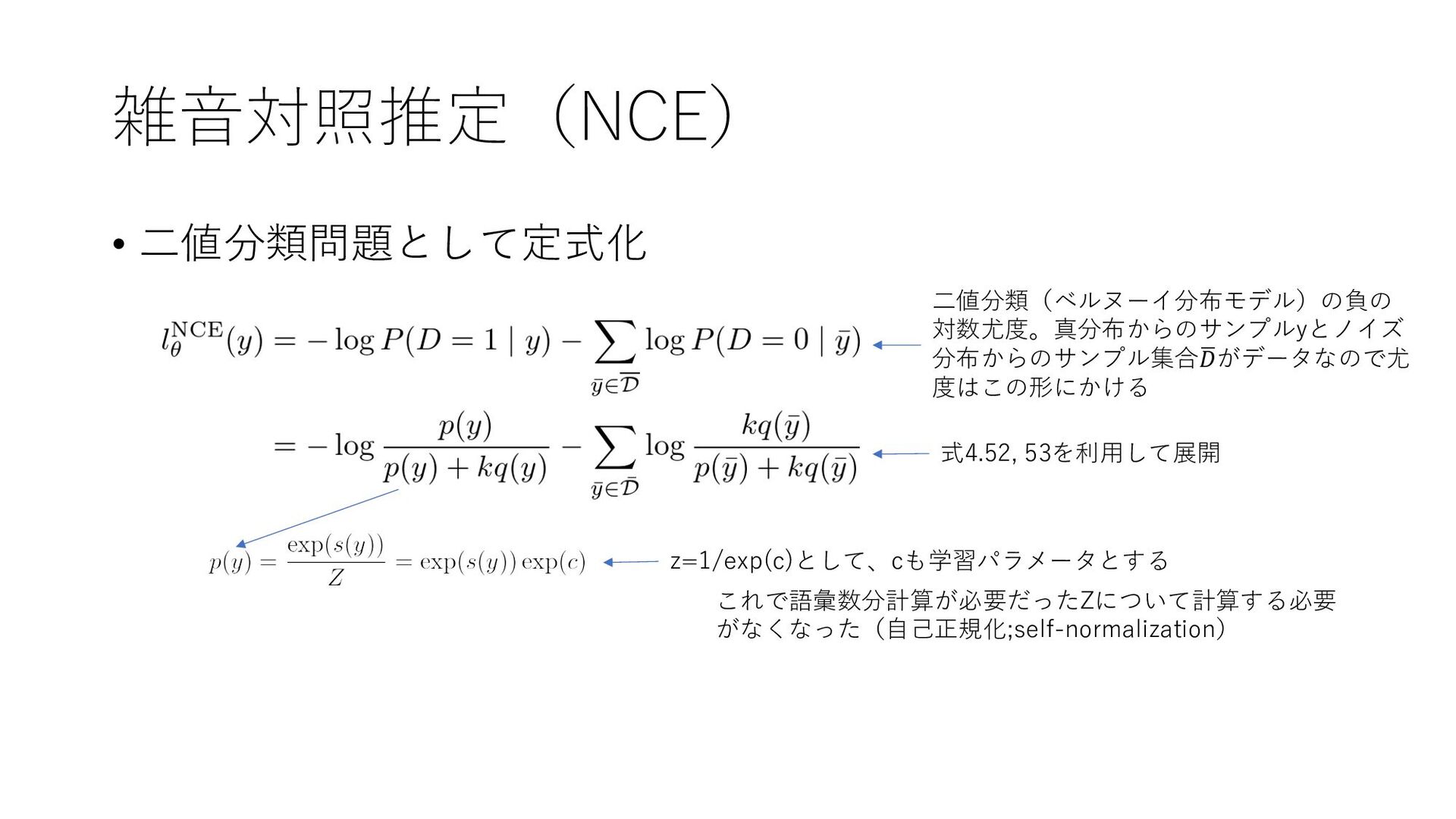{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}