ただ、最近の研究では分かち書きフリーなモデルが提案されてきてい るらしい • 「NLP における分かち書き最適化・分かち書きフリー⼿法の総まとめ」, ステー ト・オブ・AIガイド(2022/01/19, 有料記事), link • Linting+, 2021, ByT5: Towards a token-free future with pre-trained byte-to- byte models, link • Jonatham+, 2021, CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation, link
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
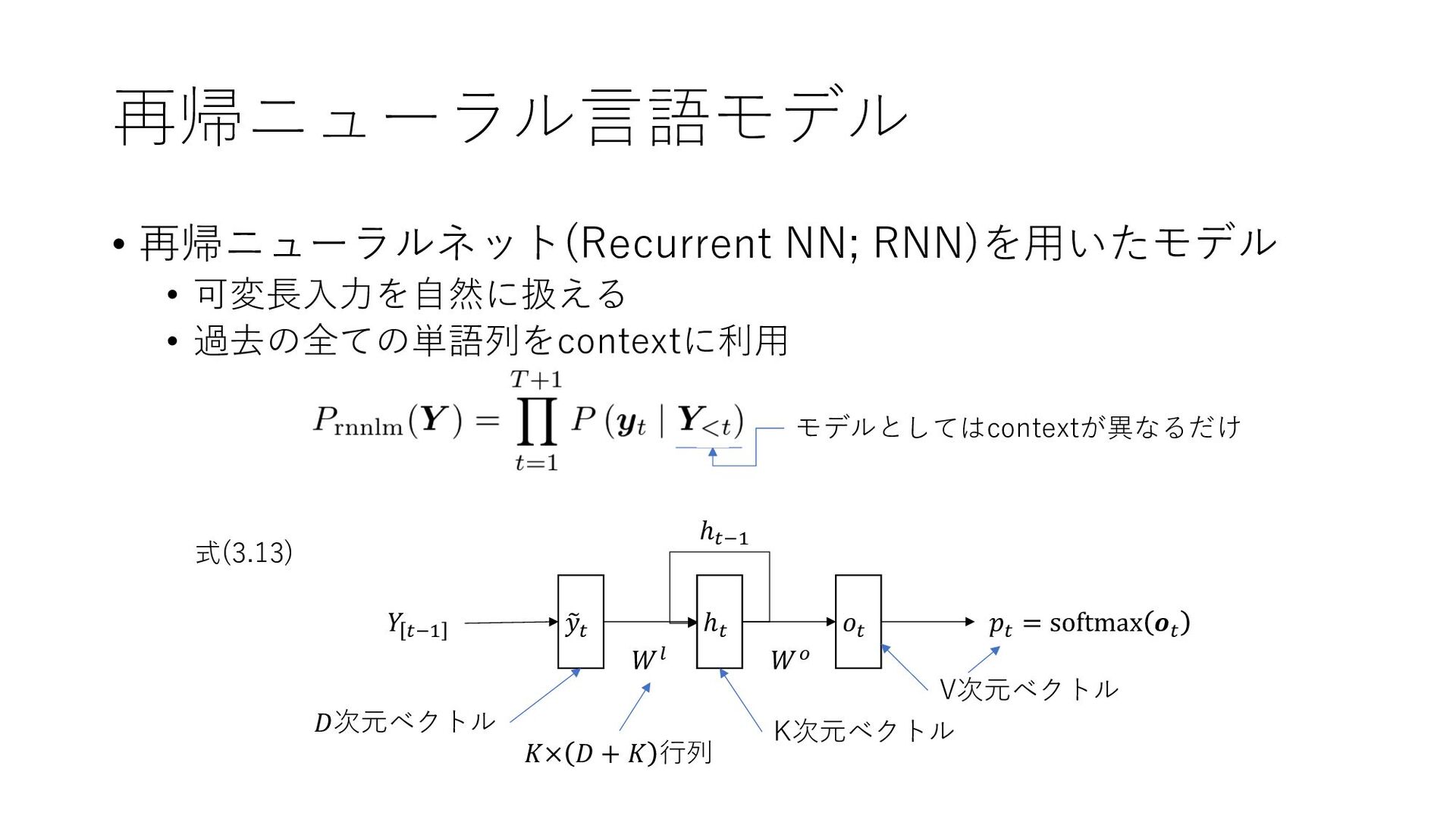{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
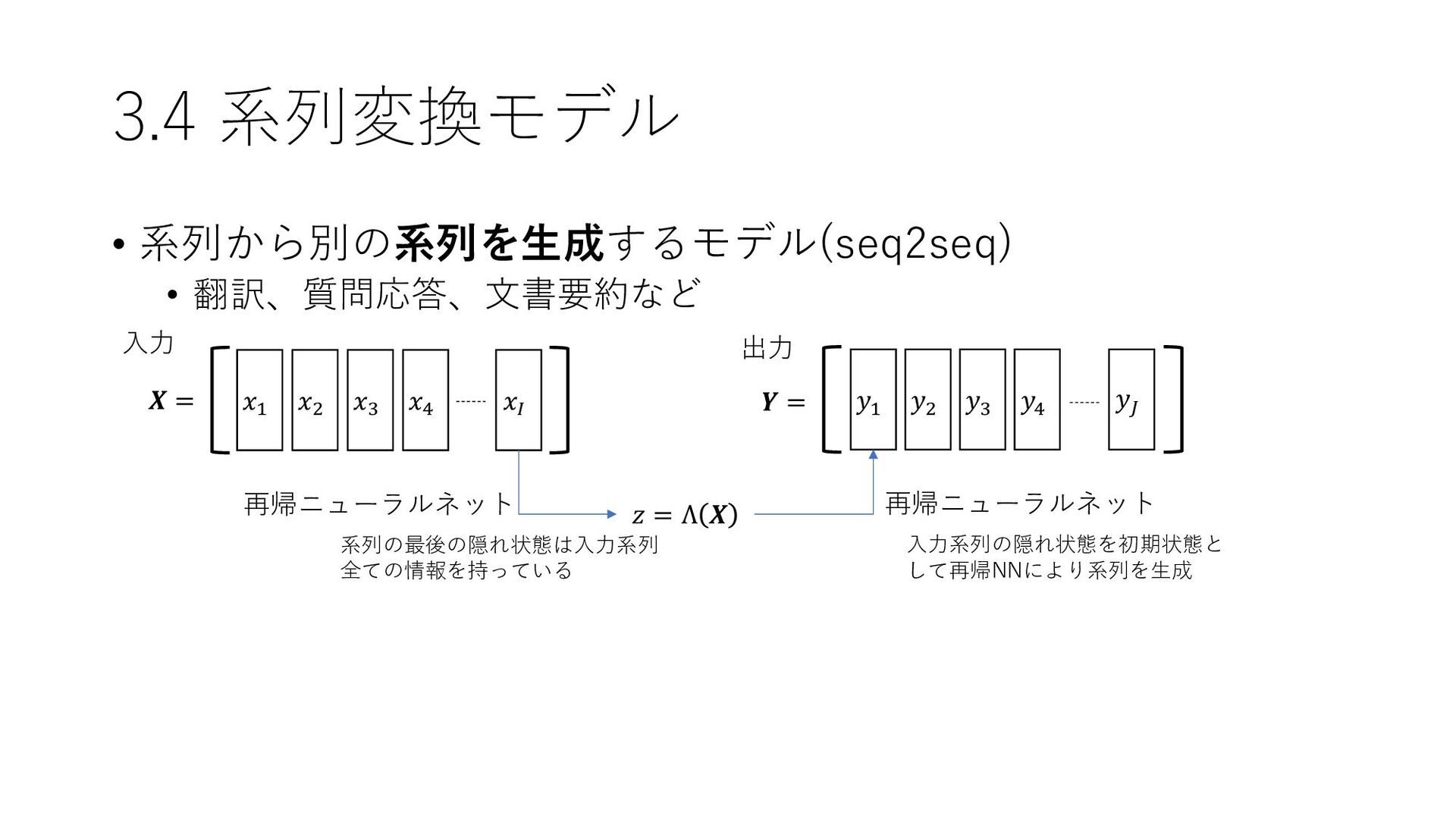{kind=link}
{kind=link}
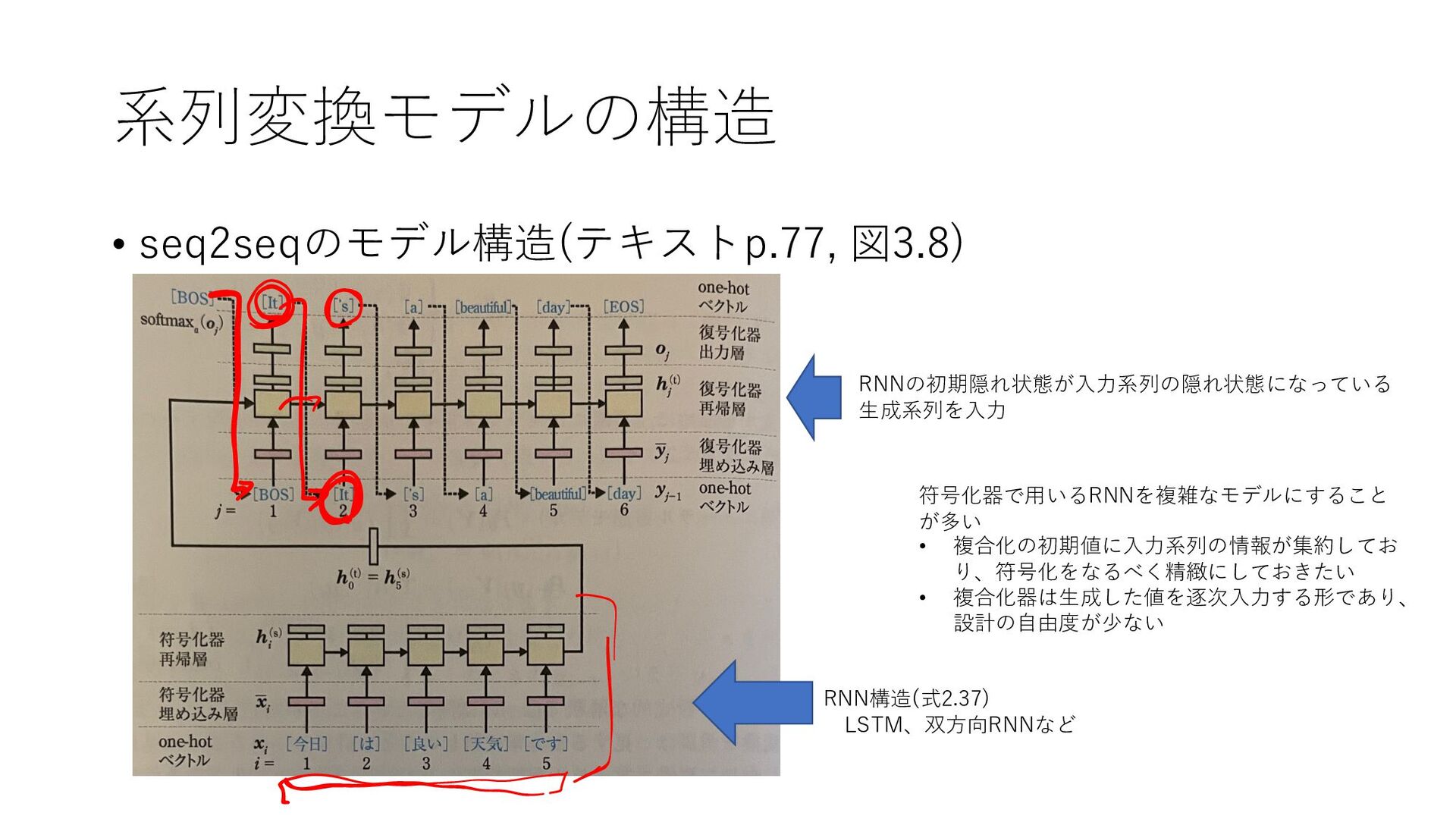{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}