Share
機械学習プロフェッショナルシリーズの「深層学習による自然言語処理」の輪読会の第4回資料。
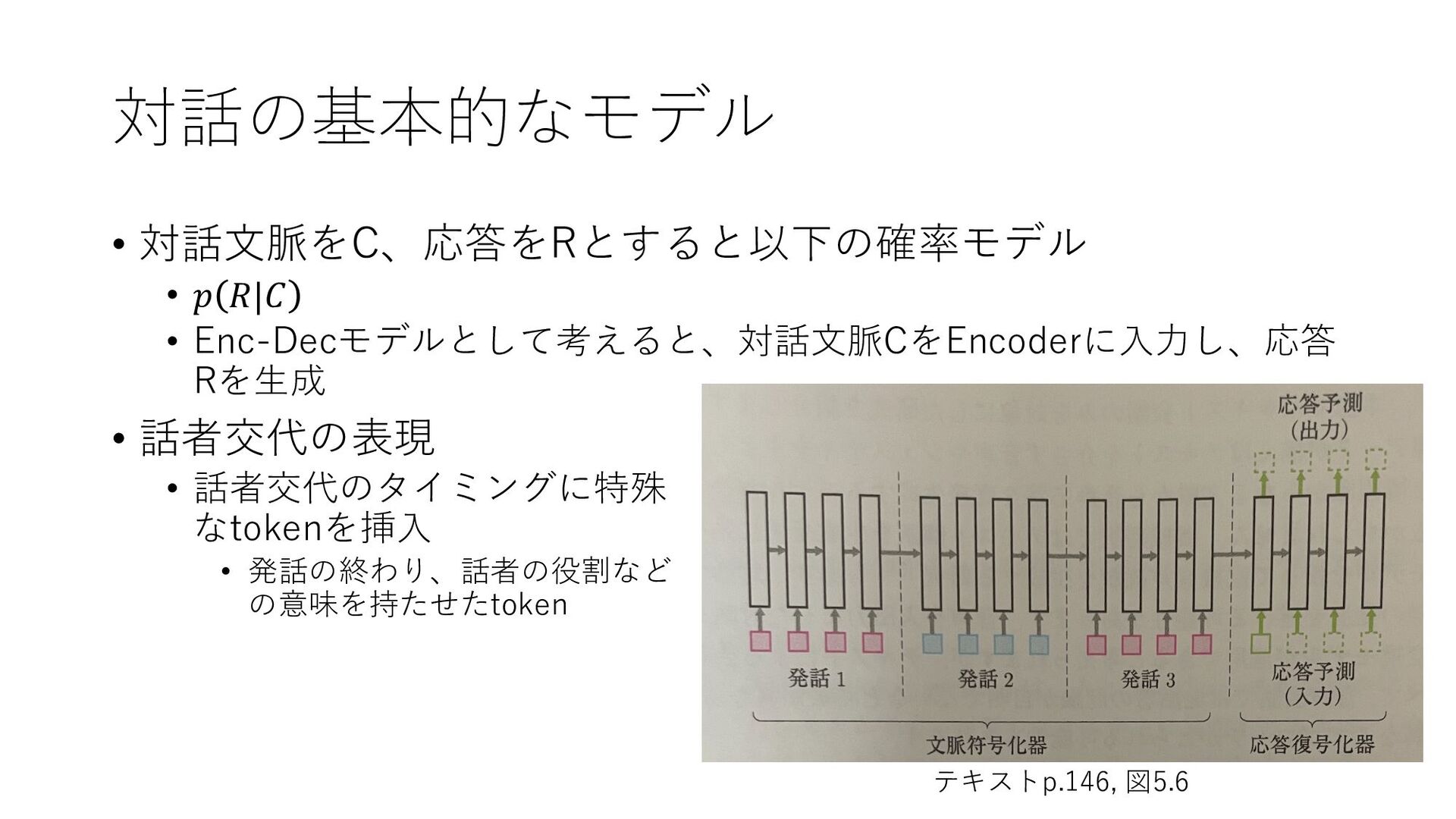
5章「応用」
https://learn-stats-ml.connpass.com/event/243417/
Natural Language Processing by Deep Learning section05
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}