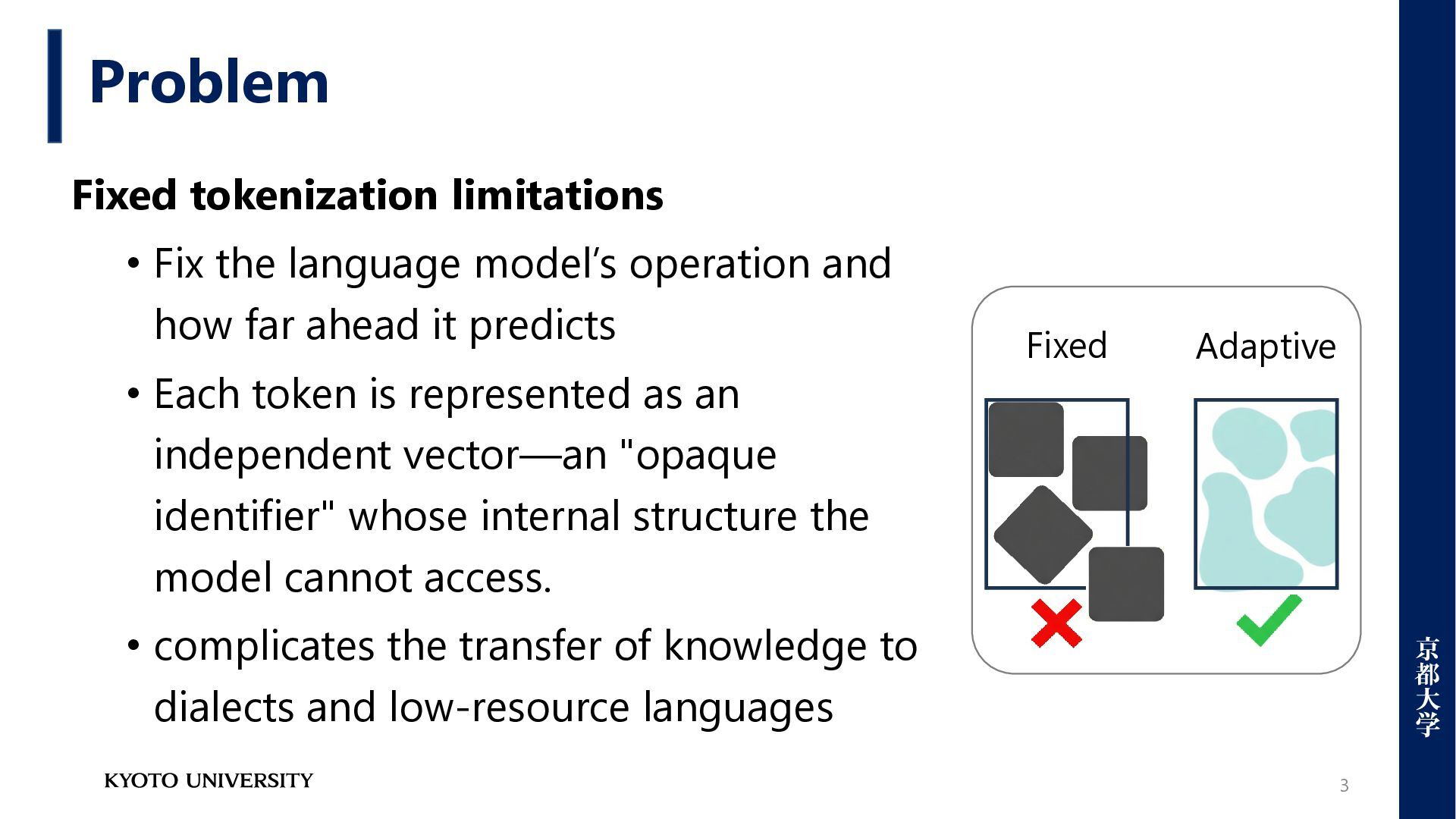
how far ahead it predicts • Each token is represented as an independent vector—an "opaque identifier" whose internal structure the model cannot access. • complicates the transfer of knowledge to dialects and low-resource languages Problem 3 Fixed Adaptive
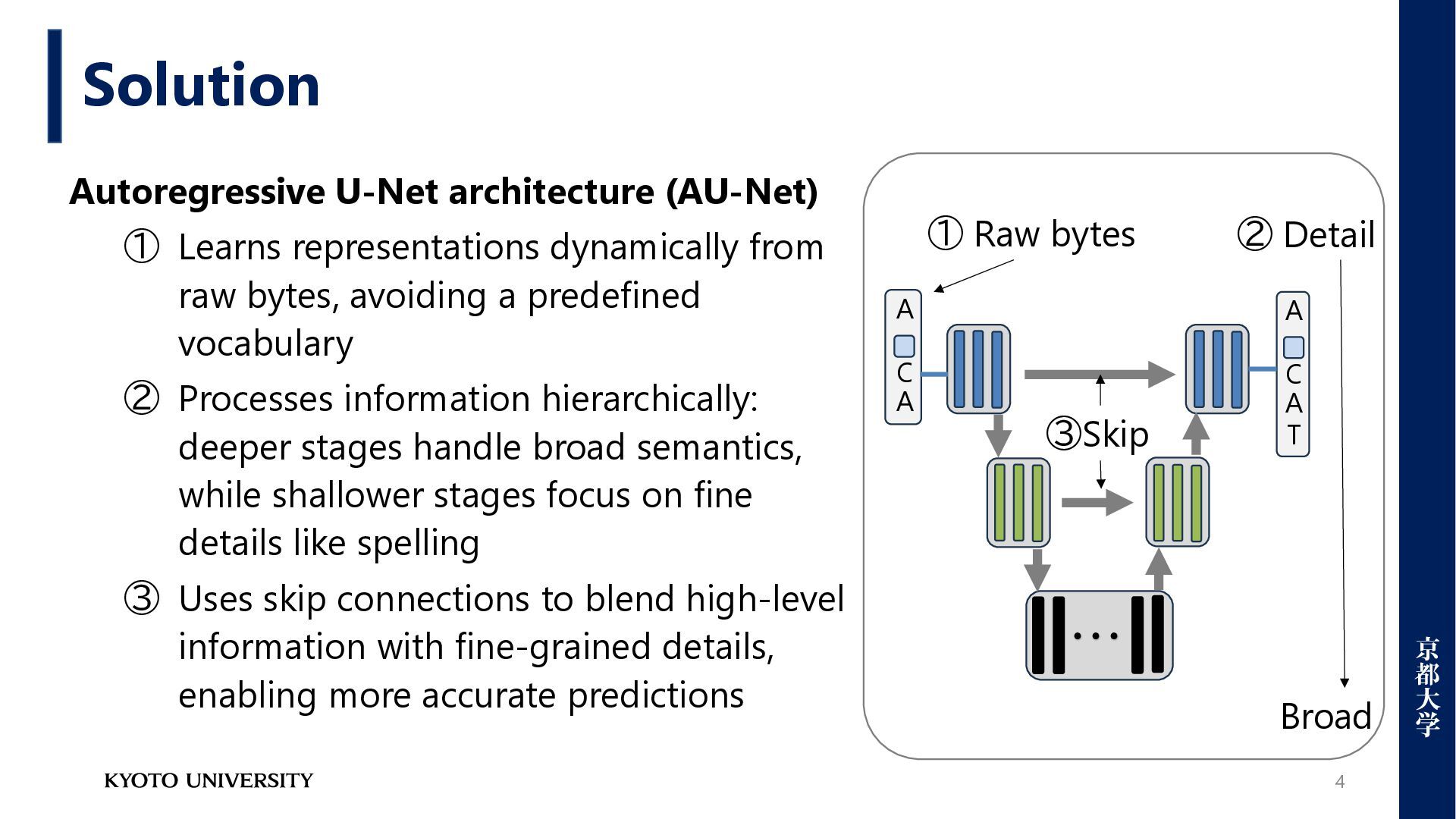
from raw bytes, avoiding a predefined vocabulary ② Processes information hierarchically: deeper stages handle broad semantics, while shallower stages focus on fine details like spelling ③ Uses skip connections to blend high-level information with fine-grained details, enabling more accurate predictions ・・・ A A C A A C T ② Detail Broad ① Raw bytes ③Skip
vectors, model can’t see shared patterns s t r a w b e r r y s t r a w b e r r i e s Easily captures common substrings AU-Net Learn semantic similarity without assists BPE straw berry straw berries 301 1831 8396 20853 301 1831 Language Model Most Common Proposed +
Problems for multilingual environments [1] • Unable to perform task-optimized tokenization [2] • Not robust to typos, spelling variations, or morphological changes[3] • A barrier to distilling knowledge between different models • Cannot pre-define tokenization for emergent languages [1] Xue, Linting, et al. "Byt5: Towards a token-free future with pre-trained byte-to-byte models." Transactions of the Association for Computational Linguistics 10 (2022): 291-306 [2] Zheng, Mengyu, et al. "Enhancing large language models through adaptive tokenizers." Advances in Neural Information Processing Systems 37 (2024): 113545-113568. [3] Wang, Junxiong, et al. "Mambabyte: Token-free selective state space model." arXiv preprint arXiv:2401.13660 (2024).
Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer international publishing, 2015. Cited by [2] Skip Connection Encoder Decoder Local Global
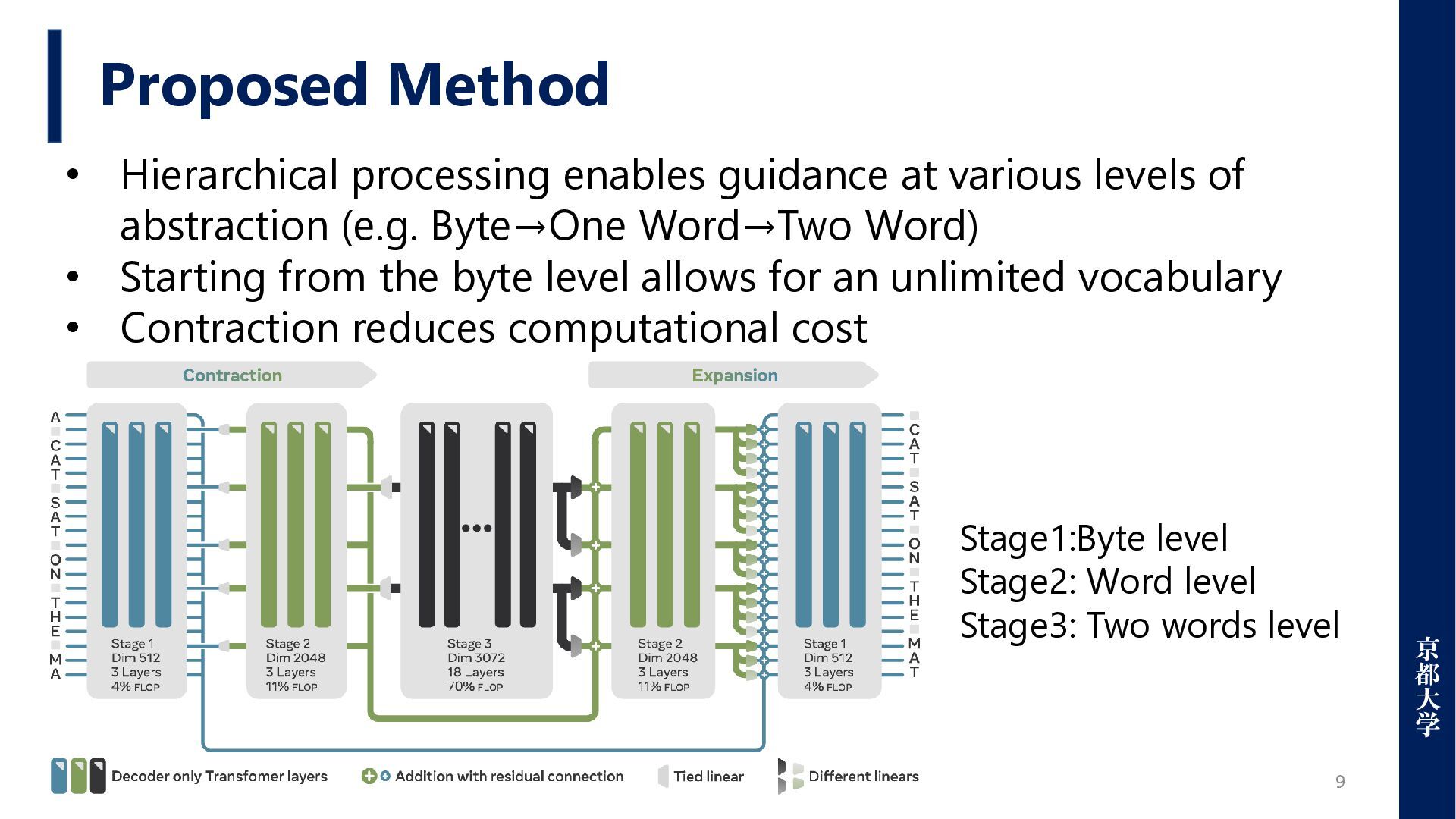
levels of abstraction (e.g. Byte→One Word→Two Word) • Starting from the byte level allows for an unlimited vocabulary • Contraction reduces computational cost Stage1:Byte level Stage2: Word level Stage3: Two words level
Pooling: selects indices from the splitting function and projects them linearly ➢ Upsampling: duplicates coarse vectors to match finer segments, applying position-specific linear transforms called Multi-Linear Upsampling 2. Splitting Function ➢ Supports flexible splitting strategies to define pooling points at each hierarchical stage ➢ Splits on spaces using different regular expressions at each stage in this paper 3. Evaluating on different scales ➢ Model size is defined by FLOPs per input unit, rather than the number of parameters ➢ FLOPs allows models like the BPE baseline and AU-Net to be compared on the same computational scale
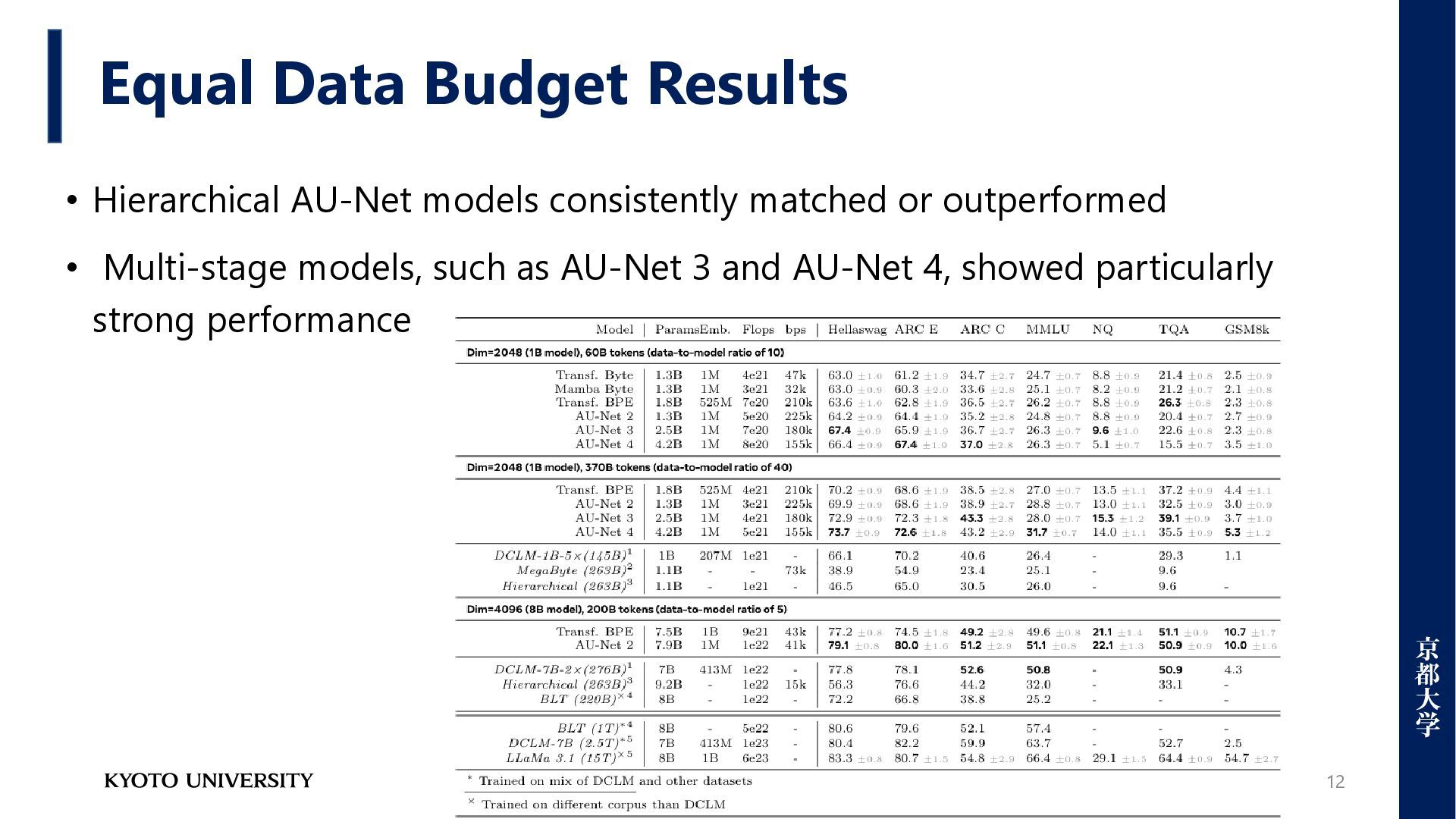
proposed Autoregressive U-Net(AU-Net) ⚫ Dataset ➢DCLM dataset [3] (predominantly English & focus on natural language understanding) ⚫ Baselines ➢A Transformer model using the LLaMa 3 BPE tokenizer ➢A Transformer model trained directly on raw bytes ➢A Mamba model trained directly on raw bytes [3] Li, Jeffrey, et al. "Datacomp-lm: In search of the next generation of training sets for language models." Advances in Neural Information Processing Systems 37 (2024): 14200-14282.
viability by matching the performance of a strong, optimized BPE baseline. • Future Potential: ➢While it lags on some tasks (GSM8K, MMLU), its delayed performance "take-off" suggests it could surpass BPE at larger scales.
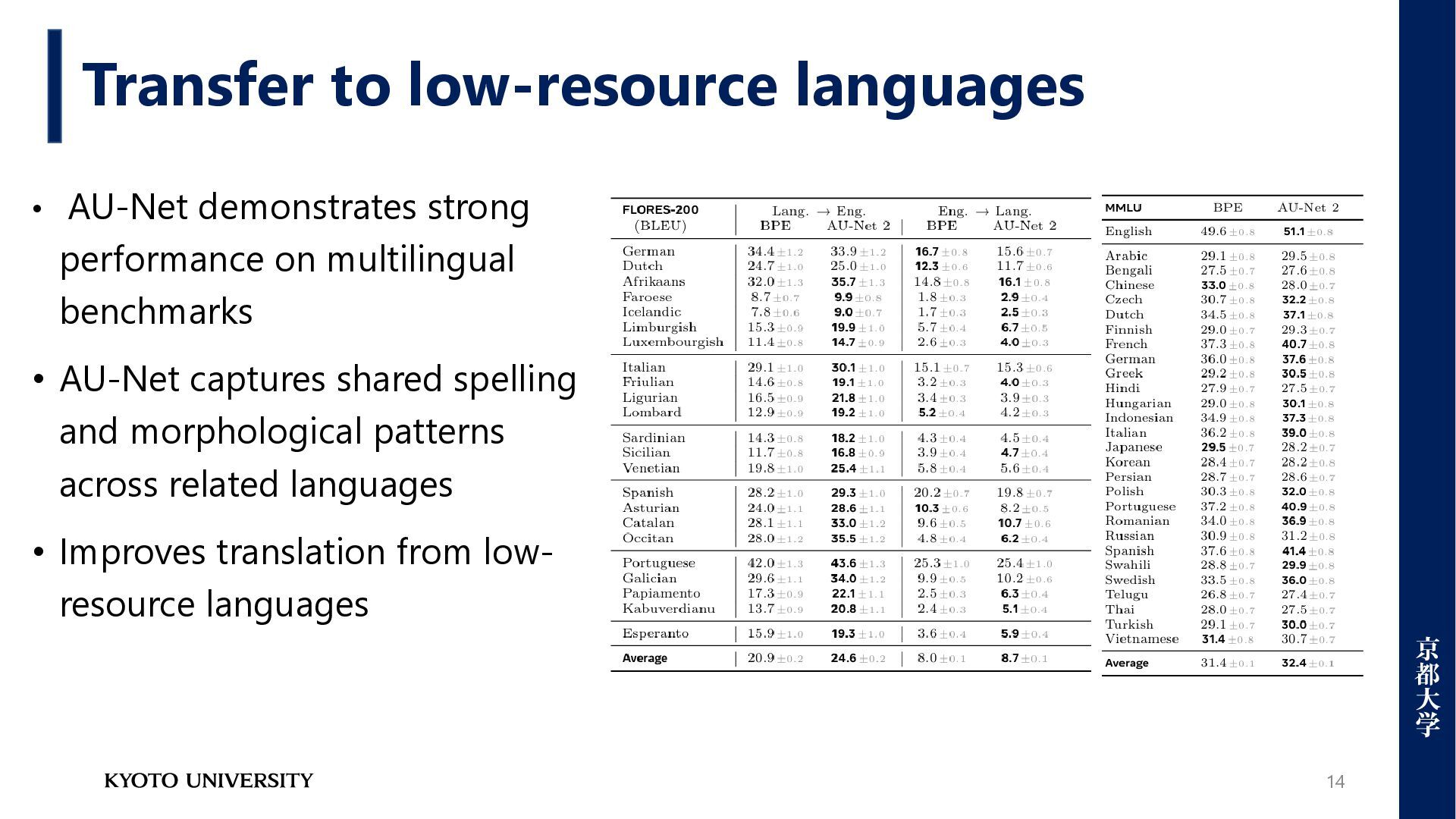
on multilingual benchmarks • AU-Net captures shared spelling and morphological patterns across related languages • Improves translation from low- resource languages
experiments highlight a natural trade-off between the models. • AU-Net performs better on character-manipulation tasks, such as spelling • The BPE baseline is stronger on word-level tasks
learns hierarchical token representation from raw bytes ➢AU-Net can eliminate the need for predefined vocabularies ➢AU-Net matches performance of strong BPE baselines under controlled compute budgets • Limitation & Future Work ➢AU-Net currently does not support non-space-based languages(e.g. Chinese). A potential solution is to learn the splitting function directly. ➢As the number of stages increases, the efficiency of the parallelization framework becomes a challenge
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![What is U-Net (From my research) 8 [2] Ronneberger, Olaf,](https://files.speakerdeck.com/presentations/c76e31d7fe3e448980c97eae8160e17f/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}