Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Rで計量経済学#3 重回帰分析とバイアス
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
TomoyaOzawa-DA
August 15, 2020
400
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Rで計量経済学#3 重回帰分析とバイアス
所属している研究会で扱った資料になります。
内容について間違いがある可能性もありますので、その際にはご連絡ください。
TomoyaOzawa-DA
August 15, 2020
More Decks by TomoyaOzawa-DA
See All by TomoyaOzawa-DA
Rで計量経済学#0 事前準備
tom01
0
280
Rで計量経済学#1 単回帰分析
tom01
0
690
Rで計量経済学#2 重回帰分析
tom01
0
210
Rで計量経済学#4 操作変数法
tom01
0
2.5k
Rで計量経済学#5 プロビット・ロジットモデル
tom01
0
600
Rで計量経済学#6 パネルデータ分析
tom01
0
6.3k
Featured
See All Featured
The Invisible Side of Design
smashingmag
301
52k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Design in an AI World
tapps
1
250
Git: the NoSQL Database
bkeepers
PRO
432
67k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Marketing to machines
jonoalderson
1
5.5k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
370
What's in a price? How to price your products and services
michaelherold
247
13k
Discover your Explorer Soul
emna__ayadi
2
1.2k
The SEO identity crisis: Don't let AI make you average
varn
0
510
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
Transcript
R Lecture #3 Tomoya Ozawa 重回帰分析 -データと向き合ってみる-
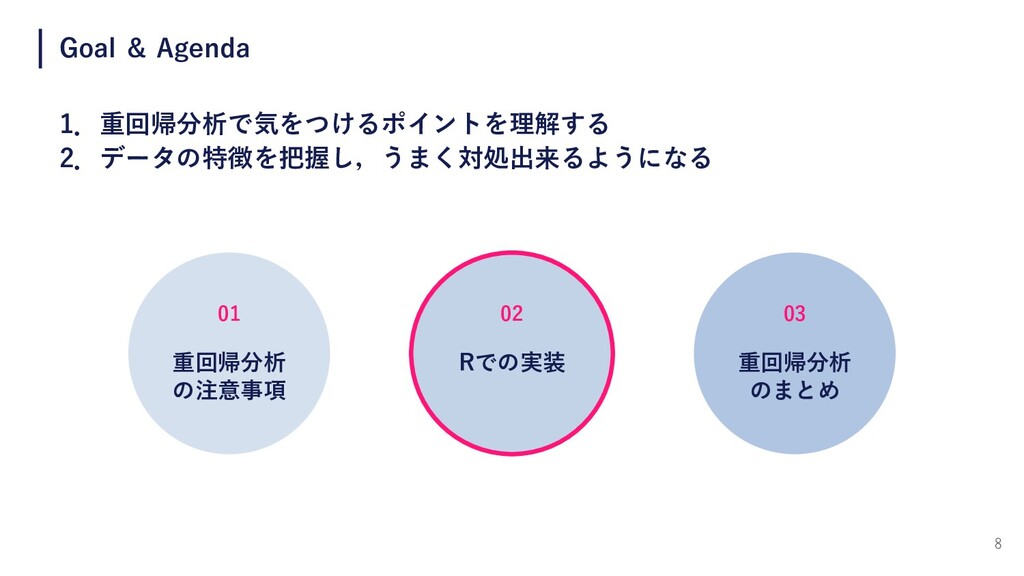
2 Goal & Agenda 1.重回帰分析で気をつけるポイントを理解する 2.データの特徴を把握し,うまく対処出来るようになる 02 Rでの実装 01 重回帰分析
の注意事項 03 重回帰分析 のまとめ
3 Goal & Agenda 1.重回帰分析で気をつけるポイントを理解する 2.データの特徴を把握し,うまく対処出来るようになる 02 Rでの実装 01 重回帰分析
の注意事項 03 重回帰分析 のまとめ
4 重回帰分析をふりかえる 01 重回帰分析の注意事項 賃⾦と教育年数との関係を以下のようにモデル化して分析. 説明変数に労働時間や⼦供の数を追加し,⽋落変数バイアスを軽減させました. _ = + ×
+ ×_ + ×_ +
5 単回帰分析の結果と⽐較して⽋落変数バイアスについて考えました. バイアスを軽減させるため,その他にも気を付けなくてはいけないことがあります. 01 重回帰分析の注意事項 バイアスをふりかえる 説明変数の不⾜によりパラメータが偏ることを⽋落変数バイアスといいました.
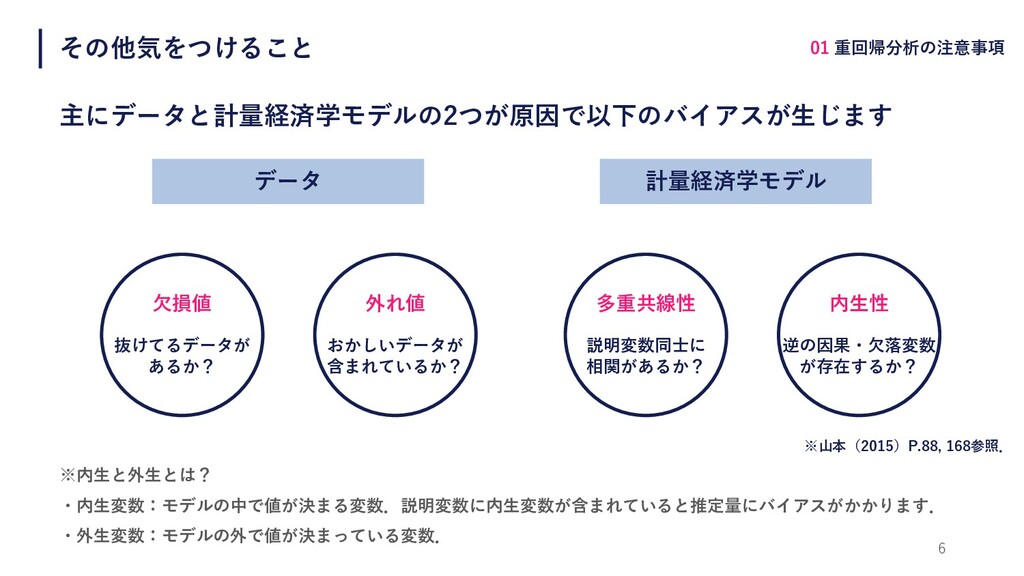
その他気をつけること 主にデータと計量経済学モデルの2つが原因で以下のバイアスが⽣じます 6 01 重回帰分析の注意事項 データ 計量経済学モデル ⽋損値 抜けてるデータが あるか?
外れ値 おかしいデータが 含まれているか? 多重共線性 説明変数同⼠に 相関があるか? 内⽣性 逆の因果・⽋落変数 が存在するか? ※内⽣と外⽣とは? ・内⽣変数:モデルの中で値が決まる変数.説明変数に内⽣変数が含まれていると推定量にバイアスがかかります. ・外⽣変数:モデルの外で値が決まっている変数. ※⼭本(2015)P.88, 168参照.
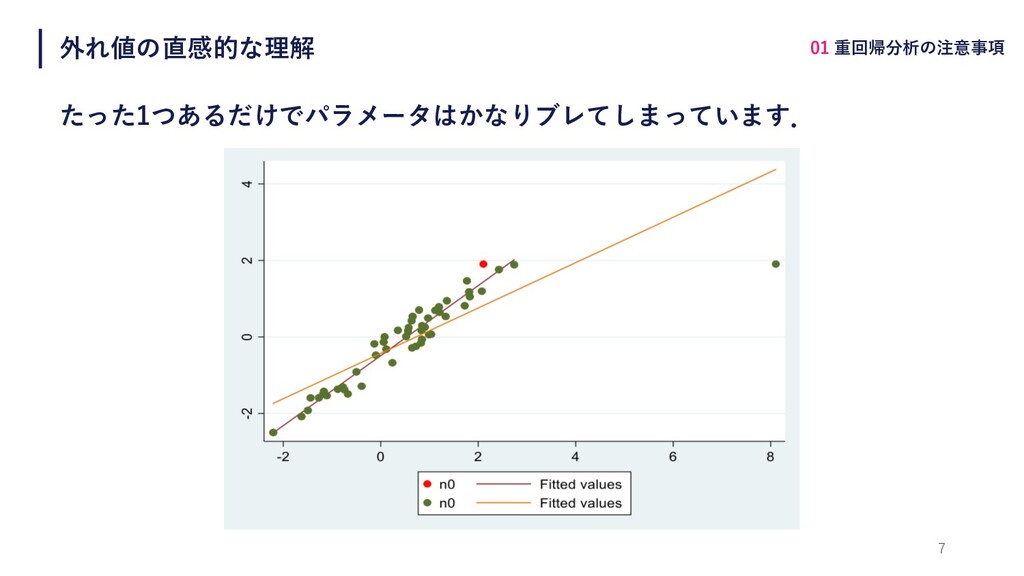
外れ値の直感的な理解 たった1つあるだけでパラメータはかなりブレてしまっています. 7 01 重回帰分析の注意事項
8 Goal & Agenda 1.重回帰分析で気をつけるポイントを理解する 2.データの特徴を把握し,うまく対処出来るようになる 02 Rでの実装 01 重回帰分析
の注意事項 03 重回帰分析 のまとめ
9 今⽇のTry 今回は推定することよりも,データの把握・加⼯がメインになります. 先ほど紹介した“気をつけること”に注意して分析していきましょう. データ上の全ての変数を説明変数に加えて, ”教育年数が増えると,賃⾦は増加するのでは?”という仮説を再度検証しよう! 02 Rでの実装
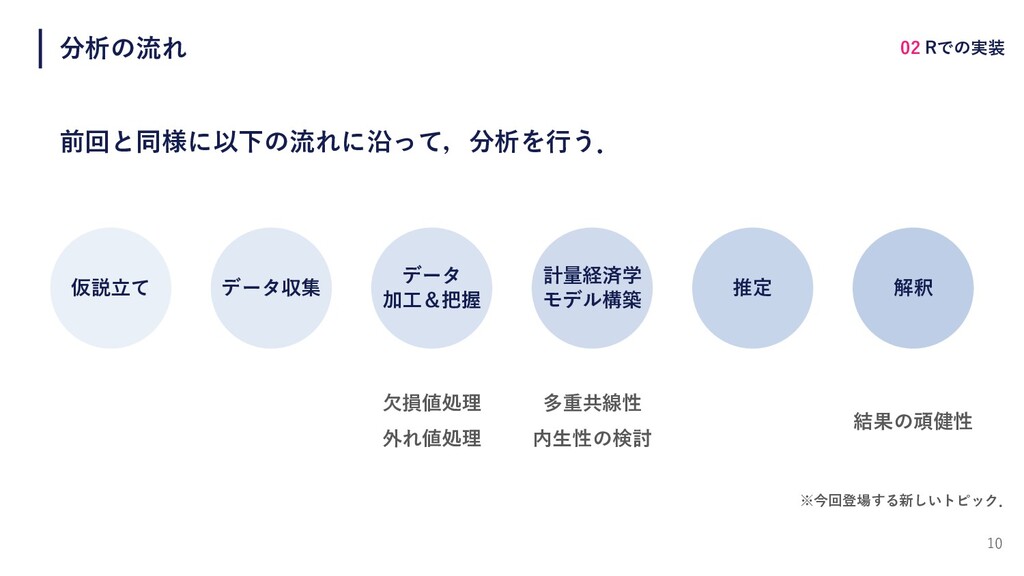
10 分析の流れ 前回と同様に以下の流れに沿って,分析を⾏う. 仮説⽴て データ収集 データ 加⼯&把握 計量経済学 モデル構築 推定
解釈 02 Rでの実装 ⽋損値処理 外れ値処理 多重共線性 内⽣性の検討 結果の頑健性 ※今回登場する新しいトピック.
11 R studioの準備 前回のプロジェクトを⽴ち上げます.サブゼミ_0507.Rprojをクリック! 前回の続きになっているはずです. 仮説 ⽴て 収集 把握 モデル
推定 解釈 ※画像ではサブゼミ0507になっていますが,R Lectureです.
データの把握:⽋損値 基本統計量から⽋損しているデータがあるかどうか確認してみましょう! 2つの変数(⺟親と⽗親の教育年数)に⽋損値が含まれているみたいですね. 仮説 ⽴て 収集 把握 モデル 推定 解釈
# dfというデータに含まれている変数について,基本統計量を算出する# summary(df) 12 【⽋損値への対応プロセス】(重要!) ①⽋損していることに意味があるかどうかを検討 - ⽋損値に意味がある場合はデータの仕様書に書いてあることが多いです. ②意味があればそのように処理,意味がなければ⽋損を含むデータを除外あるいは補完することが多いです
データの加⼯:⽋損値処理 今回は,共に最⼩値が3年であることから, ⽋損値は教育年数が0年(=教育を受けていない)という解釈としましょう. 仮説 ⽴て 収集 加⼯ モデル 推定 解釈
#⽋損値を含むデータは教育を受けていないと表現できます # # ⽋損値に0を代⼊する.# df[is.na(df)] <- 0 ・特定の変数の⽋損値に0を代⼊する場合は以下の様に書く(mother_eduの⽋損値を0とする場合) df$mother_edu[is.na(df$mother_edu)] <- 0 ・⽋損値を含むデータを削除する場合は以下の様に書く na.omit(df) 13
データの把握:外れ値 おかしい値がデータに含まれてはいないか? 基本統計量やヒストグラムを作って,じっくりデータを⾒てみよう. 仮説 ⽴て 収集 把握 モデル 推定 解釈
# 復習 # # dfというデータの中のworking_hoursという列に関して,ヒストグラムを作成する # hist(df$working_hours) ・変数が何を意味しているのかを整理してからデータを⾒てみることがポイントです. ・例えば年齢の場合.⼤体0~130歳くらいをとるよな,でも賃⾦のデータだから16〜70くらいかな.と想定してから データを⾒てみましょう.最⼤値と最⼩値をチェックすればおかしい値があるかどうかわかりますね. 14
データの加⼯:外れ値処理 労働時間(working_hours)に0時間という値が⼊っているのが気になる. 今回は賃⾦を説明したいので,働いているか否かは区別したい. 仮説 ⽴て 収集 加⼯ モデル 推定 解釈
# 労働時間を元に,働いているかどうかを⽰すダミー変数”working_dummy”を作成する # # 労働時間が0時間より⻑ければ1をとり,0時間ならば0をとるダミー変数# df$working_dummy <- ifelse(df$working_hours>0, 1, 0) ・ダミー変数とは,質的な変化(今回だと働いているかどうかの2択)を分析する時に使⽤する変数です. 0と1をとるので,ダミー変数のパラメータはその変化分を⽰します. ・ifelseの括弧の中はこんな仕組みです. ifelse(条件式, 条件式を満たす場合にとる値, 条件式を満たさない場合に取る値) 15
多重共線性の観点から,強い相関のある説明変数があるか確認しましょう. 今回はworking_dummyとworking_hoursの相関が強いので除きますか 仮説 ⽴て 収集 処理 モデル 推定 解釈 #
dfに含まれる変数どうしのそ相関係数を出⼒する cor(df) ・working_hoursとageの相関係数は-0.03311…とわかる ・強い相関に明確な基準はないです.相関係数が0.7, 0.8以上 あると怪しいかも.VIF統計量が10以上だと怪しいという概念 もあります. 16 計量経済学モデル構築:多重共線性の確認
変数が多いと結構みづらいですね. こんな時は可視化してあげると理解しやすいです. 仮説 ⽴て 収集 処理 モデル 推定 解釈 #
相関係数を図に起こすこともできる # install.packages('psych') library(psych) cor.plot(cor(df)) ・Rにはパッケージやライブラリという便利なシステムがあります. 賢い誰かさんが作ってくれたシステムを無料で使えます. ・今回はpsychという⼼理統計の分野でよく使われるライブラリを 使ってみました. 17 計量経済学モデル構築:多重共線性の確認
仮説 ⽴て 収集 処理 モデル 推定 解釈 18 計量経済学モデル構築:内⽣性 ⽋落変数バイアス
逆の因果 このデータにはないですが, 賃⾦は個⼈の能⼒に⼤きく依存する気がします 定量的な評価も難しいところですね. 個⼈の能⼒という⽋落変数に対して どのように対応するかは腕の⾒せ所ですね. 今回は,内⽣性の観点からnumber_kidsとworking_hoursは 説明変数から除いた⽅が良さそうですね.再来週くらいに対処しましょう. 賃⾦が⾼いから養える⼦供の数が増える という逆の因果関係が⽣じています. また,賃⾦が⾼いので⻑く働こうとする インセンティブもありそうですね. ※今回の推定は練習なので,厳密性には⽋けます.御容赦を.
19 計量経済学モデル構築:重回帰分析 今回は以下のようなモデルを考えます. パラメータを推定していきましょう. _ = + × + ×
+ ×_ + ×_ + ×_ + 仮説 ⽴て 収集 把握 モデル 推定 解釈 ・_ : 番⽬の⼈の賃⾦, : 番⽬の⼈の教育年数, : 番⽬の⼈の年齢 _ : 番⽬の⼈が働いているか否かを⽰すダミー変数, _ : 番⽬の⼈の⺟親の教育年数, _ : 番⽬の⼈の⽗親の教育年数 ・今回はバイアスが起こりそうな変数を説明変数から除外したが,それぞれ対処法もあります.(ここが腕の⾒せ所)
20 推定:重回帰分析 Rで重回帰分析を実⾏してみましょう! 仮説 ⽴て 収集 把握 モデル 推定 解釈
# 先ほどのモデルに従い重回帰分析を実⾏して,その結果をout2という名前の箱に格納 # out2 <- lm(data = df, hourly_wage ~ education + age + working_dummy + mother_edu + father_edu) ・重回帰分析のコードは以下のようなイメージ. out1 <- lm (data = データの名前, 被説明変数 ~ 説明変数① +説明変数② +説明変数③…)
21 解釈:重回帰分析の結果の⾒⽅ 分析結果を確認してみましょう! 教育年数の限界効果はどのようになりましたか? 仮説 ⽴て 収集 把握 モデル 推定
解釈 # 分析結果を出す # summary(out2) _ = −. + . × + . × +. ×_ −. ×_ − . ×_ + ・他の説明変数の値が⼀定の時,教育年数が1年増加すると,賃⾦は0.391624ドル増加する.(有意⽔準1%) ・前回の重回帰モデルと⽐較すると教育年数の限界効果はさほど変わらず,決定係数が改善された. ・これまで計3回の分析を実施してきたが,その分析でも教育年数の賃⾦への限界効果は統計的有意に正の値をとっていた. →仮説は確かに検証されそう.(結果の頑健性)
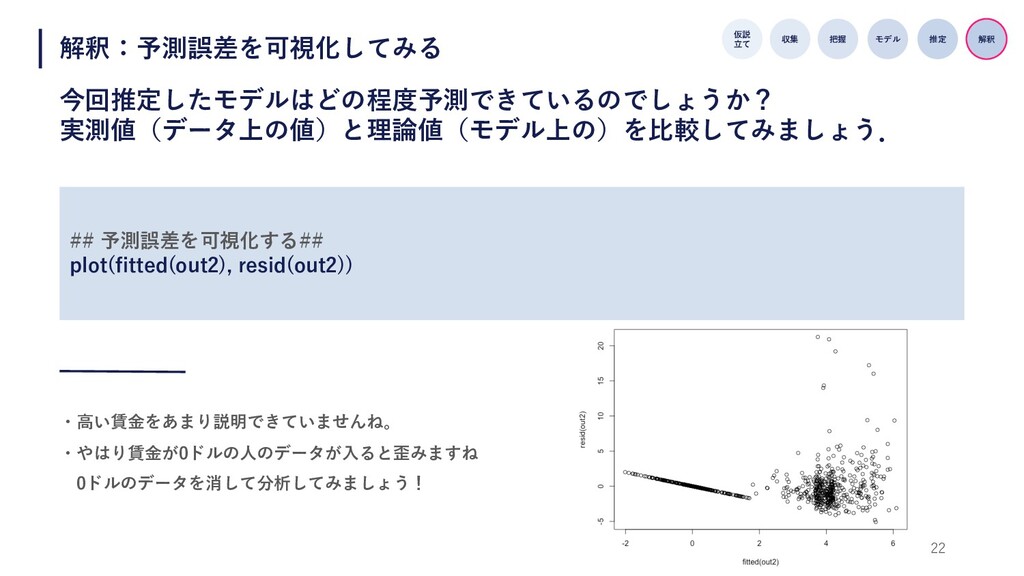
22 解釈:予測誤差を可視化してみる 今回推定したモデルはどの程度予測できているのでしょうか? 実測値(データ上の値)と理論値(モデル上の)を⽐較してみましょう. 仮説 ⽴て 収集 把握 モデル 推定
解釈 ・⾼い賃⾦をあまり説明できていませんね。 ・やはり賃⾦が0ドルの⼈のデータが⼊ると歪みますね 0ドルのデータを消して分析してみましょう! ## 予測誤差を可視化する## plot(fitted(out2), resid(out2))
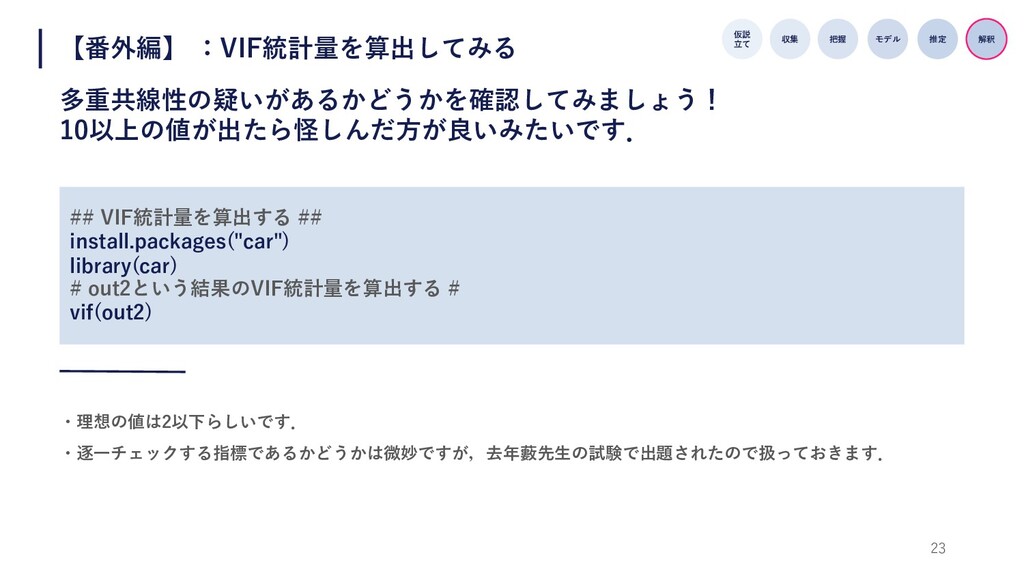
23 【番外編】 :VIF統計量を算出してみる 多重共線性の疑いがあるかどうかを確認してみましょう! 10以上の値が出たら怪しんだ⽅が良いみたいです. 仮説 ⽴て 収集 把握 モデル
推定 解釈 ・理想の値は2以下らしいです. ・逐⼀チェックする指標であるかどうかは微妙ですが,去年藪先⽣の試験で出題されたので扱っておきます. ## VIF統計量を算出する ## install.packages("car") library(car) # out2という結果のVIF統計量を算出する # vif(out2)
【番外編】データの加⼯:データの抽出 賃⾦が0であるデータを抜いた新しいデータを作成してみよう. subsetというコマンドを使うと簡単に抽出することが出来ます! 仮説 ⽴て 収集 加⼯ モデル 推定 解釈
# dfというデータの中から賃⾦が0ではないデータを抜き出して新しくdf_newという名とする# df_new <- subset(df, hourly_wage >0) ・コードの中⾝は以下のような感じです (新しいデータ名) <- subset(元のデータ名, 抽出する条件) ・df_newというデータを使って,もう⼀度重回帰分析をやってみましょう! どのような変化が起こったか考察してみましょう! 24
25 Goal & Agenda 1.重回帰分析で気をつけるポイントを理解する 2.データの特徴を把握し,うまく対処出来るようになる 02 Rでの実装 01 重回帰分析
の注意事項 03 重回帰分析 のまとめ
26 重回帰分析とは? 03 重回帰分析のまとめ 説明変数を複数加え回帰モデルを構築することで, 他の要因をコントロールした上で,仮説を検証することが出来ます. = + ×, +
×, + ×, … +
27 分析の流れ ポイントはデータの特徴を掴むこと&バイアスを気にすることの2点 仮説⽴て データ収集 データ 加⼯&把握 計量経済学 モデル構築 推定
解釈 基本統計量・グラフ作成 ⽋損値・外れ値は? 多重共線性は? 逆の因果・⽋落変数は? 仮説との整合性は? 結果の頑健性は? 仮説の背景は? 03 重回帰分析のまとめ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}