Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Rで計量経済学#5 プロビット・ロジットモデル
Search
TomoyaOzawa-DA
August 15, 2020
Education
600
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Rで計量経済学#5 プロビット・ロジットモデル
所属している研究会で扱った資料になります。
内容について間違いがある可能性もありますので、その際にはご連絡ください。
TomoyaOzawa-DA
August 15, 2020
More Decks by TomoyaOzawa-DA
See All by TomoyaOzawa-DA
Rで計量経済学#0 事前準備
tom01
0
280
Rで計量経済学#1 単回帰分析
tom01
0
690
Rで計量経済学#2 重回帰分析
tom01
0
210
Rで計量経済学#3 重回帰分析とバイアス
tom01
0
400
Rで計量経済学#4 操作変数法
tom01
0
2.5k
Rで計量経済学#6 パネルデータ分析
tom01
0
6.3k
Other Decks in Education
See All in Education
Visionary Initiative: Materials-Positive Society — Evolving “Things,” empowering a positive society | Science Tokyo
sciencetokyo
PRO
0
110
Public Space Is Not For Sale
drikkes
0
120
Info Session MSc Computer Science & MSc Applied Informatics
signer
PRO
0
300
Data Physicalisation - Lecture 9 - Next Generation User Interfaces (4018166FNR)
signer
PRO
1
1.1k
Interaction - Lecture 10 - Information Visualisation (4019538FNR)
signer
PRO
0
2.7k
生成AI時代の情報発信
molmolken
0
140
Course Review - Lecture 13 - Next Generation User Interfaces (4018166FNR)
signer
PRO
0
2.3k
Πλουτοκρατία: Η Τυραννία του Μαμμωνά και η Μεταανθρώπινη Δουλεία
amethyst1
0
270
View Manipulation and Reduction - Lecture 9 - Information Visualisation (4019538FNR)
signer
PRO
1
2.7k
✅ レポート採点基準 / How Your Reports Are Assessed
yasslab
PRO
0
380
焦燥を平穏に変えるエンジニアのための哲学
ichimichi
6
4.7k
輻射安全管理系統2.0暨輻防e++學園平台說明會
aecrp
0
1.4k
Featured
See All Featured
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Navigating Team Friction
lara
192
16k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.5k
The agentic SEO stack - context over prompts
schlessera
0
830
Designing for humans not robots
tammielis
254
26k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
430
Side Projects
sachag
455
43k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Google's AI Overviews - The New Search
badams
0
1.1k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
630
Transcript
R Lecture #5 Tomoya Ozawa 離散選択モデル -2択に確率で答える-
2 Goal & Agenda 1.どういう仮説を検証する際に⼆項モデルが役⽴つかを理解する 2.離散選択モデルをRで実装できるようになる 02 Rでの実装 01 離散選択
モデル 03 三⽥論 コンビニ班 ※⼭本(2015)P. 104- 参照.
3 Goal & Agenda 1.どういう仮説を検証する際に⼆項モデルが役⽴つかを理解する 2.離散選択モデルをRで実装できるようになる 02 Rでの実装 01 離散選択
モデル 03 三⽥論 コンビニ班 ※⼭本(2015)P. 104- 参照.
4 01 離散選択モデルとは? 今までは被説明変数が賃⾦,賃貸料など連続した数値でしたが, {参⼊する,参⼊しない}といった2値のみをとるケースも少なくありません. ⼈⼝が1000⼈増加すると,企業が参⼊する”確率”がどの程度⾼まるのか?といった仮説が考えられますね. この”確率”は重回帰分析で推定することが出来るのでしょうか? 振り返り
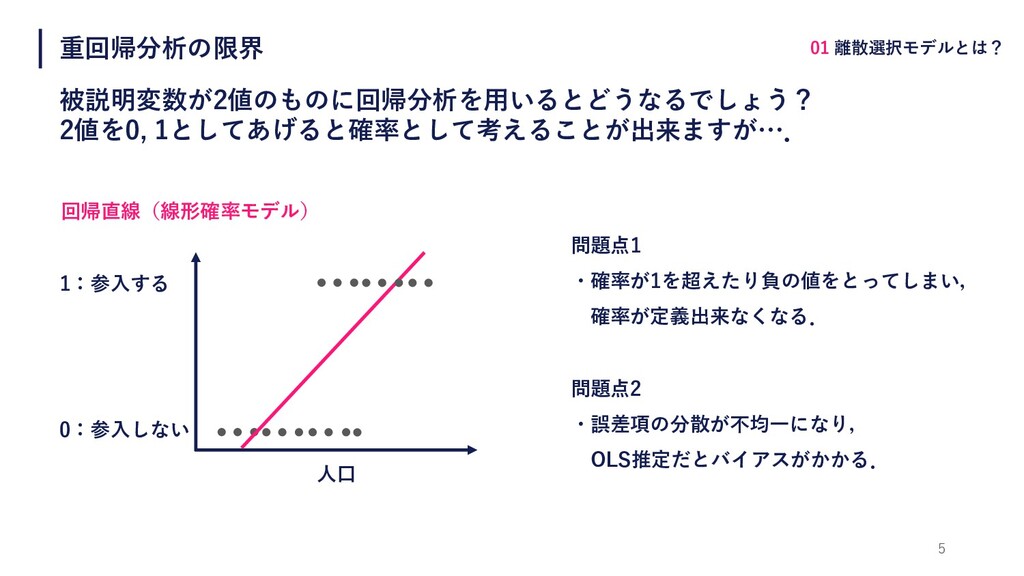
重回帰分析の限界 被説明変数が2値のものに回帰分析を⽤いるとどうなるでしょう? 2値を0, 1としてあげると確率として考えることが出来ますが…. 5 ⼈⼝ 1:参⼊する 0:参⼊しない 問題点1 ・確率が1を超えたり負の値をとってしまい,
確率が定義出来なくなる. 問題点2 ・誤差項の分散が不均⼀になり, OLS推定だとバイアスがかかる. 回帰直線(線形確率モデル) 01 離散選択モデルとは?
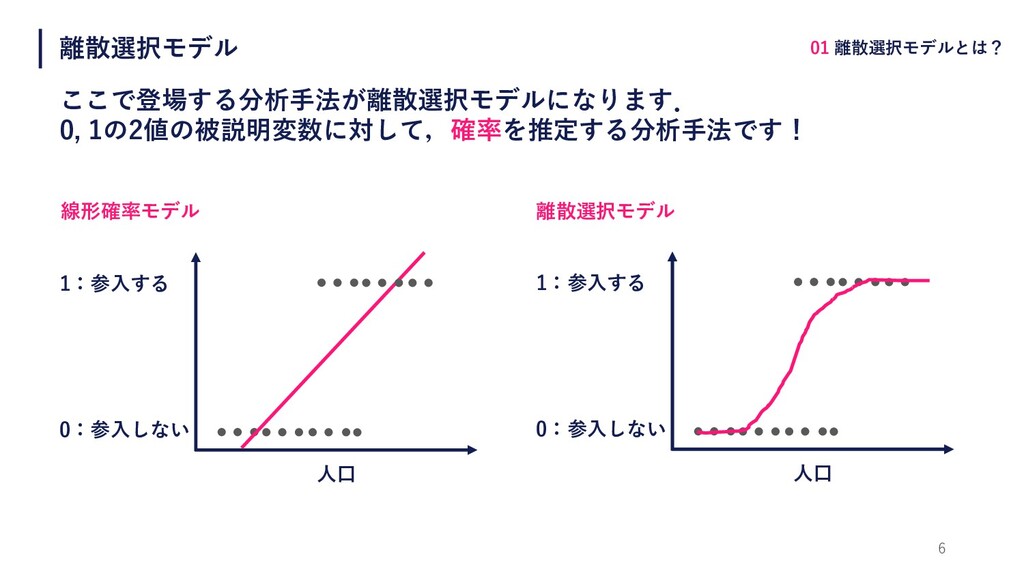
離散選択モデル ここで登場する分析⼿法が離散選択モデルになります. 0, 1の2値の被説明変数に対して,確率を推定する分析⼿法です! 6 ⼈⼝ 1:参⼊する 0:参⼊しない 線形確率モデル 01
離散選択モデルとは? ⼈⼝ 1:参⼊する 0:参⼊しない 離散選択モデル
離散選択モデル:数式でのイメージ 消費者が商品を購⼊するか否かを数式で捉えてみましょう. 離散選択モデルで書くと, ∗が商品から得られる効⽤に相当しますね. 7 01 離散選択モデルとは? = # ∶
購入する. ∶ 購入しない. とします. ∗ = + ×価格 + ×質 … = ( ( ∗ ≥ ) ( ∗ < ) = = ( + ×価格 + ×質 … ) 効⽤が以上であれば購⼊することを⽰すと, 選択確率は以下の式で推定する. ※ は関数を表しています.推定するモデルによって異なります.
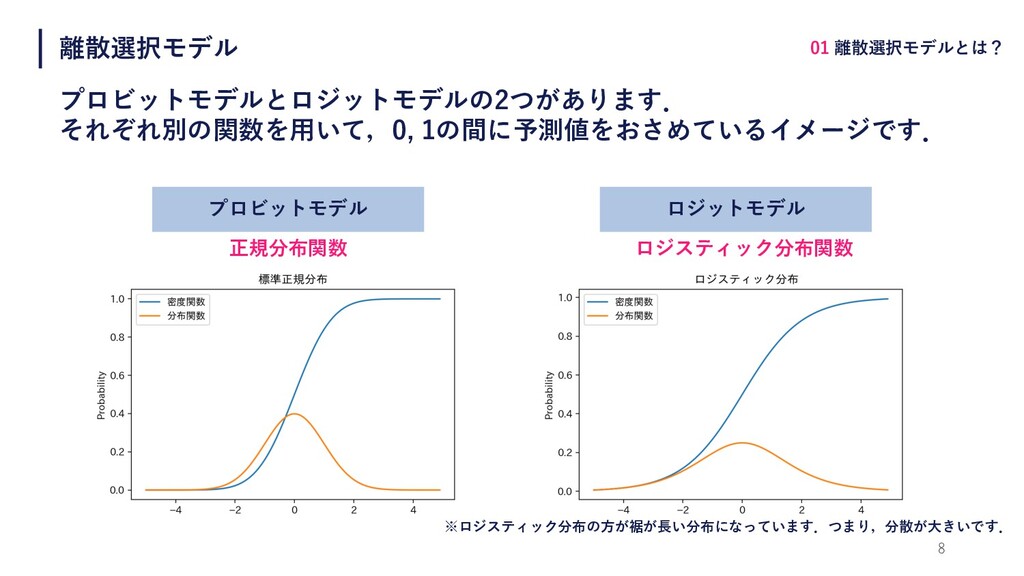
離散選択モデル プロビットモデルとロジットモデルの2つがあります. それぞれ別の関数を⽤いて,0, 1の間に予測値をおさめているイメージです. 8 01 離散選択モデルとは? プロビットモデル ロジットモデル 正規分布関数
ロジスティック分布関数 ※ロジスティック分布の⽅が裾が⻑い分布になっています.つまり,分散が⼤きいです.
離散選択モデル パラメータの推定⽅法とその解釈がOLS推定とは異なります. 解釈については実際に分析しながら理解していきましょう. 9 01 離散選択モデルとは? 推定⽅法:最尤法 解釈:平均限界効果 尤度関数を最⼤化させる パラメータを推定しています.
尤度関数はモデルがどの程度 ⼿元のデータを再現するかを⽰します. パラメータをそのまま解釈する ことは出来ません. 平均的にどのくらい確率が 変化するのかを⽰す値になります. ※平均限界効果の他にも期待限界効果がある.
【応⽤編】最尤法とは? 最尤法とは,モデルから⼿元のデータが現れる確率を最⼤にするように パラメータを探索する⼿法 10 01 離散選択モデルとは? = × × …×
= , , ⋯ , ⼿元のデータがn個あるとする パラメータをとすると尤度関数は以下のように書ける この尤度関数を最⼤化するパラメータを計算する. (計算する際は対数尤度関数.指数があると⼤変だから) ※ :パラメータがである時にデータ が予測される確率.条件付き確率ですね! max () = 7 (
11 Goal & Agenda 1.どういう仮説を検証する際に⼆項モデルが役⽴つかを理解する 2.離散選択モデルをRで実装できるようになる 02 Rでの実装 01 離散選択
モデル 03 三⽥論 コンビニ班 ※⼭本(2015)P. 104- 参照.
12 今⽇のTry ドミナント戦略が取られていれば,この仮説の通りになっているはず… Familymartの参⼊⾏動に関するデータを⽤いて,検証してみます. 2011年〜2018年の沖縄のコンビニエンスストア市場において, ⾃社の店舗が多い地域ほど出店確率が⾼まるのでは?という仮説を検証しよう! 02 Rでの実装
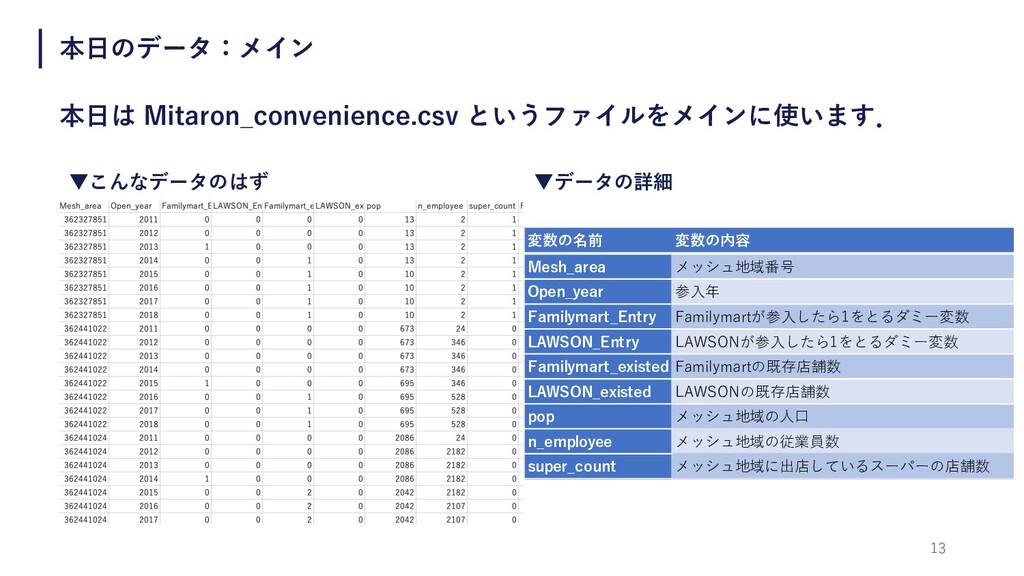
13 本⽇のデータ:メイン 本⽇は Mitaron_convenience.csv というファイルをメインに使います. ▼データの詳細 ▼こんなデータのはず 変数の名前 変数の内容 Mesh_area
メッシュ地域番号 Open_year 参⼊年 Familymart_Entry Familymartが参⼊したら1をとるダミー変数 LAWSON_Entry LAWSONが参⼊したら1をとるダミー変数 Familymart_existed Familymartの既存店舗数 LAWSON_existed LAWSONの既存店舗数 pop メッシュ地域の⼈⼝ n_employee メッシュ地域の従業員数 super_count メッシュ地域に出店しているスーパーの店舗数
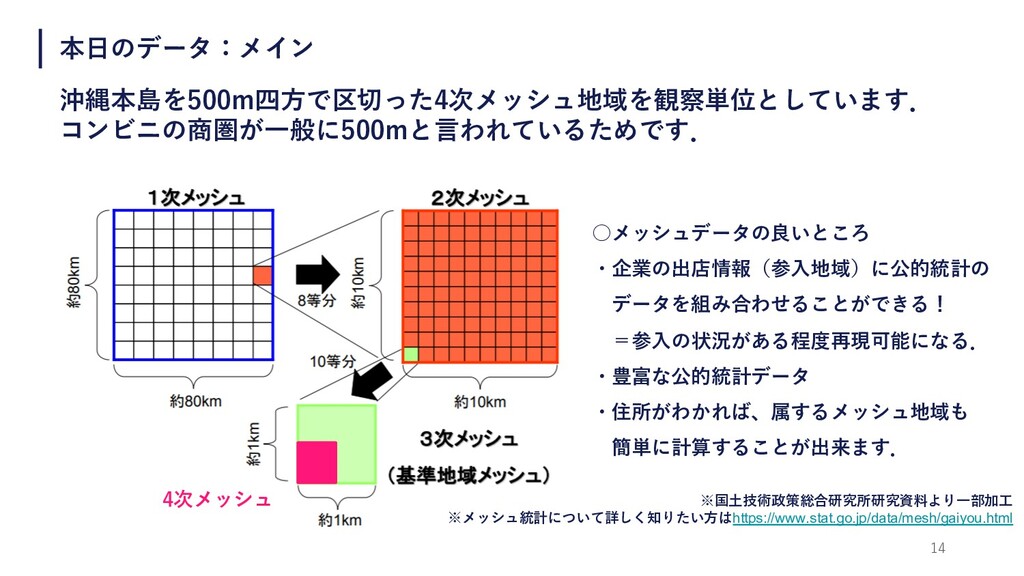
14 本⽇のデータ:メイン 沖縄本島を500m四⽅で区切った4次メッシュ地域を観察単位としています. コンビニの商圏が⼀般に500mと⾔われているためです. 4次メッシュ ※国⼟技術政策総合研究所研究資料より⼀部加⼯ ※メッシュ統計について詳しく知りたい⽅はhttps://www.stat.go.jp/data/mesh/gaiyou.html ◦メッシュデータの良いところ ・企業の出店情報(参⼊地域)に公的統計の データを組み合わせることができる!
=参⼊の状況がある程度再現可能になる. ・豊富な公的統計データ ・住所がわかれば、属するメッシュ地域も 簡単に計算することが出来ます.
15 本⽇のデータ:おまけ Familymart_mesh.csv というファイルもちょっと使います. Google Driveのサブゼミ -> R講義 -> Data
にあります. ▼データの詳細 ▼こんなデータのはず 変数の名前 変数の内容 store_name 店舗名 store_address 参⼊した場所の住所 opening_date 参⼊した⽇付 opening_year 参⼊した年 longitude 経度 latitude 緯度
【おまけ編】データの把握:地理データの可視化 Rでは簡単に位置情報を可視化することが出来ます. 緯度と経度のデータを⽤いてプロットしてみましょう! 仮説 ⽴て 収集 把握 モデル 推定 解釈
# leafletというライブラリを今回は使⽤します # install.packages("leaflet") library(leaflet) # R上で地図を作成します # map <- leaflet(df_map) %>% addTiles() # 経度と緯度で場所を指定して,プロットします.⾊はFamilymartなので緑⾊にしてみました# map %>% addCircles(lng = ~ longitude, lat = ~latitude, color = "green") 16
17 計量経済学モデル構築:モデル 今回検証したいことをモデル化してみましょう. ⾃社の参⼊状況に加えて,地域特性を⽰す⼈⼝を説明変数に加えてみます. 仮説 ⽴て 収集 把握 モデル 推定
解釈 ・この時, ∗は参⼊した際に得られる期待利潤にようなものを⽰しているイメージですね。 期待利潤 ∗がより⼤きければ参⼊の意思決定をするみたいな感じです. _ = = ( + ×_ + × ) ∗ = + ×_ + × _ = ( ∶ 参入する ( ∗ ≥ ) ∶ 参入しない ( ∗ < )
18 推定:プロビットモデル 仮説 ⽴て 収集 把握 モデル 推定 解釈 #
プロビットモデルで推定して,その結果をprobit1という名前の箱に格納 # probit1 = glm( Familymart_Entry ~ Familymart_existed + pop, family = binomial(link = "probit"), data = df_fam) まずはプロビットモデルで推定してみましょう! ・glm関数を使って離散選択モデルを推定します. glm(被説明変数 ~ 説明変数① + 説明変数②…, family = binomial(link = “logit” or = ”probit“ ), data = データ名 )
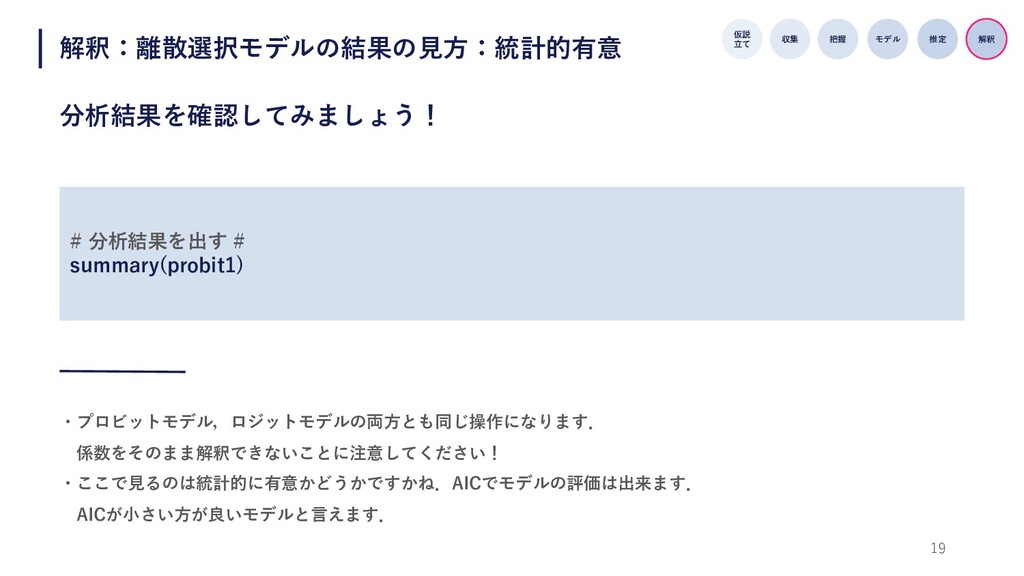
19 解釈:離散選択モデルの結果の⾒⽅:統計的有意 分析結果を確認してみましょう! 仮説 ⽴て 収集 把握 モデル 推定 解釈
# 分析結果を出す # summary(probit1) ・プロビットモデル,ロジットモデルの両⽅とも同じ操作になります. 係数をそのまま解釈できないことに注意してください! ・ここで⾒るのは統計的に有意かどうかですかね.AICでモデルの評価は出来ます. AICが⼩さい⽅が良いモデルと⾔えます.
20 解釈:離散選択モデルの結果の⾒⽅:平均限界効果 係数はそのまま解釈できないので,marginsというライブラリを使⽤して, 限界効果を求めてみます. 仮説 ⽴て 収集 把握 モデル 推定
解釈 # 平均限界効果を出す # install.packages("margins") library(margins) margins(probit1) summary(margins(probit1)) 【平均限界効果の解釈の仕⽅】 ・平均限界効果は,Xが1単位増加した際に確率が平均的にどのくらい変動するかを⽰したものです. ・既存のファミリーマートの店舗数が1店舗増えると,平均して参⼊する確率が4.2%低下する. ・⼈⼝が1⼈増加した場合,参⼊する確率は2.068e-03%増加する.つまり⼈⼝が1000⼈増えたら,2.068%増加する.
21 解釈:離散選択モデルの結果の⾒⽅:精度 離散選択モデルでは決定係数は算出されません. その代わりに擬似決定係数というものがあります. 仮説 ⽴て 収集 把握 モデル 推定
解釈 # 分析結果を出す # install.packages("BaylorEdPsych") library(BaylorEdPsych) PseudoR2(probit1) ・擬似決定係数の他にも対数尤度や混同⾏列に基づく正解率, F値などがあります.
22 推定:ロジットモデル 仮説 ⽴て 収集 把握 モデル 推定 解釈 #
プロビットモデルで推定して,その結果をprobit1という名前の箱に格納 # logit1 = glm( Familymart_Entry ~ Familymart_existed + pop, family = binomial(link = "logit"), data = df_fam) 次はロジットモデルで推定してみましょう! linkにlogitと指定すれば,ロジットモデルになります. ・glm関数を使って離散選択モデルを推定します. glm(被説明変数 ~ 説明変数① + 説明変数②…, family = binomial(link = “logit” or = ”probit“ ), data = データ名 )
23 おまけ:モデル 今までのモデルに加えて,競合の参⼊状況も考慮に⼊れて分析してみましょう. 仮説 ⽴て 収集 把握 モデル 推定 解釈
・2019年にセブンイレブンが沖縄に初出店したので,競合はLAWSONだけなんです. その他の変数も加えてみると,⾯⽩いかもしれません. _ = = ( + ×_ + ×_ + × ) ∗ = + ×_ + ×_ +× _ = ( ∶ 参入する ( ∗ ≥ ) ∶ 参入しない ( ∗ < )
24 Goal & Agenda 1.どういう仮説を検証する際に⼆項モデルが役⽴つかを理解する 2.離散選択モデルをRで実装できるようになる 02 Rでの実装 01 離散選択
モデル 03 三⽥論 コンビニ班 ※⼭本(2015)P. 104- 参照.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}