Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Rで計量経済学#2 重回帰分析
Search
TomoyaOzawa-DA
August 15, 2020
Education
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Rで計量経済学#2 重回帰分析
所属している研究会で扱った資料になります。
内容について間違いがある可能性もありますので、その際にはご連絡ください。
TomoyaOzawa-DA
August 15, 2020
More Decks by TomoyaOzawa-DA
See All by TomoyaOzawa-DA
Rで計量経済学#0 事前準備
tom01
0
280
Rで計量経済学#1 単回帰分析
tom01
0
690
Rで計量経済学#3 重回帰分析とバイアス
tom01
0
400
Rで計量経済学#4 操作変数法
tom01
0
2.5k
Rで計量経済学#5 プロビット・ロジットモデル
tom01
0
600
Rで計量経済学#6 パネルデータ分析
tom01
0
6.3k
Other Decks in Education
See All in Education
From Days to Minutes: How We Taught an AI to Onboard 50+ Tenants on our AI Features
mfcabrera
0
190
!コスパよくインターンに受かる方法!
ruribou
1
280
DECADE_ゴルフ_コースマネジメント完全ガイド.pdf
ozekinote
0
110
Visionary Initiative: Future Intelligence 「未来の知性と社会の礎を築く」|Science Tokyo(東京科学大学)
sciencetokyo
PRO
0
580
2026年度春学期 統計学 第3回 クロス集計と感度・特異度,データの可視化 (2026. 4. 23)
akiraasano
PRO
0
160
[2026前期火5] 論理学(京都大学文学部 前期 第3回)「形式言語と四つのキーワード:メタ・構成・意味論・ハーモニー」
yatabe
0
570
0526
cbtlibrary
0
180
AI 時代に KDDIアイレットで 「突き抜ける」ための働き方
danishi
0
110
生成AI時代のエンジニア育成について考えてみた
akasan
0
160
Implicit and Cross-Device Interaction - Lecture 10 - Next Generation User Interfaces (4018166FNR)
signer
PRO
2
2.3k
Visionary Initiative: Future Intelligence — Laying the foundations for the future of science, intelligence, and society | Science Tokyo
sciencetokyo
PRO
0
100
参加制約理論
roadofhope
0
130
Featured
See All Featured
How to train your dragon (web standard)
notwaldorf
97
6.7k
Six Lessons from altMBA
skipperchong
29
4.3k
Into the Great Unknown - MozCon
thekraken
41
2.6k
KATA
mclloyd
PRO
35
15k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
880
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
250
Test your architecture with Archunit
thirion
1
2.3k
How to make the Groovebox
asonas
2
2.2k
How STYLIGHT went responsive
nonsquared
100
6.2k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Prompt Engineering for Job Search
mfonobong
0
360
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
180
Transcript
R Lecture #2 Tomoya Ozawa 単回帰分析から重回帰分析へ -ちょいとステップアップ-
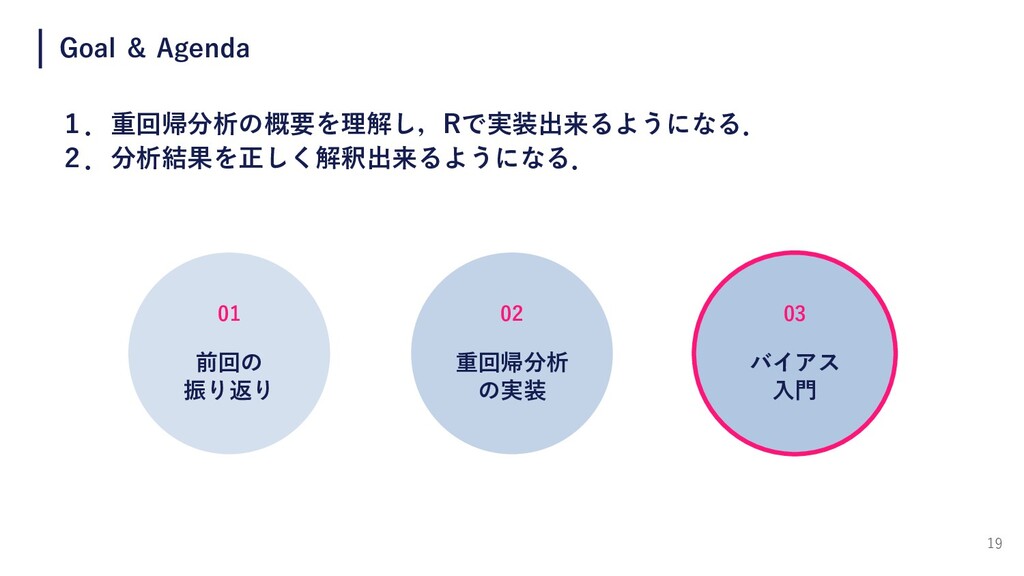
2 Goal & Agenda 1.重回帰分析の概要を理解し,Rで実装出来るようになる. 2.分析結果を正しく解釈出来るようになる. 02 重回帰分析 の実装 01
前回の 振り返り 03 バイアス ⼊⾨
3 Goal & Agenda 1.重回帰分析の概要を理解し,Rで実装出来るようになる. 2.分析結果を正しく解釈出来るようになる. 02 重回帰分析 の実装 01
前回の 振り返り 03 バイアス ⼊⾨
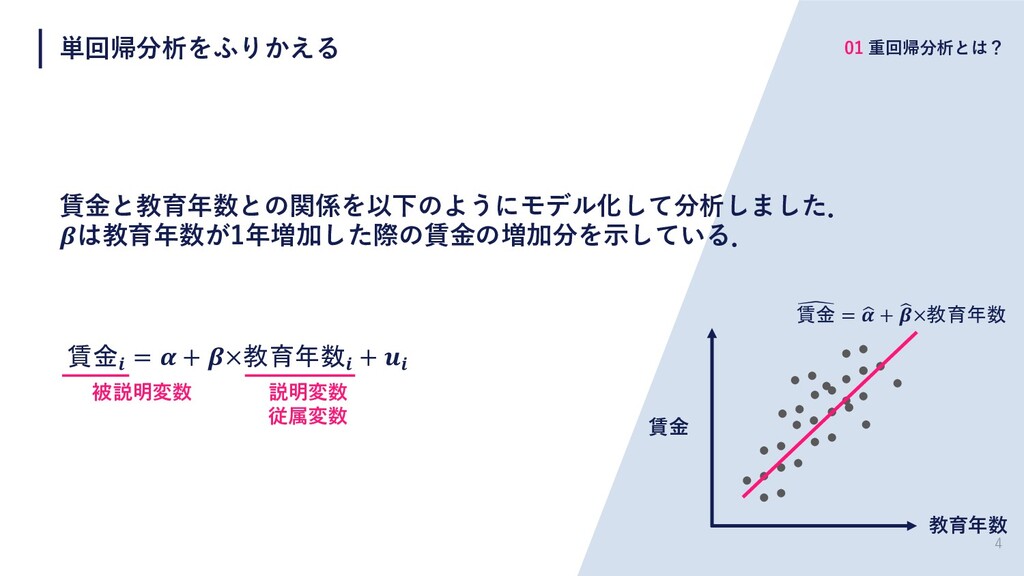
4 単回帰分析をふりかえる 01 重回帰分析とは? 賃⾦と教育年数との関係を以下のようにモデル化して分析しました. は教育年数が1年増加した際の賃⾦の増加分を⽰している. 賃金 = + ×教育年数
+ 被説明変数 説明変数 従属変数 教育年数 賃⾦ ! 賃金 = # + & ×教育年数
5 単回帰分析をふりかえる 01 重回帰分析とは? よくよく考えてみると 教育年数という1要因だけで賃⾦は決定されているのでしょうか? 例えば,以下の要因が考えられます. ・家庭状況(⼦供の数,親の学歴etc. ) ・労働環境(正規or⾮正規,労働時間etc.
) ・個⼈能⼒(もともとどんな能⼒を持っているのか?etc)
6 Goal & Agenda 1.重回帰分析の概要を理解し,Rで実装出来るようになる. 2.分析結果を正しく解釈出来るようになる. 02 重回帰分析 の実装 01
前回の 振り返り 03 バイアス ⼊⾨
7 今⽇のTry 他の要因を追加して分析することで,それらをコントロールすることが可能になります. 推定結果(限界効果: と表記されていたもの)はどうなるでしょうか? 各⾃で予想を⽴ててみましょう. 今回は賃⾦を決定する他の要因として,⼦供の数と労働時間を考慮して ”教育年数が増えると,賃⾦は増加するのでは?”という仮説を再度検証しよう! 02 Rでの実装
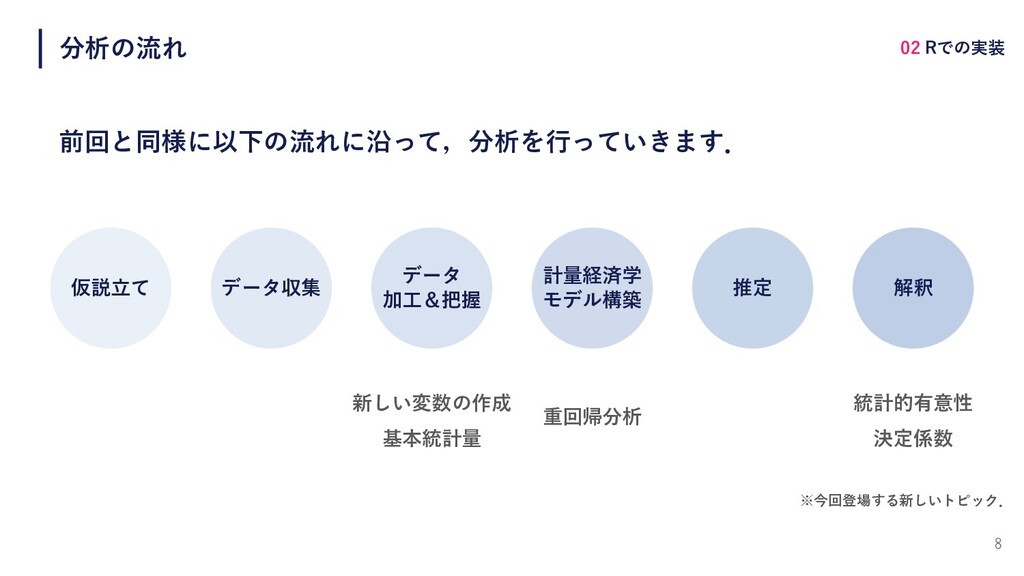
8 分析の流れ 前回と同様に以下の流れに沿って,分析を⾏っていきます. 仮説⽴て データ収集 データ 加⼯&把握 計量経済学 モデル構築 推定
解釈 02 Rでの実装 新しい変数の作成 基本統計量 重回帰分析 統計的有意性 決定係数 ※今回登場する新しいトピック.
9 R studioの準備 前回のプロジェクトを⽴ち上げます.R Lecture.Rprojをクリック! 前回の続きになっているはずです. 仮説 ⽴て 収集 把握
モデル 推定 解釈 ※画像ではサブゼミ0507になっていますが,R Lectureです.
10 データの加⼯:新しい変数作成 このデータには⼦供の数を⽰す変数が2つあります. 1つにまとめてnumber_kidsという新しい変数を作ってみよう. 仮説 ⽴て 収集 加⼯ モデル 推定
解釈 # 6歳未満の⼦供の数と18~6歳の⼦供の数の合計値を⽰すnumber_kidsという変数を作成する # df$number_kids <- df$number_kids_under6 + df$number_kids_6to18 # 新しい変数number_kidsが作成されているかどうか,データを確認してみる # View(df) ・View(df)の代わりに、head(df)というコードを書くと、 データの上から6⾏分が表⽰されます. ▼データの詳細
11 データの把握:ヒストグラム作成 新しく扱う変数である労働時間(working_hours)と⼦供の数(number_kids) にどのような値が⼊っているのか,グラフを作って⾒てみましょう! 仮説 ⽴て 収集 把握 モデル 推定
解釈 # dfというデータの中のworking_hoursという列に関して,ヒストグラムを作成する # hist(df$working_hours) ・number_kidsに関しては,各⾃で取り組んでみてください. ・plot.new() でエラー: figure margins too largeというエラーが出たら,右下のPlotsのエリアを広げてみてください!
データの把握:基本統計量 今回は基本統計量という指標を⽤いてデータを把握してみましょう. 基本統計量から先ほどのヒストグラムを想像出来るようになるといいですね. 仮説 ⽴て 収集 把握 モデル 推定 解釈
# dfというデータに含まれている変数について,基本統計量を算出する# summary(df) ・1st Qu.:第1四分位数 ・3rd Qu.:第3四分位数 ・Median:中央値(平均値と区別しましょう) ・NAʼs:⽋損している値(詳細は来週) 12
データの把握:平均値と中央値 平均値だけでデータの全体像を把握することはおすすめしません. 中央値まで捉えると,ざっくりデータの分布がわかります. 仮説 ⽴て 収集 把握 モデル 推定 解釈
# 実際のデータを使って確かめてみましょう # # 平均を算出.meanというコマンドを使います# mean(test$age_1) # 各列ごとにヒストグラムを作成して、データの分布を確認してみましょう# # 今回は同時に2つのグラフを出⼒してみましょう # par(mfrow=c(1,2)) hist(test$age_1) hist(test$age_2) ・ヒストグラムを同時に出すにはparというコマンドを⽤います.c(1, 2)で縦1個横2個で配置することを指定しています ・y軸の範囲は, hist()の中にylim = c(最⼩値, 最⼤値)と書くことで指定できます.e.g. ylim = c(0, 40), xlim = c(20, 100) 13
14 計量経済学モデル構築:重回帰分析 重回帰分析では,説明変数が複数あるモデルを考えている. , , , (パラメータという)をデータから推定していく. _ = +
× + ×_ + ×_ + 仮説 ⽴て 収集 把握 モデル 推定 解釈 ・_ : 番⽬の⼈の賃⾦, : 番⽬の⼈の教育年数, _ : 番⽬の⼈の労働時間, _ : 番⽬の⼈の⼦供の数 ・:教育年数が1年増加した際の賃⾦の増加分を⽰す.限界効果という. ・ :回帰式から算出された予測値と実際の値との差分を⽰す.誤差項という. ※これから英語表記にします.(カッコつけです)
15 推定:重回帰分析 Rで重回帰分析を実⾏してみましょう! 仮説 ⽴て 収集 把握 モデル 推定 解釈
# 被説明変数を賃⾦,説明変数を教育年数,労働時間,⼦供の数として重回帰分析を実⾏して,そ の結果をout1という名前の箱に格納します # out1 <- lm(data = df, hourly_wage ~ education + working_hours + number_kids ) ・重回帰分析のコードは以下のようなイメージです. out1 <- lm (data = データの名前, 被説明変数 ~ 説明変数① +説明変数② +説明変数③…)
16 解釈:重回帰分析の結果の⾒⽅ 分析結果を確認してみましょう! 教育年数の限界効果はどのようになりましたか? 仮説 ⽴て 収集 把握 モデル 推定
解釈 # 分析結果を出す # summary(out1) 推定値 統計的有意性(P値) (⾃由度調整済み)決定係数 _ = −. + . × + . ×_ − . ×_ この結果を先ほどのモデルに当てはめると… 労働時間と⼦供の数が⼀定の時(他の要因のコントロール), 教育年数が1年増加すると,賃⾦は0.3934232ドル増加する. ※e-09は10のマイナス9乗を⽰しています.要するにとても⼩さいということです.
17 解釈:統計的有意性(P値) 統計的に意味があるのかどうかに関してはP値(t値でも可)より判断します. 仮説 ⽴て 収集 把握 モデル 推定 解釈
・統計的有意とは,確率的に偶然ではないという意味.(ある程度確からしいということ.) ・P値とは,帰無仮説が正しい時に⼿元のデータよりも極端な分布のデータが⼿に⼊る確率.(≠帰無仮説が正しい確率) ・実際,パラメータについて帰無仮説 : = ,対⽴仮説 : ≠ として検定している.(⽇吉の統計学で扱ったはず) ・P値の扱いには注意したほうがよさそうです.(詳しくはアメリカ統計学会の声明を) P値 解釈 < . < . < . ⽔準1%で有意 ⽔準5%で有意 ⽔準10%で有意 先ほどの結果と照らし合わせると… : ⽔準1%で有意 _ : ⽔準1%で有意 _ : 統計的に有意ではない
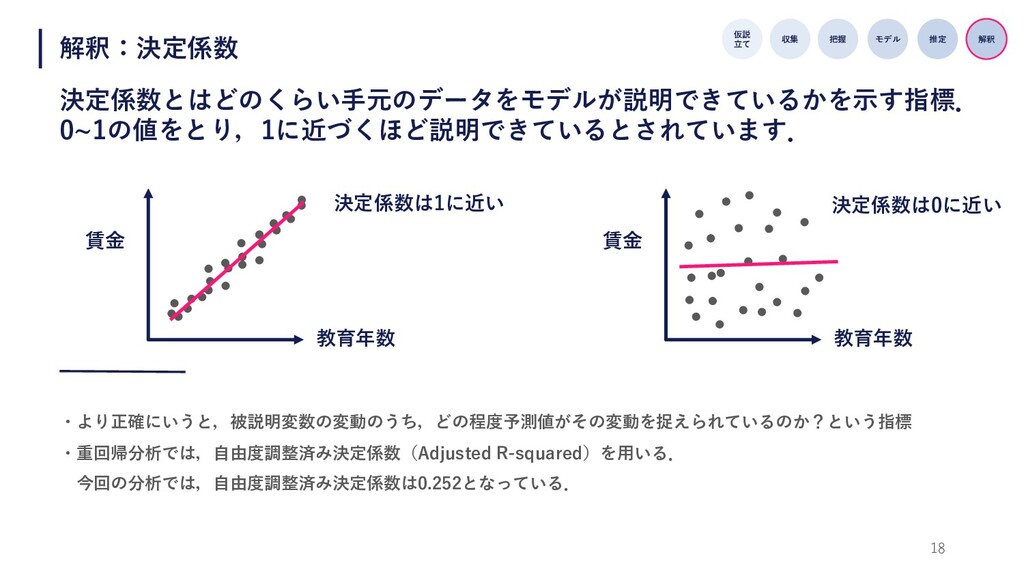
18 解釈:決定係数 決定係数とはどのくらい⼿元のデータをモデルが説明できているかを⽰す指標. 0~1の値をとり,1に近づくほど説明できているとされています. 仮説 ⽴て 収集 把握 モデル 推定
解釈 ・より正確にいうと,被説明変数の変動のうち,どの程度予測値がその変動を捉えられているのか?という指標 ・重回帰分析では,⾃由度調整済み決定係数(Adjusted R-squared)を⽤いる. 今回の分析では,⾃由度調整済み決定係数は0.252となっている. 賃⾦ 教育年数 賃⾦ 教育年数 決定係数は1に近い 決定係数は0に近い
19 Goal & Agenda 1.重回帰分析の概要を理解し,Rで実装出来るようになる. 2.分析結果を正しく解釈出来るようになる. 02 重回帰分析 の実装 01
前回の 振り返り 03 バイアス ⼊⾨
20 バイアスとは何か?なぜ注⽬しなくてはいけないのか? 最も適切な推定量と実際の推定量との乖離をバイアスといいます. バイアスは計量経済学モデルと推定⽅法の2点から⽣じてしまいます. モデルや推定⽅法には、いくつかの仮定が置かれている.これが満たされないとバイアスが⽣じます. 分析する際には,どんなバイアスが考えられるか?を忘れないでください.(モデリングの肝です) 今回は⼊⾨として今まで分析して得た2つの結果の差から,バイアスについて考えてみましょう. 03 バイアス⼊⾨
単回帰分析との⽐較からバイアスを考えてみる 単回帰分析と重回帰分析とで教育年数の賃⾦に対する限界効果が異なります. どうしてでしょう? 03 バイアス⼊⾨ −. + . × +
. ×_ − . ×_ + 21 _ = −. + . × + _ = 単回帰分析では限界効果が過剰に推定されてしまっています. →説明変数の不⾜により推定量が偏ることを⽋落変数バイアスといいます.
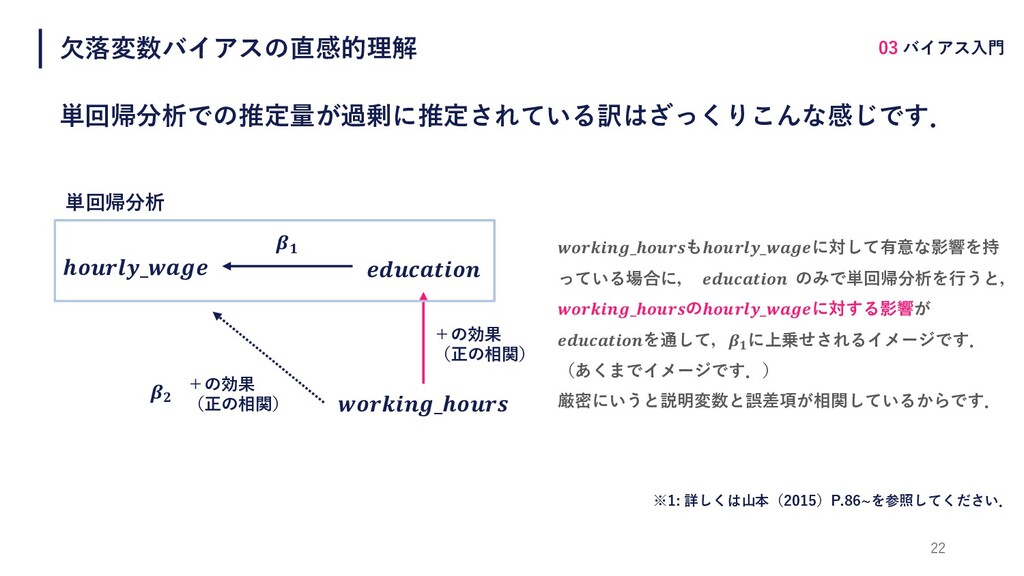
⽋落変数バイアスの直感的理解 03 バイアス⼊⾨ 22 _ _ _も_に対して有意な影響を持 っている場合に, のみで単回帰分析を⾏うと, _の_に対する影響が
を通して, に上乗せされるイメージです. (あくまでイメージです.) 厳密にいうと説明変数と誤差項が相関しているからです. 単回帰分析での推定量が過剰に推定されている訳はざっくりこんな感じです. +の効果 (正の相関) +の効果 (正の相関) 単回帰分析 ※1: 詳しくは⼭本(2015)P.86~を参照してください.
いつバイアスが起こるのか? 03 バイアス⼊⾨ 23 最⼩⼆乗推定量は以下の仮定のもとで算出されています. これらの仮定が満たされないとバイアスが⽣じてしまいます. ※1: ⼭本(2015)P.80より ※これらの仮定が完璧に満たされる時はほぼないはず.⽣じる可能性のあるバイアスを把握しておくことが⼤事だと思います. 誤差項の分散が均⼀であること
誤差項間で相関がないこと 仮定1.均⼀分散 仮定2.共分散ゼロ 仮定3.説明変数と独⽴ 誤差項と説明変数との間で相関がないこと 誤差項の仮定1 この仮定を満たす最⼩⼆乗推定量をBLUE(Best Linear Unbiased Estimator)といいます.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}