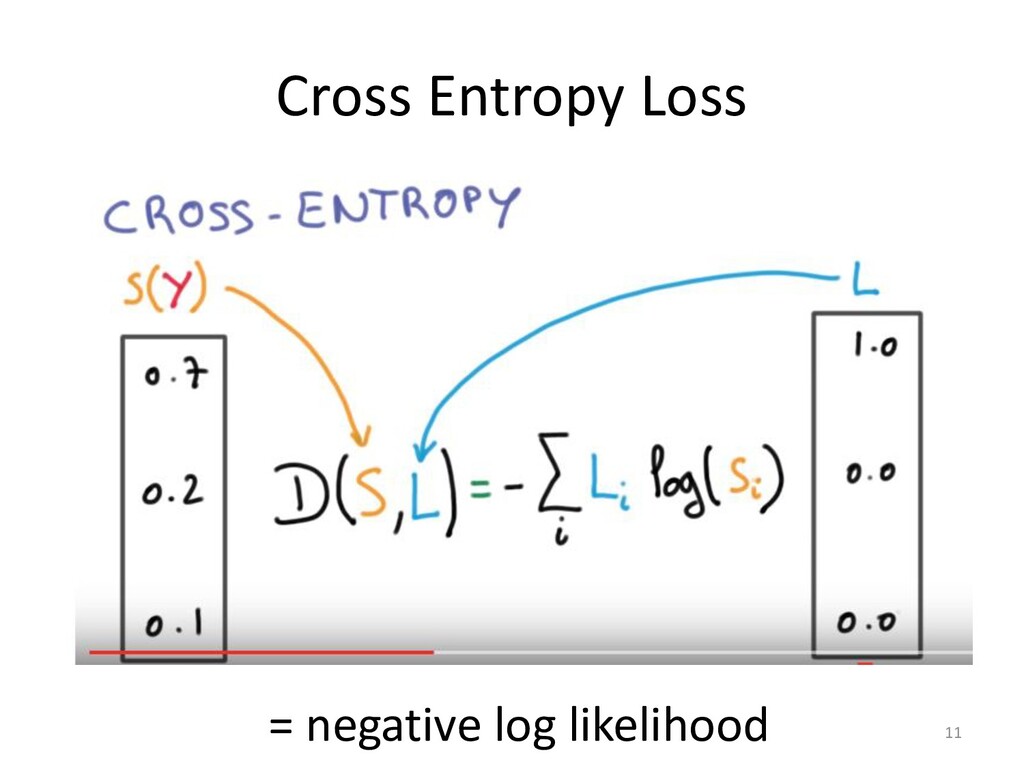
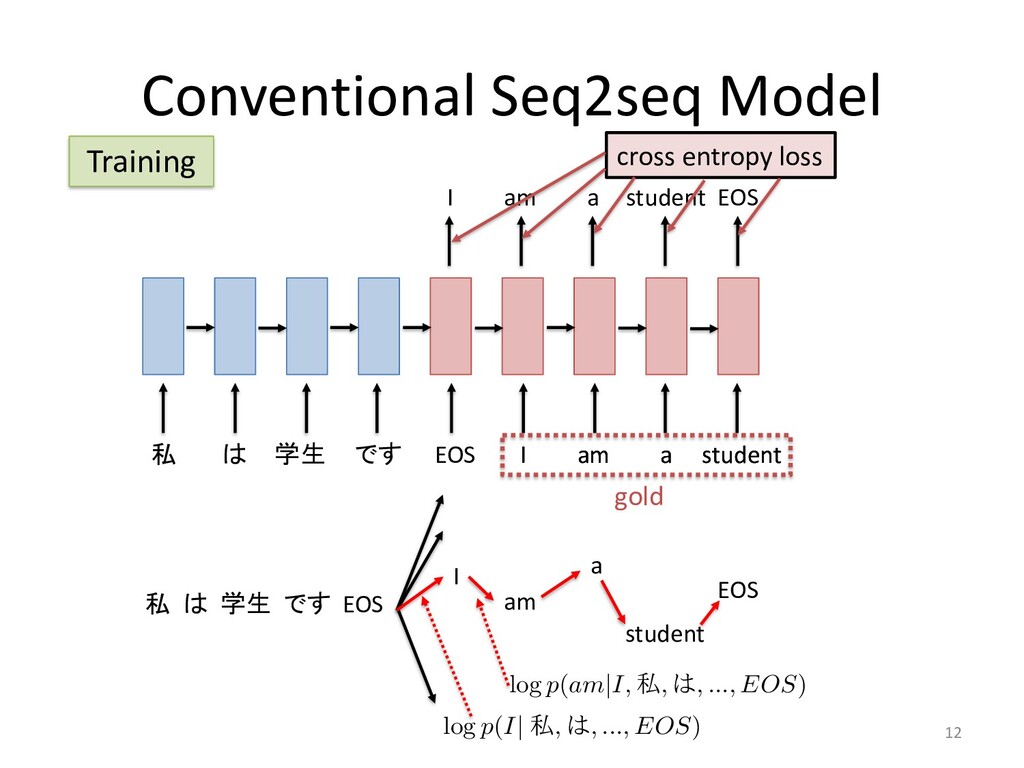
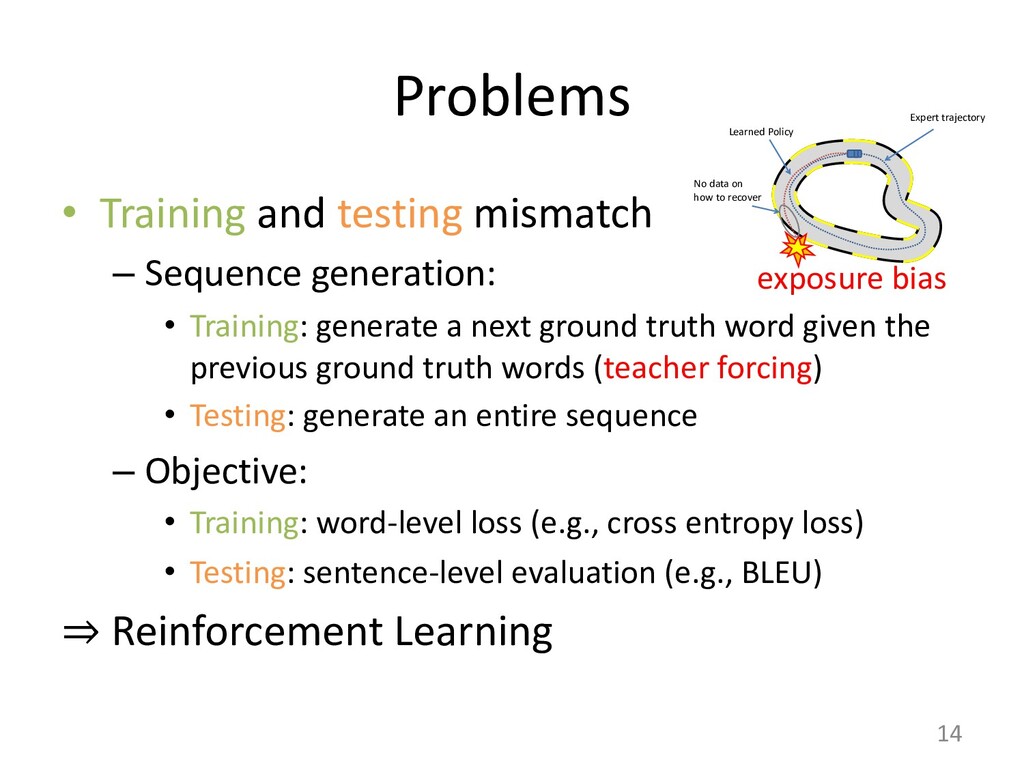
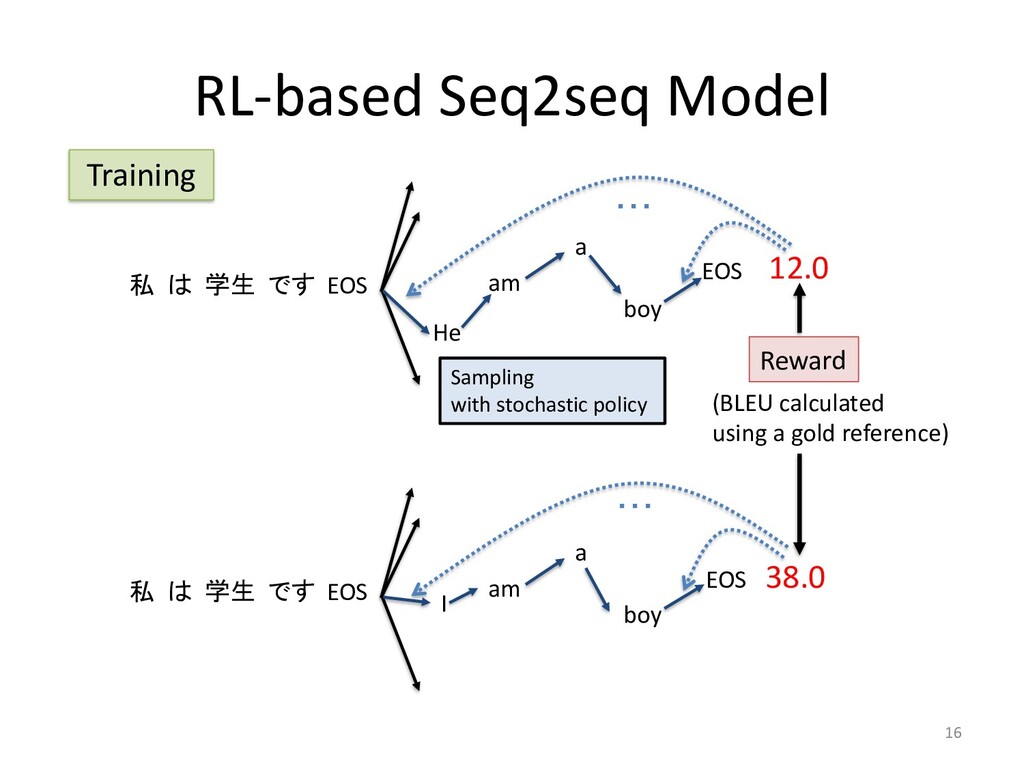
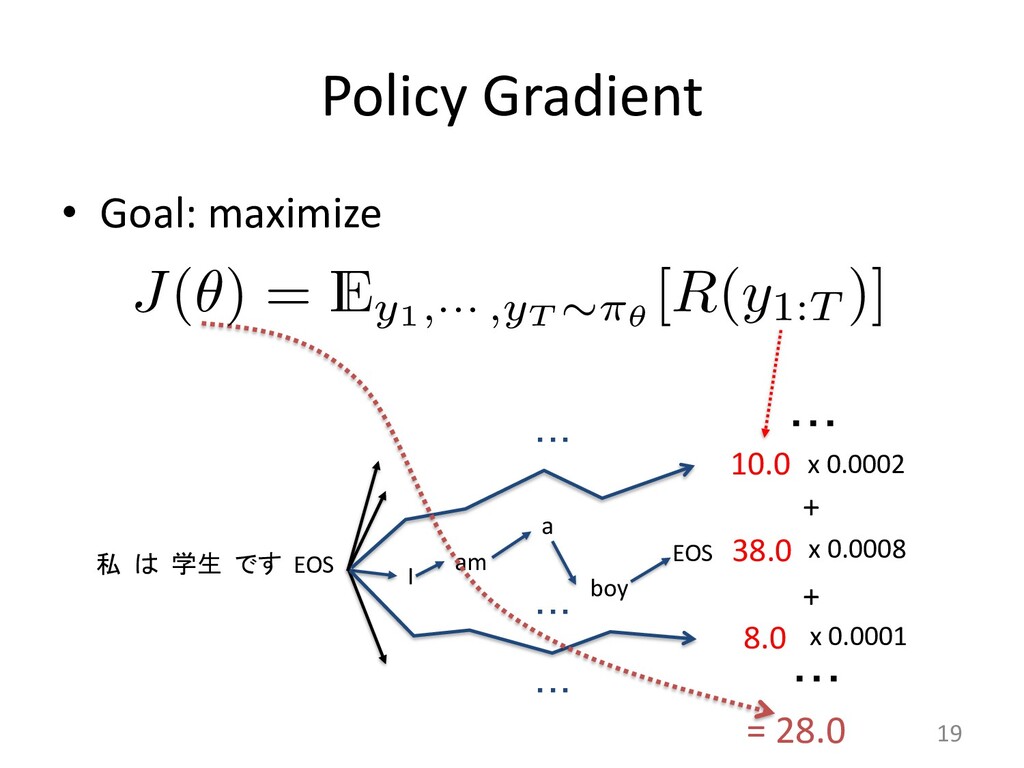
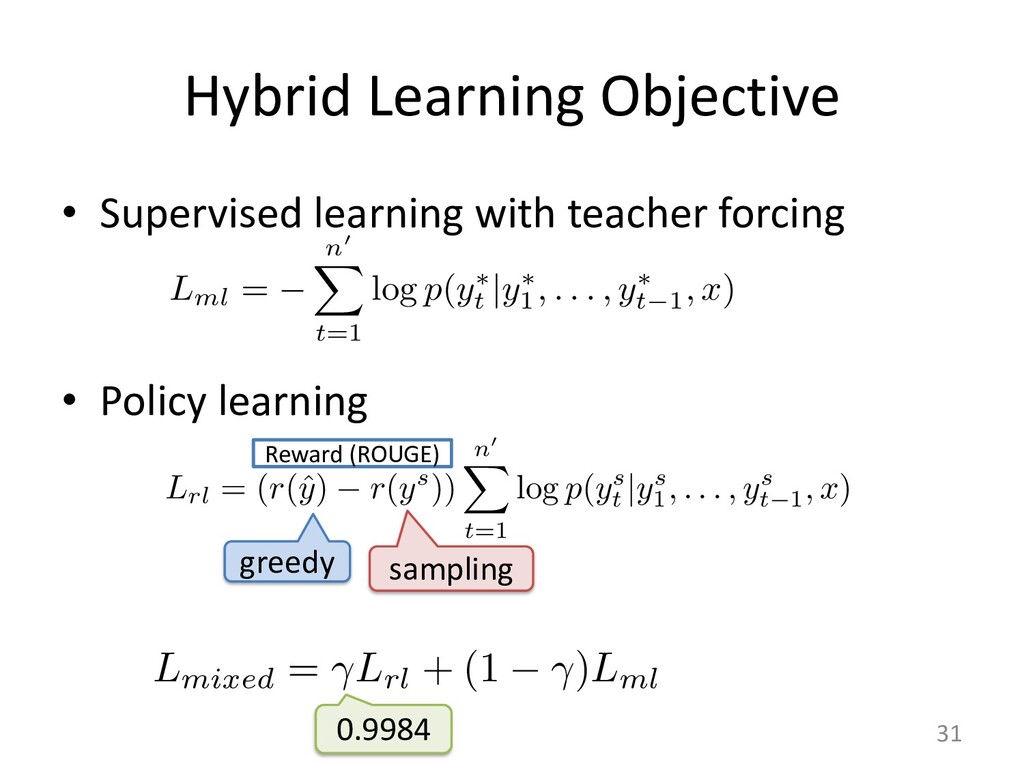
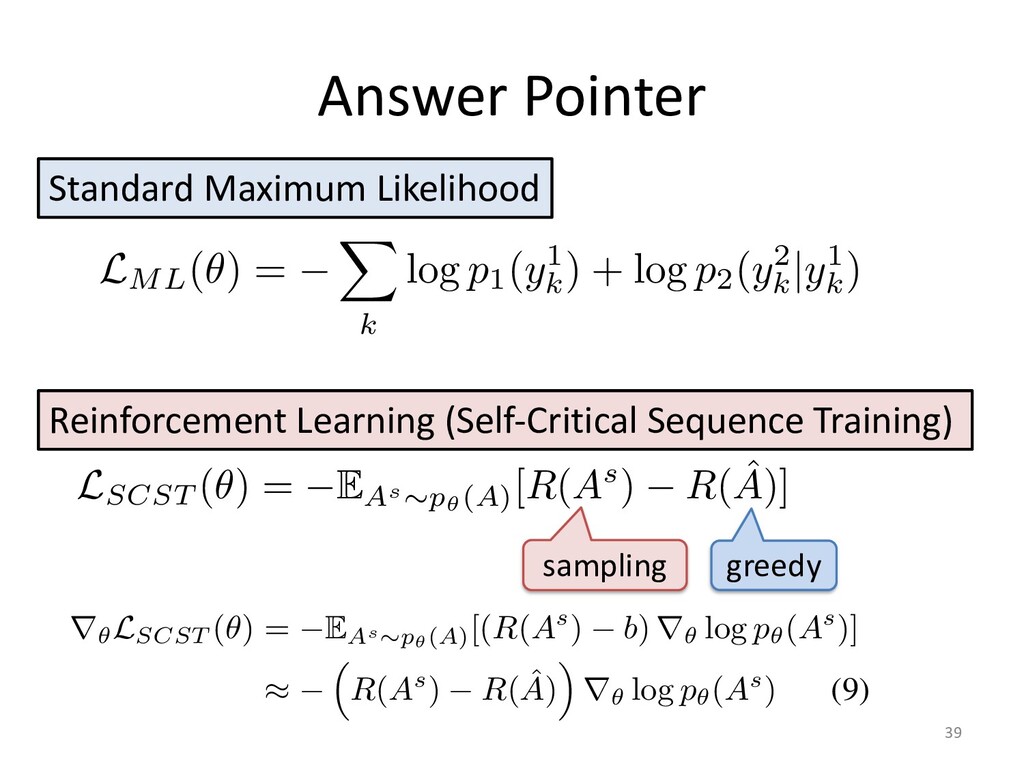
Policy learning 30 used method to train a decoder RNN for sequence generation, called the gorithm (Williams & Zipser, 1989), minimizes a maximum-likelihood lo e define y⇤ = {y⇤ 1 , y⇤ 2 , . . . , y⇤ n0 } as the ground-truth output sequence fo The maximum-likelihood training objective is the minimization of the Lml = n0 X t=1 log p(y⇤ t |y⇤ 1 , . . . , y⇤ t 1 , x) zing Lml does not always produce the best results on discrete evaluatio Lin, 2004). This phenomenon has been observed with similar sequence g aptioning with CIDEr (Rennie et al., 2016) and machine translation w Norouzi et al., 2016). There are two main reasons for this discrepancy. re bias (Ranzato et al., 2015), comes from the fact that the network has k h sequence up to the next token during training but does not have such su ce accumulating errors as it predicts the sequence. The second reason of potentially valid summaries, since there are more ways to arrange ses or different sentence orders. The ROUGE metrics take some of this he maximum-likelihood objective does not. CY LEARNING o remedy this is to learn a policy that maximizes a specific discrete metric the maximum-likelihood loss, which is made possible with reinforcement le we use the self-critical policy gradient training algorithm (Rennie et al., 2016 ning algorithm, we produce two separate output sequences at each training ite tained by sampling from the p(ys t |ys 1 , . . . , ys t 1 , x) probability distribution at e p, and ˆ y, the baseline output, obtained by maximizing the output probability d e step, essentially performing a greedy search. We define r(y) as the reward f equence y, comparing it with the ground truth sequence y⇤ with the evaluatio Lrl = (r(ˆ y) r(ys)) n0 X t=1 log p(ys t |ys 1 , . . . , ys t 1 , x) that minimizing Lrl is equivalent to maximizing the conditional likelihood o nce ys if it obtains a higher reward than the baseline ˆ y, thus increasing the rew r model. ED TRAINING OBJECTIVE FUNCTION G OBJECTIVE FUNCTION is reinforcement training objective is that optimizing for a spe es not guarantee an increase in quality and readability of th h discrete metrics and increase their score without an actua Liu et al., 2016). While ROUGE measures the n-gram overlap a reference sequence, human-readability is better captured by measured by perplexity. elihood training objective (Equation 14) is essentially a con g the probability of a token yt based on the previously predict nput sequence x, we hypothesize that it can assist our policy le natural summaries. This motivates us to define a mixed learni quations 14 and 15: Lmixed = Lrl + (1 )Lml, tor accounting for the difference in magnitude between Lrl 0.9984 greedy sampling Reward (ROUGE)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![REINFORCE [Williams 92] • Sample-based (Monte-Carlo) method • Algorithm –](https://files.speakerdeck.com/presentations/5622654dd41942f8b0cc4c1e48f65a75/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
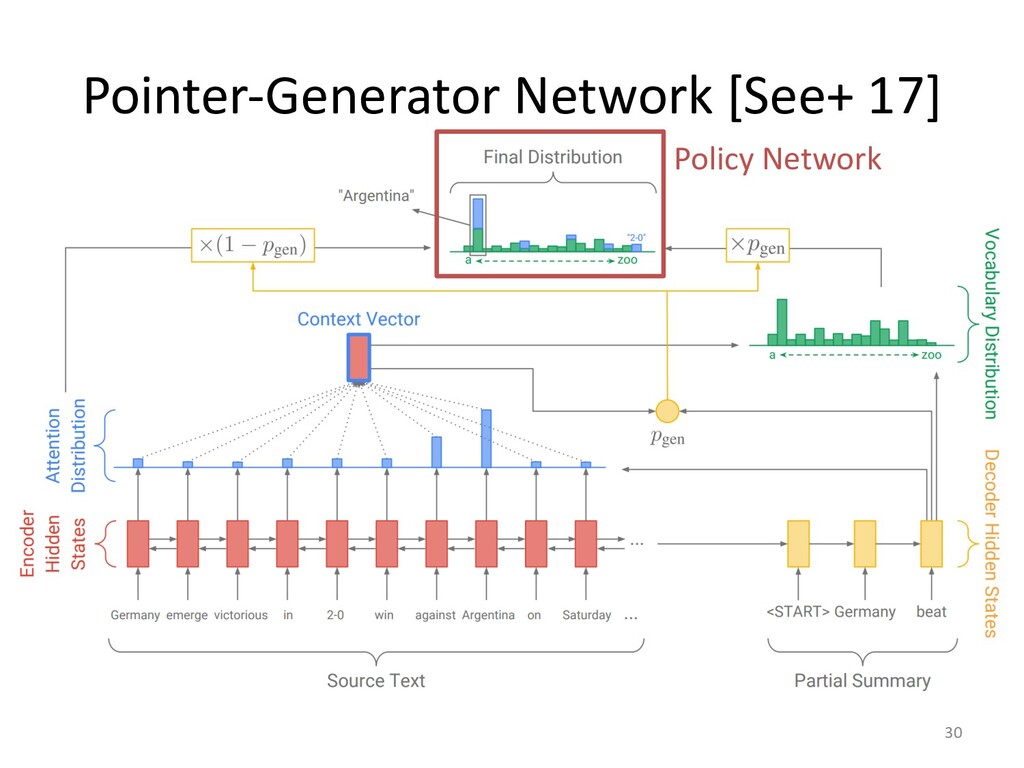
![Pointer-Generator Network [See+ 17] 29 Policy Network https://arxiv.org/abs/1704.04368](https://files.speakerdeck.com/presentations/5622654dd41942f8b0cc4c1e48f65a75/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
![Machine Translation [Johnson+ 16] 32 el text containing N input-output](https://files.speakerdeck.com/presentations/5622654dd41942f8b0cc4c1e48f65a75/slide_31.jpg){kind=link}
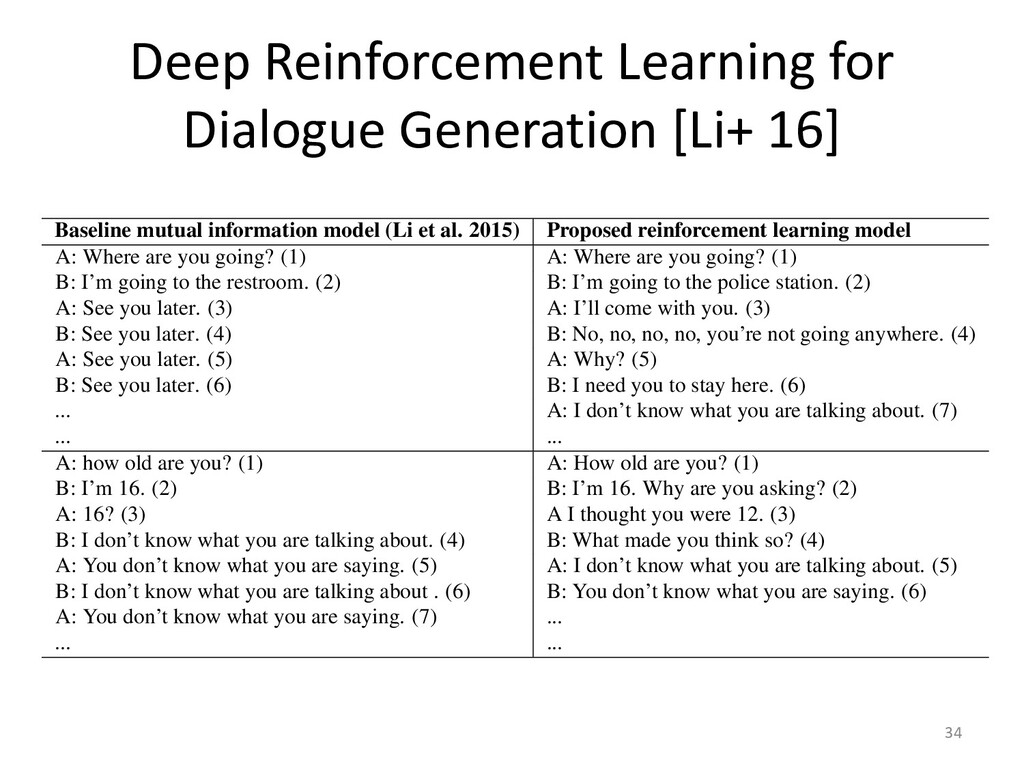
![Deep Reinforcement Learning for Dialogue Generation [Li+ 16] 33 Baseline](https://files.speakerdeck.com/presentations/5622654dd41942f8b0cc4c1e48f65a75/slide_32.jpg){kind=link}
{kind=link}
![Adversarial Learning for Neural Dialogue Generation [Li+ 17] • [Li+](https://files.speakerdeck.com/presentations/5622654dd41942f8b0cc4c1e48f65a75/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}