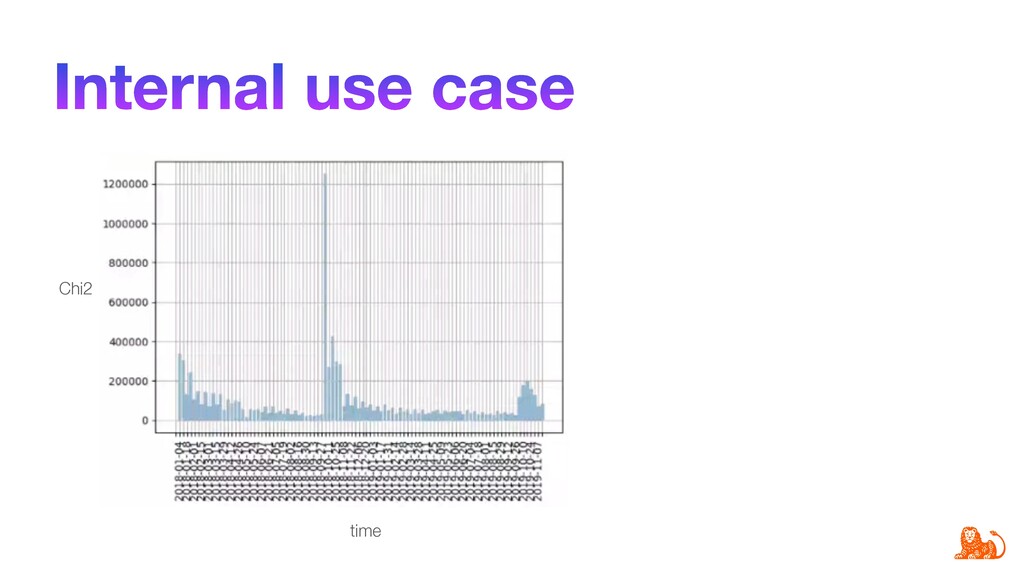
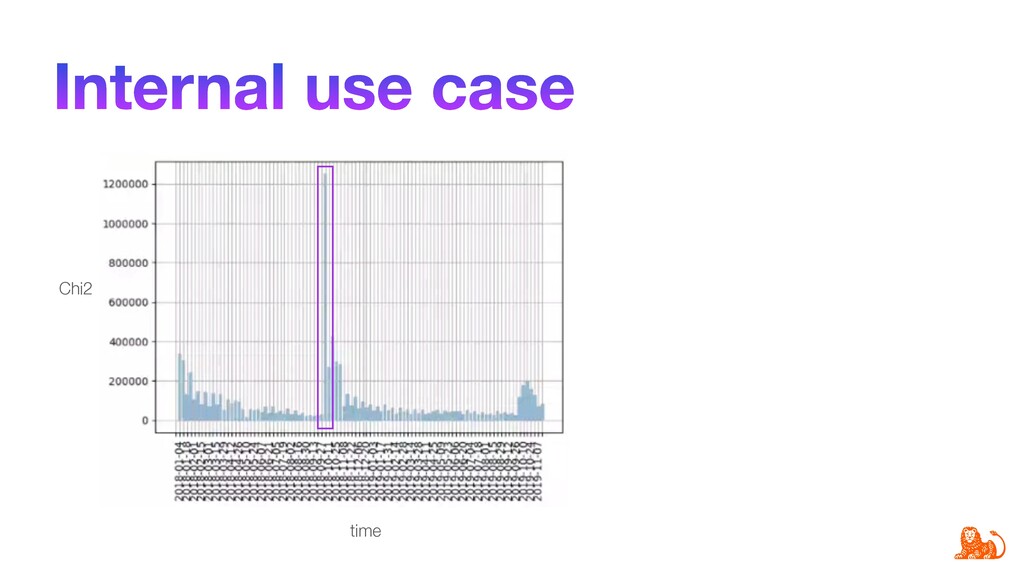
Tracking model performance is crucial to guarantee that a model behaves as designed initially. Predictions may be way ahead in time, so the performance can only be verified later, for example, in one year. Taking actions at that point might be already too late. Typical model performance questions are: is the model performing as expected, and are predictions made on current incoming data still valid?
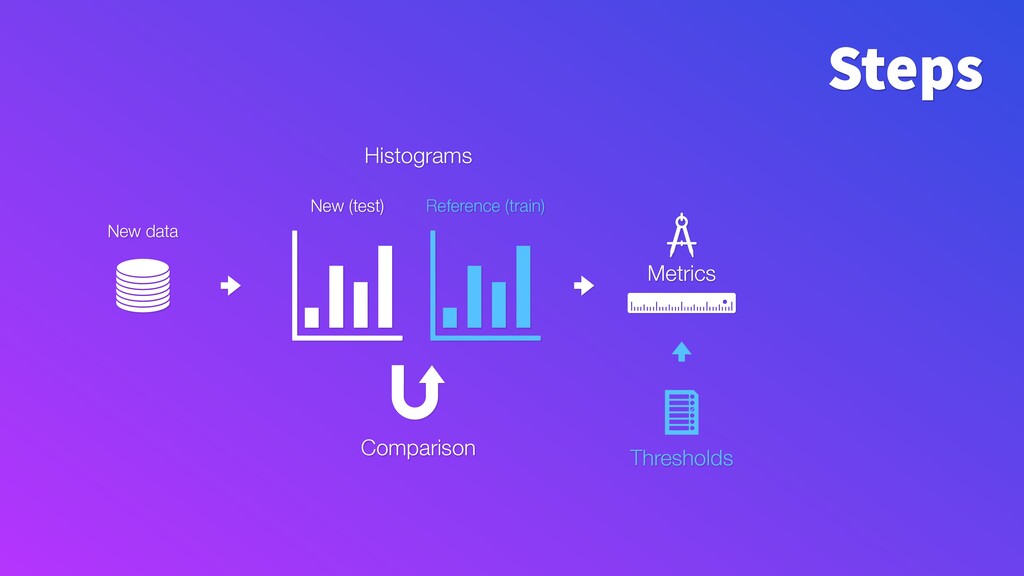
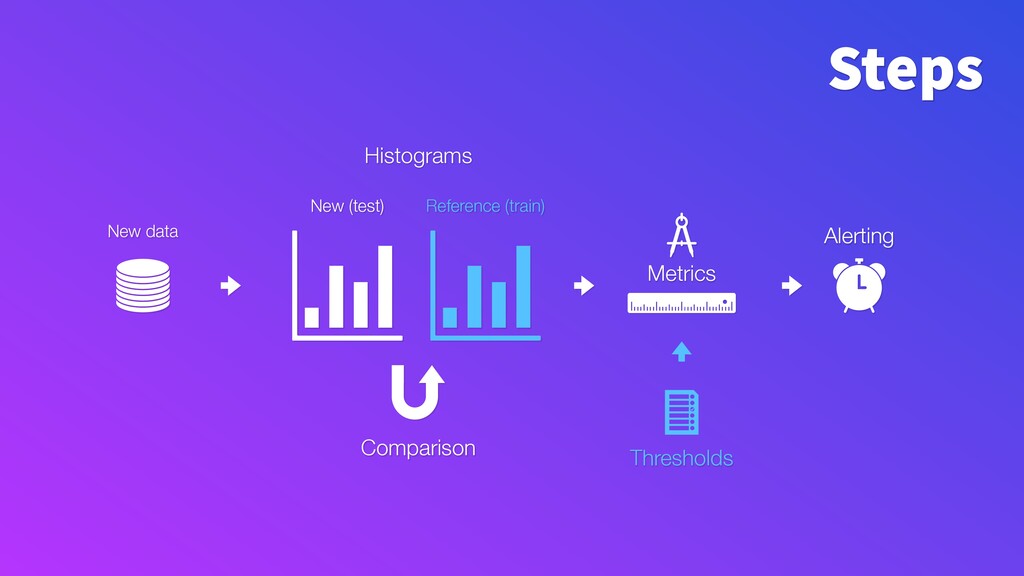
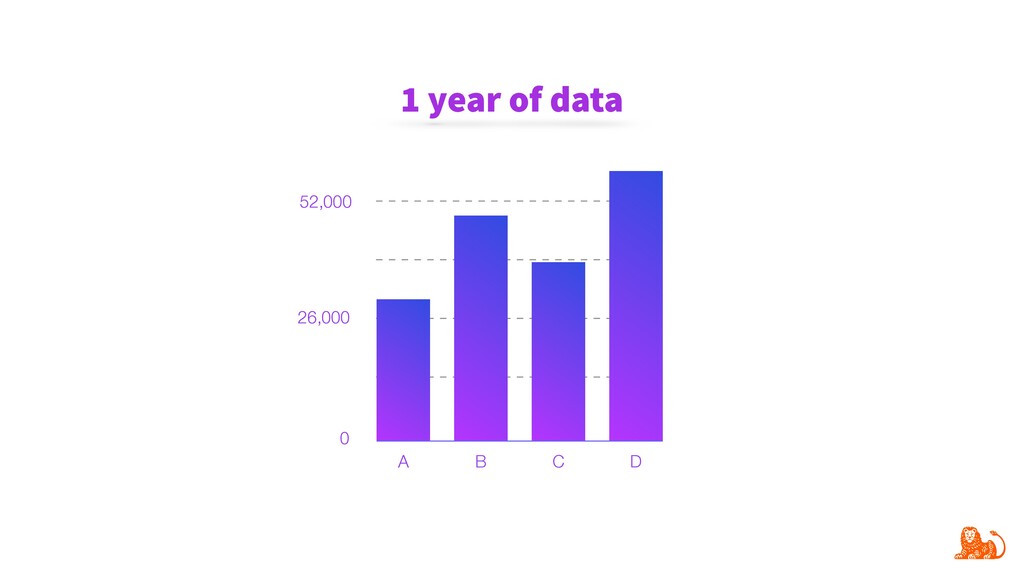
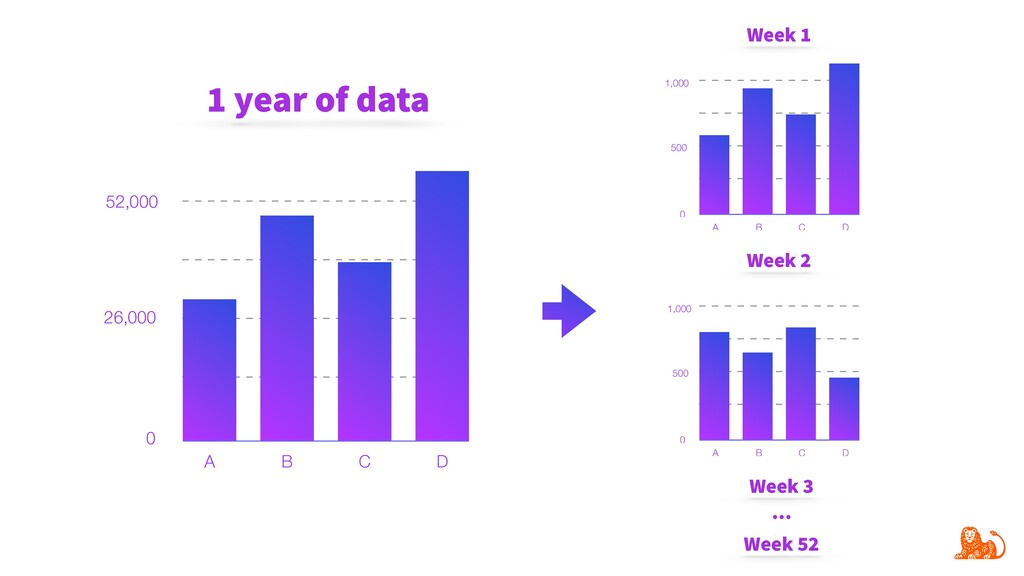
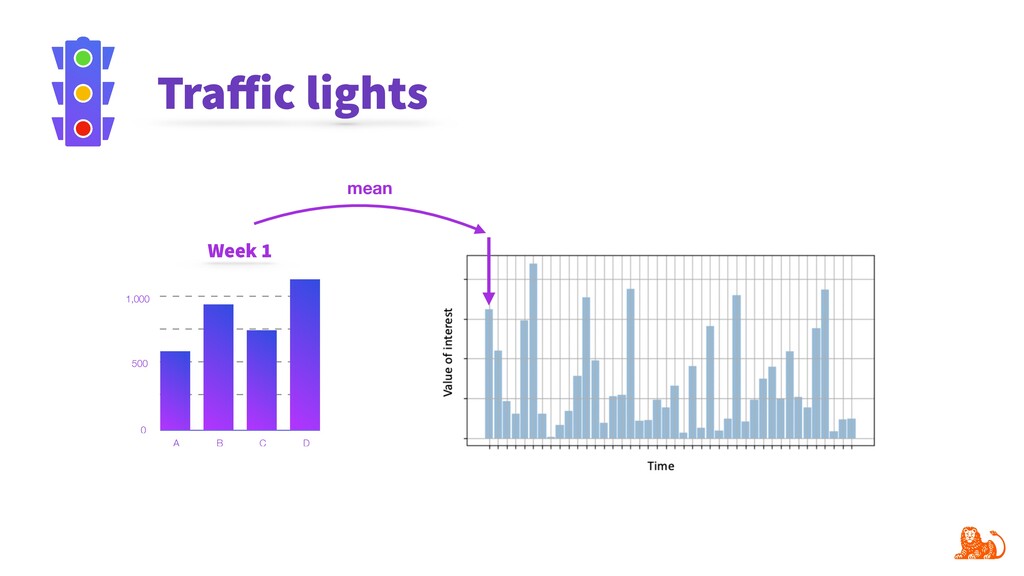
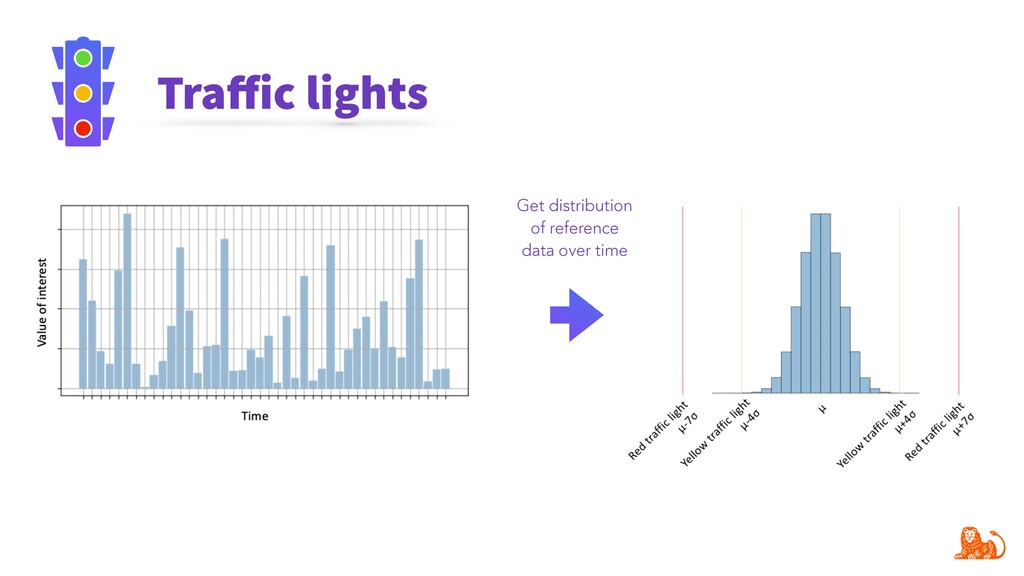
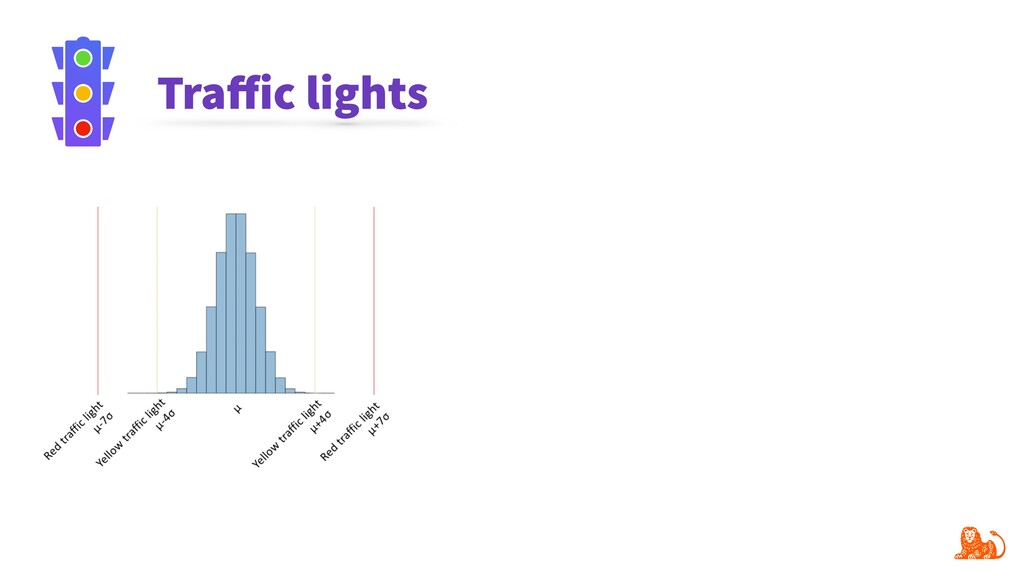
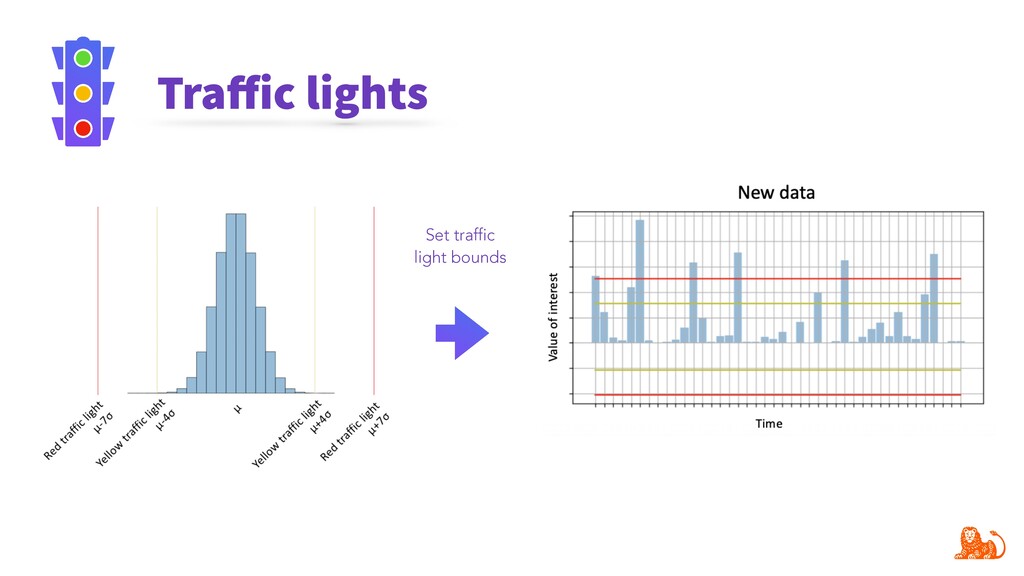
Model performance depends directly on the data used for training and the data to make predictions. Changes in the latter (e.g. certain word frequency, user demographics, etc.) can affect the performance and make predictions unreliable. Given that input data often change over time, it is important to track changes in both input distributions and delivered predictions periodically, and when they differ significantly - take actions. For example, diagnose and retrain an incorrect model in production.
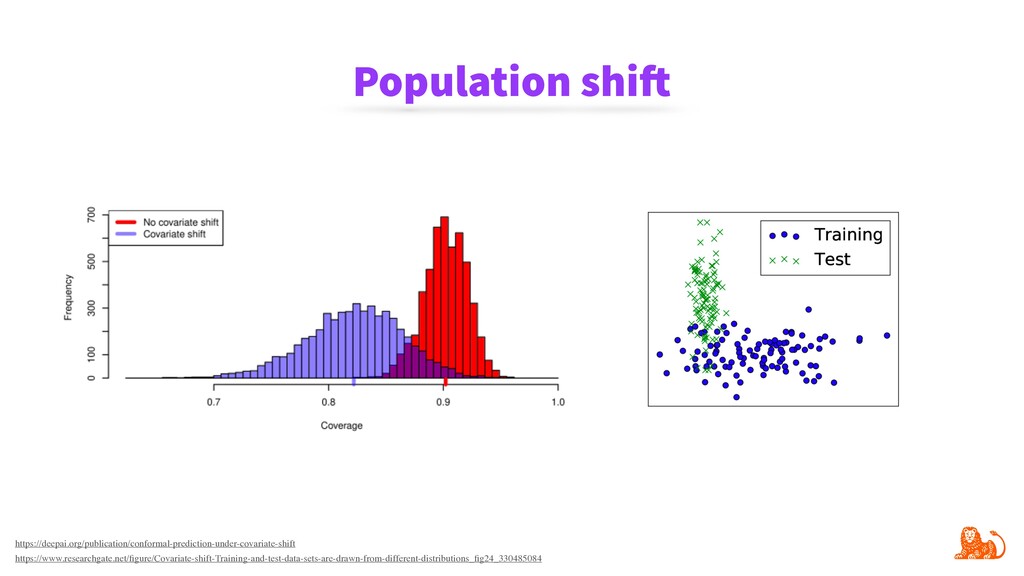
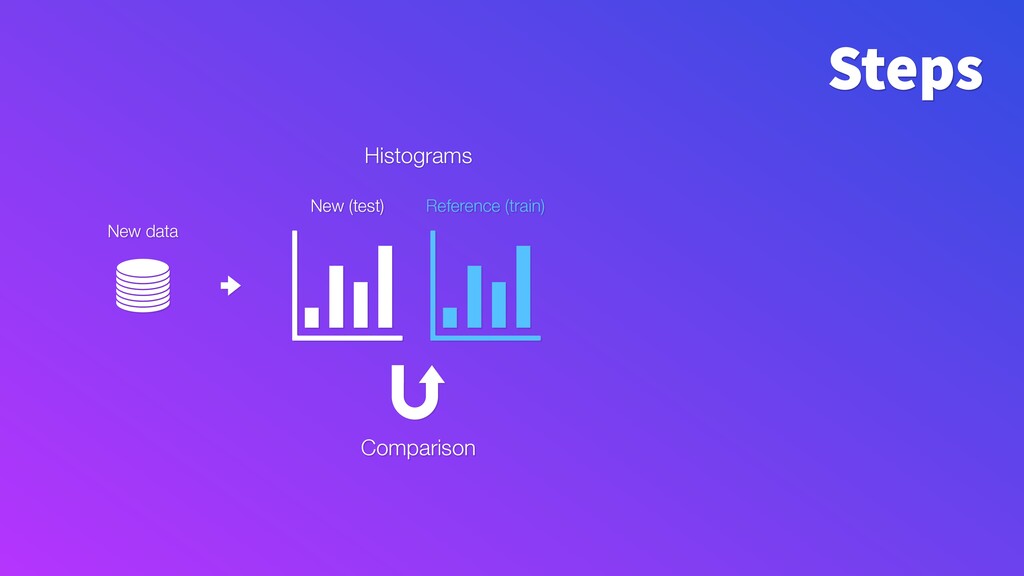
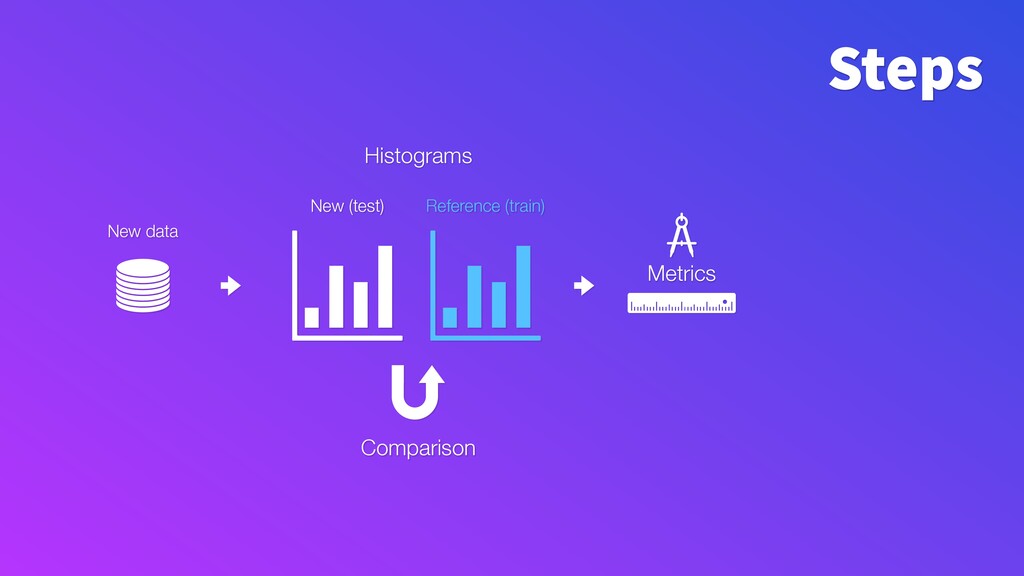
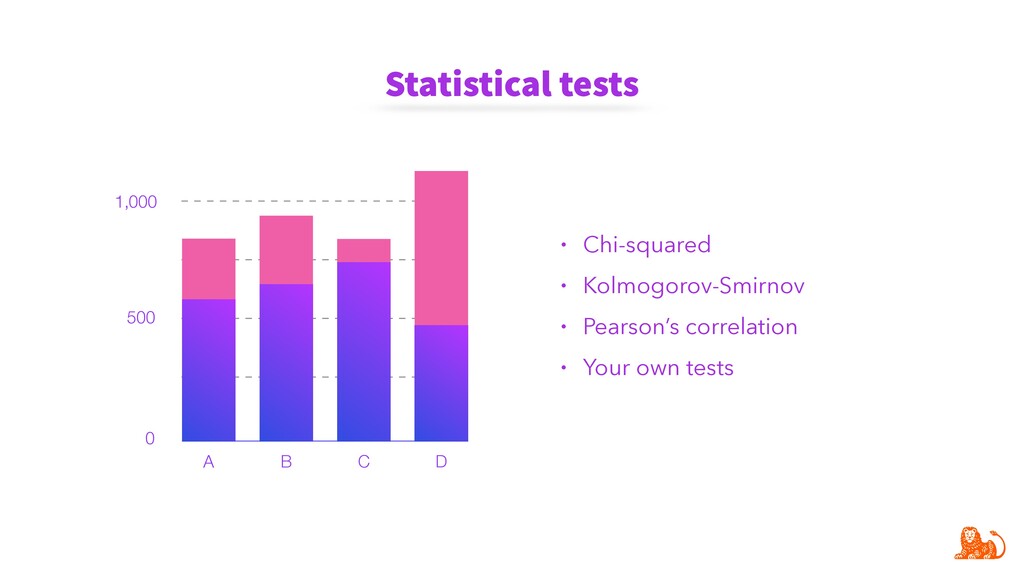
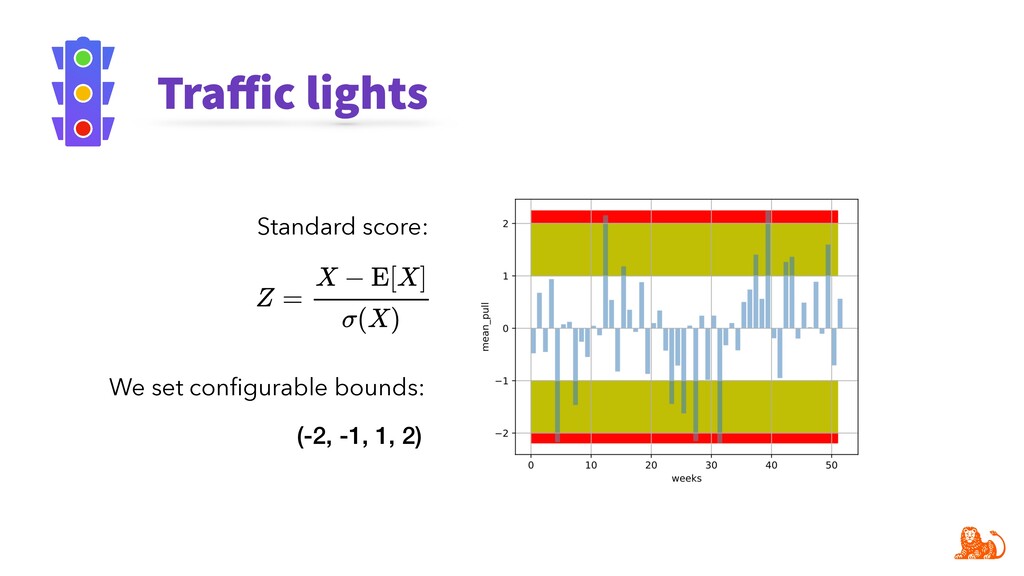
To make monitoring both more consistent and semi-automatic, at ING we have developed a generic Python package called "popmon" to monitor the stability of data populations over time, using techniques from statistical process control. In this talk, the speaker will present multiple scenarios of population shift, the motivation and challenges of population monitoring, as well as our open-source solution to these.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
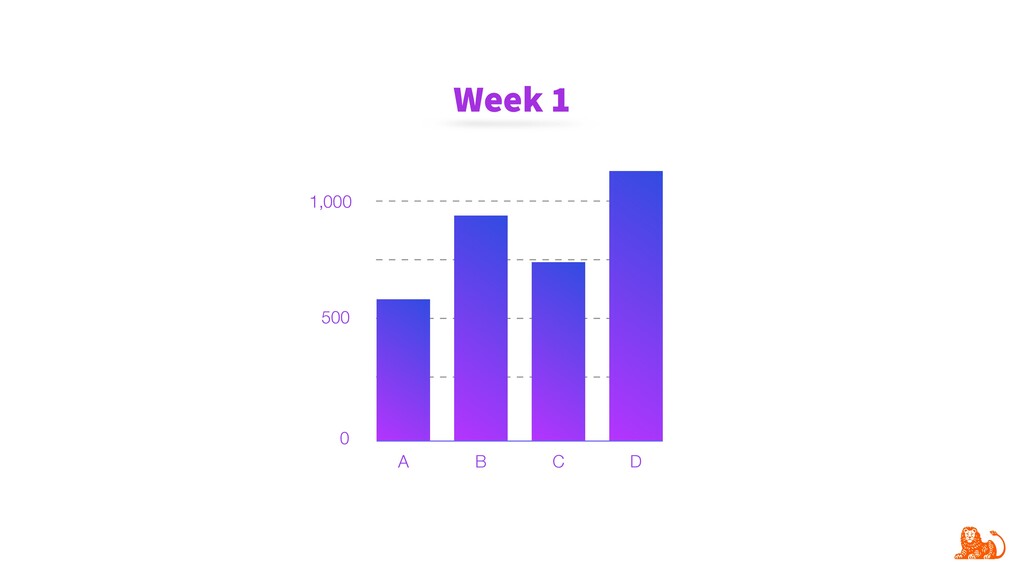{kind=link}
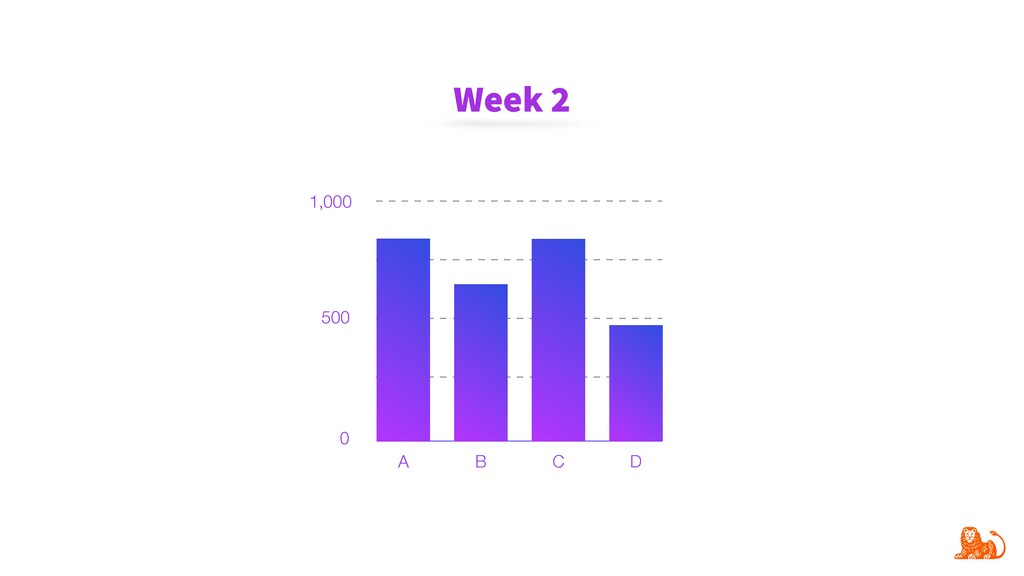{kind=link}
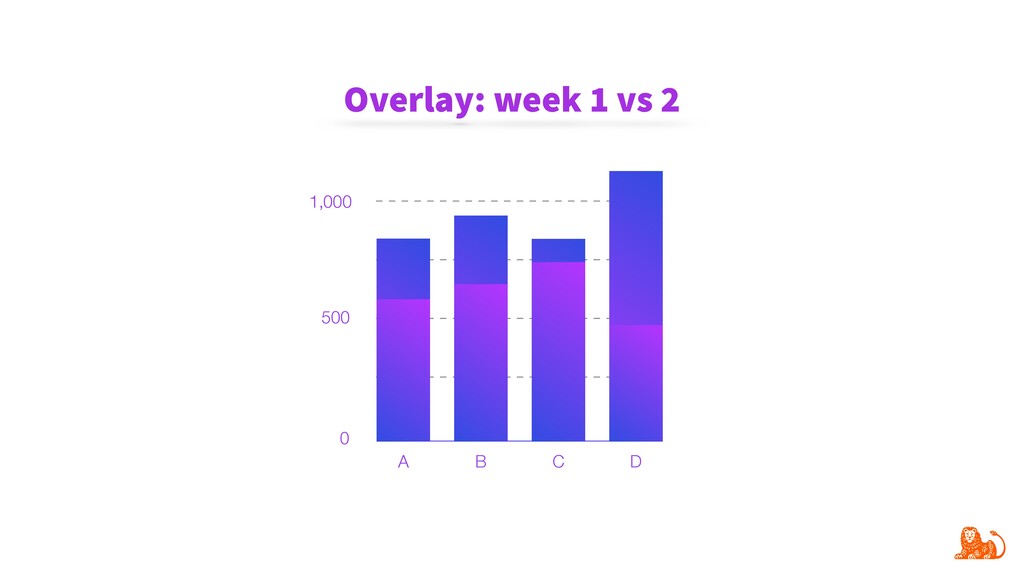{kind=link}
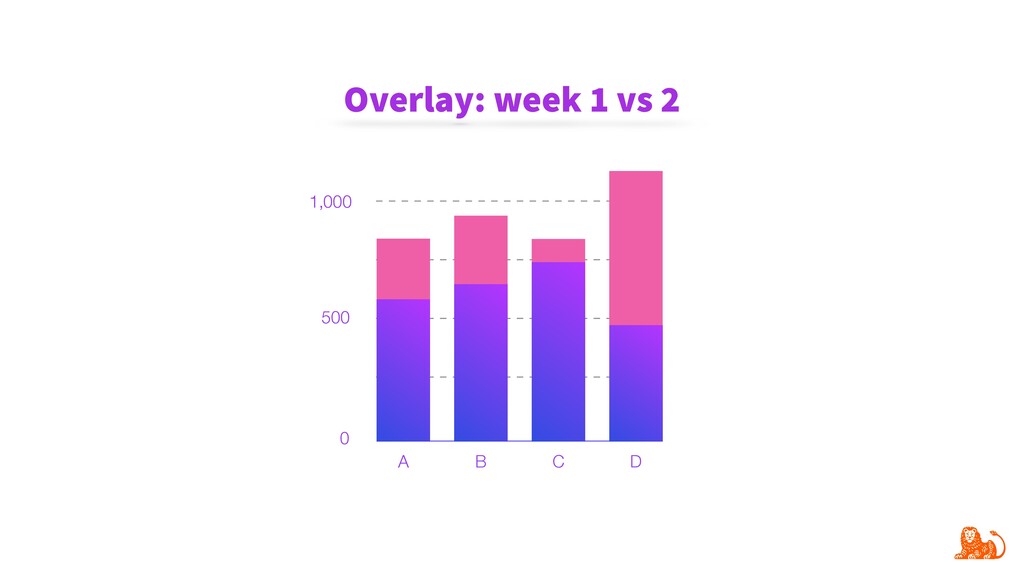{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}