L Scholten Center for Computing Research Sandia National Labs CQuIC Talk University of New Mexico 2015 December 2 Sandia National Laboratories is a multi-program laboratory managed and operated by Sandia Corporation, a wholly owned subsidiary of Lockheed Martin Corporation, for the U.S. Department of Energy’s National Nuclear Security Administration under contract DE-AC04-94AL85000. CCR Center for Computing Research 59
justified in doing so? Schwarz/van Enk - 2013 Error models in quantum computation: an application of model selection Guta et. al. - 2012 Rank-based model selection for multiple ions quantum tomography van Enk/Blume-Kohout - 2013 When quantum tomography goes wrong: drift of quantum sources and other errors 53
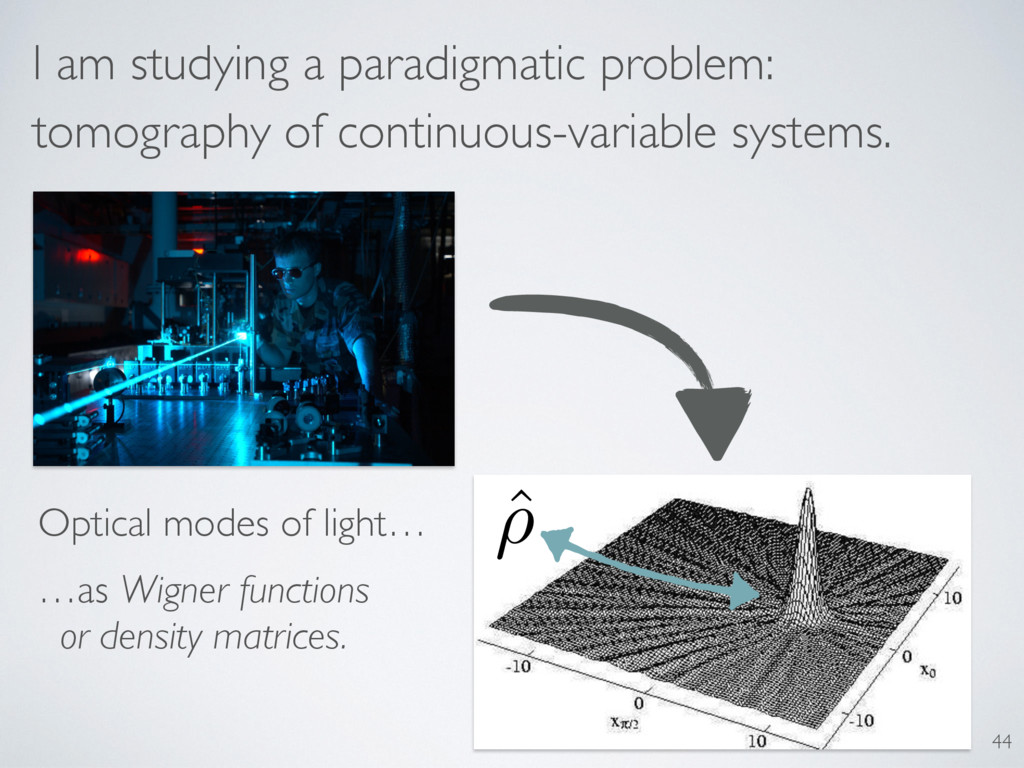
Model = parametrized family of probability distributions Probabilities via the Born rule: Pr(E) = tr(⇢E) Hypothesis = point in the model M H 51 H $ ⇢ M $ {⇢1, ⇢2, · · · }
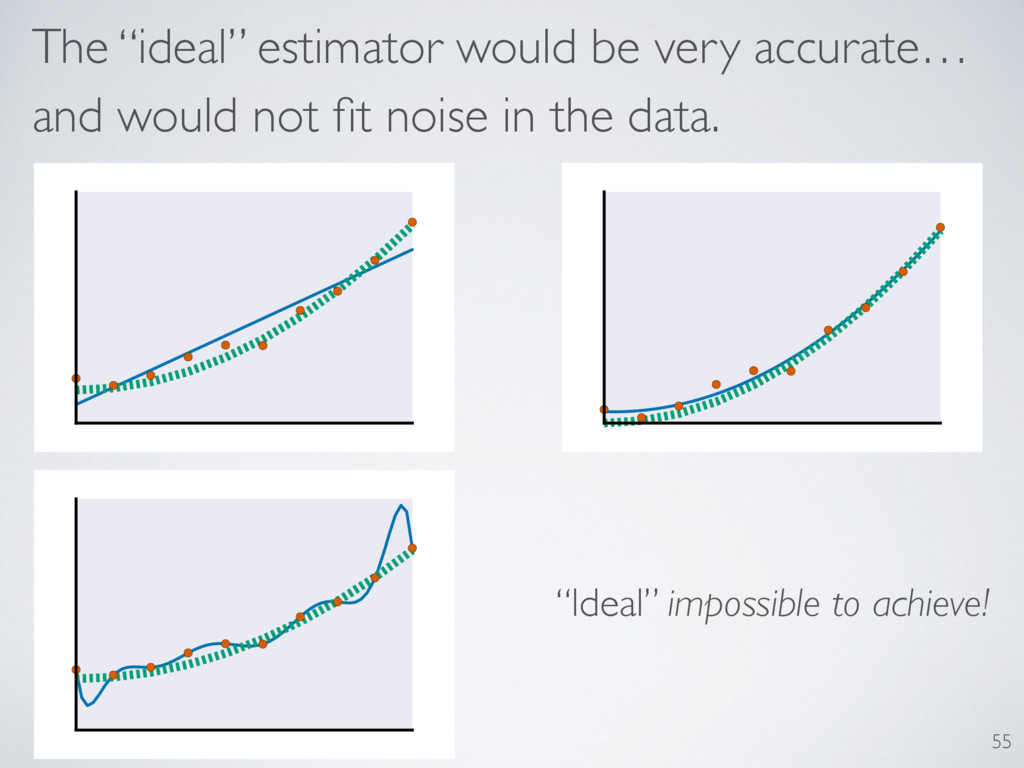
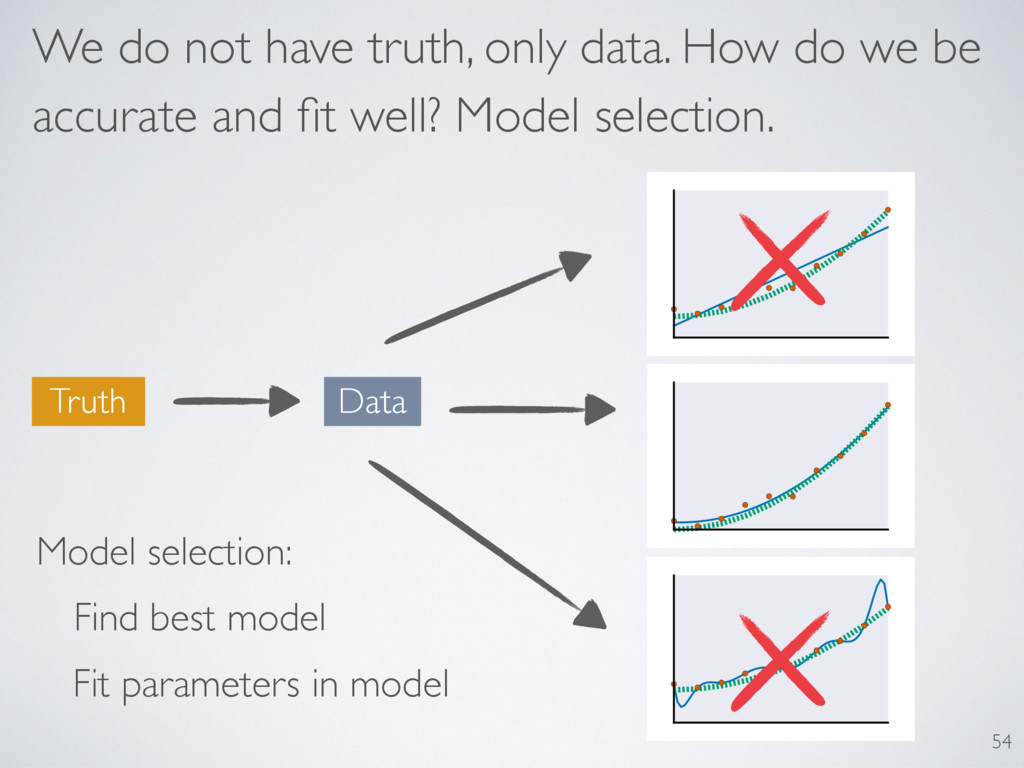
its likelihood. What is the probability assigned to the data seen? L(H) = Pr(Data|H) Hypothesis: Just compute it! L ( M ) = max H2M Pr (Data |H ) Models: Just maximize! We use likelihoods to compare models/hypotheses and to make estimates. 50
State discrimination is an instance of simple hypothesis testing Which state is it? ⇢ Neyman-Pearson lemma tells us this is the most powerful test. ( ⇢, ) = 2 log ⇣ L(⇢) L( ) ⌘ () 0 Choose the highest likelihood! 49 ⇢ () < 0
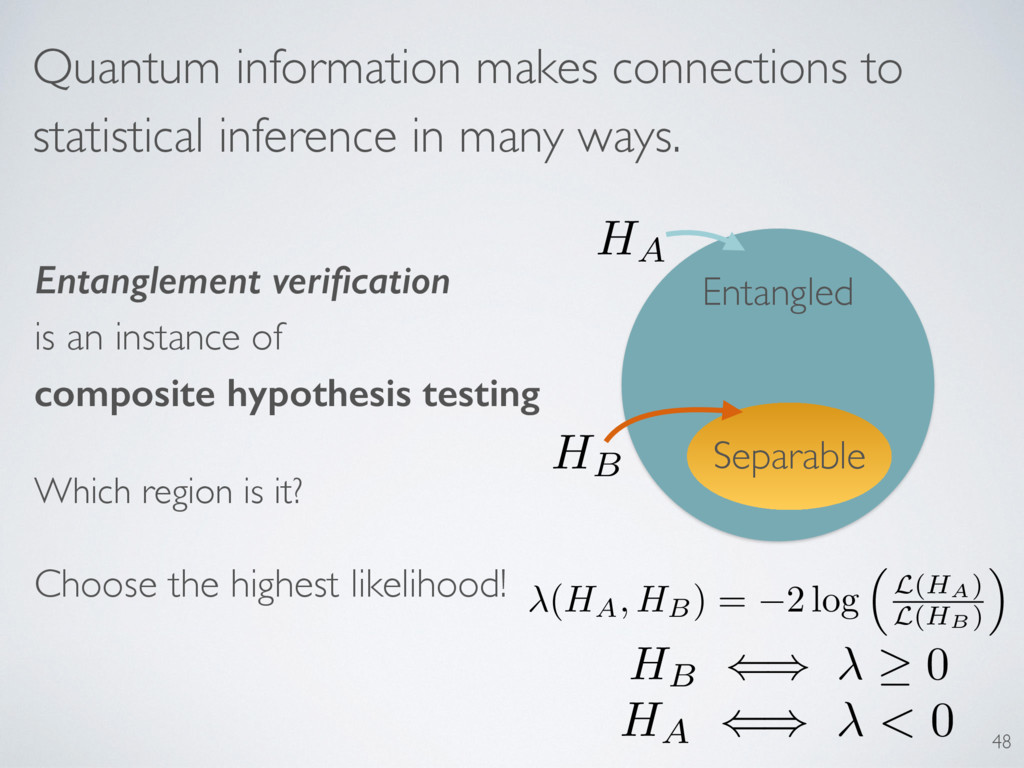
Entanglement verification is an instance of composite hypothesis testing Which region is it? Separable Entangled 48 Choose the highest likelihood! ( HA , HB ) = 2 log ⇣ L(HA) L(HB) ⌘ HB () 0 HA () < 0 HA HB
State tomography is an instance of model fitting Which parameters are best? Maximum likelihood estimation ˆ ⇢ ˆ ⇢ = argmax ⇢ L ( ⇢ ) 47 Choose the highest likelihood!
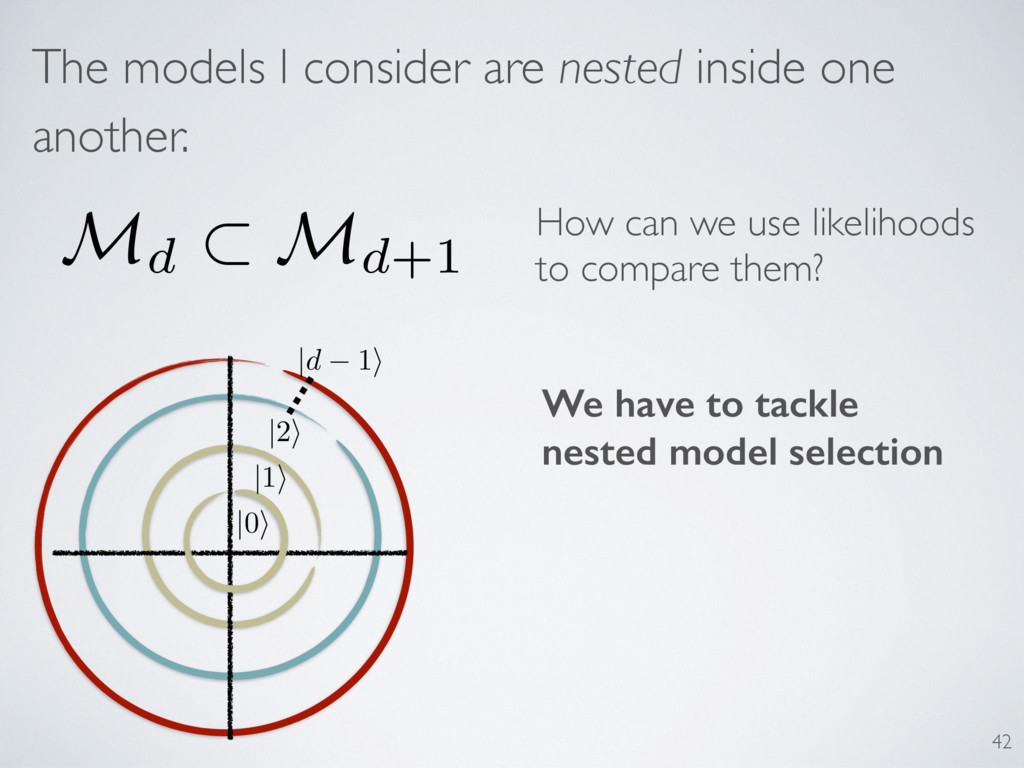
Z-diagonal state vs not is an instance of (nested) model selection Is the true state on the line? 0 =) MB ??? LLRS never negative! ( MA, MB) = 2 log ⇣ L(MA) L(MB) ⌘ MA MB 46 Choose the highest likelihood!
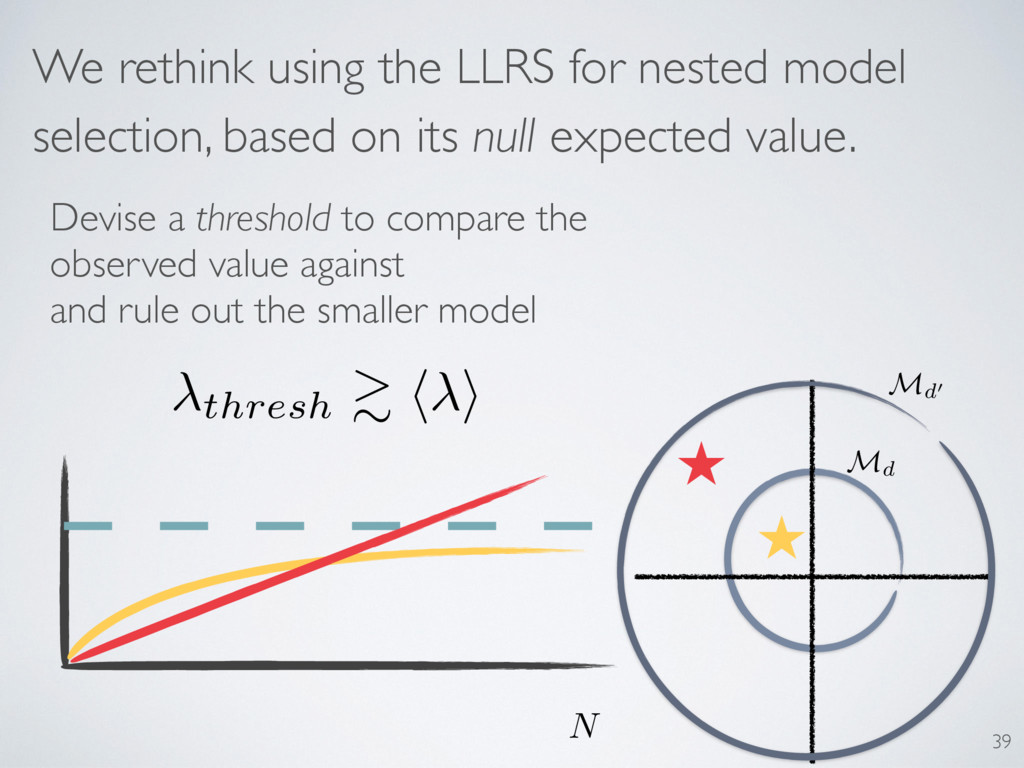
nested model selection, based on its null expected value. Devise a threshold to compare the observed value against and rule out the smaller model thresh & h i
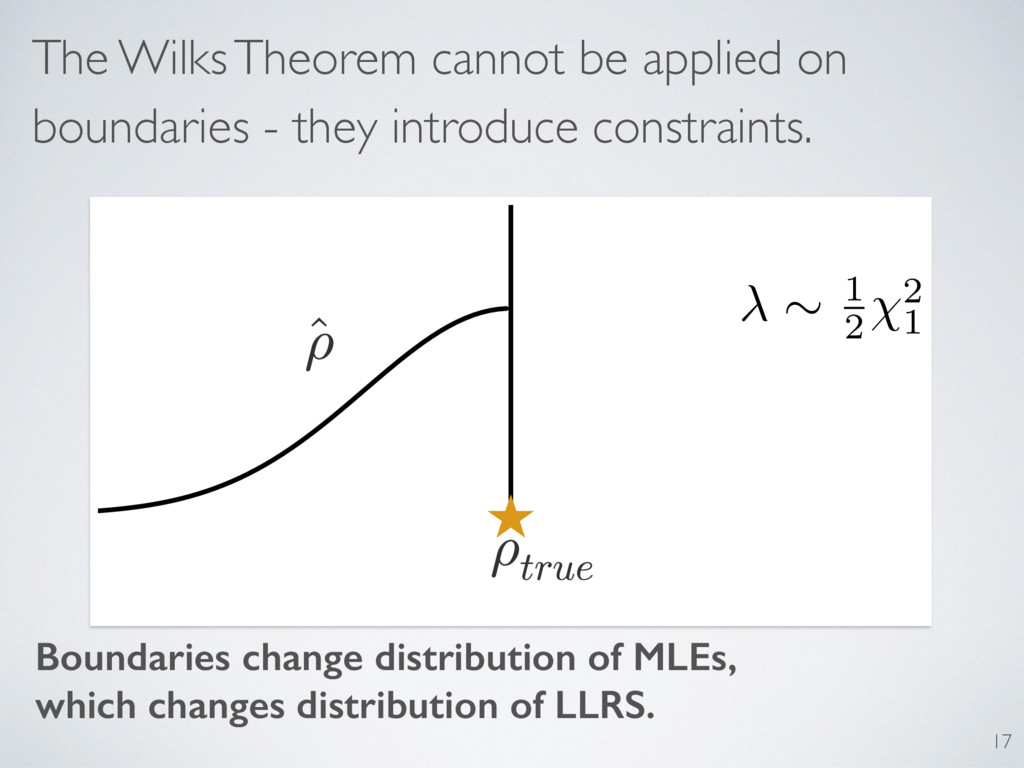
Wilks Theorem. 1938: Wilks gives distribution of LLRS (Md, Md0 ) ⇠ 2 pd0 pd 37 Gaussian distribution of estimates One fluctuating parameter = one unit of LLRS
trade off between fitting data well and having high accuracy Use of Akaike’s AIC is common Relies on Wilks Theorem (bias of estimator of KL divergence) My work helps us create a quantum information criterion 36
its behavior. Studied: - 17 true states - 100 random datasets for each state (coherent state POVM) Data = {↵j | ↵j 2 C, Pr(↵j) = h↵j |⇢true |↵j i/⇡} 33
its behavior. Studied: - 17 true states - 100 random datasets for each state (coherent state POVM) 31 - 10K to 100K samples for each dataset - MLE over {2…10}-dimensional Hilbert spaces {M2, M3, · · · , M10 } Lots of supercomputer time!
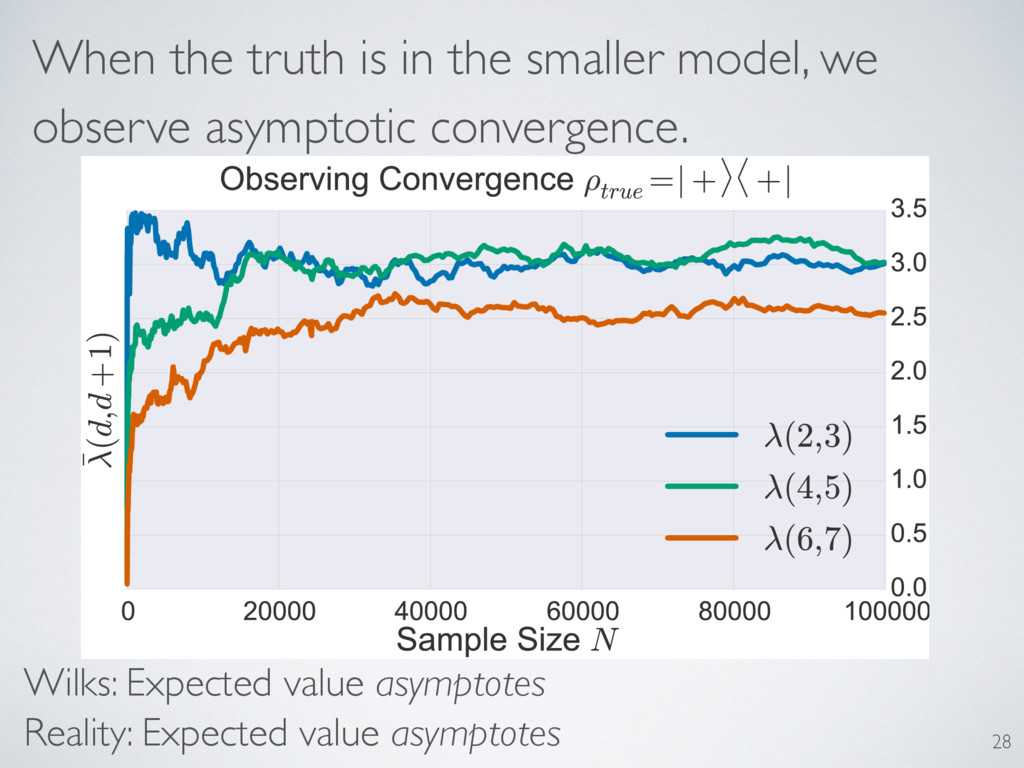
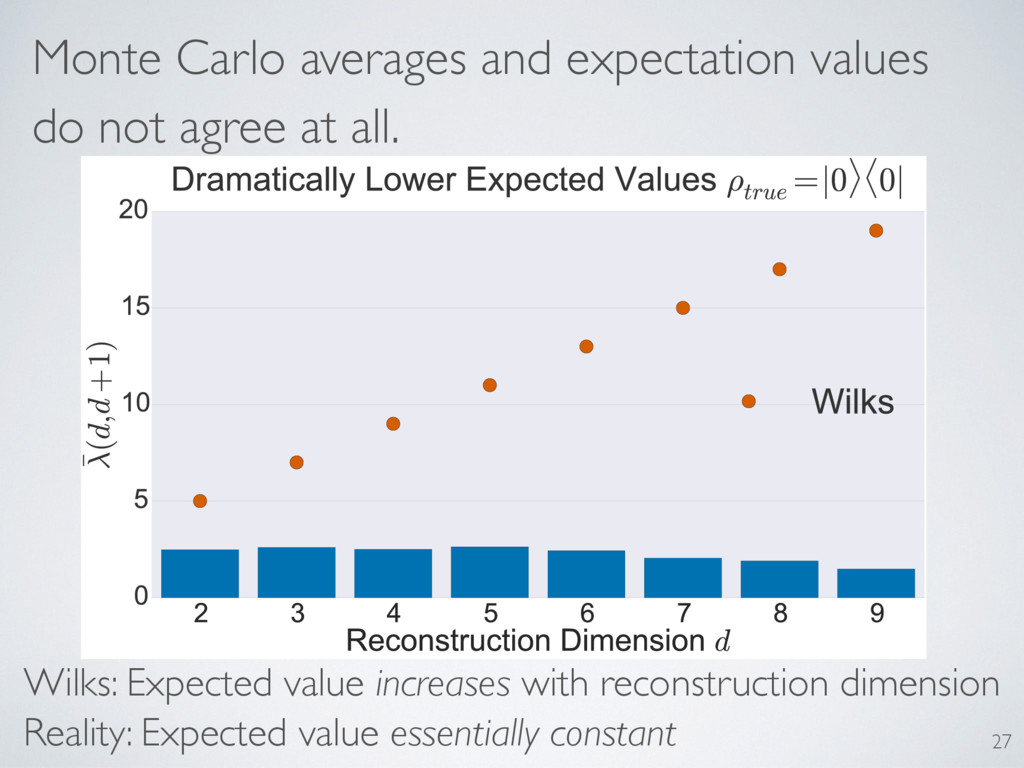
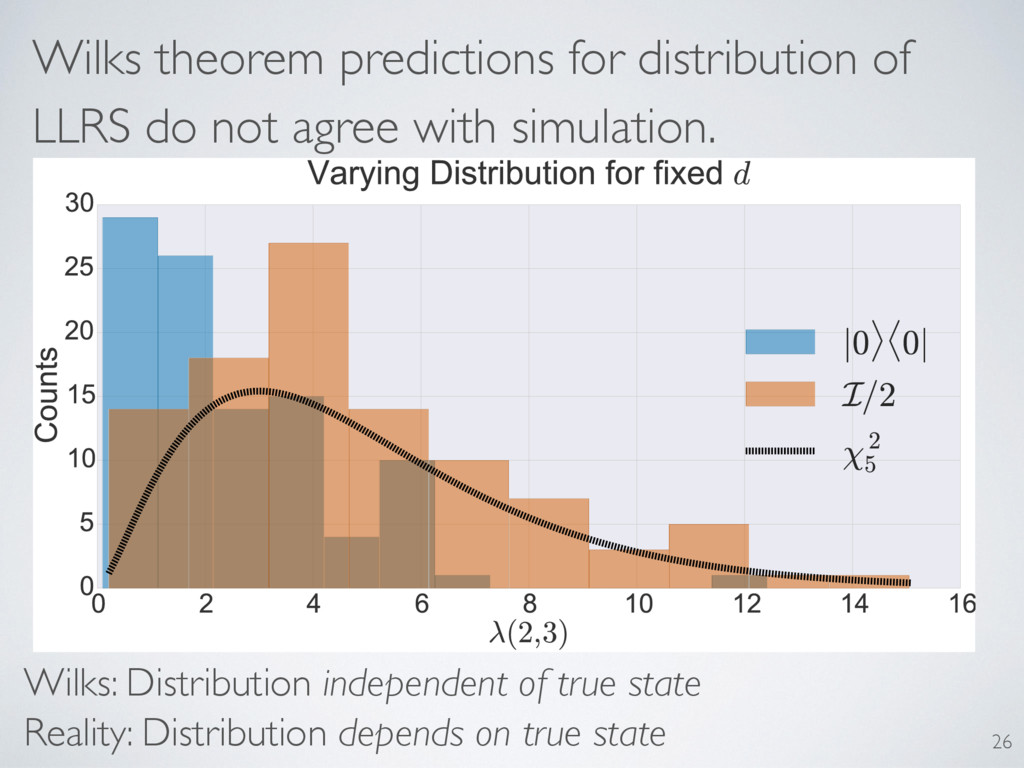
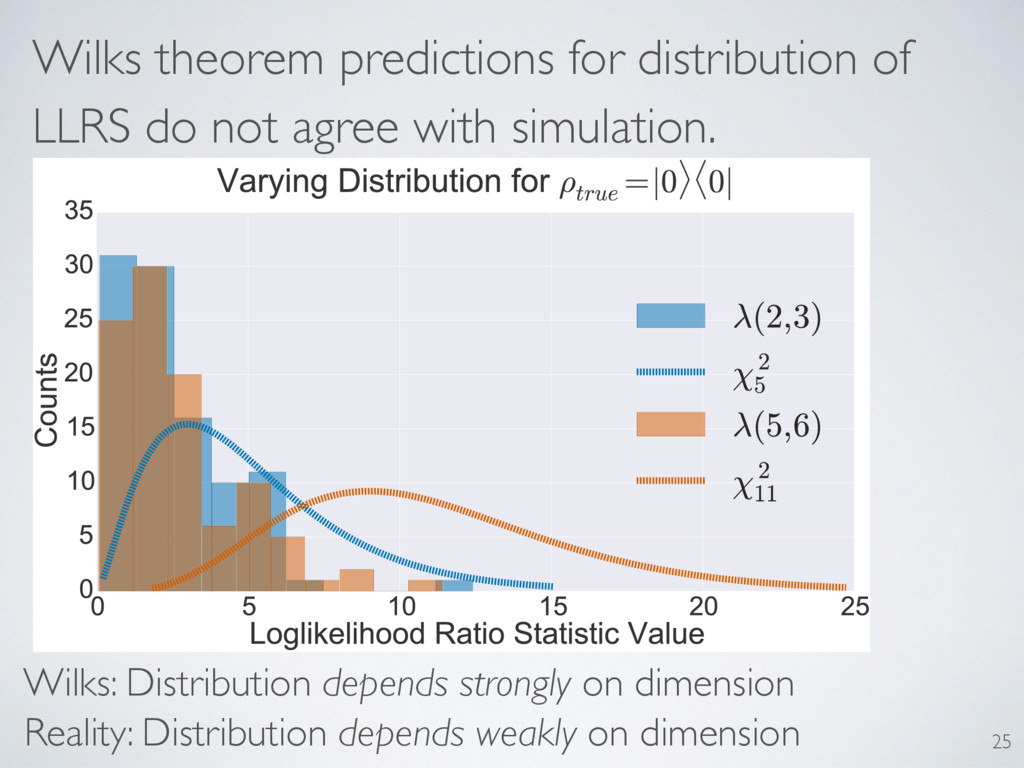
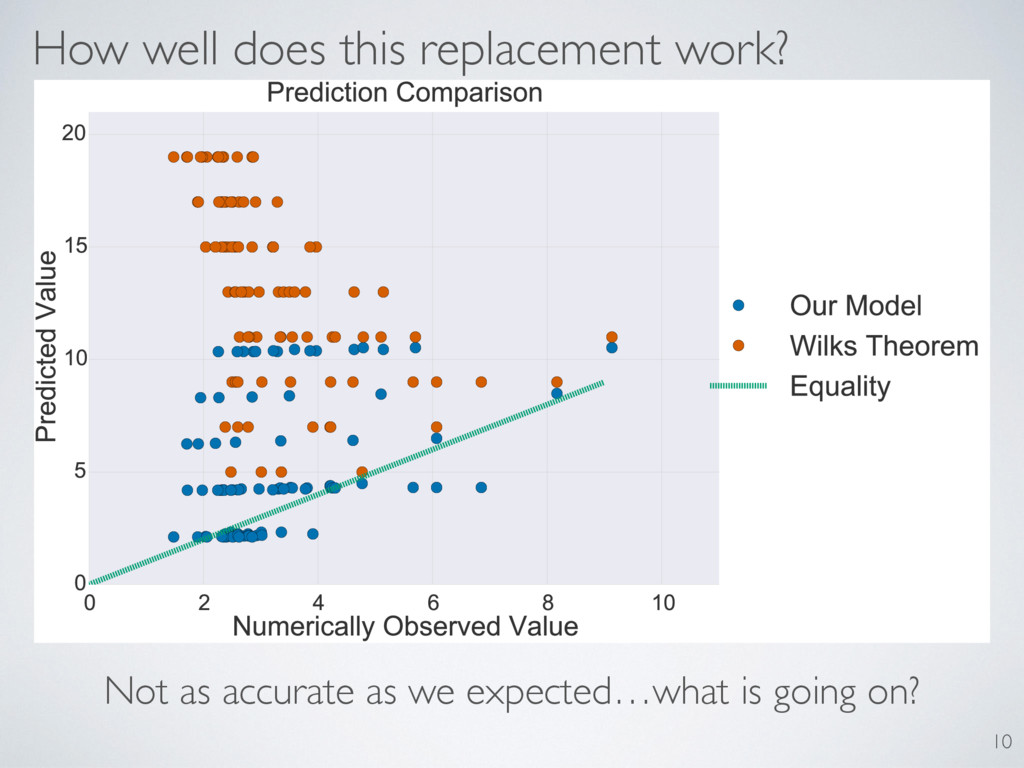
behavior of the LLRS. Only one matched. Predictions: Asymptotic convergence Distribution independent of truth A particular expected value Distribution depends on reconstruction dimension 29
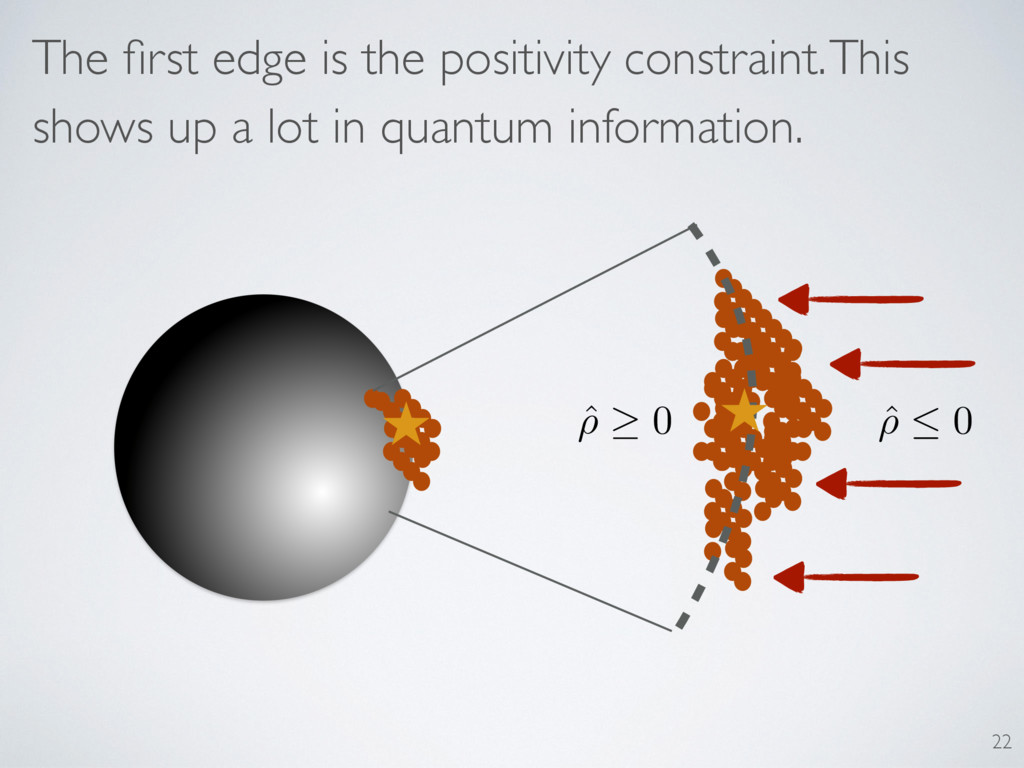
a lot in quantum information. Positivity “piles up” estimates on the boundary ! Fluctuations normal to boundary are diminished ! Estimator is biased ˆ ⇢ 0 21
respects boundaries? Quantum states = unitary DOF + classical simplexes 13 Gaussian distribution of estimates Wilks Theorem says: We model LLRS as: One fluctuating parameter = one unit of LLRS
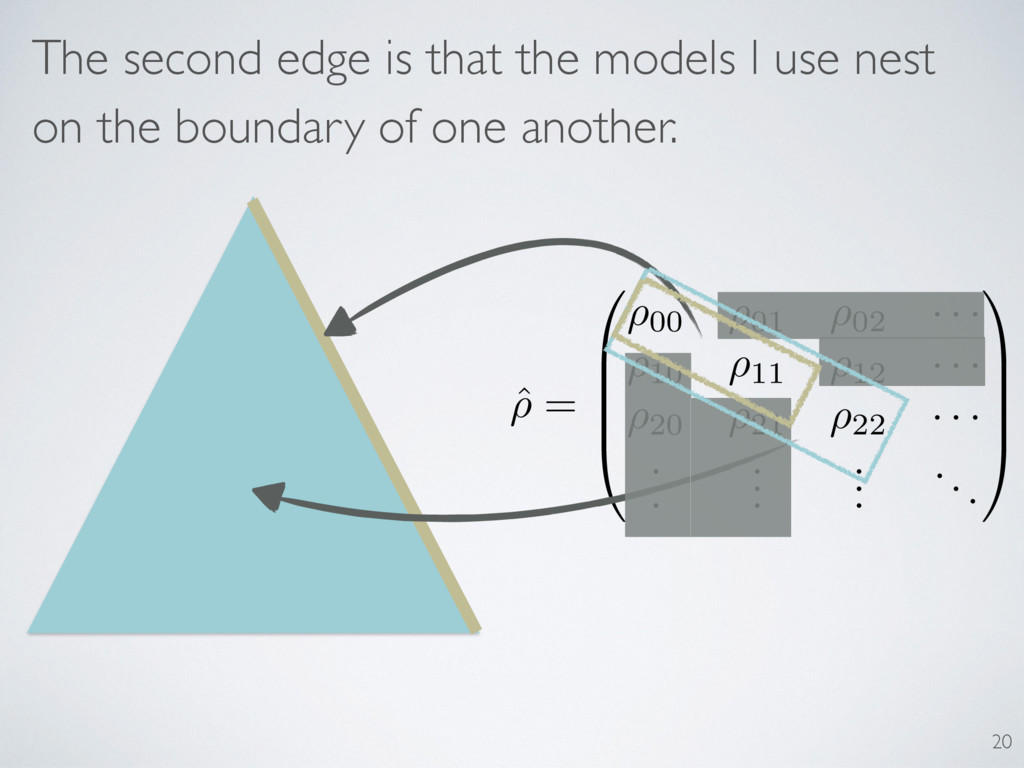
respects boundaries? Quantum states = unitary DOF + classical simplexes LLRS depends on rank of true state ˆ ⇢ = 0 B B B @ ⇢00 ⇢01 ⇢02 · · · ⇢10 ⇢11 ⇢12 · · · ⇢20 ⇢21 ⇢22 · · · . . . . . . . . . ... 1 C C C A 2 units of LLRS per rank 12
respects boundaries? LLRS depends on spectral fluctuations Requires Monte Carlo for simulating effect of boundaries Quantum states = unitary DOF + classical simplexes 11 h ( Md, Md+1) i = 2 rank( ⇢true) + Simplex Result
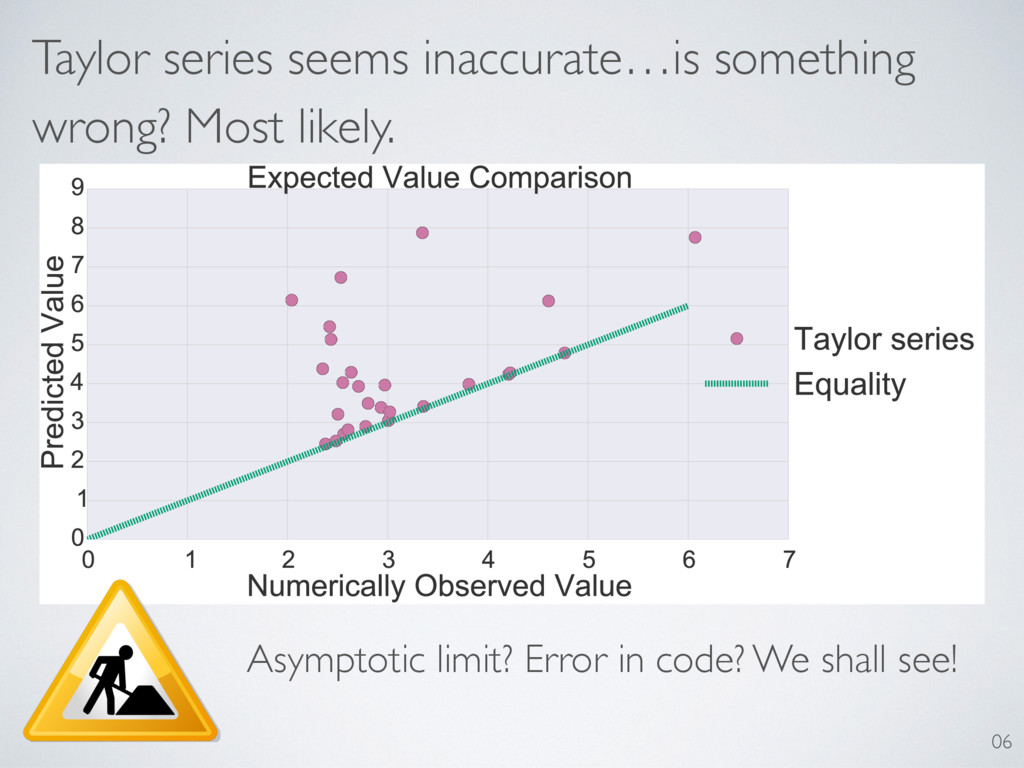
Expand LLRS as function of true state to second order (Md, Md0 ) = (⇢true, Md0 ) (⇢true, Md) Helpful trick: 09 Wilks and our model both rely on the existence of a second-order Taylor series expansion. Is Taylor expansion a good predictor of LLRS?
model selection in quantum tomography! Cannot use Wilks (too high!) Replacement: Unitary DOF + Simplex (Still too high!) 04 Models have boundaries! Construct Taylor series (reduces to Wilks) Use Taylor series to determine when our model will work Devise quantum replacement for Wilks
estimator of expected value Make a quantum information criterion A model selection rule for displaced/squeezed states Apply active subspace methods to speed up optimization What’s with compressed sensing and model selection? 02
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}