Share
2025/02/26に行われた「そのオブザーバビリティツール、どう活かした?実践例と効果の全貌」の登壇資料です。
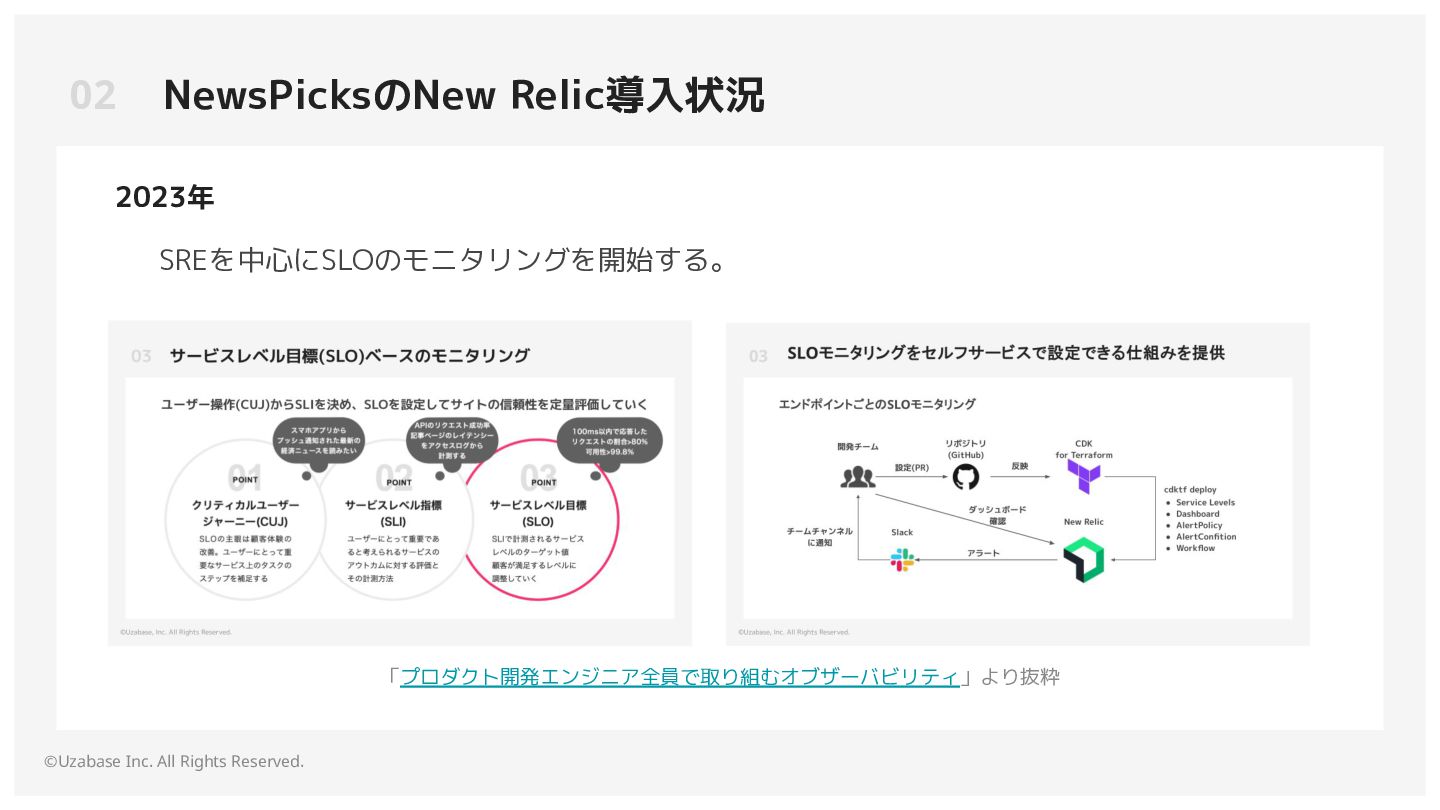
資料内のリンク プロダクト開発エンジニア全員で取り組むオブザーバビリティ HikariCPのinstrumentation S3 バケットへの Java ヒープダンプファイルのエクスポート | AWS re:Post https://github.com/newrelic/nri-ecs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}