Refactoring Mining - The key to unlock software evolution
Keynote at the International Workshop on Refactoring
co-located with the 36th IEEE/ACM International Conference on Automated Software Engineering (ASE '21)
November 14, 2021
is ignored • Method body includes only method calls and field accesses • Most refactorings detected based on signature matching • Only precision is provided • Evaluation included only 3 systems
2010): "The precision and recall on open source projects were 0.74 and 0.96 respectively." "Since these programs did not document refactorings, we created a set of correct refactorings by running REF-FINDER with a similarity threshold (σ=0.65) and manually verified them. We then measured a recall by comparing this set with the results found using a higher threshold (σ=0.85)"
checking out and parsing Git commits • Infrastructure for monitoring GitHub projects • Automatic generation of emails to contact developers • A web app for thematic analysis
and August 7th, 2015 • Sent 465 emails and received 195 responses (42%) • +27 commits with a description explaining the reasons • Compiled a catalogue of 44 distinct motivations for 12 well-known refactoring types
is not discussed or considered, that RefFinder has poor recall (0.24 [31]). The authors did a good job of combating the low-precision by manually inspecting results, the low recall is not discussed or dealt with."
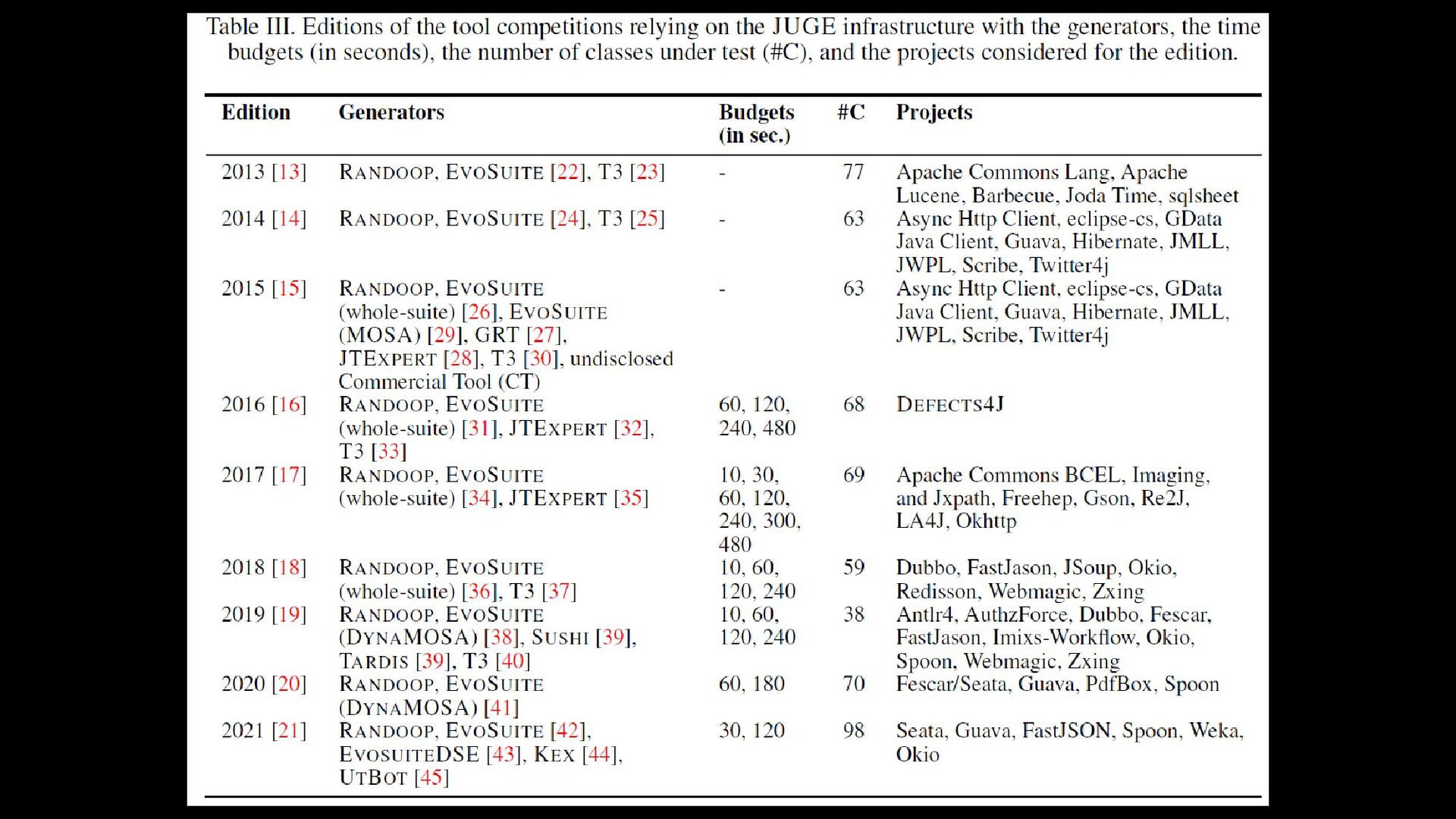
thresholds need calibration for projects with different characteristics 2. Dependence on built versions • only 38% of the change history can be successfully compiled [Tufano et al., 2017] 3. Unreliable oracles for evaluating precision/recall • Incomplete (refactorings found in release notes or commit messages) • Biased (applying a single tool with two different similarity thresholds) • Artificial (seeded refactorings)
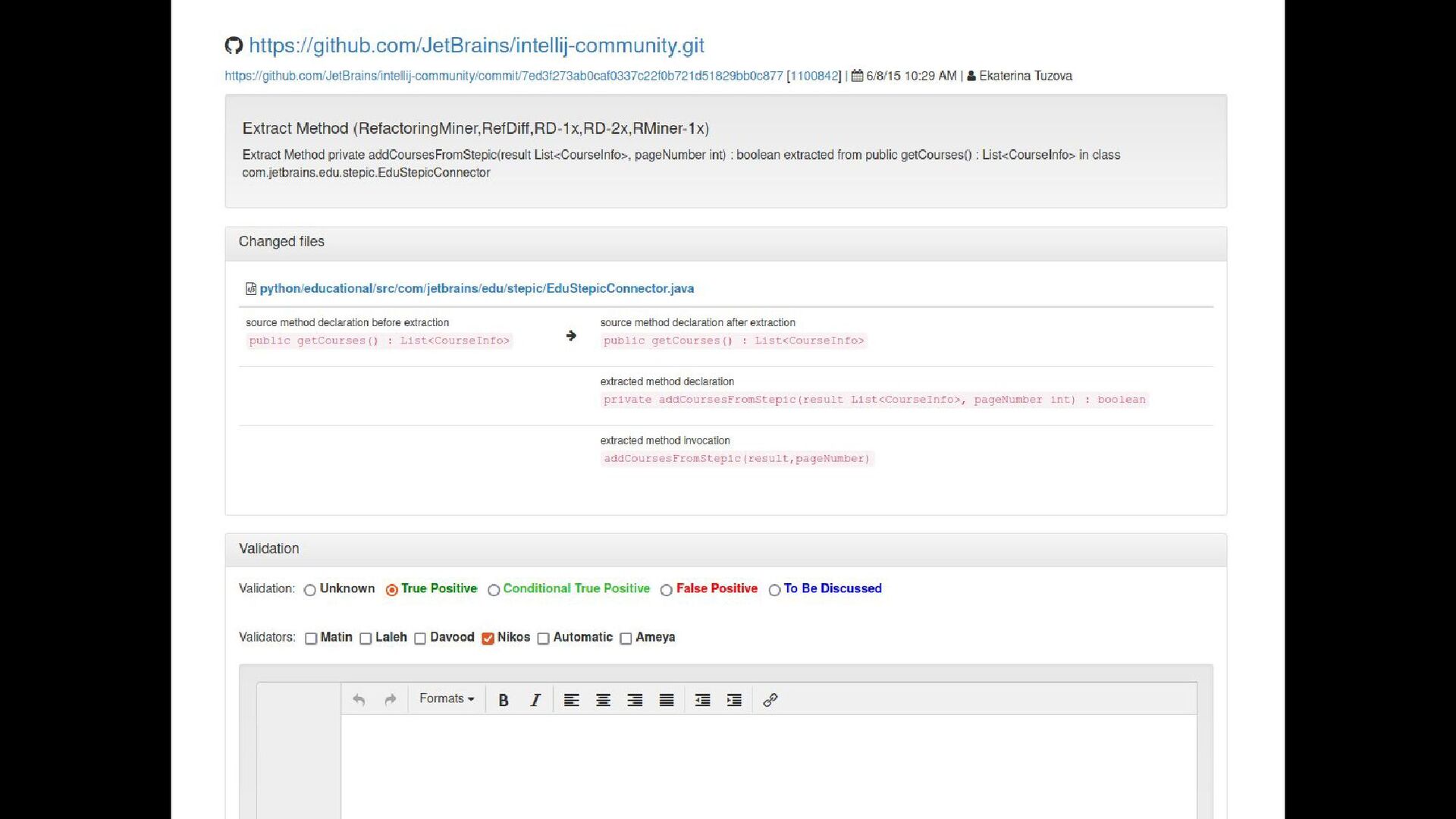
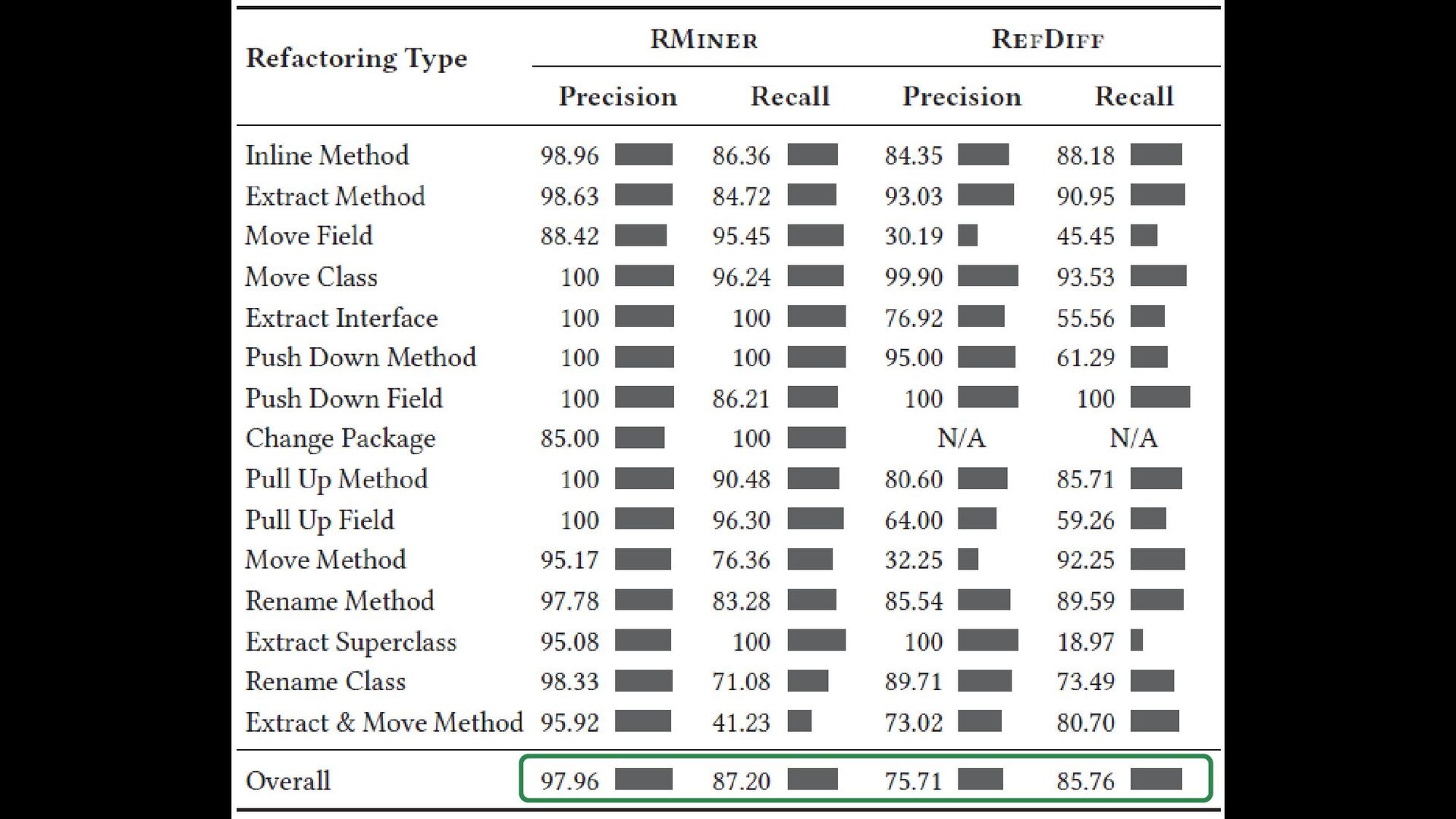
(538 commits from 185 open source projects) • We executed both available tools (RefactoringMiner and RefDiff) • Converted the output of the tools to the same format • We manually validated all refactoring instances (4,108 unique instances, out of which 3,188 were true positives and 920 were false positives) • The validation process was labor-intensive and involved 3 validators for a period of 3 months (i.e., 9 person-months) • To compute recall, we considered the union of the true positives reported by both tools as the ground truth. Matin Mansouri Laleh Eshkevari Davood Mazinanian
• Time pressure • It was urgent to establish RefactoringMiner with a publication • ICSE deadline: August 25, 2017 • Sophia’s birth: August 15, 2017 • Despite working over 1 year on this paper, there was still space for improvement • The entire team graduated after this work
refactoring types detected based on AST node replacements • Nested refactoring detection • Refactoring inference • Improved the matching of method calls to method declarations with argument type inference
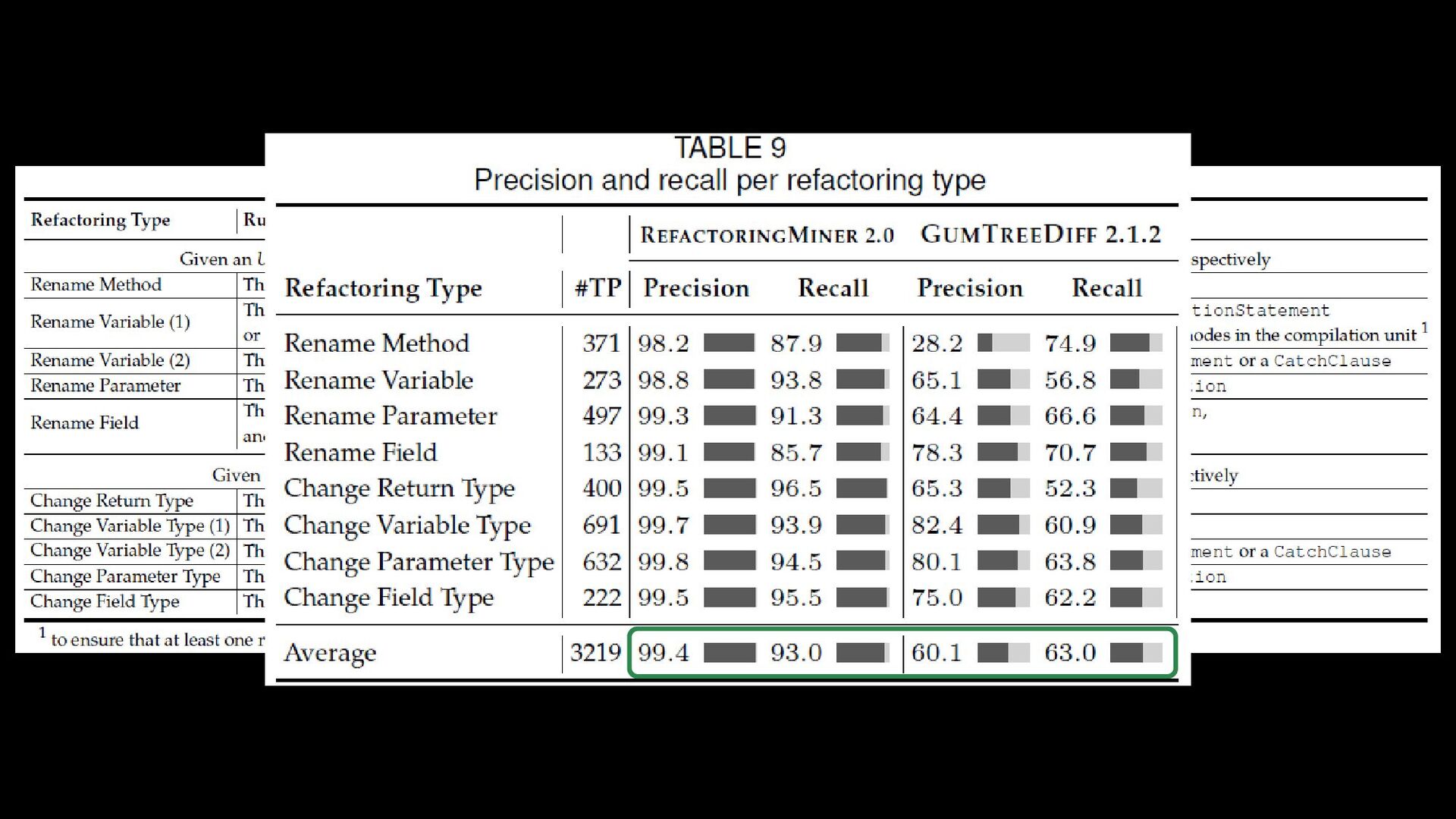
• RefactoringMiner 1.0 and 2.0 • RefDiff 0.1.1, 1.0, 2.0 • GumTreeDiff 2.1.2 • Converted the output of the tools to the same format • We validated 5,830 new unique refactoring instances, out of which 4,038 were true positives and 1,792 were false positives. • 7,226 true positives in total for 40 different refactoring types (72% of true instances are detected by two or more tools) Ameya Ketkar
true positives in the oracle • Precision: 99.7% • Recall: 97% • Most tested and reliable version (200K commits without exception) • Independent studies confirm it has the best precision
usable tool Minimum 5 years of research and development Extensive testing Detailed documentation (README with API code snippets) Supporting users (200+ issues resolved) Stable project leader Great team
Independent studies revealed that Ref-Finder had low precision/recall • 35% precision, 24% recall [Soares et al. JSS 2013] • 27% precision [Kádár et al. PROMISE 2016] • Ref-Finder paper claimed 74% precision, 96% recall • Collected refactoring info at release level (between two versions) • Coarse-grained analysis led to strong and unsafe assumptions
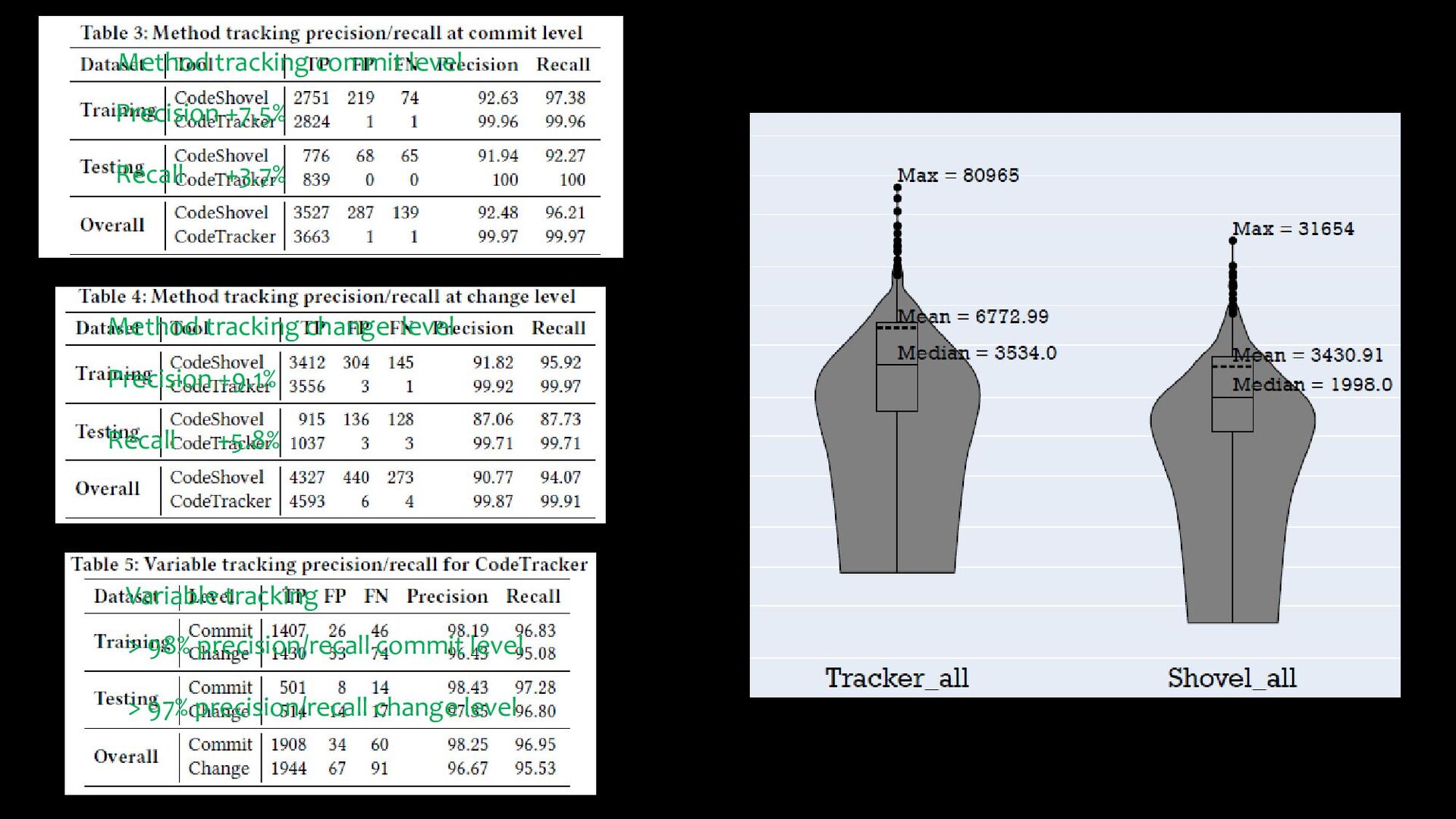
moves • File renames/moves • Uses thresholds when comparing program elements, calibrated on a training set of 100 methods • Mismatches methods from which a significant part of their body has been extracted to new methods, as it uses a 75% body similarity threshold to match modified methods • Ultra-fast: Less than 2 seconds to fetch the entire change history of a method
a way that is not computationally expensive? Mehran Jodavi Solution Partial and incremental commit analysis based on the location of the tracked program element
between the AST nodes Soft links: repetitive change patterns Refactoring links: edits in different locations originating from the same refactoring Cosmetic links: changes in comments & reformatting
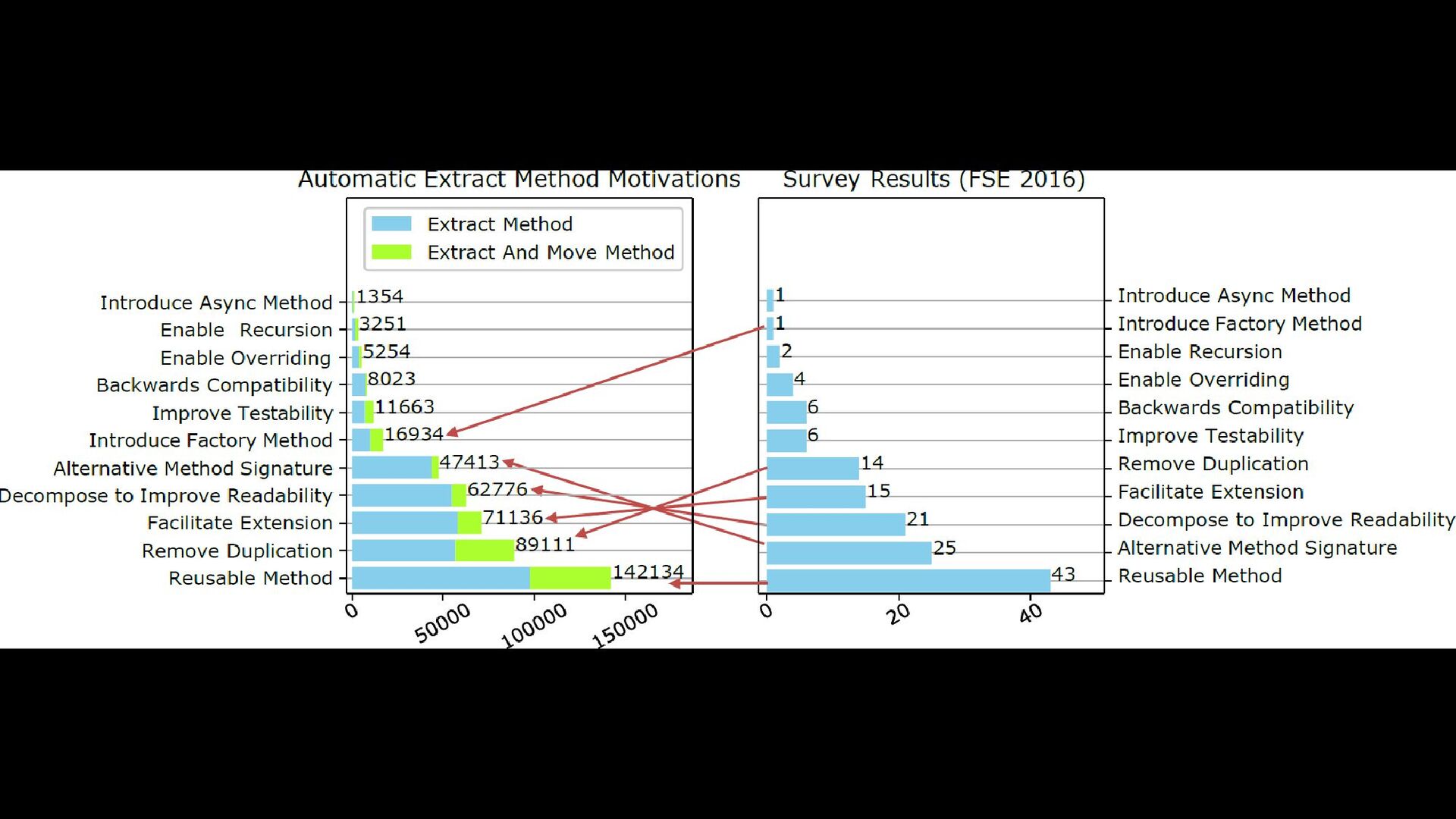
detection rules for refactoring motivations • We optimized the rules on the FSE’16 “Why We Refactor” dataset • We validated their accuracy on the TOSEM’2020 dataset • Precision: 98.4% Recall: 93.5% • We collected the motivations for 346K Extract Method instances found in 132,897 commits of 325 open-source repositories Sadegh Aalizadeh J. Pa ntiuchina , F. Za m pe tti, S. Sca la brino, V. Pia nta dosi, R. Olive to, G. Bavota , a nd M. Di Pe nta , "Why Deve lope rs Re fa ctor Source Code : A Mining-ba se d Study,“ ACM Tra nsa ctions on Softwa re Engine e ring a nd Me thodology, Volum e 29, Issue 4, Article 29, Se pte m be r 2020.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![private static Address[] createAddresses(int count) { Address[] addresses = new](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_29.jpg){kind=link}
![private static Address[] createAddresses(int count) { Address[] addresses = new](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_30.jpg){kind=link}
![private static Address[] createAddresses(int count) { Address[] addresses = new](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_31.jpg){kind=link}
![private static Address[] createAddresses(int count) { Address[] addresses = new](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_32.jpg){kind=link}
![private static Address[] createAddresses(int count) { Address[] addresses = new](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_33.jpg){kind=link}
![private static Address[] createAddresses(int count) { Address[] addresses = new](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_34.jpg){kind=link}
{kind=link}
![private static Address[] createAddresses(int count) { Address[] addresses = new](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_36.jpg){kind=link}
![private static Address[] createAddresses(int count) { Address[] addresses = new](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_37.jpg){kind=link}
![private static Address[] createAddresses(int count) { Address[] addresses = new](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_38.jpg){kind=link}
![private static Address[] createAddresses(int count) { Address[] addresses = new](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_39.jpg){kind=link}
![private static Address[] createAddresses(int count) { Address[] addresses = new](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_40.jpg){kind=link}
![private static Address[] createAddresses(int count) { Address[] addresses = new](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_41.jpg){kind=link}
![private static Address[] createAddresses(int count) { Address[] addresses = new](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
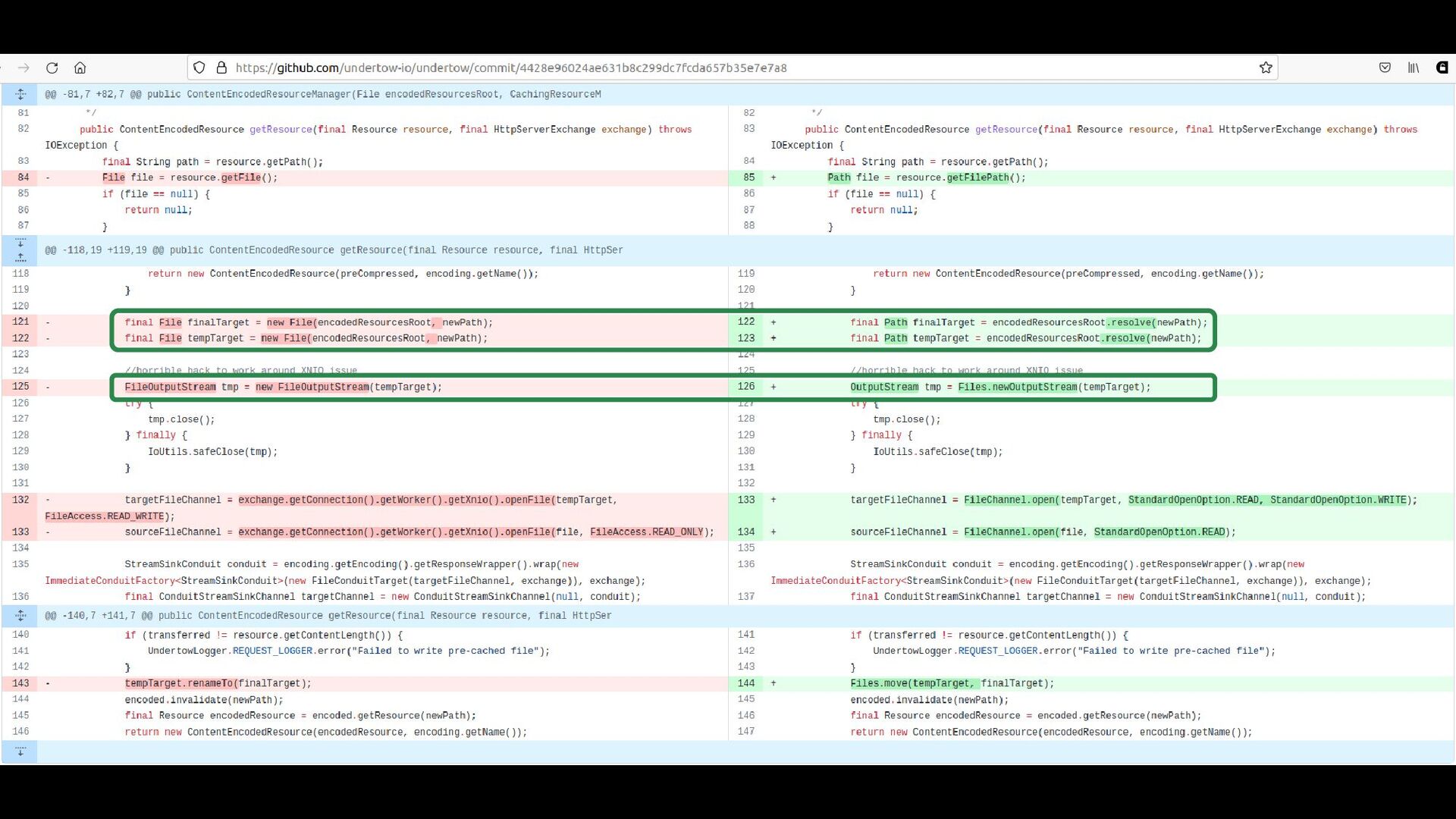
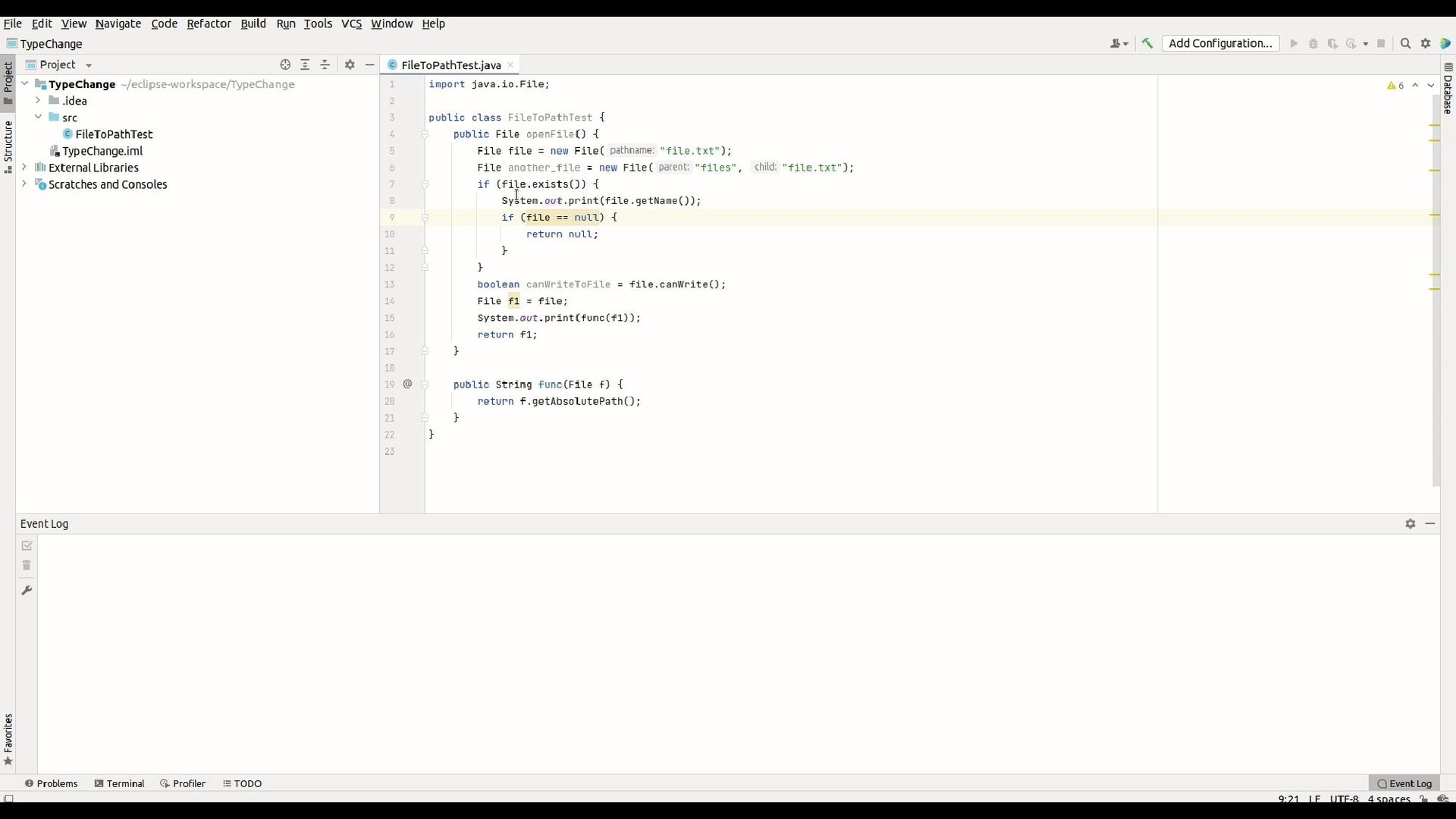
![File f = new File(:[v0], :[v1]) → Path f =](https://files.speakerdeck.com/presentations/44cd044b744449bd98a8978aeaa7c269/slide_78.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}