Каждый разработчик рано или поздно сталкивается с предметно-ориентированными языками (DSL). Мы разберемся, зачем же нам нужны DSL, и какие проблемы они нам помогают решать. Поймем, в каких случаях нам стоит разрабатывать свой язык, а в каких — использовать уже существующий. Попробуем провести грань и решить, где у нас просто библиотека, а где — предметно ориентированный язык. Придумаем свой DSL и сравним различные подходы к работе с ним в Python. Увидим, как работают лексический и синтаксический анализаторы. Обязательно поговорим про то, как облегчить жизнь пользователям нашего языка. Как сделать информативными сообщения об ошибках? Как тестировать сценарии, написанные на нашем языке? На эти вопросы мы сможем дать ответ.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
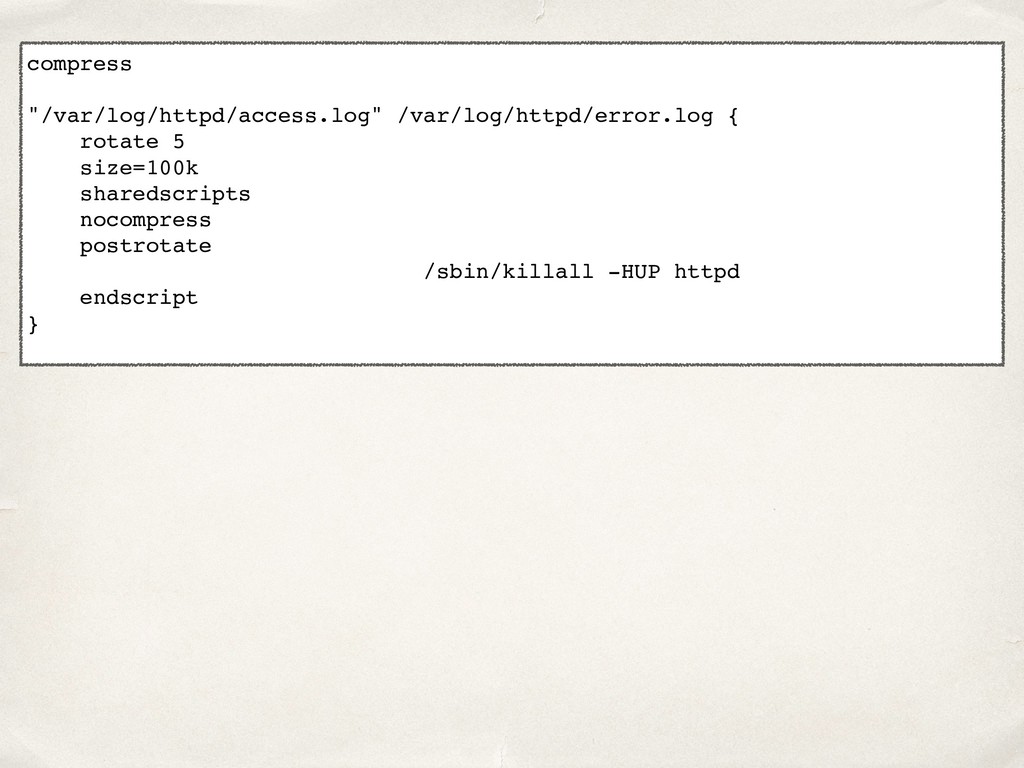
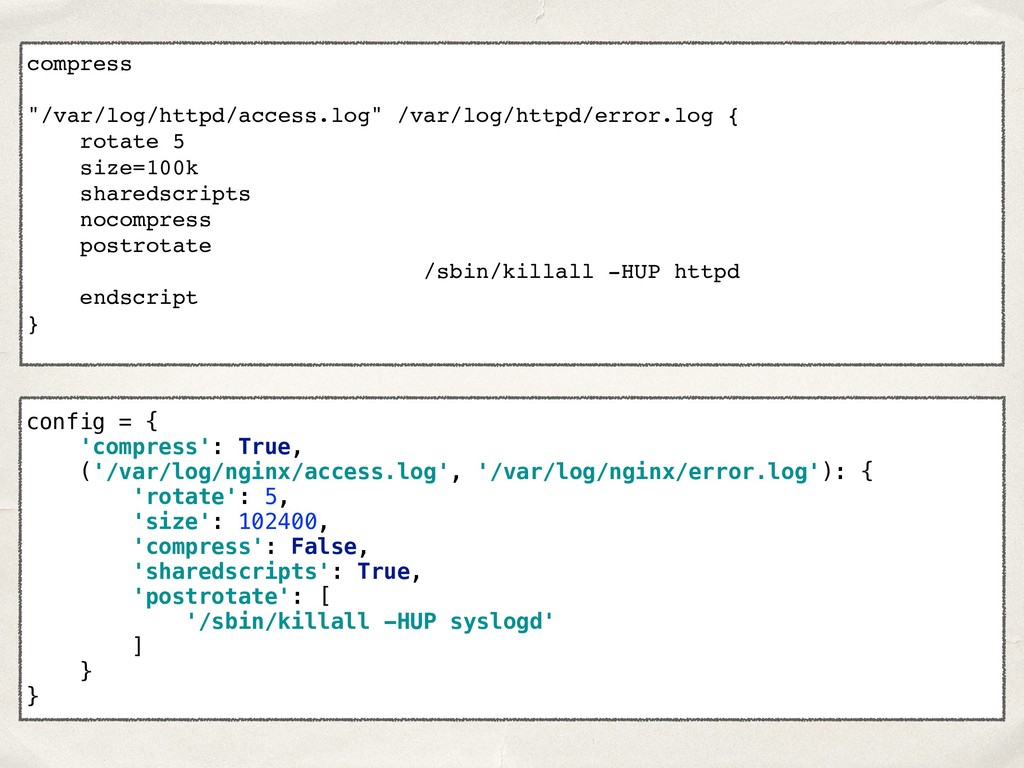
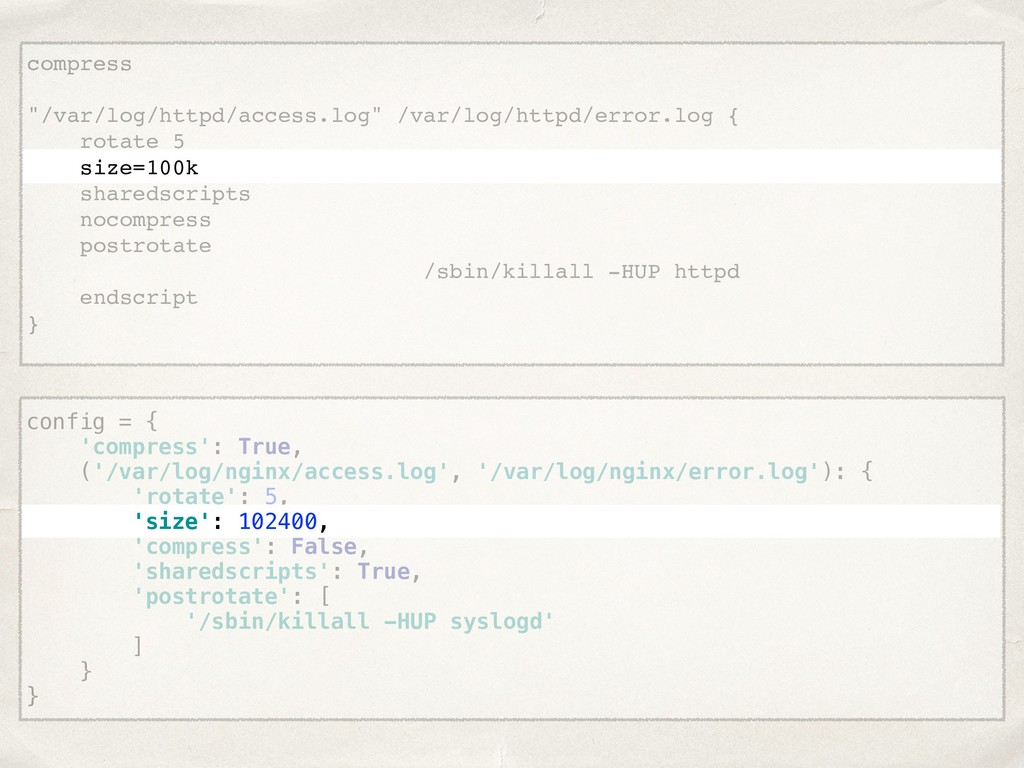
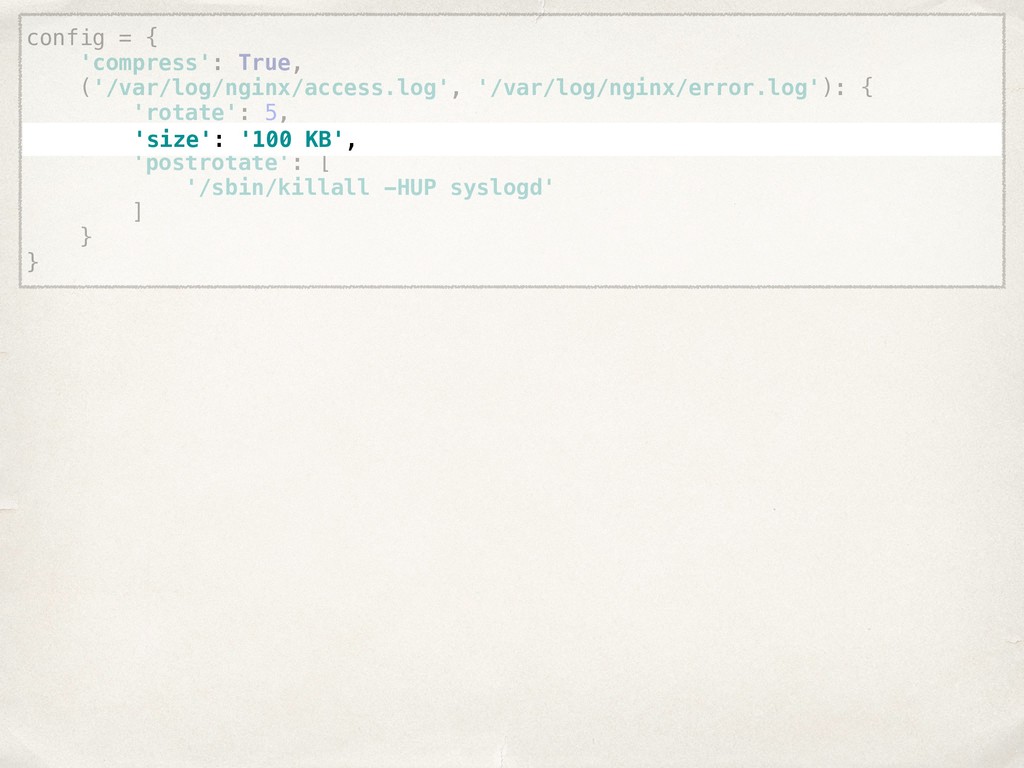
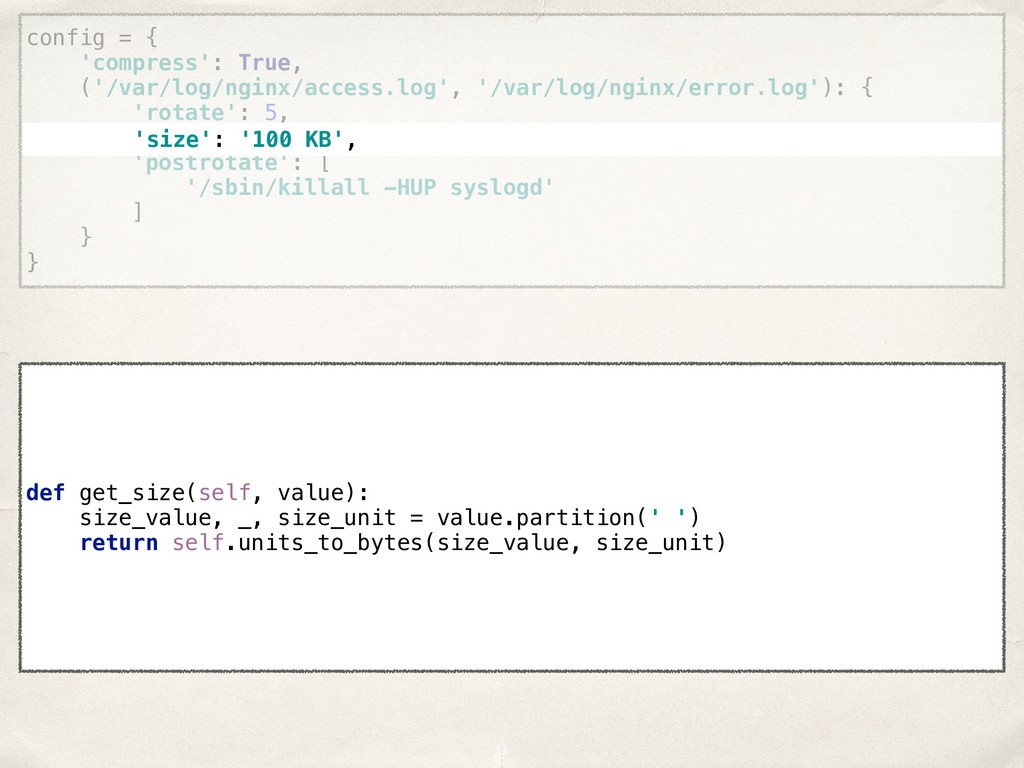
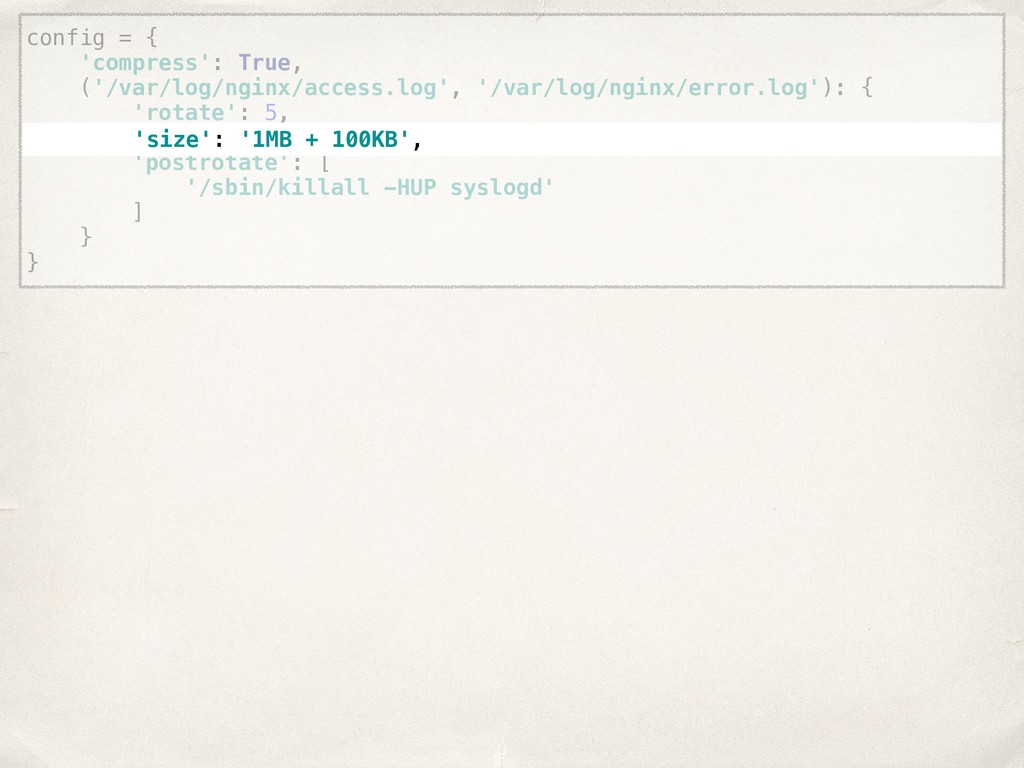
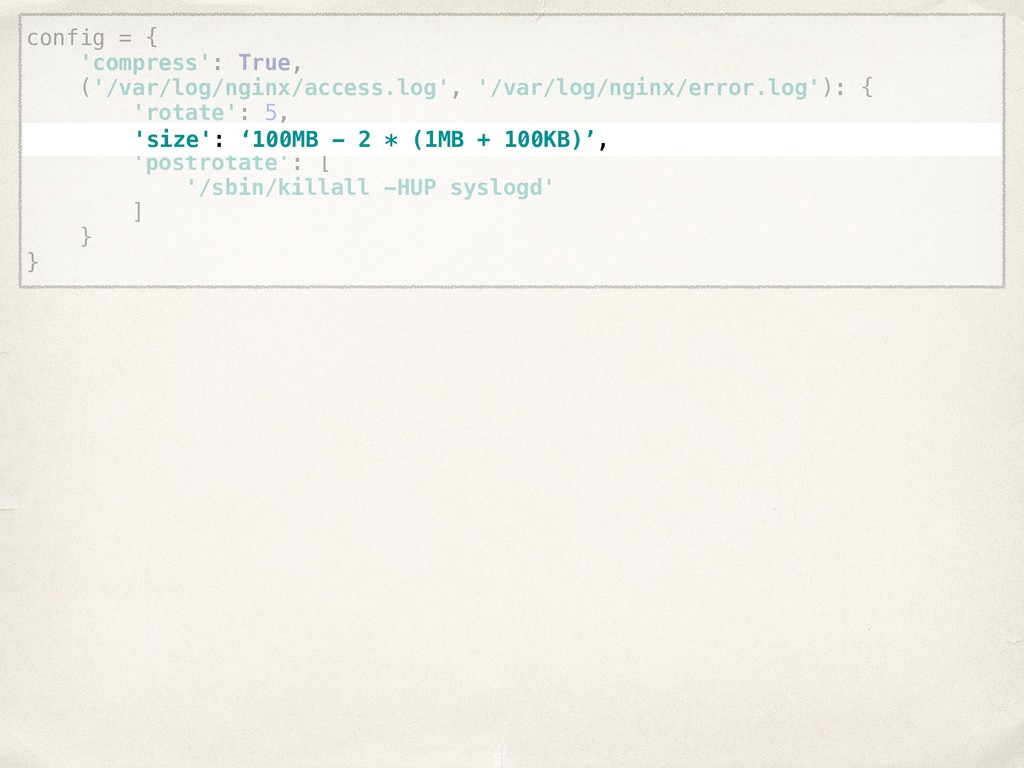
![compress: true rules: - files: [/var/log/nginx/access.log, /var/log/nginx/error.log] rotate: 5 size:](https://files.speakerdeck.com/presentations/22022261960148978445cc4d19a82760/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
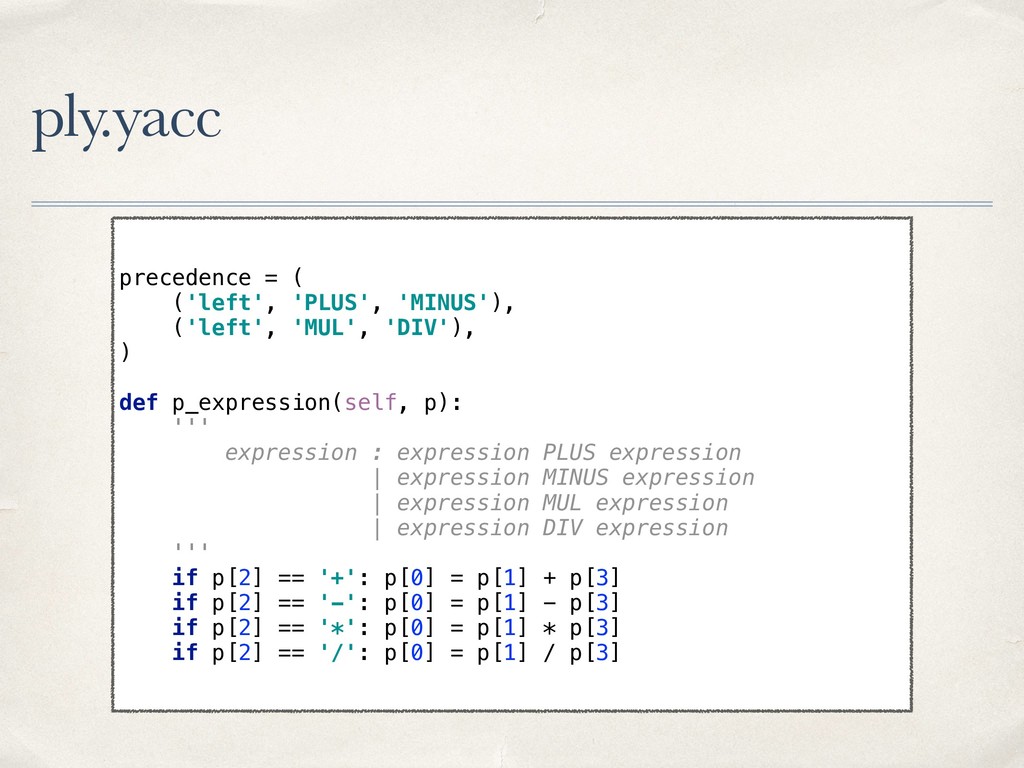{kind=link}
{kind=link}
{kind=link}
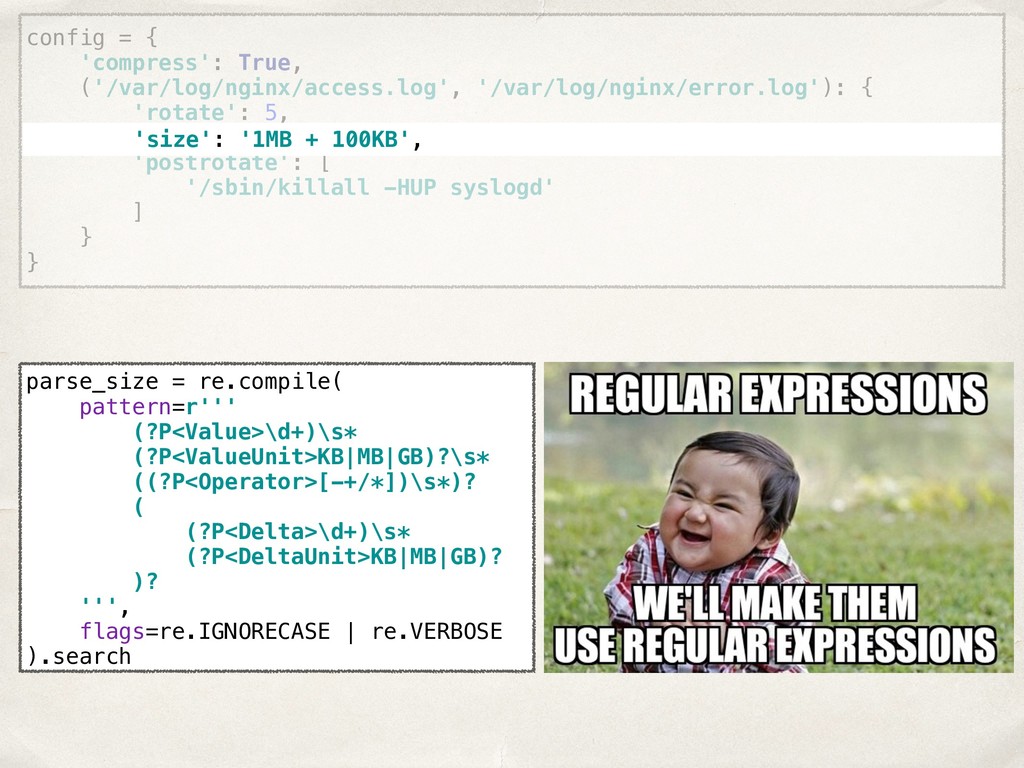
![def tokenize(str): specs = [ ('Spaces', (r'[ \s\t\r\n]+',)), ('PLUS',](https://files.speakerdeck.com/presentations/22022261960148978445cc4d19a82760/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
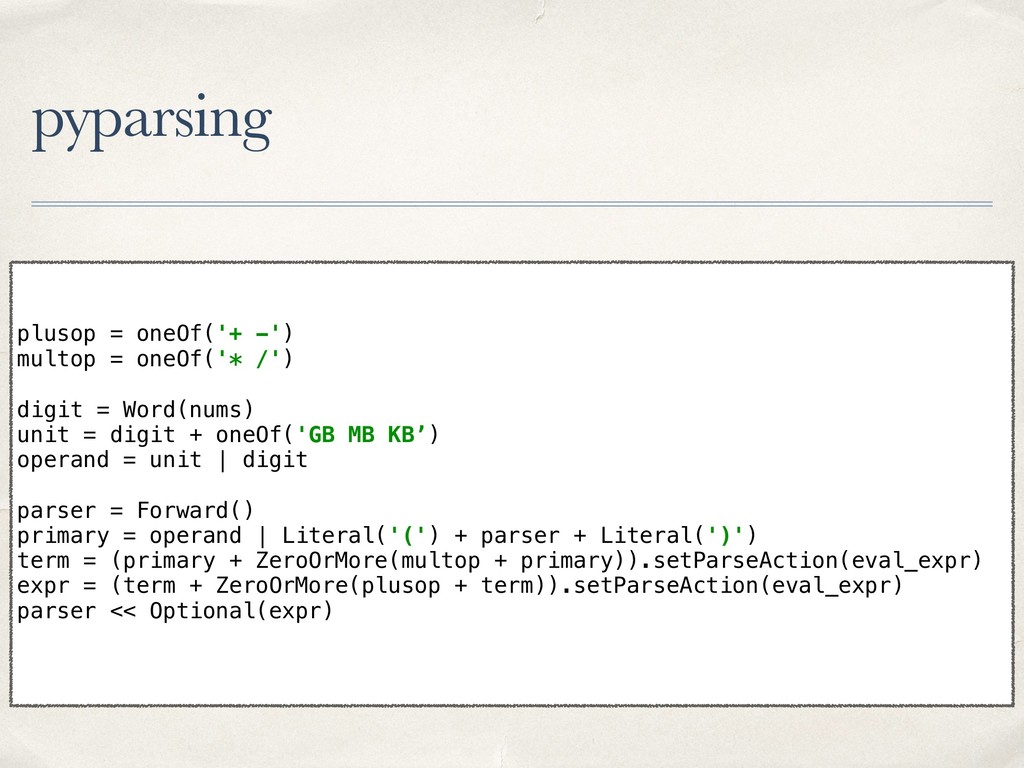{kind=link}
{kind=link}
{kind=link}
{kind=link}
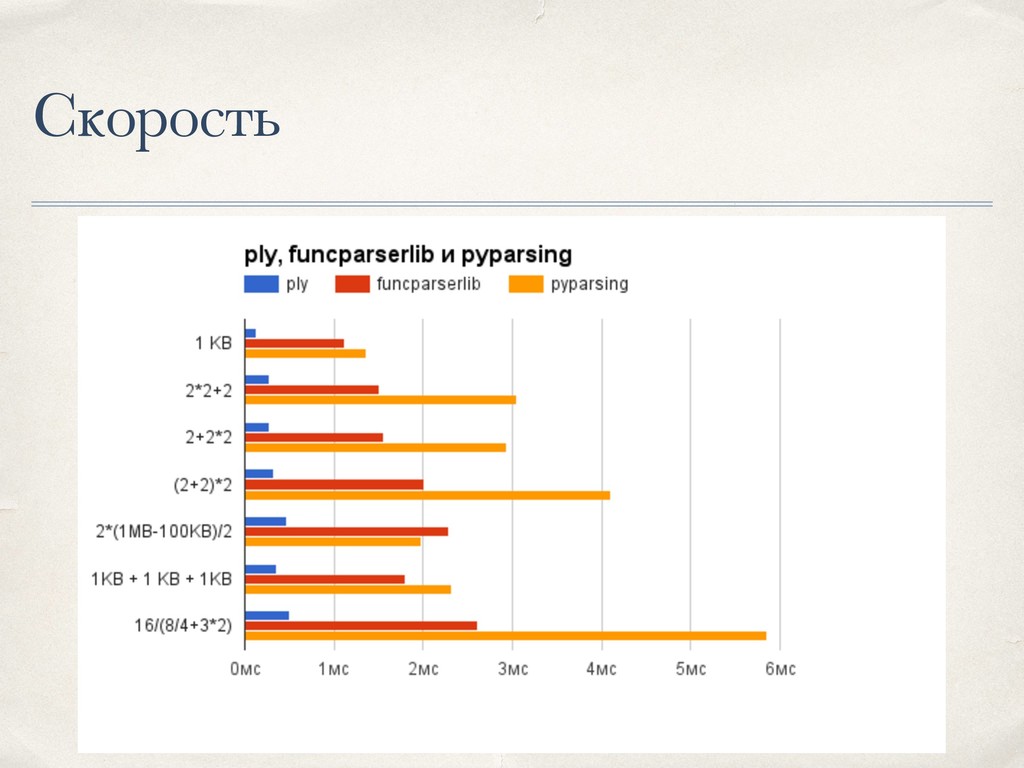{kind=link}
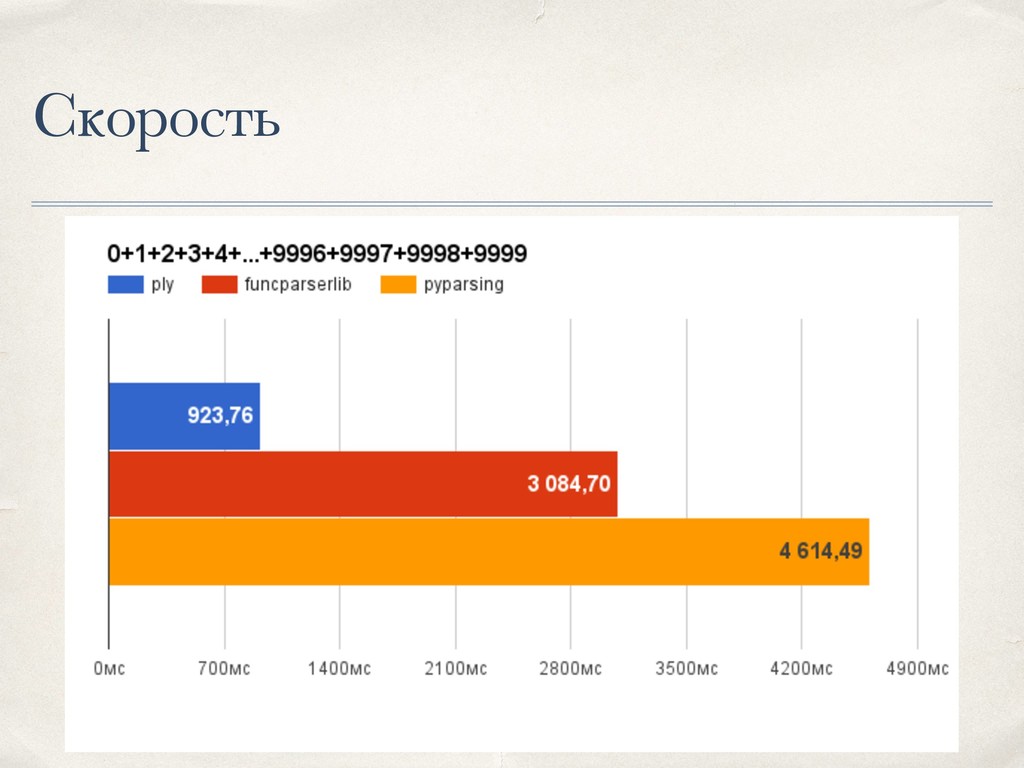{kind=link}
{kind=link}
{kind=link}
{kind=link}
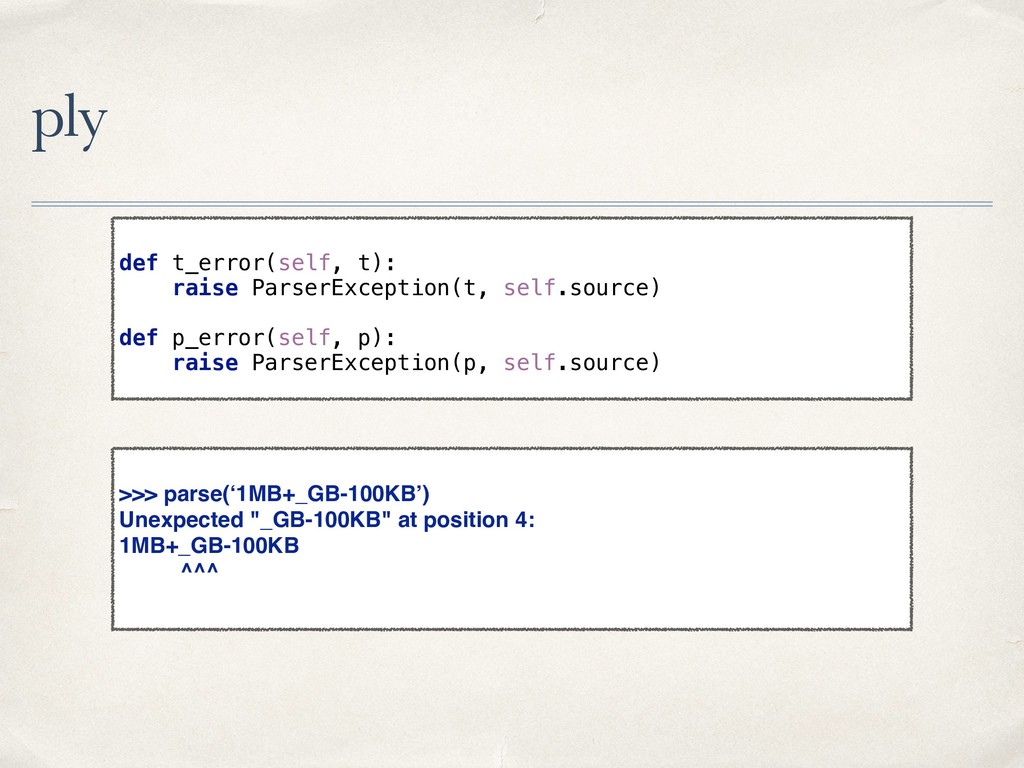{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}