• Athens University of Economics and Business, Greece Industry experience • Siemens Research (7 + 2) Books • Refactoring for software design smells Tools/platforms • Designite • QConnect
quality • Code smell detection and refactoring • Developers’ productivity • Program comprehension • Machine learning for software engineering • Software engineering for machine learning https://web.cs.dal.ca/~tushar/smart/ • Binary symbol reconstruction • Program comprehension for decompiled binaries • Vulnerability analysis for decompiled code Green AI • Sustainable machine learning • Energy hotspots and refactorings • Energy efficient code representation Sponsors and collaborators Dr. Tushar Sharma [email protected] SMART lab, Dalhousie University Tools and platforms
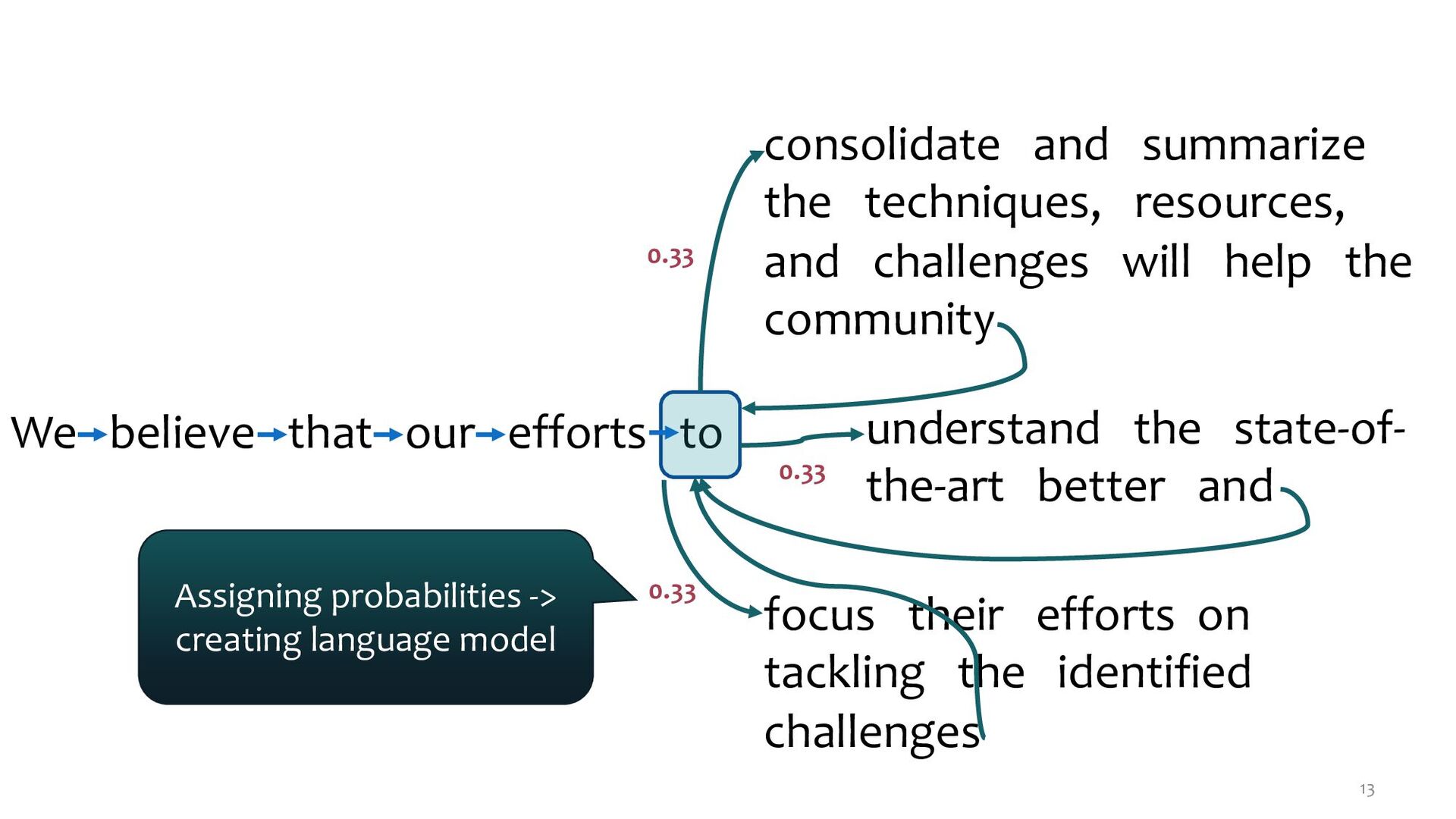
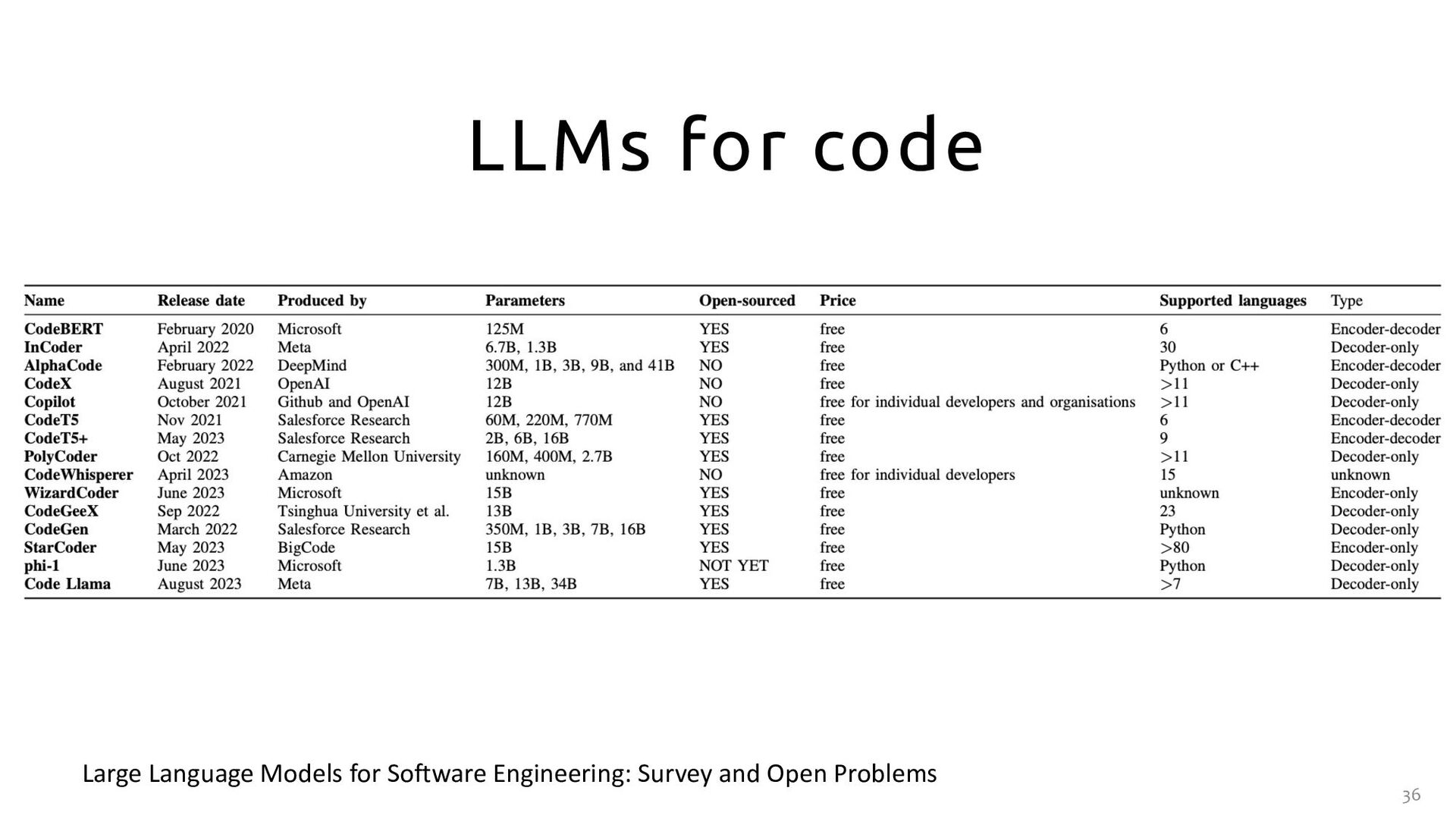
the techniques, resources, and challenges will help the community to understand the state-of-the-art better and to focus their efforts on tackling the identified challenges.
the techniques, resources, and challenges will help the community to understand the state-of-the-art better and to focus their efforts on tackling the identified challenges.
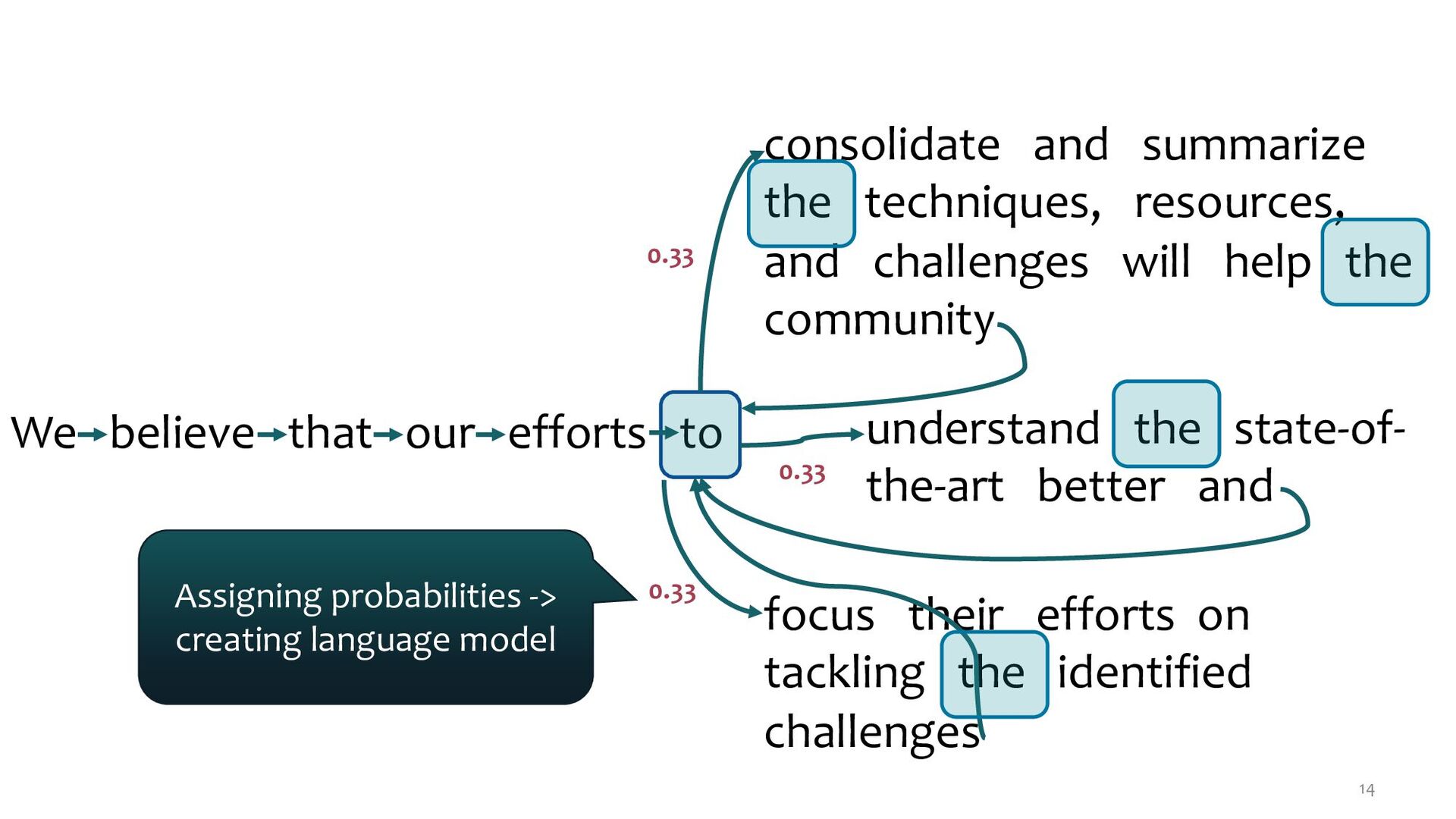
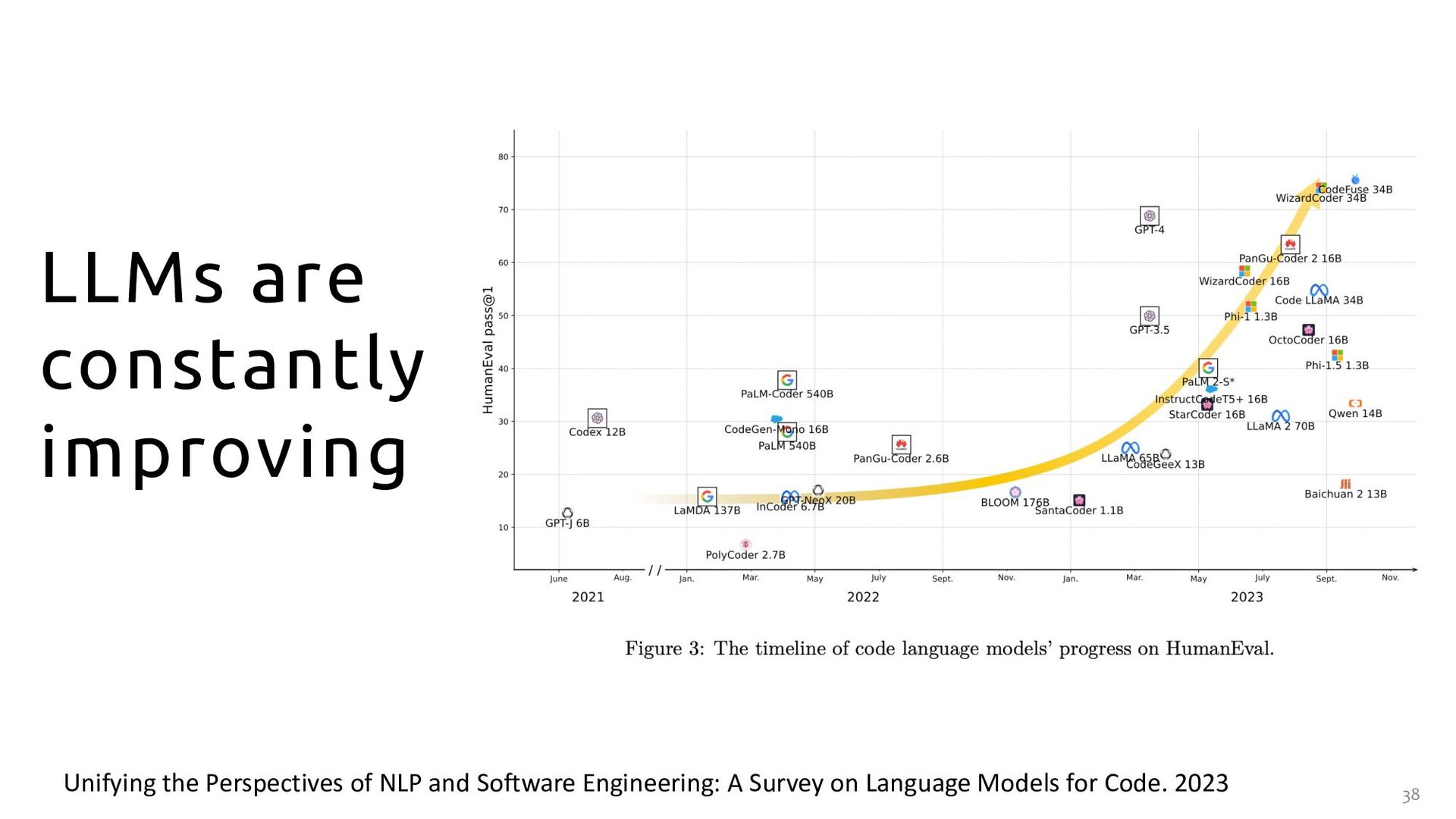
the techniques, resources, and challenges will help the community understand the state-of- the-art better and focus their efforts on tackling the identified challenges 0.33 0.33 0.33 Assigning probabilities -> creating language model
the techniques, resources, and challenges will help the community understand the state-of- the-art better and focus their efforts on tackling the identified challenges 0.33 0.33 0.33 Assigning probabilities -> creating language model
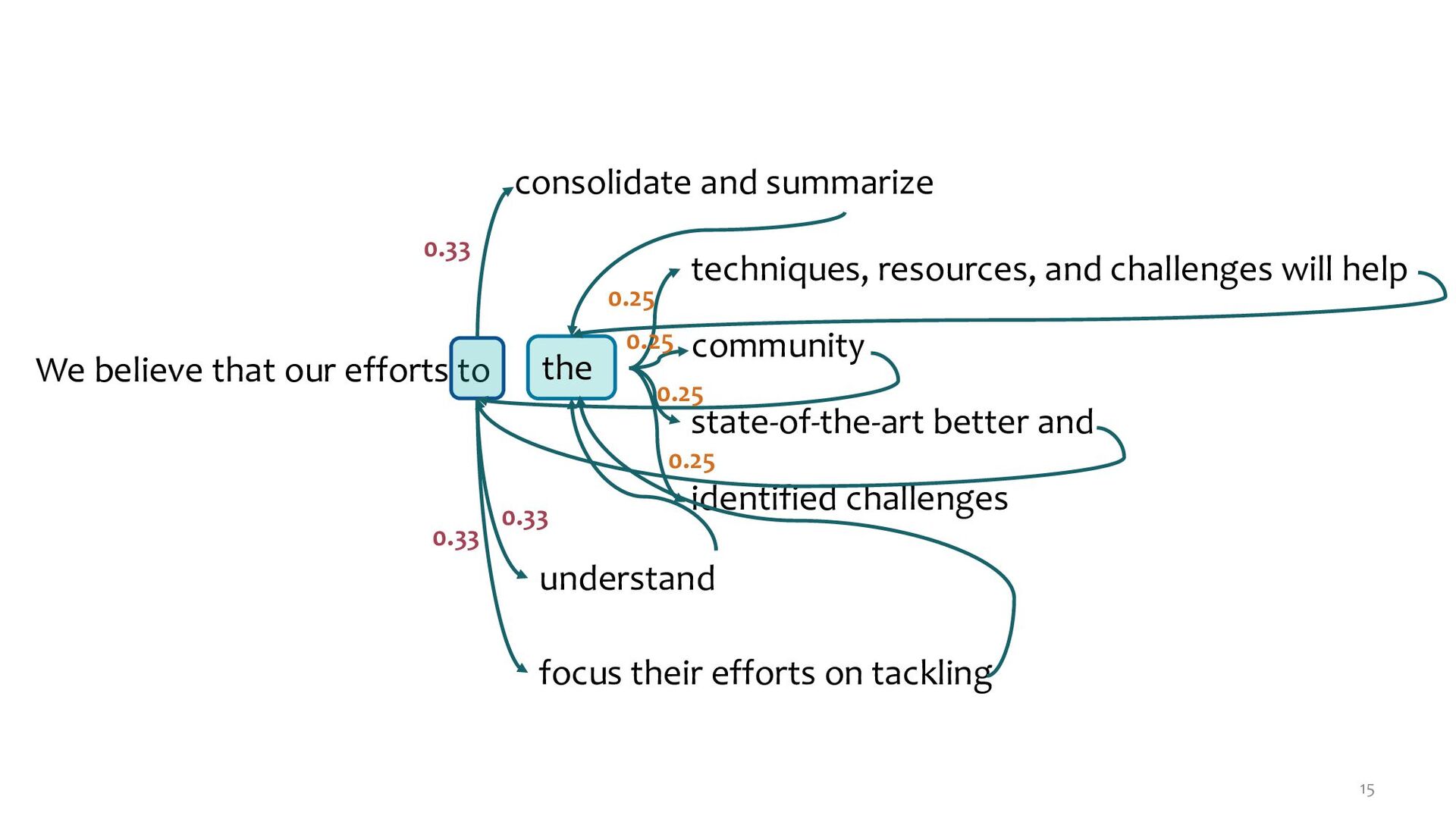
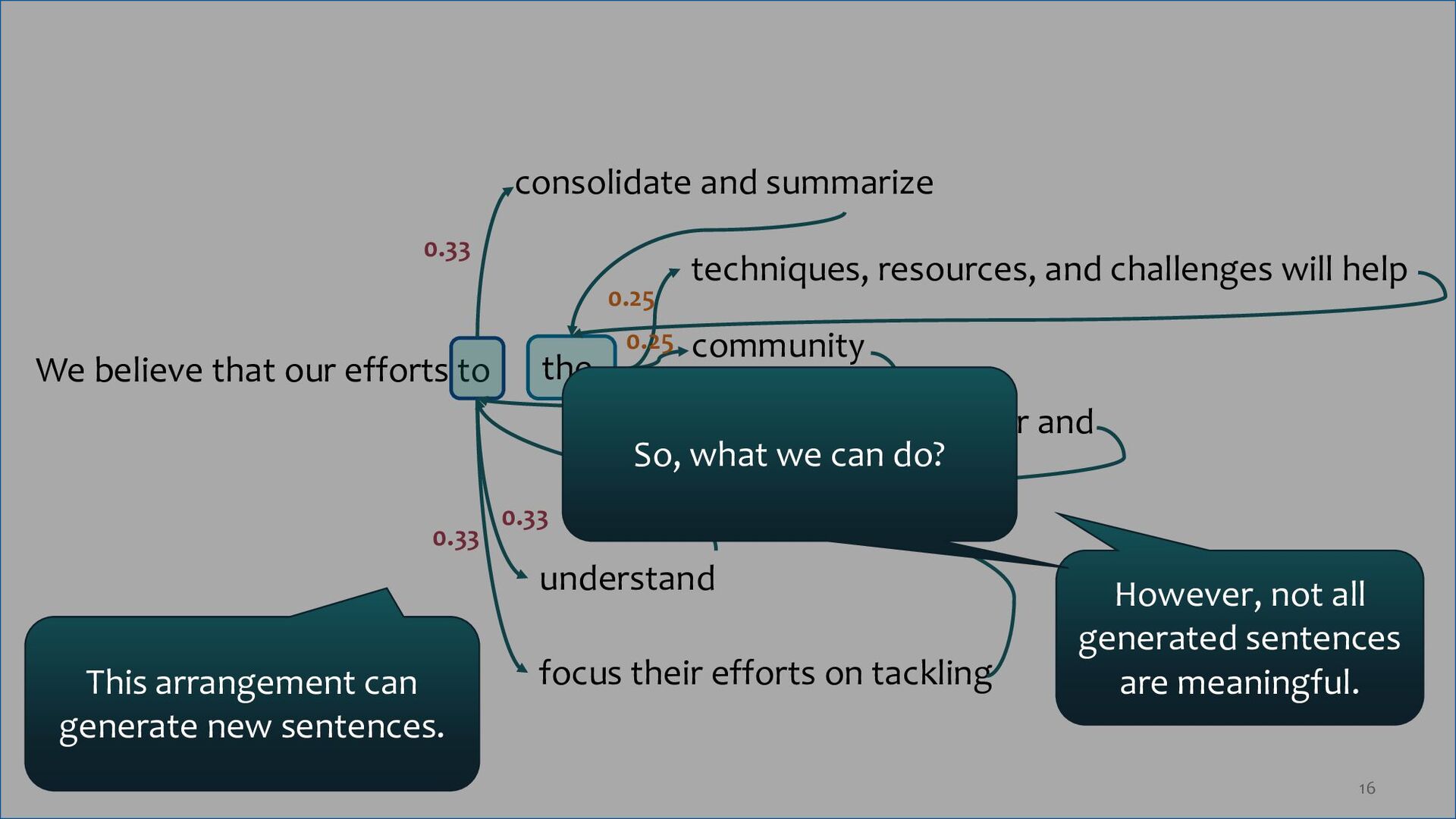
the techniques, resources, and challenges will help community understand state-of-the-art better and focus their efforts on tackling identified challenges 0.25 0.25 0.25 0.25 0.33 0.33 0.33
the techniques, resources, and challenges will help community understand state-of-the-art better and focus their efforts on tackling identified challenges 0.25 0.25 0.25 0.25 0.33 0.33 0.33 This arrangement can generate new sentences. However, not all generated sentences are meaningful. So, what we can do?
more examples to learn the probabilities. • But it might not be as helpful as desired. • A better approach would be to consider more than one token to decide the next token. • N-gram But how many?
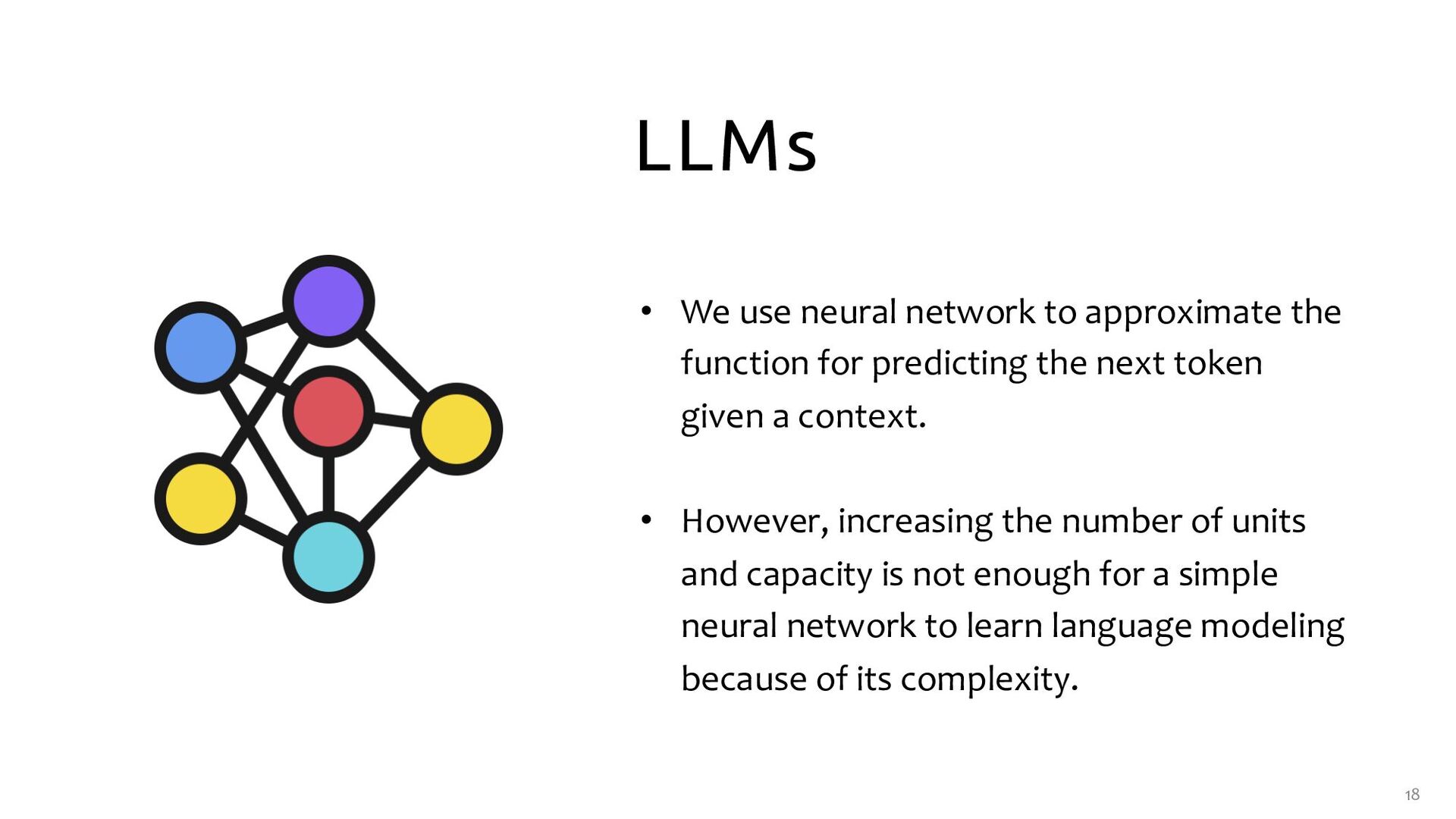
function for predicting the next token given a context. • However, increasing the number of units and capacity is not enough for a simple neural network to learn language modeling because of its complexity.
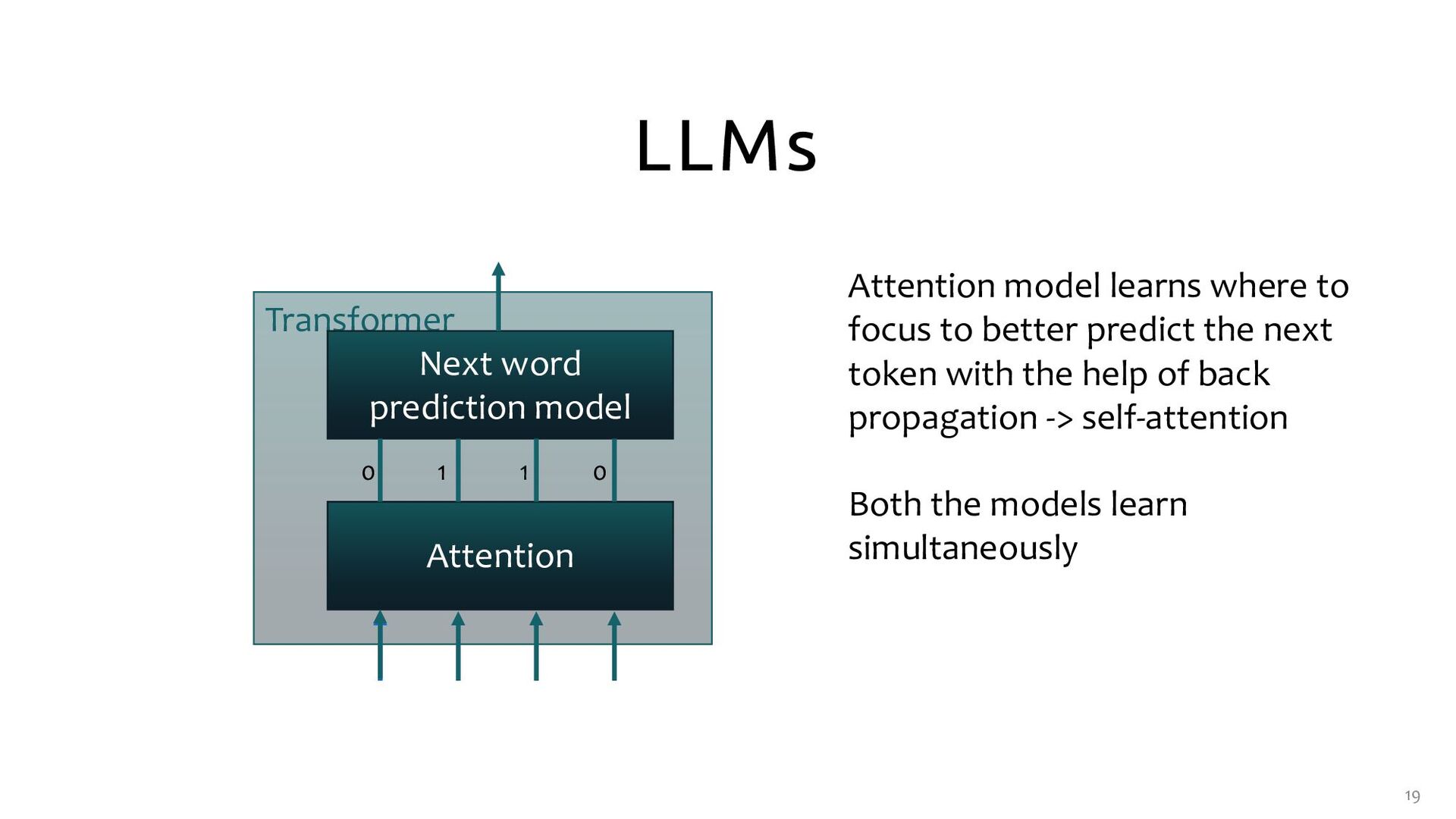
1 0 Attention model learns where to focus to better predict the next token with the help of back propagation -> self-attention Both the models learn simultaneously
model increases, the complexity also increases. • Stacking GPT-3 has 96 such layers 1 Attention Next word prediction model 0 1 0 1 Attention Next word prediction model 0 1 0 1 Attention Next word prediction model 0 1 0 1 Attention Next word prediction model 0 1 0
code Predict/Classify Summarize Selective synthesis Multi-agent processing End-to-end development Complexity Sentiment analysis, vulnerability or code quality issue prediction, … Renaming a method, document generation, … Generate code for a specific problem, … Identify security vulnerabilities in the latest commit and lodge an issue, … Identify and prioritize requirements, code, refactor, test, debug, …
- Copilot generates 61% of Java code (Feb 2023) • Test suite generation – Cover from DiffBlue • Threatening the status quo • StackOverFlow, or, in general, Google search • New tools and agents leveraging LLMs • Improved effectiveness of automated approaches using LLMs • Effective embeddings, for example 37
to newer vulnerabilities • Copilot is more prone to generate certain types of vulnerabilities • Using Copilot to fix security bugs is risky, given that Copilot did introduce vulnerabilities in at least a third of the cases we studied. Vulnerabilities in generated code Is GitHub’s Copilot as Bad as Humans at Introducing Vulnerabilities in Code?
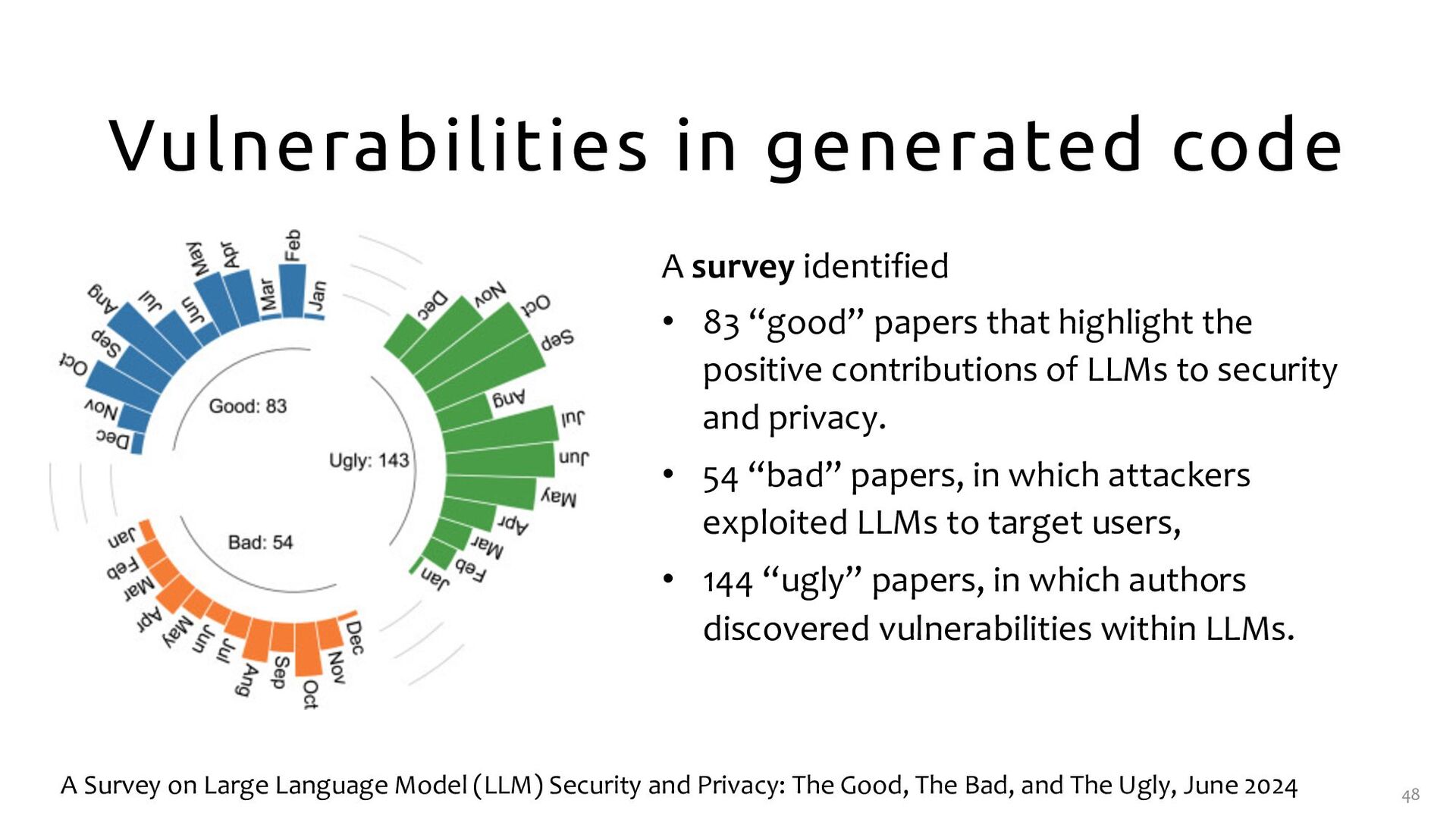
“good” papers that highlight the positive contributions of LLMs to security and privacy. • 54 “bad” papers, in which attackers exploited LLMs to target users, • 144 “ugly” papers, in which authors discovered vulnerabilities within LLMs. A Survey on Large Language Model (LLM) Security and Privacy: The Good, The Bad, and The Ugly, June 2024
these websites (approximately 78%) lacked essential extension checks exposing them to potential malicious file uploads. • Alarmingly, only 1143 (about 45.72%) websites implemented prepared statements, leaving 54.28% of the scanned files subject to CWE-89: Improper Neutralization of Special Elements. • We identified 459 SQL injection, 57 stored XSS, 394 reflected XSS vulnerable parameters in the entire dataset. LLMs in Web Development: Evaluating LLM-Generated PHP Code Unveiling Vulnerabilities and Limitations, 2024 Our findings serve as a strong reminder of the continuous and evolving threat landscape, urging developers and security professionals to remain vigilant and use generative AI with caution.
and the key influencing factor is the accuracy of self-generated examples rather than their relevance. Relevant or Random: Can LLMs Truly Perform Analogical Reasoning?
inferential rules. But compared to human performance, there still remains substantial room for improvement across all models, especially in highly compositional, symbolic and structural complex rules. Can LLMs Reason with Rules? Logic Scaffolding for Stress-Testing and Improving LLMs, May 2024
stimulate the reasoning results of logic solvers. Although LLMs demonstrate satisfactory performance on several datasets, the potential drawbacks and limitations of LLMs for logic code simulation should not be underestimated. Can LLMs Reason with Rules? Logic Scaffolding for Stress-Testing and Improving LLMs, May 2024
effectiveness • Comprehensive benchmarks (not limited to accuracy) • Evaluation on realistic problems/samples • Data leakage • Multi-step tasks that require domain-specific direction • Prompt injection • Indistinguishability between instruction and data 53
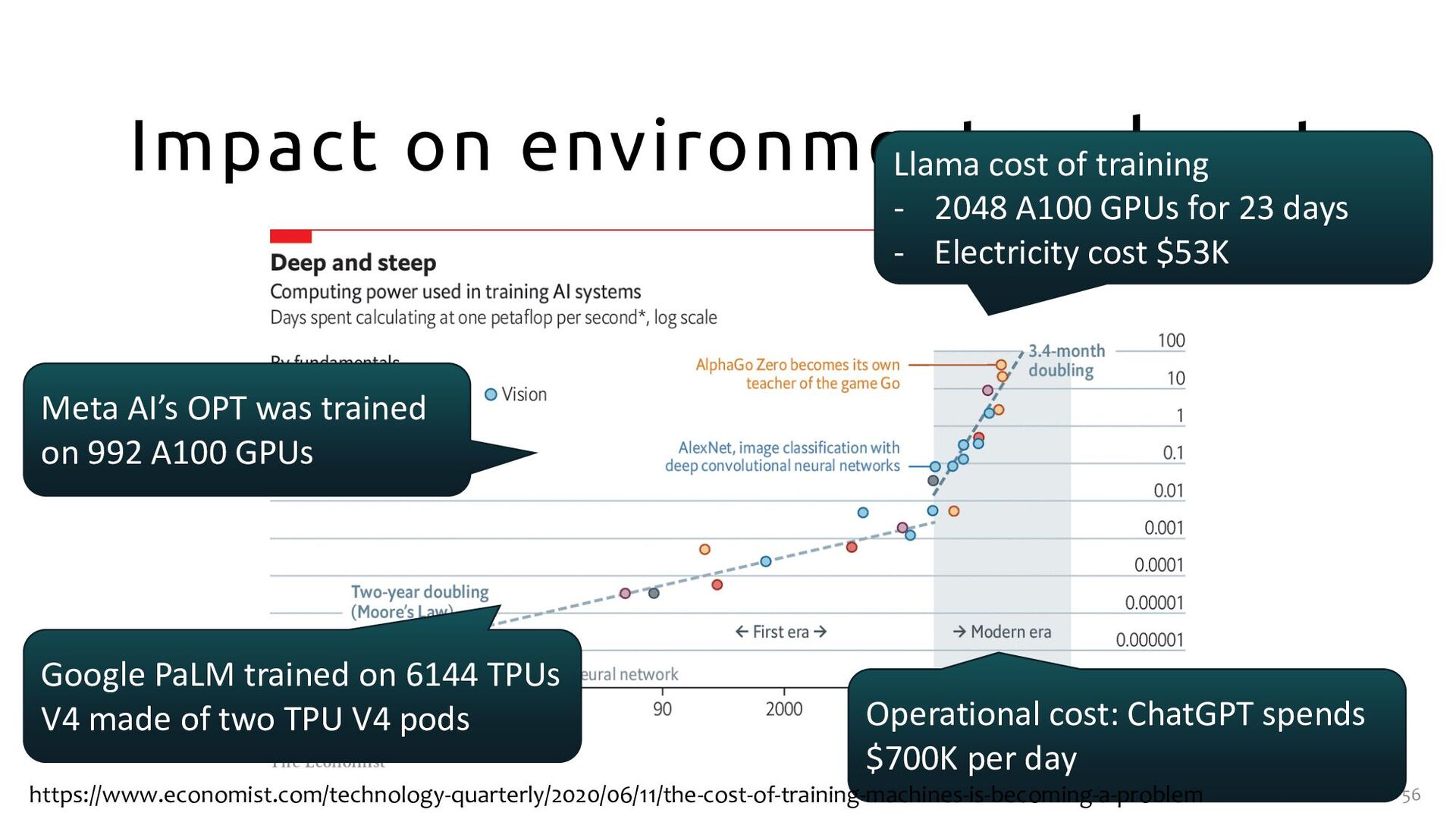
- 2048 A100 GPUs for 23 days - Electricity cost $53K Operational cost: ChatGPT spends $700K per day Google PaLM trained on 6144 TPUs V4 made of two TPU V4 pods Meta AI’s OPT was trained on 992 A100 GPUs https://www.economist.com/technology-quarterly/2020/06/11/the-cost-of-training-machines-is-becoming-a-problem
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
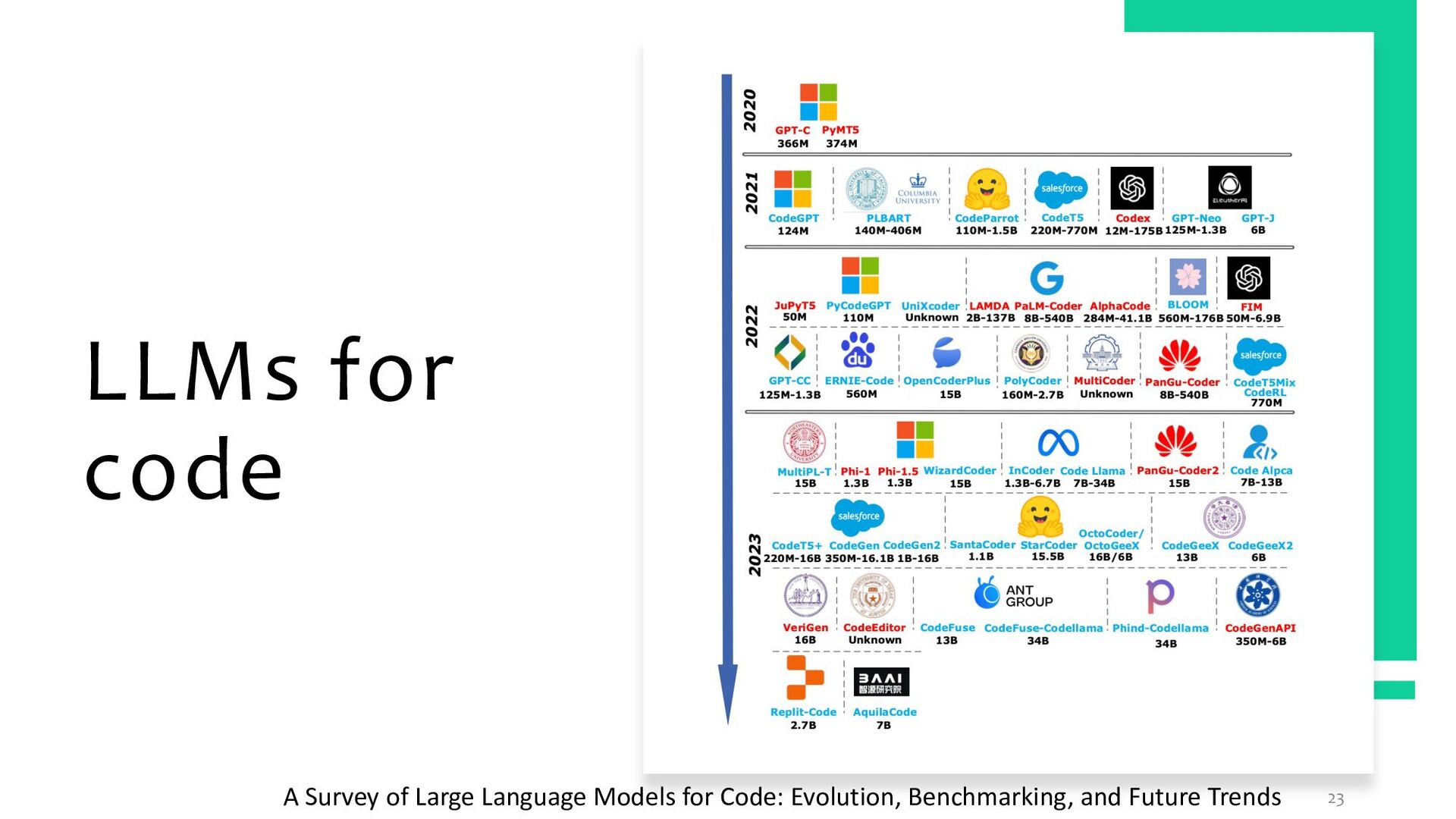{kind=link}
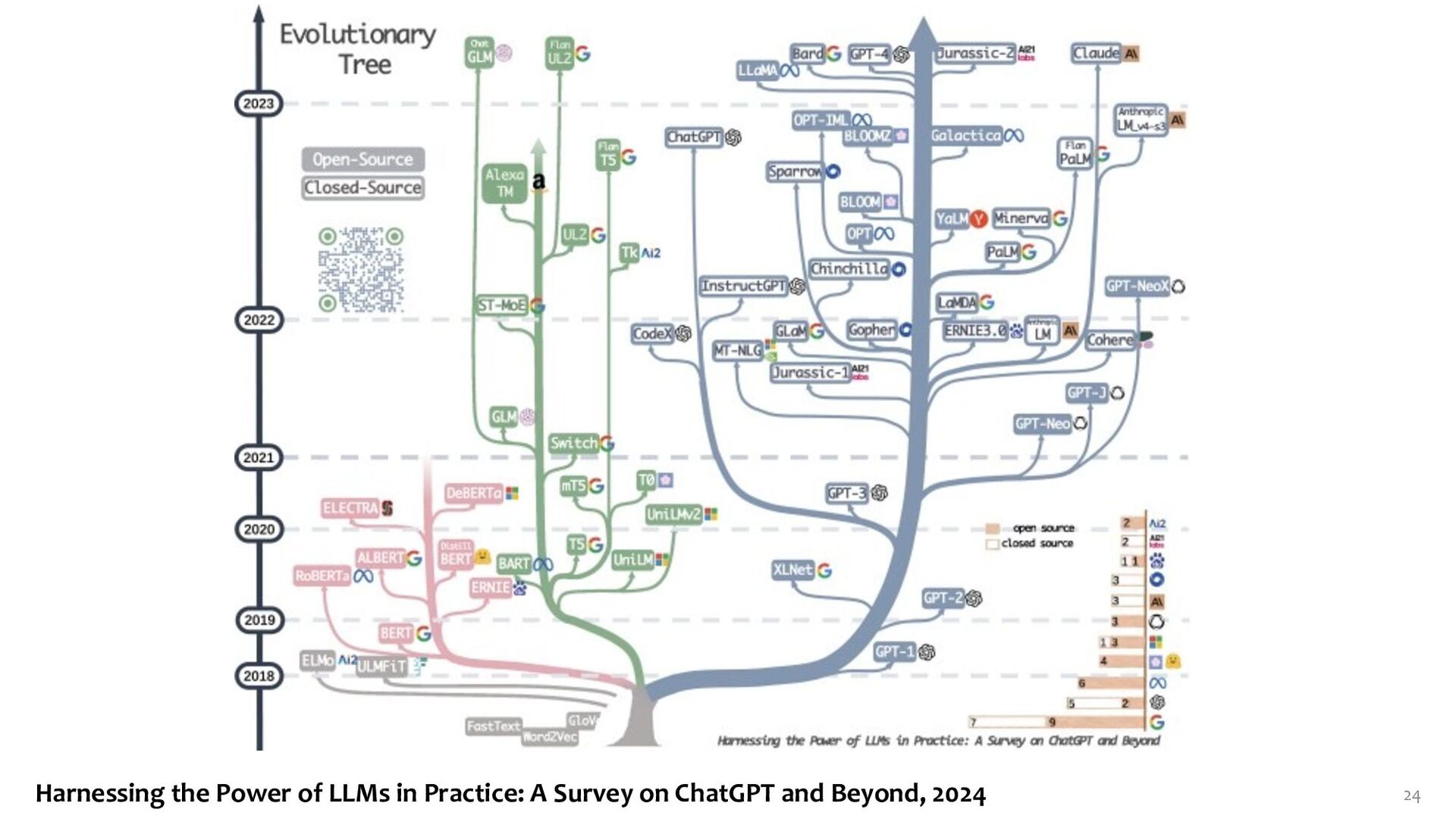{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
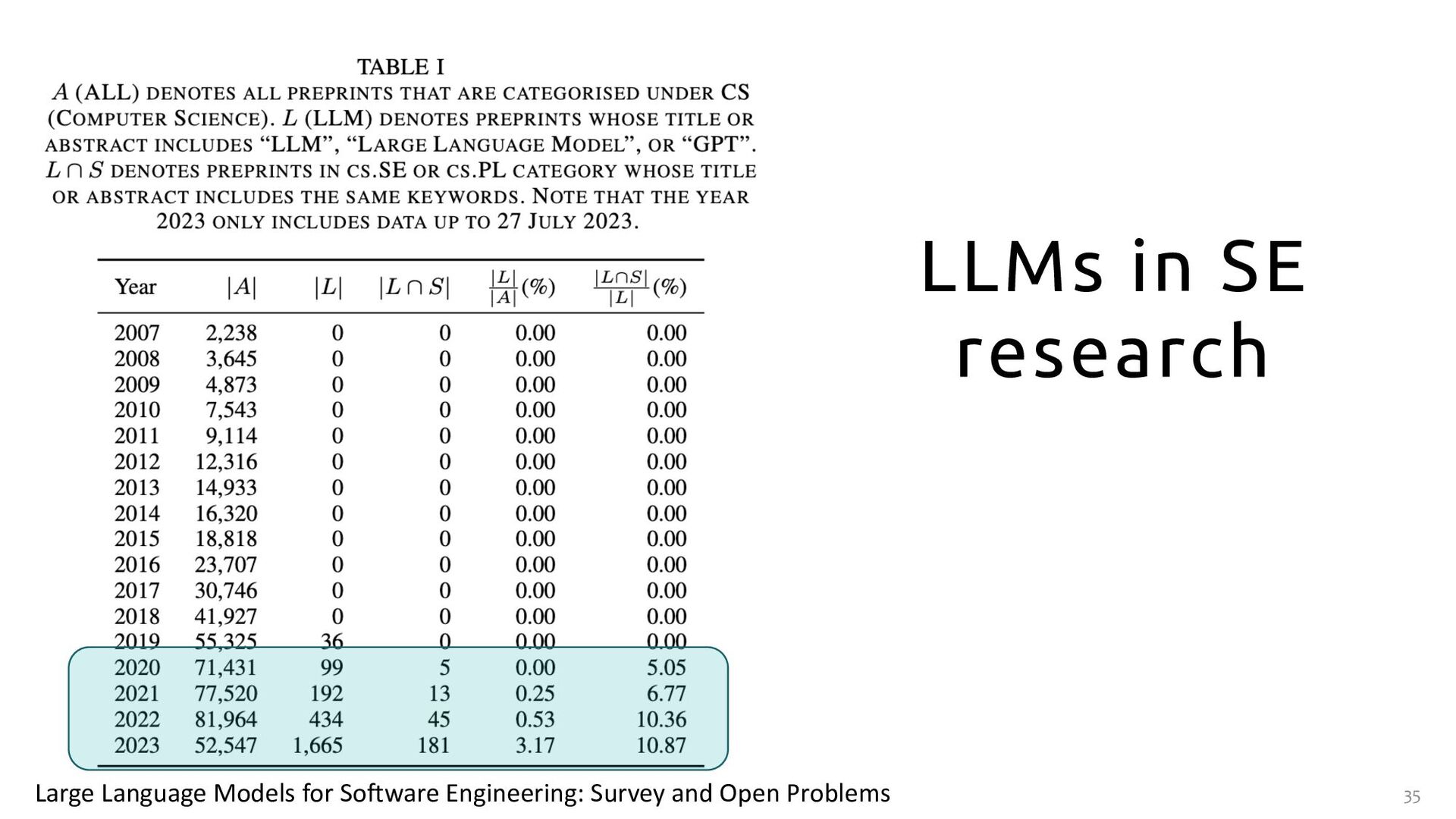{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}