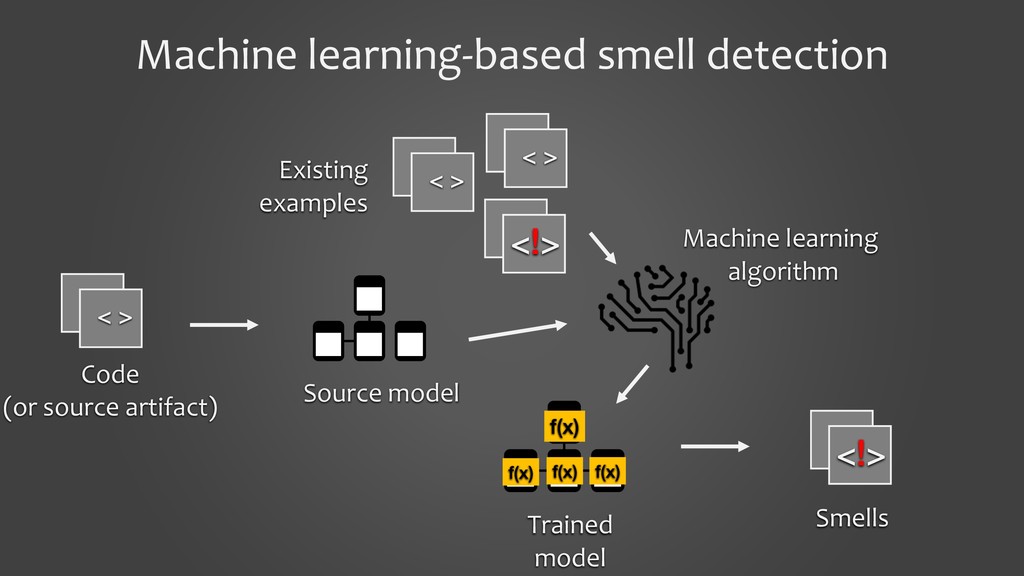
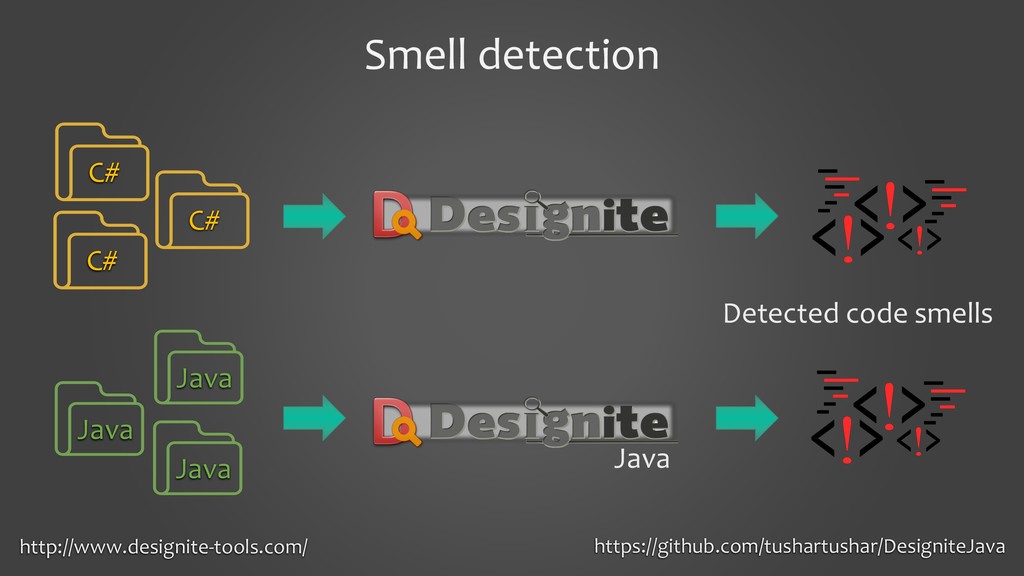
Poor quality code contributes to increasing technical debt and makes the software difficult to extend and maintain. Code smells capture such poor code quality practices. Traditionally, the software engineering community identifies code smells in deterministic ways by using metrics and pre-defined rules/heuristics. Creating a deterministic tool for a specific language is an expensive and arduous task since it requires source code analysis starting from parsing, symbol resolution, intermediate model preparation, and applying rules/heuristics/metrics on the model. It would be great if we can leverage the tools available for one programming language and cross-apply them on another language.
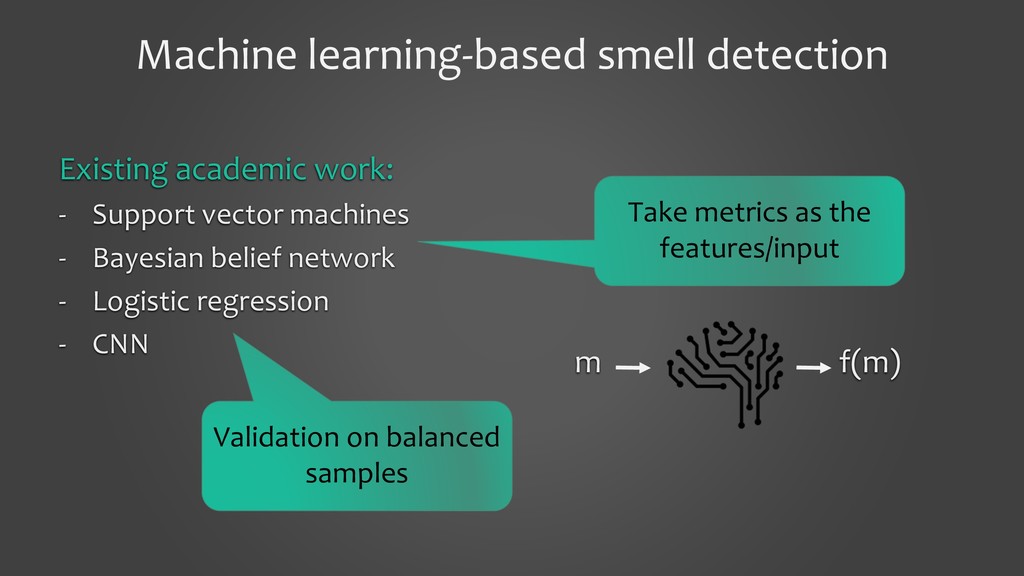
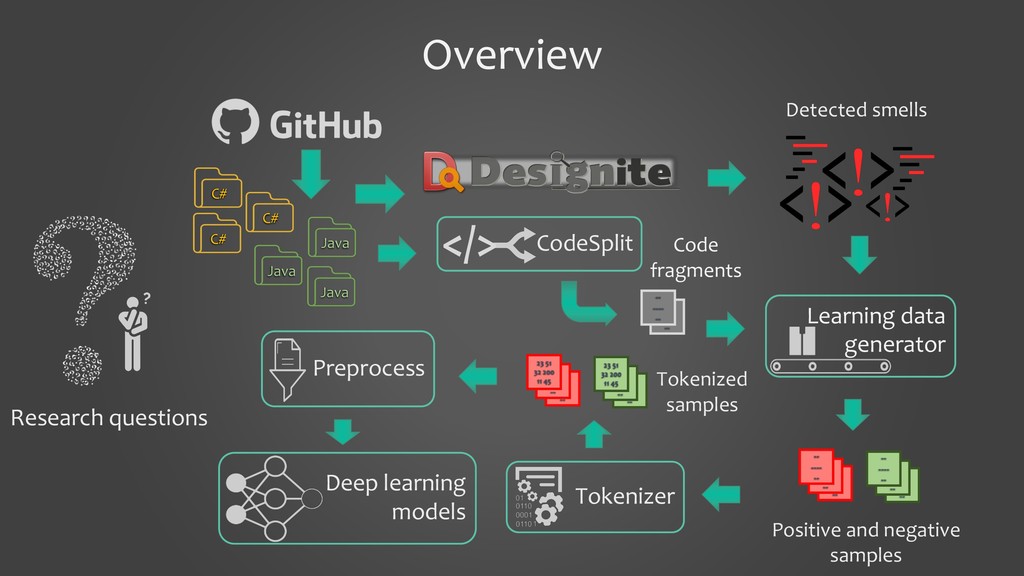
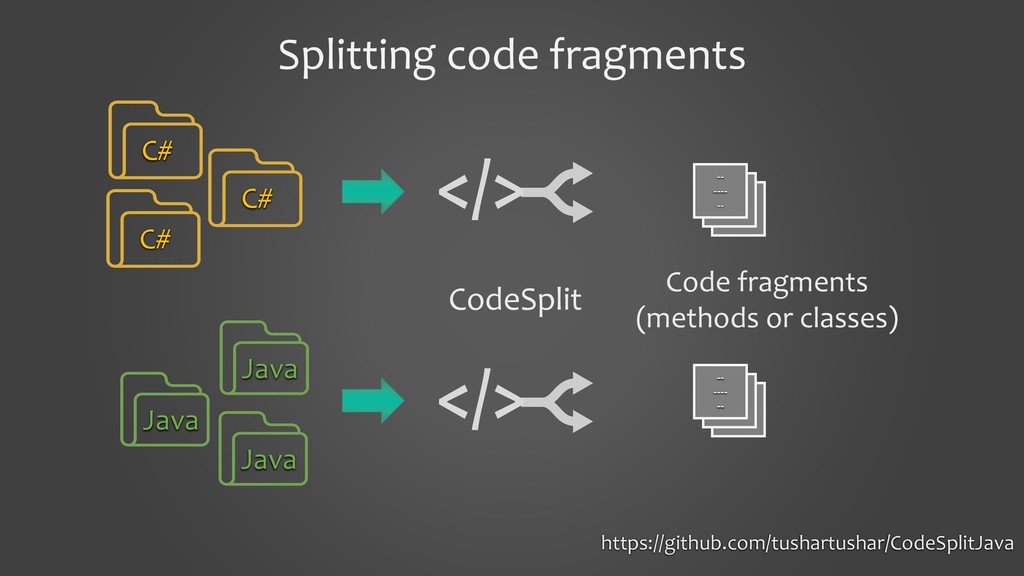
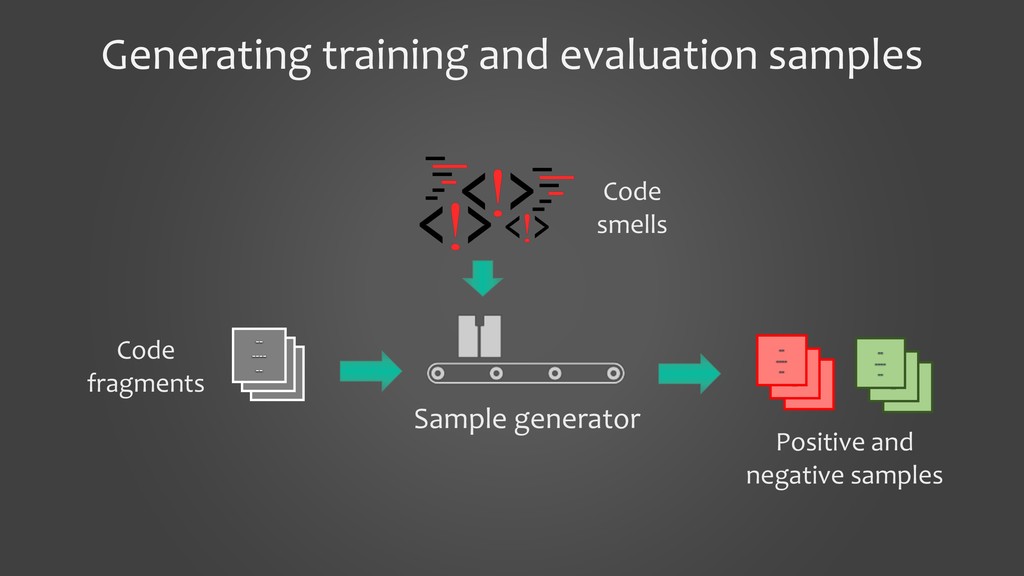
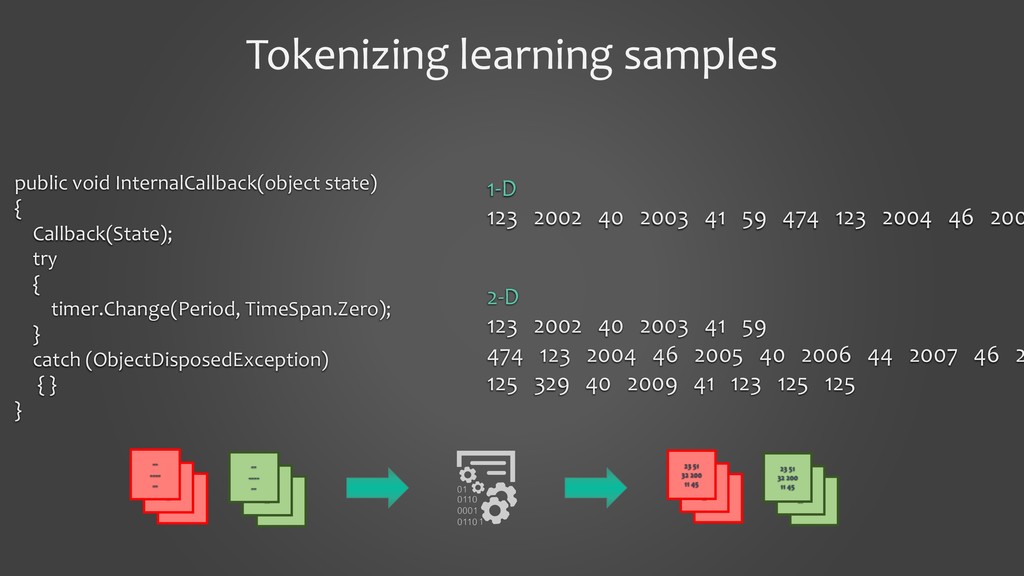
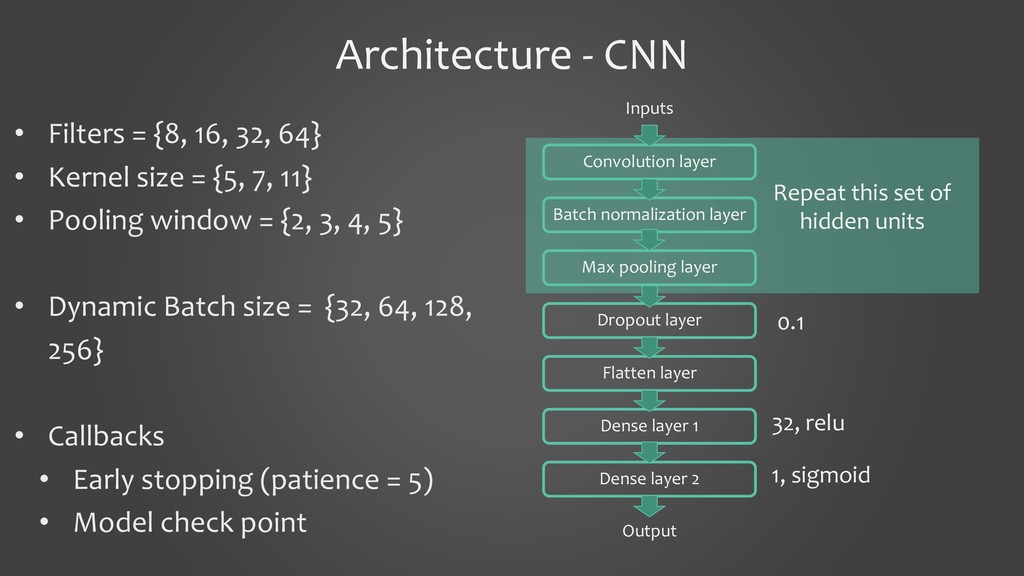
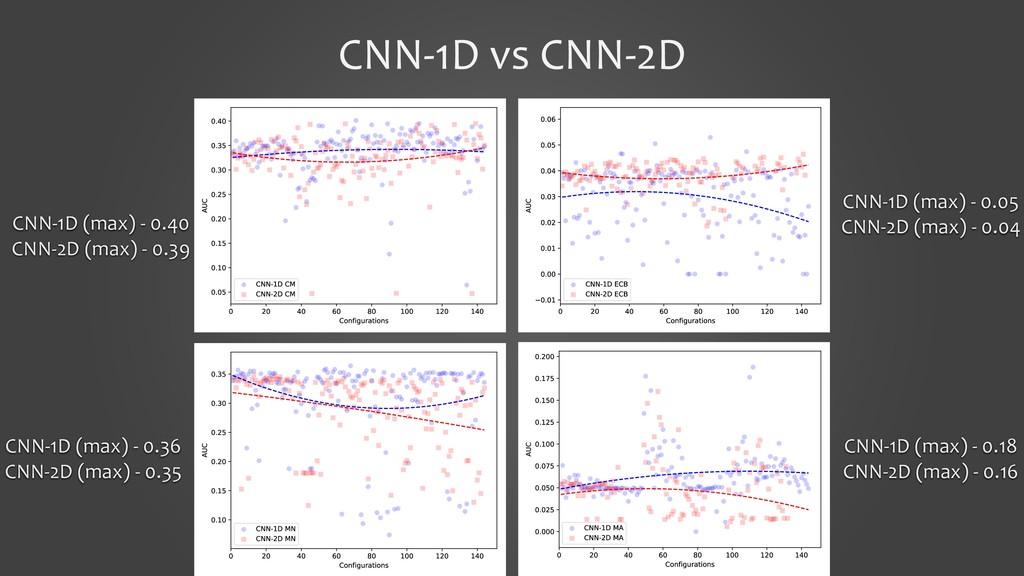
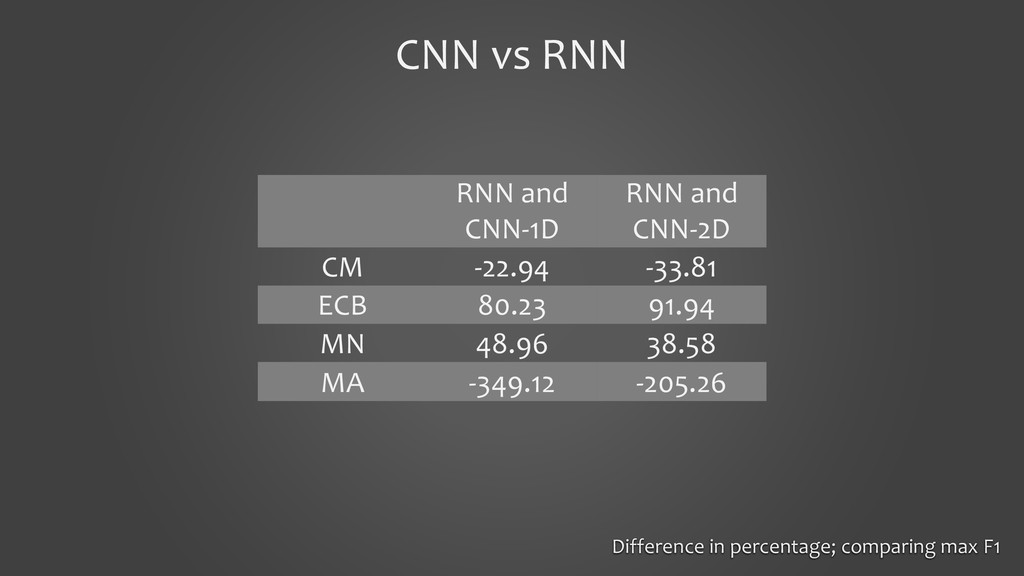
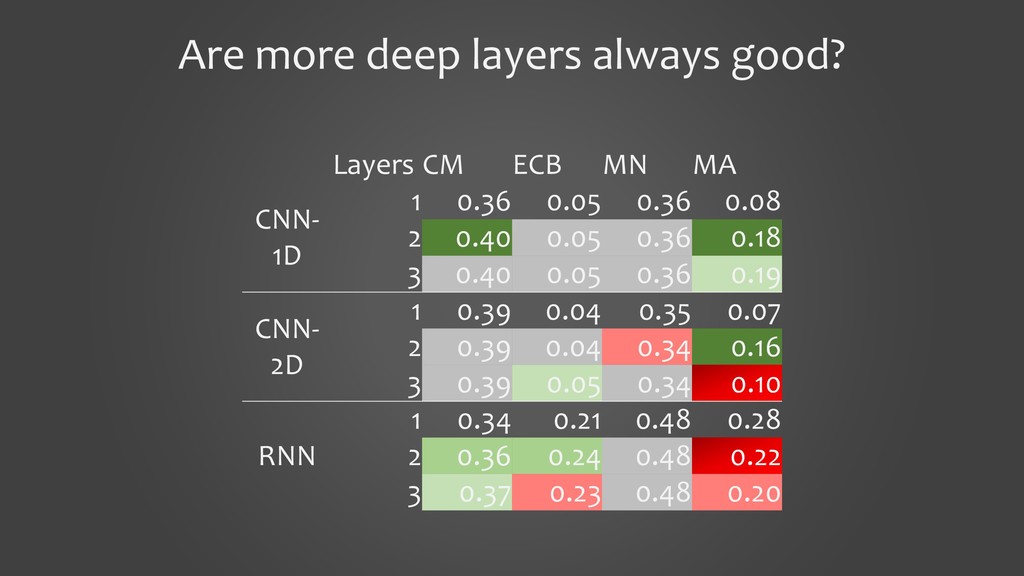
In this presentation, I would like to present our work on detecting smells using deep learning models. It will cover the tooling aspects summarizing the preparation goes behind the scene before the source code is fed into a deep learning model. The focus of the work is on two specific aspects: 1. to show that we can detect code smells with minimal pre-processing without converting them to a feature set. We compare the performance of smell detection among different deep learning models (CNN and RNN) in different configurations (i.e., model architectures). 2. to explore the feasibility of applying deep learning models across the programming languages. In other words, learning smell detection from samples in one programming language and using the model to detect smells in samples of another programming language. The presentation will bring out insights from this exploration.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}