was removed from the Linux kernel in 2018. An out-of-tree kernel module still exists and is being maintained . However the module does not appear to support network namespaces and therefore containers. Can we bring back IPX support… … without writing a kernel module? … just using eBPF and user space code? … with container support? … by abusing the existing kernel IPv6 stack? … and will it be funny? 1. https://github.com/pasis/ipx ↩︎ [1]
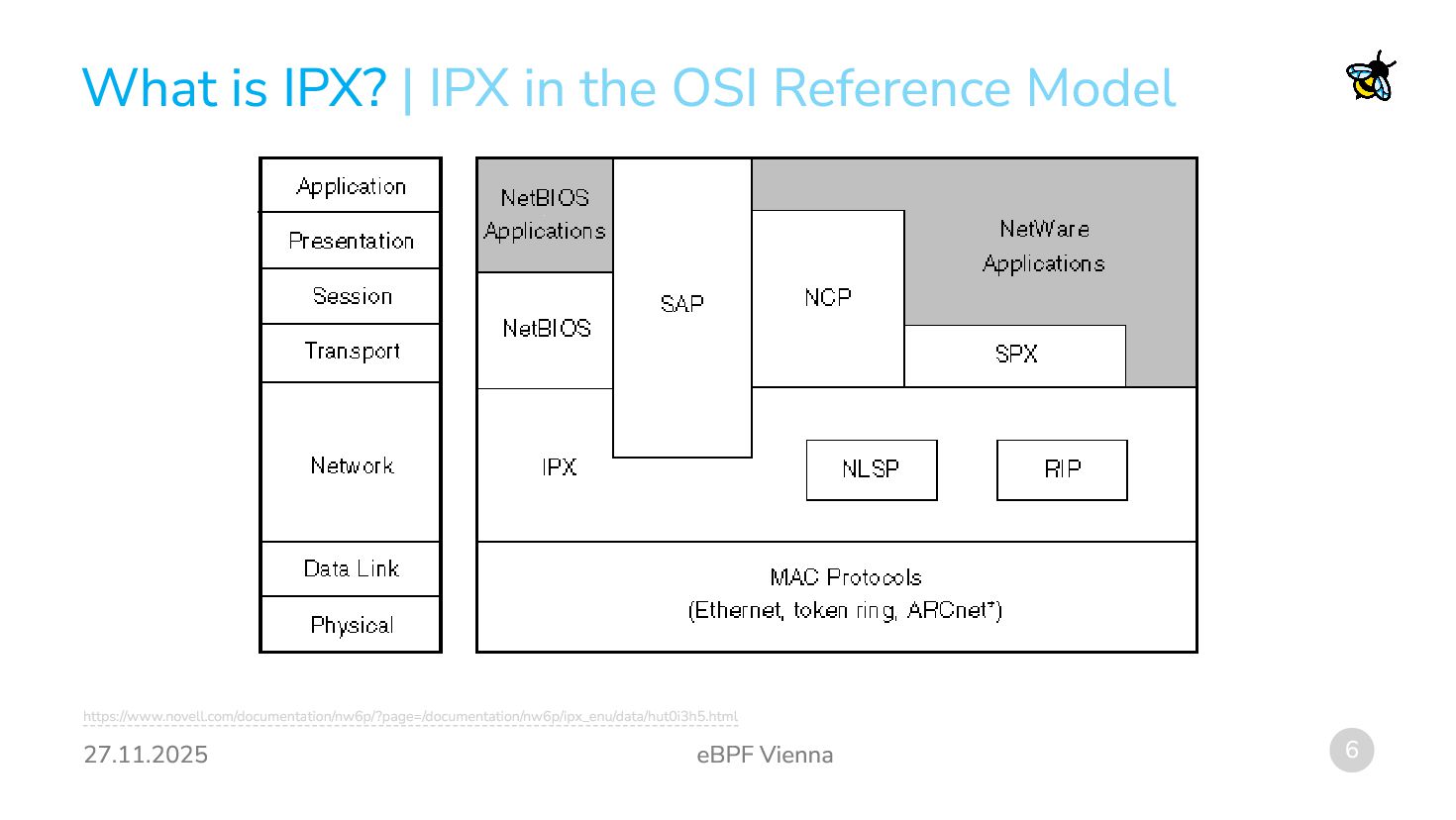
(IPX) is a network-layer protocol. It is part of the IPX/SPX suite of network protocols. Used by Novell NetWare. Popular in the late 1980ies and early 1990ies. (Almost) nobody uses it anymore. | Overview
is 12 bytes long. Network: The 4-byte network number identifies the network segment. Node: The 6-byte node number identifies a node on the network segment. Socket: The 2-byte socket number identifies a process on the node. (I.e. it has a similar function to TCP or UDP port numbers). Example: deadbeef . baadcafed00d . face . Neighbor Discovery: When Ethernet is used the node number is equal to the MAC address of the network interface. This means that no neighbor discovery mechanism is required to resolve an IPX address to a MAC address! | Addressing https://www.novell.com/documentation/nw6p/?page=/documentation/nw6p/ipx_enu/data/hvvqznoa.html#hvvqznoa
is 30 bytes long. Checksum: unused ( 0xFFFF ). Transport Control: The number of routers a packet has traversed on the way to its destination. Once it reaches 16 the packet is discarded. Packet Length: Length, in bytes, of the complete packet, which is the length of the IPX header plus the length of the data. Packet Type: Type of service offered or required by the packet. 1 2 3 4 Checksum Packet Length Transport Ctrl. Packet Type Destination Network Destination Network Destination Node Destination Socket Source Network Source Network Source Node Source Socket Data ... | Header Format https://www.novell.com/documentation/nw6p/?page=/documentation/nw6p/ipx_enu/data/hc1w6pvi.html#hc1w6pvi
bytes long. Split into a network and a host part. A prefix length can be used to specify the length of the network part. Example: fdaa:bbbb:dead:beef:baad:caff:fefe:d00d : With the prefix length /64 the network part is fdaa:bbbb:dead:beef and the host part is baad:caff:fefe:d00d . Neighbor Discovery: A neighbor discovery protocol exists to resolve an IPv6 address to a MAC address when using Ethernet. | Addressing
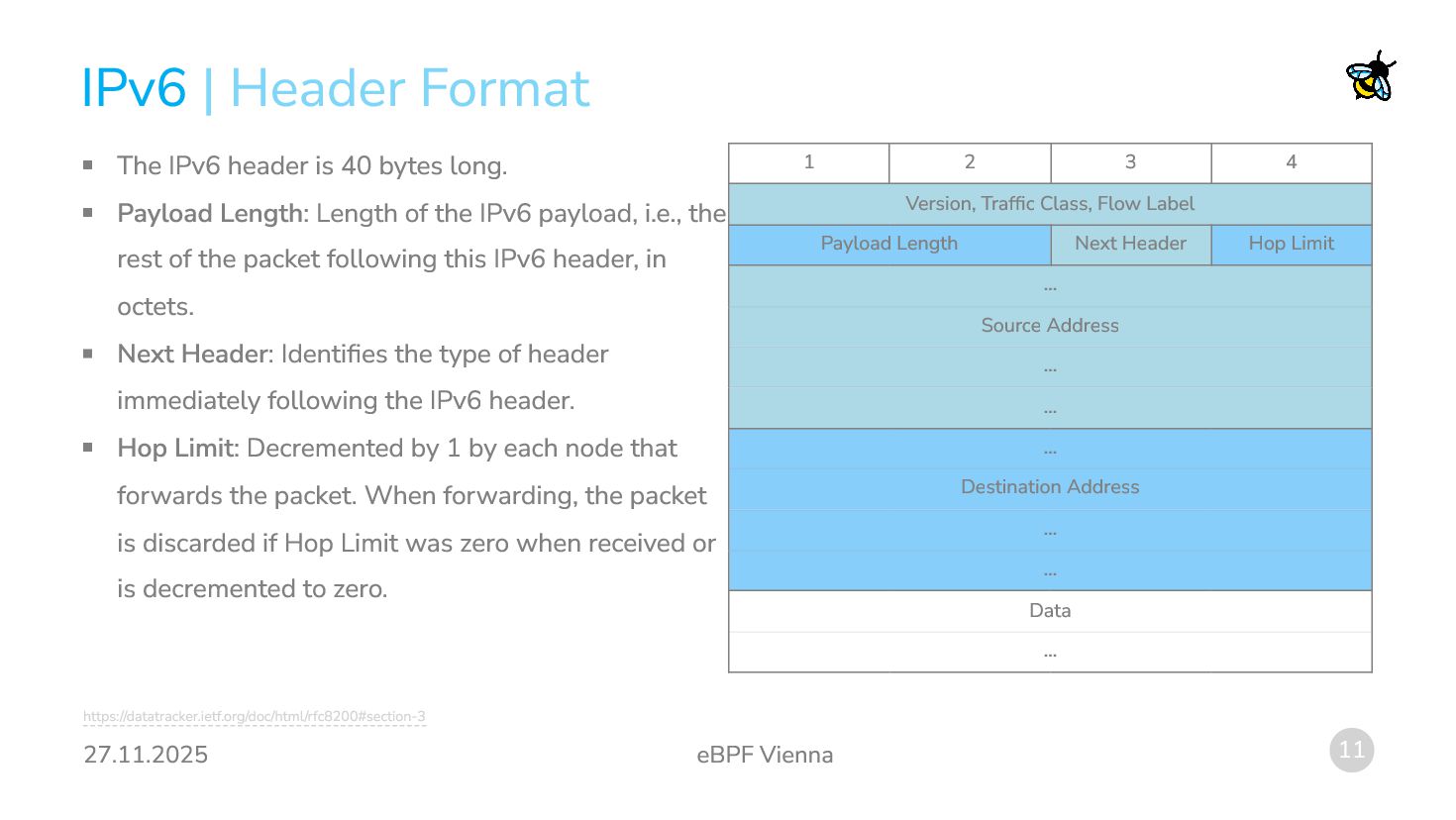
bytes long. Payload Length: Length of the IPv6 payload, i.e., the rest of the packet following this IPv6 header, in octets. Next Header: Identifies the type of header immediately following the IPv6 header. Hop Limit: Decremented by 1 by each node that forwards the packet. When forwarding, the packet is discarded if Hop Limit was zero when received or is decremented to zero. 1 2 3 4 Version, Traffic Class, Flow Label Payload Length Next Header Hop Limit ... Source Address ... ... ... Destination Address ... ... Data ... | Header Format https://datatracker.ietf.org/doc/html/rfc8200#section-3
support for IPX back without using the out-of-tree driver: 1. Trick the Kernel into believing it is handling IPv6 packets. 2. Rewrite outgoing IPv6 packets into IPX packets. 3. Rewrite incoming IPX packets into IPv6 packets. 4. Benefit from existing IPv6 infrastructure such as addressing, routing, sockets etc. | Map IPX to IPv6
are IPv6 addresses consisting of: An arbitrarily chosen 32-bit prefix. This prefix indicates that this is really an IPX address. The 32-bit IPX network. The 48-bit node number in EUI-64 format. The IPX node address deadbeef . baadcafed00d becomes fdaa:bbbb : dead:beef : baad:ca ff:fe fe:d00d . When configuring an interface, the prefix length for virtual IPv6 addresses is /64 . This way the network is identified by the arbitrary prefix and the IPX network. The IPX socket number depends on the service in use and will have to be handled separately. | Map IPX’s Node Address Space into IPv6’s
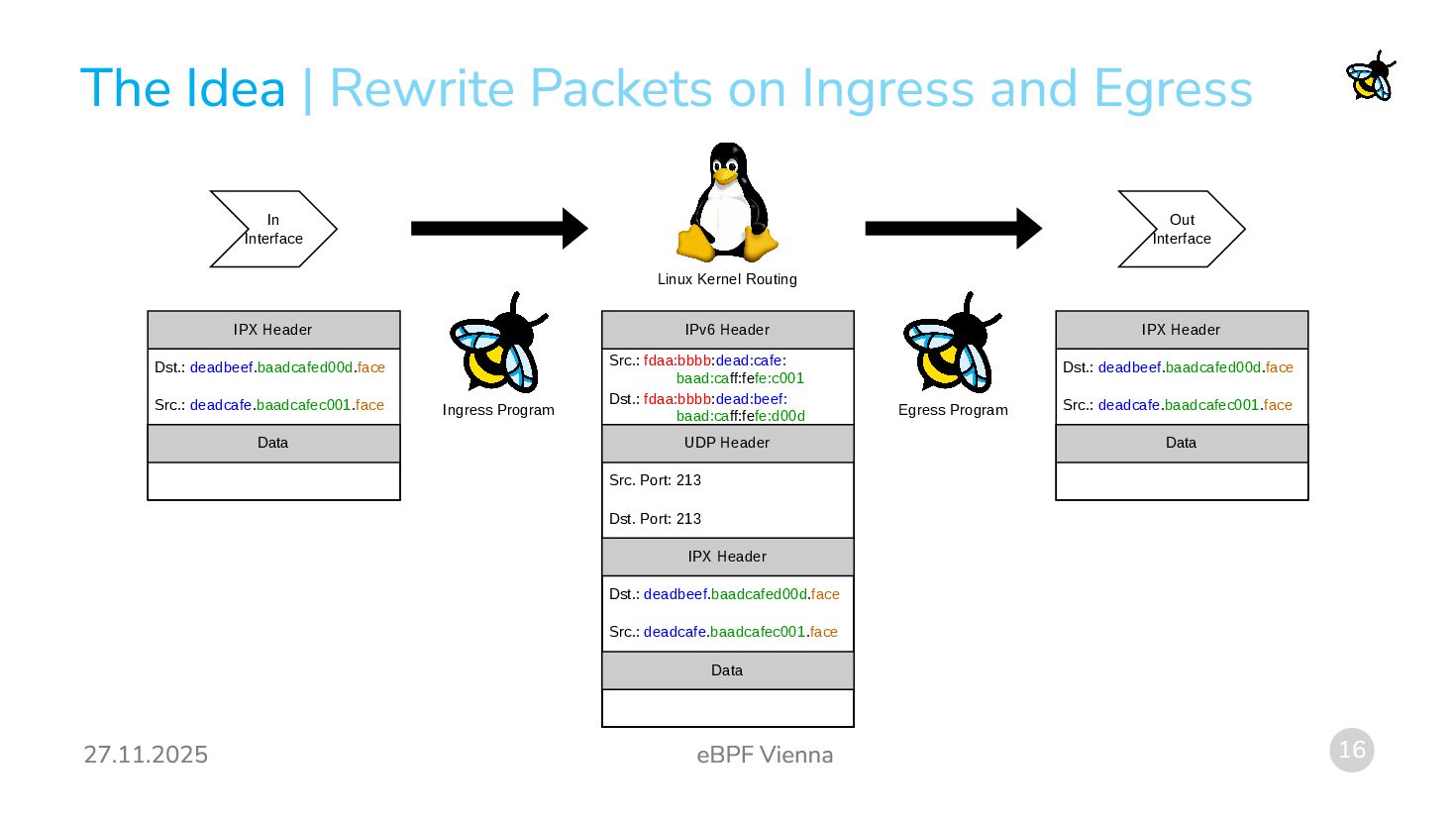
program type to rewrite packets between IPX and IPv6. Incoming IPX packets are wrapped in an IPv6-UDP packet: The entire IPX packet is wrapped. The IPv6 header is populated with the "virtual" IPX addresses derived from source and destination address in the IPX header. The Hop Limit field of the IPv6 header is calculated from the Transport Control field of the IPX header. Outgoing IPX packets are simply unwrapped by discarding the IPv6 and UDP headers. | Rewrite Packets on Ingress and Egress
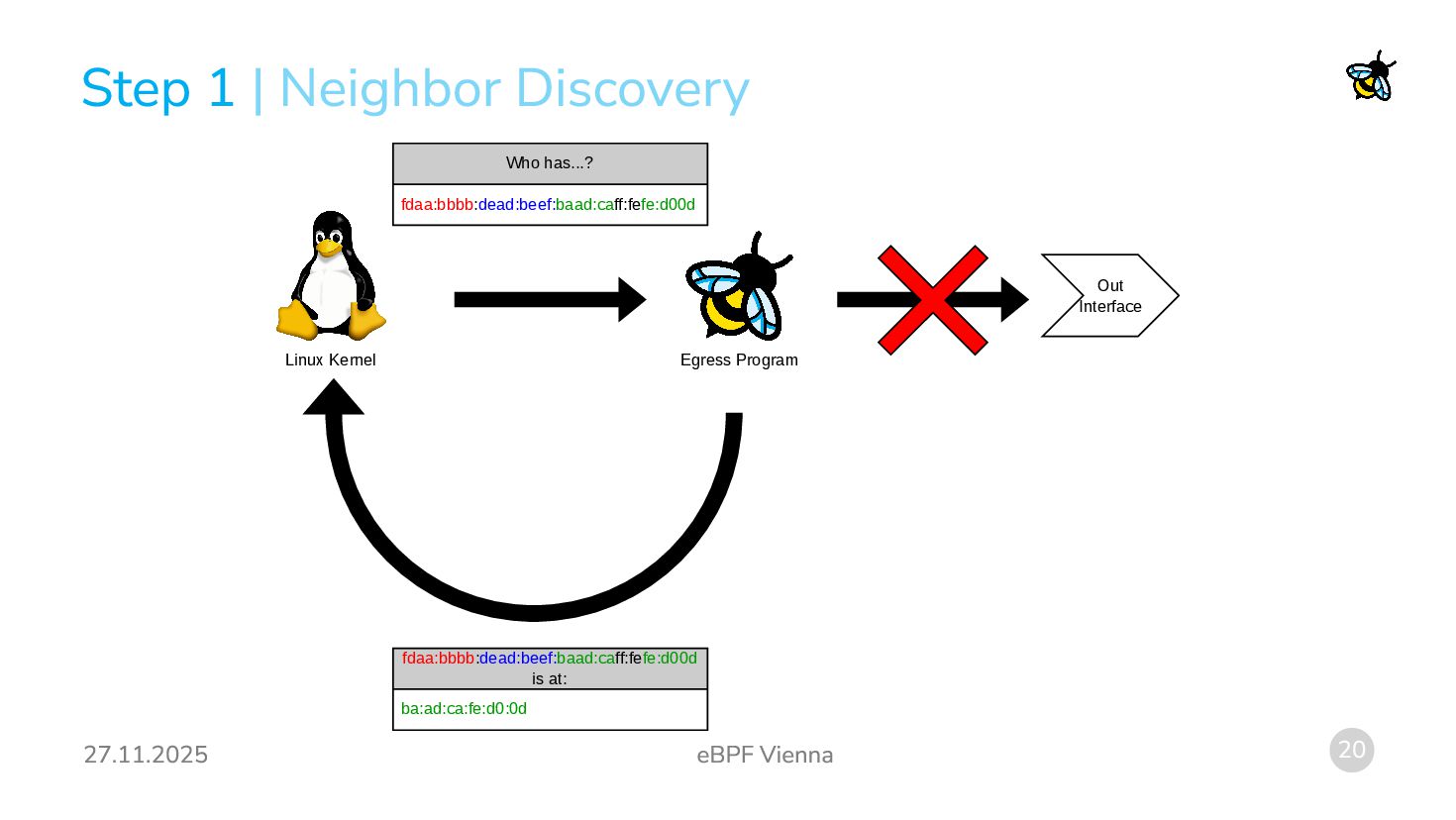
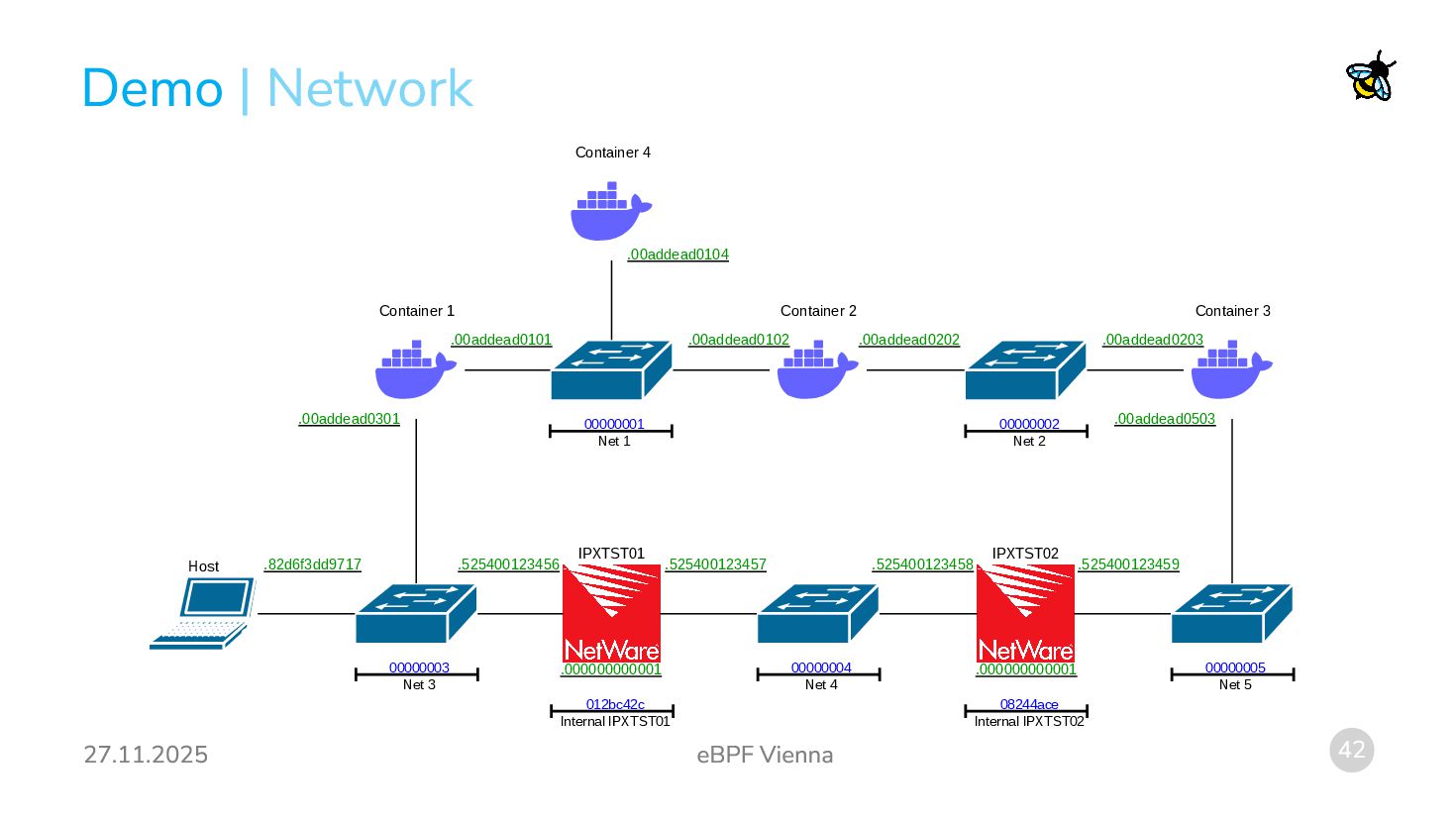
almost sufficient to trick the kernel into routing IPX. Interface Config: Configure Interfaces with virtual IPX addresses: Routing Table: Fill the routing table with routes to IPX networks: The Missing Part: Neighbor discovery! Without further steps the kernel will try to resolve virtual IPX addresses to a MAC address using the IPv6 Neighbor Discovery Protocol (NDP). This is not necessary, since the virtual IPX address already contains the MAC address! | Routing ip addr add fdaa:bbbb:dead:beef:baad:caff:fefe:d00d/64 dev eth0 ip route add fdaa:bbbb:dead:cafe::/64 via fdaa:bbbb:dead:beef:baad:caff:fefe:d00d
MAC address of Machine B is unknown to Machine A. 2. Machine A broadcasts a Neighbor Solicitation packet to the network. 3. Machine B responds with a Neighbor Advertisement containing its own MAC address. 4. Machine A inserts the MAC address for Machine B into the neighbor table. But the MAC address is already contained in the virtual IPX address! Idea: Rewrite a Neighbor Solicitation to an appropriate Neighbor Advertisement in eBPF, then redirect it to the ingress of the interface it would have exited. | Neighbor Discovery
the IPX packet to IPv6 on ingress the kernel discards it: In SCHED_CLS the kernel is opinionated about what kind of packet it received. It does not believe the packet is IPv6. Solution: Mark the rewritten packet and then use bpf_redirect to redirect it into the same interface. This will cause the kernel to receive the rewritten packet again. The second time it believes that the packet is an IPv6 packet. 2. Problem: IPX messages with a payload shorter than 10 bytes are discarded on egress: The kernel still believes it is sending an IPv6 packet. Hence, it will not allow packets shorter than the IPv6 header (40 bytes). The IPX header is shorter than the IPv6 header (30 bytes). Solution: The kernel offers bpf_skb_change_proto which allows changing the network-protocol from IPv6 to IPv4. The IPv4 header is at least 20 bytes long. Therefore, after changing the protocol to IPv4 the short IPX packet can be sent. | Pitfalls
have to be calculated. Since we are using UDP in IPv6, the UDP checksum is mandatory. Solution: Calculate the UDP checksum for every incoming IPX packet. 4. Problem: Sometimes the calculated UDP checksum is zero. In IPv6 the UDP checksum is mandatory. A checksum of zero however means that the checksum calculation was skipped. The bpf helper to replace the checksum ( bpf_l4_csum_replace ) does not check if the calculated checksum equals zero! This results in those packets where the checksum calculation yields zero to be dropped! Solution: Manually check if the calculated checksum equals zero. Set it to 0xFFFF if it does. | Pitfalls
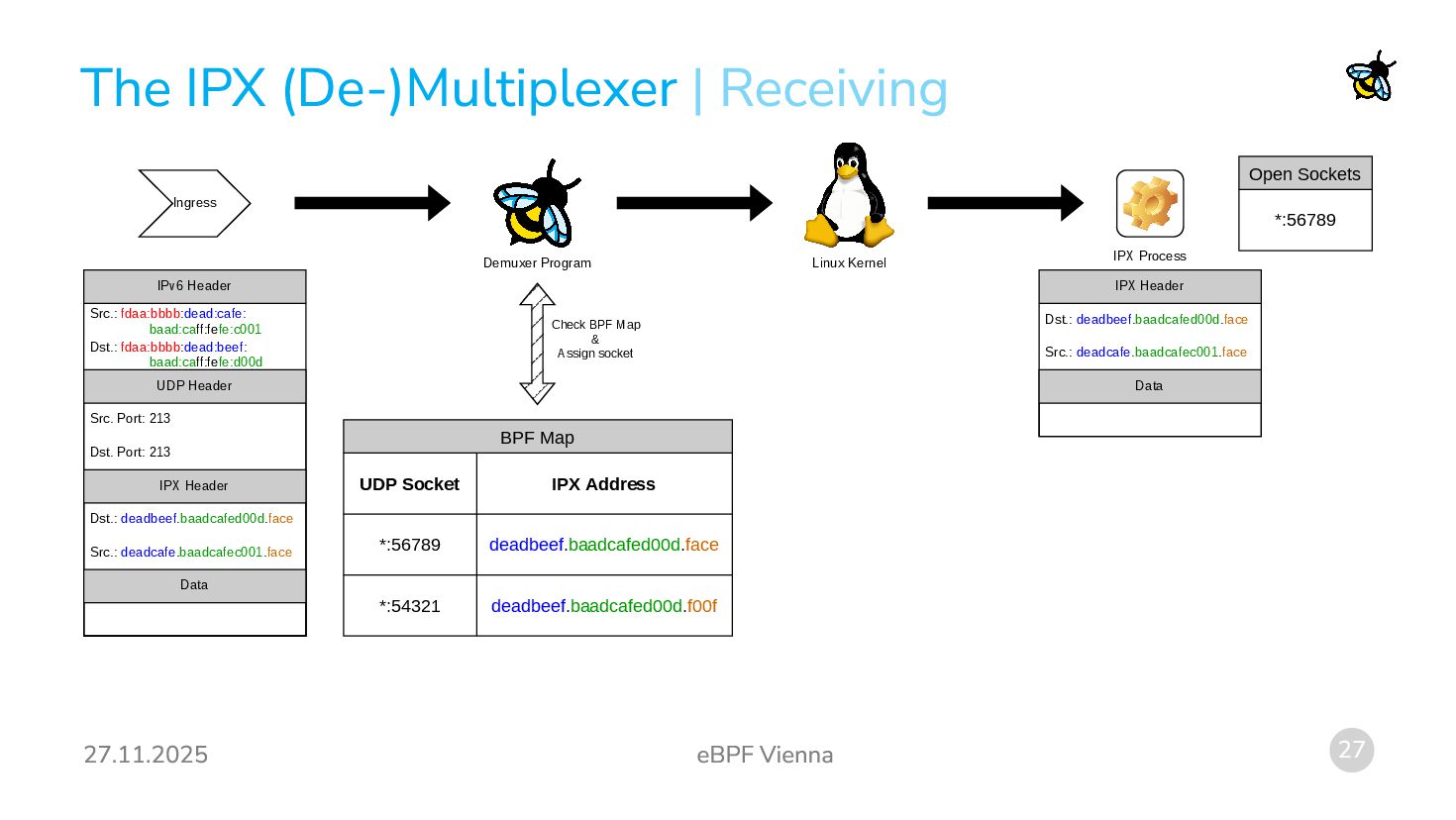
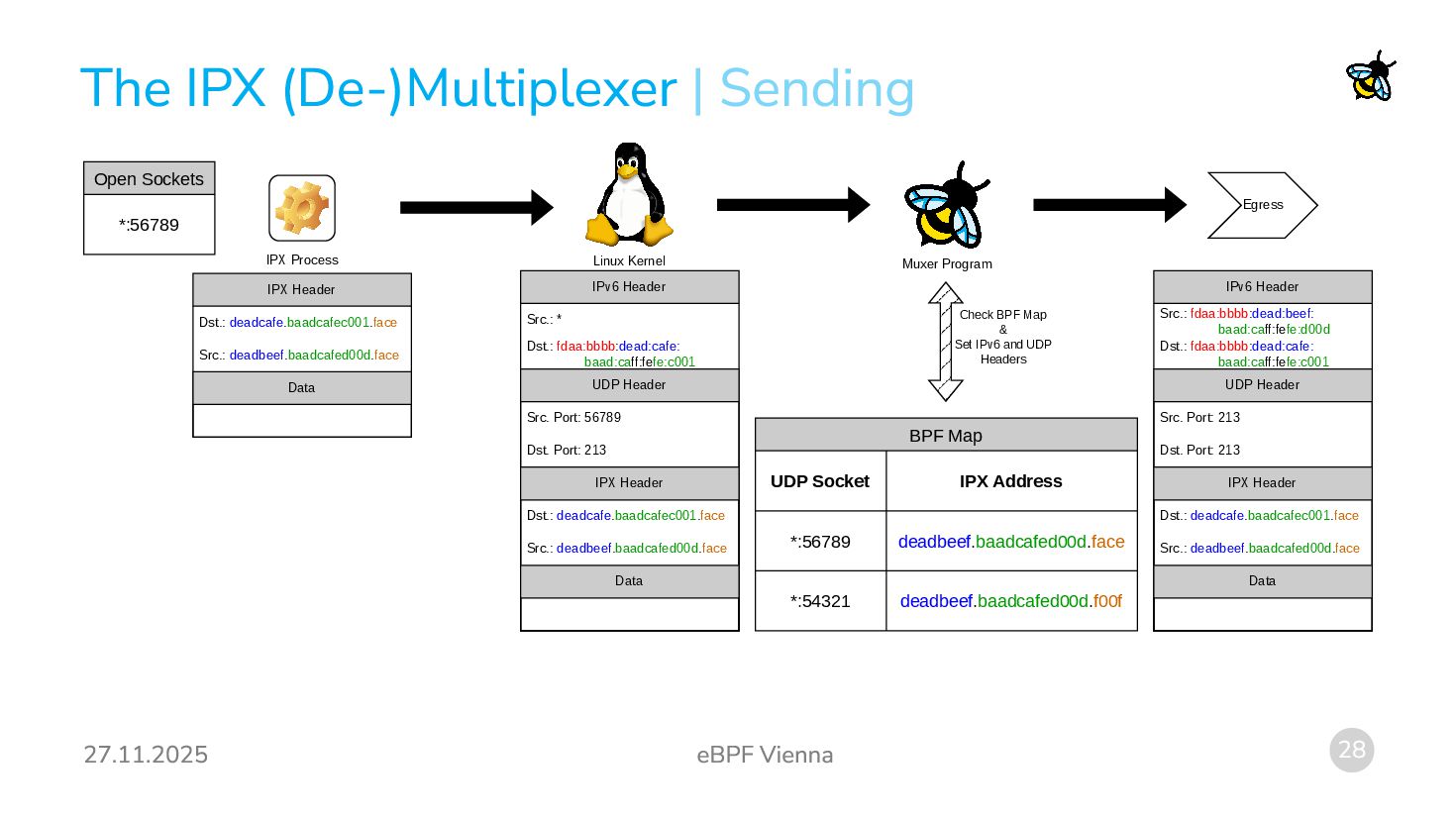
packets are already UDP packets! Terminating IPX Traffic: We can use eBPF to read the actual IPX destination socket and assign the packets to real UDP sockets! Observation 2: Outgoing UDP packets with special source and destination ports are already unwrapped to IPX packets. Originating IPX Traffic: We can use eBPF to rewrite packet contents coming from certain UDP sockets into IPX packets! We will need a way to assign IPX addresses to UDP sockets and to mark special UDP sockets as sockets that really are IPX sockets. | Originating and Terminating IPX Traffic
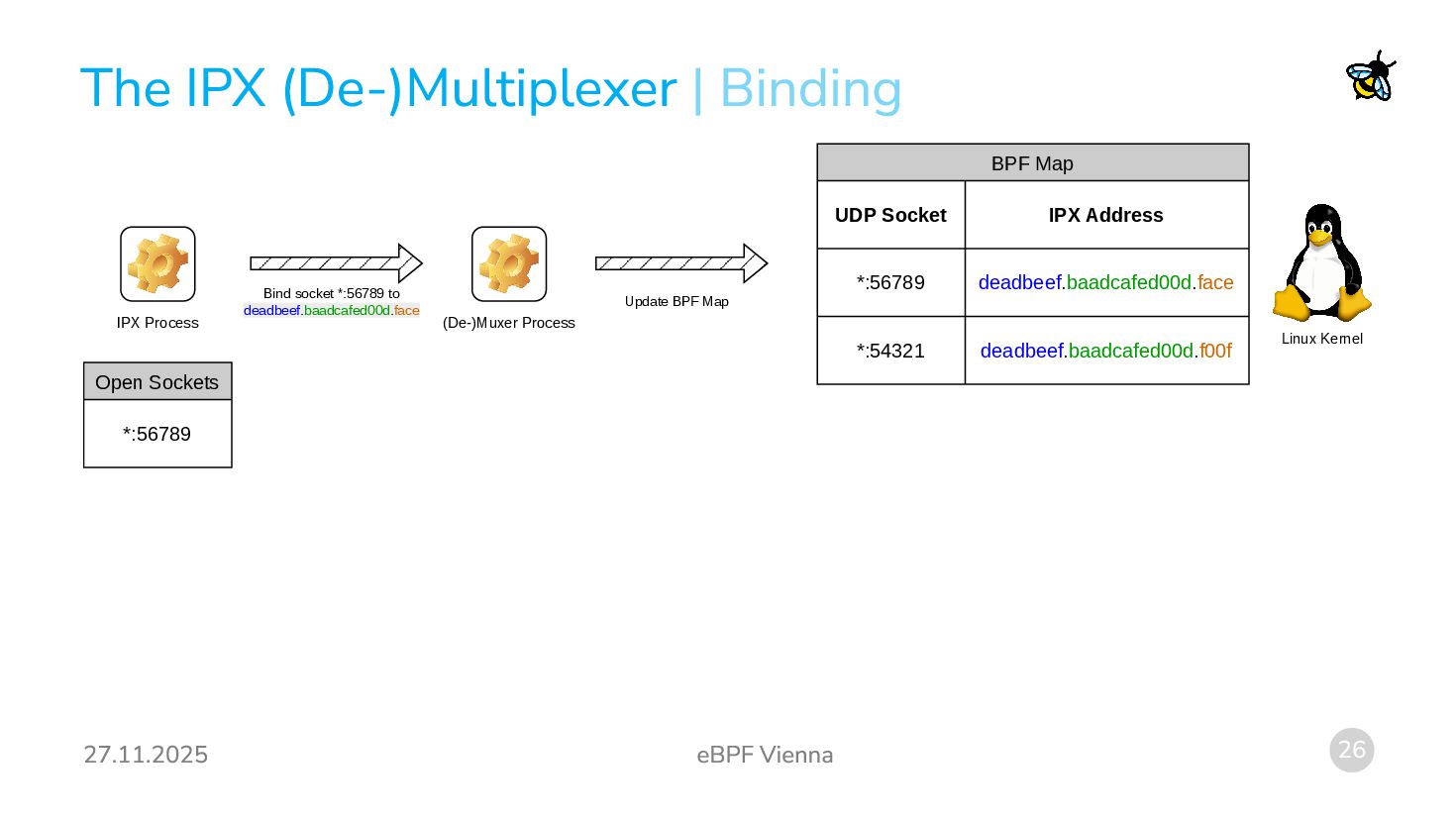
both source and destination port 213 are really wrapped IPX packets. Demultiplexing: We need to receive such packets and distribute them to the processes actually wanting to receive packets for certain IPX socket numbers. Multiplexing: We have multiple processes that each want to send on their own IPX socket. We need to turn the packets they generate into UDP packets with the source and destination port 213 and an IPX header inside the UDP packet. Idea: We create a (de-)multiplexer process: Processes can register their UDP sockets to an IPX address. (Similar to the bind system call.) The (de-)multiplexer process performs some checks (is the IPX socket number already in use etc.) and then updates a BPF-map with the UDP-socket-to-IPX-address-binding. Two eBPF programs (one for ingress and one for egress) perform the actual rewriting and socket steering.
a packet to a socket we need to be sure that the packet is actually intended for the local machine. We do not know all the possible interface addresses in the eBPF program. Solution: Perform a route lookup on the packet first. If it would not be forwarded, assume it is for the local machine. Drawback: IPv6 routing needs to be enabled on all receiving interfaces. | Pitfalls
has a connection oriented protocol called SPX. SPX guarantees in-order, deduplicated delivery of packets. Uses timeouts, acknowledgement packets and retransmits similarly to TCP. SPX does not use the IPX socket numbers to identify a connection. Instead the SPX header contains a source and destination connection ID. | Sequenced Packet eXchange (SPX)
on top of the IPX implementation. An eBPF program can determine if a packet belongs to an SPX session. This way we can have separate sockets for SPX connections. However the kernel cannot handle retransmits and timeouts, since there is no way (using eBPF) to instruct the kernel to send a packet at a later time. Unfortunately the kernel also cannot handle acknowledgements since even after a packet is assigned to a socket, there is no guarantee that the packet will actually be delivered. (The receive buffer could be full etc.) Therefore, user space has to periodically call a function to maintain the connection (send retransmits and handle timeouts) and receive packets (to acknowledge them in a timely fashion). | Sequenced Packet eXchange (SPX)
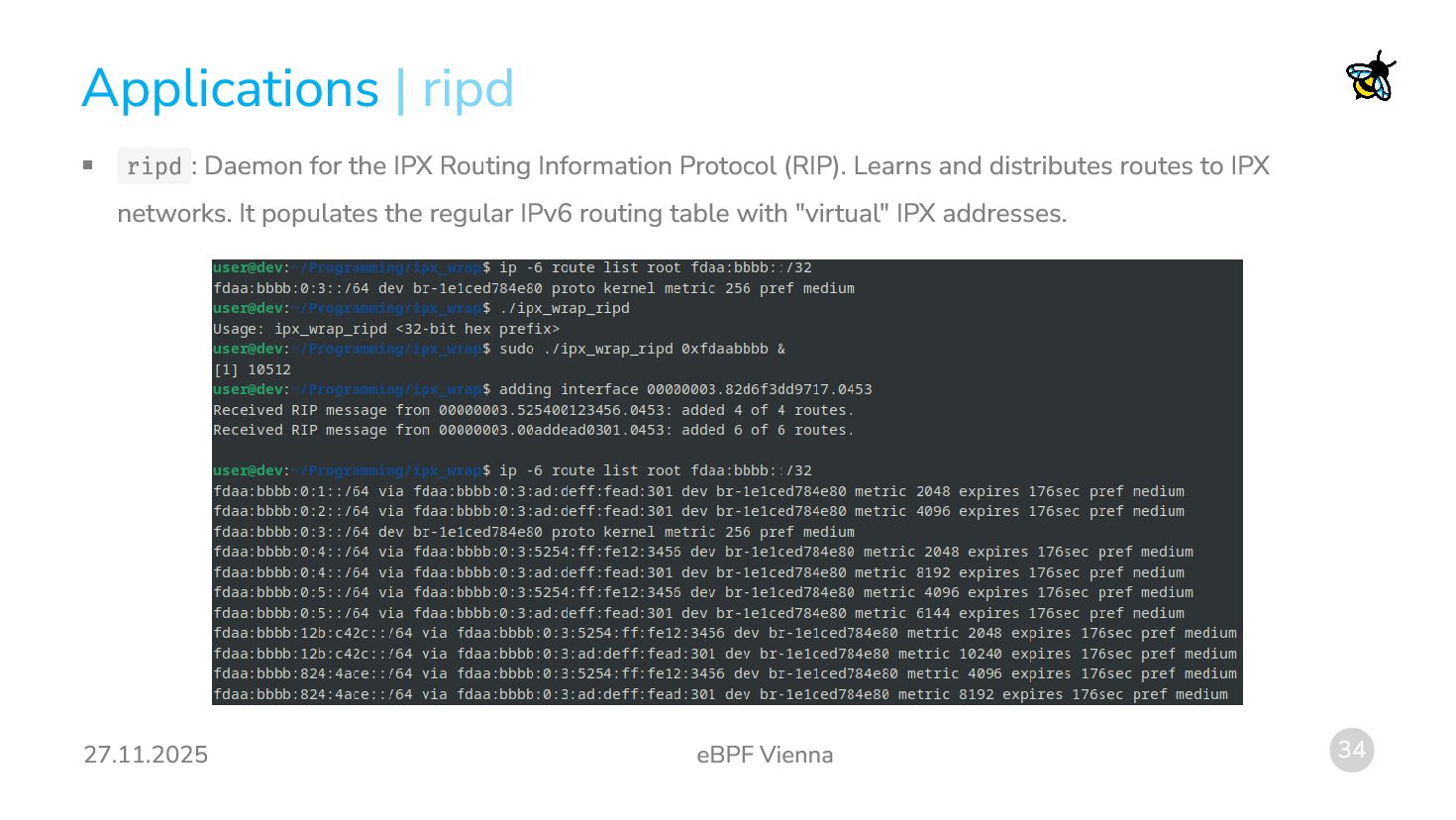
IPX Routing Information Protocol (RIP). Learns and distributes routes to IPX networks. It populates the regular IPv6 routing table with "virtual" IPX addresses. | ripd
and the surrounding protocols is rather sparse. There seems to be no equivalent to RFCs. The eBPF documentation could use some improvement: Certain corner-cases are not mentioned at all. (Ex: The UDP zero-checksum issue described before.) The applicability of certain program types and helpers is not explained. (Ex: The SK_MSG program type does not work for UDP. The SOCKHASH map type does not work for UDPLite.) The assumptions the kernel makes at certain points are explained nowhere. (Ex: Minimum length for "IPv6" packets.) In general the assumption behind the documentation seems to be that people writing eBPF code are also kernel developers. More often than not I had to check the kernel source code to figure out why something did not work as expected.
and using IPX sockets via the Socket API. Mark Sockets for IPX in Tracepoints: This would require the ability to resolve a file-descriptor to a socket structure and to access SK_STORAGE maps in tracepoints. Attach Ancillary Data to Packet Data: This requires either changing the packet data in a tracepoint for sendto , or some other mechanism to identify a packet and associate ancillary data with it. Problem with Tracepoints: TOC-TOU. Alternative to Tracepoints: A SOCK_OPS program type but for UDP? Different Approach to Socket-marking: Keep track of IPX sockets only by their source IPv6 address and UDP port and encode ancillary data in the destination address and port? Could lead to problems with SO_REUSEPORT and similar features.
require additional eBPF capabilities. Timeouts and Retransmits: This would require the ability to transmit a packet at some point in the future (and the ability to cancel the transmission). Acknowledgements: This requires a point in the kernel at which the packet is guaranteed to be delivered to userspace at which an acknowledgement packet can also be sent.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
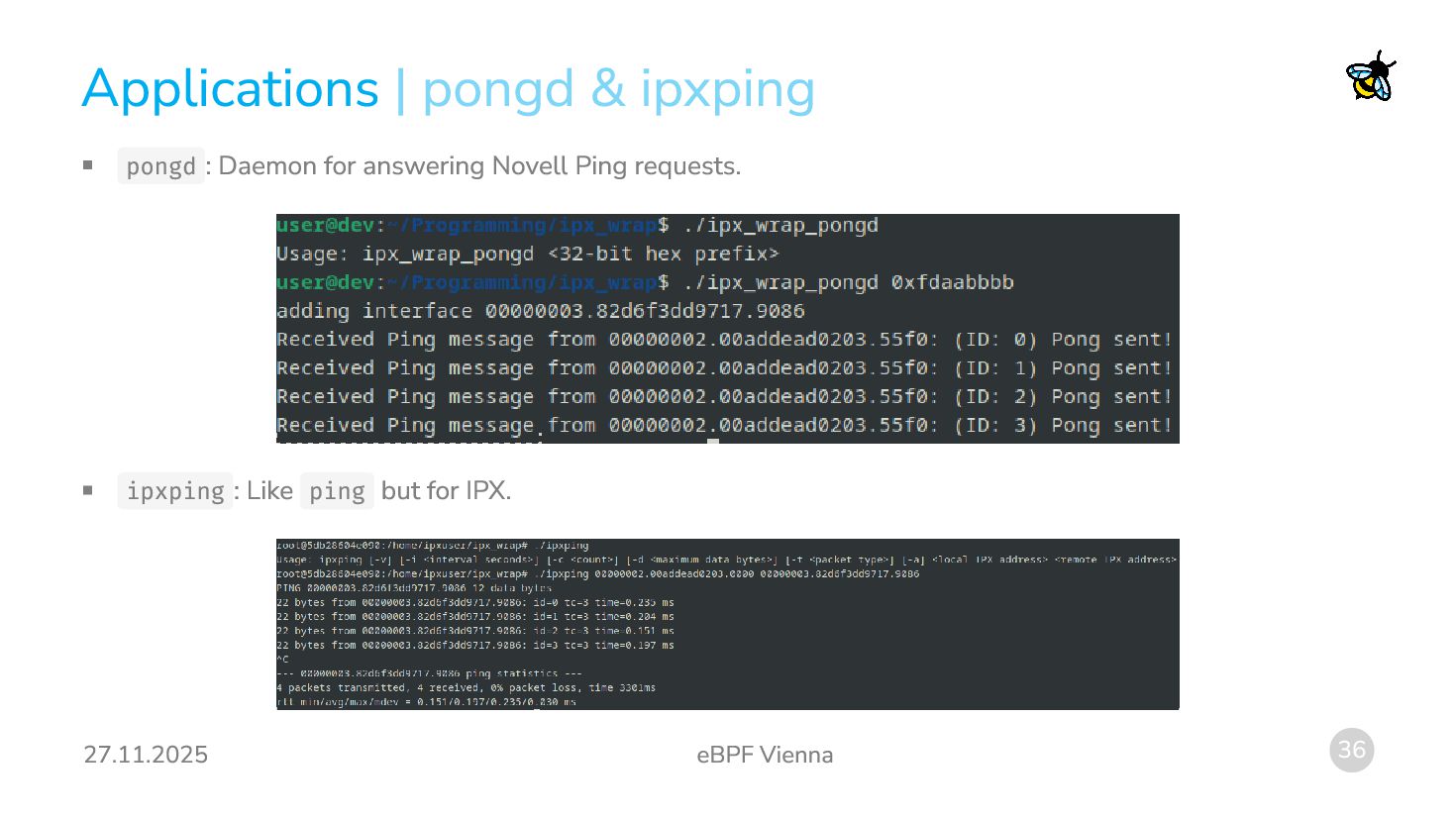{kind=link}
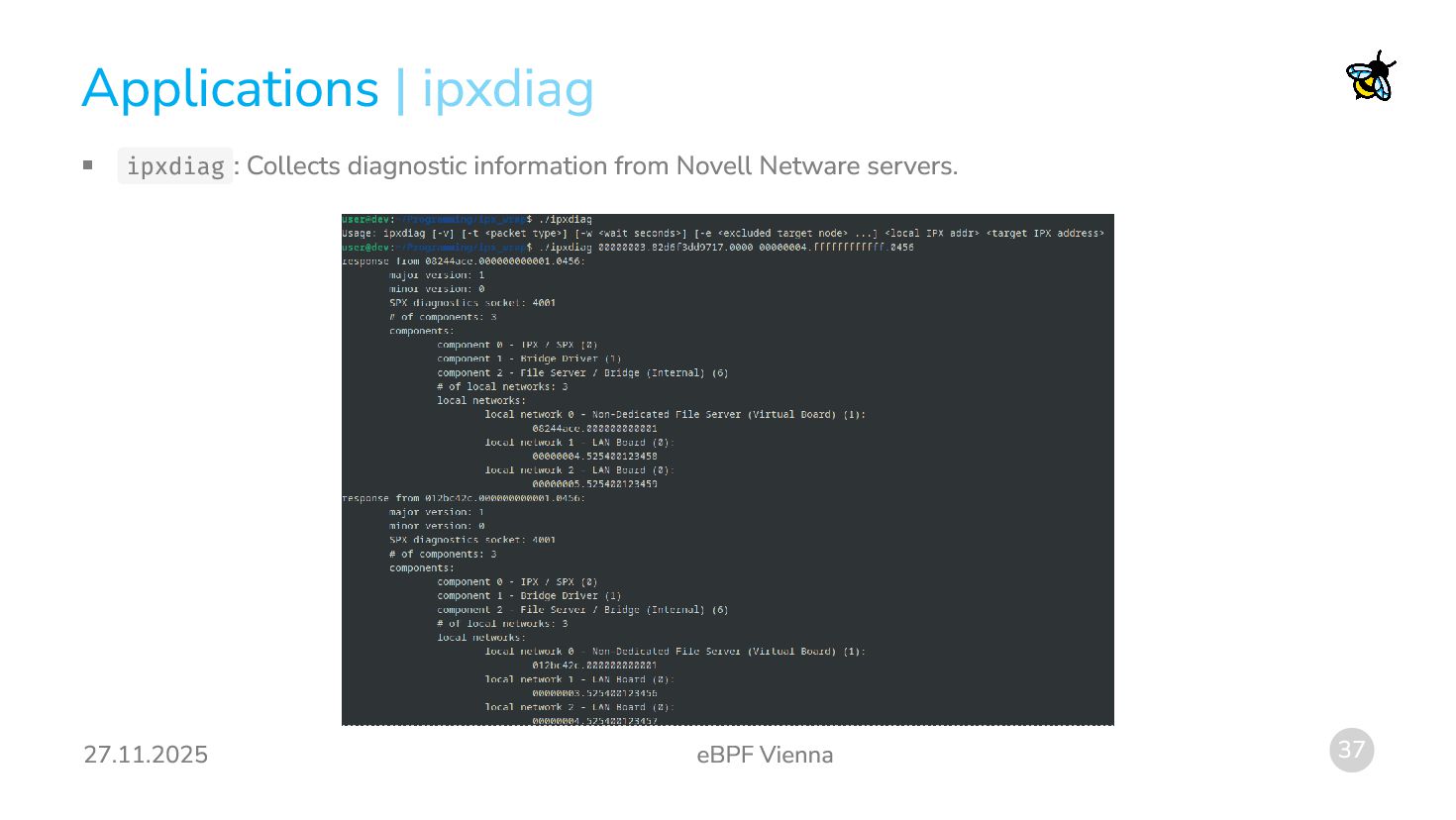{kind=link}
{kind=link}
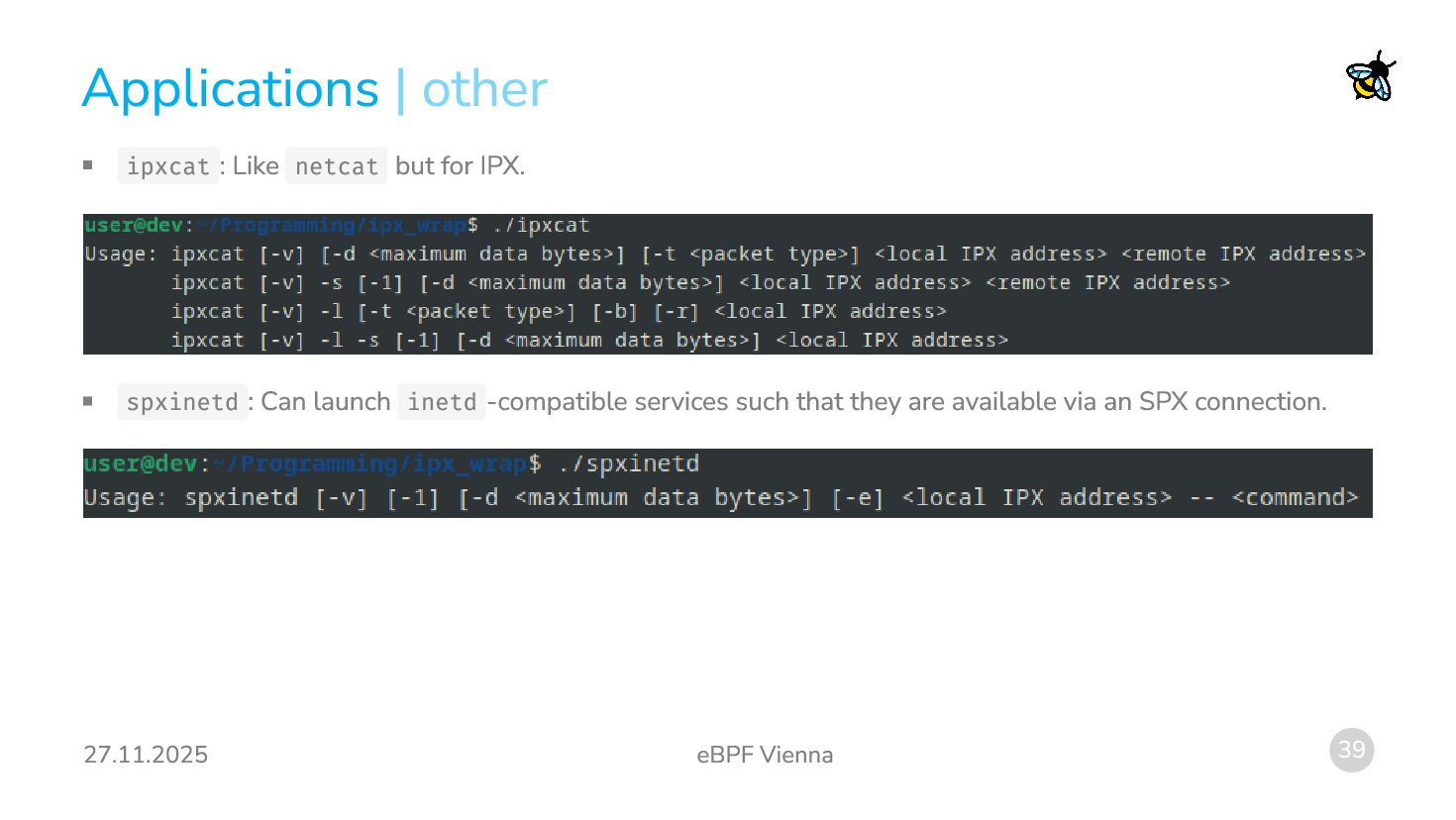{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![27.11.2025 eBPF Vienna 49 The Code https://github.com/twisted-pear/ipx_wrap Contact: [email protected]](https://files.speakerdeck.com/presentations/4db72f5a655b420ca5852c63b489d67a/slide_48.jpg){kind=link}